


Усталый босс
12 постов
12 постов

Generated by ChatGPT 5.2
На самом деле я задумал написать эту статью довольно давно и был уверен, что справлюсь с ней минут за двадцать. Тема казалась понятной, мысли — уже сформулированными. Но когда я сел писать, неожиданно выяснилось, что текст не складывается: аргументы расползались, формулировки не держались, а ощущение ясности быстро исчезло.
В итоге вместо этой статьи я написал две другие. Первая была посвящена стадиям развития проектов — от идеи до GA. Вторая — о эволюции Agile, объясняющая, откуда он взялся и почему, по всей видимости, он с нами теперь надолго. Эти тексты помогли мне навести порядок в базовых понятиях и выстроить контекст, который, как оказалось, был необходим.
Сейчас, когда эта база сформирована, я могу вернуться к изначальной теме. Но прежде важно объяснить, что именно стало отправной точкой для этой статьи и всей трилогии.
Я, по сути, типичный agile-менеджер. В каком-то смысле — евангелист. Я давно проникся этим подходом, много лет использую его в практике и вижу реальные результаты. Итерации, обратная связь, постепенное уточнение решений — всё это для меня не теория, а рабочие инструменты.
И именно поэтому на одном из недавних проектов я неожиданно столкнулся с жёстким сопротивлением. Моё руководство довольно прямо пушило меня назад. Моё желание «есть слона по частям» воспринималось как недостаток серьёзности подхода и вызывало предвзятое отношение.
Попытки двигаться итеративно регулярно наталкивались на скепсис. Черновик документации воспринимался как недодокументация, хотя по задумке это был всего лишь задел для дальнейшего обсуждения и уточнения. Попытка начать с эскиза или наброска воспринималась как нежелание «сделать нормально».
То же самое происходило и с разработкой. Я не мог начать работу над прототипом без заранее утверждённой, чёткой и «красивой» картинки финального решения. При этом мы живём во время, когда благодаря AI и современным инструментам разработка рабочего прототипа — это вопрос нескольких дней, а не месяцев.
В результате вместо движения и проверки гипотез мы снова и снова возвращались к обсуждениям того, как всё должно выглядеть в идеале.
Именно в этот момент вопрос перестал быть про Agile как методологию. Он стал вопросом о границе: где заканчивается стремление всё продумать заранее — и где начинается необходимость двигаться через итерации.

Generated by ChatGPT 5.2
Всегда ли выверенное решение оказывается правильным?
Принимая решения, мы всегда несем за плечами прошлый опыт — местами успешный, местами нет — и он напрямую влияет на то, какие решения мы считаем правильными.
Помимо этого, у нас есть текущее состояние «здесь и сейчас», а также прогноз и видение будущего, которое ещё не наступило и по определению неопределённо.
И вот именно вокруг этого будущего всё и вертится. Практически каждый человек — будь то менеджер, инженер или просто хороший человек — так или иначе выстраивает свою мотивацию, приоритеты и работу вокруг образа будущего. Мы принимаем решения не ради настоящего момента и не ради прошлого опыта, а ради того, каким мы хотим видеть результат впереди.
Но у этого подхода есть фундаментальный недостаток: будущее плохо поддаётся предсказанию.
Конечно, всем нам нравится думать и рассказывать, как мы интеллектуально всё просчитали, учли риски и сделали выводы. Это придаёт нам ореол рациональности и интеллектуальной зрелости. Почему-то в нашем мире умным чаще считается тот, кто выглядит способным предсказывать будущее.
Но на практике наши прогнозы почти никогда не сбываются на сто процентов. Это неизбежно приводит к разочарованию: менеджмент не получает ожидаемых результатов, проекты не достигают заявленных KPI.
Формально ответственность в таких случаях ложится на PM. Но по большому счёту виноватых здесь нет. Проблема не в людях, а в том, что далеко не все готовы — или хотят — мыслить вероятностями.
Во многих организациях до сих пор живо солдафонское отношение к планированию: «мужик сказал — мужик сделал». Неважно как, неважно какой ценой — хоть об стену разбейся, но уложись в срок и выполни обещанное. В такой картине мира неопределённости просто не существует.
В результате образ будущего, вокруг которого мы строим «правильное» решение, часто оказывается гораздо менее надёжным, чем нам кажется.
На основе этого набора мы не находим правильное решение, а формируем рабочую гипотезу. Причём таких гипотез, как правило, несколько.
Именно здесь возникает иллюзия. Мы начинаем искать не просто жизнеспособный вариант, а единственно верное решение, как будто оно объективно существует и может быть вычислено заранее.
Чем дольше мы находимся в этом поиске, тем сильнее ощущение контроля. Кажется, что ещё немного размышлений — и появится то самое решение, после которого не придётся ничего переделывать. На практике же неопределённость никуда не исчезает, а движение просто откладывается.
Именно здесь и становится видно, в чём состоит иллюзия: правильность не обнаруживается заранее — она формируется в процессе.

Generated by ChatGPT 5.2
Так что же нам делать в такой ситуации?
Пытаться сразу сделать всё хорошо и правильно — или всё-таки идти по итерациям?
Из моего опыта — пока вы размышляете о том, как сделать всё правильно, я успеваю накидать несколько прототипов. И как минимум один из них оказывается рабочим и начинает приносить пользу — пусть даже в таком, прототипном виде.
При этом совсем не факт, что тщательно продуманное решение в итоге взлетит. Его ведь недостаточно просто разработать. Его ещё нужно внедрить — фактически заставить пользователей начать с ним работать. А пользователи, как правило, самые упрямые участники процесса.
Здесь важно понимать ещё одну вещь: каждое решение — это ставка.
Когда мы пытаемся сразу сделать «идеально», мы фактически ставим всё на одно видение будущего. Если оно не срабатывает, цена ошибки оказывается высокой — и в деньгах, и во времени, и в доверии.
Итеративный подход снижает размер этой ставки. Мы не пытаемся угадать правильный ответ с первого раза. Мы делаем небольшой шаг, проверяем гипотезу, получаем знания и только потом принимаем следующее решение.
В этом смысле итерации — это не способ ускориться. Это способ дешевле ошибаться.
Самая дорогая ошибка — не та, которую мы совершили, а та, о которой мы узнали слишком поздно. Итерации сокращают это расстояние между предположением и реальностью.

