Закреплено

5 130 постов
•
11 517 подписчиков
0 просмотренных постов скрыто


Функции потерь и алгоритмы оптимизации в линейной регрессии: обзор основных подходов1
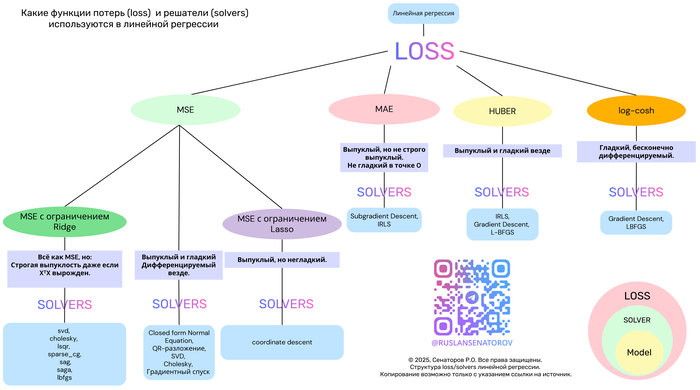
Линейная регрессия — один из самых фундаментальных и широко применяемых методов в машинном обучении. Несмотря на простоту, её эффективность сильно зависит от двух ключевых компонентов:
Функции потерь (loss function) — что именно мы минимизируем?
Метода оптимизации (solver) — как мы ищем решение?
В этой статье мы разберём популярные функции потерь — MSE, MAE, Huber и Log-Cosh — их свойства, плюсы и минусы. А также покажем, как выбор функции потерь определяет выбор алгоритма оптимизации.
Почему функция потерь так важна?
Функция потерь измеряет, насколько предсказания модели отличаются от реальных значений. От её формы зависят:
Чувствительность к выбросам
Наличие замкнутого решения
Выпуклость задачи
Скорость и стабильность обучения
Давайте сравним четыре ключевые функции потерь в контексте линейной регрессии.
1. MSE (Mean Squared Error) — стандарт по умолчанию
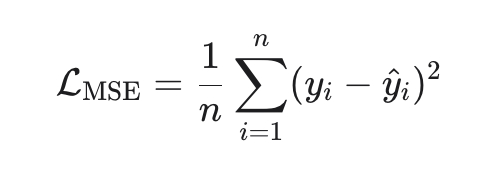
Эквивалентна максимуму правдоподобия при нормальном шуме.
Замкнутое решение (метод наименьших квадратов):
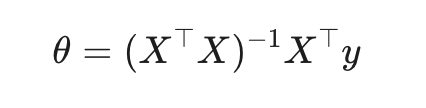
Плюсы:
Выпуклая, гладкая, дифференцируемая → легко оптимизировать
Минусы:
Чувствительна к выбросам (ошибки возводятся в квадрат).
Solver:
Normal Equation (аналитическое решение)
SGD, SAG, LBFGS (в scikit-learn: solver='auto', 'svd', 'cholesky' и др.)
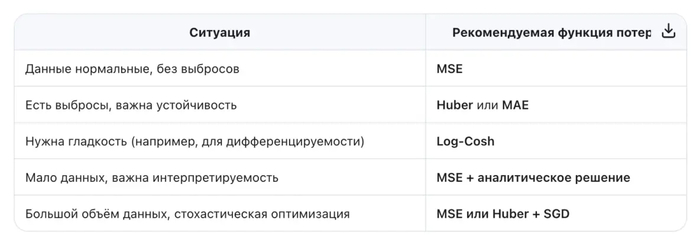
Когда использовать: когда данные «чистые», ошибки гауссовские, и важна интерпретируемость.
2. MAE (Mean Absolute Error) — робастная альтернатива
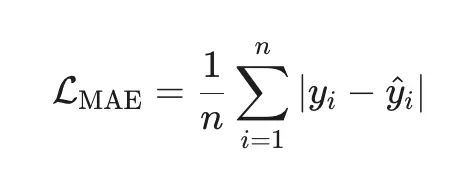
Плюсы:
Робастна к выбросам (ошибки в первой степени).
Минимизирует медиану ошибок (а не среднее).
Минусы:
Недифференцируема в нуле → нет аналитического решения.
Требует итеративных методов.
Solver:
Linear Programming (например, через симплекс-метод)
Subgradient Descent (в scikit-learn: QuantileRegressor с quantile=0.5)
Когда использовать: когда в данных есть аномалии или тяжёлые хвосты (например, цены, доходы).
3. Huber Loss — лучшее из двух миров

