Опять вышел в рынок вакансий. Лично кажется, что вакансий стало меньше в IT, что не касается гигантов. Например T-банк вообще без остановки спамит вакансиями по городам, Сбер всех троллит и заставляет общаться с роботом. МТС, ВБ, Озон - лично у меня отказы. Про Яндекс уже и писать не хочется, зашквар
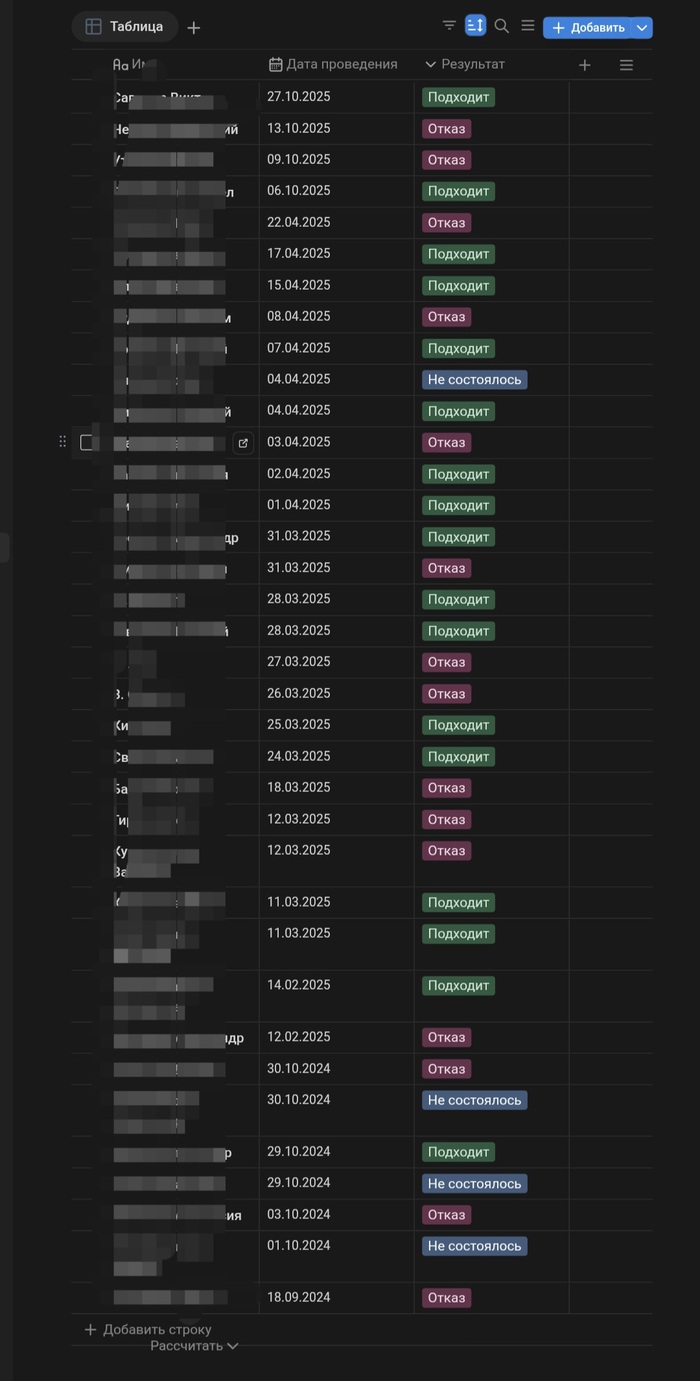
Тут кто то сказал собеседование в IT? Есть мне что сказать. Самый объективный показатель - приложенный скрин моей таблицы собеседований с результатами. А тепепь подробнее:
В течении года (даты есть на скрине) был учисиленный поиск Java-разработчиков. В сумме надо было 3 человека на усиление текущей команды. Я - тимлид и сам Java-разработчик, проводил технические собеседования. Т.е. до меня дошли уже те, кого просеили наши HR. Сначала штатные, потом наняли стороннего т.к. не справлялись наши. А теперь что мне запомнилось:
1. Сюда не попали те, кого я отсеивал после просмотра резюме. Самый забавный случай - указанны некорректнын данные по опыту. Как я понял? Смутило что у нескольких был опыт работы в компании, по названию которую я даже не нашел, вообще 0 упоминаний в интернете. Так бы и не обратил внимания, но реально попалось сразу в нескольких резюме поэтому полез искать. Подозреваю резюме им помогали составлять всякие упомянутые "менторы" на курсах по прошраммированию.
2. Использование ИИ при собеседовании. Я не противник ИИ, даже сейчас сам используют для ускорения работы. Но ИИ в разработке это инструмент а не замена. Как говорю всегда своим протеже - сначала должен идти ваш мозг, потом искуственный. Наоборот не работает. Из самого вопмющего запомнилась молодая девушка. На теоритичнские вопросы отвечала сначала расплывчато а потом правильно. Но как дошло дело до практики все стало понятно. Собесы проходили удаленно по видео с камерой. И взгляд у нее в процессе написания кода бегал то влево то вправо. И писала сразу сходу вск правильно и подряд по строчкам. Для тех кто нн в ИТ приведу аналогию. Вот вы пишете реферат. Сначала пишите введения, сразу без единой ошибки. Потом глава 1 сразу без ошибок, затем следующую главу и т.д. и вск время куда подглядываете. Правда подозрительно? Более естественно человеку написать оглавление, потом писать каждый пункт из оглавления попутно внося правки в ранее написанное. С написанием кода так же. На том девушка и спалилась.
3. Амбиции и "опыт". В резюме вск красиво, теория вроде ничего. Но как дело доходит до места, где нужно ее просто заучить а думать, то все сразу сыпется. А требования были сразу как у твердого мидла.
А в принципе и все. Сейчас все уверены что достаточно пройти собес и жизнь сразу наладится. По началу из за малогл опыта я таких (одного точнее) пропускал. Сразу виден уровень работы и распрощаться с подобными ребята приходилось довольно быстро.
Если нужны какие то советы:
1. Прохождение интервью это отдельный навык. Но качать толькл его без прокачки нужных навыков для работы бессмысленно.
2. Софтскилы. Была история найма хорошего по хардам разработчика но с никакими софтамт. А это значит организовать его работу с командой невозможно. Харды прокачать легко, а вот если человек нкорганизованный и необщительный это уже не поменять, а команда получает обузу.
3. Возраст в разработке не важен. Нанимали и ребят студентов и мужиков за 40. Что имеет значение см. два предыдущих пункта.
4. Ну и еще раз для точного понимания - ИИ это помощник а не раб, который будет выполнять за вас все. Если в компании ксть маломалькое ревью то ни один опытный разработчик не пропустит пустой код нейронки, потому что потом его придется очень долго править.
Не знаю в какой отрасли ищет работу ТС, но знаю про айти. Что тут сейчас жопа, особенно для начинающих, не имеющих опыта реальной работы людей. В эту категорию входят выпускники ВУЗов, в том числе мой сын. Так как у меня ещё 2 младшие дочки, требовалось дать сынуле пинка под жопу обеспечить молодому специалисту хорошее рабочее место.
Я сам в айти уже 30 лет, так что понятно что сверх теоретической университетской программы дал парню хорошие знания и практику, погонял в реальных проектах, нарисовал в резюме красивые и правильные вещи. Но, увы, на сегодня этого мало...
В процессе общения со знакомыми сына, которые достигли успешного успеха, выяснилось что лучше всего брать специального ментора, которые предметно натаскивает на собесы. И по технолониям и по софт скиллам и по внутренним правилам, в которые надо тупо попадать чтобы пройти на следующий этап. Ну это как подготовка к ЕГЭ, которая имеет мало общего со знаниями и наукой, тупо проработка типовых тем.
Полгода занятий и прохождения тестовых собесов параллельно с подготовкой диплома под моим чутким руководством. Результат - 2 месяца реальных собесов и оффер в одну из ведущих компаний России на 330к грязными в месяц для начала. Считаю, более чем достойно.
Если вам неудержимо хочется использовать оборудование из музея для современной разработки — статья специально для вас.
Машины должны служить а не требовать ресурсы. И автор патча l9 об этом знает.
Эпический баг
Сейчас наверное некоторые читатели сильно удивятся:
с 2007 года в ядре Linux живет серьезный баг, приводящий к полному зависанию системы при работе под большой нагрузкой на память.
На дворе на момент написания статьи май 2025 года, так что баг успел отпраздновать совершеннолетие и открыть первую бутылку пива.
Оригинальный репорт выглядит так:
Разумеется разработчики ядра в курсе проблемы, но по ряду причин.. не считают этот баг важным.
Да, вы правильно прочитали:
«полное зависание системы под нагрузкой» и «разработчики не считают важным исправлять» — как вам такие реалии Linux?
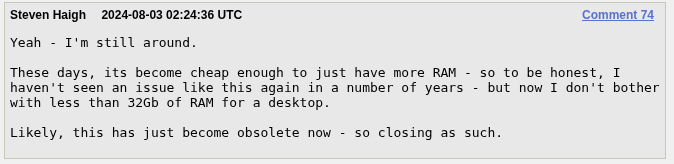
Более того, недавно тикет с описанием этого бага вообще закрыли с эпической формулировкой «just become obsolete»:
С легким намеком, что некоторым стоит перестать собирать себе компьютеры по помойкам:
but now I don't bother with less than 32Gb of RAM for a desktop.
Теперь прокрутите обсуждение бага в трекере вниз и посмотрите на последнее сообщение о проблеме:
Специально сохранил картинкой для истории, вдруг не поверите.
Оно конечно все замечательно и у самого автора этой статьи давно 64Гб на одной из рабочих машин, а некоторые коллеги успели впихнуть даже 128Гб, причем в ноутбук — чтобы мы наконец увидели SUSE Linux, которая не тормозит.
Но к сожалению одними любителями компьютерного антиквариата данная проблема не ограничивается — на нынешние облачные времена типичное рабочее окружение Linux это виртуальная машина, с ограниченным обьемом памяти. Скорее всего даже ваш корпоративный сайт крутится на виртуальной машине с 4Гб памяти.