Generated by ChatGPT 5.2
Возможно, главный вопрос сегодня не в том, использовать ли итерации или нет. В какой-то момент они перестают быть выбором и становятся следствием того, как устроена реальность вокруг нас.
Гораздо важнее другое — пересмотреть само представление о том, что значит быть «умным» в сложных системах. Долгое время ум ассоциировался со способностью заранее увидеть правильный ответ, просчитать последствия и уверенно провести решение до конца. Такой образ хорошо работал в мире, где будущее было относительно стабильным и поддавалось прогнозированию.
Но по мере роста сложности этот образ всё чаще даёт сбой. Ум сегодня — это уже не способность безошибочно предсказывать будущее. Это способность достаточно рано понять, что ты ошибаешься, и иметь пространство, время и полномочия, чтобы с этим что-то сделать.
Ценность смещается с уверенных ответов к умению задавать правильные вопросы, с жёстких обещаний — к способности корректировать курс, с демонстрации контроля — к реальной работе с неопределённостью.
И, возможно, следующий шаг — это разговор уже не про методологии и фреймворки, а про культуру принятия решений. Про то, как мы договариваемся с будущим, зная, что оно всё равно нас переиграет.
Читайте мою серию: Усталый Босс
Прошлые статьи:
Generated by Nano Banana
Agile ругают за пустые ритуалы, водопад — за медлительность. Но спор чаще идёт о форме, нежели о сути. Когда-то бюрократия — в духе Макса Вебера и его рационально-легальной модели — научила организации масштабироваться: стандарты, роли, предсказуемость. Цена этой масштабируемости — тяжёлый пересмотр решений и медленный разворот. Agile — следующий шаг эволюции: он учит быстро учиться в процессе поставки, а не только планировать. Смысл — в коротких циклах, где каждая итерация заканчивается работающим инкрементом и проверкой гипотез на реальности.
Противоречия между Agile и Waterfall нет. Можно рассматривать Waterfall как одну из конфигураций Agile, когда из-за требований/рисков команда выбирает очень длинный спринт с единым выпуском в конце.

Generated by Nano Banana
Люди, воспитанные в логике годовых планов и phase-gates-модели, оптимизируют предсказуемость и контроль. Их KPI — «по плану и в срок», зачастую игнорируя выученные уроки. Итерации для них выглядят как «незавершёнка», а видимые переработки — как провал, хотя это нормальная цена за ранние факты.
Плюс срабатывает выученная модель: «сначала всё решает начальник, потом команда просто реализует». Agile переворачивает это местами: команде приходится чаще принимать решения, а менеджеру — мириться с тем, что путь меняется по дороге.
Agile подменяют ритуалами и пытаются применять «везде одинаково».
Итерации тащат в зоны необратимых решений (критичные данные, публичные контракты, безопасность) — получаются дорогие ошибки, после чего делают вывод «Agile не работает».
Или, наоборот, объявляют «гибкость» синонимом хаоса: без Definition of Done, наблюдаемости, критериев «достаточно» и guardrails. Тогда Agile превращается в оправдание «делать что хотим».
В обоих случаях это не Agile по смыслу, а просто плохо настроенный процесс с другим названием.
Топ-менеджмент пишет годовые планы с KPI, спускает их на линейных менеджеров и одновременно требует «работать по Agile». На бумаге — спринты и бэклог, в реальности — жёстко зафиксированный объём, сроки и метрики запуска «как в плане».
В таких условиях Agile на линейном уровне превращается в пародию:
команда должна делать вид, что «гибко адаптируется»,
но её оценивают по тому, насколько она не отклоняется от изначального годового плана.
Любая попытка честно скорректировать курс по результатам итерации воспринимается как «неисполнение плана», а не как нормальное обучение. Естественно, после такого у людей возникает стойкое отвращение к слову Agile.

Generated by Nano Banana
Само по себе неприятие Agile — не что-то уникальное. Почти любое серьёзное управленческое новшество проходит долгий цикл — десятилетиями — через фазы: страх → неприятие → торг → принятие → базовая норма. Хороший пример — **Management by Objectives (MBO) Питера Друкера: когда-то идея управлять через согласованные цели, а не только через приказы сверху, пугала и казалась «теорией консультантов»; компании проходили через торг — цели формально ввели, но часто просто переписывали их из планов руководства. Сегодня MBO и его наследники (KPI, OKR) стали фоном: почти никто не спорит, что у команды должны быть понятные цели, спорят уже о том, как именно их формулировать. С Agile происходит тот же процесс, только объект изменений другой: не сами цели, а способ движения к ним — длинными монолитными циклами или короткими витками обучения.
Точно такой же паттерн можно увидеть и в более близких примерах:
Удалённая работа и онлайн-обучение.
Ещё недавно идея «команда работает из дома» или «учиться можно онлайн» воспринималась как временная мера или вынужденный компромисс. Сейчас онлайн-форматы стали частью нормы, хотя до сих пор есть те, кто не принимает это как состоявшийся факт.
Гигиена и мытьё рук медперсоналом.
Когда-то требование мыть руки между пациентами вызывало яростное сопротивление и воспринималось как сомнение в профессионализме врача. Сегодня отказ от гигиены — маргинальное поведение, а не «альтернативный подход».
Во всех этих историях новое сначала кажется опасным, лишним или «модой», затем идёт долгий период торга и полумер, и только потом наступает стадия, когда вчерашняя инновация превращается в baseline — фон, с которого начинается следующий виток изменений.
С Agile, скорее всего, будет то же самое: через какое-то время спорить будут не о том, «нужен ли Agile в принципе», а о том, как именно конфигурировать процессы и архитектуру работы под конкретную организацию, считая итерационную работу и обучение на поставке чем-то само собой разумеющимся.

