Сегодня необычные сервисы, а помощники для LLM и ИИ-агентов, чтобы они анализировали ваши файлы без галлюцинаций и ошибок. Обычные ИИ плохо справляются с PDF и картиками: путают колонки, не понимают таблицы и заголовки. Следующие инструменты читают документы как человек — учитывают структуру, формат, сноски, даже логику. Эти же инструменты превращают документ в качественно распознанный и разбитый по структуре текст, который уже можно загрузить в Большие Языковые модели (LLM) для дальнейшего взаимодействия без галлюцинаций. Этакие парсеры документов.
Проще, зачем они нужны? Для создания:
• систем поиска по внутренним документам (вопрос-ответ по внутренним документам)
• интеллектуального анализа юридических, медицинских, технических файлов
• создания базы знаний из PDF/HTML/DOCX, изображений и тд
Вот два таких сервиса:
1) LlamaParse
LlamaParse — умный парсер документов и файлов от LlamaIndex. Очень круто извлекает сложные таблицы. Можно интегрировать через API в приложения. Бесплатно можно обработать до 1 000 страниц в день.
LlamaParse поддерживает:
• Документы: PDF, DOC, DOCX, RTF, TXT, EPUB, XML, HTML, Pages, Keynote и др.
Например: Вы загружаете инструкцию по продукту, договор или научную статью → LlamaParse анализирует структуру и разбивает по логике → вы используете это в GPT-боте, который теперь может грамотно отвечать на вопросы по документу.
Больше проверенной информации и пользы в моемтелеграм канале.
Contextual - тоже самое, вы загружаете документ со сложными таблицами, рисунками и диаграммами, сервис так же преобразовывает это в текстовый файл с метаданными, понятный для любой LLM. Бесплатно можно обработать до 500 страниц.
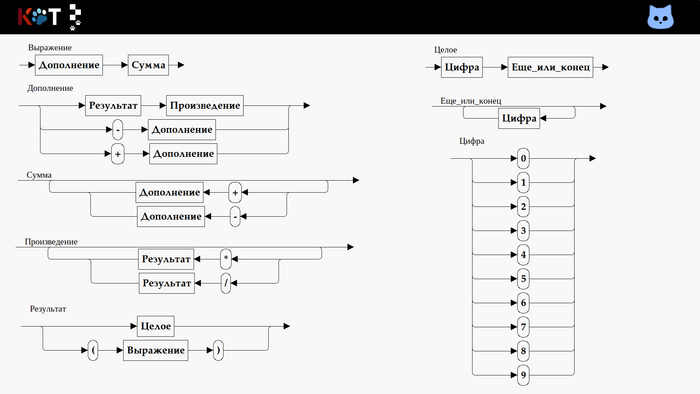
Разбор порядка символов цепочки отвечает на вопрос принадлежности к языку, также выявляет её смысловой состав. Состав может подан явно, например в виде древа, или не явно в виде порядка действий разборщика. Разборщик выступает остовом для перевода или содержательной обработки, в который вкрапляются смысловые действия. Действия могут определены как функции, операторы, процедуры.
Вот здесь (язык C) и здесь (псевдокод) вы можете посмотреть на рекурсивный калькулятор целых чисел, построенный по грамматике:
ДОПОЛНЕНИЕ -> РЕЗУЛЬТАТ ПРОИЗВЕДЕНИЕ | - ДОПОЛНЕНИЕ | + ДОПОЛНЕНИЕ ПРОИЗВЕДЕНИЕ -> ε | * РЕЗУЛЬТАТ ПРОИЗВЕДЕНИЕ | / РЕЗУЛЬТАТ ПРОИЗВЕДЕНИЕ
РЕЗУЛЬТАТ -> ЦЕЛОЕ | ( ВЫРАЖЕНИЕ )
Унарный минус и плюс учтён, а в качестве чисел использованы целые без знака:
ЦЕЛОЕ -> ЦИФРА ЕЩЕ_ИЛИ_КОНЕЦ
ЕЩЕ_ИЛИ_КОНЕЦ -> ЦИФРА ЕЩЁ_ИЛИ_КОНЕЦ | ε
ЦИФРА -> 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 0
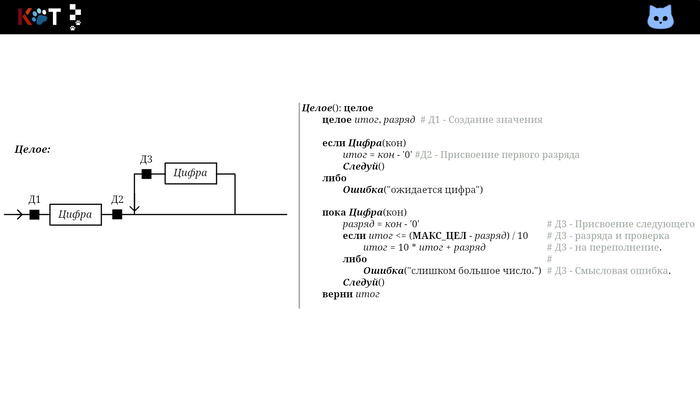
Ниже показаны процедура распознавания «Целое» с смысловыми действиями и её отдел рисунка порядка:
Смысловые действия для целого.
Обратите внимание на отдел рисунка, чёрными квадратами заданы моменты выполнения действий. Выделим основные смыслы: Д1 - говорит о том, что при обработке мы храним значения, операнды. Д2 и Д3 - говорит о том, что конечные символы могут выступать данными для формирования значения, а так же по сути являются операторами. В случае с «Целым», их можно рассматривать как унарные операторы добавления разряда.
Эти небольшие замечания помогут нам разобраться с включением действий в «Провидца».
Что же, на этом всё, подытожим списком рассмотренных тем:
P. S. Существуют и другие типы разборщиков по направлению разбора, но мы познакомились с достаточно мощными алгоритмами для продолжения изучения, что из себя представляет язык программирования.
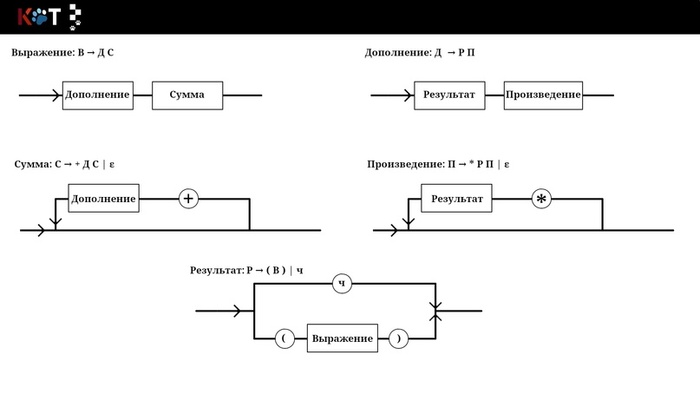
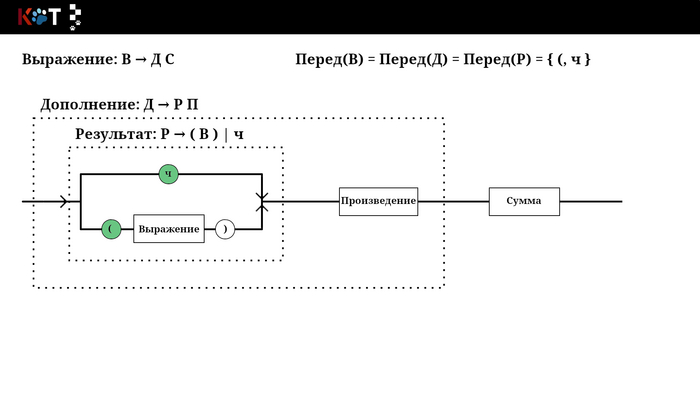
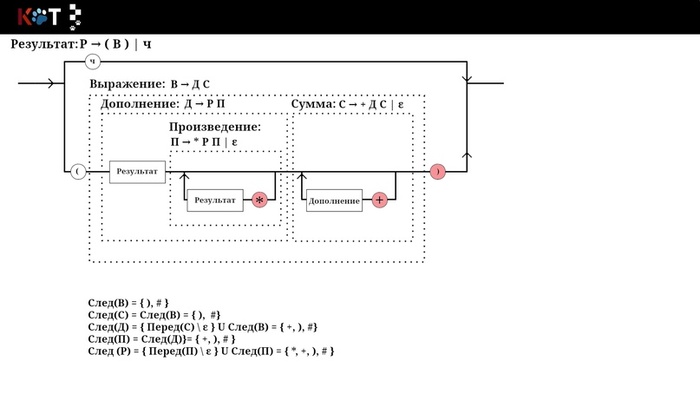
Здравствуйте! Для составления табеля возьмём немного упрощённую рассмотренную нами грамматику арифметических выражений:
Г: В → ДС С → +ДС | ε Д → РП П → *РП | ε Р → ч | (В)
Вот её рисунок порядка, который поможет нам прояснить некоторые моменты:
Рисунок порядка
Теперь придём к соглашению используемых определений:
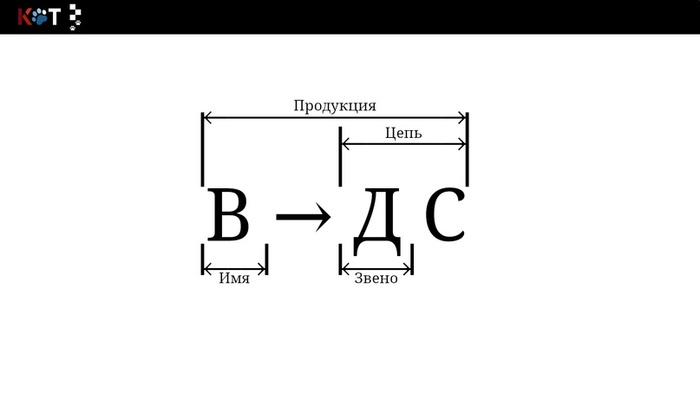
1. Правило вывода тождественно понятию продукция.
2. Пусть есть некоторая продукция П → α, тогда левая часть называется именем продукции, то есть П, а правая часть цепью, то есть α.
3. Цепь состоит из звеньев, коими являются конечные и неконечные символы.
Состав продукции.
Сперва нам следует научиться собирать множества Перед и След, также известные как множества First и Follow.
Что такое множество «Перед»?
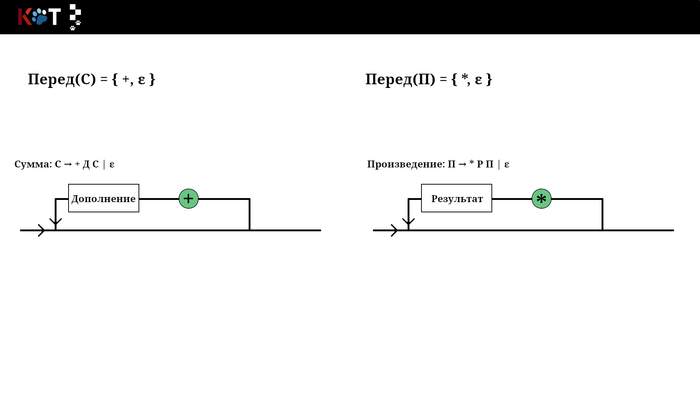
Перед - это множество конечных символов, которые могут встретиться первыми при разложении неконечного символа, также может включать в себя пустую цепочку (ε).
Что такое множество «След»?
След - это множество конечных символов, которые могут встретиться после разложения неконечного символа, также множество для стартового обязательно включает в себя символ ограничитель.
Как получить Перед(П)?
Символ ⊂ - означает «входит». Символ ∈ - означает «содержит». Символ ∉ - означает «не содержит». Символ \ - означает «исключает».
Имея продукцию П → α, Перед(П) вычисляется:
Если α - конечный символ , то Перед(П) ∈ α, Перед(α) = {α}.
Если цепь α это ε (пустая цепочка), то добавим ε к Перед(П).
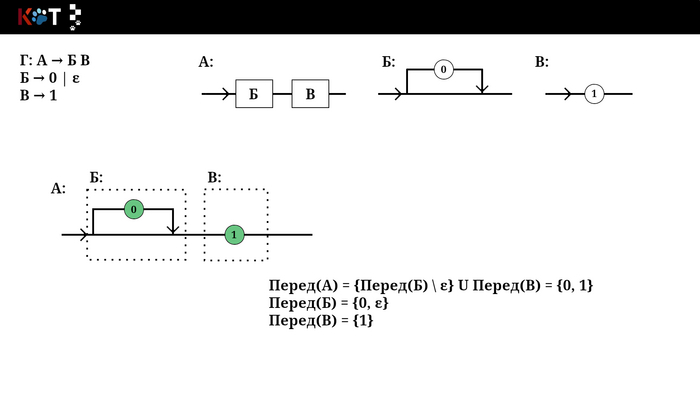
Пусть α состоит из последовательности символов П → Н₁Н₂ … Нₘ :
а) К Перед(П) идут в придачу все множества Перед(Н₁₊ₖ) \ ε, где k >= 0, пока Перед(Н₁₊ₖ) ∈ ε и 1 + k < m, завершая придачей Перед(Н₁₊ₖ) ∉ ε или Перед(Нₘ) (см. п 3.б).
б) Если Н₁₊ₖ последний, то есть 1 + k = m, тогда Перед(Нₘ) ⊂ Перед(П) включая ε, еслиПеред(Нₘ)∈ ε.
Звучит устрашающе, но на самом деле всё проще чем кажется, для этого воспользуемся рисунком порядка. Будем как бы разворачивать некоторые его отделы, зелёным цветом отметим конечные символы входящие в множества. Последний рисунок построен по другой грамматике, который лучше отображает суть п3.
1/3
Отображение переда, листай → …
Раз уже мы решили отобразить множества на рисунке, давайте посмотрим теперь на множество След, а потом опишем как его получить. Красным отмечены символы которые попадают в множества.
Отображение следа.
Как получить След(П)?
α и β - произвольные цепочки.
Поместим # в След(П), если П - стартовый символ, # - правый ограничитель потока.
Если есть продукция А → αПβ, то все элементы множества Перед(β) кроме ε попадают в множество След(П).
Если есть продукция А → αП или А → αПβ, гдеПеред(β) содержит ε, то След(А) входит вСлед(П).
Строим табель.
Большая часть пути пройдена, осталось научится создавать табель. Что он из себя представляет? А он представляет из себя пары конечного и неконечного символа и связанные с этими парами продукции. И так, для каждой продукции П → α выполним:
Для каждого конечного k из Перед(α) добавим П → α в ячейку Т[П,k].
Если Перед(α) ∈ ε, то для каждого k из След(П) добавляем П → α в Т[П,k]. Если Перед(α) ∈ ε и След(П) ∈ #, то добавляем П → α и в Т[П,#].
Например, есть продукция В → ДС: Перед(ДС) = Перед(Д) = { (, ч }, тогда добавим эту продукция в Т[В, (] и в Т[В, ч]. В конечном итоге мы получим следующий табель:
Сей табель используется в движке распознавания, который мы рассмотрим в следующей части. Также, табель можно построить для любой грамматики, что позволяет нам определить обладает ли грамматика ЛЛ(1)-свойствами, то есть если у нас оказывает более одной продукции на одну пару, значит что данная грамматика не приндлежит к классу ЛЛ(1)-грамматикам.
Вспомним о характере разбора цепочки. Стоит ли кость на своём месте при её постановке? Если постоянно да, то наш алгоритм предопределённый, в противном случае нам следует делать возвраты и пробовать подставить иную кость. Возможно узнать принадлежность цепочки заданной длинны, хотя бы из тех соображений, что можно построить все предложения (сентенции) грамматики совпадающие по длине с этой цепочкой.
Такой алгоритм работает по принципу полного перебора, для организации перебора используют стэк (англ. stack - рус. стог) - структуру данных по принципу «последним вошёл, первым ушёл». Полный перебор крайне неэффективен и на практике, как правило, не применяется.
Но! Есть широкий подкласс КС-грамматик, для которых накладывается ряд ограничений, что позволяет нам обходится без полного перебора и использовать эффективные алгоритмы распознавания, которые мы будем рассматривать в следующих уроках.
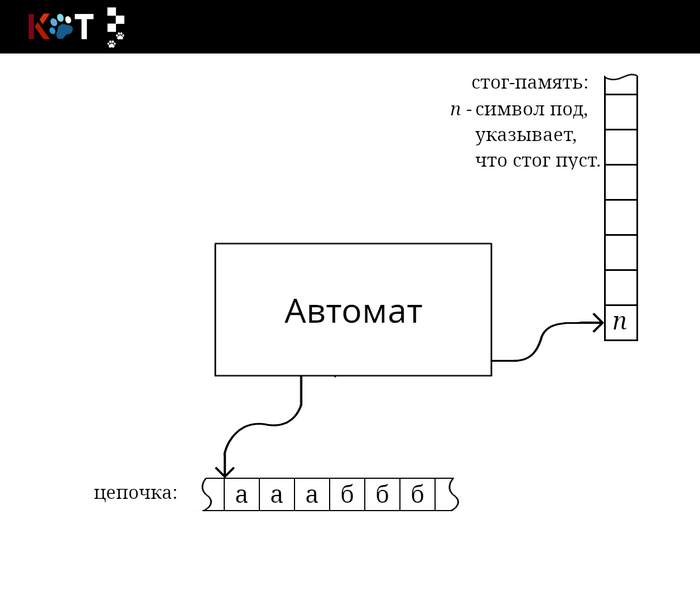
Если для автоматных грамматик в качестве распознавателя используется конечный автомат, то для КС-грамматик используется автомат с магазинной памятью.
Здесь нужно остановится на понятии «магазинная память», которое использовано крайне не удачно. По идее у вас должна быть выстроена ассоциация с магазином АК-47 (или другого оружия), где пуля заряженная последней, выстреливается первой. Но дело в том, что само слово магазин обозначает просто склад и он не обязательно должен выстроен по вышеуказанному принципу, лично я вовсе подумал о продуктовом. Поэтому используем термин стог-памятьили просто стог, так как если из стога вытащить что-то не сверху он превратится в кучу.
Перед тем как дать формальное описание, мы сперва построим простой стог-автомат. Отобразим общее представление об автомате:
Общее представление стог-автомата.
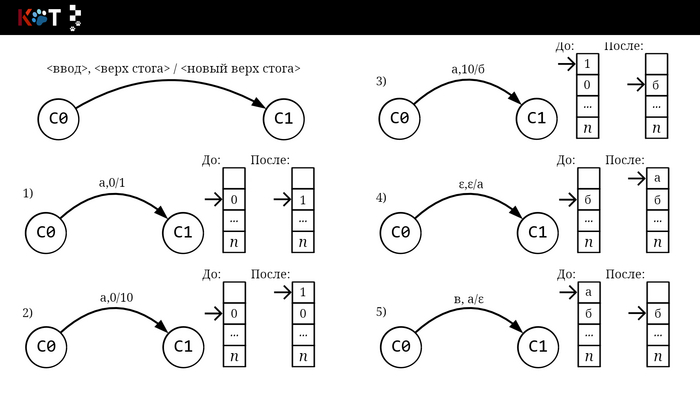
Мы видим, что автомат обращается за чтением цепочки и за чтением из стог-памяти, в стог вложен отдельный символом п обозначающий под или дно. Внутреннее устройство автомата можно представить в виде направленного графа как и конечный автомат (далее КА), только для перехода из состояния в новое состояние направленное ребро помечается по мимо принимающего символа, верхней цепочкой символовстога, которая будет заменена на новую цепочку символов в обратном порядке по очереди («первым вошёл, первым ушёл»), также входит в метку:
Переходы и стог.
Выше приведены примеры переходов с отображением операций над стогом. Первых три примера прозрачны, считали символ и поменяли цепочки. В 4 и 5 используется пустая цепочка ε и здесь нужно пояснение. Между любыми двумя символами всегда лежит пустая цепочка , что является причинной почему КА с ε-переходами недетерминирован. Проверьте, зайдите https://regex101.com/, введите любой текст и регуляр (), вы получите кучу совпадений. В стог-автомате ε используетсяв целях внутренней работы без считывания символа принимаемой цепочки, выталкивания и помещения символов из/в стог(-а), ведь пустота означает, что нечего брать или класть.
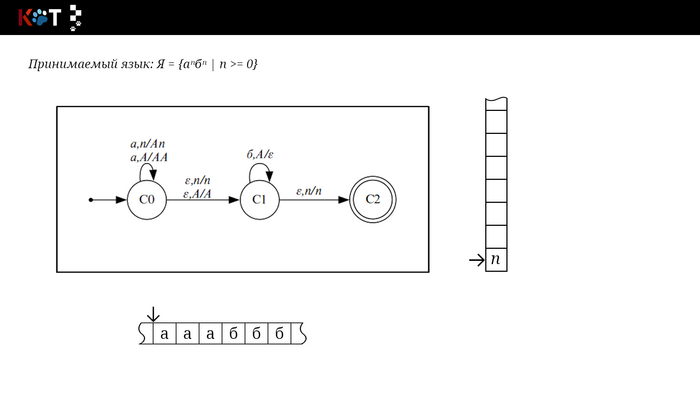
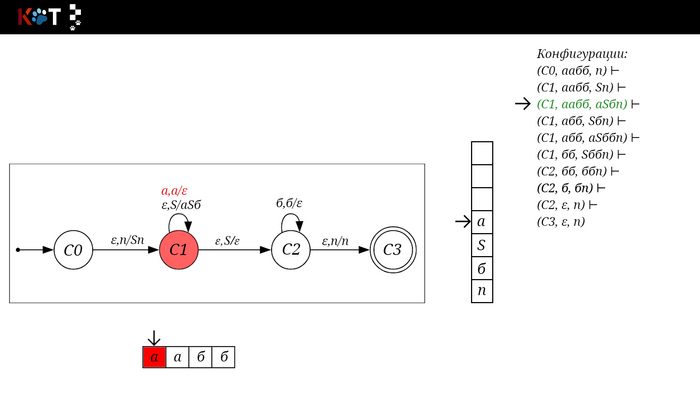
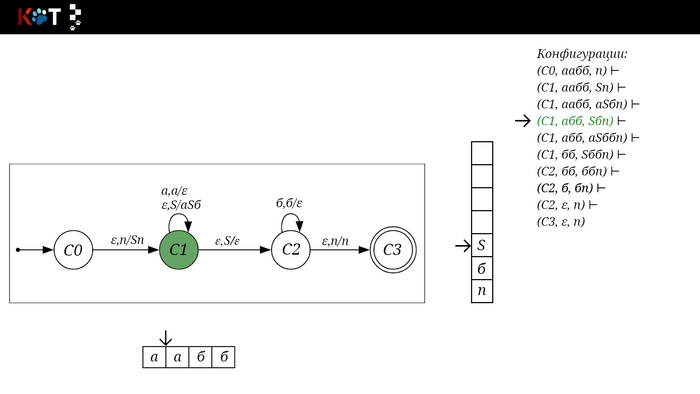
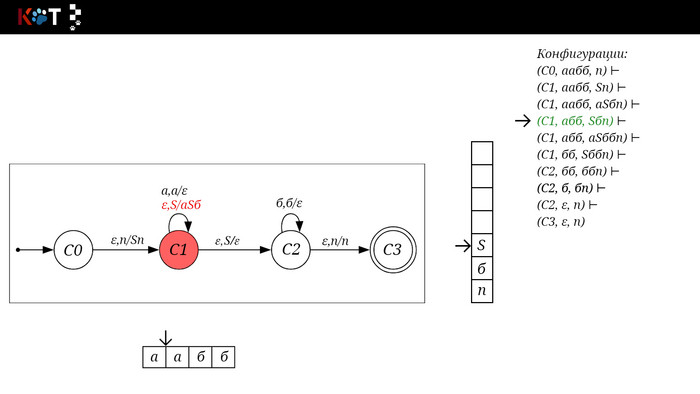
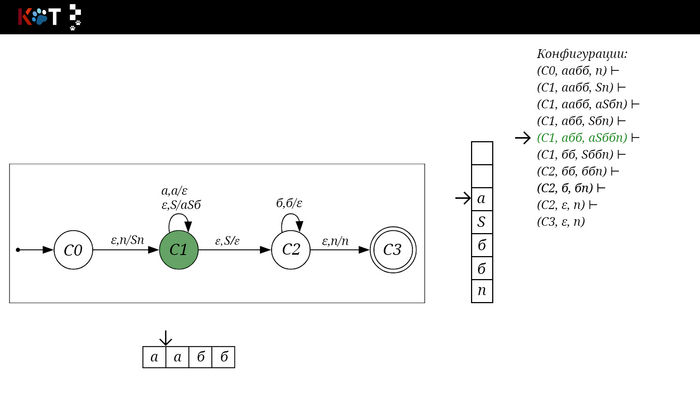
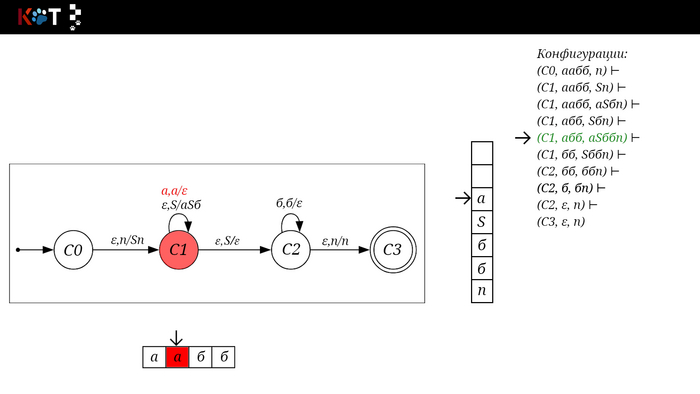
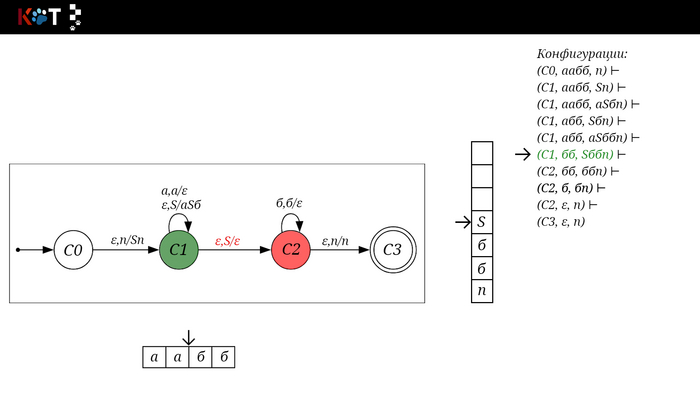
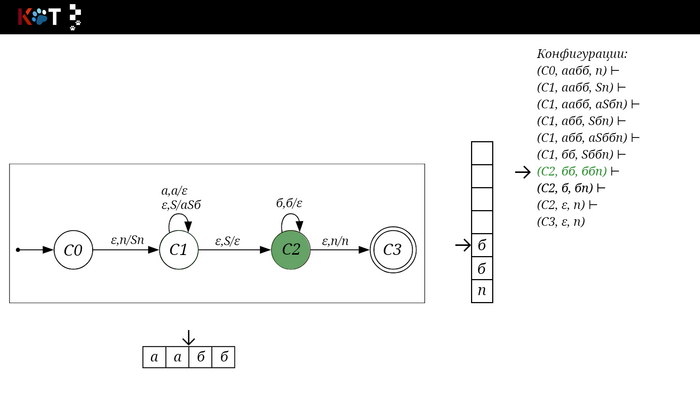
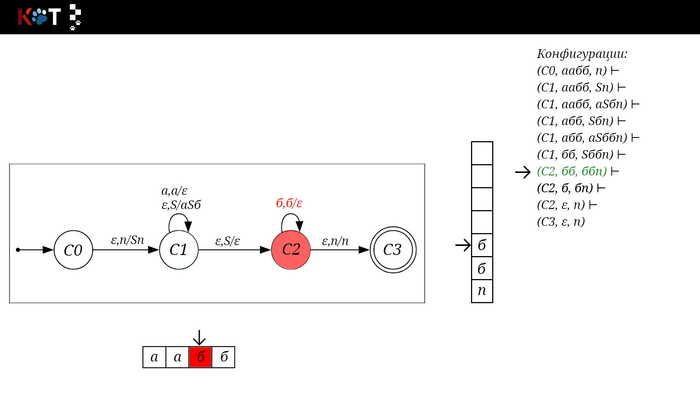
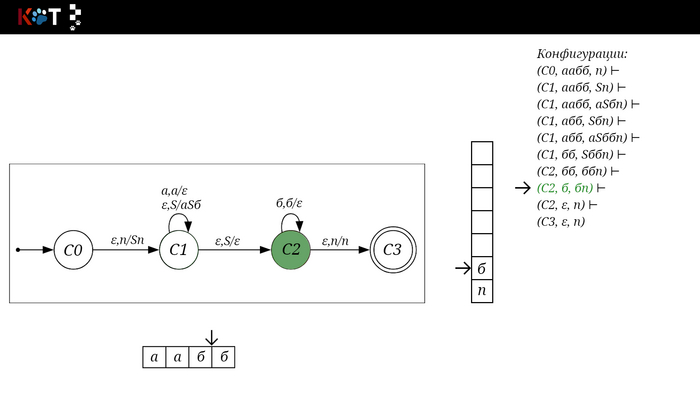
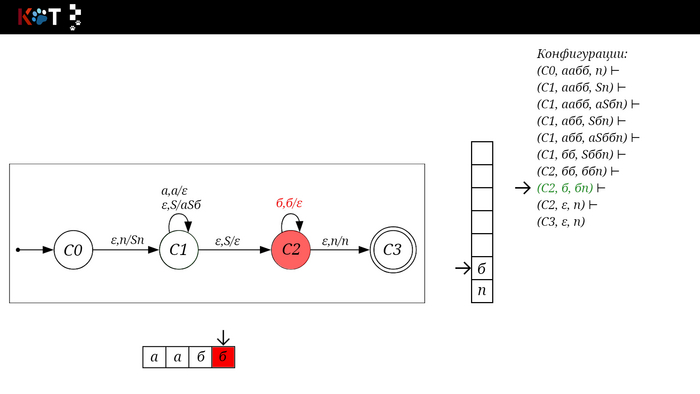
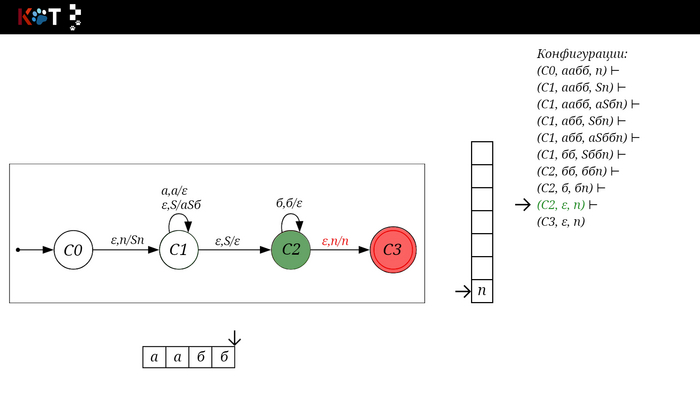
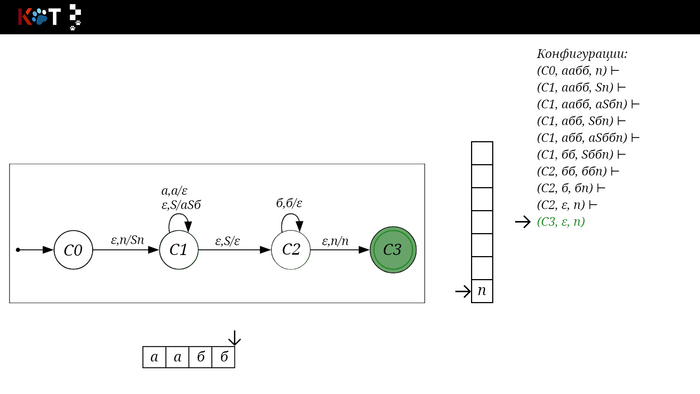
Изобразим граф стог-автомата принимающего язык: Я = {аⁿбⁿ | n >= 0}, где в цепочках символы а и б повторяются в равном количестве, примеры { аб, аабб, аааббб, …}.
