Люди, спасите. Может у кого есть FineReader licensing server и license manager? Я весь интернет перерыла, ничего не нашла. И вообще я в этом не разбираюсь, помогите((( Мне дали задание серверную часть установить, лицензии все куплены, все есть, а сервер год назад слетел и хз как восстановить это все 🥲🥲🥲
Столкнулся с задачей перевести на русский язык скан старого аргентинского документа. Проблема в том, что я не знаком с испанским языком, а распознавание символов происходит с ошибками. Проблема решена связкой (OCR) abbyy finereader + ИИ (deepseek). Об этом, собственно, пост.
Ниже приведён пример страницы документа:
Работа со сканом. Улучшение изображения
Открываем документ в редакторе OCR Abbyy Finereader (инструменты - редактор OCR), сталкиваемся с ошибкой "неверное разрешение изображения".
Не забудьте выставить язык распознавания, в данном случае - испанский
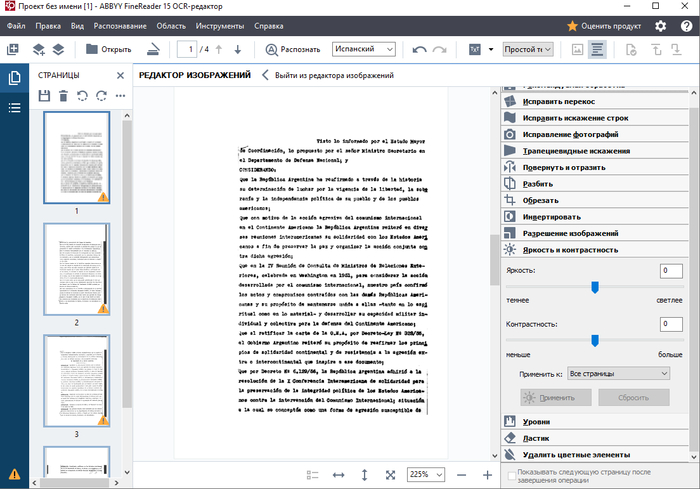
Будем исправлять. Заодно отредактируем сами изображения сканов, чтобы облегчить работу программе для распознавания символов. Нажимаем "Открыть редактор изображений". В этот редактор так же можно перейти через панель инструментов сверху.
Открывается, собственно, редактор:
Я рекомендую идти по панели инструментов, которая расположена справа, в обратном порядке, т.е. снизу вверх.
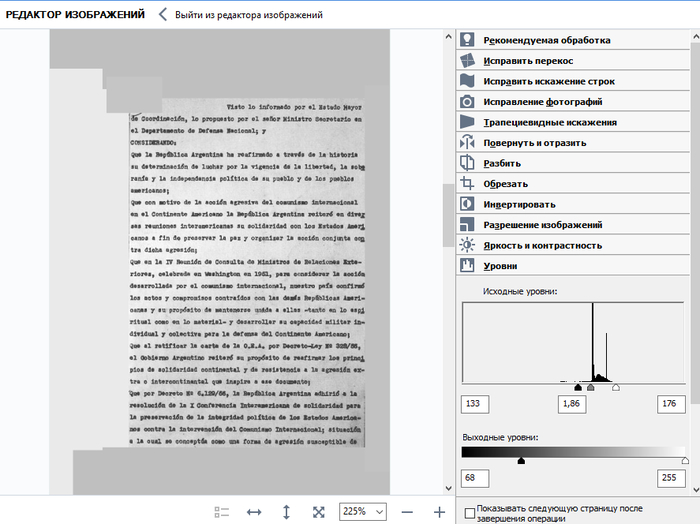
1. Для начала выбираем ластик и несчадно вырезаем абсолютно всё, кроме текста, который нам нужен: печати, подписи, штампы, номера страниц и т.п.
2. Далее - Уровни. Смещаем исходные уровни таким образом, чтобы крайние ползунки попадали на начало и конец уровней. С помощью чёрного ползунка выходного уровня "подтягиваем" контраст скана. На данном этапе наша задача - добиться хорошего соотношения контрастности изображения с фоновыми шумами от бумаги.
