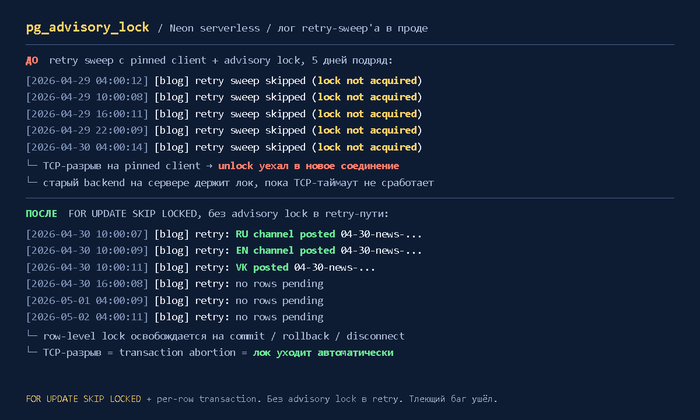
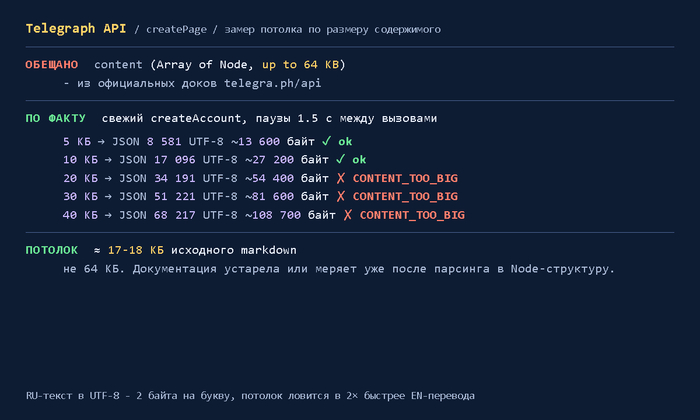
Я 15 лет в IT, и меня достало делать «кнопочки». Пошёл на hh.ru, пересчитал все вакансии и выбрал бэкенд. Спойлер: PHP ещё жив
Сергей, Ульяновск. В IT с середины 2000-х: jQuery, ExtJS, Backbone, ранний Angular. Сейчас React и TypeScript. Коммерческий фронтенд — три года. До этого — всё подряд.
Полгода назад упёрся.
Не в деньги — в развитие. Делаешь сложные формочки. Микрофронтенды. Стейт-машины на XState. А хочется понимать систему целиком. Почему API тормозит. Как данные идут в базу. Что там, под капотом.
Fullstack. Но какой бэкенд?
На YouTube — ролики «ТОП-5 ЯЗЫКОВ, ПОКА НЕ ПОЗДНО». Парень с укладкой, Hello World три месяца назад. Я пошёл на hh.ru и начал считать сам.
Вот что вышло.
---
## Как я считал
Два источника.
**hh.ru.** Только совпадения в названиях вакансий. Без поиска по описанию — там слишком много шума. Пятнадцать запросов: Python, Java, Go, PHP, Node.js, C# — плюс их комбинации с fullstack и React. Фильтр: вся РФ, зарплата любая.
**Хабр Карьера.** 43 716 анкет, июль 2026. Медианы, а не средние — чтобы пара зарплат из Яндекса не перекосила картину.
Даты: 14–20 июля 2026. Всё руками. Без скриптов.
Что нельзя гарантировать:
Поиск по заголовкам режет абсолютные цифры. Вакансия «Senior разработчик» без языка в названии — мимо выборки. Но пропорции держиЎ смещение одно и то для всех языков.
Это срез недели. Не годовой тренд.
Закрытый рынок (внутрянка, рекомендации) не виден. Совсем.
Регионы: Москва и Ульяновск — разные галактики. Мои цифры — среднее по стране, а не по столице.
И всё же. Для карьерного решения точности достаточно.
---
## Общий рынок: Python — 519. Но это ловушка
Беру все бэкенд-вакансии. Без фильтрации. Грубая масса:
> 📊 **[ВСТАВИТЬ КАРТИНКУ: horiz_bar.png]**
- Python — 519
- Java — 468
- C#/.NET — 227
- PHP — 207
- Go — 141
- Node.js — 62
- TypeScript (бэкенд) — 53
- Ruby — 15
Python вдвое опережает C#. Картинка ясная?
Нет.