Стог-автомат.
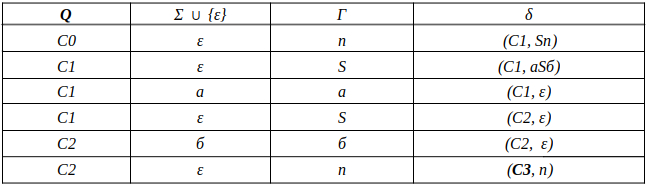
Так же как в КА конечное состояние автомата обозначаем узлом с двойным кружком, а начальное просто стрелкой. Для того, чтобы не изображать лишних рёбер правила переходов записывают друг над другом. Формально данный стог-автомат записывается так: М = ({С0, С1, С2},{а,б}, {А. п}, δ, С0, п, {C2})
Теперь мы готовы к общему формальному описанию, приступим: M = {Q, Σ, Γ, δ, q0, Ζ, F} F - множество конечных (принимающих) состояний автомата, наше {C2}. Ζ - символ конца стога, наш п - символ под. q0 - начальное состояние автомата, наше С0. δ - функция переходов автомата δ: ( Q × (Σ ∪ {ε}) × Γ) → (Q × Γ*). Γ - алфавит стога, наше {А, п}. Σ - входной алфавит, наше {а,б}. Q - множество состояний автомата, наше {С0, С1, С2}.
Остановимся на функции переходов δ: ( Q × (Σ ∪ {ε}) × Γ) → (Q × Γ*), она нам говорит о том, что переход зависит от текущего состояния Q, от принимаемого символа Σ с возможностью его оставить в покое ε и от верха стога Γ, в замен мы получаем новое состояние Q и новое содержимое стога Γ*. Γ* - звездочка обозначает, что наше множество разрастаемое, то есть стог заполняется символами.
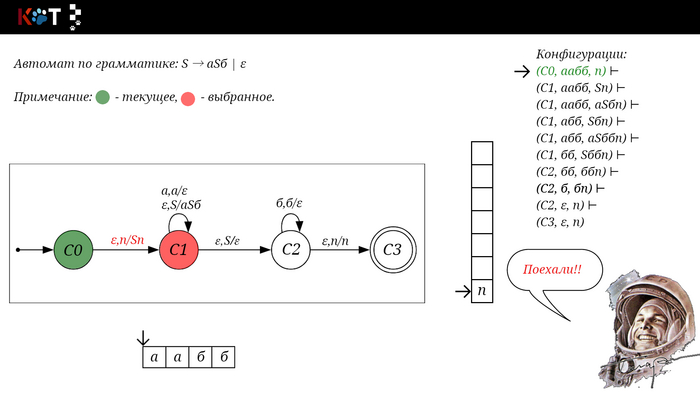
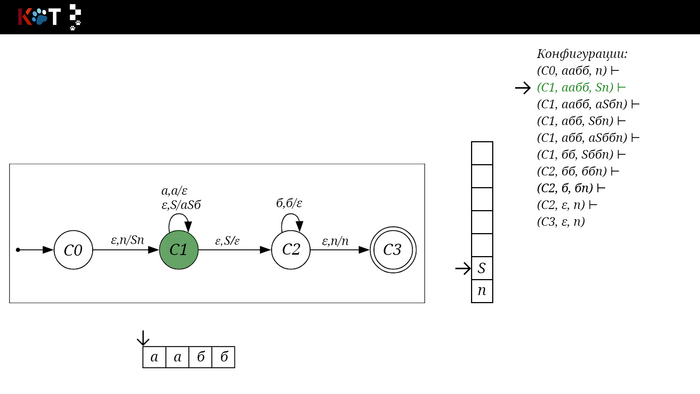
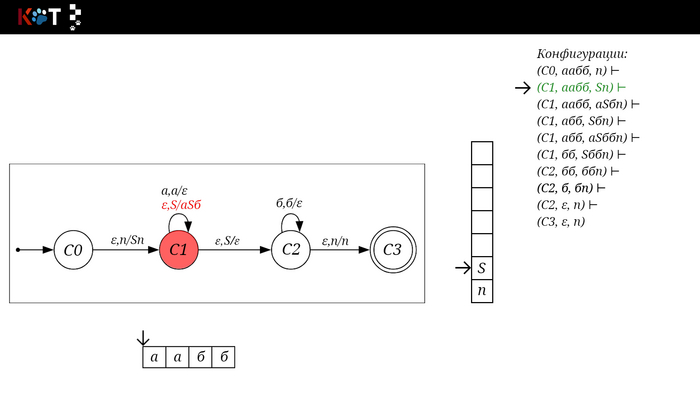
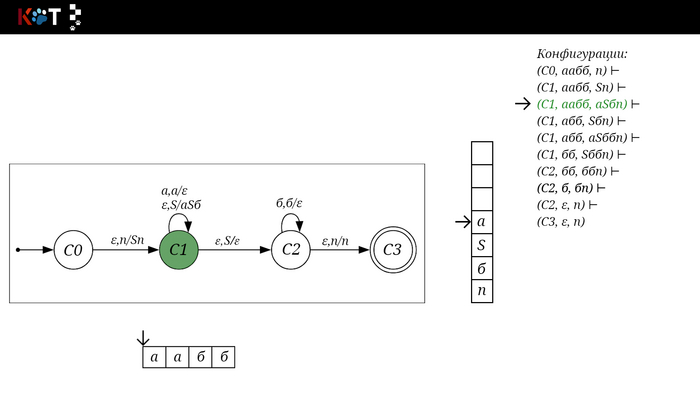
Для дальнейшего объяснения предоставляю работу автомата того же языка, но построенный по его грамматике: G: S → aSб | ε
1/16
Поехали!! Листай!
