Коротко — как я уперся в потолок железа на 20 FPS, снова обломался с зарубежными знаменитостями, внезапно получил репост от AlexGyver и оформил основу своего рендер движка.
В октябре была собрана первая партия из 10 кубов, изучены конкуренты и реализована первая рабочая концепция. Ноябрь же стал месяцем глубокого погружения в программную часть, битвы за каждый FPS, некоторого разочарования в нейросетях и неожиданного успеха.
Пристегнитесь, это был тот еще месяц.
Глава 1. Погружение в оптимизацию и битва за каждый FPS: фризы, гонка данных и потолок железа.
1-11 ноября.
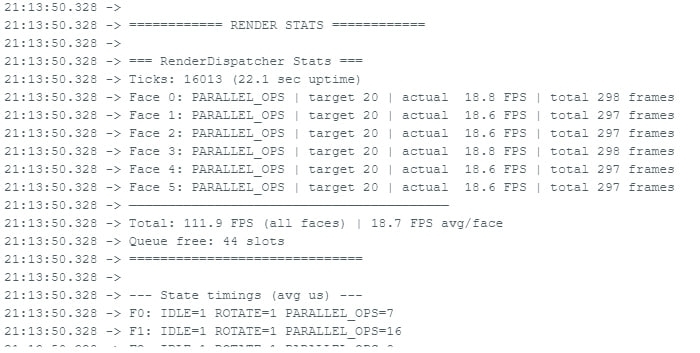
Начало месяца прошло под знаком войны за производительность. Каждый шаг в разработке кубика упирается в нужду в глубокой оптимизации. Вроде бы в ESP32 есть целых 8MB "быстрой" памяти (PSRAM), но ее реальная скорость — всего около 20MB/s при стандартных настройках. Когда нужно на 6 экранов протолкнуть данные (а это по 112 КБ на каждый кадр, итого почти 700 КБ каждую долю секунды), мощный процессор вместо полезных вычислений начинает заниматься тупым переливанием байтов.
Поначалу я пытался решить это с помощью нейросетей, объясняя им свои идеи про параллелизм. Но как спросишь, так и получишь — ИИ выдавал полурабочий код, и стало ясно: придется самому, по старинке, разбираться с семафорами и мьютексами.
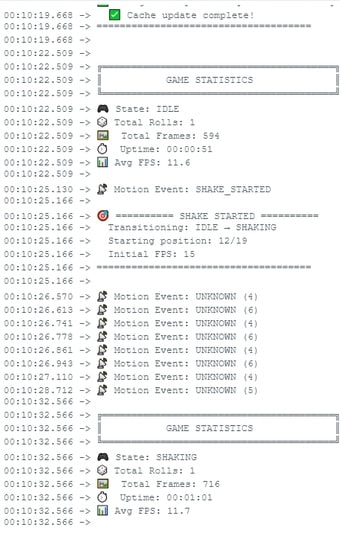
И это дало первые результаты. Сделал класс для перелива данных в фоне и запустил имитацию тяжелых расчетов : последовательное выполнение (перелив + математика + рисовка) дало 15 FPS. А вот параллельное (заливка в фоне + математика + ожидание) — уже 18 FPS на ВСЕХ шести экранах. Уже что-то. Процессор чилил и ждал, пока зальются буферы, а значит, в это время он мог делать что-то полезное.
Следующим шагом стало копание в настройках железа. Оказалось, что можно поднять скорость копирования памяти почти вдвое, с 18 до 40 MB/s! Это был прорыв. Судя по замерам, показ на всех 6 экранах теперь выдавал 25 FPS. Забавно, что этот микроконтроллер для DIY-поделок превращается в карманную игровую машину.