Не забывайте применять изменения для страницы к переходу на следующий пункт
3. В случае с яркостью и контрастностью изображения наша задача фактически полностью "отбелить" задний фон, но при этом максимально сохранить читаемость символов. Для этого в процессе передвигания ползунков лучше приближать текст так, чтобы следить за читаемостью символов.
Я случайно применил изменения, поэтому положения ползунков обнулились((( Но, думаю, тут принцип понятен
4. Далее мы заходим в Разрешение изображений, нажимаем "определить оптимальное" и применяем то, что нам посоветовала программа.
После этого мы можем выйти из редактора изображений и провести распознавание документа.
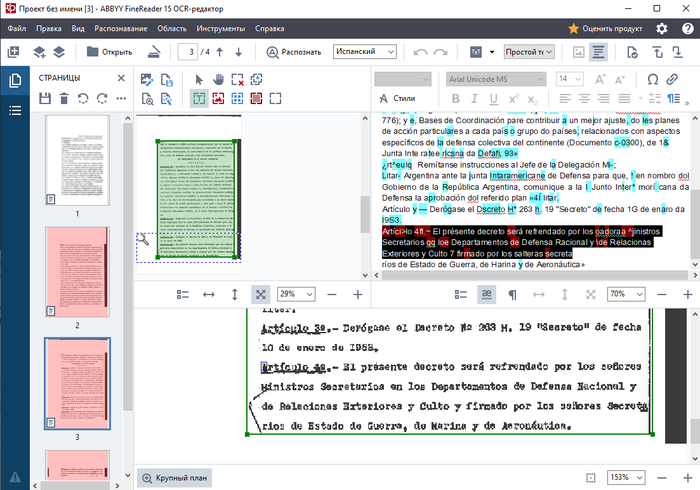
"Абракадабра" выделена черным"
Мы видим, что качества распознавания нам далеко недостаточно для машинного перевода. Часто встречаются артефакты, вот кусок текста для примера:
"Artíci>lo 4fl.~ El présente decreto será refrendado por los oadoraa ^jinistros Secretarios qq loe Departamentos de Defensa Racional y \de Relacionas Exteriores y Culto 7 firmado por los salteras secreta"
Не расстраиваемся. Жмём файл - сохранить как - документ TXT и сохраняем файл в удобное место. Этот файл содержит наш распознанный текст.
Исправляем ошибки распознавания в DeepSeek
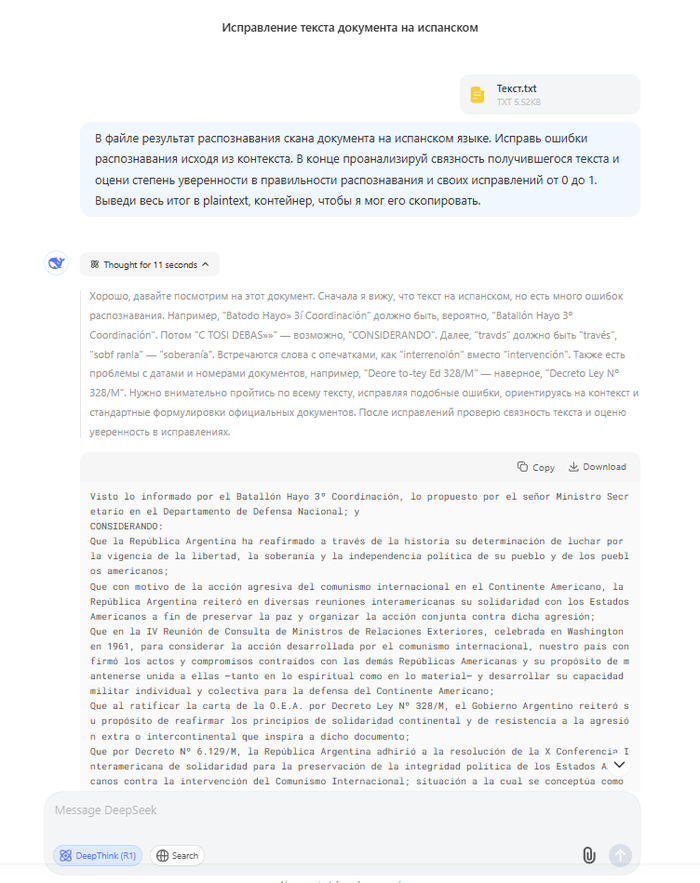
Заходим на chat.deepseek.com, включаем DeepThink(R1), прикрепляем к чату наш txt-файл и пишем промпт:
В файле результат распознавания скана документа на испанском языке. Исправь ошибки распознавания исходя из контекста. В конце проанализируй связность получившегося текста и оцени степень уверенности в правильности распознавания и своих исправлений от 0 до 1. Выведи весь итог в plaintext, контейнер, чтобы я мог его скопировать.