Так что на самом деле проблема касается практически всех пользователей Linux, а не только идейных нищебродов энтузиастов, собирающих себе оборудование по музеям.
Как так получилось
Если вы хоть немного понимаете в компьютерах, прочитав абзац выше и сопоставив масштаб проблемы и отношение к ней разработчиков Linux, думаю уже сделали определенные выводы:
либо команда разработки ядра Linux — поголовно некомпетентны, либо у автора контракт с рептилоидами в описании выше был упущен ряд важных нюансов.
Правда как обычно где‑то между — «особенных» среди современных разработчиков Linux действительно хватает, но ряд нюансов я все же намеренно упустил.
Опишу в какой момент проявляется этот баг:
надо долго и упорно увеличивать нагрузку на использование памяти, причем маленькими порциями и обязательно из нескольких разных процессов — чтобы OOM Killer не успел отработать.
На практике надо либо заниматься тренировкой нейросетей, либо непрерывно гонять тяжелые приложения на Java/Node (в первую очередь IDE) и постоянно запускать сборку больших проектов.
И все это на неподготовленном офисном оборудовании с 4-6 Гб памяти, представляющем историческую ценность, либо в виртуальной машине.
Патч l9ec
Уже давно существует неофициальный патч, решающий описанную проблему с зависанием квадратно-гнездовым радикальным способом:
The kernel does not provide a way to protect the working set under memory pressure. A certain amount of anonymous and clean file pages is required by the userspace for normal operation. First of all, the userspace needs a cache of shared libraries and executable binaries. If the amount of the clean file pages falls below a certain level, then thrashing and even livelock can take place.
По сути этим патчем формируется небольшой объем памяти (тот самый working set), которую запрещается перегружать даже самым хитрым приложениям, откусывающим память по килобайтам.
Разумеется патч заметили и тут находится архив эпической переписки в рассылке Linux Kernel длиною в год, где автор патча пытается объяснить окружающим что он не верблюд и проблема действительно есть.
Однако патч в мейнстрим так и не попал, что наводит на определенные нехорошие мысли.
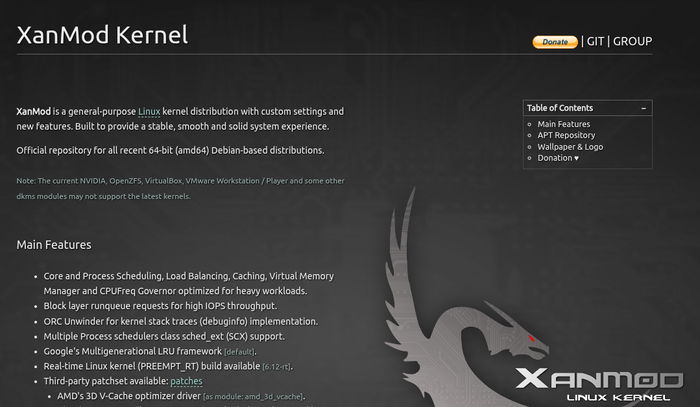
История с Xanmod
Помимо основной версии ядра т. н. «vanilla», исходники которого выкладываются на широко известном kernel.org, существуют «васянские сборки» — наборы патчей ядра, собранные энтузиастами под конкретную задачу.
Одна из таких сборок называется Xanmod и посвящена работе современного ядра на desktop-системе с минимальными визуальными задержками:
XanMod is a general-purpose Linux kernel distribution with custom settings and new features. Built to provide a stable, smooth and solid system experience.
Так вот на момент появления l9ec патча, он был включен в сборку Xanmod:
Но в последних 6.х версиях Xanmod его уже нет, на что есть формальная причина — появление вот этого патча, вроде как окончательно решающего проблему c зависанием:
На данный момент MGLRU в mainline и скорее всего работает прямо сейчас и у вас в системе, если конечно у вас современный линукс и MGLRU не отключен вручную.
К сожалению принцип работы MGLRU другой (см. комментарий выше про 32Гб памяти на десктопе) и тестировался его функционал тоже в другом месте:
On Android, our most advanced simulation that generates memory pressure from realistic user behavior shows 18% fewer low-memory kills, which in turn reduces cold starts by 16%.
Как нетрудно догадаться, «realistic user behavior» на мобильном Android несколько отличается от тотальной перегрузки тяжелыми средствами разработки на дохлом десктопе или еще более слабой виртуальной машине.
Поэтому «продвинутым пользователям Linux» в очередной раз придется заботиться о себе и своих проблемах самостоятельно.
Эта история — еще одна причина, по которой стоит использовать *BSD. Реклама.
Портирование на 6.х ядро
К сожалению автор патча l9 видимо устав бодаться с идиотами, не стал переносить свой замечательный патч в 6.х ветку ядра, решив что раз более умные ребята из Google выкатили MGLRU — от его решения толку больше не будет.