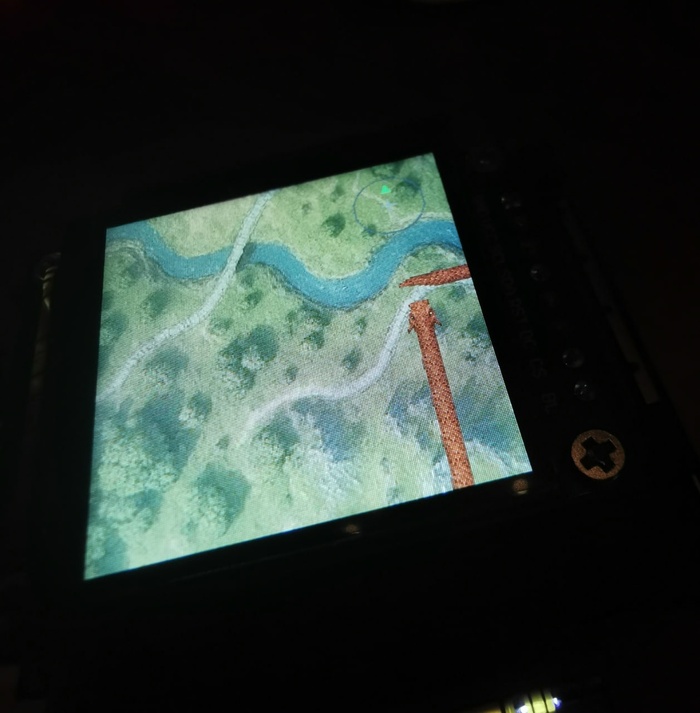
Прикрутил чтение PNG-файлов для фонов и спрайтов с хромакеем и запустил тест с бегающими картинками.
Но радоваться было рано. Появились небольшие фризы и вообще началась “гонка данных” — некоторые экраны, похоже, получали не те данные, показывая артефакты. Вдобавок, один из экранов начал подтормаживать, видимо из-за длинного сигнального провода. Пришлось снижать настройку размера пакетов данных на экраны.
Да, я знаю, что “стабильные 20 FPS” в 2025 году звучит как начало плохого анекдота. Но для микроконтроллера ESP32, который в реальном времени перезаписывает картинку на шесть экранов, это та самая маленькая инженерная победа. А для экспертов по Crysis на калькуляторах — отличная тема для комментариев =)
Глава 2. От хаоса к системе… и обратно. Архитектура, сложность математики и рождение основы рендер движка.
Пока шла борьба за FPS, я параллельно пытался превратить хаос в коде в осознанную систему. Начал разделять код по файлам, выносить константы, все по фэн-шую. Добавил обработку TTF-шрифтов, которые библиотека сама переводила в 4-битный растр.
И в какой-то момент я понял, что то, что начиналось как драйвер для железа, превратилось в нечто большее. После долгих мучений с архитектурой, конечными автоматами (привет, универ!) и руганью с нейросетями, я наконец-то собрал рендер-движок v0.1. Это уже полноценная система на десяток классов.
Вот первая анимация на полном движке. Не особо зрелищно, но оно работает.
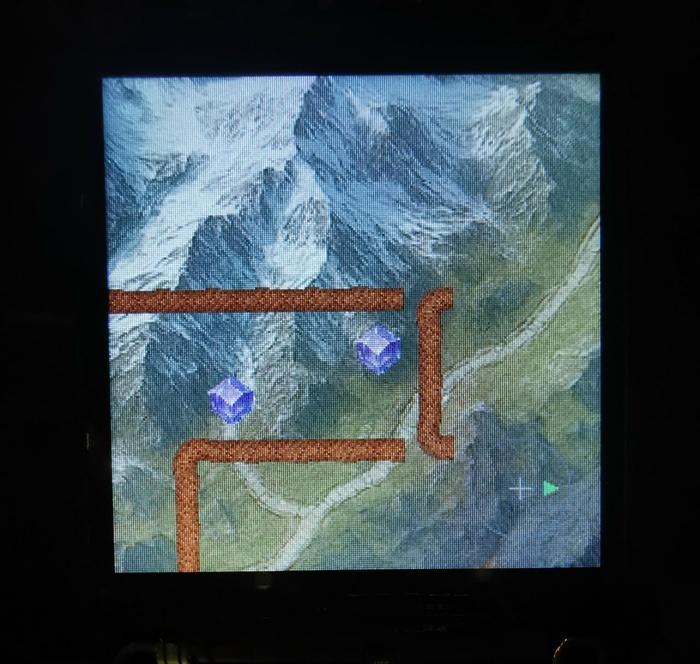
Но путь к движку был тернист. На нем меня поджидала «Змейка»… и ее проклятая математика. Прикрутить текстурки к змейке было легко, а вот заставить их правильно поворачиваться на изгибах — оказалось не простой задачей. Я, понадеявшись на ИИ, раз 20 получал от него разные формулы поворота, и каждый раз получал какую-то дичь. Придется снова, как в старые добрые времена, обклеивать куб бумажками и выводить все формулы вручную.
