Для СУБД важна не максимальная скорость в коротком тесте, а стабильный отклик диска под рабочей нагрузкой. Требования к I/O зависят от профиля: OLTP, аналитика и смешанные нагрузки по-разному используют чтение, запись, WAL, временные файлы и кэш. VDS для баз данных оценивают по стабильному IOPS, p99-задержке и поведению под длительной нагрузкой, а не по лучшей цифре из прайса.
Почему БД чувствительны к стабильности I/O
PostgreSQL пишет WAL, MySQL – redo log и, если включён, binlog. При скачках задержки fsync с 2 до 80 мс транзакции могут ждать диск, а очередь запросов расти даже при нормальной средней скорости. io_wait сам по себе не всегда означает проблему: его нужно смотреть вместе с latency диска, p95/p99 и временем ответа запросов.
Пиковая скорость vs устойчивый IOPS
На VDS с burst-профилем короткий тест может показать высокий результат, но через несколько минут упереться в лимит хоста или нагрузку соседних VM. Для OLTP важнее, чтобы 5 000 IOPS держались ровно 10–15 минут, чем разовый пик в 50 000 IOPS на старте теста.
Метрики, на которые смотреть
Смотрите не только среднюю задержку, а p95/p99, джиттер и самые медленные операции записи. Оценивать график лучше относительно SLO конкретной СУБД и приложения: p99-задержка, время ответа запросов и io_wait не должны регулярно выходить за допустимые для проекта значения при одинаковой нагрузке.
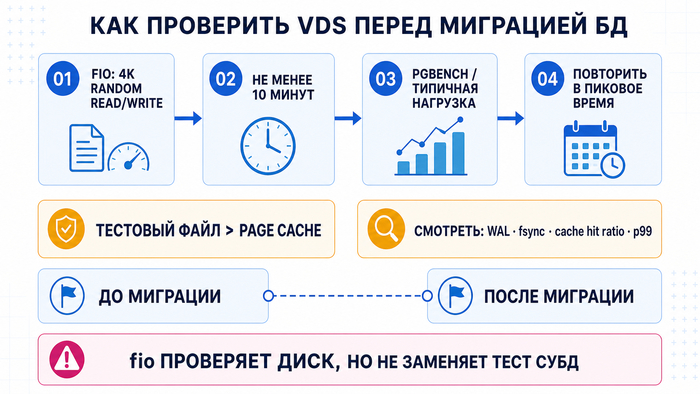
Как проверить VDS перед миграцией БД
Перед переносом запустите fio со случайным чтением и записью блоками 4K минимум на 10 минут и отдельно проверьте СУБД через pgbench или другой нагрузочный тест. fio помогает оценить диск, но не полностью повторяет поведение PostgreSQL или MySQL: важны WAL, fsync, cache hit ratio и размер рабочего набора данных. Размер тестового файла должен быть больше объёма памяти, который может использоваться под page cache, иначе результат может попасть в кэш и показать нереалистично высокую скорость. Тестируйте VDS-сервер в то же время суток, когда у проекта обычно пиковая нагрузка.
Что замерить до переноса продакшена
• Стабильный IOPS на длительном fio-тесте
• p99-задержка чтения и записи
• p99-задержка fsync при типичной нагрузке вашей СУБД
• io_wait во время pgbench или тестовой нагрузки
• Наличие резервирования дисков, RAID-схему и поведение платформы при сбое накопителя
• Доступный объём RAM, использование page cache и активность swap под нагрузкой
• Поведение диска после 10–15 минут непрерывной нагрузки
До миграции продакшена проверьте диск под реальный профиль БД, а после переноса повторите тесты уже на рабочей нагрузке. Если тест показывает стабильную p99-задержку без резких всплесков, миграция будет менее рискованной: вы выбираете сервер по поведению под нагрузкой, а не по пиковой скорости.
В логах пусто, CPU в норме, но приложение тормозит. Часто виновата метрика, которую игнорируют: cpu steal time, или %st. Она показывает, сколько времени VPS провёл в ожидании физического процессора.
Что такое CPU Steal и откуда он берётся?
На гипервизоре несколько VM делят физические ядра. Когда vCPU готов работать, но планировщик отдал ядро соседней машине, ожидание засчитывается в steal. Так устроен Cloud VPS с общими ресурсами: несколько виртуальных машин конкурируют за физические ядра одного хоста. Steal может расти из-за высокой загрузки гипервизора, оверселлинга, особенностей планировщика виртуализации или кратковременной конкуренции за CPU.
Для наблюдения в динамике – vmstat 1: колонка st показывает steal за каждую секунду. Разбивку по ядрам даёт mpstat -P ALL 1. Для минутного замера с усреднением – sar -u 1 60.
Какие значения считать нормой
На стабильной ноде steal обычно близок к нулю, но универсальной нормы нет: многое зависит от типа нагрузки и платформы виртуализации. Практические ориентиры:
• 0–1% – обычно не вызывает проблем
• 3–5% – повод проверить динамику и сопоставить её с задержками приложения
• >10% – часто заметно влияет на производительность, особенно у чувствительных к задержкам сервисов
Смотрите на устойчивое значение за 10–15 минут, а не на пиковый выброс.
Что делать, если steal стабильно высокий
Сначала подтвердите устойчивость: sar -u 1 600 даст картину за 10 минут. Если steal держится выше 5%, стоит обратиться в поддержку провайдера: причина может быть в конкретной ноде, тарифе или особенностях инфраструктуры. Иногда помогает миграция на другой хост, но сначала лучше подтвердить проблему вместе с поддержкой. Если ситуация повторяется, рассмотрите тарифы с выделенными CPU-ядрами или смену провайдера.
Быстрый мониторинг VPS: чек-лист
• Запустите top, найдите строку %Cpu и проверьте %st
• Понаблюдайте за vmstat 1 в течение 30–60 секунд
• Сравните пики steal с замедлениями приложения
• Если steal стабильно выше 5%, зафиксируйте замеры и передайте их в поддержку
• Рассмотрите тариф с выделенными ядрами, если проблема системная
Запустите диагностику прямо сейчас хватит одной команды. Если steal стабильно высокий и совпадает с замедлениями приложения, сначала проверьте инфраструктуру, а уже потом ищите проблему в коде.
Да, это нативная сборка под Linux, причем с фейковым Vulkan API и без железа - используется программный рендер на встроенной видеокарте.
История с исходниками достойна экранизации:
Code here is decompiled with IDA Pro and manually cleaned up, uninlined and rewritten to use templates. It is not a matching decompilation, and there is no workflow to merge the functions here with functions from the binary. The .exe contains class names as part of RTTI (see objtree.txt) but there has been no source leak. There has however been a debug info leak for Tomb Raider (2013). It's a different game, but uses a similar engine.
Можно грузить уровни, модели и персонажей, к сожалению сама игра пока не работает. Но редакция внимательно следит за развитием событий.
Anthropic двадцать четвёртого июля показала Opus 5, и самое интересное в этом релизе вовсе не про интеллект. Оно про деньги. За новую модель просят ровно половину от того, что стоит флагманская Fable 5, а на дешёвой подписке Pro её открыли вообще всем. Разбираюсь, откуда взялась такая щедрость и в каких задачах новинка реально уделывает старшую сестру.
Откуда взялась дешёвая топ-модель
Родословная тут не секретная. Под коммерческой Fable 5 лежит закрытая Mythos, и её, если верить утечкам, внутри компании щупали ещё зимой. Весной запустили служебный проект с названием Glasswing, релиз старшей модели планировали на начало лета, но притормозили после того, как в историю влез Вашингтон.
Полугода за глаза хватает, чтобы с дорогой архитектуры снять облегчённую сборку и выкатить её в массы. Так и появился Opus 5.
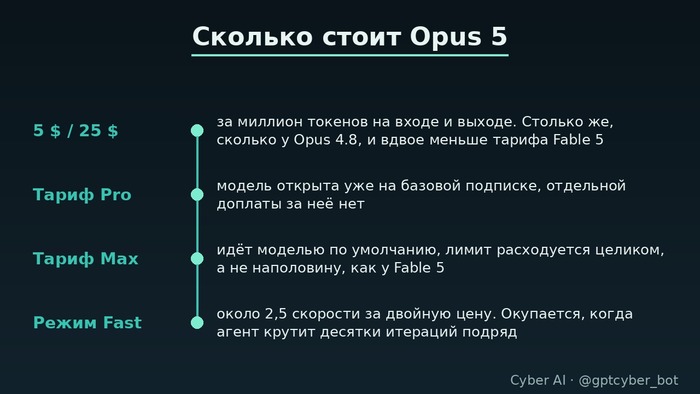
Цена, ради которой всё затевалось
За миллион токенов на входе разработчик отдаёт пятёрку в долларах, за исходящий миллион двадцать пять. Ценник не шевелился со времён Opus 4.8 и равен половине того, что берут за Fable 5.
Подписчикам достался бонус поинтереснее. Нейросеть Claude Opus пятой версии закинули в базовый Pro, на тарифе Max она стоит основной, и квота под неё тратится в полном объёме, тогда как у Fable 5 та же квота срезалась пополам. Отдельной опцией докрутили Fast: скорость примерно в два с половиной раза выше за удвоенный ценник. Вещь нишевая, но агенту, который прогоняет десятки итераций подряд, она окупается за вечер.
Официальная формулировка Anthropic звучит обтекаемо: дескать, модель приблизилась к передовому интеллекту старшей версии, отдав половину стоимости. Читается без словаря. Переплачивать ради Fable 5 большинству больше незачем.
В чём новинка обгоняет старшую модель
Преимущество нашлось в трёх дисциплинах, и объединяет их одна деталь. Везде модель работает долго и без человека над душой. Это агентское программирование, корпоративные сценарии на AutomationBench от Zapier и управление компьютером по методике OSWorld 2.0. Точные цифры я собрал в таблицу выше, если коротко: в первой дисциплине отрыв почти в полтора раза, в двух остальных поскромнее, зато уверенный. Тем, кто подбирает нейросеть для написания кода, интересна как раз первая строчка.
На остальном поле ничья с уклоном в размен. Общие знания у обеих моделей практически совпали, в паре кодовых замеров новинка отстаёт на десятые доли. Ощутимо проседает Opus 5 там, где требуется юридическая и медицинская фактура. При двукратной разнице в деньгах это не провал, а честная плата за компромисс.
История с ARC-AGI-3, которую хочется проверить
Громче всего звучит другой результат. На ARC-AGI-3 новая модель забрала 30,2 процента, тогда как прежний рекорд держался на отметке 7,8. Тест устроен зловредно. Испытуемого бросают в пошаговую игру и молчат про правила, разбираться приходится вслепую, а игр там целый набор и у каждой свой характер.
Разрыв почти четырёхкратный и выглядит эффектно, но восторги я бы придержал. Показали этот бенчмарк ещё в марте, задолго до финиша обучения. Открытых заданий в нём горстка, основную часть авторы прячут, однако разобрать доступные и заточить модель под сам формат вполне реализуемо. Обвинений никто не выдвигал, доказательств нет, а хронология складывается уж очень удачно.
Что мне понравилось больше цифр
В отчёте Anthropic есть эпизод, который объясняет модель лучше любой таблицы. Ей подсунули картинку с чертежом механической детали и поставили задачу: получить на выходе код, который воссоздаст такую же деталь в редакторе FreeCAD. Загвоздка в том, что смотреть на картинку модели запретили, зрение отключили специально.
Соперники в такой постановке честно капитулировали. Opus 5 сообразил, что изображение на диске это просто массив чисел, три значения на точку, и написал под него собственный разборщик. Программа вылавливала в массиве отрезки, дуги и стрелки размеров. По сути модель слепила себе примитивное зрение и закрыла задачу. Согласно отчёту, у соперников не вышло даже после пяти заходов.
Рядом лежат ещё две истории. Модели подсунули живой баг из пакетного менеджера, и она добралась до корня проблемы, попутно прикрыв редкий сценарий, мимо которого прошло даже комьюнити-исправление. А разработчик из трейдинговой конторы за один присест сделал с ней парсер котировок под новую биржу. Реальных данных под рукой не оказалось, и модель соорудила себе стенд для проверки самостоятельно.
Знаменатель у всех трёх историй общий. Пятый Opus не сдаёт первое, что получилось, а перепроверяет результат и додавливает задачу.
Отказов стало меньше
Fable 5 славилась паранойей. Пользователи жаловались на отказы там, где отказывать было незачем: устройство мозга у осьминога, парадокс Ферми и прочая безобидная любознательность. Классификаторы в Opus 5 перебрали, и в компании рассчитывают, что ложных срабатываний станет меньше процентов на восемьдесят пять. Сомнительный запрос больше не упирается в стену, его молча передают Opus 4.8. Ответ приходит, просто от модели поосторожнее.
Забавная деталь про безопасность. Искать уязвимости новинку специально не учили, но на профильном замере она почти догнала закрытую Mythos, отстав на полпроцента. Вывод напрашивается неприятный: умение писать хороший код автоматически тянет за собой умение находить в чужом коде дыры. Выручает то, что доводить находку до боевого эксплойта модель умеет плохо, вокруг этого Anthropic и выстраивает оборону.
В биологии всё зеркально, планку не поднимали и оставили как у Opus 4.8, поэтому научные задачи новинка тянет лучше любой другой публичной версии Claude.
Как подступиться из России
Карты российских банков Anthropic не принимает, отсюда два сценария.
Тем, кому claude нейросеть нужна ежедневно, под код, документы и рабочие проекты, подойдёт подписка Claude Pro. На Озоне она лежит обычным цифровым товаром за 3300 рублей, ключ активации приходит на электронную почту сразу после оплаты, ехать никуда не надо.
Тем, кому хватает разовых заходов, подписка избыточна. Opus 5 мы уже подключили в бот Cyber AI, так что погонять модель на своих задачах можно прямо там: TG | MAX
Сухой остаток
Прорыва в интеллекте здесь нет, зато есть точный расчёт. Почти весь потенциал старшей модели продают за половину денег, а в автономной работе новинка ушла вперёд. Если в ближайшие недели не вскроется что-нибудь досадное вроде деревянных формулировок или приступов фантазии, Fable 5 можно спокойно провожать на покой, не дожидаясь версии 5.1.
Расскажите в комментариях, кто уже погонял Opus 5 и на чём он вас удивил.
Больше разборов новых моделей - в нашем канале: TG | MAX
VPS куплен, SSH-сессия открыта. У многих здесь возникает пауза: непонятно, с чего начать и под какую задачу настраивать VPS-сервер. Разберём пять практических сценариев того, как использовать VPS: хостинг сайтов, запуск ботов, размещение API, мониторинг и автоматизация. У каждого – конкретный стек, ориентиры по ресурсам и нюансы, которые лучше знать до начала настройки, а не в процессе. Реальные требования зависят от сложности проекта, нагрузки, выбранного стека и числа одновременно работающих сервисов.
Что даёт VPS и почему его берут
VPS-сервер отличается от shared-хостинга тремя вещами. Первое – у вас есть заявленные параметры тарифа: CPU, RAM, диск и сетевой канал. На качество работы всё ещё может влиять общая инфраструктура хоста, но изоляция здесь выше, чем на shared-хостинге. Второе – root-доступ: можно установить любой софт, выбрать версию PHP, настроить nginx под конкретную задачу. Третье – VPS-сервер работает круглосуточно без вашего участия, независимо от состояния вашего компьютера или интернета. На shared-хостинге чужая нагрузка может повлиять на соседние сайты, если провайдер плохо ограничивает ресурсы аккаунтов.
От облачных функций (AWS Lambda, Yandex Cloud Functions) VPS отличается предсказуемостью: нет cold-start задержек, нет тарификации за каждый вызов функции, нет ограничений по времени выполнения. Для задач с постоянными процессами: баз данных, ботов, мониторинга – VPS часто проще и предсказуемее, чем serverless-архитектура с оплатой за вызов. При низкой или нерегулярной нагрузке serverless может оказаться дешевле.
Базовая подготовка: что сделать сразу после покупки
Настройка VPS начинается не сразу с рабочего проекта, а с базовой конфигурации. Базовая настройка снижает риск классических проблем: открытого SSH, устаревших пакетов, лишних портов и нехватки памяти при пиковых нагрузках. Пропуск таких шагов может увеличить риск потерять сервер из-за брутфорса или случайной команды от root.
• SSH-ключи. Сгенерируйте пару через ssh-keygen, передайте публичный ключ через ssh-copy-id, отключите аутентификацию по паролю в sshd_config.
• Пользователь без root. Создайте аккаунт с правами sudo. Работа от root в продакшене – плохая практика. Одна ошибка может стоить всей системы.
• Firewall. Откройте в UFW SSH-порт, 80 и 443, если они нужны вашему сценарию. Если используется стандартный SSH-порт, это 22. Fail2ban добавит защиту от брутфорса на SSH.
• Swap. Если RAM меньше 2 ГБ, добавьте swap-файл на 1–2 ГБ. Он снижает риск OOM при пиковой нагрузке, но при активном использовании может ухудшить производительность.
• Обновления. Запустите sudo apt update && apt upgrade сразу после входа на сервер, до начала любой работы.
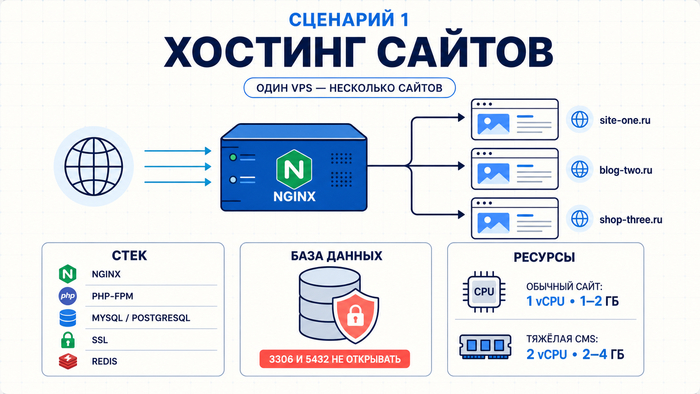
Сценарий 1. Хостинг сайтов и веб-проектов
Хостинг на VPS оправдан, когда shared-хостинг перестал справляться: нет нужной версии PHP или Python, не хватает памяти, несколько доменов требуют разных настроек или нестандартного ПО. На VPS больше свободы в настройке: можно выбрать версии ПО, настроить веб-сервер, подключить нужные модули и управлять несколькими проектами независимо. Именно поэтому многие переезжают сюда с первого же конфликта с техподдержкой shared-хостинга.
Стек: Nginx как веб-сервер и reverse proxy, PHP-FPM для WordPress или других CMS, MySQL или PostgreSQL как база данных. Для статических сайтов (Hugo, Astro, Next.js SSG) Nginx работает без интерпретатора, нагрузка минимальная. SSL – Let’s Encrypt через Certbot, бесплатно и с автообновлением. Один Nginx обслуживает несколько доменов через server blocks.
Порты СУБД (3306, 5432) наружу не открывайте: приложение обращается к базе внутри сервера. Для сайта с умеренным трафиком часто хватает 1 vCPU и 1–2 ГБ RAM; для тяжёлых CMS с кешированием, большим числом плагинов или высокой посещаемостью лучше закладывать 2 vCPU и 2–4 ГБ. Добавьте Redis для кеша сессий: это может снизить нагрузку на базу данных и улучшить отклик WordPress при росте трафика.
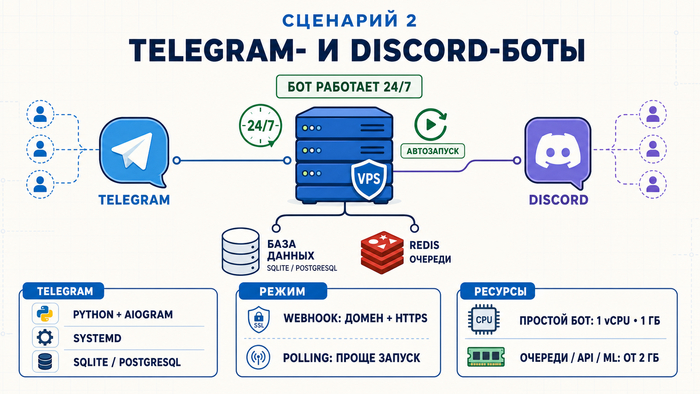
Сценарий 2. Запуск Telegram- и Discord-ботов
Боту часто нужно работать круглосуточно и хранить состояние: настройки пользователей, историю диалогов, очереди задач. Локальная машина для этого не подходит, а облачные функции удобны в основном для коротких команд без постоянного процесса. VPS решает обе задачи: бот постоянно запущен, а база данных может работать рядом на том же сервере.
Стек для Telegram: Python + aiogram, управление процессом через systemd, хранение состояния в SQLite или PostgreSQL. SQLite подходит для небольших ботов с умеренной нагрузкой, но при высокой конкуренции запросов или запуске нескольких экземпляров приложения лучше сразу выбирать PostgreSQL. Для Discord – Node.js + discord.js, для управления процессом удобен PM2. Redis подойдёт для быстрого хранения временных данных и очередей.
Для большинства продакшен-сценариев с Telegram-ботами удобен webhook-режим: сервер сам получает обновления, не опрашивая API Telegram. Для webhook нужен домен с HTTPS. Polling тоже остаётся корректным вариантом для небольших проектов: он проще в запуске и не требует домена с HTTPS. Простой бот без базы данных умещается на 1 vCPU и 1 ГБ RAM. Бот со сложными очередями, вызовами внешних API и ML-моделями потребует минимум 2 ГБ RAM. Через systemd настраивается автозапуск: после перезагрузки сервера бот поднимется сам.
Сценарий 3. Размещение API и бэкендов
VPS-сервер даёт API постоянный адрес, свою базу данных и полный контроль над окружением, без vendor lock-in и без ограничений по времени выполнения запросов. Это важно для бэкендов с длительными операциями: обработкой файлов, парсингом, генерацией отчётов.
Стек: FastAPI (Python) или Express.js (Node.js) для REST, Docker для изоляции сервисов, Nginx или Traefik как reverse proxy. Приложение слушает на localhost, наружу открыты только 80 и 443. GraphQL – Strawberry (Python) или Apollo Server (Node.js). Для автодеплоя – GitHub Actions: пуш в main запускает пересборку и перезапуск контейнера.
Порты базы данных держите внутри Docker-сети, не открывайте наружу: бэкенд обращается к базе по имени сервиса внутри сети. Для API с базой данных начинайте с 2 vCPU и 2–4 ГБ RAM. При росте нагрузки Docker и reverse proxy позволяют масштабировать сервисы без переписывания архитектуры. Traefik автоматически получает и обновляет SSL-сертификаты через Let’s Encrypt при настроенном ACME, поэтому отдельная настройка Certbot не нужна.
Сценарий 4. Мониторинг и сбор метрик
Сервер мониторинга должен работать независимо от мониторируемой инфраструктуры. Если основной сервер упал, система мониторинга должна увидеть это первой и отправить алерт, а не упасть вместе с ним. Отдельный небольшой VPS для мониторинга решает эту задачу.
Uptime Kuma – удобный инструмент с веб-интерфейсом: отслеживает HTTP-статусы, время ответа, порты TCP, отправляет алерты в Telegram, Slack и другие каналы. Разворачивается через Docker за несколько минут и обычно помещается в небольшой VPS. Для лёгкого мониторинга часто достаточно 512 МБ RAM, но потребление зависит от числа проверок и их типа.
Prometheus + Grafana – полный стек для сбора метрик, построения дашбордов и настройки алертов. Prometheus собирает данные с exporters, Grafana строит графики. Оба сервиса вместе могут потреблять примерно 600–1000 МБ RAM в покое, но фактическое потребление зависит от retention, числа targets и объёма метрик. Под этот сценарий обычно стоит закладывать не меньше 2 ГБ RAM. Node Exporter собирает системные метрики хоста – CPU, RAM, диск, сеть; добавьте его на каждый наблюдаемый сервер. Алерты в Telegram настраиваются через Alertmanager за несколько минут.
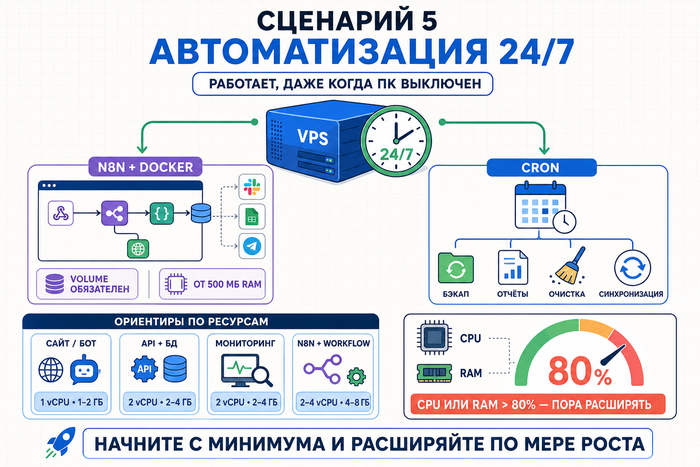
Сценарий 5. Автоматизация и рабочие процессы
Сервер не выключается. Это главное преимущество VPS для автоматизации: cron-задачи запускаются по расписанию в любое время суток, скрипты работают столько, сколько нужно, без ограничений по времени выполнения и без зависимости от того, включён ли ваш компьютер.
n8n – self-hosted инструмент для визуальной автоматизации, аналог Zapier на вашем сервере. Разворачивается через Docker, а потребление памяти может начинаться примерно от 500 МБ RAM и расти с числом workflow, интеграций и выбранной БД. Данные о задачах хранятся в БД, поэтому volume для персистентности обязателен. Настроенный VPS с n8n заменяет подписку на облачные сервисы автоматизации и не передаёт данные третьим сторонам.
Для простых задач достаточно cron: бэкап файлов, отправка отчётов, очистка временных директорий, синхронизация данных между сервисами.
Как выбрать свой сценарий и не перегрузить сервер
Примерные ориентиры по ресурсам под основные задачи:
• Сайт или бот без тяжёлых фоновых задач: 1 vCPU, 1–2 ГБ RAM
Несколько сценариев на одном VPS совместить возможно, но требования зависят от сложности проекта, выбранного стека, объёма трафика и числа одновременно работающих сервисов. Для простого сайта, небольшого бота и лёгкого мониторинга 2 ГБ RAM могут быть достаточны, если нет тяжёлых фоновых задач. Docker упрощает совмещение: каждый сервис в своём контейнере, порты не конфликтуют, ресурсы лимитируются. Постоянная загрузка CPU или RAM выше 80% может стать сигналом для апгрейда. Начните с минимального тарифа и расширяйте по мере роста – большинство провайдеров позволяют сделать это без пересоздания сервера.
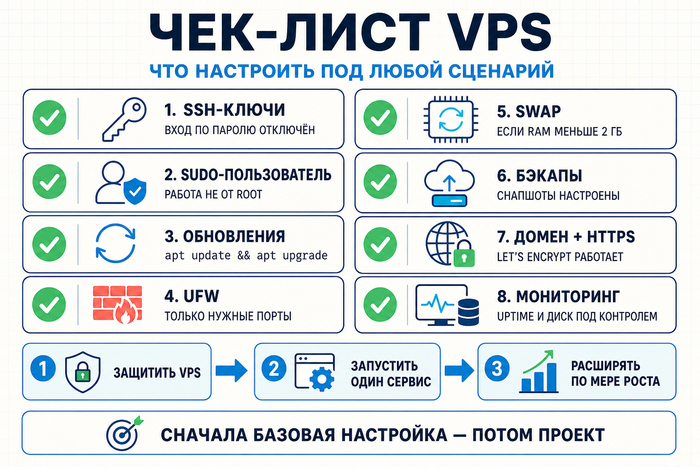
Чек-лист: что настроить на VPS под любой сценарий
1. SSH-ключи настроены, аутентификация по паролю отключена
2. Создан sudo-пользователь, работа от root прекращена
3. Система обновлена: sudo apt update && apt upgrade
4. UFW включён: открыты только нужные входящие порты, например SSH-порт, 80 и 443 для веб-сценариев
5. Swap настроен при RAM < 2 ГБ
6. Автоматические снапшоты или бэкапы настроены
7. Домен привязан, HTTPS работает через Let’s Encrypt
8. Базовый мониторинг: uptime и диск под контролем
VPS это не готовый продукт, а платформа для разных задач: сайта, бота, API, мониторинга или автоматизации. Начните с одного сценария, не пытайтесь запускать всё сразу. Сначала закройте базовую настройку из чек-листа: SSH-ключи, firewall, обновления, бэкапы и мониторинг. После этого разверните минимальную рабочую версию сервиса и расширяйте конфигурацию по мере роста нагрузки.
Облачный инстанс создан, SSH-доступ работает, и первое, что хочется сделать, это запустить приложение. Но новый сервер в этот момент уязвим: root-доступ может быть разрешён, часть пакетов требовать обновления, firewall ещё не настроен, мониторинга нет. Автоматические сканеры находят новые IP-адреса за минуты и начинают перебор паролей ещё до того, как вы откроете второй терминал.
Настройка облачных серверов перед нагрузкой – это четыре конкретных блока: сеть, пользователи и доступ, firewall, мониторинг. Каждый занимает от десяти минут до получаса. Пропустить любой – значит получить дыру в безопасности и эксплуатации.
Разберём все четыре блока по порядку на примере Ubuntu 22.04 LTS. Все команды воспроизводимы и проверены. Порядок шагов важен: каждый следующий опирается на предыдущий. Не запускайте приложение до настройки firewall: незащищённый VPS с открытым SSH быстро попадает под автоматический перебор паролей.
С чего начинается настройка облачного сервера?
Терминал Ubuntu 22.04 с обновлением пакетов, проверкой синхронизации времени, запущенных служб и свободного места на диске.
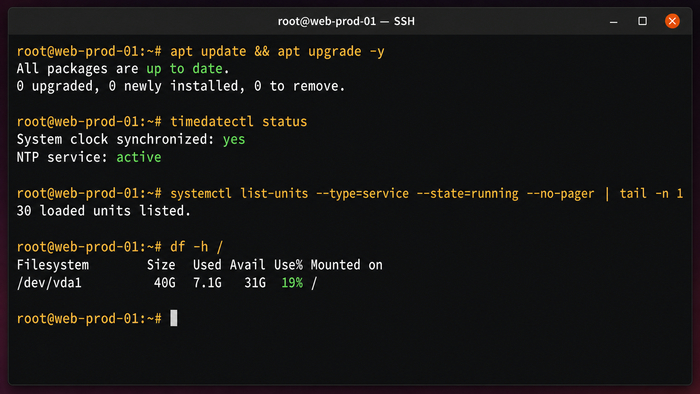
Прежде чем двигаться дальше, нужно привести систему в актуальное состояние. Образы облачных провайдеров зачастую собираются заранее и поставляются с пакетами недельной или месячной давности. Первое же обновление нередко закрывает десятки CVE, включая критические в OpenSSH и ядре. Выполните:
apt update && apt upgrade -y
Если обновление затронуло ядро – перезагрузите сервер. После перезагрузки убедитесь, что соединение восстановилось, и продолжайте.
Следующий шаг – проверить синхронизацию времени. Расхождение системных часов ломает TLS-рукопожатие, сбивает JWT-токены и делает логи бесполезными при сравнении событий с разных хостов. На Ubuntu 22.04 за это отвечает systemd-timesyncd. Проверьте его статус:
timedatectl status
В строке NTP service должно стоять active. Если нет – включите вручную:
systemctl enable --now systemd-timesyncd
Также сразу посмотрите, что уже запущено на сервере, и сколько свободно дискового пространства. На минимальном образе Ubuntu 22.04 запущено около 25–30 системных сервисов. Если их заметно больше, образ уже преднастроен провайдером:
Если корневой раздел занят более чем на 80%, разберитесь с этим до любых дальнейших шагов: нехватка места ломает обновления пакетов, ротацию логов и запись временных файлов.
Настройка сети на облачном сервере
Терминал Ubuntu 22.04 с проверкой сети, настройкой статического IP через Netplan и изменением имени облачного сервера.
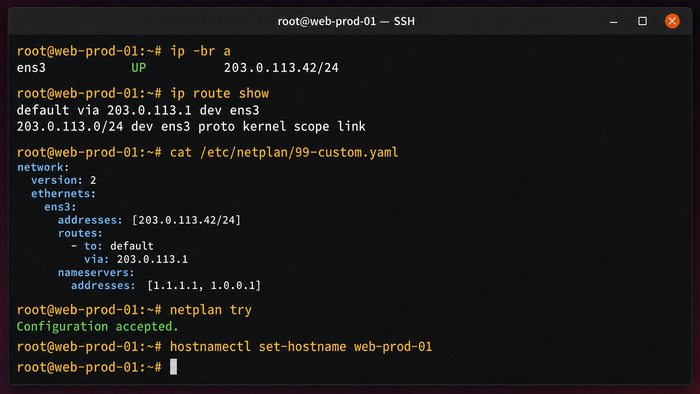
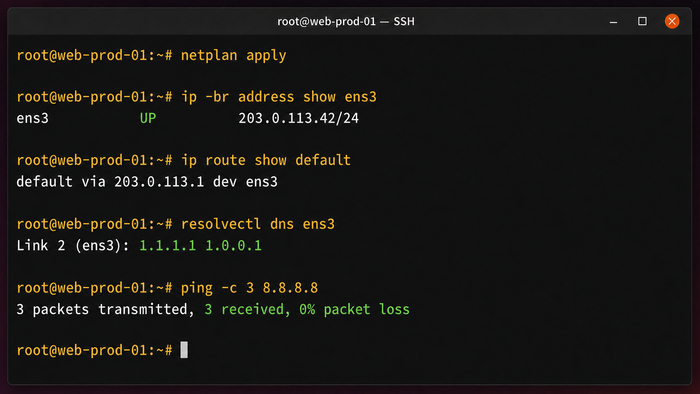
Начните с просмотра текущего состояния сетевых интерфейсов. Две команды дают полную картину: какие интерфейсы подняты, какие IP назначены и куда идёт маршрут по умолчанию.
ip a
ip route show
В выводе ip a найдите интерфейс с публичным IP-адресом – обычно это ens3, ens4 или eth0, в зависимости от провайдера. Запомните его имя: оно понадобится в конфигурации netplan.
На Ubuntu 22.04 сетевые настройки управляются через netplan: конфигурационные файлы лежат в /etc/netplan/. Если провайдер использует cloud-init для автоматической конфигурации сети, в /etc/netplan/ уже может быть файл 50-cloud-init.yaml. Его можно редактировать, но изменения могут быть перезаписаны cloud-init при следующей перезагрузке или пересоздании конфигурации. Безопаснее создать отдельный файл с более высоким приоритетом, например 99-custom.yaml: числа в именах файлов определяют порядок применения, большее число применяется последним и переопределяет предыдущее.
Пример конфигурации со статическим IP (замените значения на реальные):
Терминал Ubuntu 22.04 с применением Netplan и проверкой IP-адреса, маршрута, DNS и внешнего соединения.
Директива addresses задаёт статический IP с маской. routes описывает маршрут по умолчанию – шлюз, через который идёт весь трафик. nameservers – DNS-серверы; при необходимости укажите серверы провайдера или вашего корпоративного резолвера.
Перед применением проверьте конфигурацию через netplan try: он применит настройки и автоматически откатит их через 120 секунд, если вы не подтвердите. Это страховка от потери соединения. Если всё в порядке – зафиксируйте:
netplan apply
Последний штрих – задать осмысленное имя хоста. Понятное имя упрощает навигацию в логах и мониторинге, особенно когда серверов несколько:
hostnamectl set-hostname web-prod-01
echo "127.0.1.1 web-prod-01" >> /etc/hosts
Диагностика сетевых проблем
Терминал Ubuntu 22.04 с успешной проверкой подключения, DNS-серверов и открытого SSH-порта.
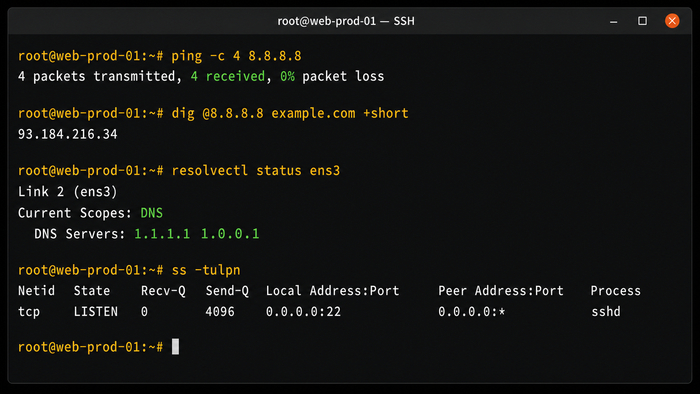
Если после применения netplan что-то пошло не так, три команды помогут локализовать проблему:
Если ping проходит, а dig не разрешает имена – проблема в DNS. На Ubuntu 22.04 DNS управляется через systemd-resolved. Его состояние:
resolvectl status
Если dig не установлен, установите пакет:
apt install bind9-dnsutils -y
В выводе resolvectl смотрите секцию DNS Servers для каждого интерфейса. Если серверы не отображаются или стоит 127.0.0.53, убедитесь, что в файле netplan прописан раздел nameservers, и заново примените конфигурацию.
Команда ss -tulpn полезна не только при диагностике сети: её стоит запускать после каждого шага настройки, чтобы убедиться – ничего лишнего не появилось на открытых портах.
Управление пользователями и доступом (users)
Постоянно работать от root – плохая практика. Опечатка в пути к файлу под root может уничтожить данные без возможности отмены. Любая уязвимость в запущенном от root приложении даёт атакующему полный контроль над системой. При командной работе аудит затруднён: в логах нет разграничения между разными администраторами.
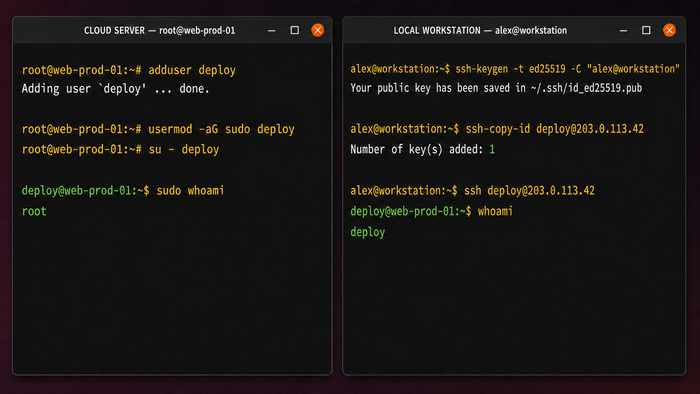
Создайте пользователя для повседневной работы. В Ubuntu удобнее использовать adduser: команда создаёт домашнюю директорию, настраивает оболочку и интерактивно запрашивает пароль.
adduser <name>
usermod -aG sudo <name>
Команда usermod -aG sudo <name> добавляет пользователя в группу sudo. На Ubuntu эта группа по умолчанию имеет право выполнять любые команды через sudo без изменения файла /etc/sudoers. Проверьте, что всё работает не закрывая текущую сессию root:
su - <name>
sudo whoami # должно вывести: root
Для входа по SSH без пароля сгенерируйте ключ на локальной машине и скопируйте публичную часть на сервер. Тип ed25519 предпочтительнее rsa:
# На локальной машине
ssh-keygen -t ed25519 -C "user@pc_name"
ssh-copy-id <name>@<IP_сервера>
Два терминала: создание пользователя deploy и проверка sudo на Ubuntu-сервере, генерация и копирование SSH-ключа с локального компьютера.
Два терминала: создание пользователя deploy и проверка sudo на Ubuntu-сервере, генерация и копирование SSH-ключа с локального компьютера.
Если нужно добавить публичный ключ вручную – создайте структуру директорий самостоятельно. Разрешения важны: 700 на директорию, 600 на файл:
После настройки ключа войдите в новый сеанс под пользователем через SSH. Убедитесь, что аутентификация по ключу работает, и только после этого переходите к следующему шагу.
Безопасные настройки SSH
Настройка SSH на сервере сводится к нескольким директивам в /etc/ssh/sshd_config. Ключевой принцип: ограничить поверхность атаки. Откройте файл:
nano /etc/ssh/sshd_config
Перед отключением парольного входа не закрывайте текущую root-сессию и убедитесь, что вход по SSH-ключу работает в новом терминале. Если в конфиге или ключах есть ошибка, SSH-доступ можно потерять, и восстанавливать его придётся через консоль провайдера, VNC/KVM или rescue mode.
Внесите следующие изменения:
# Запретить прямой вход под root
PermitRootLogin no
# Только ключи; пароли не принимать
PasswordAuthentication no
PubkeyAuthentication yes
# Разрешить вход только указанному пользователю
AllowUsers deploy
# Сократить время и попытки аутентификации
MaxAuthTries 3
LoginGraceTime 30
PermitRootLogin no закрывает наиболее атакуемый вектор: большинство автоматических сканеров перебирают именно root. PasswordAuthentication no убирает парольный вход полностью после этого единственным способом войти остаются SSH-ключи. AllowUsers deploy добавляет дополнительный слой: даже если на сервере появятся другие пользователи, по SSH они войти не смогут.
Директива AllowUsers особенно полезна при командной работе: она задаёт явный белый список тех, кто может войти по SSH. Новый пользователь, не включённый в список, не получит доступ даже с корректным ключом.
Перед перезапуском проверьте синтаксис конфига, ошибка в директиве заблокирует вас при работающем соединении:
sshd -t # пустой вывод означает: конфиг корректен
systemctl restart ssh
Откройте новый терминал и убедитесь, что вход по ключу работает, прежде чем закрывать текущую сессию. Это самая частая ошибка при настройке SSH: отключают парольный вход до того, как проверяют, что ключ принимается.
Дополнительно: смена стандартного порта 22 на нестандартный снижает количество автоматических сканирований и шум в логах. Если решите сменить, сначала откройте новый порт в UFW, затем измените Port в конфиге и перезапустите sshd, не наоборот.
Настройка firewall: UFW и iptables
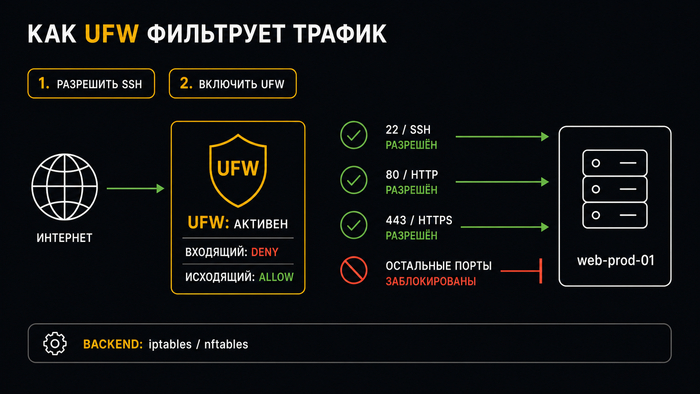
UFW – стандартный инструмент управления firewall на Ubuntu. Он даёт простой интерфейс для настройки правил, а конкретный backend зависит от версии Ubuntu и конфигурации системы: это может быть iptables-совместимый слой или nftables. На новом сервере UFW установлен, но часто не активирован.
Настройка облачных серверов без активного firewall оставляет все порты открытыми. Порядок имеет значение: сначала разрешить SSH, потом включать UFW, иначе заблокируете собственное соединение:
ufw default deny incoming # всё входящее – запрещено по умолчанию
Если SSH настроен на нестандартный порт, замените 22 на него. Правило ufw status verbose покажет активные разрешения и политику по умолчанию – полезно сверить сразу после включения.
Для отладки сначала используйте вывод UFW:
ufw status verbose
Если нужно посмотреть низкоуровневые правила, используйте инструмент, который соответствует backend системы:
iptables -L -n --line-numbers
или:
nft list ruleset
На Ubuntu 22.04 UFW может работать через iptables-совместимый backend или nftables. Поэтому не стоит ориентироваться только на одну цепочку INPUT: фактическое расположение правил зависит от backend и конфигурации системы.
Для автоматической блокировки IP-адресов после нескольких неудачных попыток входа установите fail2ban:
apt install fail2ban -y
systemctl enable --now fail2ban
Создайте файл пользовательских настроек /etc/fail2ban/jail.local. Редактировать jail.conf напрямую не стоит – он перезаписывается при обновлении пакета:
[DEFAULT]
bantime = 1h
findtime = 10m
maxretry = 5
[sshd]
enabled = true
При таких настройках IP блокируется на час после пяти неудачных попыток входа за десять минут. Перезапустите сервис и проверьте статус jail:
systemctl restart fail2ban
fail2ban-client status sshd
В выводе Currently banned покажет количество активных блокировок. Разбанить конкретный IP можно командой fail2ban-client set sshd unbanip <IP>. Кроме SSH, fail2ban поддерживает джейлы для nginx, apache2 и postfix. Они конфигурируются аналогично, добавлением отдельных секций в jail.local.
Мониторинг облачного сервера
Мониторинг сервера Linux без агентов начинается со встроенных инструментов. Для быстрой диагностики их вполне хватает:
Для постоянного мониторинга с метриками и алертами нужен агент. Выбор зависит от контекста: если в инфраструктуре уже есть Prometheus, оптимален node_exporter – он экспортирует более 800 метрик ОС с минимальным потреблением ресурсов (около 20–50 MB RAM):
apt install prometheus-node-exporter -y
systemctl enable --now prometheus-node-exporter
Агент слушает на порту 9100 и отдаёт метрики в формате Prometheus по адресу http://<IP>:9100/metrics. Добавьте этот адрес как scrape target в конфигурацию Prometheus, и метрики появятся в Grafana. Не открывайте порт 9100 наружу: ограничьте доступ через security group, UFW или приватную сеть Prometheus.
Если Prometheus ещё нет – Netdata даёт готовый интерактивный дашборд из коробки, без дополнительной инфраструктуры:
apt install netdata -y
systemctl enable --now netdata
Netdata слушает на порту 19999. Настройте SSH-туннель для разового просмотра или nginx с basic auth для постоянного доступа. Netdata потребляет от 100 MB RAM, на VPS с 1 GB это существенная разница по сравнению с node_exporter.
Алерты настраиваются поверх метрик. Для node_exporter используйте Prometheus Alertmanager: правила на PromQL, уведомления в Slack, email или PagerDuty. Для Netdata встроена собственная система уведомлений – настройте её в /etc/netdata/health_alarm_notify.conf. На практике для старта хватает трёх порогов: CPU load выше числа vCPU, диск выше 85%, список упавших сервисов непуст.
Что мониторить в первую очередь
На только что настроенном сервере важны шесть базовых показателей:
CPU load average – если значение устойчиво превышает количество vCPU в течение 5–10 минут, сервер перегружен. htop или uptime показывают три скользящих средних: за 1, 5 и 15 минут.
Память – при использовании свыше 85% система начинает активно использовать swap, что резко увеличивает latency. Для веб-серверов и баз данных это ощутимо. Контролируется через free -h.
Диск – заполненность свыше 80% блокирует запись логов, временных файлов и данных приложений. Дополнительно следите за iostat (из пакета sysstat) – высокий await при умеренной нагрузке указывает на проблемы с хранилищем.
Failed services – systemctl --failed выводит список упавших юнитов. Перед выводом в продакшен этот список должен быть пустым.
Auth log – journalctl -u ssh --since "1 hour ago" покажет активность после настройки fail2ban. Строки Failed password могут продолжать появляться до бана или с других IP-адресов. Важнее проверить, что fail2ban видит попытки входа и добавляет нарушителей в jail; строки Accepted publickey должны соответствовать вашим успешным входам.
Открытые порты – ss -tulpn один раз после каждого изменения конфигурации. Всё, что слушает наружу, должно быть в явном белом списке UFW.
Чек-лист финальной проверки
Пройдитесь по списку перед открытием сервера под рабочий трафик:
• Непривилегированный пользователь создан, добавлен в sudo
• Перед отключением парольного входа проверен вход по SSH-ключу в новом терминале
• PasswordAuthentication no и PermitRootLogin no прописаны в sshd_config
• UFW включён: ufw status verbose показывает только нужные порты
• fail2ban запущен: fail2ban-client status sshd показывает активный jail
• Пакеты обновлены: apt upgrade -y выполнен, при обновлении ядра – перезагрузка
• NTP активен: timedatectl показывает NTP service: active
• Мониторинг-агент запущен и метрики доступны
• Бэкапы настроены через панель провайдера или отдельный инструмент
• systemctl --failed возвращает пустой список
• Имя хоста и /etc/hosts настроены корректно
Четыре блока: сеть, пользователи, firewall, мониторинг – это минимальная конфигурация, без которой облачный сервер не готов к продакшену. Пропуск любого из этих шагов рано или поздно даёт о себе знать: либо взломом, либо аварией без видимой причины, либо часами поиска проблемы в логах.
Сохраните этот гайд и пройдитесь по нему при следующем деплое нового инстанса. В блоге Aeza регулярно выходят материалы по администрированию и безопасности серверов – подпишитесь, чтобы не пропускать NETTOWN5 обновления.