Generated by Nano Banana
Если отбросить лозунги, Agile нужен не для того, чтобы «всем было весело на стендапах». Он про другое: как дешевле учиться на реальности, когда окружение меняется быстрее наших планов.
Бюрократия и классический проектный подход решают задачу предсказуемости: чтобы люди знали свои роли, процессы повторялись, а результат можно было встроить в годовой план. В мире, где изменения редкие и медленные, этого достаточно.
Проблема начинается там, где:
требования двигаются вместе с рынком и технологиями,
цена задержки становится выше, чем цена возможных переделок, а «идеальное ТЗ» устаревает быстрее, чем его успевают согласовать.
Agile в такой среде меняет точку оптимизации:
вместо «минимизировать переделки» — минимизировать задержку обучения на ошибках,
вместо «сделать один большой правильный выстрел» — провести короткую разведку боем,
вместо «дотянуть любой ценой до финального релиза» — иметь право остановиться раньше, когда ценности уже достаточно или направление оказалось тупиковым.
Отсюда и вся остальная механика: инкременты, экспериментальность, короткие циклы. Не потому что так написано в книжке по Scrum, а потому что это дешёвый способ регулярно задавать себе два простых вопроса:
*«Мы всё ещё делаем то, что нужно?» и «Не пора ли остановиться или повернуть?»
А как же оптимизация? В такой формулировке Agile действительно не выглядит «идеально вылизанным»: лишние инкременты, разведка боем, работа над ошибками. Возможно, в моменте так и есть — по локальным затратам классический водопад иногда выглядит выгоднее. Но всё поддаётся сравнению на длинной дистанции. Гипотетически проект можно провести по Waterfall достаточно быстро, возможно даже быстрее, чем по Agile… вопрос только в том, принесёт ли он пользу в той реальности, в которую придёт через год. Как говорится, большое видится на расстоянии* на коротком отрезке мы экономим на «лишних» итерациях, на длинном — часто расплачиваемся за это годами поддержки не того решения.
Generated by Nano Banana
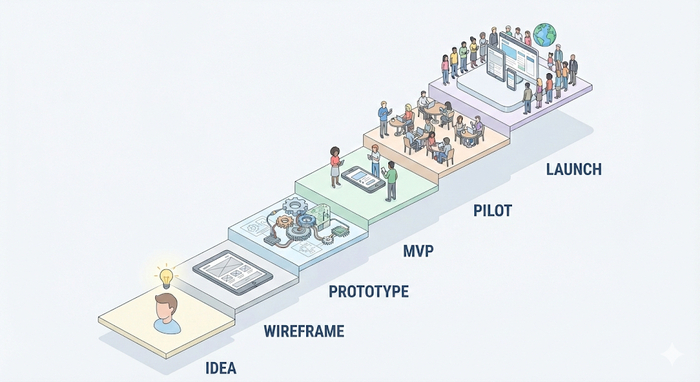
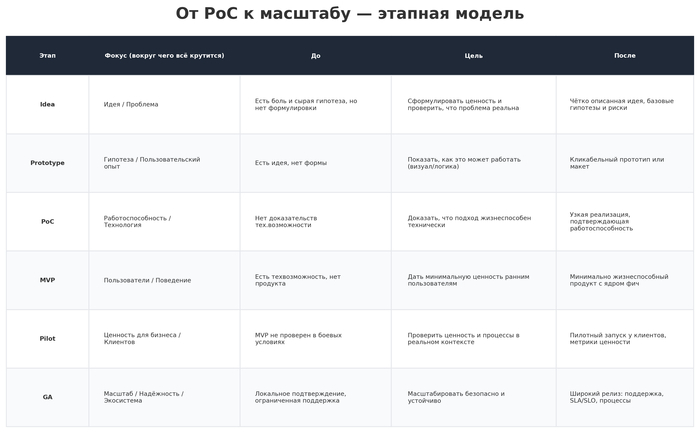
Если оглянуться назад на классический путь фичи или инициативы — Idea → Prototype → PoC → MVP → Pilot → GA — становится видно, что это по сути тоже конфигурация Agile.
Во-первых, каждый этап даёт **ощутимый инкремент**, пусть и не всегда в продакшене.
💡Идея оформлена и проговорена — уже инкремент по сравнению с неоформленным хаосом.
🧠 Прототип позволяет «пощупать» UX.
⚙️ PPoC проверяет техническую реализуемость.
👥 MVP — это уже рабочий продукт для ограниченной аудитории.
💼 Пилот даёт реальный опыт эксплуатации.
Каждый из этих шагов можно показать, обсудить, на нём можно учиться.
Во-вторых, такой workflow даёт возможность «съехать» на любой стадии с минимальными потерями. Если что-то не взлетает на уровне прототипа или PoC, мы теряем существенно меньше, чем если бы сразу шли к большому релизу. Это и есть та самая управляемая гибкость: мы не обязаны бежать до GA любой ценой, у нас есть несколько точек выхода по дороге.
Более того, в Agile совершенно нормально начать с одной идеи, а реализовать в итоге другую — и это не провал, а признак здорового процесса обучения. Об этом я расскажу в следующей статье.
Читайте мою серию: Усталый Босс
Прошлые статьи:
Generated by Copilot
Когда речь идет о серьезной инициативе, командам нужен общий язык и предсказуемая, и известная последовательность шагов.
Главный риск в крупных инициативах — не технологии, а координация людей и ожиданий. Поэтому разумнее сначала подтвердить ценность на ограничённой зоне и лишь потом масштабироваться: короткие волны, явные критерии выхода и решения go/no-go на каждом этапе. Такая этапная модель снимает организационный шум и позволяет безопасно двигаться к целевому состоянию без попытки сразу строить «идеал».
Эта статья — про стадии реализации крупной инициативы: как перейти от замысла к широкому запуску с минимальными рисками и оптимизированными усилиями.
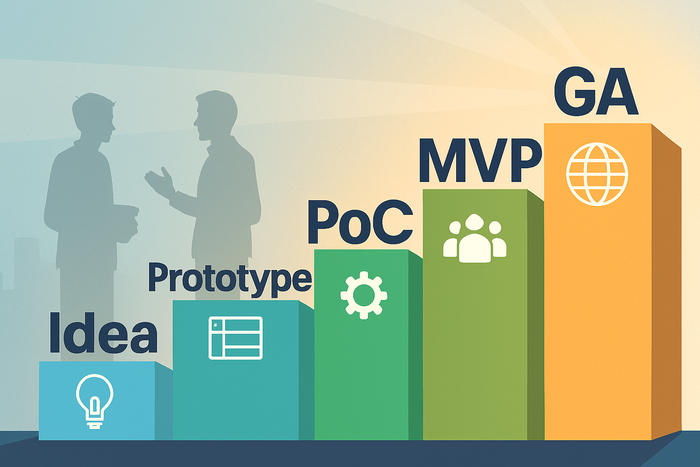
💡 Idea — формулировка проблемы и "гипотезы ценности".
🧠 Prototype — быстрый способ показать как это будет выглядеть/работать (макет, кликабельная демка, «волшебник из страны Оз»; быстрая сборка из подручных средств).
⚙️ PoC (Proof of Concept) — техническая проверка реализуемости в приближённых к реальности условиях.
👥 MVP (Minimum Viable Product) — минимальный продукт для проверки "ядра ценности" на реальных пользователях.
💼 Pilot — частичное внедрение в production; доказательство, что решение может и будет жить в эксплуатации; финальный approval перед масштабированием.
🌍 GA (General Availability) — довнедрение и доступность для всей целевой аудитории.
Сводную таблицу по всем этапам смотрите в Приложении в конце статьи.

Generated by Copilot
Реализация крупной инициативы начинается с "Идеи".
Наша идея проста и амбициозна: перенести около ста баз данных — вперемешку prod и non-prod — в облако.
Важно не «как», а «зачем» — и стоит ли игра свеч? Анализируем возможности, плюсы и минусы, считаем TCO, проводим встречи со стейкхолдерами (бизнес, безопасность, эксплуатация, финансы). Здесь же можно остановиться, если «игра не стоит свеч» — самое время закончить проект без убытков 🙂.
Generated by Copilot
Дальше нужна «картинка будущего», чтобы все говорили об одном и том же. И чтобы инициатива не зашла в ситуацию, когда кажется, что обсуждаем одно и то же, а на деле каждый понимает своё, — как можно быстрее переходим в практическую плоскость. Нужен рабочий стенд — это и есть прототип.
Поднимаем экземпляр базы данных (или несколько) в облаке. Загружаем анонимизированные данные. Например, можно собрать отдельную БД с аудит-логами разных систем на сотни гигабайт, предварительно их анонимизировав.
Теперь у нас есть рабочее черновое решение. На его основе можно строить реальные демо и убеждать стейкхолдеров эффективнее. Кроме того, на следующих стадиях мы сможем оттачивать гипотезы уже на реальном продукте, пусть ещё в форме набросков.

Generated by Copilot
Теперь — практика. Цель PoC — доказать, что инициатива будет работать. Делаем внедрение, максимально приближённое к реальности.
Если в прототипе мы прежде всего убеждали СЕБЯ 🧑, что всё ВООБЩЕ 🤔может работать, то теперь настало время убедить БИЗНЕС 💼 И речь не только о работоспособности целевого решения, но и о самом методе движения к нему: последовательности шагов, повторяемости процедуры, понятных входах/выходах и критериях качества.
Берём non-prod базу (с данными, максимально приближёнными к prod) и клонируем её в облако. Прогоняем процесс миграции, фиксируем шаги, пишем первичную документацию, проводим замеры. Приглашаем реальных пользователей и владельцев приложений потестировать. Master-копия остаётся on-prem.
Результат: у нас есть продукт (или его часть), который работает и потенциально приносит value — это подтверждают замеры. Есть повод вынести на очередной approve (go/no-go).

