

Распознавание сканов и их перевод через связку OCR+ИИ
Столкнулся с задачей перевести на русский язык скан старого аргентинского документа. Проблема в том, что я не знаком с испанским языком, а распознавание символов происходит с ошибками. Проблема решена связкой (OCR) abbyy finereader + ИИ (deepseek). Об этом, собственно, пост.
Ниже приведён пример страницы документа:

Работа со сканом. Улучшение изображения
Открываем документ в редакторе OCR Abbyy Finereader (инструменты - редактор OCR), сталкиваемся с ошибкой "неверное разрешение изображения".
Не забудьте выставить язык распознавания, в данном случае - испанский
Будем исправлять. Заодно отредактируем сами изображения сканов, чтобы облегчить работу программе для распознавания символов. Нажимаем "Открыть редактор изображений". В этот редактор так же можно перейти через панель инструментов сверху.
Открывается, собственно, редактор:
Я рекомендую идти по панели инструментов, которая расположена справа, в обратном порядке, т.е. снизу вверх.
1. Для начала выбираем ластик и несчадно вырезаем абсолютно всё, кроме текста, который нам нужен: печати, подписи, штампы, номера страниц и т.п.
2. Далее - Уровни. Смещаем исходные уровни таким образом, чтобы крайние ползунки попадали на начало и конец уровней. С помощью чёрного ползунка выходного уровня "подтягиваем" контраст скана. На данном этапе наша задача - добиться хорошего соотношения контрастности изображения с фоновыми шумами от бумаги.
Не забывайте применять изменения для страницы к переходу на следующий пункт
3. В случае с яркостью и контрастностью изображения наша задача фактически полностью "отбелить" задний фон, но при этом максимально сохранить читаемость символов. Для этого в процессе передвигания ползунков лучше приближать текст так, чтобы следить за читаемостью символов.
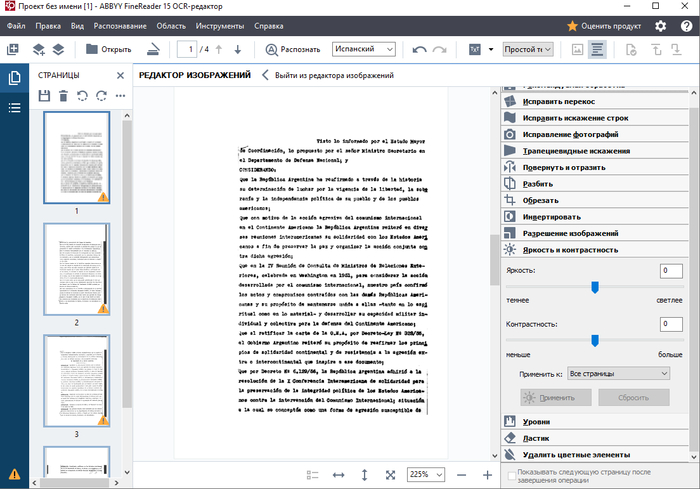
Я случайно применил изменения, поэтому положения ползунков обнулились((( Но, думаю, тут принцип понятен
4. Далее мы заходим в Разрешение изображений, нажимаем "определить оптимальное" и применяем то, что нам посоветовала программа.
После этого мы можем выйти из редактора изображений и провести распознавание документа.
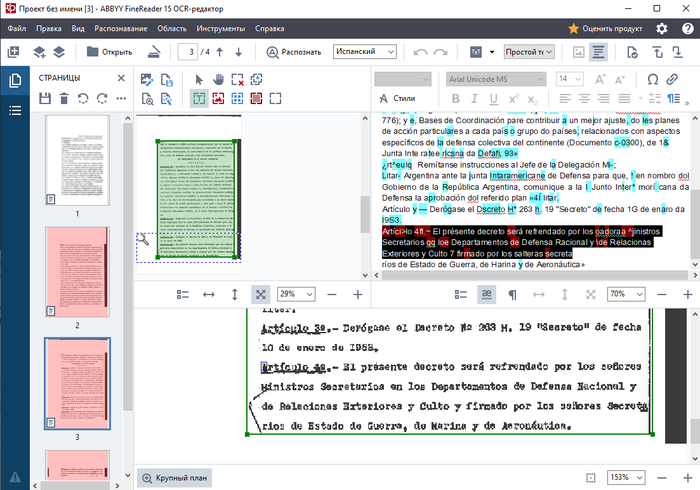
"Абракадабра" выделена черным"
Мы видим, что качества распознавания нам далеко недостаточно для машинного перевода. Часто встречаются артефакты, вот кусок текста для примера:
"Artíci>lo 4fl.~ El présente decreto será refrendado por los oadoraa ^jinistros Secretarios qq loe Departamentos de Defensa Racional y \de Relacionas Exteriores y Culto 7 firmado por los salteras secreta"
Не расстраиваемся. Жмём файл - сохранить как - документ TXT и сохраняем файл в удобное место. Этот файл содержит наш распознанный текст.
Исправляем ошибки распознавания в DeepSeek
Заходим на chat.deepseek.com, включаем DeepThink(R1), прикрепляем к чату наш txt-файл и пишем промпт:
В файле результат распознавания скана документа на испанском языке. Исправь ошибки распознавания исходя из контекста. В конце проанализируй связность получившегося текста и оцени степень уверенности в правильности распознавания и своих исправлений от 0 до 1. Выведи весь итог в plaintext, контейнер, чтобы я мог его скопировать.
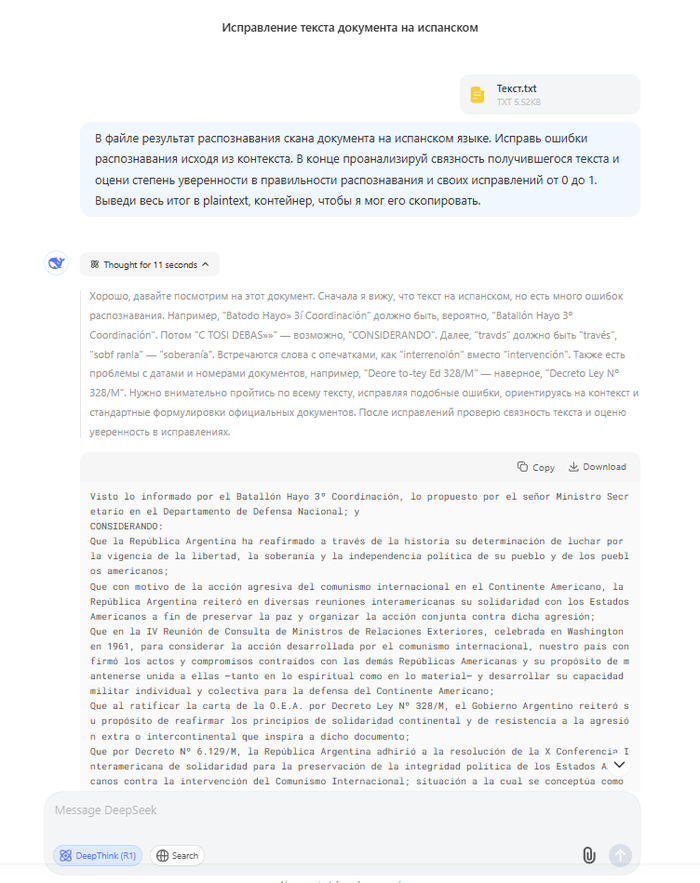
Итог работы промпта
В данном случае модель выдала такую оценку
**Степень уверенности:** 0.9 (Незначительные неясности остаются в деталях, например, «C-776» — возможна опечатка в номере, но общая точность высокая.)
В остальном всё замечательно. Благодаря plaintext можем в один клик скопировать или скачать полученный результат на компьютер и использовать его для перевода на русский. Для перевода, по моему мнению, лучше всего подходит переводчик от Яндекса, но это уже дело вкуса.
Перевод и структурирование текста
В Яндекс.Браузере переходим в нейропереводчик (в адресной строке browser://neuro-translate/) и вставляем туда свой текст, переводим и получаем нечто следующее:
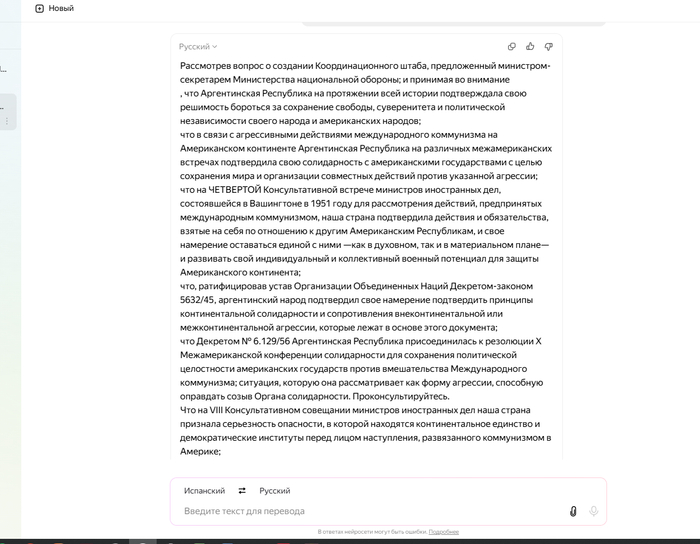
Сплошной текст читается тяжело
Чтобы структурировать текст я пользуюсь нейроредактором (browser://neuro-editor), использую промпт "не изменяя текст структурируй его". В процессе оформления структуры текста яндекс нейро убирает мелкие неточности перевода, что улучшает сам текст.
Итого мы получили готовый документ, с которым можно работать:

Надеюсь, кому-то было полезно.
Сам документ содержит сведения о деятельности Аргентины в рамках антикоммунистической оси в период Холодной Войны. В частности, в документе ведется речь о том, что ВС Аргентины вмешивались в конфликт в Карибском бассейне, действуя против Кубы, СССР и Китая.
P.S. Дописав пост понял, что он огромный. Это из-за скриншотов. На самом деле весь процесс занимает 5-10 минут максимум. И, конечно, забыл: это личный опыт, наверняка есть способы лучше, проще, быстрее и т.д., но я о них пока не знаю. Поделитесь - буду благодарен.