Итог работы промпта
В данном случае модель выдала такую оценку **Степень уверенности:** 0.9 (Незначительные неясности остаются в деталях, например, «C-776» — возможна опечатка в номере, но общая точность высокая.)
В остальном всё замечательно. Благодаря plaintext можем в один клик скопировать или скачать полученный результат на компьютер и использовать его для перевода на русский. Для перевода, по моему мнению, лучше всего подходит переводчик от Яндекса, но это уже дело вкуса.
Перевод и структурирование текста
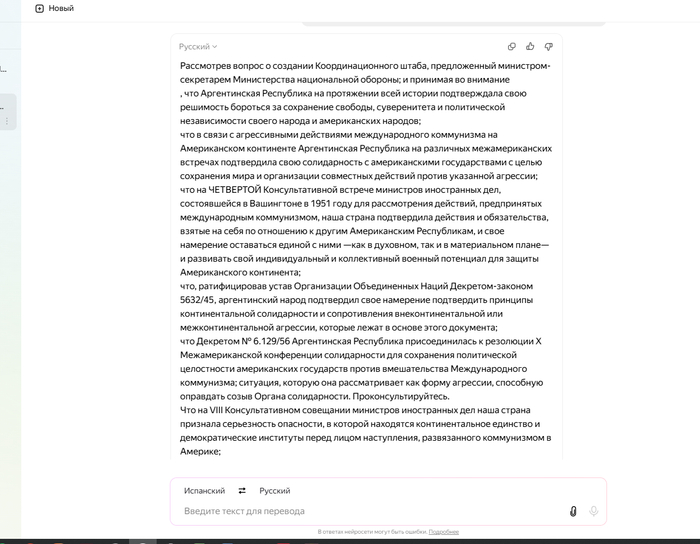
В Яндекс.Браузере переходим в нейропереводчик (в адресной строке browser://neuro-translate/) и вставляем туда свой текст, переводим и получаем нечто следующее:
Сплошной текст читается тяжело
Чтобы структурировать текст я пользуюсь нейроредактором (browser://neuro-editor), использую промпт "не изменяя текст структурируй его". В процессе оформления структуры текста яндекс нейро убирает мелкие неточности перевода, что улучшает сам текст.
Итого мы получили готовый документ, с которым можно работать:
Надеюсь, кому-то было полезно.
Сам документ содержит сведения о деятельности Аргентины в рамках антикоммунистической оси в период Холодной Войны. В частности, в документе ведется речь о том, что ВС Аргентины вмешивались в конфликт в Карибском бассейне, действуя против Кубы, СССР и Китая.
P.S. Дописав пост понял, что он огромный. Это из-за скриншотов. На самом деле весь процесс занимает 5-10 минут максимум. И, конечно, забыл: это личный опыт, наверняка есть способы лучше, проще, быстрее и т.д., но я о них пока не знаю. Поделитесь - буду благодарен.
🦟 Газета «Труд» 20 июля сообщала: «Двое москвичей решили провести пару недель в палатке на берегу знакомого озера. К поездке купили даже импортное снадобье от комаров. Между прочим, за доллары, в аптеке. В первый же вечер смазали им лица и руки. И только успели откупорить бутылку, плеснуть в стаканы, как началось… Полчища звенящих насекомых обрушились на друзей, покрывая толстым шевелящимся слоем. И не было от них спасения. Назавтра ребята сбежали в Москву. В аптеке, куда они обратились с претензиями и с тюбиком купленного здесь же крема, им прочитали инструкцию, приложенную к тюбику, где было написано (естественно, не по-русски): мазь содержит ароматические вещества, побуждающие комаров к любовным играм, ее следует тонким слоем нанести на какой-либо предмет и поместить его поодаль, тогда все комары округи к нему и устремятся, и вам уже досаждать не станут».