Generated by Copilot
Первая настоящая эксплуатация — но в управляемом контуре. Цель MVP — доказать, что продукт может эксплуатироваться. Конечные реальные пользователи пробуют продукт и дают обратную связь. Они — главные тестировщики, а не специалисты поддержки и разработчики. Продукт может не иметь всех заявленных фич, но core-фичи на месте. Если до этой стадии мы тянули с трудом сани в гору, то после MVP уже катимся с ветерком с горы. Остальные стадии (Pilot, GA) с точки зрения приёмки уже выглядят как sanity-checks.
Два практичных сценария для переноса баз данных в облако (в идеале оба):
1) Частичный перенос в облако значимых для бизнеса БД, но ещё non-prod — например, UAT-серверы (User Acceptance Testing) с серьёзной нагрузкой.
2) Частично переносим некритичный prod.
Перенесённое в рамках MVP — с вероятностью ~99% остаётся в облаке.
Если мы всё делали как надо, объём проекта (scope) уменьшается: то, что уже переехало в рамках MVP, повторно переносить не придётся.
Что получаем?
Подтверждённая жизнеспособность решения в эксплуатации.
Переключение/откат проверены и описаны.
Есть опорный контур для масштабирования.
Документация и рутины (чек-листы, runbook, окна) в рабочем состоянии.
Сопротивление стейкхолдеров должно значительно упасть.

Generated by Copilot
К началу Pilot, как правило, уже понятно, что проекту «быть»: утверждён бюджет, подписаны контракты с поставщиками, согласованы сроки и объём. Теперь задача — организовать плавное и максимально безопасное «приземление» План по дням/неделям/месяцам есть — осталось начать. Чтобы снизить риск, выбираем лояльных заказчиков и приложения, сбой которых не остановит бизнес, но эффект будет заметен; одновременно в пилоте проверяем и подтверждаем бизнес-ценность (метрики результата, экономия/затраты, отклик пользователей, готовность владельцев процессов).
Pilot — это работа с реальными пользователями и PROD-нагрузками. Здесь в последний раз оттачиваем процессы и доводим документацию.
Например, выбираем две базы: одну с OLTP-нагрузкой и одну с DWH. Они не критичны, но и не самые лёгкие — влияние видно. Переносим их в облако и делаем все нужные измерения.
Что получаем?
Работает у реальных пользователей без сюрпризов.
Переключение/откат отрепетированы, шаги и ответственные понятны.
Мониторинг даёт нужные сигналы без лишнего шума.
Инструкции и чек-листы готовы, контакты дежурных назначены.
Интеграции проверены; скрытые зависимости сняты или в плане.
Затраты подтверждены реальными счетами.
Есть чемпионы-пользователи и референсы.
Короткий список что доделать до GA с приоритетами.

Generated by Copilot
Финальный поворот — не эффектный «большой релиз», а аккуратная дораскатка и переход к обычной жизни. Планируем волны, заранее коммуницируем freeze-периоды, делаем cutover по чек-листам, усиливаем дежурства и связь с бизнесом. Путь отката должен быть реальным*а не «на бумаге» — проверен на репетициях. Параллельно доводим наблюдаемость и эксплуатацию до стандартов: дашборды, алерты, runbook’и, регламенты эскалации, расписания on-call.
Через какое-то время, когда новый ритм стабилизируется, аккуратно выводим из эксплуатации старые ресурсы — чтобы не платить дважды и убрать путаницу в контурах.
Что получаем?
Продукт доступен всей целевой аудитории и стабильно работает.
Эксплуатация ведётся по устойчивым процедурам (мониторинг, алерты, on-call, регламенты).
Предсказуемые затраты*и прозрачный биллинг; legacy выключен.
Метрики стабильности/производительности/стоимости под контролем, риски локализованы.
В больших инициативах хаос возникает не из-за нехватки умных людей, а из-за отсутствия общего языка и последовательности. Шесть этапов — это простой контракт ожиданий между бизнесом, инженерами, безопасностью и эксплуатацией. Каждый шаг «сжигает» конкретный класс рисков:
💡 Idea — риск «делаем ли мы то, что нужно»; 💡 Prototype — риск непонимания решения; ⚙️ PoC — риск технической реализуемости; 👥 MVP — риск жизнеспособности в реальной среде; 💼 Pilot— риск эксплуатационной готовности; 🌍 GA — риск операционной устойчивости и масштабирования.
Почему нельзя «перепрыгнуть»? Потому что ускорение без снятия рисков — это долг с высокой ставкой. Типичные антипаттерны:
⚙️ Вечный PoC: нет мостика к эксплуатации и критериям выхода.
👥 MVP как конечная остановка: «временное» становится постоянным без наблюдаемости и отката.
💼 Пилот без exit-критериев: бесконечная бета, в которой всё «почти готово».
🌍 GA без плана вывода legacy: двойная оплата и путаница в контурах.
Не бойтесь останавливаться: если данные на любом этапе говорят «нет», это тоже результат. Вы экономите бюджет, сокращаете риск и оставляете после себя полезные наработки — документацию, скрипты, метрики, выводы.
И наконец, этот каркас работает не только для миграций: платформенные изменения, интеграции, запуск новых сервисов, крупные рефакторинги — везде, где много участников и высока цена ошибки. Сила подхода в том, что он делает сложное управляемым и социально приемлемым: все понимают, где мы находимся, какой следующий шаг, чем меряем успех и как откатываемся, если что-то пойдёт не так. Определите свой текущий этап, назовите следующий инкремент и договоритесь о критериях — и «большая гора» превратится в серию коротких, понятных подъёмов.
Читайте мою серию: Усталый Босс
Прошлые статьи:
Generated by ChatGPT
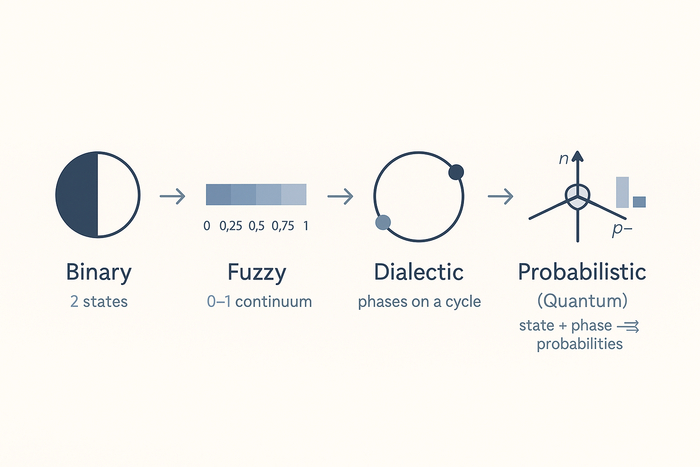
По образованию я физик, а по профессии — IT-специалист. Казалось бы, с логикой у меня всё должно быть в порядке: строгие формулы, алгоритмы, доказательства — привычная среда. Долгое время я жил в парадигме классической логики, где всё делится на «истину» и «ложь», «правильно» и «неправильно». Но всё время чего-то не хватало: мир всё равно ускользал от этих схем.
Были периоды поиска. Я увлекался эзотерикой, интересовался религиями, читал Кастанеду и квантовую механику. Адептом всего этого я, к счастью, не стал — хотя искушение было. Но именно этот путь привёл меня к простому пониманию: мир не плоский и не черно-белый, и объяснить его правилами одной только классической логики невозможно. Как оказалось, мыслить можно по-разному — и существует несколько видов логики, каждая из которых по-своему помогает нам понимать реальность. Вот о них я и хочу поговорить.