Я открыл эти 519 вакансий. Добрая половина — Data Science. Нейросети. ML. Автоматизация. Python-разработчик в банке может не писать API вообще — он обучает скоринговые модели. К fullstack это имеет слабое отношение.
Сырые цифры врут. Красиво врут — но врут. Нужна другая выборка.
Теперь Node.js и TypeScript. Если считать их одним (TypeScript-бэкенд — NestJS или Next.js, технически Node.js), вместе — 115. Третье место, сразу за Python и Java. По-моему, так честнее. Но в таблицах ниже я их разделяю — для прозрачности.
Go — 141. Много для 15-летнего.
PHP — 207. Язык, который «умер» в 2012. В 2015. В 2018. В 2020. 207 вакансий. Никак не добьют.
Ruby — 15.
---
## Fullstack-срез: PHP на первом месте. Я перепроверил трижды
Дальше — фильтрую. Только вакансии, где в заголовке или первом абзаце чётко: «фронтенд + бэкенд». Пришлось вручную просмотреть около 200 штук. Некоторые заголовки врут: написано «Fullstack Developer», внутри — чистый бэкенд.
> 📊 **[ВСТАВИТЬ КАРТИНКУ: fullstack_bar.png]**
- PHP — 30
- Python — 29
- Java — 28
- C#/.NET — 21
- Node.js — 15
- TypeScript — 10
- Go — 2
- Ruby — 1
PHP.
На первом месте.
Я не поверил. Пересчитал. Ещё раз. Цифра честная.
Только вот интерпретация. PHP вырвался не потому, что это лучший язык для веба — а потому что Laravel-экосистема исторически fullstack. Фреймворк даёт бэкенд и Blade-шаблоны из коробки. В вакансиях на Laravel ищут одного человека: база, API, фронт — всё он. Это артефакт экосистемы. Не сигнал «беги учить PHP».
Node.js + TypeScript — 25. Второе место. Я ждал меньше. Думал, fullstack занят PHP и Java, а Node.js где-то в нише. Ошибся.
Go — две вакансии на всю страну.
Две.
Не случайность. Go проектировали для микросервисов, не для fullstack. Искать fullstack на Go — как спорткар с кузовом универсал. Можно, но зачем.
### Несколько цифр без прикрас
- Fullstack-вакансий в выборке: 330
- Удалёнка: 190 (58%)
- Senior: 61, Middle: 24
- hh.индекс: 8,3 — конкуренция
- Динамика: вакансий +8%, резюме −2%
61 senior, 24 middle. В 2,5 раза.
Fullstack — не входная точка в IT. Сначала стань кем-то одним. Потом расширяйся. Рынок ждёт опытных, а middle-позиции подбирает по остаточному принципу.
---
## React + бэкенд: график, ради которого я это затеял
Главный вопрос. Какие бэкенды реально ищут в паре с React? Не «упомянут где-то в глубине требований» — прямо в заголовке или первом абзаце:
> 📊 **[ВСТАВИТЬ КАРТИНКУ: react_combos.png]**
- React + Node.js — 16
- React + PHP — 9
- React + Python — 8
- React + Java — 6
- React + .NET — 5
- React + Go — 1
16 против 9. Node.js отрывается почти вдвое.
И вот что интересно. На общем рынке Node.js — скромный середняк: 62 вакансии. В fullstack-нише — третье-четвёртое место. А в связке с React — уверенное первое.
Не самый массовый бэкенд вообще. Но для React-фронтендера — самый частый выбор нанимателя.
Почему? Четыре причины, которые, по-моему, не случаются сами собой:
**Один язык.** TypeScript на клиенте и на сервере. Типы кочуют туда-сюда без переписывания. DTO описал один раз — работает везде.
**Next.js размывает границу.** API routes, Server Components, Server Actions. Разработчик на Next.js пишет бэкенд, часто не замечая.
**NestJS — когда Next.js маловато.** Модульная архитектура, DI, guards, interceptors. Enterprise-уровень на знакомом TypeScript.
**Общий тулинг.** Zod для валидации, date-fns для дат, shared-библиотеки в монорепе. Никакого дублирования.
React + PHP (9 штук) — обычно Laravel на бэке, React как админка или SPA. Работает. Особенно в e-commerce.
React + Go (1 штука).
Одна.
Кто-нибудь вообще видел такую вакансию вживую? Отпишитесь, мне правда интересно, что за проект.
---
## Деньги: где самый толстый скачок
Хабр Карьера, 43 716 анкет. Медианы.