20 июля московская компания Bit Software провела презентацию новой программы распознавания текста FineReader. По словам генерального директора фирмы Давида Яна, при создании алгоритма распознавания была применена новая технология, созданная сотрудниками фирмы — она получила название "фонтанное преобразование". Эта технология дает возможность заранее обучить программу узнавать символы самых разнообразных шрифтов и размеров, что позволило сделать программу максимально простой для пользователя. Не желающий разбираться в тонкостях оптического распознавания образов конечный потребитель может управлять программой с помощью единственной кнопки — "Scan and Read". По уверениям г-на Яна, для текстовых оригиналов удовлетворительного качества FineReader дает не более 2-3 ошибок на машинописный лист. Новая система поступит в продажу в августе, цена — 59,9 тыс. руб. «КоммерсантЪ» 23 июля 1993 года
Материал проекта «30 лет назад», в котором я ежедневно рассказываю о событиях, произошедших в этот день, ровно 30 лет назад. Дабы не травмировать, и без того слабую психику телеграмоненавистников, ссылки спрятал в профиль
Хочу рассказать свой способ распознавания текста. Наверняка о нем все слышали, но боялись спросить. Итак, берём программу (название скрыто во избежание рекламы)
Вот что она умеет.
В ней очень легко разобраться.
И у нее широкие возможности. Кстати, у программы есть мобильная версия, скачать которую вы всегда сможете на (название скрыто). Спасибо. Если будет интересно, напишу немного подробнее.
(Здесь может быть ссылка на Ваш ТГ) (Здесь может быть ссылка на Ваш Дзен) На правах рекламы.
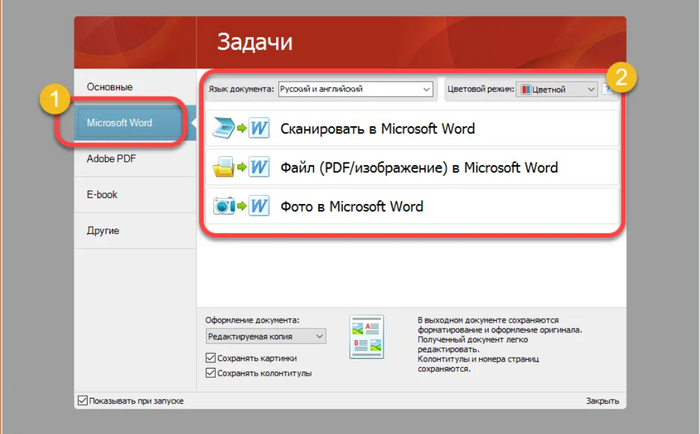
Данный пост не призывает нарушать чьи либо авторские права. Пост несет ознакомительный и познавательный характер для тех кто хочет переводить старые книги в цифру в хорошем качестве. Пост рассказывает о подробностях пользования программой ABBYY FineReader (в моем случае 15 версия).
Сразу к делу. FineReader на мой взгляд очень капризная программа со своими особенностями, поэтому сразу перейду к способу, который я вычислил путем многократных ошибок и потери часов рабочего времени.
Итак, попунктно, что нам нужно для создания цифровой копии. Конкретно я хотел PDF файл с хорошей читаемость и возможностью поиска по тексту (с текстом который спрятан под картинку):
1) Нам нужны фотографии (оригиналы) книги в хорошем качестве. В моем случае, сканер (со стеклянной закрывающейся крышкой) мне не помог, т.к. полный разворот книги невозможно разместить на ровной поверхности сканера из-за корешка книги (корешок не гнется) поэтому на сканере часть текста теряется и этот вариант получения фотографий я отмел.
Я занялся съемкой страниц книги на камеру смартфона.
Условия съемки следующие: Столик, с одной стороны которого закреплен на штатив смартфон (высота штатива подобрана таким образом чтобы лист книги влезал в кадр), смартфон расположен горизонтально и снимает ровно плоскость стола, с другой стороны находится место оператора.
Для удобства съемки к смартфону в комплект был куплен небольшой беспроводной Bluetooth пульт. Пульт соединяться со смартфоном по Bluetooth и при нажатии кнопки имитирует нажатие на кнопку повышения громкости смартфона. В настройках камеры можно выставить опцию "кнопка громкости" отвечает за затвор камеры, т.е. делает снимок. Сама кнопка кладётся на пол и по нажатии на неё пальцем ноги осуществляется съемка, очень удобно и освобождает руки оператора.
До начала съемки, в моем смартфоне можно было вручную выставить фокусное расстояние, так называемый режим Pro, чем я и воспользовался. Автофокус же постоянно сбивался в процессе перелистывания страниц.
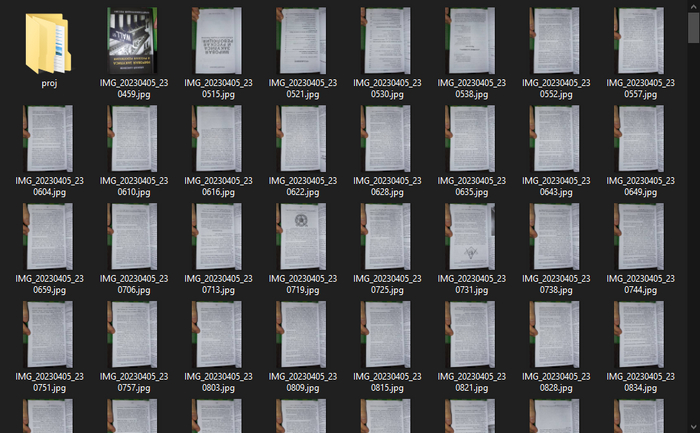
Порядок съемки страниц только такой: Снимаем все Нечетные страницы, затем все Четные страницы. По итогу, мы должны иметь папку в которой будут собраны фотографии примерно такого вида:
Первой фотографией у меня идёт обложка, её мы пока не рассматриваем. Мы знаем, что в этой папке страницы у нас идут в таком порядке: 3, 5, 7 ... 463, 2, 4, 6, 8, 10.... 462. Это важно, в дальнейшем мы укажем программе их расположить в правильном порядке.
Снимать нужно с наименьшим искажением текста, как можно меньше раскрывая обложку книги, при этом придавливать пальцем с противоположной стороны, чтобы страницы не смещались. Страницы всё равно будут смещаться и это мы поправим на этапе обработки.
Итак, мы имеем папку с условными 463 страницами, переходим на этап обработки фото в программе.
2) Создаем новый проект в программе.
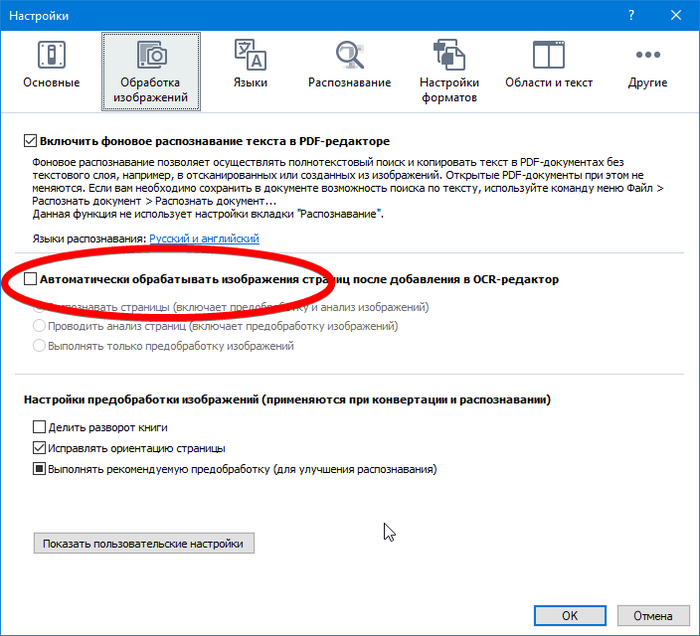
Открываем в нем все изображения, но перед этим надо убрать галочку автоматической обработки изображений в опциях. Я не знаю по какой причине, но автоматическая обработка (я пытался много раз) обрезает часть текста, мы теряем часть страницы, поэтому будем обрабатывать вручную (сразу все страницы).