На рисунке отображено, ещё не рассмотренное нами понятие конфигурации. Конфигурация представляет из себя набор (q, ω, γ), где q - текущее состояние, ω - цепочка ещё не рассмотренных символов, γ - содержимое стога. Символом ⊢ обозначают такт автомата, то есть переход из одной конфигурации в другую. Обозначим символом ⊢* последовательность ноль и более тактов, теперь мы можем описать условие принятия цепочки или допускаемый язык автомата: L(M) = {ω ∈ Σ* и (q0, ω, Z) ⊢* (q, ε, Z), где q ∈ F} - то, есть когда наш стог опустошился до пода, завершился в конечном состоянии, а так же вся входная цепочка прочитана полностью. Лично у меня остался вопрос, почему везде записывают принятие по пустому стогу так: L(M) = {ω ∈ Σ* и (q0, ω, Z) ⊢* (q, ε, ε,) где q ∈ F} - ведь никто не извлекает Z?
Так же существует соглашение условия принятия: L(M) = {ω ∈ Σ* и (q0, ω, Z) ⊢* (q, ε, γ), где q ∈ F, γ ∈ Γ*} - то, есть когда наша цепочка полностью прочитана и мы достигли конечного состояния, а в стоге остались символы. Если мы уберём состояние С3, а С2 сделаем конечным, то становится понятно почему, такое соглашение есть.
Так же автомат можно описать таблицей, вот наш случай:
Таблица автомата.
В заключении следует сказать: Для произвольной КС-грамматики можно построить недетерминированный автомат с магазинной памятью (стог-памятью), принимающий язык, порождаемый этой грамматикой.
Возможно построить и детерминированный, как отмечалось раньше, для этого грамматикам накладываются некоторые ограничения, о которых будет рассказано в других уроках.
Постскриптум: Очень сильно надеюсь, что изложил тему доступным языком. Будьте мне здоровы, подписывайтесь.
Привет, друзья! Надеюсь, этот пост будет не единственным из серии «С ноги в IT». Может быть мой опыт будет полезен как начинающим кодерам, так и продавцам.
Начнем с болей продавцов:
Если вы занимаетесь продажами на маркетплейсе Wildberries, то наверняка сталкивались с одной из самых неприятных задач – регулярным обновлением цен и остатков. Эта рутина отнимает много времени и сил, особенно если у вас большой ассортимент. Я, как разработчик софта, рад поделиться решением, которое автоматизирует этот процесс и избавляет вас от лишних хлопот.
За такие 6 кнопок можно получить очень хорошие деньги
Проблема, с которой сталкиваются продавцы:
Поставщики часто предоставляют доступ к информации о ценах и остатках в личных кабинетах. Однако, для обновления данных на Wildberries приходится вручную переносить всю информацию. Это не только трудоемко, но и чревато ошибками.
Мы разработали софт, который парсит данные из личных кабинетов поставщиков и автоматически обновляет цены, остатки и скидки на Wildberries через API. Вот как это работает:
1. Парсинг данных: Наше приложение подключается к личному кабинету поставщика, используя предоставленные им учетные данные, и извлекает актуальную информацию о ценах и остатках.
2. Обработка данных: Данные проходят обработку и преобразуются в формат, совместимый с API Wildberries.
3. Автоматическое обновление: Обработанные данные отправляются на платформу Wildberries через их API, где обновляются цены, остатки и скидки.
Для начинающих разработчиков могу дать главный совет – кодить, постоянно, осваивать новые технологии, делать пет проекты. Найдите рычаги, чтобы мотивировать себя не только решать задачки на литкоде, но делать продукт. Ниже обязательный список технологий, минимум который нужно знать и который использовал в этом проекте:
- Python: Основной язык программирования для разработки скриптов парсинга и обработки данных.
-JS (TypeScript): Язык всех основных фреймворков для фронта, а так же широко используется в беке.
- BeautifulSoup и Selenium: Библиотеки для парсинга HTML-страниц и автоматизации взаимодействия с веб-интерфейсами.
- Docker: Для контейнеризации приложения и обеспечения его бесперебойной работы.
- База данных: Для хранения и управления данными.
Заключение
Наше решение значительно упрощает жизнь продавцам на Wildberries, автоматизируя процесс обновления цен и остатков. Это позволяет экономить время, избегать ошибок и сосредоточиться на развитии бизнеса.
Если у вас есть вопросы оставляйте комментарии или пишите в личку. Будем рады помочь и поделиться опытом!
В следующем посте поделюсь опытом создания пет проекта с использованием ИИ, который по итогу оказался никому не нужен, но опыт - бесценен!
Я не являюсь профессионалом в сфере парсинга данных, лишь учусь этому ремеслу в свободное время и посредством производства подобного рода инструкций, хотел бы оставлять для себя же подробные объяснения, что и как работает. Этот материал будет полезен, как мне, так и тем людям, которым также интерес парсинг.
Буду благодарен любой критике, ваша обратная связь поможет мне делать дальнейший материал лучше.
Парсинг – это автоматизированный сбор данных и их систематизация. Сбор данных осуществляется с помощью специальных программ, что называются парсерами. Парсеры нужны для ускорения рутинной работы. Парсить можно, как поисковые фразы, так и цены конкурентов. Всё что угодно можно парсить.
Первый урок будет посвящен парсингу простых заголовков объявлений с html-страницы агро-ресурса.
Подключение необходимых библиотек
Для этого, нам понадобится.
1. Язык программирования Python
2. Модули Python:
– requests (для упрощенной работы с HTTP-запросами)
– BeautifulSoup (анализирует HTML и XML, создает дерево разбора для проанализированных страниц, что далее позволяет извлекать данные из HTML)
– пакет xml (модуль обработки xml)
Переходим к установке библиотек.
Для удобного написания кода на Python, буду использовать IDE ( это программное приложение, которое помогает программистам эффективно разрабатывать программный код. Оно повышает производительность разработчиков, объединяя такие возможности, как редактирование, создание, тестирование и упаковка программного обеспечения в простом для использования приложении.) под названием PyCharm.
1. Открываю PyCharm и перехожу во вкладку “Terminal”. Устанавливаем библиотеку requests командой “pip install requests”
2. Устанавливаем библиотеку BeautifulSoup командой “pip install BeautifulSoup”
3. Устанавливаем пакет xml
Отлично. Все необходимые библиотеки установлены, можем начинать.
Определяемся с целью парсинга
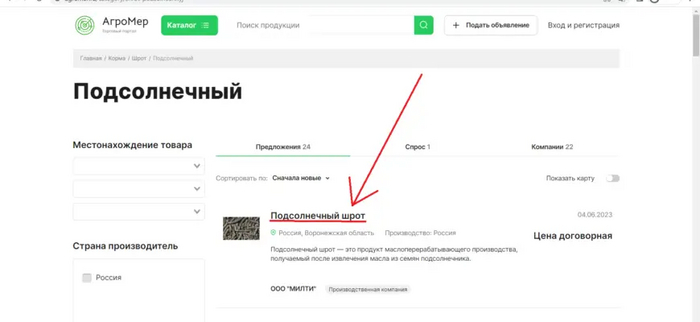
Моей сегодняшней целью является одно из названий объявлений на сайте АгроМер.
Пишем код
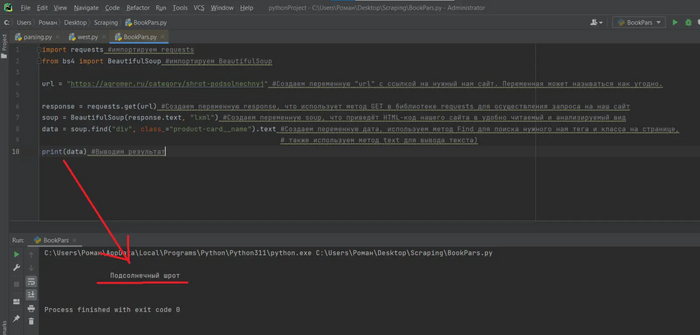
Далее прилагаю скриншот кода. Постарался к каждой строке кода дать соответствующий комментарий, чтобы было понятно, что делает каждая строка.
Дополнительно разбираемся с кодом
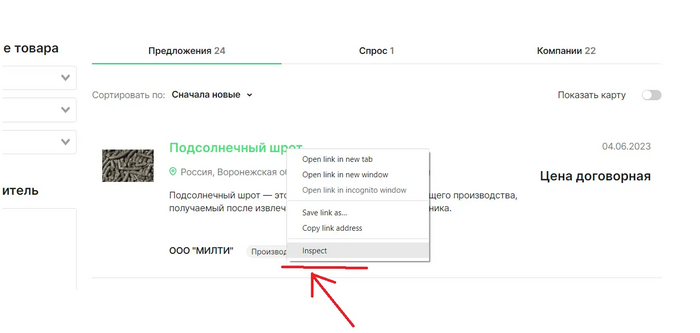
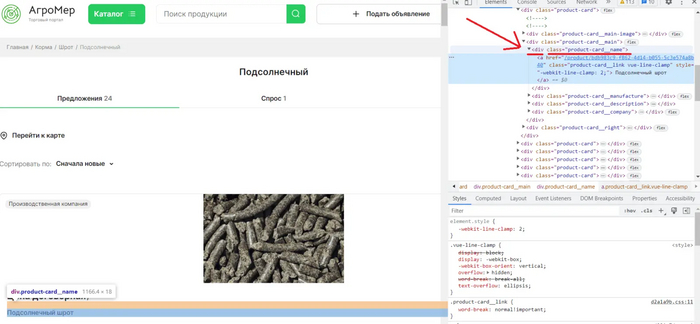
Как видим, получилось вывести заголовок “Подсолнечный шрот”. Опять же, для понимания, прошу обратить внимание на строку № 8.Нужно понять, почему именно мы ведем обращение по тегу ""div" и классу “product-card__name”.Открывем код страницы, наведя курсор мыши на заголовок “Подсолнечный шрот” и нажав “Inspect”, на русском это будет команда браузера “просмотреть код”
Как видим, искомому нами заголовку “Подсолнечный шрот” соответствует именно тег “div” и класс “product-card__name”, и именно метод “find” (строка кода №8) позволяет найти на странице необходимые нам элементы HTML-страницы.
Надеюсь, разбор получился понятным. Думаю, эта инструкция поможет мне вспомнить основы при необходимости и вам, если вам также интересен парсинг.Далее, буду также изучать парсинг подробнее и писать новые инструкции. Уверен, моя первая инструкция возможно полна недочетов, но со временем буду стараться для своих читателей делать их лучше и понятнее.
Мой канал в телеграмм
Если мануал показался вам интересным, то буду благодарен за подписку на мой
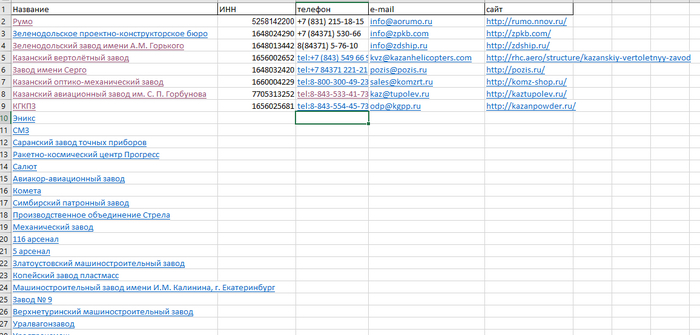
Добрый день, есть файл Excel куда я выгрузил названия предприятий с гиперссылками, нужно с него по порядку выгрузить отдельные данные (на фото).
Как это сделать? Обычный Power Quary не дает - выдает ошибку. Уже смирился делать это ручками, но может есть какой-то отдельный способ. В гугле решения не совсем подходящие (может я не туда гуглю) В общем прошу помочь, если кто-то разбирается. Поможете сэкономить кучу времени спасибо