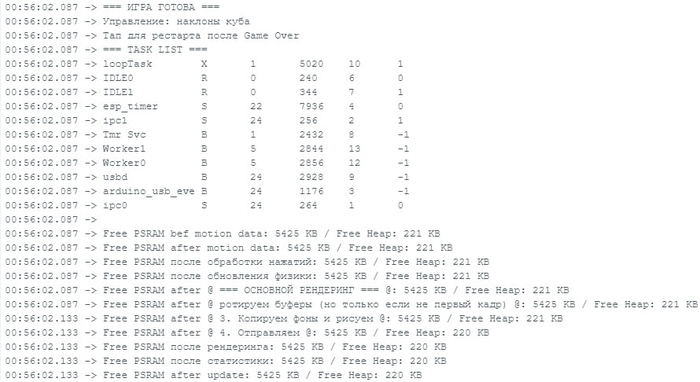
А потом, проверяя, сколько RAM жрет “Змейка”, увидел, что на некоторых этапах съедается почти вся память! Ее всего-то 270 КБ в сумме. Оказалось, PSRAM нельзя напрямую отправлять на экраны, данные все равно сначала копируются в основную RAM память. Пришлось снова переписывать ядро драйвера экранов.
Еще поколдовал с паралелелизмом. PSRAM конечно прям достанется =)
Все функции в коде её хотят и дерутся за неё. В общем, всё та же цифра в 18-20 фпс это потолок.
Глава 3. Маркетинг: погоня за звездами и неожиданный успех
Иногда от программирования ядра тошнит. Хочется не на буковки и циферки смотреть на экране компьютера, а делать шоу. В ноябре продолжил свой принципиальный квест: достучаться до Viva La Dirt League. Reddit забанен, мейл они не читают. Пришлось делать не по изначальному плану: создал комиксы про них и начал бомбить сторисами с отметками всех актеров. Результат: один из топов глянул и… промолчал.
Провал с VLDL меня не остановил. Я переключился на Critical Role, у которых как раз намечалась премьера нового сериала. План тот же: комиксы, видео с кубиком, отметки. И снова — полная, оглушительная тишина. Никто из топов даже не посмотрел.
НО, внезапно, алгоритмы соцсети бустанули мой пост с комиксом))
Поняв, что пока что стучаться к зарубежным миллионникам - не лучшая стратегия, я решил найти своих звезд здесь. Переключился на ту аудиторию, которая говорит со мной на одном языке — на DIY-сообщество.
Сделать контент, который поймут и оценят именно гики и инженеры. Так родилась идея “гача-игры”, из которой выпадают не мечи и щиты, а провода, электронные модули и тд.
Доставить это в комментарии к главному в ру-сегменте DIY-блогеру, AlexGyver.
Расчет оправдался на 100%. Ему зашло, и он репостнул видео к себе в канал.
Вот это видео и сам репост, на память.
На этой волне я завел блог на DTF и начал перезаливать старые посты. Результаты скромнее (пост про змейку набрал 2.8к просмотров против 35к на Пикабу), но радует, что в комментариях писали: «У Гайвера видел такой кубик». Узнаваемость работает =)
Глава 4. Маркетинг: партизанские идеи, провалы и халявные канапешки
Кроме онлайн, надо выбираться на живые встречи с людьми. Впереди Игрокон Lite 2026.
Я написал организаторам с предложением о сотрудничестве — описал свой уникальный проект, и предложил сделать что-то крутое с их брендинком. В ответ пришла отписка, суть которой сводилась к простому: “С вас 15 000 рублей за стол и стул на ярмарке”. Что ж, это было ожидаемо. Видимо, инди-разработчик с уникальным железом менее интересен, чем продавец акриловых дайсов.