Теперь выделяем все наши замечательные изображения и они скорее всего будут развернуты на 180 градусов, поэтому сначала их надо развернуть. Заходим в редактор изображений (ctrl+i) выбираем пункт повернуть на 180 для всех выделенных изображений, ждем несколько минут.
Затем, точно также жмем пункты "Исправить перекос" и "Исправить искажение строк".
Далее, лично я осветляю изображения.
И мне этого достаточно. изображения уже имеют хороший читаемый вид. А теперь нужно удалить с них всё лишнее, т.е. обрезать их. К сожалению, данный этап придется делать вручную. Много раз пробовал автоматические инструменты, но все они режут не так как надо и выдают много ошибок. Подрезание вручную даёт самый наилучший результат для меня.
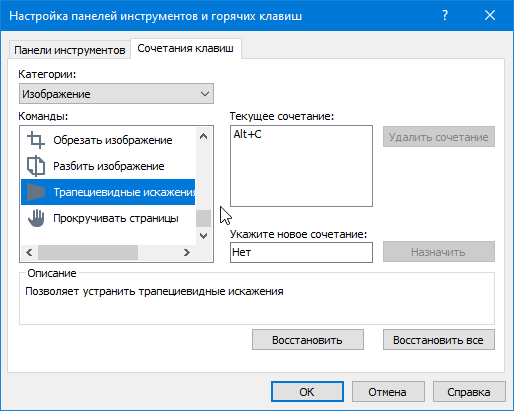
Чтобы ускорить процесс мы назначим горячие клавиши для команд редактора изображений. У меня стоит так:
Трапециевидные искажения: Alt + C Стереть: Alt + V Предыдущая страницы: Alt + Z Следующая страницы: Alt + X
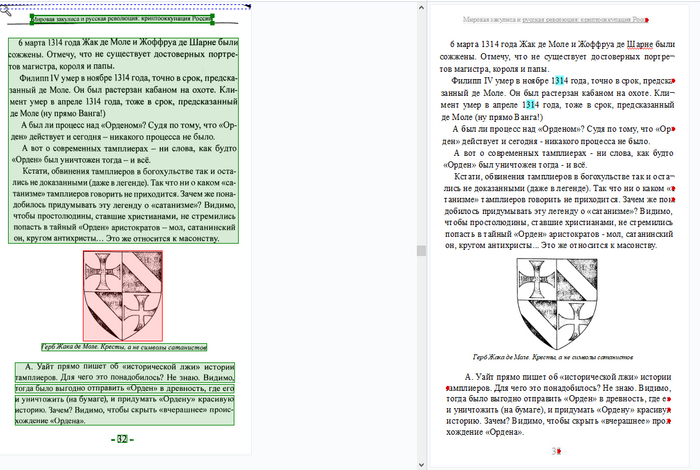
С помощью сетки трапециевидных искажений мы пытаемся выровнять текст, заодно сразу его и обрезать, стараемся натянуть сетку вдоль текста как на картинке ниже:
Кликаем два раза ЛКМ по сетке и сетка подрежет изображение. Затем берем инструмент "Стереть" (ластик) и убираем лишние элементы с картинке, например часть пальца или часть текста который вылез слева. Жмем на кнопку "следующее изображение". Процесс не быстрый, но результат в конечном итоге лучше любых автоматических.
Кстати, я заметил, что выделение страниц мышкой конфликтует с переключением страниц горячими клавишами. Так что иногда надо переключать страницы вперед и назад чтобы сбросить выделение мышкой.
3) Теперь запускаем анализ и распознавание текста. Именно в таком порядке. Выделяем все страницы и запускаем анализ. (ctrl + E) Ждем несколько минут. Затем запускаем распознавание всех страниц. (ctrl + R). Результат примерно такой:
Можно по желанию подкорректировать оглавление, чтобы переход по главам работал корректно. И мы уже почти закончили.
4) Теперь нужно расположить страницы в правильном порядке. Выделяем все страницы и выбираем пункт "изменить порядок страниц".
