Всем привет! В данный момент наша команда озвучки ищет человека, который сможет сделать мод для озвучки игры «Доки Доки литературный клуб» и «Доки Доки плюс», а также в дальнейшем участвовать в нашей группе для помощи в создании модов.
Мы — группа энтузиастов, которые любят заниматься этим хобби. Данный пост — не вакансия, а поиск человека, которому также, как и нам, интересно попробовать себя в этом направлении!
Я пробую заниматься разработкой игр на Unity. Получается как попало. А хочется по хорошему. Научиться разбивать проект на модули, встраивать отдельные системы, снизить связанность, понять как устанавливать зависимости, научиться делать тесты, разобраться с атрибутами. Делать код расширяемым! В общем - ищу наставника.
На приведенной ниже диаграмме показана схема работы поисковой системы.
▶️ Шаг 1 - Краулинг
Веб-краулеры сканируют интернет в поисках веб-страниц. Они переходят по ссылкам URL с одной страницы на другую и сохраняют URL в хранилище URL. Краулеры ищут новый контент, включая веб-страницы, изображения, видео и файлы.
▶️ Шаг 2 - Индексирование
После того как веб-страница просмотрена, поисковая система анализирует ее и индексирует содержимое, найденное на странице, в базе данных. Содержимое анализируется и классифицируется. Например, оцениваются ключевые слова, качество сайта, свежесть контента и многие другие факторы, чтобы понять, о чем эта страница.
▶️ Шаг 3 - Ранжирование
Поисковые системы используют сложные алгоритмы для определения порядка результатов поиска. Эти алгоритмы учитывают различные факторы, включая ключевые слова, релевантность страниц, качество контента, вовлеченность пользователей, скорость загрузки страниц и многие другие. Некоторые поисковые системы также персонализируют результаты, основываясь на истории поиска пользователя, его местоположении, устройстве и других личных факторах.
▶️ Шаг 4 - Запрос
Когда пользователь выполняет поиск, поисковая система просматривает свой индекс, чтобы предоставить наиболее релевантные результаты.
Год назад я наткнулся на статью, которая предсказывала деградацию нейросетей и автор приводил интересную теорию:
● Нейросети обучаются на контенте из интернета, который по большей части делает человек.
● Качество итоговой работы нейросети на данный момент ниже, чем оригинальный контент живого автора. Логические и смысловые ошибки, а так же некое "отсутствие души".
● Несмотря на это, нейросети массово используют для создания контента. Растет количество некачественных материалов в интернете и нейросеть начинает брать эти данные для обучения.
● Из-за общего снижения качества "скармливаемой" информации, нейросеть начинает тупить, все чаще повторяя свои же ошибки и неточности.
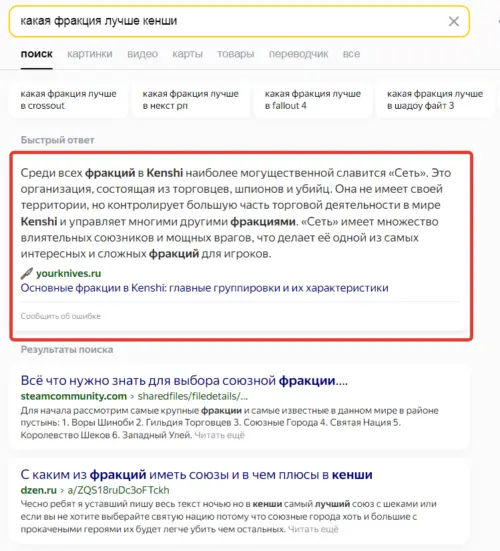
Вот недавно я решил поиграть в Kenshi, вспомнить лор и почитать информацию о фракциях. И первая же статья которую мне выдает поиск Яндекса выглядит так:
▸ Я может быть какое то обновление пропустил, но про "Сеть" в Кенши не слыхал
Увидев этот странный текст, я из интереса перешел по ссылке, а там безумие в чистом виде!
▸ Даже в Kenshi есть свой филиал "Без баб"
▸ А как вам такое? Холодные осадки в Kenshi осознали себя и из погодных условий превратились во фракцию
▸ А Шеки решили позабыть свой культ битвы и стать торговцами тех-охотниками
Для тех кто еще не понял - эта статья написана нейросетями!
