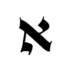Telegraph API обещает 64 КБ. Валится на 17. Замерил и обошёл
В документации Telegraph API на эндпоинт "createPage" написано:
"content (Array of Node, up to 64 KB)". По факту русскоязычный markdown в районе 20 КБ ловит "CONTENT_TOO_BIG". Замерил, где реально проходит граница, и расскажу, как обойти.
Поймал я это так. У меня сервис генерит посты блога и публикует их в двух местах сразу: на сайте и параллельно отправляет в Telegraph ради красивой OG-карточки в TG-канале. Англоязычные переводы летели нормально. Русские оригиналы с конца марта молча перестали публиковаться в Telegraph, в обработке стоял fallback «если ссылка не вернулась, шлём в канал без неё», и недели две никто этого не замечал. В логи смотреть надо было раньше.
Минимальное воспроизведение
Создаём свежий аккаунт через "createAccount" (он сразу выдаёт "access_token"), кидаем через "createPage" контент разного размера:
const para = 'Тестовый абзац с нормальным текстом. ';
let md = '';
while (md.length < kbTarget * 1024) md += para + '\n\n';
const content = md.split('\n\n').filter(Boolean).map(
p => ({ tag: 'p', children: [p] })
);
const res = await fetch('https://api.telegra.ph/createPage', {
method: 'POST',
headers: { 'Content-Type': 'application/json' },
body: JSON.stringify({ access_token, title: `${kbTarget} KB`, content }),
});
Прогнал от 5 до 40 КБ с паузой полторы секунды между вызовами, чтобы исключить rate-limit. Что вышло.
5 КБ исходного markdown - это после "JSON.stringify" 8 581 символ, по UTF-8 примерно 13 600 байт. Прошло. 10 КБ markdown - 17 096 символов JSON, около 27 200 байт. Тоже прошло. 20 КБ - 34 191 символов JSON, около 54 400 байт - "CONTENT_TOO_BIG". 30 и 40 КБ markdown упираются ровно в ту же стену.
Реальный потолок где-то между 10 и 20 КБ исходного markdown. Не 64, как в документации, и даже не близко.
Пробовал отправлять через "application/x-www-form-urlencoded" вместо JSON - поведение идентично, ошибка на тех же порогах. Envelope добавляет 200-300 байт, разница до обещанных 64 не заполняется. Скорее всего, Telegraph внутри парсит payload в свою структуру "Node" и меряет лимит уже после парсинга, где она пухнет за счёт служебных полей. Но это домыслы, проверить нечем.
Почему русский язык упирается раньше английского
Это вторая половина бага. В JavaScript длина строки считается в UTF-16 code units, и "String.prototype.length" для кириллической буквы вернёт 1, как и для латинской. А вот в HTTP-теле строка едет в UTF-8, и там кириллический символ занимает 2 байта на букву. Получается, при одинаковом "length" русский текст по сети ровно в два раза тяжелее английского.
Если Telegraph меряет лимит по байтам после кодирования (это правдоподобная версия), русский контент упирается в потолок где-то на 40-50% быстрее. EN-переводы у меня делает Gemini Flash Lite, они на 30-40% короче по символам, и на все 50% - по байтам. Большой пост в RU даёт 60-80 КБ, его перевод 20-30 КБ. Перевод помещается в зелёную зону, оригинал нет. Вот вам и «на одном языке работает, на другом нет», хотя код между ними общий.
Налажал я именно тут: думал, что байтовый лимит и символьный - это одно и то же. Получил по голове.
Как обойти
Резать markdown под безопасный размер и ставить маркер «полный текст на сайте». Эмпирическая зелёная зона - 18 КБ исходного markdown:
const TELEGRAPH_SAFE_MD_BYTES = 18 * 1024;
function truncateMarkdownAtBoundary(md, maxBytes, lang) {
if (Buffer.byteLength(md, 'utf8') <= maxBytes) {
return { md, truncated: false };
}
let cut = md;
while (Buffer.byteLength(cut, 'utf8') > maxBytes) {
cut = cut.slice(0, Math.floor(cut.length * 0.9));
}
// По возможности режем по границе абзаца, а не посреди слова
const lastBreak = cut.lastIndexOf('\n\n');
if (lastBreak > cut.length * 0.5) cut = cut.slice(0, lastBreak);
const note = lang === 'en'
? '\n\n\_Article truncated for Telegraph. Read full version on the site.\_'
: '\n\n\_Статья сокращена для Telegraph. Полный текст на сайте.\_';
return { md: cut + note, truncated: true };
}
Две детали, на которых легко обжечься.
Цикл режет по длине строки, а не по байтовому индексу. Если бы я сразу резал по целевому байт-индексу, мог бы попасть в середину кириллического двухбайтового символа. Получилась бы невалидная UTF-8 последовательность, и Telegraph такой payload отбрасывает без объяснений. Срез через "String.prototype.slice" по длине гарантирует валидную границу для BMP-символов, куда попадает кириллица.
Шаг 10% на первый взгляд жадноват, но на реальных входах цикл обычно укладывается в 1-2 итерации. На очень коротких текстах работает ранний return.
Поверх этого ставлю retry: если 18 КБ всё равно не прошло (бывает, если в тексте много ссылок - каждая "[text](url)" это плюс 30-50 байт после сериализации), уменьшаю лимит на 40% и пробую ещё раз. Максимум три попытки. Если всё ушло в потолок, публикую без Telegraph-ссылки, в канале остаётся ссылка только на сайт.
Что забрать с собой
Документированные 64 КБ у Telegraph - не верхняя граница, не нижняя, вообще не граница. Эмпирическое число на апрель 2026 - 17-18 КБ исходного markdown. Если они подкрутят свой внутренний лимит, придётся подкручивать и у вас. Сервис существует с 2016, документация обновлялась, кажется, тогда же.
Если у вас пайплайн «генерируем контент - публикуем в Telegraph для OG-карточки - потом ссылка в TG-канал», и в логах хоть раз мелькало "CONTENT_TOO_BIG", - скорее всего, RU-публикация у вас молча отваливается на длинных постах. Загляните в логи, там может быть приятный сюрприз.
И наконец общее. UTF-8 байты и UTF-16 code units - разные вещи. Если интеграция живёт на байтовом лимите, считать надо через "Buffer.byteLength", не через "length". Касается и баз, и транспортного слоя, и rate-лимитов. С токенами LLM ситуация ещё веселее, там для кириллицы вообще другие правила, чем для латиницы, и единственный способ не промахнуться - прогонять корпус на всех языках, которые у вас в проде.