Generated by ChatGPT
Наверное, человек, далекий от математики и философии, знает только один тип логики — бинарный. Для него других просто не существует. Логика в таком понимании — это простые и понятные схемы: если A = A, то иначе быть не может. Или как в школе: 2 × 2 = 4, и уж никак не 3 или 5.
Такая логика воспринимается как нечто абсолютно естественное, «здравый смысл». В ней действует закон идемпотентности: повторение одного и того же аргумента даёт тот же результат, и любые альтернативы отбрасываются как «нелепые». Это мышление удобно и предсказуемо: мир представляется чётким, с ясными правилами, где каждая вещь имеет однозначное значение.
Несмотря на всю базовость, адептами такой логики является очень широкий круг людей. Ею пользуются дети и взрослые, рабочие и интеллигенция, люди с высшим образованием и политики. По сути, это универсальный инструмент, который одинаково применим и на заводе, и в парламенте, и в школьном классе. И именно поэтому бинарная логика так прочно укоренилась в массовом сознании: она проста, наглядна и кажется абсолютно достаточной для объяснения мира.
Мало того, наверное, нет другого способа донести информацию более-менее точно и с минимальными искажениями, чем использовать именно этот тип логики. В частности, у меня нет другого выбора, кроме как писать этот текст, опираясь на бинарную логику, хотя внутренне хотелось бы изложить всё совсем по-другому. Такая вот ирония.
Резюме (логика ↔ интеллект). Бинарная логика естественно соотносится с аналитическим (логико-математическим) интеллектом. Хорошо работает в теории, формальных доказательствах и спорах, где важны чёткие критерии и строгие выводы.

Generated by ChatGPT
В отличие от бинарной картины мира, многозначная логика допускает промежуточные значения. Один и тот же факт можно трактовать по-разному: стакан, наполненный наполовину, для кого-то «наполовину пуст», а для другого — «наполовину полон». В жизни и в работе мы часто сталкиваемся именно с такими «наполовину или на четверть полными стаканами».
Однако в этой логике всё равно есть крайности — особые состояния. Полностью пустой стакан и полностью полный стакан — это уже не интерпретация, а чёткие пределы шкалы.
Таким образом, бинарная логика — это частный случай градуальной на уровне интерпретации шкалы (крайние точки отрезка).
Резюме (логика ↔ интеллект). Градуальная логика ближе к эмоциональному и практическому интеллекту. Сильна в реальном воплощении идей: учёт контекста, компромиссы, работа с несколькими критериями одновременно.
Generated by ChatGPT
Бинарная логика показывает мир как чёткую пару полюсов — кажется, что они взаимоисключающие. Градуальная логика даёт надежду: между противоположностями есть путь с градациями — путь от зла к добру, от тьмы к свету, от пустого стакана к полному. Но даже при таком взгляде остаются крайние проявления, которые кажутся несовместимыми.
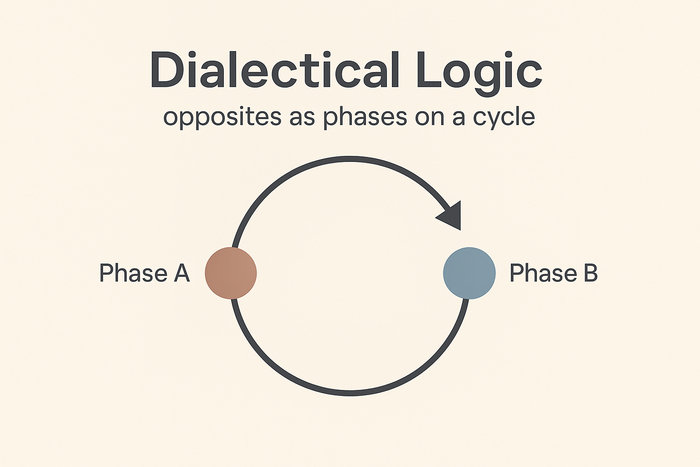
Диалектическая логика идёт дальше и соединяет противоположности через понятие фазы. День и ночь — это по сути одно и то же явление (суточный цикл), только в разных фазах. Пословица «нет худа без добра» — тот же диалектический мотив: негативная фаза процесса несёт в себе потенциал позитивной (и наоборот). В этой оптике вместо прямой с концами — замкнутая окружность состояний: «полюса» оказываются обычными позициями на фазовом круге, а переходы между ними — естественными.
Противоположности здесь — не «враги по разные стороны баррикад», а разные конфигурации одного процесса, которые становятся значимыми для конкретного наблюдателя из-за его персональной чувствительности (к добру и злу, «холодно — жарко» и т. д.). Ночь и день — не абсолютные антиподы, а точки одного цикла; сумерки и рассвет показывают, как «противоположности» плавно перетекают друг в друга без жёсткой границы.
Принцип проекций. Все события — части одного целого, проявляющиеся в разных проекциях.
«Тьма» и «свет» — фазы одного явления (циклы, колебания, движение), а не изолированные сущности.
«Холодно» и «горячо» — про среднюю кинетическую энергию частиц (в твёрдых телах — амплитуду колебаний решётки); «крайности» здесь во многом человеко-зависимы: пороги терпимости и безопасности различаются у людей, поэтому одна и та же температура разными наблюдателями оценивается по-разному.
Одна и та же ситуация, разложенная по разным осям (времени, ценностей, участников, масштаба), даёт разные оценки — отрицательные, положительные, нейтральные — оставаясь одним событием в целом.
Зачем это нужно?
Для мышления. Снимает напряжение «или-или»: можно удерживать оба полюса и искать переход/баланс.
Для жизни. Помогает избегать крайностей, видеть «третьи решения» и долгосрочные эффекты.
Для развития. Конфликт старого и нового даёт динамику — рост появляется на стыке фаз.
Резюме (логика ↔ интеллект). Диалектическая логика ближе к системному/интегративному интеллекту: соединять взгляды, примирять «противоположности», видеть целое и процессы перехода.

Generated by ChatGPT
Если посмотреть на всю картину, видна иерархия: бинарная логика — частный случай градуальной; градуальная — частный случай диалектической; а диалектическая становится «пищей» для ещё более всеобъемлющей модели — вероятностной (квантовой) логики. Она не отрицает прежние подходы, а включает их как предельные случаи и добавляет ключевой элемент — вероятностность.
Почему вероятностное (квантовое), и при чём тут квантовая механика? Потому что в жизни очень часто у нас нет возможности утверждать точно: полная информация недоступна или её извлечение требует времени и усилий. Однако решения принимать всё равно нужно — управлять неопределённостью помогает именно вероятностная логика.
А квантовая механика здесь потому, что в начале прошлого века учёные обнаружили: поведение элементарных частиц нельзя объяснить законами классической механики. В квантовом мире много «чудес», в которые мы здесь не углубляемся, но важно другое: всё это строго формализуется математикой, только вместо конкретных значений координат и скоростей мы получаем вероятностные предсказания измеряемых величин. То есть теория заранее говорит не «что будет точно», а с какой вероятностью тот или иной исход проявится при измерении. И это квантовое представление мира хорошо согласуется с тем, что в реальной жизни мы называем вероятностной логикой — когда мы заранее оцениваем шансы, управляем рисками и живём с неполнотой знаний.
Например, планирование покупки акций. Мы не можем заранее знать, вырастет цена или упадёт. Но можем строить прогнозы, опираясь на прошлую динамику, финансовую отчётность и состояние спроса/рынка. Чтобы не «прогореть», не кладём все яйца в одну корзину: диверсифицируем портфель (добавляем прочие активы), распределяем капитал по позициям и горизонтам, используем лимиты на долю одной идеи. Так риск отдельной ошибки не разрушает всю стратегию — это и есть вероятностное управление.
Одновременно удерживаем несколько сценариев как возможных до момента «схлопывания» в один исход.
Результат зависит от выбора метрики/базиса: какую ось оценки берём — такую проекцию и видим.
Не хаос, а закономерность: фундаментальные законы остаются в силе, просто не всегда интуитивны.
Резюме (логика ↔ интеллект). Вероятностное мышление ближе к прогностическому/вероятностному типу интеллекта: держать неопределённость, мыслить сценарно, осознанно выбирать «базис» оценки.
Читайте мою серию: Усталый Босс
Прошлые статьи:

Generated by Copilot
Эту статью я решил написать после очередного раунда общения с поддержкой одного крупного поставщика ИТ услуг. Я пришёл с конкретной проблемой: симптомы, версии, логи, репро-кейс — всё на месте. В ответ получил аккуратное, холодное: «Это не на нашей стороне. Обратитесь к вашим местным сетевым инженерам». Иными словами — отфутболили.
Такое случается повсеместно, и всё же именно в тот момент я поймал себя на мысли, что уже видел эту картину раньше — только с другой стороны. Я вспомнил свой путь: от «эникейщика» на госслужбе до Service Delivery Manager в международной компании. Я помню время, когда один человек чинил всё — от розетки до кода. И помню, как в больших организациях между командами вырастают стены: обращения ходят по кругу, метрики выглядят прилично, а сервис по-прежнему стоит.
С тех пор у меня простое убеждение: поддержка XXI века обязана измеряться не количеством уровней поддержки, а скоростью и качеством восстановления, не говоря уже о постоянном улучшении сервиса (Continuous Service Improvement, CSI). Не «чей запрос», а «кто взял на себя ответственность довести до результата». Это и есть главная тема этой статьи — как вернуть поддержке цельность и скорость, не потеряв безопасность и зрелость процессов.
Дальше — о том, что мы потеряли на пути от «человека-оркестра» к узкой специализации, и как вернулась назад универсальность, но уже в версии 2.0.

Generated by Copilot
Конец 90-х, начало 2000-х — время, когда ИТ было ближе к ремеслу, чем к выстроенному процессу. В небольших компаниях от одного человека ждали целиком «закрыть контур»: протянуть витую пару и обжать коннектор, переустановить Windows и поднять домен, настроить бэкап и написать скрипт, починить принтер и выправить отчёт в базе. «Человек-оркестр» — не фигура речи, а способ выживания: меньше согласований, выше скорость, ниже стоимость.
В такой среде вырабатывалась полезная привычка — мыслить целостно. Не было никаких очередей и порталов: если у кладовщика не печатается накладная, ты идёшь по цепочке — есть ли бумага, не зажевало ли её, включён ли принтер, жив ли кабель/порт, виден ли принтер в системе, не зависла ли очередь печати, корректно ли установлен драйвер, доступен ли сервер печати, не упал ли свитч, хватает ли прав в приложении, отвечает ли база. И так — пока накладная не выйдет из принтера. Важно было одно: вернуть работу в строй как можно скорее.
Разумеется, у этой модели были издержки. Надёжность держалась на индивидуальном героизме, знания передавались из рук в руки, а документация жила в голове и в папке с утилитами на флешке (если вообще была). Но именно тогда я приобрёл опыт, которым дорожу до сих пор: если можно вернуть систему к жизни за пять минут — это надо делать; а потом уже разбираться, как оформить решение так, чтобы оно стало штатным. Не зная, что такое Agile, я жил по Agile 😅.

Generated by Copilot
Затем мне повезло поработать в большой федеральной компании. Там не было отдела ИТ — там был целый ИТ-департамент, около 500 человек. Предсказуемость, роли, процессы, регламенты — всё по рельсам. И вместе с этим выросли толстые стены специализаций на стыках команд. Мне пришлось выбрать специализацию, и я выбрал быть DBA — администратором баз данных, хотя очень любил программировать; но тогда DBA платили больше 💸: бэкапы и восстановление, производительность, HA/DR, патчи, соответствие требованиям — моё новое всё.
Я видел это много раз. Ночью падает производительность, прилетает тикет — у пользователей «висит» форма. Мониторинг БД показывает рост ожиданий ввода-вывода. Я подозреваю диски и переназначаю тикет администраторам систем хранения — через час он возвращается с отпиской «проблем не видим». Кидаю тикет сетевикам — ещё через час он возвращается обратно. Пинг-понг повторяется, а проблема не решается. В итоге SLA «протухает», и виноватым становится тот, на чьих руках тикет застал дедлайн. А через сутки выясняется, что причина — просто крошечная настройка на одном из узлов ERP-системы (за эти серверы я вообще не отвечал).
Специализация — не враг. Она дает глубокую экспертизу и качество. Проблема в другом: нет сквозного владения и прочных «мостов» между командами — кто ведёт запрос до конца и отвечает за результат. Именно здесь я впервые по-настоящему почувствовал, что «правильно» — не всегда «полезно» для сервиса.

Generated by Copilot
Я хорошо помню это чувство: ты всё делаешь «по правилам», а сервис стоит. Передаёшь дальше, ждёшь ответа, согласовываешь — а людям нужно, чтобы заработало сейчас.
Однажды ночью встал склад: отгрузка уперлась в баг печатной формы. Формально это не моя зона. Я нашёл форму, реверс-инжинирингом в дамп-редакторе нашёл баг, поправил его — что называется, «херак-херак — и в продакшн». Через пять минут конвейер ожил, и компания не потеряла сотни тысяч долларов. Формально это зона ответственности разработчиков; в ту ночь они спали, и даже разбуди их — решение бы затянулось до утра, ведь они играют только по правилам.
И в этот раз я ещё раз убедился — как и в случае с «человеком-оркестром» — что в поддержке действует принцип «сначала восстановить, потом нормализовать»: правильная последовательность — сначала вернуть работу в строй как можно скорее, параллельно фиксируя сделанные шаги и уведомляя владельцев; а уже утром — оформить изменение, поправить код и документацию, коротко разобрать причины. Так эпизод героизма превращается в улучшение процесса — и в следующий раз решает уже не смелость, а система.

