Anthropic двадцать четвёртого июля показала Opus 5, и самое интересное в этом релизе вовсе не про интеллект. Оно про деньги. За новую модель просят ровно половину от того, что стоит флагманская Fable 5, а на дешёвой подписке Pro её открыли вообще всем. Разбираюсь, откуда взялась такая щедрость и в каких задачах новинка реально уделывает старшую сестру.
Родословная тут не секретная. Под коммерческой Fable 5 лежит закрытая Mythos, и её, если верить утечкам, внутри компании щупали ещё зимой. Весной запустили служебный проект с названием Glasswing, релиз старшей модели планировали на начало лета, но притормозили после того, как в историю влез Вашингтон.
Полугода за глаза хватает, чтобы с дорогой архитектуры снять облегчённую сборку и выкатить её в массы. Так и появился Opus 5.
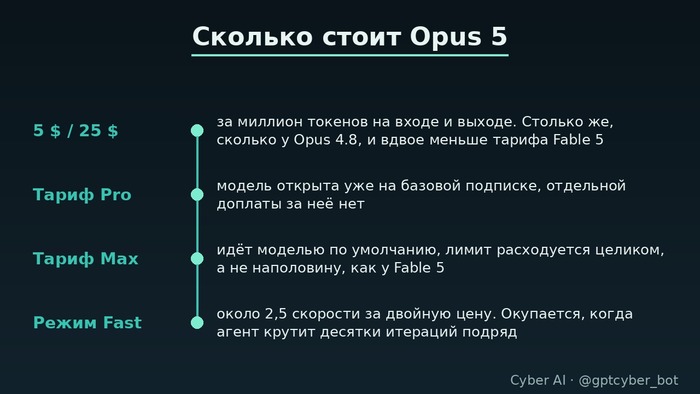
За миллион токенов на входе разработчик отдаёт пятёрку в долларах, за исходящий миллион двадцать пять. Ценник не шевелился со времён Opus 4.8 и равен половине того, что берут за Fable 5.
Подписчикам достался бонус поинтереснее. Нейросеть Claude Opus пятой версии закинули в базовый Pro, на тарифе Max она стоит основной, и квота под неё тратится в полном объёме, тогда как у Fable 5 та же квота срезалась пополам. Отдельной опцией докрутили Fast: скорость примерно в два с половиной раза выше за удвоенный ценник. Вещь нишевая, но агенту, который прогоняет десятки итераций подряд, она окупается за вечер.
Официальная формулировка Anthropic звучит обтекаемо: дескать, модель приблизилась к передовому интеллекту старшей версии, отдав половину стоимости. Читается без словаря. Переплачивать ради Fable 5 большинству больше незачем.
В чём новинка обгоняет старшую модель
Преимущество нашлось в трёх дисциплинах, и объединяет их одна деталь. Везде модель работает долго и без человека над душой. Это агентское программирование, корпоративные сценарии на AutomationBench от Zapier и управление компьютером по методике OSWorld 2.0. Точные цифры я собрал в таблицу выше, если коротко: в первой дисциплине отрыв почти в полтора раза, в двух остальных поскромнее, зато уверенный. Тем, кто подбирает нейросеть для написания кода, интересна как раз первая строчка.
На остальном поле ничья с уклоном в размен. Общие знания у обеих моделей практически совпали, в паре кодовых замеров новинка отстаёт на десятые доли. Ощутимо проседает Opus 5 там, где требуется юридическая и медицинская фактура. При двукратной разнице в деньгах это не провал, а честная плата за компромисс.
История с ARC-AGI-3, которую хочется проверить
Громче всего звучит другой результат. На ARC-AGI-3 новая модель забрала 30,2 процента, тогда как прежний рекорд держался на отметке 7,8. Тест устроен зловредно. Испытуемого бросают в пошаговую игру и молчат про правила, разбираться приходится вслепую, а игр там целый набор и у каждой свой характер.
Разрыв почти четырёхкратный и выглядит эффектно, но восторги я бы придержал. Показали этот бенчмарк ещё в марте, задолго до финиша обучения. Открытых заданий в нём горстка, основную часть авторы прячут, однако разобрать доступные и заточить модель под сам формат вполне реализуемо. Обвинений никто не выдвигал, доказательств нет, а хронология складывается уж очень удачно.
Что мне понравилось больше цифр
В отчёте Anthropic есть эпизод, который объясняет модель лучше любой таблицы. Ей подсунули картинку с чертежом механической детали и поставили задачу: получить на выходе код, который воссоздаст такую же деталь в редакторе FreeCAD. Загвоздка в том, что смотреть на картинку модели запретили, зрение отключили специально.
Соперники в такой постановке честно капитулировали. Opus 5 сообразил, что изображение на диске это просто массив чисел, три значения на точку, и написал под него собственный разборщик. Программа вылавливала в массиве отрезки, дуги и стрелки размеров. По сути модель слепила себе примитивное зрение и закрыла задачу. Согласно отчёту, у соперников не вышло даже после пяти заходов.
Рядом лежат ещё две истории. Модели подсунули живой баг из пакетного менеджера, и она добралась до корня проблемы, попутно прикрыв редкий сценарий, мимо которого прошло даже комьюнити-исправление. А разработчик из трейдинговой конторы за один присест сделал с ней парсер котировок под новую биржу. Реальных данных под рукой не оказалось, и модель соорудила себе стенд для проверки самостоятельно.
Знаменатель у всех трёх историй общий. Пятый Opus не сдаёт первое, что получилось, а перепроверяет результат и додавливает задачу.
Отказов стало меньше
Fable 5 славилась паранойей. Пользователи жаловались на отказы там, где отказывать было незачем: устройство мозга у осьминога, парадокс Ферми и прочая безобидная любознательность. Классификаторы в Opus 5 перебрали, и в компании рассчитывают, что ложных срабатываний станет меньше процентов на восемьдесят пять. Сомнительный запрос больше не упирается в стену, его молча передают Opus 4.8. Ответ приходит, просто от модели поосторожнее.
Забавная деталь про безопасность. Искать уязвимости новинку специально не учили, но на профильном замере она почти догнала закрытую Mythos, отстав на полпроцента. Вывод напрашивается неприятный: умение писать хороший код автоматически тянет за собой умение находить в чужом коде дыры. Выручает то, что доводить находку до боевого эксплойта модель умеет плохо, вокруг этого Anthropic и выстраивает оборону.
В биологии всё зеркально, планку не поднимали и оставили как у Opus 4.8, поэтому научные задачи новинка тянет лучше любой другой публичной версии Claude.
Как подступиться из России
Карты российских банков Anthropic не принимает, отсюда два сценария.
Тем, кому claude нейросеть нужна ежедневно, под код, документы и рабочие проекты, подойдёт подписка Claude Pro. На Озоне она лежит обычным цифровым товаром за 3300 рублей, ключ активации приходит на электронную почту сразу после оплаты, ехать никуда не надо.
Тем, кому хватает разовых заходов, подписка избыточна. Opus 5 мы уже подключили в бот Cyber AI, так что погонять модель на своих задачах можно прямо там: TG | MAX
Сухой остаток
Прорыва в интеллекте здесь нет, зато есть точный расчёт. Почти весь потенциал старшей модели продают за половину денег, а в автономной работе новинка ушла вперёд. Если в ближайшие недели не вскроется что-нибудь досадное вроде деревянных формулировок или приступов фантазии, Fable 5 можно спокойно провожать на покой, не дожидаясь версии 5.1.
Расскажите в комментариях, кто уже погонял Opus 5 и на чём он вас удивил.
Больше разборов новых моделей - в нашем канале: TG | MAX