Данный пост не призывает нарушать чьи либо авторские права. Пост несет ознакомительный и познавательный характер для тех кто хочет переводить старые книги в цифру в хорошем качестве. Пост рассказывает о подробностях пользования программой ABBYY FineReader (в моем случае 15 версия).
Сразу к делу. FineReader на мой взгляд очень капризная программа со своими особенностями, поэтому сразу перейду к способу, который я вычислил путем многократных ошибок и потери часов рабочего времени.
Итак, попунктно, что нам нужно для создания цифровой копии. Конкретно я хотел PDF файл с хорошей читаемость и возможностью поиска по тексту (с текстом который спрятан под картинку):
1) Нам нужны фотографии (оригиналы) книги в хорошем качестве. В моем случае, сканер (со стеклянной закрывающейся крышкой) мне не помог, т.к. полный разворот книги невозможно разместить на ровной поверхности сканера из-за корешка книги (корешок не гнется) поэтому на сканере часть текста теряется и этот вариант получения фотографий я отмел.
Я занялся съемкой страниц книги на камеру смартфона.
Условия съемки следующие: Столик, с одной стороны которого закреплен на штатив смартфон (высота штатива подобрана таким образом чтобы лист книги влезал в кадр), смартфон расположен горизонтально и снимает ровно плоскость стола, с другой стороны находится место оператора.
Для удобства съемки к смартфону в комплект был куплен небольшой беспроводной Bluetooth пульт. Пульт соединяться со смартфоном по Bluetooth и при нажатии кнопки имитирует нажатие на кнопку повышения громкости смартфона. В настройках камеры можно выставить опцию "кнопка громкости" отвечает за затвор камеры, т.е. делает снимок. Сама кнопка кладётся на пол и по нажатии на неё пальцем ноги осуществляется съемка, очень удобно и освобождает руки оператора.
До начала съемки, в моем смартфоне можно было вручную выставить фокусное расстояние, так называемый режим Pro, чем я и воспользовался. Автофокус же постоянно сбивался в процессе перелистывания страниц.
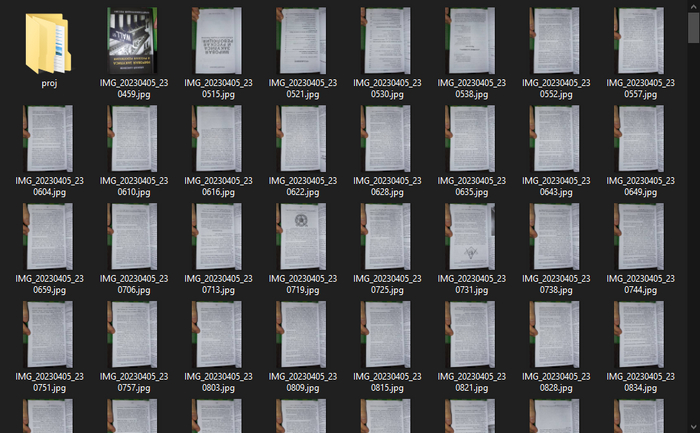
Порядок съемки страниц только такой: Снимаем все Нечетные страницы, затем все Четные страницы. По итогу, мы должны иметь папку в которой будут собраны фотографии примерно такого вида:
Первой фотографией у меня идёт обложка, её мы пока не рассматриваем.
Мы знаем, что в этой папке страницы у нас идут в таком порядке:
3, 5, 7 ... 463, 2, 4, 6, 8, 10.... 462.
Это важно, в дальнейшем мы укажем программе их расположить в правильном порядке.
Снимать нужно с наименьшим искажением текста, как можно меньше раскрывая обложку книги, при этом придавливать пальцем с противоположной стороны, чтобы страницы не смещались. Страницы всё равно будут смещаться и это мы поправим на этапе обработки.
Итак, мы имеем папку с условными 463 страницами, переходим на этап обработки фото в программе.
2) Создаем новый проект в программе.
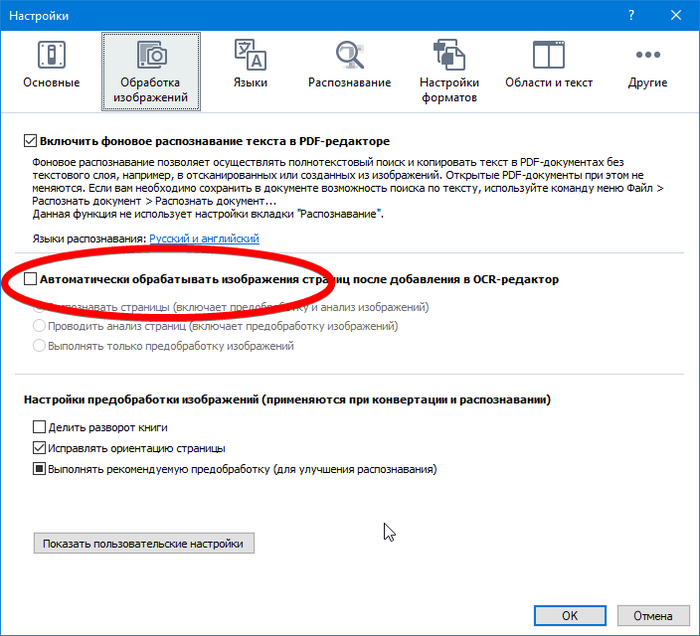
Открываем в нем все изображения, но перед этим надо убрать галочку автоматической обработки изображений в опциях. Я не знаю по какой причине, но автоматическая обработка (я пытался много раз) обрезает часть текста, мы теряем часть страницы, поэтому будем обрабатывать вручную (сразу все страницы).
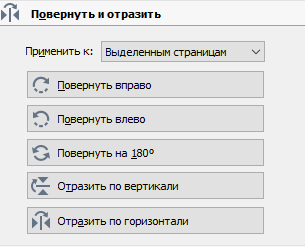
Теперь выделяем все наши замечательные изображения и они скорее всего будут развернуты на 180 градусов, поэтому сначала их надо развернуть.
Заходим в редактор изображений (ctrl+i) выбираем пункт повернуть на 180 для всех выделенных изображений, ждем несколько минут.
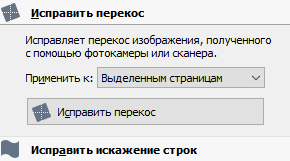
Затем, точно также жмем пункты "Исправить перекос" и "Исправить искажение строк".
Далее, лично я осветляю изображения.
И мне этого достаточно. изображения уже имеют хороший читаемый вид.
А теперь нужно удалить с них всё лишнее, т.е. обрезать их. К сожалению, данный этап придется делать вручную. Много раз пробовал автоматические инструменты, но все они режут не так как надо и выдают много ошибок. Подрезание вручную даёт самый наилучший результат для меня.
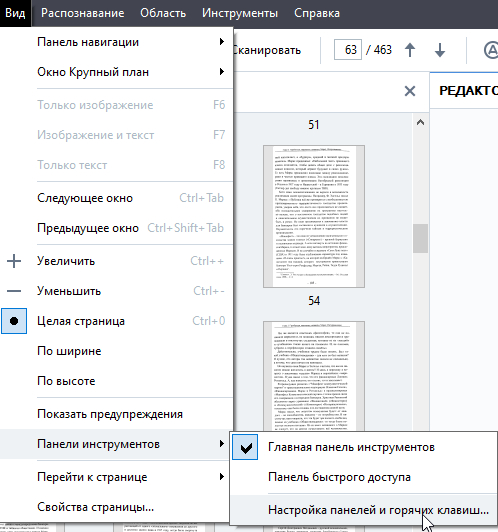
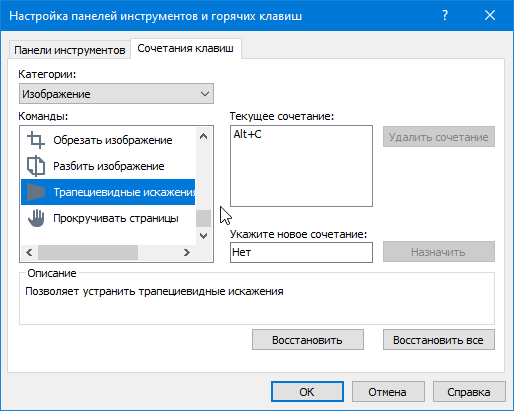
Чтобы ускорить процесс мы назначим горячие клавиши для команд редактора изображений.
У меня стоит так:
Трапециевидные искажения: Alt + C
Стереть: Alt + V
Предыдущая страницы: Alt + Z
Следующая страницы: Alt + X
С помощью сетки трапециевидных искажений мы пытаемся выровнять текст, заодно сразу его и обрезать, стараемся натянуть сетку вдоль текста как на картинке ниже:
Кликаем два раза ЛКМ по сетке и сетка подрежет изображение.
Затем берем инструмент "Стереть" (ластик) и убираем лишние элементы с картинке, например часть пальца или часть текста который вылез слева.
Жмем на кнопку "следующее изображение".
Процесс не быстрый, но результат в конечном итоге лучше любых автоматических.