> 📊 **[ВСТАВИТЬ КАРТИНКУ: salaries.png]**
- Intern — 66 000 ₽
- Junior — 95 000 ₽
- Middle — 177 000 ₽
- Senior — 303 000 ₽
- Lead — 378 000 ₽
Ступеньки: Junior → Middle — плюс 82 тысячи. Middle → Senior — плюс 126 тысяч. Senior → Lead — плюс 75 тысяч.
Самый крутой подъём — между middle и senior. Рынок платит за глубину. Fullstack-middle, который «всё понемногу», стоит сильно дешевле fullstack-senior, который глубоко знает оба направления.
Что за кадром:
Разброс внутри грейдов — пропасть. Senior fullstack в региональной веб-студии и senior fullstack в финтехе живут в разных финансовых измерениях.
Хабр Карьера смещена вверх. Те, кто получает мало, реже заполняют анкеты.
Зарплаты по языкам — за регистрацией. Я не знаю, получает ли PHP-senior столько же, сколько Node.js-senior. Подозреваю, что нет. Доказательств у меня нет.
---
## Удалёнка: 190 из 330
190 fullstack-вакансий из 330 — удалённые.
Я в Ульяновске. Ближайшие офисы крупных IT — Казань, Самара. С удалёнкой это не проблема: работаешь на Москву или Питер из квартиры с видом на Волгу.
Деталь: большинство удалённых fullstack-позиций — аутсорсинг и стартапы. Enterprise осторожничает. Банки. Телеком. Им всё ещё нужен офис. Хотите Java в банке — готовьтесь к гибриду как минимум.
---
## Что я выбрал
Node.js + NestJS + TypeScript.
Не «потому что модно». Пять вещей, которые перевесили:
**Язык один.** Пишу на TypeScript больше пяти лет. Декоратор `@controller()` в NestJS — продолжение того, что знаю. Не прыжок в другую вселенную.
**16 против 1.** React + Node.js — 16 вакансий, React + Go — одна. Работодатель, которому нужен fullstack на React, ждёт Node.js. Мне не надо его переубеждать.
**Потолок далеко.** Простой CRUD на NestJS — за вечер. Дальше — CQRS, event-driven, микросервисы на Kafka/NATS. Есть куда расти.
**Next.js как трамплин.** Server Actions и API Routes — это бэкенд, просто в рамках одного фреймворка. Переход к NestJS — структурирование тех же концепций.
**Одна кодовая база.** Типы, валидация, утилиты живут в одном месте. Без дублирования.
Что через год-два? Не знаю. Может, вторым языком возьму Python + FastAPI — мост в AI/ML-проекты. Может, останусь в Node.js и пойду в ширину: базы данных, инфраструктура, девопс.
Посмотрим.
---
## Если примерять к себе
Ты React/TypeScript-фронтендер? **Node.js, NestJS.** Язык знаешь, рынок подтверждает, вход плавный.
Ты в Data Science / ML? **Python, FastAPI.** Строить веб вокруг ML-моделей — редкая комбинация. Только учти: вакансий меньше, чем в чистом вебе.
Ты в enterprise или планируешь? **Java / C#.** Стабильно. Дорого. Порог входа высокий, экосистема тяжёлая.
Любишь highload и инфраструктуру? **Go.** Fullstack-позиций почти нет. Но как чистый бэкенд — мощно.
Нужна работа прямо сейчас? **PHP, Laravel.** 30 fullstack-вакансий — больше всех. Только готовься к культурной адаптации после TypeScript.
---
Четыре вещи, которые остались после подсчётов.
Node.js — не самый большой рынок. Но для React-фронтендера — точка входа с наименьшим сопротивлением. 16 против 1. Не погрешность.
Fullstack — не старт. 61 senior-вакансия, 24 middle. Сначала глубина. Потом ширина.
Один язык на клиенте и сервере — не «удобно». Это скорость. Меньше ошибок, общий тулинг, никаких «забыл обновить типы после смены API».
Цифры — не догма. Срез июля 2026. Через полгода пересчитаю — и не поручусь, что картина не изменится.
Пишите в комментариях, какой бэкенд выбрали вы. И главное — почему. Реальный опыт интереснее любых цифр.
А если кто-то видел fullstack на Go вживую — маякните. Мне правда интересно.
---
*Данные: hh.ru и Хабр Карьера, 14–20 июля 2026, РФ. Поиск по заголовкам — абсолютные цифры занижены, пропорции репрезентативны. Детальные зарплаты по языкам — за регистрацией, не включены. Региональные перекосы возможны.*