Generated by Copilot
Став тимлидом, я сделал ставку на управляемую широту. Не «все делают всё», но каждый способен протащить задачу через стык, не роняя мяч. Разработчик — не DevOps-инженер, но умеет собрать простой пайплайн для новой фичи на Jenkins; позже этот пайплайн перепишет профессиональный DevOps, зато работа не стоит и появляется необходимая взаимозаменяемость. Сотрудник поддержки — не бэкендер, но открывает git-репозиторий, читает логи и на языке кода объясняет разработчику, в чём проблема; а в несложных случаях — сам правит код и формирует аккуратный pull request. DBA — не владелец продукта, но может предложить безопасный обходной путь, чтобы бизнес не стоял.
Чтобы это работало, широту пришлось «закрыть рамками». Любая правка идёт через короткий pull request и review; выкладки — маленькими порциями с возможностью отката (а-ля release management и change management); доступы — по принципу наименьших привилегий. Продукт активно обсуждается всей командой на регулярных встречах — поднимаем и кроссфункциональные темы. Так вся команда в курсе, как устроен продукт целиком.
Главный эффект — исчез лишний бег по кругу. Там, где раньше запрос кочевал между очередями, сегодня он движется по прямой: один человек берёт его в работу, зовёт тех, кто нужен, фиксирует шаги — и доводит до результата. Скорость выросла не за счёт героизма, а за счёт реальной командной работы и привычки смотреть на систему целиком. При этом сохраняется ownership: независимо от того, кто решает проблему в данный момент, всегда есть тот, кто знает полную картину.

Generated by Copilot
Мы и правда вернулись к широте — только осознанной. «Универсал 2.0» — это не человек, который делает всё один, а тот, кто доводит задачу до результата, понимает соседние части системы и вовремя подключает нужных людей.
Владение до результата. Запрос имеет владельца до финала.
Скорость решения, но с контролем качества.
Широта — управляемая. T-shape навыки, guardrails, парные дежурства, кросс-обучение.
Прозрачность и учёба. Blameless RCA, чистые runbook’и, обновления после каждого случая.
Метрики по делу. Оцениваем не «сколько перераспределили», а как быстро и стабильно восстановили сервис.
Читайте мою серию: Усталый Босс
Прошлые статьи:

Generated by Copilot
Поучаствовал в рубрике #УмХорошоДваЛучше владельца Телеграмм канала «Лайфхаки управленца» Сергея Вепренцева
Со своей стороны хотел бы предложить расширенный вариант Ошибок работодателей и кандидатов. и дать больше рекомендаций обеим сторонам
Собеседование — процесс взаимный 🤝. Работодатель ищет компетенции под реальные задачи, кандидат — возможность продать релевантный опыт. При этом кандидат в более уязвимой позиции, значит, задача руководителя — снизить стресс и создать условия, в которых человек раскроется. Когда обе стороны готовятся и ведут честный диалог, собеседование превращается из «экзамена на выживание» в точную проверку совместимости.
Рекомендации руководителю 👔
Требования позиции 🎯
Требования должны соответствовать на 100% тому, чем кандидат будет заниматься в ближайшие 6 месяцев.
Подготовка к собеседованию 📝
Читать CV на собеседовании — red flag для кандидата. С ним следует ознакомиться заранее, провести сопоставление с описанием позиции. Приоритизируйте навыки от «наиболее нужных» к «наименее нужным» и ведите интервью по этому порядку. Так за 60 минут можно обсудить действительно важные вещи, а если на что-то не хватит времени — это не будет критично. Обратите внимание на наличие сертификатов: не стоит тратить много времени на уже «подтверждённые» навыки.
Интервьюер — лицо компании 🏢
По вашему тону и структуре кандидат считывает климат и зрелость. Невежливость, сумбур, несогласованные критерии — частая причина отказа сильных кандидатов, даже при хорошей зарплате.
Практика важнее теории 🛠️
Интересуйтесь, как кандидат решал/будет решать практические кейсы, а не только знанием теории 📚.
Сортируем core- и развиваемые навыки 🧩
Core-навыки намного ценнее прочих развиваемых навыков, которые приходят с практикой.
Эмпатия и кооперация 🤝
Снижайте напряжение.
«Понимаю, кейс сложный — я и сам не смог бы решить его идеально, но давай порассуждаем».
«Мы недавно столкнулись с проблемой — мог бы ты посоветовать решение?»
Допустимы и небольшие подсказки: как в работе, так и на интервью «бриллиант» может раскрыться позже.
Без предвзятости ⚖️
Во время интервью собирайте данные, уважайте мотивированную позицию кандидата (даже если вы не согласны). Решение — после де-брифа, по единым критериям роли.
Рекомендации кандидату 🧑💼
Изучить информацию о компании 🔎
Понять в интернете, что за компания: что производит, что продаёт. Миссия/видение — если доступны.
Сопоставить описание позиции и собственные навыки 📌
Разделите требования на core и развиваемые и честно соотнесите их со своими скиллами.
Подготовить короткую речь о себе 🎙️
Не пересказывайте всю карьеру и список компаний — говорите только релевантное роли:
— кто вы для этой роли (2–3 сильных core-навыка) 💪;
— 2 кейса по STAR с метриками ⭐📈;
— почему это соответствует задачам команды 🎯.
Освежить забытые навыки 🧠
Перед интервью допустимо «размять память» (конспекты, песочница, ИИ) — но без вранья на встрече. Широкая осведомлённость помогает связать понятия:
«Blue/Green на практике не делал, но понимаю: два прод-окружения (blue/green), переключение трафика балансировщиком, быстрый rollback без даунтайма».
5. Mock-интервью с помощью ИИ 🤖 Загрузите описание позиции и своё резюме в ИИ и попросите провести mock-интервью: с поведенческими и практическими вопросами, таймингом и обратной связью. Это помогает потренироваться, вычленить слабые места и подготовить ясные ответы по ключевым темам.
Читайте мою серию: Усталый Босс
Прошлые статьи:

Generated by Copilot
Иногда решения в ИТ принимаются не головой, а… мозгом. А мозг любит экономить батарейку и ошибается по шаблону. Эти «шаблонные ошибки» и называются когнитивными искажениями. Ниже — 10 самых частых ловушек для ИТ менеджеров и команд

Generated by Copilot
Замечаем то, что подтверждает наши прежние убеждения, и пропускаем остальное.
Приложение «тормозит» — application support сразу винит DBA: месяц назад после оптимизации базы данных «всё висело», значит и сейчас наверняка виноваты снова они, симптомы похожи на те что были месяц назад. Варианты то что проблемы могут быть в прочих компонентах приложения (инфраструктура, сеть и пр.) даже не рассматриваются.
Точнее проверяйте факты: Неподтверждённое обвинение может обидеть другую сторону и испортить отношения надолго. Предъявляйте не предположение, а проблему, доказанную конкретными метриками. Используйте корпоративные системы мониторинга, которые охватывают весь стек (приложение, база данных, сетевой слой, инфраструктура) и доступны для анализа широкому кругу участников.
⚓ Эффект привязки (Anchoring)