Кстати, я заметил, что выделение страниц мышкой конфликтует с переключением страниц горячими клавишами. Так что иногда надо переключать страницы вперед и назад чтобы сбросить выделение мышкой.
3) Теперь запускаем анализ и распознавание текста.
Именно в таком порядке.
Выделяем все страницы и запускаем анализ. (ctrl + E) Ждем несколько минут.
Затем запускаем распознавание всех страниц. (ctrl + R).
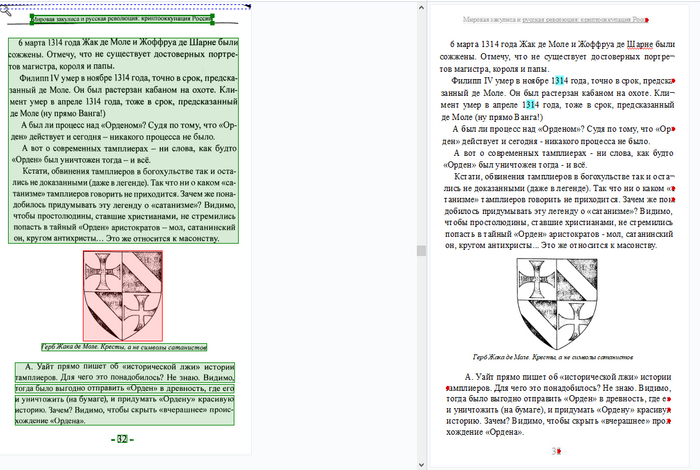
Результат примерно такой:
Можно по желанию подкорректировать оглавление, чтобы переход по главам работал корректно. И мы уже почти закончили.
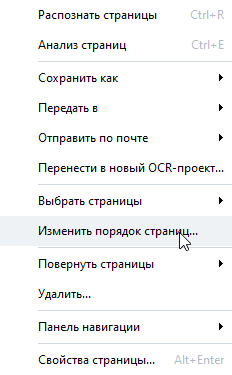
4) Теперь нужно расположить страницы в правильном порядке.
Выделяем все страницы и выбираем пункт "изменить порядок страниц".
В диалоговом окне выбираем второй пункт:
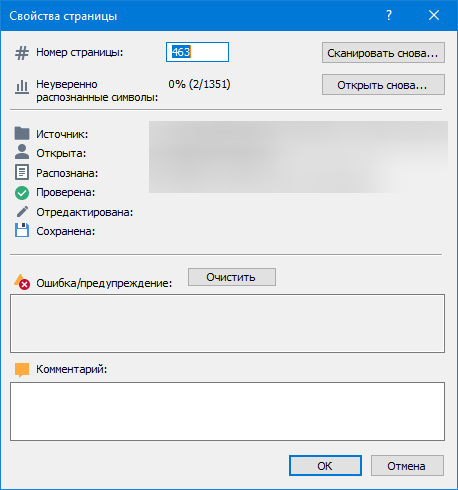
Если самая последняя страницы вылезла вперед как у меня, то нужно зайти в её свойство и присвоить ей правильный номер.
5) Создание PDF файла.
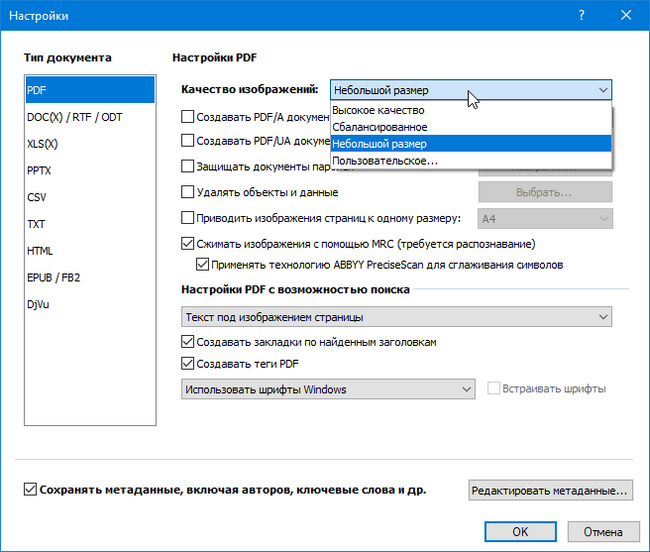
Теперь я создаю PDF документ с возможность поиска.
Нажимаем настройки и выбираем качество изображений.
Ждем несколько минут и документ готов.
Оглавление активно и на него можно жмякать, чтобы перемещаться по документу.
Можно выделять текст и копировать его. Всё как я хотел.
А теперь пляшем и танцуем по возможности.