Как ни странно, но это не так и l9 патч куда более предсказуем и надежен как удар ломом, в отличие от цирка с аж 14 патчами MGLRU:
These initial multi-generational LRU patches amount to 14 patches at the moment and in a patched kernel can be enabled via the LRU_GEN Kconfig switch
Собственно эта статья появилась на свет после того как автор опять словил зависание под нагрузкой во время работы над большим проектом, из-за чего и решил откопать дедовский пулемет портировать известный патч в 6.х ядро.
За основу был взят последний патч для 5.х ветки без учета MGLRU: le9ec-5.15.patch а его логика добавлялась в Xanmod-версию ядра 6.14.5.
Ниже по шагам объясняю как выполнить перенос логики патча, чтобы процедуру можно было повторить и на более новых ядрах и на «vanilla» версиях.
Скачиваем архив с Xanmod ядром и l9-патч по ссылкам выше и распаковываем.
Стоит сразу предупредить, что размер текущей версии ядра Linux в распакованном виде ~1.8 Гигабайт, а для сборки понадобится еще ~28 Гигабайт.
Вот такие нынче ядра.
Разумеется применить готовый diff автоматически для ветки 6.х не получится, так что будем переносить логику патча по шагам.
Всего в рамках патча изменения происходят в пяти файлах:
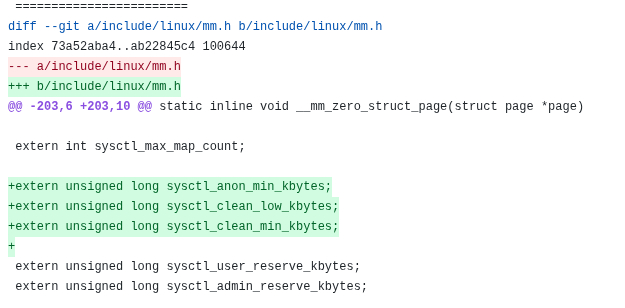
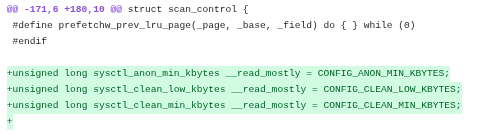
Поскольку исправлять документацию нам не очень актуально, первый файл можно пропустить. Таким образом первое актуальное исправление находится в файле include/linux/mm.h, куда добавляются глобальные переменные, отвечающие за настраиваемые лимиты:
Все что нужно сделать — вставить строки в файл include/linux/mm.h:
/* * Force-scan anon if clean file pages is under vm.clean_low_kbytes * or vm.clean_min_kbytes. */ if (sc->clean_below_low || sc->clean_below_min) { scan_balance = SCAN_ANON; goto out; }
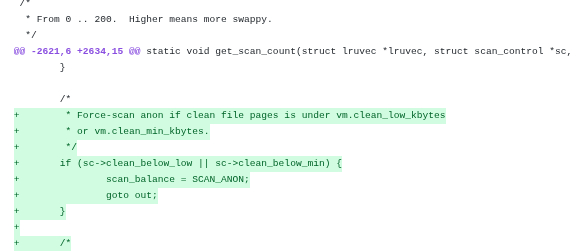
Следующая правка в этом же файле должна быть вставлена в этот же метод get_scan_count, но ниже по коду — ориентируйтесь на строку nr[lru] = scan;благо она такая одна:
Я вставил логику проверки сразу над ней:
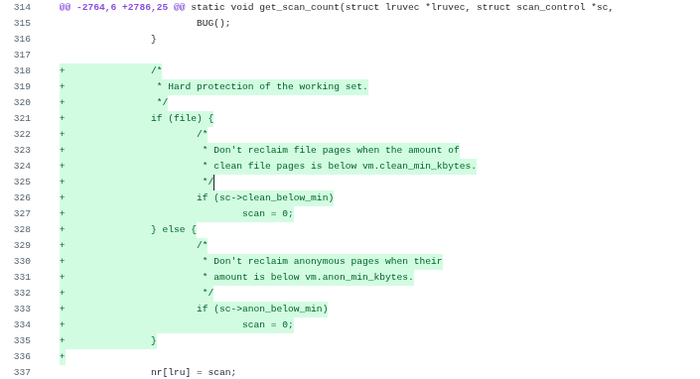
/* * Hard protection of the working set. */ if (file) { /* * Don't reclaim file pages when the amount of * clean file pages is below vm.clean_min_kbytes. */ if (sc->clean_below_min) scan = 0; } else { /* * Don't reclaim anonymous pages when their * amount is below vm.anon_min_kbytes. */ if (sc->anon_below_min) scan = 0; } nr[lru] = scan;
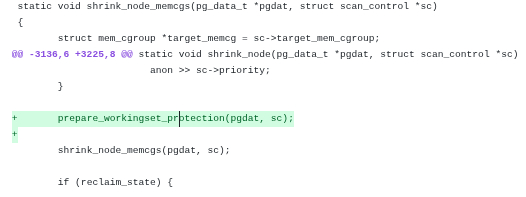
Следующей правкой добавляется новая функция prepare_workingset_protection, которая должна вызываться из существующего метода shrink_node_memcgs:
Так что вам надо найти функцию shrink_node_memcgs (она такая одна) и вставить новую функцию prepare_workingset_protection над ней:
static void prepare_workingset_protection(pg_data_t*pgdat, struct scan_control *sc) { /* * Check the number of anonymous pages to protect them from * reclaiming if their amount is below the specified. */ if (sysctl_anon_min_kbytes) { unsignedlong reclaimable_anon;
/* * Check the number of clean file pages to protect them from * reclaiming if their amount is below the specified. */ if (sysctl_clean_low_kbytes || sysctl_clean_min_kbytes) { unsignedlong reclaimable_file, dirty, clean;
reclaimable_file = node_page_state(pgdat, NR_ACTIVE_FILE) + node_page_state(pgdat, NR_INACTIVE_FILE) + node_page_state(pgdat, NR_ISOLATED_FILE); dirty = node_page_state(pgdat, NR_FILE_DIRTY); /* * node_page_state() sum can go out of sync since * all the values are not read at once. */ if (likely(reclaimable_file > dirty)) clean = (reclaimable_file - dirty) << (PAGE_SHIFT - 10); else clean = 0;
Собственно последняя правка это вызов новой функции из существующей shrink_node_memcgs:
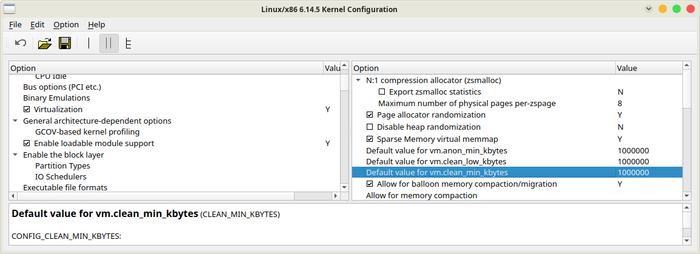
После внесения всех этих исправлений, запускаем один из вариантов настройки ядра:
make xconfig
И наблюдаем новые поля настройки:
Цепочка сборки и установки ядра совершенно стандартная:
make && make modules && make modules_install && make install
К сожалению это еще не все и прежде чем патч заработает надо будет отключить MGLRU, который как я уже описывал — успели внести в основную ветку ядра:
cat /sys/kernel/mm/lru_gen/enabled
Должен показать 0x0007 если MGLRU включен, отключить можно командой:
echo 0 | sudo tee /sys/kernel/mm/lru_gen/enabled
Вот тут у автора патча лежат готовые скрипты для автоматизации всего этого цирка. Я же просто добавил строчку с отключением в /etc/rc.local.
Пруфы
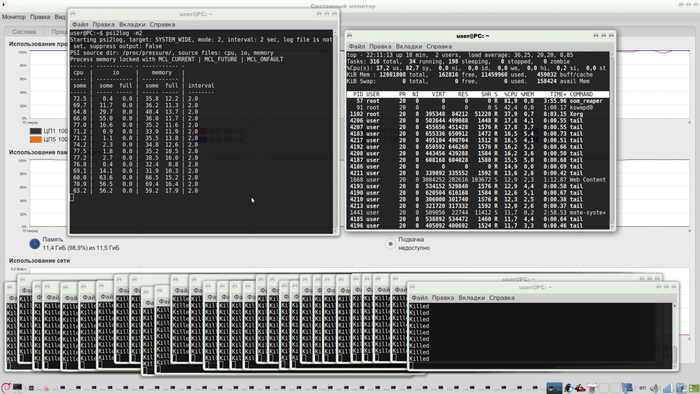
Для тестов портированного патча, был взят один из моих боевых ноутбуков Lenovo Z580 2012го года выпуска, с 8Гб памяти:
На нем постоянно творится всевозможная дичь — тут пять разных операционных систем и куча проектов и инструментов для разработки на каждой.
Поэтому без особого труда были одновременно запущены:
PostgreSQL с реальной базой
MySQL тоже с реальной базой
Intellij Idea
VSCode
Сборка проекта на Node.js с Webpack и hot reload
Сборка достаточно крупного Java-проекта (~3000 исходных файлов)
Chromium с 20 вкладками
Напоминаю что все это на 8Гб реальной памяти и на ноутбукe. Причем в качестве ОС в этот раз была обычная Ubuntu:
Как-то так это выглядит в действии:
Через неделю после публикации я решил пойти еще дальше и поставил пропатченное с l9 ядро на ноутбук 2007 года с 3Гб памяти. И повторил тесты с нагрузкой. Видео тут.
Все более чем работает и пропатченное ядро замечательно отрабатывает свою пайку.
Эпилог
Можно сколько угодно стебаться с пожеланиями «купи себе наконец нормальный компьютер», скажу что намеренно и давно использую старое железо — в первую очередь для оценки производительности создаваемого ПО.
И это одна из причин, по которой у нас получаются технические чудеса вроде Телепорты.
Если вы пока не дошли до столь глубокой стадии просвещения в разработке — все равно стоит знать, что мы ловили подобные зависания и в виртуальных машинах с Linux, например на CI‑сервере при сборке нескольких проектов одновременно.
Так что актуальность описанного все же высокая и как получилось, что столь простой и очевидный патч, который гарантированно решает проблему до сих пор не используют активно — ума не приложу. Ну и разумеется автору патча лучи респекта, благо это лучший представитель отечественной инженерной школы.
Статья была опубликована на Хабре, оригинал, в котором автор статьи себя не сдерживал и в красках рассказал все что думает о разработчиках ядра Linux как обычно можно найти в нашем блоге.
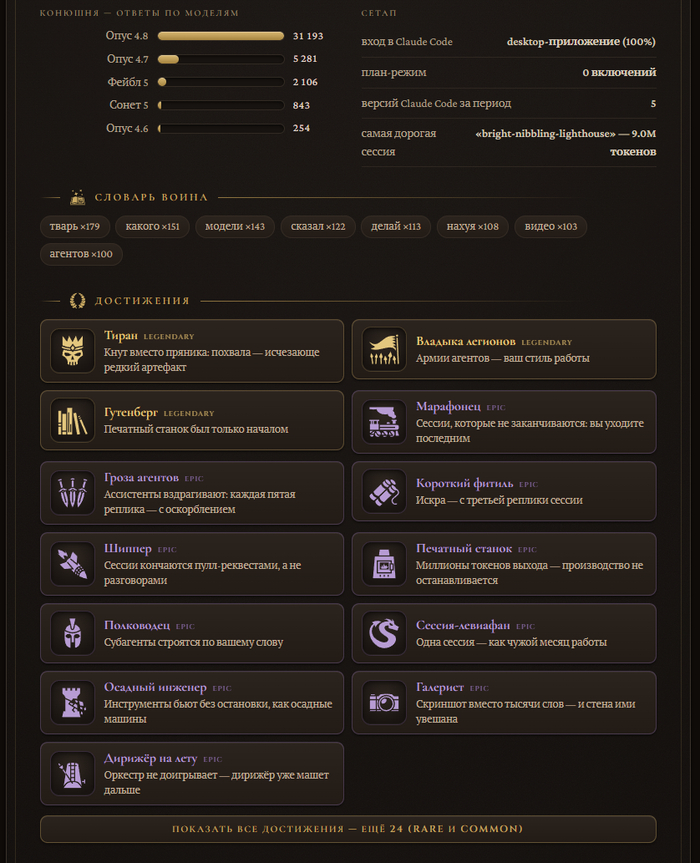
Ваш ИИ-агент давно ведёт на вас досье. Каждая сессия Claude Code тихо ложится на диск в JSONL-логах: каждая команда, каждое «проверь», каждый капс в три часа ночи. У меня таких логов накопилось на 200 тысяч слов за полтора месяца — и в какой-то момент стало интересно: а как я вообще выгляжу со стороны машины?
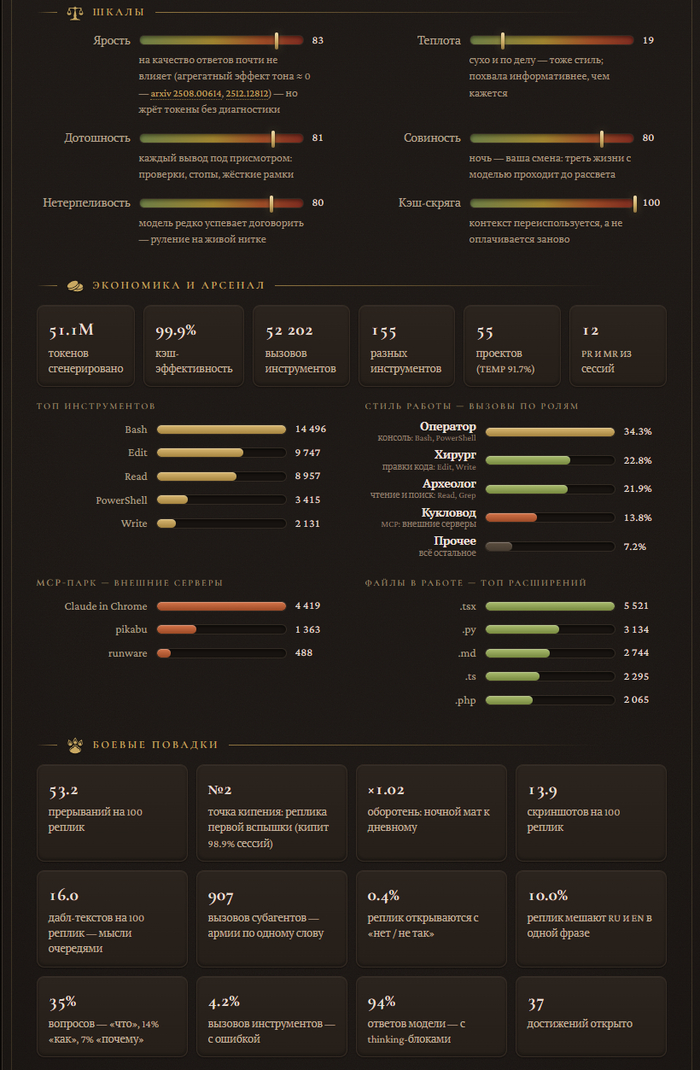
Так родился Prompt Warrior — открытый скилл, который вскрывает этот архив и собирает из него честный психологический портрет того, как вы НА САМОМ ДЕЛЕ общаетесь с нейросетью. И подаёт его так, что скриншотом хочется делиться: с титулом, уровнем и ачивками, как в Стиме. На скрине выше — мой собственный портрет: «Неистовый Командир Терминала 90 уровня, Железная Длань». Летопись, как видите, не щадит никого — даже автора.
Отдельная фишка — «Хроника воина»: короткую биографию по вашим повадкам пишет сама нейросеть, по фактам из профиля. Она заметила, что я почти всё диктую голосом, ругаюсь ночью ровно так же, как днём, и ни разу не открыл план-режим. Выходит пугающе точно и слегка неловко. В хорошем смысле.
Работает это просто: скрипт на чистом Python (только stdlib, ноль зависимостей) читает локальные логи в режиме «только чтение», считает десятки метрик по замороженной шкале SCALE и отдаёт профиль. Дальше агент собирает карточку в стиле старинного гримуара: пергамент, латунь, сургучная печать, иконки с game-icons.net. Формулы у всех одинаковые — так что карточками можно честно меряться с коллегами и выяснять, кто тут настоящий Тиран.
Что скилл вытаскивает из логов. Шесть шкал характера: Ярость, Теплота, Дотошность, Совиность, Нетерпеливость и Кэш-скряга. Цифры, которых вы о себе не знали: индекс оборотня (ночной мат против дневного), точка кипения сессий (на какой реплике случается первая вспышка), частота дабл-текстов, армии призванных субагентов и час суток, в который вы наиболее опасны.
Тут же экономика и арсенал: сколько миллионов токенов сожжено (с дедупликацией повторных записей, как в ccusage), кэш-эффективность, какие инструменты и MCP-серверы в ходу, роли вашего стиля работы — Оператор, Хирург, Археолог или Кукловод — и самая дорогая сессия. У меня, например, одна сессия съела девять миллионов токенов — «Сессия-левиафан», есть за это отдельная ачивка.
Ачивки — как в Стиме, только честнее. Их 74, четырёх редкостей, у каждой своя иконка, а условие получения всплывает при наведении. От простого «Клуба ста» (сто реплик в корпусе) до легендарного «Тирана» — это когда негатива в десять раз больше, чем похвалы, — и «Гутенберга» за 25 миллионов сгенерированных токенов. Пороги заморожены, даром не даётся ни одна. Сразу показываются только legendary и epic, остальные — под спойлером, чтобы не превращать карточку в простыню.
Аватар-монстр в шапке — тоже локальный: собирается офлайн из PNG-слоёв по вашему титулу и эволюционирует, когда меняетесь вы. Никаких нейрогенераций по API — детерминированная сборка, у одного титула всегда одна морда.
Про ДНК проекта. Весь скилл — от первой метрики до последней иконки — собран за одни сутки в диалоге с Claude: он и статистику по своим же логам считал, и дизайн гримуара рисовал, и сам себя потом тестировал с нуля как «свежий пользователь». Финальный штрих вышел рекурсивным: карточку про то, как я командую нейросетью, собрала та самая нейросеть, которой я командовал.
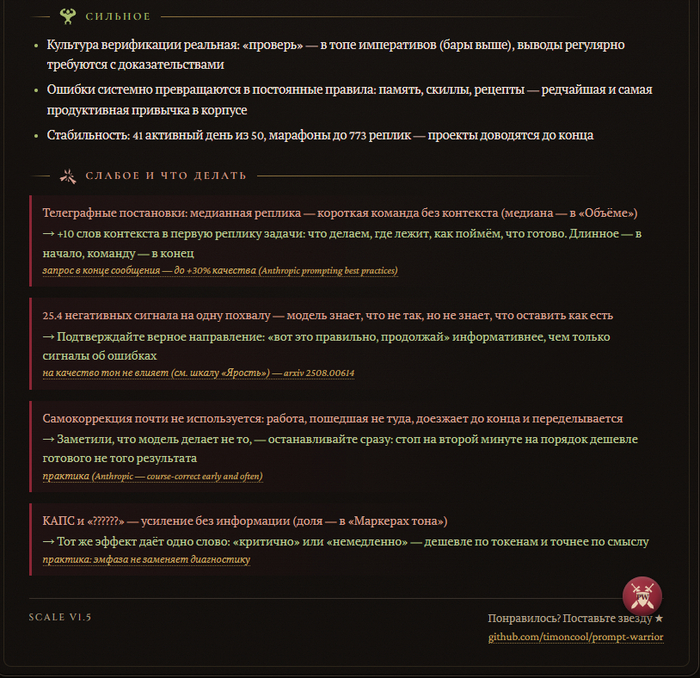
Это не только цирк с ачивками. В конце карточки — разбор сильного и слабого строго по вашим цифрам, и к каждой слабости приложен фикс со ссылкой на исследование или документацию Anthropic. А в базе скилла лежит отдельный список развенчанных мифов промпт-инженеринга — про «магические» приёмы, которые на качество ответов не влияют, только жгут токены.
Установка — самый ленивый способ: в README лежит готовый промпт, вставляете его в Claude Code целиком, и агент сам клонирует репозиторий, прогонит анализ и откроет карточку в браузере. Руками тоже просто: git clone в папку скиллов (~/.claude/skills/), потом сказать агенту «построй мой промпт-профиль» — получите HTML-карточку на русском или английском, виджет и разбор с рекомендациями. Claude Code поддержан из коробки; форматы логов Codex CLI, OpenCode, Gemini CLI и GitHub Copilot задокументированы в репо — идею можно перенести на любой харнесс.
Всё локально, приватно и бесплатно: ни одного сетевого вызова, ни ключей, ни телеметрии — логи не покидают вашу машину, код открыт под MIT. Профиль запоминается локально: вернётесь через неделю — увидите новые ачивки, левел-апы и сдвиги метрик. Никакой пользы для бизнеса, чистое удовольствие: узнать, что ты «Полуночный Верховный Ревизор с Коротким фитилём», — бесценно.
Я знаю одно приложение, которое позволяет снимать и выкладывать в него фото только из камеры внутри приложения. это важно для нашей ситуации из-за кастрюлеголовых любителей зелебобы.
Гдебенз критически важно оснастить возможностью писать есть/нет бензина только при гео около заправки и фото подтверждением.
Прошлый пост еще раз подтвердил, что фактчекинг обязательно должен быть. Я в любой непонятной ситуации включаю камеру и делаю фото/видео. А хохлы даже с ИИ соснут историю с съемкой только из приложухи и гео условно в 100м от заправки.
Вопрос - это реально сделать в краткие сроки и вывести приложение в гугл и апстор?
ИИ против репетитора по программированию: кто выиграл за 30 дней (спойлер: всё неоднозначно)
Представь: нашёл репетитора по Python. Хороший, с опытом в продакшне, объясняет понятно. 3 500 рублей в час, два раза в неделю. Параллельно попробовал ИИ-ментор на . И запустил эксперимент на месяц: что даст каждый?
Вот что вышло.
Неделя 1: репетитор ведёт с разгромным счётом
Первое занятие с репетитором — разбор почему твой код работает, но написан плохо. Репетитор смотрит на функцию в 40 строк и говорит: «Это можно сделать в три». Показывает как. Объясняет list comprehension так, что наконец понимаешь зачем оно вообще нужно.
ИИ-ментор в первую неделю — так себе. Задаёшь вопросы слишком широко, получаешь ответы слишком широко. «Объясни мне Python» — бесполезно. Учишься формулировать точнее.
Счёт после недели 1: репетитор 1 — ИИ 0
Неделя 2: ИИ начинает отыгрываться
Между занятиями с репетитором — пять дней. В эти пять дней застрял на рекурсии. Не понимаешь почему стек вызовов работает именно так.
Репетитор недоступен. Открываешь ИИ-ментор, пишешь: «Объясни мне стек вызовов при рекурсии на примере факториала, пошагово». Получаешь разбор с трассировкой каждого вызова. Переспрашиваешь три раза — ИИ объясняет три раза, без раздражения.
На следующем занятии репетитор спрашивает как разобрался — и удивляется что разобрался сам.
Счёт после недели 2: репетитор 1 — ИИ 1
Неделя 3: неожиданный поворот
Репетитор даёт задачу: реализовать бинарное дерево поиска с операциями insert, search, delete. Две недели назад это звучало бы как заклинание. Сейчас садишься, думаешь, пишешь.
Застрял на delete — удаление узла с двумя потомками. Репетитор на следующем занятии объяснил за 15 минут лучше, чем любая статья.
ИИ-ментор в эту неделю — ежедневные вопросы по теории графов. «Чем BFS отличается от DFS на практике, когда что использовать?» — конкретный ответ с примерами задач. Экзаминатор на той же платформе создал тест по деревьям за минуту — выяснилось что балансировку понимаешь плохо. Лучше узнать сейчас, чем на собеседовании.
Счёт после недели 3: ничья, но оба молодцы
Неделя 4: итог
30 дней, 8 занятий с репетитором, 28 000 рублей... нет, стоп. 8 занятий × 3 500 = 28 000 рублей за месяц. Очень много!
Что дал репетитор: понимание что такое «нормальный код», разбор сложных структур данных с живым объяснением, задачи точно под уровень.
Что дал ИИ-ментор: ответы в любое время суток, объяснение концепций столько раз сколько нужно, тесты для проверки понимания, скорость покрытия теоретических вопросов.
Кто выиграл?
Никто. Или оба — зависит как смотреть.
Репетитор незаменим когда нужен разбор кода живым взглядом и задачи под контролем. ИИ незаменим в промежутках — когда репетитор спит, а вопрос не ждёт.
Если бы пришлось выбирать только одно: на раннем этапе — ИИ дешевле и доступнее. На финальном этапе перед собеседованием — репетитор эффективнее.