Generated by Copilot
Первое число/факт которое попадает в наше поле зрения задаёт «якорь» для дальнейших решений — всё остальное подгоняем к нему.
Выбирая вендора для новой системы мониторинга, берём первого из выдачи Google — остальные варианты уже не воспринимаются всерьёз.
Это сильное искажение, от которого нелегко избавиться, но влияние можно уменьшить. До поиска сформулируйте параметры и критерии желаемой системы и выбирайте по соответствию требованиям, а не по порядку выдачи. Соберите несколько альтернатив, представьте их команде в случайном порядке и соберите обратную связь.
Generated by Copilot
Тянем проект/технологию «потому что уже столько вложили», вместо того чтобы смотреть на будущие выгоды.
Есть дорогие Enterprise-perpetual-лицензии на Oracle Database — держимся за неё, хотя можно перейти на бесплатную open-source-альтернативу или более экономичный managed-сервис. Решение диктуют прошлые траты.
Делаем новый расчёт с учётом перехода на свежие технологии — вероятные выгоды могут перекрыть потери. Считаем не только деньги, но и будущие «возможности»: скорость вывода фич, гибкость архитектуры, снижение vendor lock-in. Улучшение климата в коллективе и мотивации — тоже бенефит.

Generated by Copilot
Систематически недооцениваем сроки и усилия: в голове — «идеальный мир», в жизни — зависимости, очереди и внезапные «а сертификат то истёк».
Задачу планировали сделать за 5 часов, но по ходу всплыли неучтённые сложности — в итоге ушло 10 часов, а ещё пришлось завести пару тикетов в technical debt.
Человек, который окончательно решит задачу точного планирования, получит Нобелевскую премию. А пока используем базовые стратегии: трёхточечные (или шеститочечные) оценки/PERT, «покер планирования» для независимых прикидок и буферы как на уровне задач, так и на уровне проекта.

Generated by Copilot
Мнение «большого начальника» автоматически кажется верным: даже если кто-то в команде не согласен, спорить «не принято», и точку зрения руководителя принимают — пусть и с сомнениями.
Большой босс говорит: «В прошлой компании мы внедряли этот продукт — выгоды не получили, значит и здесь внедрять не будем». Детали того внедрения (цели, масштаб, настройки, метрики) не раскрываются, но решение фактически принимается «по весу» спикера.
Конструктивно спорить с боссами и «звёздными» коллегами — нормально: опирайтесь на метрики, результаты пилота, TCO/ROI и чёткие критерии. Если убедить руководителя не удалось, заранее зафиксируйте риски и последствия выбранного курса (краткий one-pager/decision record), договоритесь о метриках успеха и триггерах для пересмотра решения.

Generated by Copilot
«Все так делают — и мы сделаем»: популярность решения подменяет его пригодность именно для нас.
Внедряем Prometheus + Grafana для time-series-мониторинга, потому что «это у всех». Хотя у нас монолит на ~200 пользователей, нужен мониторинг здесь и сейчас, и текущий вендорский мониторинг уже закрывает потребности. В итоге получаем лишнюю инфраструктуру и лишнюю точку сбоя — без реальной выгоды.
Когда тянет идти за трендом, сначала выписываем свои use cases и критерии успеха: зачем нам это и какие метрики улучшатся. Отвечаем на вопросы, кто будет это поддерживать? Не превратится ли это через год в кладбище ненужных технологий? Сравниваем с базовой альтернативой («оставить как есть»/вендорское решение) и принимаем решение по пользе, а не по моде.
Generated by Copilot
В малых выборках велик шанс случайных «крайностей» в нетипичных местах: разброс высок, закономерности ещё не проявились — поэтому мы склонны делать большие выводы по маленьким данным.
Фидбэк. Получили три отзыва: два нейтрально-негативных и один сильно позитивный. По двум «минусам» делаем вывод, что «всё плохо», хотя выборка слишком мала и легко искажена.
Интервью. Пять бесед с «любимыми» клиентами → «фича нужна всем», а реальное использование потом — всего 7%.
Проводите исследования на репрезентативных выборках. Если большую выборку собрать не удается, то убедитесь хотябы что она охватывает как можно больше категорий.

Generated by Copilot
Видим истории успеха, а «кладбище неудач» — нет. Делаем выводы по тем, кто выжил, а не по полной картине.
Выбираем платформу observability по витрине «успешных внедрений» и логотипам на сайте вендора. Не спрашиваем, сколько PoC провалилось и в каких условиях те кейсы взлетели — и повторяем чужой путь вне нашего контекста.
Требуем «знаменатель»: сколько компаний пробовало и каков процент успеха/отказов для нашего масштаба и домена. Запрашиваем негативные кейсы и контакты референсов; запускаем короткий пилот с чёткими метриками успеха/остановки и сравниваем с базовой альтернативой (status quo) — решаем по данным, а не по красивым историям.

Generated by Copilot
Люди с низкой компетенцией переоценивают себя, а опытные — осторожничают. Уверенность легко маскируется под экспертизу.
Молодой менеджер после 2–3 удачных внедрений воодушевляется, берёт завышенные обязательства на следующий крупный проект — и проваливается. Параллельно мнение опытного менеджера, который трезво оценивал сроки и риски, игнорируется: уверенный новичок «кажется опытнее».
Отделяйте уверенность от компетенций: оценивайте аргументы и данные, а не тон. Учитывайте мнение обеих сторон, просчитывайте риски (допущения, зависимости, план B). Следуйте проверенным процессам и критериям, а не личной симпатии.

После события кажется, что «и так было ясно» — и мы переоцениваем предсказуемость прошлого.
На ретро: «Очевидно было, что интеграция сложная!» — хотя в рисках этого не было, а тесты не ловили. Память дорисовала причинность.
Ведите лог предположений до релиза (какие риски и ожидания были), на ретро сравнивайте с записью, а не с памятью. Фиксируйте решения и их основания (decision record), чтобы отличать «тогдашние знания» от «сегодняшней мудрости». Также не скрывайте своих сомнений - активно пишите в почту и в рабочие чаты. В дальнейшем когда все пойдет не так как планировалось - вам будет легче доказать, что конкретно вы это предвидели.
Читайте мою серию: Усталый Босс
Прошлые статьи:

Прочитал книгу Цель Э. Голдратта. Есть четкая корреляция с другой книгой «Проект Феникс». Обе книги написаны в жанре романа. В обоих есть патовая ситуация на заводах когда хуже некуда и фирмы на грани банкротства, но всегда появляется некий «гуру» который учит главного героя некой философии. За короткое время получается стабилизировать ситуацию и не только выйти из кризиса, но еще увеличить доход компании.
Ну и как же без параллельной линии связанной с личной жизнью героев. У обоих проблемы с женами , которые решаются ровно в тот момент , когда на работе наступает стабильность.
Ну а в целом рекомендую к прочтению всем кто мало мальски управляет: людьми, проектами, бюджетами, бизнесом -не важно. Теория ограничений (TOC) описанная в книгах - это база для менеджеров любого уровня
Читайте мою серию: Усталый Босс
Прошлые статьи:


