Agile 2.0 Где заканчивается перфекционизм и начинаются итерации

Generated by ChatGPT 5.2
На самом деле я задумал написать эту статью довольно давно и был уверен, что справлюсь с ней минут за двадцать. Тема казалась понятной, мысли — уже сформулированными. Но когда я сел писать, неожиданно выяснилось, что текст не складывается: аргументы расползались, формулировки не держались, а ощущение ясности быстро исчезло.
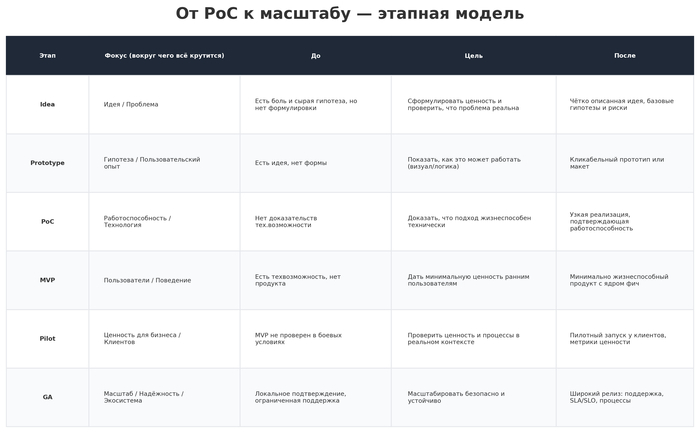
В итоге вместо этой статьи я написал две другие. Первая была посвящена стадиям развития проектов — от идеи до GA. Вторая — о эволюции Agile, объясняющая, откуда он взялся и почему, по всей видимости, он с нами теперь надолго. Эти тексты помогли мне навести порядок в базовых понятиях и выстроить контекст, который, как оказалось, был необходим.
Сейчас, когда эта база сформирована, я могу вернуться к изначальной теме. Но прежде важно объяснить, что именно стало отправной точкой для этой статьи и всей трилогии.
Я, по сути, типичный agile-менеджер. В каком-то смысле — евангелист. Я давно проникся этим подходом, много лет использую его в практике и вижу реальные результаты. Итерации, обратная связь, постепенное уточнение решений — всё это для меня не теория, а рабочие инструменты.
И именно поэтому на одном из недавних проектов я неожиданно столкнулся с жёстким сопротивлением. Моё руководство довольно прямо пушило меня назад. Моё желание «есть слона по частям» воспринималось как недостаток серьёзности подхода и вызывало предвзятое отношение.
Попытки двигаться итеративно регулярно наталкивались на скепсис. Черновик документации воспринимался как недодокументация, хотя по задумке это был всего лишь задел для дальнейшего обсуждения и уточнения. Попытка начать с эскиза или наброска воспринималась как нежелание «сделать нормально».
То же самое происходило и с разработкой. Я не мог начать работу над прототипом без заранее утверждённой, чёткой и «красивой» картинки финального решения. При этом мы живём во время, когда благодаря AI и современным инструментам разработка рабочего прототипа — это вопрос нескольких дней, а не месяцев.
В результате вместо движения и проверки гипотез мы снова и снова возвращались к обсуждениям того, как всё должно выглядеть в идеале.
Именно в этот момент вопрос перестал быть про Agile как методологию. Он стал вопросом о границе: где заканчивается стремление всё продумать заранее — и где начинается необходимость двигаться через итерации.
Иллюзия правильного решения

Generated by ChatGPT 5.2
Всегда ли выверенное решение оказывается правильным?
Принимая решения, мы всегда несем за плечами прошлый опыт — местами успешный, местами нет — и он напрямую влияет на то, какие решения мы считаем правильными.
Помимо этого, у нас есть текущее состояние «здесь и сейчас», а также прогноз и видение будущего, которое ещё не наступило и по определению неопределённо.
И вот именно вокруг этого будущего всё и вертится. Практически каждый человек — будь то менеджер, инженер или просто хороший человек — так или иначе выстраивает свою мотивацию, приоритеты и работу вокруг образа будущего. Мы принимаем решения не ради настоящего момента и не ради прошлого опыта, а ради того, каким мы хотим видеть результат впереди.
Но у этого подхода есть фундаментальный недостаток: будущее плохо поддаётся предсказанию.
Конечно, всем нам нравится думать и рассказывать, как мы интеллектуально всё просчитали, учли риски и сделали выводы. Это придаёт нам ореол рациональности и интеллектуальной зрелости. Почему-то в нашем мире умным чаще считается тот, кто выглядит способным предсказывать будущее.
Но на практике наши прогнозы почти никогда не сбываются на сто процентов. Это неизбежно приводит к разочарованию: менеджмент не получает ожидаемых результатов, проекты не достигают заявленных KPI.
Формально ответственность в таких случаях ложится на PM. Но по большому счёту виноватых здесь нет. Проблема не в людях, а в том, что далеко не все готовы — или хотят — мыслить вероятностями.
Во многих организациях до сих пор живо солдафонское отношение к планированию: «мужик сказал — мужик сделал». Неважно как, неважно какой ценой — хоть об стену разбейся, но уложись в срок и выполни обещанное. В такой картине мира неопределённости просто не существует.
В результате образ будущего, вокруг которого мы строим «правильное» решение, часто оказывается гораздо менее надёжным, чем нам кажется.
На основе этого набора мы не находим правильное решение, а формируем рабочую гипотезу. Причём таких гипотез, как правило, несколько.
Именно здесь возникает иллюзия. Мы начинаем искать не просто жизнеспособный вариант, а единственно верное решение, как будто оно объективно существует и может быть вычислено заранее.
Чем дольше мы находимся в этом поиске, тем сильнее ощущение контроля. Кажется, что ещё немного размышлений — и появится то самое решение, после которого не придётся ничего переделывать. На практике же неопределённость никуда не исчезает, а движение просто откладывается.
Именно здесь и становится видно, в чём состоит иллюзия: правильность не обнаруживается заранее — она формируется в процессе.
Итерации как способ получения знания

Generated by ChatGPT 5.2
Так что же нам делать в такой ситуации?
Пытаться сразу сделать всё хорошо и правильно — или всё-таки идти по итерациям?
Из моего опыта — пока вы размышляете о том, как сделать всё правильно, я успеваю накидать несколько прототипов. И как минимум один из них оказывается рабочим и начинает приносить пользу — пусть даже в таком, прототипном виде.
При этом совсем не факт, что тщательно продуманное решение в итоге взлетит. Его ведь недостаточно просто разработать. Его ещё нужно внедрить — фактически заставить пользователей начать с ним работать. А пользователи, как правило, самые упрямые участники процесса.
Здесь важно понимать ещё одну вещь: каждое решение — это ставка.
Когда мы пытаемся сразу сделать «идеально», мы фактически ставим всё на одно видение будущего. Если оно не срабатывает, цена ошибки оказывается высокой — и в деньгах, и во времени, и в доверии.
Итеративный подход снижает размер этой ставки. Мы не пытаемся угадать правильный ответ с первого раза. Мы делаем небольшой шаг, проверяем гипотезу, получаем знания и только потом принимаем следующее решение.
В этом смысле итерации — это не способ ускориться. Это способ дешевле ошибаться.
Самая дорогая ошибка — не та, которую мы совершили, а та, о которой мы узнали слишком поздно. Итерации сокращают это расстояние между предположением и реальностью.
Заключение

Generated by ChatGPT 5.2
Возможно, главный вопрос сегодня не в том, использовать ли итерации или нет. В какой-то момент они перестают быть выбором и становятся следствием того, как устроена реальность вокруг нас.
Гораздо важнее другое — пересмотреть само представление о том, что значит быть «умным» в сложных системах. Долгое время ум ассоциировался со способностью заранее увидеть правильный ответ, просчитать последствия и уверенно провести решение до конца. Такой образ хорошо работал в мире, где будущее было относительно стабильным и поддавалось прогнозированию.
Но по мере роста сложности этот образ всё чаще даёт сбой. Ум сегодня — это уже не способность безошибочно предсказывать будущее. Это способность достаточно рано понять, что ты ошибаешься, и иметь пространство, время и полномочия, чтобы с этим что-то сделать.
Ценность смещается с уверенных ответов к умению задавать правильные вопросы, с жёстких обещаний — к способности корректировать курс, с демонстрации контроля — к реальной работе с неопределённостью.
И, возможно, следующий шаг — это разговор уже не про методологии и фреймворки, а про культуру принятия решений. Про то, как мы договариваемся с будущим, зная, что оно всё равно нас переиграет.
Читайте мою серию: Усталый Босс
Прошлые статьи: