В этой статье познакомимся сDeep-Live-Cam - это инструмент для замены лицв реальном времени и создания видеодипфейков с использованием всего одного изображения.
Софт включает встроенную проверку на недопустимые материалы и поддерживает GPU ускорение для улучшенной производительности.
Также расскажу, как не париться с установкой и запустить Deep Live Cam в один клик.
Всё, что нам понадобится, чтобы завести Deep Live Cam - это веб-камера и видеокарта Nvidia или AMD с более чем 6-ью Гб видеопамяти.
P. S. Если вы используете смартфон как веб-камеру то, к сожалению, программа просто не будет распознавать устройство. Возможно, в будущем это пофиксят, было бы очень удобно!
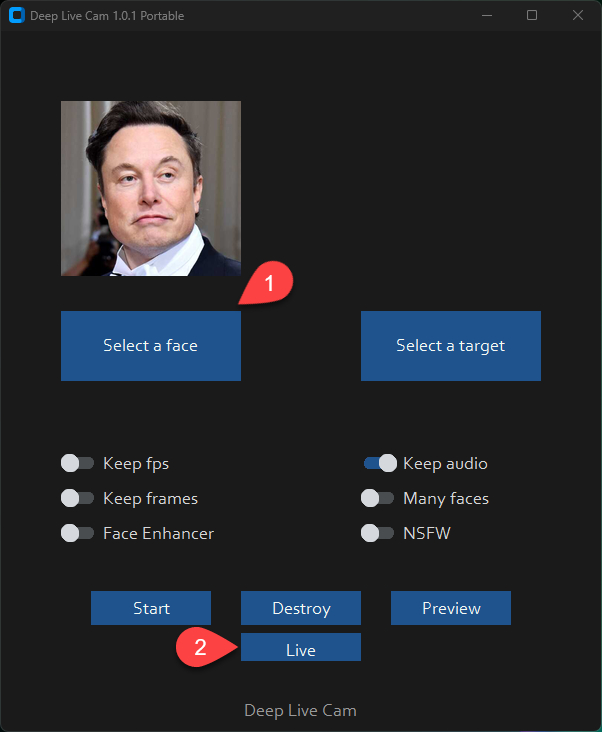
Интерфейс Deep Live Cam
Интерфейс Deep-Live-Cam интуитивно понятен и позволяет легко управлять основными функциями программы. Рассмотрим основные элементы интерфейса и их назначение.
Select a face - выбор исходного изображения с лицом, которое будет использовано для замены.
Live - включить дипфейк в реальном времени.
Preview - скрыть окно с превью видео.
По факту, это всё, что нужно для замены лица в реальном времени. Удивительно, что понадобится всего одна фотография!
Ещё я использовал Face Enhancer для апскейла лица на видео.
В одно мгновение я стал настоящим Томми Шелби!
Когда вы запускаете эту программу в первый раз, она загружает некоторые модели размером ~300 МБ. Так что проявите немножко терпения :3
Вот как это выглядит без апскейла:
Превращаемся в Папича:
Без апскейла и keep frames:
И тут мне пришла в голову идея превратиться в Шрека:
И с этим Deep Live Cam справляется отлично, главное подобрать хорошее исходное изображение.
Если хотите добавить превью в OBS, то просто добавьте захват окна и выберите Preview:
В заключение хочется сказать, что Deep Live Cam - крутая технология, которая открывает большое пространство для творчества, что может пригодиться блогерам и тем, кто создаёт контент.
Поэтому используйте ПО исключительно в позитивном ключе, придерживаясь этики и закона:
Не используйте лица людей без их явного согласия.
Избегайте применения для обмана или введения в заблуждение других лиц.
Воздержитесь от использования в коммерческих целях без соответствующих разрешений.
Не создавайте контент, порочащий репутацию или унижающий достоинство других людей.
Не применяйте технологию для создания фальшивых новостей или дезинформации.
Избегайте использования в целях политической пропаганды или манипуляции общественным мнением.
Не используйте для создания порнографического контента без согласия.
Воздержитесь от применения в ситуациях, где требуется подтверждение личности (например, при онлайн-экзаменах или собеседованиях).
Не используйте для обхода систем безопасности или аутентификации.
Избегайте создания контента, нарушающего авторские права или интеллектуальную собственность.
Помните, что ответственность за его использование лежит на пользователе. Применяйте технологию этично, уважая права и достоинство других людей.
Чтобы установить Deep Live Cam, достаточно скачать нашу портативную версию с установкой в один клик.
Перед установкой отключите антивирус, он ругается на самораспаковывающийся архив. Если переживаете, то скачивайте 7z-архив, который нужно просто разархивировать в любое удобное место
Подписывайтесь на 👾Нейро-Софт, канал с портативными версиями ваших любимых нейросетей!
Нейросеть проекта Dadabots научилась генерировать музыку в стиле блэк-метал. Послушать экспериментальный альбом, записанный системой искусственного интеллекта можно здесь.
Проектом Dadabots руководят исследователь Кристофер Джеймс Карр и музыкальный продюссер Зака Зуковски. Для создания альбома «Сoditany of Timeness» они использовали видоизмененную нейросеть SampleRNN, в основе которой лежит LSTM-нейросеть — разновидность архитектуры рекуррентных нейронных сетей. Разработчики обучали алгоритм с помощью альбома Diotima нью-йоркской группы Krallice, который включает в себя семь треков общей длительностью более часа. Все композиции были разбиты на восьмисекундные отрывки: после прослушивания фрагмента программа должна была «предположить», как будет звучать его продолжение. Если она угадывала верно, то вес определенных нейронов увеличивался, а работа системы совершенствовалась.
Друзья, всем привет, в прошлой статье Fooocus v2 — бесплатный Midjourney у вас на компьютере, вы познакомились с рисующей нейросетью которая вполне способна заменить Midjourney, узнали как её установить, как пользоваться, за что отвечают все настройки и как работают режимы, как писать запросы, чтобы нейросеть вас понимала.
Из этой части вы узнаете как с помощью нейросети Fooocus можно дорисовать любое изображение выйдя за его границы, изменить любую деталь на изображении, узнаете как добавить на свою генерацию текст, наложить свое лицо или как создать изображение по вашему референсу. Сегодня я расскажу про раздел Input Image.
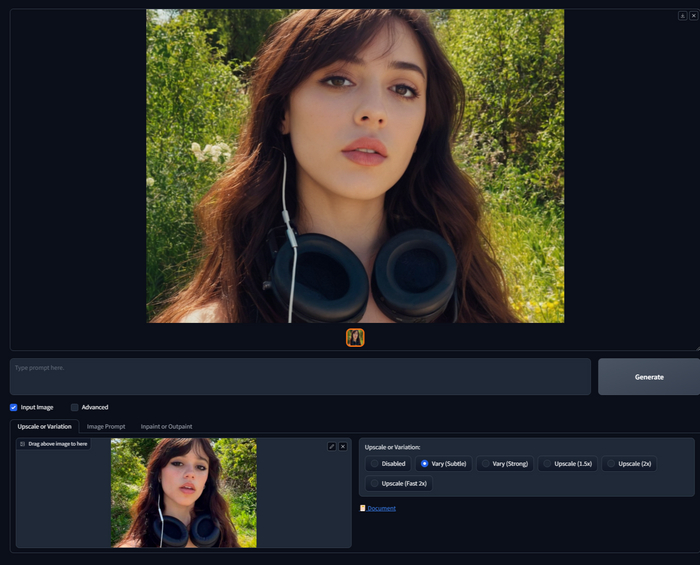
Ставим галочку на Input Image и попадаем в мир роскоши и комфорта, на вкладку где вы можете либо создать вариации уже существующего изображения, либо увеличить изображение. Это может быть как то, что вы сгенерировали, так и ваша фотография. Чтобы что-то заработало нам надо загрузить изображение, я для примера возьму фотографию Джены Ортеги, которая играла Уенсдей в одноименном сериале от Нетфликс.
Variation - Вариации
Допустим нам нельзя использовать фотографию Джены, например в коммерческой публикации, но она идеально соответствует нашей задаче, для рекламы наушников например. Выбираем в таком случае Vary (Subtle), чтобы получить то же самое, что изображенона загруженном изображении, в нашем случае девушку в лесу в наушниках, нам даже запрос писать не нужно, нейросеть сама поймет что нужно сделать. Если будем использовать Vary (Strong), то такого сходства с загруженным изображением уже не получим, оно будет просто "на тему", режим Vary (Strong) лучше работает для того, чтобы сделать вариацию генерации, где используется запрос.
Вариации отличный и простой способ получить собственную версию любого изображения, но что делать, если изображение нужно использовать, например для печати, как увеличить его разрешение?
A picture of a beautiful girl with headphones around her neck walking in the woods
В положении Upscale происходит увеличение изображения, можно выбрать увеличение в 1.5 или 2 раза, есть еще 2x Fast, но он делает ощутимо хуже. Важно понимать, что новые детали таким образом не появятся, изображение просто будет увеличено с некоторым количеством едва заметных артефактов. Если необходимо вы можете несколько раз по кругу закидывать полученное изображение в апскейл, для этого просто перетащите его сверху в форму ниже. А мы переходим дальше, к самому мощному инструменту.
Вкладка Image Prompt
close-up female portrait. road, retrowave colors
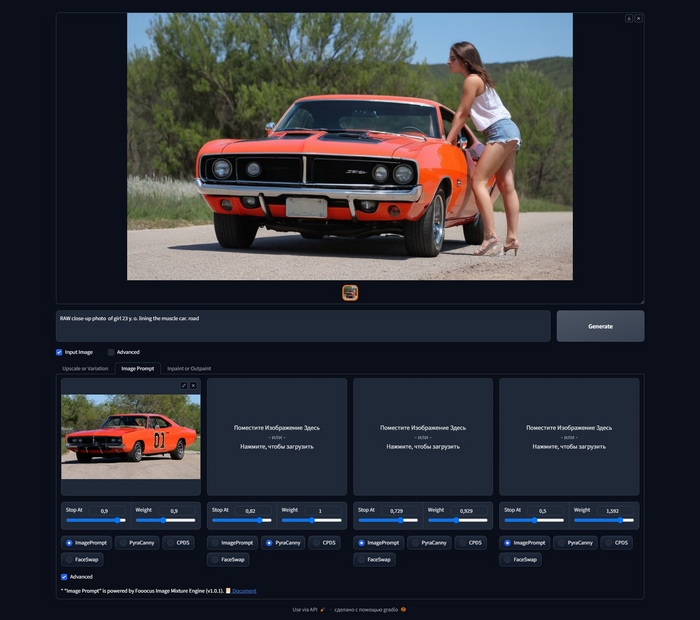
Вкладка Image Prompt позволяет вам использовать в качестве подсказки изображение, и сделать это большим количеством способов, используя различные модели ControlNet. Комбинируя разные способы вы можете получить совершенно любое изображение. Вот в примере выше я взял фотку Джены, текст на прозрачном фоне, пейзажик и ретро фотографию жигулей. С первой картинки я получил надпись, со второй позу, расположение и эмоцию девушки, с третьей часть фона и с четвертой часть палитры. Невероятный результат, по очень простому запросу. Ниже я расскажу как работает каждый из режимов, чтобы увидеть эти дополнительные настройки нажмите на галочку Advanced.
ImagePrompt - Стиль и содержимое
Режим Image Prompt он же СontrolNet IP adapter создан для того, чтобы вы могли использовать в качестве запроса изображение, при том забирает с референсного изображения Image Prompt не только стиль, но и содержимое, т.е. улавливает контекст. Покажу на простом примере. Загружаем фотографию ретро автомобиля, пишем простой запрос RAW close-up photo of girl 23 y. o. lining the muscle car. road, я не пишу в запросе ни модель машины ни цвет, но получаю фотографию девушки рядом с очень похожей машиной, на ту что я загрузил в качестве референса.
RAW close-up photo of girl 23 y. o. lining the muscle car. road
Таким же образом можно взять стиль с любого изображения. Еще пример: я нашел классную картинку с разрушенным городом на PromptHero, это сайт где можно найти интересные примеры и запросы для нейросетей. Картинка атмосферная, мне нравится, но она сделана в миджорни и её запрос мне не поможет. К тому же мне нужна такая же только с перламутровыми пуговицами горизонтальная и с плюшевым медведем. Задачка кажется сложной.
Чтобы получить похожую картинку только по запросу придется постараться. Можно поступить проще, загружаю это изображение в Image Prompt, пишу запрос Photo of a gloomy ruined city, close-up of a teddy bear, и получаю сразу же отличный результат, ровно такой, каким я себе представлял. Драматичная темная картинка с плюшевым мишкой который героически идет к светящемуся зданию, сразу хочется узнать что будет дальше.
Photo of a gloomy ruined city, close-up of a teddy bear
Но что делать, если результат не устраивает, всегда можно подкрутить Stop At, он отвечает за то, когда нейросеть перестанет смотреть на то изображение которое вы загрузили. По умолчанию стоит на 0.5. т.е. половину всей генерации фокус придерживается загруженного изображения, а потом уже генерирует как хочет. Часто бывает полезно увеличить или наоборот уменьшить это значение.
Увеличивать стоит если вы хотите хорошо перенести визуальный стиль. А уменьшить, если вам достаточно лишь общей композиции, так вы дадите нейросети больше свободы. Кроме того можно увеличить влияние изображения, с помощью ползунка Weight, чем больше вес, тем сильнее влияние на генерацию, выше интенсивность влияния, но одновременно с этим уменьшается и креативность нейросети, поэтому находите баланс.
Когда использовать Image Prompt? Когда надо скопировать стиль, атмосферу, освещение, а при высоком Weight и композицию изображения.
PyraCanny - Контуры
Canny создает так называемую карту, того, что изображено на картинке которую вы загружаете. Это карта состоит только из ключевых контуров, на ней отсутствует информация о цвете или стиле. Эти контуры лягут в основу вашей будущей генерации.
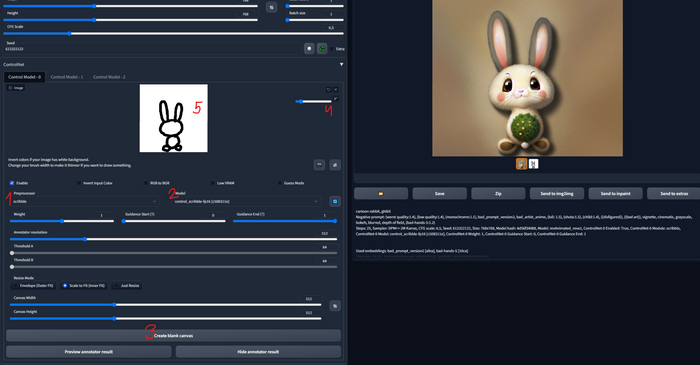
Например я сгенерировал милого кролика, но мне хочется сделать кролика в другом стиле, при этом я хочу полностью сохранить его пропорции. Загружаю кролика в Image Prompt, выбираю PyraCanny, ставлю Stop At на 0.9 или даже на 1, чтобы сохранить пропорции до конца генерации. И просто по промпту Bunny начинаю переключать различные встроенные в фокус стили, пока не найду то, что мне нравится. Про стили подробно рассказывал в первой части. Вот такой получается результат у меня.
Bunny + стили
Очень полезный инструмент, чтобы сделать вариации персонажей, иконок в разных стилях. Кстати вам не обязательно загружать готовое изображение, вы можете загрузить и контурный набросок сделанный от руки и Фокус попытается сгенерировать по нему изображение.
Еще PyraCanny отлично подходит чтобы стилизовать текст. Все что вам нужно, это сделать PNG изображение текста, на прозрачном фоне, для этого подойдет любой редактор, онлайн могу посоветовать photopea.com он удобный и бесплатный. Я предпочитаю делать обводку тексту, так обычно интереснее стилизуется. Чтобы текст был читаемым и не прыгал стоит поставить Stop At на 1 и Weight на 1.2, а иногда и выше, если текст искажается или недостаточно виден.
Когда использовать PyraCanny? Когда надо скопировать содержимое изображения, персонажа, архитектуру, черты лица или композицию, или добавить текст.
CPDS - Глубина и контрастность
confused Keanu Reeves as John Wick in the desert, holding a gun
CPDS создает карту на основе резкости и контрастности загруженного изображения. После обесцвечивая изображения, остается только информация о силуэте, очертаниях и резкости и глубине. Это позволяет перенести в вашу генерацию любую сложную сцену или позу, не ограничиваясь при этом строгими контурами как это делает Canny.
Для примера я взял знаменитую сцену с Траволтой из фильма Криминальное чтиво и воссоздал с участием других персонажей: Гомера Симпсона, Гэндальфа, Джона Уика, Дарта Вейдера и еще нескольких.
Получилось отлично, а главное достаточно просто, запросы были в духе confused Homer Simpson.
Когда использовать CPDS? Когда нужно перенести силуэты и глубину, воссоздать сложные сцены, позы, глубину в пространстве.
FaceSwap - Замена лица
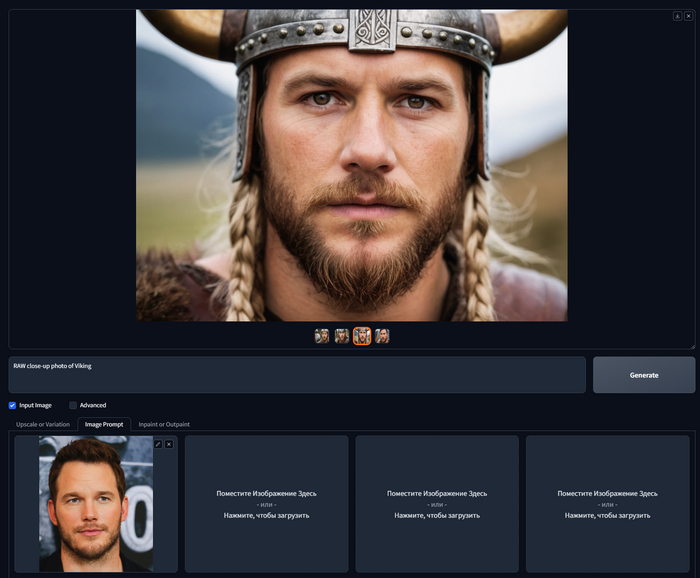
Вот мы добрались и до единственной ложки дегтя, то, что разработчик называет FaceSwap, на самом деле никакой не FaceSwap, а просто IP Adapter, как и Image Prompt, но обученный на лицах, он их вырезает и пытается встроить в генерацию. Но, честно говоря, это работает плохо. Такое ощущение, что пьяный друг кому-то рассказал как вы выглядите, и генерация это результат по мотивам такого описания. Определенно есть какое-то сходство, но есть и различие , которое пугает эффектом зловещей долины. Как я не крутил настройки так и не смог заставить этот режим работать хорошо. Разве узнаете вы на этой фотке Криса Пратта, Звездного лорда из Стражей галактики? Я нет.
RAW close-up photo of Viking
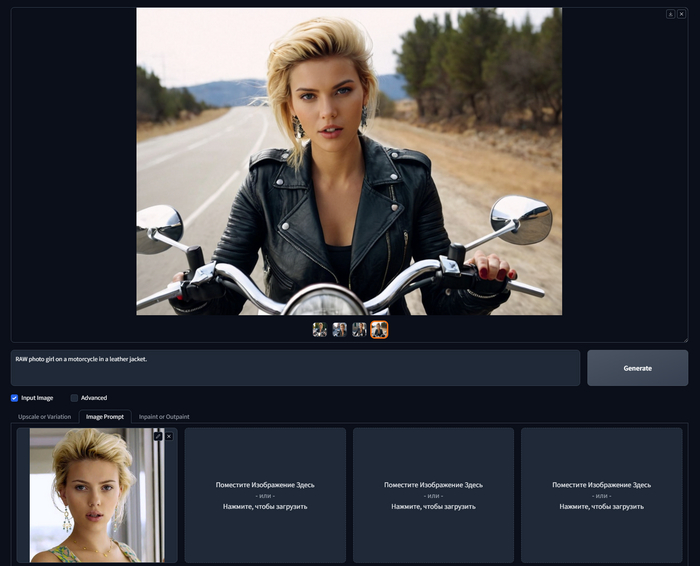
Хотел бы я сказать, что с женщинами получается лучше, но нет, вместо Скарлетт Йоханссон на мотоцикле, у меня получается её троюродная сестра, видимо.
RAW photo girl on a motorcycle in a leather jacket
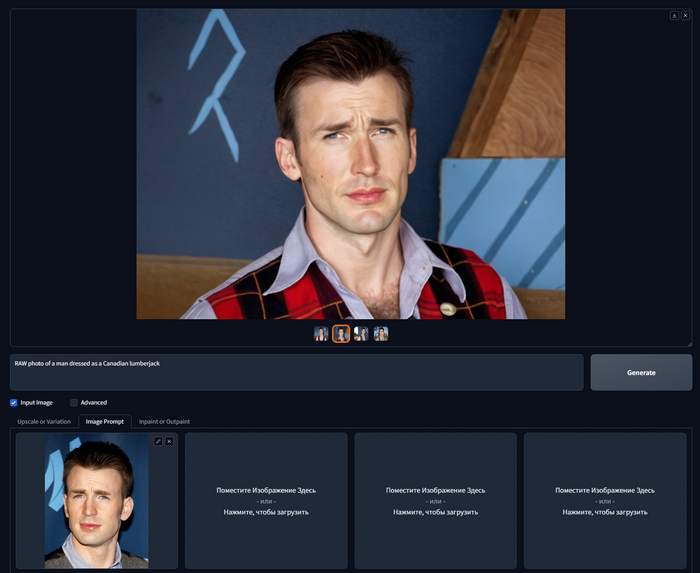
Если вы думаете что получится просто поднять Weight, то и тут вас ждет разочарование, если его поднять, то композиция, ракурс и цвета будет наследоваться с загруженного изображения, а то что вы пишите в запросе практически не будет учитываться. Для примера я загрузил фотку Криса Эванса, и выкрутил вес до 1.4, да так лицо действительно чуть больше похоже, это уже не родственник, а конкурс двойников. Но теперь все время пролезает кусок фона с референса, а ракурс лица невозможно изменить.
RAW photo of a man dressed as a Canadian lumberjack
Настоящий же FaceSwap очень аккуратно и тщательно смешивает черты лица с оригинала с загруженным лицом и практически всегда дает отличный результат, я об этом рассказывал в статьеСтань героем мемов! Делаем гифки со своим лицом с помощью нейросетей, посмотрите, очень интересная.
Я не могу назвать реализацию замены лиц в фокусе действительно работающей. Будем надеяться что в будущем разработчики либо улучшат этот редим, либо сделают тот классический FaceSwap который мы знаем по другим приложениям.
Когда использовать FaceSwap? Когда вы хотите чтобы у всех ваших персонажей было похожее лицо или типаж, либо готовите базовую картинку для замены лица в другом приложении, например в ReActor.
Различные комбинации
Самое классное, что вы можете комбинировать возможности Image Prompt как угодно, загружайте разные изображения, добавляйте текст, стили, и конечно управляйте запросом. Вот еще несколько классных примеров, которые были бы сложно получить только по текстовому описанию.
anime character in a cloud of fire, super strength
Close-up portrait of a girl on road, foggy, fireflies
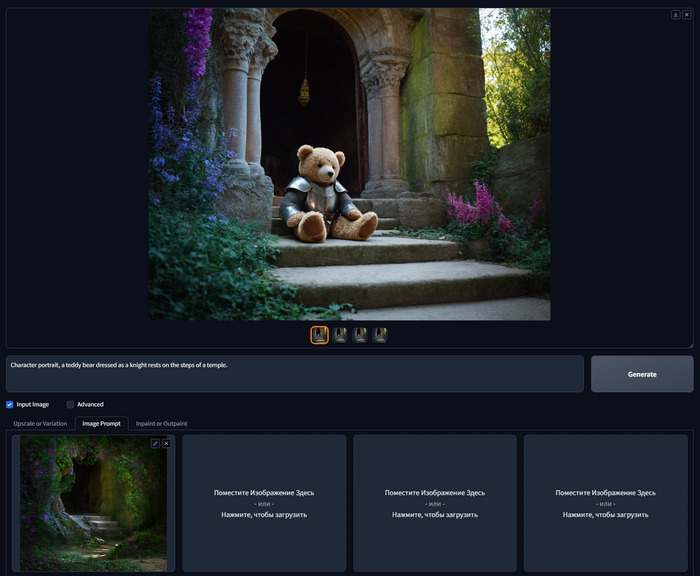
Character portrait, a teddy bear dressed as a knight rests on the steps of a temple.
Специально для моих подписчиков на Бусти я собрал пак из 1 800 необычных и интересных изображений - референсов, для использования в Image Prompt. В этом материале многие изображения как раз оттуда. Теперь добавить необычный эффект, сделать интересный фон или стиль можно в пару кликов и без сложных запросов. Подпишитесь на Бусти и вы, там много полезных материалов, записи обучающих стримов и доступ в наш закрытый чат. Только поддержка подписчиков позволяет мне писать такие подробные гайды и инструкции для вас друзья. А мы двигаемся к двум оставшимся, но не менее крутым функциям, впереди Inpaint и Outpaint.
Вкладка Inpaint or Outpaint
Конечно Свидетель из Фрязино уже был на этом фото c Папой Франциском, когда я его нашел, сгенерировать его не получится, но на этом примере я могу показать как можно изменить реальное изображение, прежде чем мы приступим к аутпеинтингу.
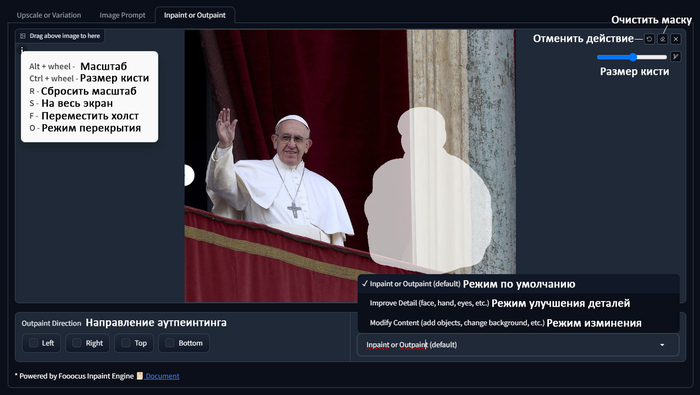
Inpaint - Изменяем изображение
Шпаргалка по быстрым клавишам и основным функциям
Как часто бывает, что на хорошей фотографии есть что-то, чего там быть не должно, раньше исправить такое фото было сложно. Теперь же есть инпеинтинг, простая механика - закрашиваем то, что нам не нравится маской, пишем что хотим вместо того, что под маской и получаем отличный результат. При том использовать запрос не обязательно. У инпеинтинга есть три режима:
Inpaint or Outpaint (default) - режим включенный по умолчанию, он же используется на аутпеинтинга. Подходит в целом для любой задачи, но разрешение в этом режиме будет ниже чем в двух других.
Improve Detail (face, hand, eyes, etc.) - режим улучшения деталей, отлично подходит для улучшения детализации лица, рук, глаз или других объектов.
Modify Content (add objects, change background, etc.) - режим изменения, в этом режиме удобно изменять или добавлять, то чего на изображении не было.
В режимах Improve и Modify появляется дополнительное поле, в котором можно указать конкретные изменения, это сделано чтобы вам не пришлось менять основной запрос, а потом вспоминать что там было.
Например, если мы хотим избавиться от персонажа на фото, то просто запустим генерацию с пустым запросом, либо с описанием той поверхности которая находится рядом, например стена или природа. Точно так же мы можем заменить персонажа на любого другого, достаточно лишь описать его. Конечно если делать это так же грубо как я на этих примерах, то будут заметны артефакты. Но если у вас есть тачпад, то вы сможете очень аккуратно нарисовать маску.
Но, этим не ограничиваются возможности инпеинтинга, еще вы можете: заменить фон, поменять одежду или прическу, улучшить лицо, добавить то, чего не хватает, удалить то что есть, возможности ограничиваются только вашей фантазией. На мой взгляд инпеинтинг самая мощная механика в работе с изображениями, а в фокусе она к тому же максимально удобно реализована.
Outpaint - Расширяем изображение
Атупеинтинг позволяет выйти за границы изображения, работает он очень просто. Вам достаточно выбрать сторону, в которую надо расширить изображение, влево, вправо, вверх, или вниз, вы конечно можете поставить сразу все 4 галочки, но так качество будет хуже, лучше делать одну сторону за раз. Вы можете как указывать запрос, так и нет. Допустимо немного изменять запрос между итерациями аутпеинтинга, чтобы добиться желаемого результата.
Вы можно делать аутпеинтинг много раз подряд, перетягивая сгенерированную картинку вниз, но важно помнить что каждый раз разрешение изображения становится больше и в какой-то момент у вас просто не хватит видеопамяти.
Аутпеинтинг прекрасная механика которая не только позволяет изменить размер кадра и соотношение сторон, заглядывая за границу несуществующего, но и отличный инструмент для создания больших детализированных изображений. Как это, его разрешение 4674х2772, но для вашего удобства я превратил его в видео. Есть конечно косячки на склейках, но их можно убрать множеством других способов.
Друзья, на этом мы закончили изучать возможности Input Image в Фокусе, поздравляю вас! Теперь вы знаете как делать вариации, увеличивать изображения или генерации, как использовать вкладку Image Prompt и все виды ControlNet, чтобы получить уникальное изображение созданное по вашему референсу, содержащее текст или даже похожее на вас. И конечно же вы теперь сможете изменить что-то в уже существующем изображении с помощью инпеинтинга или заглянуть за границы изображения с помощью аутпеинтинга.
Cinematic still of cat holding shopping bag full of vegetables with paws, shopping with smile in a market
Делитесь тем что у вас получается в нашем чате нейро-энтузиастов и увидимся на стримах, ближайший, уже 28 ноября в 20:00 на Бусти, вход как и всегда свободный, подпишитесь чтобы не пропустить начало. Разберем Фокус по косточкам, отвечу на все вопросы.
А еще я рассказываю больше о нейросетях у себя на YouTube, в телеграм и на Бусти. Буду рад вашей подписке и поддержке. Всех обнял.
Американские разработчики создали алгоритм, способный оживлять фигуры людей на двумерных изображениях. Он создает для нарисованного человека трехмерную модель, а затем воспроизводит анимацию с выбегающей из картины моделью.
Созданная исследователями система представляет собой связку из нескольких разработанных ранее алгоритмов и собственного кода. Изначально она принимает двумерное изображение и обрабатывает его с помощью нейросети Mask R-CNN. На этом этапе алгоритм распознает на изображении область с человеком и отделяет ее от фона. Затем еще один разработанный ранее алгоритм превращает область изображения с человеком в двумерную модель скелета, состоящую из прямых сегментов и их соединений. После этого еще один алгоритм создает реалистичный фон в областях кадра, изначально закрытых человеком.
TLDR: Че тут происходит вообще? Я тут делюсь своим опытом по работе с нейронками. Если тебе эта тема интересна, но ты только начал вникать загляни ко мне в профиль или в конец статьи, там есть полезные ссылки. Сейчас это может быть слишком сложным для тебя.
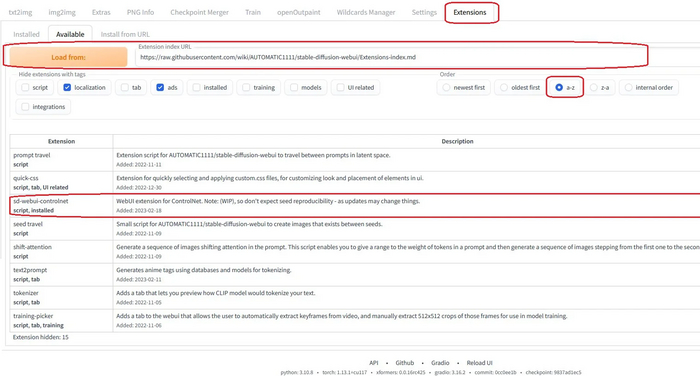
Сегодня покажу как установить, настроить и начать пользоваться одним из самых лучших расширений для стабильной диффузии. Способов его применения огромное множество, но все по порядку.
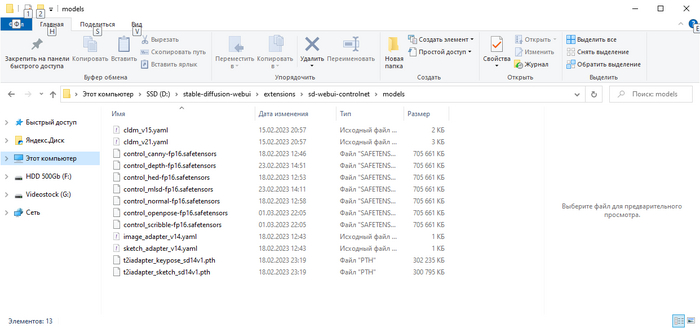
Для начала становим расширение. Запустите автоматик, зайдите Extensions - Available - Нажмите кнопку Load from. Загрузятся расширения доступные к установке, найдите sd-webui-controlnet и нажмите Install. С расширением всё.
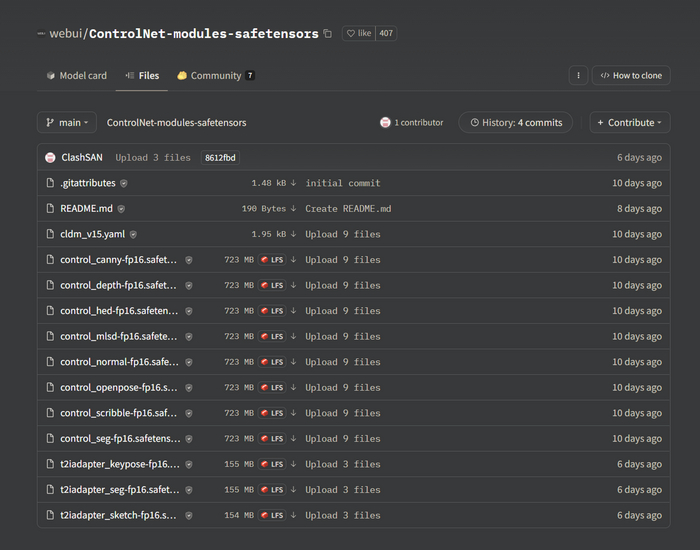
Теперь нужно скачать модели и я походу объясню какая и зачем.
Модели. Есть полные версии, а так же их уменьшенные версии, заметной разницы в качестве я не обнаружил и пользуюсь уменьшенными так как SSD не резиновый.
Можете скачать все со словом control в начале. Я в основном использую 3, это depth, openpose, hed, но так как весят не много и удобно иметь под рукой, имею все.
Препроцессоры:
У всех у них одна задача, получить тот или иной контур объекта, поза, линии, силуэт чтобы затем вы могли изменить картинку не отходя от этого самого контура, позы, силуэта. Так вот теперь вы можете забрать с нее только композицию и нарисовать по ней все что угодно. В разумных пределах конечно.
canny - обводит края тонкой линией, подходит для изображений с резкими краями, например аниме
hed - толстой размазанной, смягчая края
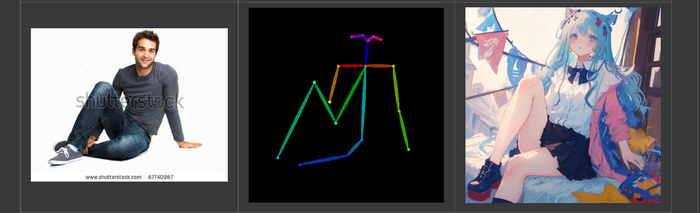
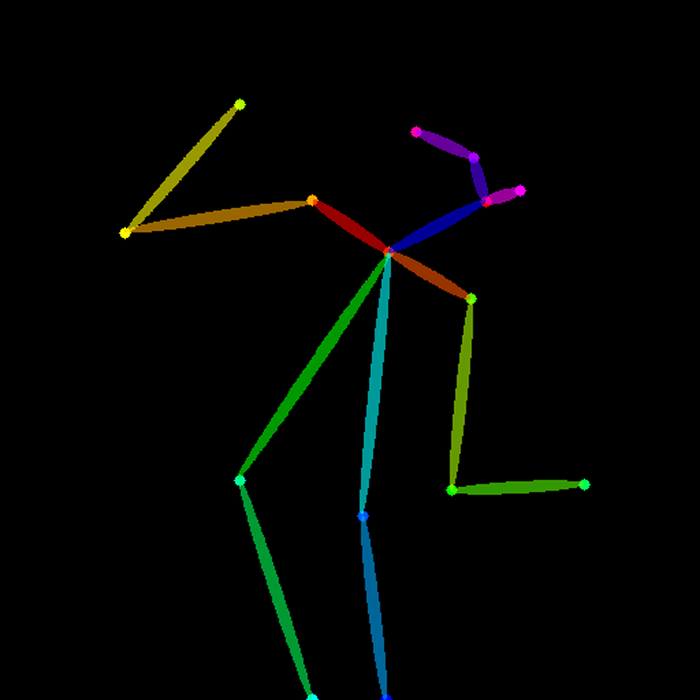
openpose - берет только позу людей кадре, никаких краёв, а значит можно менять например фигуру. Для всего
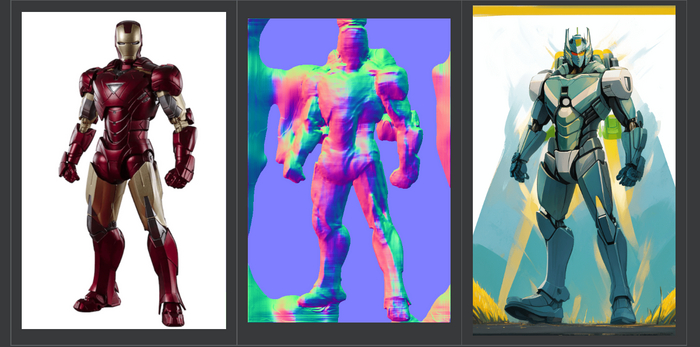
depth - маска глубины чем ближе к камере тем белее, для всего когда нужно получить объем сцены чтобы его сохранить
normal - карта объёма
scribble - создает каракули и может создавать что-то из каракуль
mlsd - работает с ровными прямыми линиями, хорош с помещениями, чтобы передать их геометрию ну и потом перерисовать конечно.
seg- делит картинку на сегменты, затем пытается в тех же сегментах нарисовать те же объекты которые могут относиться к этому сегменту. Использовал я его примерно 0 раз, но кто знает…
После скачивания моделей поместите их по пути: ваша_папка_с_автоматиком\extensions\sd-webui-controlnet\models
После того как все сделали, полностью перезапустите стабильную диффузию.
Запускаем снова и смотрим вниз. Появилась вкладка ControlNet. Давайте сгенерируем что нибудь и сразу возьмем его позу для генерации чего-то другого.
Конечно же не обязательно генерировать. Вы можете поместить в окно контролнета любую фотографию которую хотите взять за основу.
Ставлю галку на Enable, чтобы активировать расширение. Выбираю препроцесср Openpose модель тоже openpose.
Еще пример изображения в той же позе:
А теперь давайте разберемся с настройками. По крайней мере на дату выхода статьи , в мире нейросетей все очень быстро меняется.
Enable - включить
Invert Input Color - инвертировать изображение. Бывает что вам понадобится черный контур на белом фоне, а ваша картинка имеет обратные цвета. Галка поможет
RGB to BGR - сменить компоновку пикселей. Видимо на матрицах BGR даст результат лучше, но я с такими дело не имел
Low VRAM - уменьшает требование к видеопамяти
Guess Mode - удалите промпт, контрол сам попробует понять что на картинке и повторить по своему. По мне фигня какая-то (на текущую дату)
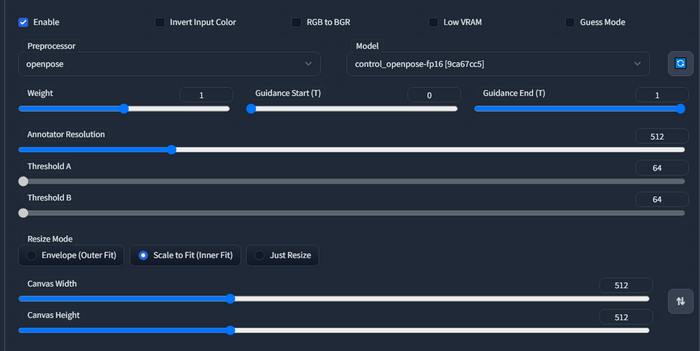
Preprocessor - обработчик изображения которое вы скормили расширению. То есть openpose превращает изображение в позу. Из примера выше она выглядит вот так
Model - берет то что получила от препроцессора и обрабатывает.
Weight - как сильно контролнет будет влиять на композицию
Guidance Start (T) - когда вмешаться
Guidance End (T) - когда перестать
Диффузия получает изображение из шума, делает она это степами\шагами. Вы можете выбрать когда контрол нету влиять на очистку шума, а когда нет. Это уже чуть более продвинутая техника. Расскажу о ней в другой раз. В вкратце, если поставить 0 и 0.5 контрол будет контролировать общий силуэт до половины генераций, а дальше полностью отпустит вожжи и в дело вступит только диффузия.
Annotator Resolution - разрешение считывания, ставьте по самой короткой стороне вашей картинки, качество работы препроцессора должно стать лучше.
Threshold A\B - предназначены для очистки “мусора” на таких препроцессорах как canny например. Если у вас считывает что что вы не хотели бы или наоборот, поиграйте этими ползунками.
Оба максимум \ Оба минимум
С позами понятно. А остальные что?
Теперь вам не нужно долго добиваться от диффузии нужной вам композиции. Вы можете использовать любую уже созданную, хоть вами хоть кем то другим. Это только часть возможностей данного расширения, об остальных расскажу в других статьях.
Выбирайте препроцессор при принципу что вам важно взять с изображения? Только позу? Openpose. Силуэт? Depth. Нужно сохранить практически все грани, но переделать в другой стиль? Canny, hed.
На прощание нарисуем кролика:
мой промпт: cartoon rabbit, ghibli
Поделиться результатом или задать вопрос вы можете в нашем комьюнити нейроэнтузиастов.
Больше гайдов на моем канале, подписывайтесь чтобы не пропустить. Так же вы можете заказать у меня работу если не может что-то сделать сами, ну или не хотите)
Вокруг темы дипфейков множество слухов и домыслов. Мы сами стараемся не попасть впросак, когда комментируем для журналистов эту тему. Например. Можно ли подделать голос в телефонном разговоре, то есть налету? (пока нет) Увеличивается ли число мошенничеств с дипфейками? (Достаточной статистики нет, если неаккуратно оценивать ситуацию, можно тысячи процентов насчитать, всё ж пока исчисляется «от плинтуса»). Можно ли создать дипфейк дендрофекальным способом, работая только с тем, что есть в открытом доступе?
А вот тут надо проверять, потому что однозначного ответа без дополнительных «но» нет. В качестве начальных условий поставил такие: можно ли сделать качественный дипфейк (видео и аудио), не особо вникая в вопрос? Результаты под катом.
А еще бонусом, на основе полученных результатов, – разобрал ролик под названием «10 лучших Дипфейк видео». На их примере предлагаю и вам поупражняться в поиске признаков подделки.
Disclaimer! Понятно, что актуальность этой статьи будет утрачиваться очень быстро. Поэтому не стесняйтесь делиться в комментах ссылками на новые инструменты и сервисы. Ещё заранее прошу прощения за качество некоторых гифок. Пост изначально создавался для Хабра, а у него есть ограничение на размер картинок. Поэтому пришлось в некоторых гифках ухудшить качество.
Актуальность
Кто-то радуется развитию технологий, а у меня взгляд с другой стороны – для «ибэшников» это риски. Массового применения дипфейков в корпоративном секторе, к счастью, пока не видно. Но риски точечных атак очень вероятны.
Вот несколько примеров использования дипфейков для обмана и мошенничества.
Раз
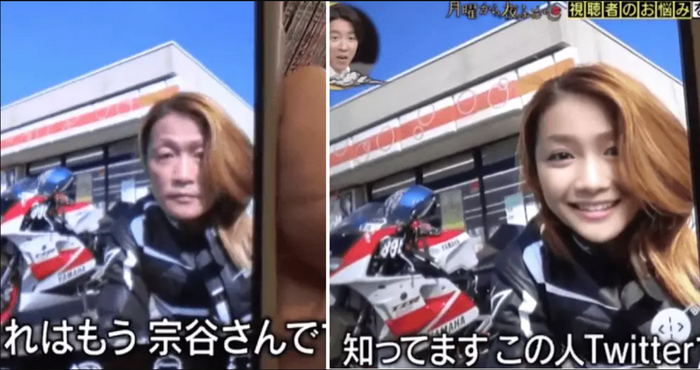
Начнём с безобидного. Популярная японская байкерша-блогер оказалась 50-летним мужчиной — он притворялся девушкой с помощью фильтров FaceApp. Обман раскрылся случайно: подписчики увидели отражение в боковом зеркале мотоцикла на одном из снимков, где вместо молодой девушки было лицо взрослого мужчины. А до этого их смутила волосатая мужская рука на фото.
Цзунгу (так на самом деле зовут блогера) рассказал журналистам, что для перевоплощения использовал фильтры приложения FaceApp: помимо настроек «красоты», они позволяют поменять гендер и возраст на фото.
По его словам, он просто хотел почувствовать себя интернет-знаменитостью, но решил, что в сети все хотят видеть «красивую девушку, а не пожилого дядю».
Два
В марте 2019 управляющий директор британской энергетической компании был ограблен на €220 000 (около $240 000). Он отправил эти деньги фирме-поставщику из Венгрии, потому что его босс, глава материнской фирмы в Германии, несколько раз подтвердил ему такую инструкцию. Но на самом деле какой-то хитрый злоумышленник просто использовал софт с AI-технологиями, чтобы в режиме реального времени заменять лицо и голос руководителя, и требовать, чтобы тот заплатил ему в течение часа.
Сообщение исходило с адреса босса в Германии, в подтверждение британскому директору был направлен e-mail с контактами. Предположить, что что-то идёт не так, можно было разве что по требованию босса провести всю сделку как можно быстрее, но это далеко не первый аврал, который случался в их бизнесе.
Три
Китай. Мошенники покупали на чёрном рынке фотографии людей в высоком разрешении и их персональные данные ($5-38 за комплект). Покупали «специально подготовленные» смартфоны ($250), которые умели имитировать работу фронтальной камеры, на самом деле адресату (госведомству) передавалось сгенерированное дипфейк-видео.
Схема позволила мужчинам создавать от лица ненастоящих людей компании-пустышки и выдавать своим клиентам поддельные налоговые накладные. Таким образом им удалось за два года украсть $76,2 млн.
Четыре
Индия. С мужчинами в социальных сетях связываются женщины с фейковых аккаунтов, а затем звонят по видео, общаются с пользователем и производят действия сексуального характера. После такого разговора мужчины получают угрозы разослать записанное видео знакомым и родственникам жертвы, если тот не перечислит определённую сумму на счёт шантажистов. И если в такой схеме раньше участвовали настоящие женщины, то сейчас мошенники используют deepfake, а также технологию преобразования текста в звук, которая помогает в создании речи фальшивых девушек на видео. Некоторые из жертв мошенников перечисляют крупные суммы денег, которые доходят до миллионов рупий, а некоторые не ведутся на провокации.
Это далеко не все новости. Регулярно всплывает что-то ещё. То исследование выйдет, что тесты банков для проверки личности «чрезвычайно уязвимы» для deepfake-атак. То банки просят ЦБ провести эксперимент по использованию видеозвонков для удалённого открытия счетов новым клиентам.
Тем не менее можно сделать вывод, что на данный момент качественные дипфейки используются чаще как элемент большой сложной кампании. Простыми же, которые легко тиражировать (например, deepnude), бьют по площадям.
Подделка видео
Начнем с теории. В этом вопросе я опирался на работу «Deepfakes Generation and Detection: State-of-the-art, open challenges, countermeasures, and way forward. В ней авторы выделяют 5 техник:
Face-swapping. «Пересадка» лиц. Чаще всего дипфейками именуют ролики, созданные с помощью этой техники.
Lip syncing. Буквально «синхронизация губ». Здесь пересадок не происходит. Губы «жертвы» на видео двигаются синхронно с подменённой аудиодорожкой. Как дубляж.
Puppet master. Буквально «кукловод». В идеале, полная передача характеристик лица «донора» на лицо «жертвы». Как делали «людей» из племени Нави в Аватаре Джеймса Кэмерона.
Face Synthesis and Attribute Editing. Буквально «синтез лиц и редактирование атрибутов». В отличие от Puppet Master, здесь идёт работа с одним лицом. Его можно состарить, омолодить, изменить цвет, причёску, дорисовать очки, шляпу и т.п. Из относительно свежих ярких представителей я бы сюда отнёс фоторедактор Lensa, хотя понятней иллюстрирует идею Snapchat со своими фильтрами.
Audiodeepfakes. Авторы работы к этому разделу отнесли всё, что связано с аудио, хотя лично я бы разделил на 3 категории: искажение голоса, синтезаторы, клонировщики.
Также все инструменты можно разделить на 2 большие группы: те, которые осуществляют подмену в режиме реального времени и те, кто генерирует результат постфактум.
Проще познакомиться с плюсами и минусами каждой техники на конкретных примерах. Разберем несколько приложений/сервисов. Какие-то пробежим, на некоторых остановимся подробнее.
MSQRD
Несмотря на множество аналогичных по идее приложений (например, Reface), начать хочется с MSQRD, потому что на моей памяти, это первая программа для создания дипфейков, которая появилась в публичном доступе. Белорусский стартап, который за 1 миллиард долларов был куплен потом ТемиКогоВРоссииНельзяБезЗвёздочкиНаписать.
В примере ниже MSQRD используетFace-swapping\Face Synthesis and Attribute Editing.
Плюсы подобных инструментов:
Низкий порог вхождения по знаниям. Не нужно дополнительно штудировать мануалы.
Низкий порог вхождения по технике. Обработка происходит на стороне сервиса.
Низкий порог вхождения по затраченному времени. Результат получаем практически мгновенно.
Бесплатно.
Минусы:
Нет свободы воли. Перечень сцен и героев для подмены ограничен создателями приложения.
Цифровой след. Регистрация, водяные знаки и т.п.
DeepFaceLab
Пожалуй, самый известный, самый замануаленный, самый проработанный и прочие «самый» инструмент. Яркий представитель техники Face-swapping, обойти вниманием который было нельзя.
Инструкции есть на многих языках как в формате текста, так и в видео-гайдах. Обработку и обучение нейронки можно запустить даже на CPU, поэтому решено было проверить на себе. Результат:
Мда…Совсем не то, что ожидал. Почему? А потому что решено ведь было следовать принципу, вынесенному в начало статьи: сделать качественный дипфейк (видео и аудио), не особо вникая в вопрос. В случае с DeepFaceLab это явно не получится. Нужно учитывать довольно много нюансов. Перед обучением нейронки нужно как минимум учесть:
качество видео «донора» и «жертвы» (свет, цвет и т.д.);
масштаб пересаживаемых лиц (чтоб не получилось, как у меня, когда маленькая картинка растягивается и мылит);
наличие в обоих видео всех положений головы (особенно, если собираетесь сильно ею вертеть);
необходимость удалить «плохие» кадры из наборов данных перед началом обучения (кадры без лица, размытые кадры, кадры с посторонними предметами, перекрывающими лицо и т.п.).
После обучения работы тоже хватает. Внутри DeepFaceLab есть встроенный инструмент Merger, с помощью которого можно осуществлять покадровую подгонку пересаженного лица.
Именно в нём регулируется размытие, размер маски, её положение, цвет и т.д.
Если же подходить к вопросу в стиле «Далее-Далее-Готово», то результат получится, как у меня.
Плюсы подобных инструментов:
Свобода воли. Можно создавать произвольный контент.
Низкий порог вхождения по технике. Но стоит отметить, что чем слабее железо, тем дольше будет проходить обучение нейросети и прочая обработка.
Минимальный цифровой след;
Бесплатно.
Минусы:
Высокий порог вхождения по знаниям;
Высокий порог вхождения по затраченному времени;
Нельзя сделать подмену в режиме реального времени.
Wav2Lip
Настала пора инструмента, который использует технику Lip syncing. И хоть подходящего железа под рукой не было, проект позволял поиграться с помощью Google Colab. Вооружившись инструкцией, получил результаты:
Свобода воли. Можно создавать произвольный контент;
Меньше возни с предварительной подготовкой данных, если сравнивать с DeepFaceLab;
Больше достоверности, так как ничего не заменяется, а лишь искажается небольшой участок рта;
Минимальный цифровой след (если не работать через Colab);
Бесплатно.
Минусы:
Высокий порог вхождения по знаниям;
Высокий порог вхождения по технике (если не работать через Colab);
Высокий порог вхождения по затраченному времени;
Нельзя сделать подмену в режиме реального времени.
А ещё желательно избегать неоднотонных фонов. В противном случае область подмены будет бросаться в глаза.
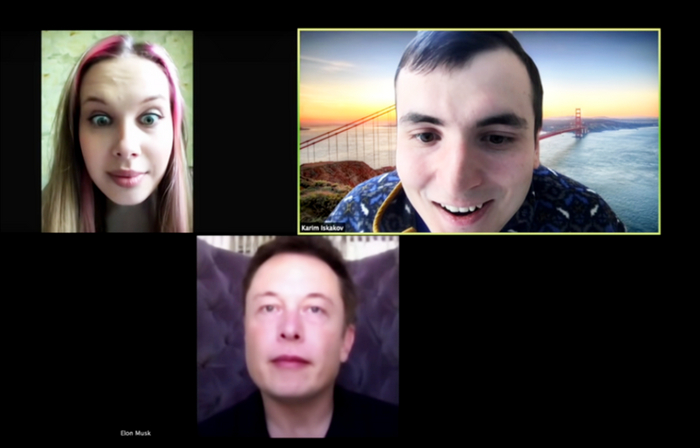
Avatarify
Программа использует технику Puppet master и позволяет в режиме реального времени «оживить» какое-нибудь фото. Есть известный ролик, который показывает возможности этого решения: «Илон Маск» вошел в конференцию в зуме». Обратите внимание, «Илон Маск» почти не шевелит головой. Только глазами. Он как восковая фигура. Но некоторые и в жизни не демонстрируют живость мимики или пребывают в разных состояниях, так что вполне можно и обмануться. Голос, понятно, совсем не подделан – подробнее о синтезе речи в режиме реального времени поговорим ниже.
Потенциал здесь определённо есть, но пока всё же этот проект не рассматриваю, как серьёзную угрозу. Уж слишком много факторов должны сойтись, чтобы на выходе получился приемлемый результат. К примеру, требуется определённый перечень софта и железа. Причём, подозреваю, что в ряде случаев нужно будет точное попадание в версию, а не «от 3.5 и выше». У меня так и не получилось запустить проект (хотя может дело в руках).
Если посмотреть на успехи тех, кто смог стартануть, выяснится, что нужно подбирать подходящую позу, угол и т.п., чтобы аватар не пучило. Смотрите сами:
Но если глянуть в сторону коммерческих проектов, результаты будут более впечатляющими.
Плюсы подобных инструментов:
Подмена в режиме реального времени;
Свобода воли. Перечень сцен и героев для подмены не ограничен;
Минимальный цифровой след (для некоммерческих инструментов);
Бесплатно (для некоммерческих инструментов);
Низкий порог вхождения по знаниям (для коммерческих инструментов).
Минусы:
Высокий порог вхождения по знаниям (для некоммерческих инструментов);
Высокий порог вхождения по технике (для некоммерческих инструментов);
Платно (для коммерческих инструментов);
Цифровой след (для коммерческих инструментов).
Что до Face Synthesis and Attribute Editing, то в части создания дипфейков я склонен рассматривать эту технику как продолжение Puppet Master с аналогичными преимуществами, ограничениями и выводами.
Подделка аудио
Настало время попробовать подделать голос. По одной из версий, которые читал про первый в мире инцидент с применением deepfake, голос жертвы не клонировали. Был найден пародист с изначально похожим на жертву голосом, который затем сымитировал акцент, манеру речи и прочее. Чтобы было ещё более похоже, голос дополнительно искажали в момент разговора. С этого и начнём.
«Искажатели»
Они часто используются в игровой индустрии – например, если игрокам важно, чтобы по голосу их не узнали. Искажатели работают в режиме реального времени и меняют голос на лету.
Плюсы подобных инструментов:
Можно найти бесплатные;
Работа в режиме реального времени;
Низкий порог вхождения по технике.
Низкий порог вхождения по знаниям.
Минусы:
Вряд ли получится сымитировать любой голос;
В теории, подделанный голос можно преобразовать обратно и получить изначальный голос говорящего.
Синтезаторы речи
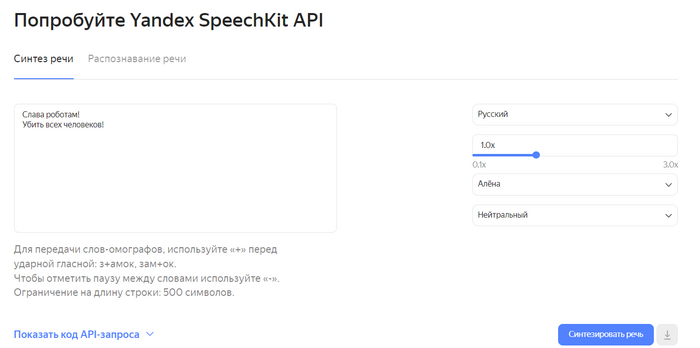
Принцип работы прост: вводим текст – нам его озвучивает голос. Часто такие инструменты представлены в виде сервисов.
Как видите, есть опции по выбору языка, скорости, «актёра» и тона речи. Некоторые сервисы предлагают синтезировать актёра под заказ.
Плюсы подобных инструментов:
Можно найти бесплатные;
Низкий порог входа по знаниям;
Низкий порог входа по технике;
Низкий порог входа по времени.
Минусы:
Свобода воли. Произвольный голос не подделать.
Ограничения инструмента (не во всех сервисах даже есть возможность изменять ударение);
Цифровой след;
Не работает в режиме реального времени.
Клонирование голоса + синтезаторы речи
Логичным развитием синтеза речи является синтез речи конкретного человека. Из бесплатных инструментов я попробовал этот.
Упрощённо логику работы можно описать так:
Добываем аудио «жертвы», чей голос будем поддерживать. Чем выше качество записи, тем лучше. В идеале wav, на котором только голос человека без посторонних шумов.
Готовим набор данных. Нарезаем аудио на отдельные фразы, транскрибируем и всё это дело сохраняем определённым образом.
ВЖУХ (запускается обучение нейросети);
Пишем текст, синтезатор его озвучивает подделанным голосом.
Хватает инструкций, где подробно показан каждый этап. Результатом, к сожалению, поделиться не могу, т.к. действовал через Colab и добиться чего-либо приемлемого на выходе не получилось. В основном из-за того, что если оставить обучаться нейронку надолго, то что-то шло не так и валилось с ошибкой. Если же обучение шло недолго, сгенерированный голос был не особо похож на «жертву».
Плюсы подобных инструментов:
Бесплатно;
Свобода воли. Можно подделывать любой голос;
Минимальный цифровой след (если запускать на своей технике, естественно).
Минусы:
Высокий порог входа по знаниям;
Высокий порог входа по технике;
Высокий порог входа по времени;
Ограничения инструмента (ударения, интонации и т.п.);
Не работает в режиме реального времени.
Клонирование + синтез. В режиме реального времени
Логичное развитие логичного развития. Пока сказать об эффективности такого подхода мне нечего, не дошли руки (и техника) попробовать. Но различные инструменты, как коммерческие, так и бесплатные, уже есть. Вот для видео, вот для аудио. Наверняка кто-то в скором времени и вместе соберёт, если уже не собрал. Как минимум, на поверхности лежит идея запуска Real-Time-Voice-Cloning в паре с Avatarify.
Кстати, в задаче повышения достоверности дипфейков есть не одно направление. Параллельно, идя по пути улучшения подделки, можно идти по пути внесения осознанных ухудшений. Например, чтобы скрыть неидеальный фейк при звонке можно вносить на лету различные помехи в видео и аудио: посторонние шумы, пикселизацию, прерывание сигнала и прочее.
Как выявлять дипфейки без специализированных инструментов и сервисов. Практика
Итак, нагрузившись теорией по самое горлышко, пора сформулировать не просто списки признаков, а понятную инструкцию. Поясню мысль. Выкатить кучу «сигнатур» дипфейков любой может. И нельзя сказать, что это ложная информация. Вот, например, мой список, на что стоит обращать внимание для аудио:
Выразительность;
Одышка;
Эмоции;
Ударения;
Слова-паразиты;
Специфические дефекты;
Темп.
А ведь в реальности у каждого инструмента, с помощью которого создаётся подделка, есть свои ограничения.
Но запомнить, а главное, вспомнить в нужный момент, всё это человек вряд ли сможет. Поэтому предлагаю такую инструкцию по выявлению дипфейков:
Контекст
Определить технику
Вспомнить ограничения
Искать артефакты в местах, которые следуют из п.2
Проиллюстрирую на примерах, о которых упоминал в самом начале статьи (ролик под названием «10 лучших Дипфейк видео»). В качестве дополнительных инструментов будет задействован любой проигрыватель, который способен воспроизводить видео покадрово.
Пример 1
Тут, как и во многих других подделках, нет смысла идти дальше шага Контекст. Тем не менее, пройдёмся по алгоритму:
Используется техника Face Swapping.
Ограничения касаются положения головы при поворотах на большие углы.
Нейронка просто не знает, как нарисовать правильно, пытается до последнего показывать оба глаза. В итоге лицо получается похожим на блин. Как такое произошло? Когда готовили дата-сет изображений Стива Бушеми, скорее всего не «скормили» нейронке фото в нужном ракурсе.
Пример 2
Если уменьшить скорость воспроизведения или смотреть покадрово, можно сразу увидеть несколько артефактов. Например, несовпадение текстуры кожи.
Ещё переборщили с размытием. Во время движения весьма бросается в глаза.
На крупных планах «мыло» видно ещё больше.
На одном кадре нейросеть даже перестаралась и попыталась нарисовать лицо там, где его не должно быть.
Также на крупных планах вы сможете найти эффекты «дрожания» наложенного лица. А пока пройдёмся по алгоритму:
Используется Face-swapping.
Если не попали с размерами лиц «донора» и «жертвы», лицо донора будет мылить. Для более качественной «пересадки» используется размытие границ, но с ним можно переборщить. Лицо в каждом кадре накладывается без оглядки на прошлое и будущее. Как следствие, лицо может «дрожать».
Удалось с лихвой найти артефакты.
Лоб выделяется, он блестит, а другие части лица нет.
Очень хорошо видно размытие по границе «маски».
На крупных планах видно, как отличается текстура кожи.
Есть моменты, когда голова (лоб, шея, уши) «жертвы» не двигается, а лицо «донора» немного смещается. Дрожание.
Т.к. у Пикабу есть лимит на количество медиа в посте, придётся разбить пост на 2 части. UPD: Вторая часть.