Плюсы:
Гладкая и дифференцируемая.
Робастна к выбросам (линейная штраф за большие ошибки).
Гибкость через параметр δδ.
Минусы:
Нужно настраивать δδ (часто выбирают как процентиль ошибок).
Нет замкнутого решения.
Solver:
Gradient Descent, LBFGS, Newton-CG(в scikit-learn: HuberRegressor с fit_intercept=True)
Когда использовать: когда вы подозреваете наличие выбросов, но хотите сохранить гладкость оптимизации.
4. Log-Cosh Loss — гладкая робастность
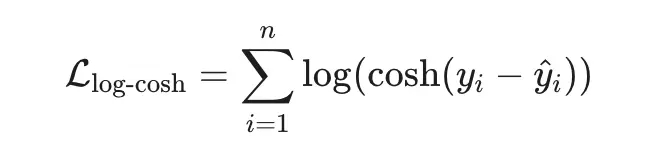
Плюсы:
Гладкая везде (бесконечно дифференцируема).
Ведёт себя как MSE при малых ошибках и как MAE при больших.
Устойчива к выбросам, но без «изломов».
Минусы:
Вычислительно дороже (логарифм и гиперболический косинус).
Не так распространена в классических библиотеках.
Solver:
Gradient-based методы: SGD, Adam, LBFGS(в TensorFlow/PyTorch легко реализуется; в scikit-learn — через кастомный регрессор)
Когда использовать:
когда вы ищете баланс между робастностью MSE и гладкостью MAE.
Вы хотите избежать чувствительности MSE к выбросам, но сохранить дифференцируемость.
Вы строите гибридную модель, где loss должен быть всюду гладким (например, для вторых производных).

Правило:
Если loss квадратичен → можно решить напрямую.
Если loss неквадратичен → нужен итеративный численный метод.
И помните: нет универсально «лучшей» функции потерь — только та, что лучше всего подходит вашим данным и задаче.
Показать полностью
7

Галлюцинации вместо фактов. Исследователей призвали не верить нейросетям при работе с архивами
Чат-боты готовы выдумать любые данные, лишь бы не оставлять запрос без ответа.

Автоматические системы, создающие текст с помощью искусственного интеллекта, всё чаще используются в сфере исторических исследований, включая работу с архивами. Однако Международный комитет Красного Креста (МККК) предупредил об опасности использования подобных инструментов при обращении к архивным источникам. В своём заявлении организация подчёркивает, что такие генераторы, как ChatGPT, Gemini, Copilot и Bard, не обладают механизмами проверки фактов и склонны к выдумке.
Особую обеспокоенность вызывает то, что подобные системы всегда создают ответ, даже если исторических данных по запросу нет. Их алгоритмы заточены на генерацию правдоподобного текста, а не на проверку достоверности. В результате появляются ссылки на якобы архивные документы с вымышленными номерами, названиями и платформами, которые в реальности никогда не существовали. Такие «галлюцинации» способны ввести в заблуждение даже опытных исследователей.
МККК обращает внимание, что если запрошенного архива не удаётся найти, это вовсе не означает сокрытия информации. Причины могут быть разными: от неполной или некорректной ссылки до хранения нужного документа в других учреждениях. Также может оказаться, что такой документ никогда не существовал, и его описание — продукт искусственного интеллекта, не подкреплённый никакими реальными данными.
Для получения достоверной информации о фондах МККК специалисты рекомендуют использовать официальный онлайн-каталог. Через него можно изучить существующие описи и обратиться напрямую к архивистам. Также надёжным источником считаются академические публикации, в которых точно указаны архивные ссылки и контекст, позволяющий проследить происхождение данных.
Организация подчёркивает свою приверженность принципам открытости и готова оказывать помощь в поиске проверенной информации. Однако использование генеративных систем без дополнительных проверок вредит точности исследований и может привести к искажению исторических данных.
По материалам: https://www.securitylab.ru/new...
Показать полностью

ИИстерия
Здарова всем. Это будет мой первый пост, но далеко не последний. Думал написать книгу по всему тому не совершенству, на которое натыкаюсь, но ждать нет сил. (если что, я не писатель, просто есть такая цель донести до людей свою позицию) Чувствую, что опоздаю.
И так, речь пойдёт про искусственный интеллект.
Я работаю в большой конторе довольно продолжительное время, более 10 лет и конечно буду приводить примеры из своей жизни. Тригером к написанию поста послужила статья в одном известном журнале о повсеместно и тотальном использовании ИИ в ближайшем будущем.
Отцифруй меня полностью.
Сидим мы с коллегами значит, на работе, работу работаем и тут всю контору собирает директор по планам на ближайшее будущее. Толкает речь про прогресс, индустриализацию 4.0 и общемировые тренды. Главным тезисом стала всеобщая цифровизация (не путать с мобилизацией). Объявлено, что мы все будем использовать в работе ИИ, упростим сложные отчёты и будем сидеть на лаврах в куче премий, а кто не хочет идти за руку с прогрессом, пойдёт на улицу подметать листья.
Окей, первый вопрос : Вы же в курсе, что ИИ в интернете, а у нас закрытая сетка с чувствительными данными?
Ответ: мне пофигу как, но вы это сделаете. Я хочу идти в ногу со временем.
Окей, второй вопрос: что вы хотите получить по итогу?
Ответ: как что? Автоматизация всей работы в компании и массовые сокращения работников. Представляете, сколько я экономлю денег?
Все сразу смекнули, что дело дрянь. Шеф наслушался бредовых мифов где-то в мажор сауне и начал фантазировать.
Деваться некуда, задача съесть рыбку и остаться натуралом. По итогу носим к руководству красивые графики и диаграммы, рисуем презентации и говорим, что это ИИ.
При вопросе, дайте мне тоже поговорить с богом машиной, даём ссылку на gpt. После некоторых манипуляций приходят отрицательные отзывы и комп закрывается.
Никто не хочет терять работу, а самые умные понимают, что любой машиной должен управлять человек. Пусть вы заскриптуете рутину, но управлять процессом машина не сможет никогда. Человек должен задать кучу определённых задач и параметров, чтобы получить искомый ответ, просто щёлкать пальцем не получится. Людей не нужно сокращать, их нужно обучить.
Все сказки о мире терминаторов ведут в никуда.
Экономии не будет, будет модернизация производственных процессов с заделом на окупаемость в будущем.
Надеюсь меня прочитают такие руководители и сделают выводы.
До скорых встреч!
Показать полностью
Как я начал зарабатывать на Hailuo AI через Авито и теперь стабильно получаю 90 000 в месяц
Я вечно ищу способы заработать в интернете без вложений, без курсов и без риска остаться с «пустыми руками». В какой-то момент наткнулся на генератор Hailuo AI — это была просто ещё одна нейросеть в списке технологий, которые «вот-вот изменят мир», но реальных историй, как на этом можно заработать — было мало.
Я решил проверить это сам.
Как всё началось
Пару месяцев назад я наткнулся на официальный сайт hailuo и познакомился с возможностями этой хайлу нейросети — она умеет превращать обычные фотографии в живые видео на основе текста или настроек пользователя. Из любопытства попробовал создать несколько роликов для друзей — вышло интереснее, чем я ожидал , но у меня быстро закончились бесплатные генерации
официальный сайт hailuo ai
Потом я попробовал ещё бесплатные генерации в приложении на ios
ios hailuo ai генератор
Дальше пришлось искать аналоги в России, на тот момент наткнулся на сайт официального представителя hailuo в России и до сих пор пользуюсь, уже порядка 1000 видео создал там за 3 месяца

Представитель hailuo ai с официальным api
На следующем шаге я задал себе простой вопрос: если эта нейросеть может оживлять изображения и делать видео на основе текста, почему бы не предложить эту услугу людям за деньги и перепродавать где-либо?
Я решил протестировать это на Авито, и просто сделал объявление с услугой оживления фоток, я не придумывал никаких маркетинговых слов, просто написал как есть...
Моё первое объявление
Я создал объявление на Авито:
«Оживление фото. Видеопоздравление. Реставрация фото — от 91₽».

Профиль с авито
Я не ожидал всплеска, думал, может пара человек отреагирует, попробует. Но уже в первые дни начали люди и просили создавать им видео из их фоток.
Первый заказ был прост: оживить старую фотографию дедушки. Я загрузил фото на hailuo ai , настроил параметры под пожелания клиента и получил результат через пару минут. Клиент был доволен — и заплатил 100₽.
Это был только старт.
Первый месяц: 5000₽
За первые четыре недели я получил около 50 заказов и заработал примерно 5000₽. Многие приходили по сарафанному радио — люди делились моим объявлением с друзьями и знакомыми.
Вот что я заметил на этом этапе:
Люди хотели оживить семейные фото и детские снимки.
Многие спрашивали, можно ли сделать анимацию с движением камеры.
Некоторые просили музыку под видео или добавить краткий текст.
Я понял, что база интереса есть — и решил развивать направление.

Кто-то просил оживить например старые военные фотографии, таких людей было тоже много...
Второй месяц: 30 000₽
Когда у меня накопилось достаточно примеров работ, я обновил объявление и добавил в описание фразу о том, что используюhailuo ai minimax — продвинутую версию модели, которая делает результат более плавным, естественным и реалистичным.
Это сработало. Заказы пошли быстрее. Некоторые клиенты стали готовы платить не 100₽, а 300, 500 и даже 800₽ за персональные видео-истории из фото и коротких текстов.
Так, во второй месяц я уже заработал около 30 000₽, не меняя общего подхода, но улучшая качество работ.
Сейчас: ~90 000₽ в месяц
Сейчас я делаю примерно 90 000₽ в месяц на этом деле. Причём модель заработка проста:
Клиент присылает фото и пожелания.
Я создаю видео через Hailuo AI генератор (плюс модель обновилась до версии 2.3)
Полученный ролик отправляю заказчику.
Клиент оплачивает работу.
Процесс стал быстрее — от 10 до 30 минут на заказ, в зависимости от сложности.
Почему это работает
Я выделил для себя несколько причин, почему эта идея оказалась успешной:
Услуга необычная и эмоциональная — люди любят видеть живые воспоминания.
Многие не умеют сами работать с ИИ-инструментами, но готовы платить, чтобы это сделал кто-то другой.
Инструмент, который я использую — hailuo ai нейросеть — действительно быстро генерирует качественные видеоролики.
Я не ограничиваюсь только оживлением — есть опции анимации фона, добавления текста, музыки и стилизации.
Что я советую тем, кто тоже хочет попробовать
Если у тебя есть аккаунт на Авито и ты хочешь попробовать заработок через онлайн-услуги, вот что поможет:
Покажи примеры работ — это вызывает доверие и помогает людям понять, за что они платят.
Используй продвинутые модели вроде hailuo ai minimax — они дают более живой результат.
Следи за качеством — мелкие детали делают видео лучше воспринимаемым.
Заключение
Когда я начинал, я думал, что это будет просто эксперимент. Но идея действительно сработала — и теперь я не только получил стабильный доход, но и нашёл интересное дело, которое делает людей счастливыми, оживляя их воспоминания.
Инструмент, который я использовал в этой истории, ты можешь посмотреть на https://hailuo-ai.online/ — это стало тем самым ключом, который позволил мне начать этот путь быстро, т.к. оплата вся обычным РФ картами, в данный момент покупаю пакеты кредитов большие со скидками до 40%.
Если у тебя есть вопросы или ты тоже пробовал что-то подобное — обязательно поделись в комментариях. Мне интересно узнать, как у других складывается опыт с такими технологиями.
Есть также ещё много других нейросетей, по типу runway, вео3, sora2 и так далее, но они стоят дороже и с ними чуть сложнее работать. Всем спасибо за внимание.
Показать полностью
5
1

Signalist: Представлена GPT-5.2





OpenAI официально представила новую флагманскую линейку — GPT-5.2. Модели созданы для профессиональной работы и сложных задач, но главный тезис релиза звучит как начало новой эры: ИИ впервые превзошел экспертов-людей в реальных рабочих кейсах. В бенчмарке, охватывающем 44 профессии (от финансов до медицины), GPT-5.2 Thinking победила или сыграла вничью с профессионалами в 70.9% случаев. При этом работает она в 11 раз быстрее и стоит меньше 1% от затрат на живого специалиста.
Ключевые апгрейды:
— Кодинг: Модель стала SOTA-решением для создания ИИ-агентов и получила серьезный буст во фронтенде и работе с 3D.
— Наука и математика: Взяла 100% в AIME 2025 и почти 93% в GPQA Diamond, а в сложнейшем тесте FrontierMath вышла на уровень экспертов-математиков.
— Абстрактное мышление: Версия Pro стала первой моделью, пробившей порог 90% в тесте ARC-AGI-1.
— Длинный контекст: Почти 100% точность поиска на контексте до 256 000 токенов.
— Агенты: Новый уровень работы с инструментами. Тестировщики говорят о создании «мега-агентов», управляющих 20+ инструментами одновременно.
Галлюцинирует модель на 30% реже, а инструкции понимает значительно лучше.
Линейка и цены:
— GPT-5.2 Instant: быстрая версия на каждый день.
— GPT-5.2 Thinking: основная модель для анализа и кода.
— GPT-5.2 Pro: самая мощная версия для критических задач. API, конечно, подорожал ($1.75 за 1М входных и $14 за 1М выходных токенов), но OpenAI уверяет, что за счет эффективности итоговая стоимость решения задач может даже снизиться.
Модели уже начали раскатывать для платных подписчиков и в API.
P.S. Ненавязчиво прошу поддержать меня и подписаться на мой телеграмм. Там посты выходят раньше (и чаще)
📡 Never lose your signal.
Показать полностью
5

Стартап обещает «вечную жизнь» с помощью цифровых двойников — извините, но это уже нездоровая херня1
Канадский актер Калум Уорти запустил стартап, который обещает «вечную жизнь».
Пока ты живой, скармливаешь нейросети видосики со своей мимикой, голосом и воспоминаниями. Ты откидываешь лапки, и у семьи остается твой цифровой двойник. Он отправляет им шутейки на Новый год или собирает внуков в школу. Через смартфон. Родня счастлива. Твой «заменитель» помог пережить утрату на самом пике горя, и теперь он всегда под рукой. А тебе в принципе пофигу, ты уже мертвый.
Правда, твое бессмертие в мире живых длится до тех пор, пока жена не забыла продлить платную подписку. То есть память о папочке станет платной услугой: живые перестали платить — мертвых «отключают». Звучит цинично, но таков бизнес.
Больше всего меня впечатлил их рекламный ролик.
41 млн просмотров.
Беременная женщина показывает свой живот аватару своей покойной матери. Потом они общаются, когда мальчик подрастет. Через 10 лет бабуля все еще на созвоне с Чарли. И вот парню уже 30, и он хвастается ей, что у него скоро будет ребенок. Цикл замкнулся. Я думаю, дальше Чарли присоединится к бабушке, и активируется тариф «Семейный» с хорошей скидкой для новых членов семьи.
Это так противоестественно и отвратительно, что я даже не хочу думать о том, что в моем мире, где и так хватает безумных людей, эта технология приживется.
Да, потерять человека — это ужасно.
Умереть и лишиться любимых еще ужаснее.
Но обманывать смерть иллюзией, сгенерированной ИИ, — это самый дебильный способ истязать себя скорбью годами и окончательно поехать кукухой, разговаривая с чат-ботом, который просто удачно подбирает слова, чтобы притвориться твоей мамой.
В голове не укладывается, как можно заменить дорогих тебе людей подделкой (нейросетью).
Спасибо, что дочитали
Если понравился пост, поставь сердечко и напишите в комментариях.
Из других статей рекомендую пересказ интервью Джеффри Хинтона (крестный отец нейросетей), где он рассуждает о рисках ИИ. А тут я разобрал как крупные бренды заменили тысячи людей на ИИ, а потом дали заднюю.
Присоединяйтесь к 15 000+ подписчиков в Бегин, где я делюсь опытом работы с нейросетями и выкладываю полезные подборки.
Показать полностью

Как писать промты для GPT-5.2 в ChatGPT
OpenAI вчера выкатили GPT-5.2, чтобы не отставать от Gemini, и одновременно опубликовали официальный гайд по промтам. Я его вычитал и разобрал, чтобы вам не пришлось.
Ниже — самое главное: что реально изменилось в работе модели и что это означает на практике, когда вы пишете промты.
1. Задавайте конкретный формат ответа.
По умолчанию GPT-5.2 заточена на сухие, лаконичные ответы «по делу». Если не задать конкретный формат, она может ответить коротко и без подробностей, и не решить ваш вопрос.
Поэтому формат нужно задавать прямо в промте. На практике это выглядит так:
— «пост для соцсетей, 4–5 коротких абзацев»;
— «список из 10 пунктов, каждый не больше двух предложений»;
— «короткая статья: лид + 3 смысловых блока».
2. Ставьте жёсткие рамки.
Новая модель ведёт себя как перфекционист. Она старается «сделать лучше», и из-за этого делает лишнее: добавляет функции в код, новые разделы в статью или дополнительные строки в отчёт.
Поэтому в промте нужно строго прописывать ограничения и прямо запрещать самодеятельность: «строго следуй инструкции», «не добавляй новых идей и выводов», «не улучшай результат и не расширяй требования».
3. Работа с большим контекстом.
При работе с большим контекстом (книги, PDF-инструкции, длинные чаты) модель может терять нить. Она начинает опираться на второстепенные детали или просто забывает, что именно вы от неё хотите.
Поэтому сначала фиксируйте фокус (что важно), и только потом просите ответ. В промтах просите кратко пересказать текст или ваши требования, составить план и выделить главное и только после этого переходите к основной задаче.
4. Борьба с галлюцинациями.
GPT-5.2 стал осторожнее и меньше глючит, но если в промте не указано, что делать при нехватке данных, модель всё равно начнёт додумывать.
На практике добавляйте в промты следующее: «Если ты не уверена или вопрос непонятен — не выдумывай. Лучше задай мне 3 уточняющих вопроса».
5. Используйте шаблоны ответов для работы с данными.
GPT-5.2 заточена под работу с данными и лучше понимает не абстрактные просьбы, а конкретные. Если попросить её просто «выписать данные», она сама решит, что считать важным и в каком виде это отдавать.
Правильный подход — давать шаблон ответа в промте и требовать его заполнить: «Вот [ШАБЛОН] ответа. Заполняй его строго по этому образцу, ничего не добавляй и не меняй. Если данных для поля нет — оставь пустым или поставь null».
От себя добавлю: по первым впечатлениям GPT-5.2 похож на 4o и GPT-5 — более послушный, конкретный и, если нужно, креативный. А по сравнению с 5.1 — это вообще космос, разница ощущается сразу.
Но первые впечатления могут быть обманчивыми. Пока работаем и наблюдаем.
Показать полностью

Умеет ли Gemini в TTS и транскрибацию?
Немного о работе с моделями гемини, небольшой анализ других LLM и собственный инструмент
Привет, Хабр! В предыдущих статьях я делился опытом создания инструментов для работы со структурированными данными на базе Gemini. Этот проект, начатый из практической необходимости, перерос в нечто большее — в исследовательский интерес к возможностям современных ИИ-моделей.
Если работа с текстами и таблицами стала понятной, то огромный пласт неструктурированных данных — аудиозаписи совещаний, вебинары, обучающие видео — оставался для моих инструментов «слепой зоной». Моей новой целью стало освоение мультимодальных возможностей Gemini. Частично это был чистый интерес — желание научиться работать с моделями, способными обрабатывать звук и видео. Частично — решение прикладных задач.
Я сформулировал для себя три ключевые задачи, которые должен был решить мой обновленный инструмент:
Слушать: Превращать любую аудиозапись в точный, читаемый текст (Speech-to-Text).
Говорить: Озвучивать любой текст практически человеческим голосом (Text-to-Speech).
Смотреть: Анализировать видео и извлекать из него суть, экономя время.
Эта статья — практический рассказ о создании трех новых модулей на базе Google Gemini: транскрибации, синтеза речи и анализа видео. Но прежде чем перейти к реализации, я поделюсь результатами своего «кабинетного исследования» — небольшого анализа рынка, в котором я сравнил подходы Google с решениями OpenAI, Qwen и Yandex.
Предварительный анализ и обоснование выбора технологического стека
Перед началом разработки я провел анализ рынка существующих ML-решений для работы с аудио и видео. Изначально я планировал остаться в экосистеме Google (Vertex AI), так как это обеспечивало единую аутентификацию, биллинг и уже знакомую среду разработки. Однако, чтобы убедиться, что этот выбор не накладывает критических ограничений на качество и функциональность будущего продукта, я провел сравнительный анализ ключевых альтернатив от OpenAI, Yandex и open-source сообщества.
Целью исследования было не найти абсолютного лидера, а понять, насколько конкурентоспособны решения Google в контексте моих конкретных бизнес-задач. Ниже приведены результаты анализа по трем ключевым направлениям.
1. Распознавание речи (ASR): Сравнение точности в различных акустических условиях
В данном сегменте рассматривались три основных решения: OpenAI Whisper, Google Speech-to-Text v2 (модель Chirp) и Yandex SpeechKit. Сравнение проводилось по метрике WER (Word Error Rate — процент ошибок на слово) и наличию встроенных функций постобработки.
Точность на чистых данных: Согласно бенчмаркам (на датасете LibriSpeech), модель OpenAI Whisper демонстрирует наилучшие показатели на студийных записях с низким уровнем шума. Значение WER составляет менее 3%. Это делает модель предпочтительной для транскрибации аудиокниг, подкастов или диктовки в идеальных условиях.
Точность в реальных условиях: При анализе зашумленных записей (датасеты CHIME-5, записи телефонных разговоров) производительность Whisper снижается, а WER возрастает до 25–30%. В этих условиях модель Google Chirp демонстрирует большую стабильность. Это обусловлено тем, что модель Google обучалась на массивах данных из YouTube, содержащих аудиофайлы низкого качества, фоновые шумы и перекрёстную речь.
Диаризация (разделение спикеров): Особенно критическим фактором для бизнес-задач (протоколирование совещаний) является способность системы различать спикеров.
OpenAI Whisper: Не имеет встроенной функции диаризации. Для реализации этого функционала требуется интеграция сторонних библиотек (например, Pyannote Audio), что усложняет архитектуру приложения и увеличивает время обработки.
Google Speech-to-Text: Поддерживает нативную диаризацию (enableSpeakerDiarization) через API. Система автоматически маркирует реплики разных участников, что исключает необходимость развертывания дополнительных сервисов.
Анализ показал, что OpenAI Whisper является лидером по точности в идеальных условиях. Однако для моей задачи (анализ записей совещаний) функционал Google оказался более чем достаточным, а наличие встроенной диаризации стало ключевым практическим преимуществом. Это подтвердило, что первоначальный выбор в пользу экосистемы Google не является компромиссом и полностью покрывает требуемые функциональные возможности без усложнения архитектуры.
2. Синтез речи (TTS): Методы управления интонацией
Сравнение проводилось между Yandex SpeechKit и Google Gemini TTS. Основным критерием был способ управления просодией (интонацией, темпом, паузами) и фонетикой.
Программный контроль (Yandex SpeechKit): Данное решение предоставляет инструменты для точного фонетического контроля. Используя специальную разметку, можно принудительно выставлять ударения (символ + перед гласной), задавать точную длительность пауз в миллисекундах (например, sil <500>) и корректировать произношение отдельных фонем. Этот подход оптимален для статических сценариев, требующих строгого соответствия стандартам (например, IVR в банковской сфере) и создания уникальных брендированных голосов.
Семантический контроль (Google Gemini TTS): Google использует подход, основанный на интерпретации контекста и промптов (Prompt-driven control). Вместо жесткой разметки пользователь может задать эмоциональную окраску речи через текстовые теги, например [angry], [calm] или [news reporter style]. Нейросеть самостоятельно адаптирует высоту тона, скорость и интонационный контур. Также поддерживается стандарт SSML (разметка для синтеза голоса), но акцент смещен на генеративное управление стилем (через промпт можно задать общий стиль речи).
Мое небольшое исследование продемонстрировало два принципиально разных, но одинаково мощных подхода к стилизации речи. Решение от Yandex незаменимо для задач, требующих глубокого инженерного контроля над произношением. В то же время, семантический подход Google идеально соответствовал моим целям — дать нетехническим пользователям простой инструмент для быстрой генерации аудиоконтента с разной эмоциональной окраской. Таким образом, выбор Gemini TTS был вполне оправдан.
3. Видеоаналитика: Специализация против мультимодальности
В сегменте анализа видео сравнивались мультимодальная модель Google Gemini 2.5 Pro и специализированная модель Qwen2.5-VL (Vision-Language).
Точность временной привязки: Модель Qwen2.5-VL архитектурно оптимизирована для работы с видеопотоком. Она использует механизмы динамического разрешения и абсолютного временного кодирования. Это позволяет ей генерировать саммари с точными таймкодами (time-coded summaries) и локализовать события с высокой точностью. Это решение предпочтительно для задач поиска конкретных кадров или событий в видеопотоке.
Контекстное окно и интеграция: Gemini 2.5 Pro обладает контекстным окном объемом до 2 миллионов токенов, что позволяет загружать в контекст видеофайлы большой длительности целиком. Ключевым преимуществом для архитектуры проекта стала возможность нативной обработки ссылок YouTube.
Для использования Qwen или аналогов необходимо предварительно скачать видеофайл, извлечь аудиодорожку или раскадровку, и только затем передать данные в модель.
API Gemini позволяет передать URL видео напрямую, выполняя процессинг на стороне провайдера.
Специализированные модели, такие как Qwen, предлагают более высокую точность в задачах временной локализации (саммари с таймкодами). Однако для моей цели (быстрый семантический анализ вебинаров и докладов) ключевым фактором является минимизация предварительной обработки данных. Нативная поддержка YouTube-ссылок в Gemini API представляет собой значительное архитектурное упрощение, которое подтвердило целесообразность моего первоначального выбора для создания быстрого и удобного пользовательского инструмента.
Итог и подтверждение выбора
Рынок речевых и видеотехнологий предлагает множество высококачественных, но идеологически разных решений. Мое первоначальное решение остаться в рамках единой инфраструктуры Google прошло проверку на адекватность. Небольшой анализ подтвердил, что, хотя по отдельным метрикам (как WER на чистом аудио у Whisper или контроль фонетики у Yandex) существуют более сильные специализированные решения, для моих бизнес-задач комплексный продукт от Google не имеет критических недостатков.
Распознавание речи: Встроенная диаризация и устойчивость к шуму в реальных условиях делают Google Speech-to-Text v2 оптимальным практическим выбором.
Синтез речи: Семантический контроль Gemini TTS более интуитивен для нетехнических пользователей, что соответствует целям проекта.
Анализ видео: Нативная обработка YouTube URL значительно упрощает рабочий процесс, что является ключевым преимуществом.
Таким образом, я пришел к выводу, что выбранный технологический стек не только удобен в интеграции, но и полностью конкурентоспособен для решения поставленных задач.
Построение инструментов: от логики к реализации
Вооружившись этим пониманием, я приступил к проектированию и созданию трех новых модулей. Как я ранее говорил, я технически неподкованный специалист (вайбкодинг и общее понимание — мои основные инструменты), поэтому в технические аспекты лезть не буду. Просто расскажу про подход.
Модуль 1: Транскрибация аудио
Логика и тактика: Моей главной целью было избавить коллег от необходимости слушать многочасовые записи. Я представил себе инструмент: я загружаю файл, нажимаю кнопку и через пару минут получаю не просто стену текста, а структурированный документ с основными моментами и задачами.
Эта мысль привела меня к двухэтапной логике:
Этап "Механическая работа": ИИ должен превратить звук в текст. Это чисто техническая задача.
Этап "Осмысление": Другой ИИ (или тот же, но в другой роли) должен прочитать этот текст и превратить его из хаоса в порядок.
Именно эта двухэтапная концепция легла в основу. Я не стал пытаться решить все одной моделью, а разделил процесс, как это сделал бы человек: сначала записал, потом проанализировал.
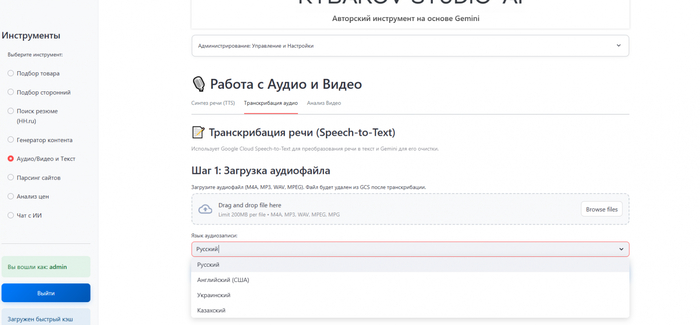
Реализация:
В интерфейсе все просто: кнопка загрузки аудио, выпадающий список для выбора языка и большая кнопка "Начать транскрибацию".
Когда пользователь нажимает кнопку, запускается процесс. Обработка часового аудио не может быть мгновенной, поэтому пользователь должен видеть, что что-то происходит. Для этого я добавил прогресс-бар, который проходит три логических стадии: "Загрузка файла в облако", "Выполнение транскрибации (может занять несколько минут)" и "Структурирование текста". После завершения под формой появляются два текстовых поля. В первом — "сырой" транскрипт, который можно скопировать при необходимости. Далее можно прописать промпт для работы с данным текстом. Тут можно структурировать, делать саммари, ставить задачи (в общем, все как и при работе с любым другим текстом).
Собственно, а для чего? Теперь после часовой планерки (если так можно назвать наши «заседания») за пару минут можно получить четкий документ: саммари для отчета вышестоящему руководству и список задач, которые можно сразу скопировать в Битрикс.
Модуль 2: Синтез речи (TTS)
Разработка данного модуля была обусловлена скорее не прикладными задачами, а стремлением к освоению технологии синтеза речи, созданию удобного инструмента для генерации аудио и банальным интересом. Основной задачей было внедрение функционала Text-to-Speech (TTS) на базе доступных API.
Реализация:
Интерфейс модуля был разработан с упором на минимализм. Он включает в себя большое текстовое поле для ввода озвучиваемого текста, поле для описания желаемого стиля или интонации, выбора модели озвучки, выбор голоса и языка озвучки, и кнопку «Озвучить речь».