Написана убого, коряво, без намека на логику, но с нужными SEO элементами - тот самый информационный мусор. А самое забавное, что мусор вынесен на первую позицию поисковой выдачи Яндекса. Да что там, 5 из 15 ссылок на первой странице поиска вели на такие же плоды нейросетей разной степени бредовости.
И в этом ключевая проблема нейросетей - слишком высокая скорость генерации контента. Она априори будет выше, чем создание уникального контента от живого автора. Ужасное качество итогового продукта меркнет на фоне человеческой жадности и лени.
Какая задача у информационного контента в 21 веке? Решить проблему пользователя? Нет - привлечь трафик и желательно здесь и сейчас, ведь трафик это деньги. Поэтому количество такого контента будет расти в геометрической прогрессии.
Масштаб проблемы и как она будет решаться в будущем?
На мой взгляд ключевой момент - это умение отличать материалы живого человека и материалы сделанные нейросетью. И я говорю даже не про умение пользователя, а про умение машинных систем.
● Для самих нейросетей встает вопрос обучения. Chat-GPT потребляет информацию из интернета и недавно с него сняли ограничения 2021 года (все что вышло позже этой даты нейросеть не учитывала). Если на системном уровне не будет фильтра, то в обозримом будущем качество ответов заметно упадет, ведь они будут составляться на основе ошибочных материалов созданных нейросетью до этого.
● Google, Яндекс и другие поисковики в какой то момент столкнутся с недоверием аудитории, ведь перестанут решать основную задачу пользователя - поиск полезной информации. Пока что их инструменты оценки качества контента слишком примитивны, что доказывает пример приведенный в начале статьи (1/3 выдачи поиска загажена мусором нейросетей). Единственный возможный критерий отбора доступный в данной ситуации - отдавать приоритет оригинальным статьям от живого автора.
А что в итоге?
Я пишу эту статью для того, чтобы люди более критично относились к информации в интернете и поддерживали живых авторов. Экспертного контента в сети все меньше и нельзя позволить ему утонуть под лавиной бреда нейросетей. В конце концов за ошибкой человека стоит мыслительный процесс, а за ошибкой нейросети - случайный алгоритм. И пока что к человеку доверия больше, чем к машине.
Ждем, когда техно-жрецы найдут решение этой проблемы и оно вскроет еще десяток других. А пока подписывайся на мой гоблинский блог - тут много интересного про разработку игр и нейросети.
P.S. По поводу моего месячного отсутствия. Несмотря на навалившийся ворох дел - я не забрасывал изучение инструментов для разработки игр. Просто написание статьей не вписывалось в мое плотное расписание. В ближайшие пару недель постараюсь выложить новую статью про Godot.
Давеча приглянулись одни онлайн курсы по Python, но сохраненная ссылка на них затерялась, поиск в гугл тоже не помог, т.к. название не помню. Признаки следующие:
Некрупная, не мейнстримовая как Нетология, Гигбрейнс, Яндекс, Скиллбокс/фактори и т.д.
Всем привет, ищу стажировку или опытного программиста, который возьмет на под свое крыло неопытного бакалавра, готового выполнять черновую работу.
Работаю джуном ковыряю в основном php( ну еще HTML, CSS). Студентом был отвратительным - чудом закончил универ(нет, не в этом году), но волей случая таки вкатился в это дело. Сейчас мои основные задачи состоят из парсинга, парсинга и парсинга. Но это дело не вечное, стараюсь смотреть в будущее, стремлюсь к повышению скилла.
Навыков - нет, ничего не умею (вот прям база), но готов учиться на ходу.
Если что-то будет получаться - копеечка не помешает, но можно, конечно, и без нее.
Давным-давно, когда я был маленький, в интернете ходила байка то ли про программиста, то ли про айтишника. История явно выдуманная. Такой дневник наблюдений то ли в НИИ, то ли еще где-то. Суть сводилась к тому, что автор писывал последовательность дней. к ним приходили новенькие, они гнали самогон через реактор из странных продуктов, делали какой-то лазер и еще куча всякой дичи. Было смешно читать. Пытался вспомнить и нагуглить - ничего не получается. Помогите пожалуйста вспомнить, найти и вернуться в детство.