В диалоговом окне выбираем второй пункт:
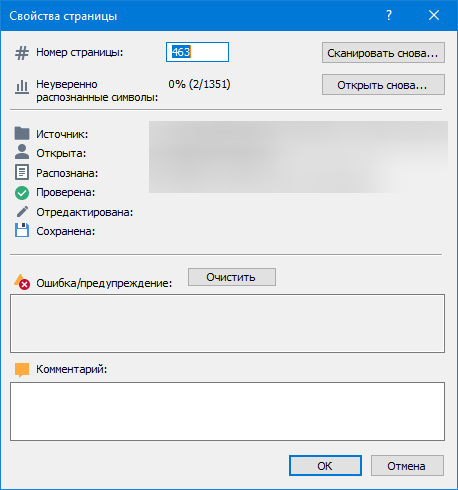
Если самая последняя страницы вылезла вперед как у меня, то нужно зайти в её свойство и присвоить ей правильный номер.
5) Создание PDF файла. Теперь я создаю PDF документ с возможность поиска.
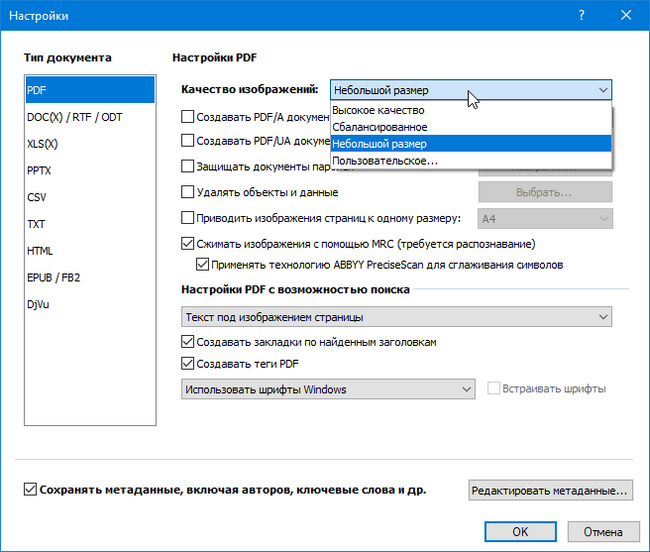
Нажимаем настройки и выбираем качество изображений.
Ждем несколько минут и документ готов. Оглавление активно и на него можно жмякать, чтобы перемещаться по документу. Можно выделять текст и копировать его. Всё как я хотел.
14 марта возникла необходимость купить пакет на 500 страниц для сервиса распознавания finereaderonline.com. Из них было израсходовано лишь 200, остальные 300 сгорят уже 14 апреля. Больше мне распознавать нечего, и мне очень жаль терять оплаченные страницы... Сервис позволяет не только неплохо распознавать текст на изображениях, экспортируя в большинство популярных форматов, но и применить к нему машинный перевод, который, на мой взгляд, качественнее оного от Корпорации Добра. Крайне надеюсь, что кому-нибудь на пикабу такая штука может пригодиться, а я с радостью безвозмездно поделюсь страничками с вами! :-)
Когда-то мне это надоело и стало обыденным и простым... но сейчас мне во мне загорелся огонь азарта. Мне нравится это делать, каждый раз зная все хитрости "доброжелателя", но всё же с интересом выполняя очередную миссию я получаю значительное удовольствие...
И вот новая цель... Пробираюсь в окно... снова... но всё же с каким-то трепетом и лёгким страхом провала. Ищу скрытые элементы, какие-то незначительный "полезные" примочки... Но тут обнаруживаю что-то новенькое... А, нет, с этим я уже сталкивался. Тут всё просто, началась подготовка. Она будет длиться относительно недолго, но главное - не пропустить важные пункты и опять те же примочки... Подготовка завершена, но впереди ещё многое...
Теперь надо выбрать путь и стиль выполнения задачи. С путём всё просто, а режим... тут всё не так однозначно... Если видны трудности, то стиль выбран правильно. А возвращаться уже нельзя.
На следующем шаге можно передохнуть и побольше подумать, что будет нужно дальше... Проверить снаряжение, перевести дух. Решение принято, теперь надо ждать... Снова... Это будет дольше, чем в первый раз, но почти всё позади и прошло гладко. Эта мысль согревает сознание и сводит с ума одновременно. Ты понимаешь, что близится конец и ты скоро насладишься результатом, перед твоими глазами проходит весь прогресс. Терпение даёт свои плоды, ты снимаешь последнюю галочку "Запустить программу" и нажимаешь кнопку "Завершить установку программы и выйти".