После активации кнопки «Озвучить» система направляет запрос к Gemini TTS API, передавая как текст, так и заданный промпт стиля. В течение нескольких секунд сгенерированное аудио воспроизводится во встроенном плеере, с возможностью загрузки файла. Данный процесс обеспечивает простоту и функциональность использования.
А это то зачем?
Если честно ответить на данный вопрос, то «я просто захотел попробовать». Но что можно с этим сделать:
Обучающие материалы: Генерация аудиофайлов для объемных инструкций и обучающих курсов, повышающая доступность информации.
Прототипирование IVR-систем: Возможность быстрого итерационного тестирования голосовых меню (Interactive Voice Response) без привлечения профессиональных дикторов. Это позволяет оперативно генерировать и оценивать различные варианты сообщений, значительно ускоряя процесс разработки и оптимизируя финансовые затраты на финальную озвучку.
Озвучивание внутренних коммуникаций: Создание аудиоверсий информационных сообщений и новостных дайджестов.
Модуль 3: Анализ видео (та же транскрибация практически с теми же целями)
При проектировании данного модуля приоритетом было упрощение процесса взаимодействия с видеоданными. Ранее подготовка видео для анализа часто требовала скачивания, конвертации и загрузки, что являлось трудоемким этапом. Обнаружение в документации Gemini функционала прямой обработки видео по URL-ссылке YouTube было признано оптимальным решением для устранения этих сложностей.
Логика модуля основана на интерактивном взаимодействии в формате "вопрос-ответ". Целью было предоставить пользователю возможность не только получать сводное содержание, но и задавать конкретные вопросы к видеоматериалу для извлечения целевой информации.
Реализация:
Интерфейс модуля разделен на две вкладки: "Ссылка YouTube" и "Загрузить файл". В обеих вкладках ключевыми элементами являются поле для указания источника видео и большое текстовое поле для ввода вопроса пользователя к видеоматериалу.

При активации кнопки "Анализировать" система формирует мультимодальный запрос. Этот запрос состоит из двух частей: объект, содержащий видеоданные (по ссылке или из загруженного файла), и текстовый промпт с вопросом пользователя. Такой подход позволяет формулировать конкретные запросы, например: "Определите момент, где спикер демонстрирует график роста, и опишите его содержание" или "Извлеките все упомянутые в докладе технологии и соответствующие таймкоды". Ответ, сгенерированный Gemini, выводится в текстовом поле под кнопкой активации.
А это пригодилось?
Тут ответ реально убедительный. Инструмент позволяет получать сводное содержание видеоматериалов, перечень анонсированных продуктов или соответствующие таймкоды значительно быстрее, чем при ручном просмотре. Обработка видео (с учетом огромного количества видео на YouTube на самые разные темы) потенциально дает много разного рода информации. По-простому, я «кайфанул» от использования этой технологии.
Итог:
В части проведенного анализа — модели Gemini можно использовать, не опасаясь за качество. В части инструмента – результаты внедрения меня удовлетворили, чего желаю и вам с вашими продуктами.
Благодарю за уделенное время! Надеюсь, мой подробный рассказ о пути от небольшого исследования до реализации вдохновит и вас на создание собственных ИИ-помощников.
оригинал статьи
Показать полностью
3