Чтож, будет партизанский маркетинг =) Я приду как обычный участник с тремя кубами, в гавайской рубашке Томми Версетти и с кучей 3D-печатных сувениров (и не только). При тряске куба можно будет получить подарок. Посмотрим, кто соберет больше внимания — стол за 15к или энтузиаст с горящими глазами =)
А вот другая выставка, на которую случайно попал в ноябре, стала отличной тренировкой перед Игроконом. Тренировкой провала. Я со своими технологиями абсолютно не вписался в тусовку художников и фотографов (выставка была о народном творчестве в нашем городе). За весь вечер подошло всего пара человек. Но есть и плюсы: я понял, насколько важно правильно выбирать целевые мероприятия, и объелся халявными канапешками. Опыт, пусть и такой.
Глава 5. Рождение игровых механик: от “гачи” к “Алхимслоту”
Весь месяц не только боролся с железом, но и пилил то, ради чего все затевалось — игровые механики. Началось все с переделки “гача-игры” (показ случайных картинок при тряске). И тут же я столкнулся с багом: датчик движения срабатывал через раз. Ни одна нейросеть не смогла найти ошибку в логике. Пришлось снова вспоминать универ и переписывать класс акселерометра на конечном автомате. Теперь все заработало как часы.
Вот так теперь выглядит “гача”: при тряске — “рубашки”, после — анимация смены картинок. Для красивых роликов даже собрал целый натюрморт с игральными костями, бусами и перьями.
Перенос “гачи” на новый движок открыл простор для экспериментов. Так родилась слот-машина: пока трясешь — барабаны крутятся. Можно даже останавливать их резким наклоном. Куб учит обращаться с ним аккуратно: от легкой тряски все медленно движется, а можно раскрутить и пытаться остановить в нужный момент. Это уже не просто “потряс-посмотрел”, а тактильный игровой процесс.
Не "лимонные" картинки ниже, это идея тематики под Utopia Show. Чуть позже планирую доработать стиль иконок, и также отправить как и для AlexGyver.
А потом я пошел дальше и сделал “Алхимслот”: барабаны не просто крутятся, а картинки на центральной линии могут смешиваться, образуя новые. Из этой механики можно придумать кучу игр, начиная с классической «Little Alchemy 2». Вот где кубическая форма начинает раскрываться по-настоящему =)
И вот тут я прямо слышу, как эксперты из комментариев уже набирают сакраментальное: “Автор, все это можно сделать на телефоне! Зачем этот куб?”. И знаете что? Они абсолютно правы. Конечно, можно. На телефоне можно сделать и змейку, и слот-машину, и алхимию.
Более того, они добавят: “В телефоне тоже есть гироскоп, его тоже можно наклонять и трясти!”. И снова будут правы! А теперь, ради эксперимента, попробуйте взять свою 6-дюймовую “лопату” и начать ее резко дергать в руках, как я это делаю с кубом на видео. Попробовали? Чувствуете, как этот стеклянный бутерброд за 50+ тысяч рублей так и норовит вылететь из руки и разлететься на атомы?
В этом и есть разница. Телефон — это прямоугольный, плоский и хрупкий инструмент для связи, который можно заставить делать что-то еще. А куб изначально спроектирован, чтобы его крутили, трясли и даже роняли (он уже летал со стола, все работает). Это как сравнивать езду на городской малолитражке по бездорожью и на специально подготовленном багги. Обе машины поедут, но опыт, комфорт и результат будут совершенно разными.
Этот проект — не про “сделать то, чего нет на телефоне”. Это про “сделать то же самое, но получить совершенно другой, физический и тактильный опыт”. Про то, чтобы держать игру в руках, а не бояться уронить свой основной инструмент для жизни, пытаясь им играть).
Итоги месяца
Ноябрь получился месяцем контрастов: отчаяние от ограничений железа сменялось эйфорией от успешной оптимизации, а оглушительная тишина от мировых звезд — неожиданным признанием в родном DIY-сообществе.
Выжать максимум из железа: Стабильные 19-20 FPS на 6 экранах — это мой личный потолок для этой версии железа. Больше — только с новой архитектурой или другим контроллером.
Создать фундамент: Рендер-движок v0.1 — это огромный шаг вперед. Теперь вместо набора разрозненного кода у меня есть основа системы, на которой можно строить игры.
Получить “знак качества”: Репост от AlexGyver — это не просто хайп. Это подтверждение от авторитета в индустрии, что идея интересна целевой аудитории.
Нащупать новые механики: Слот-машина и “Алхимслот” — это не просто тесты, а уже почти готовые концепции игр, которые родились из экспериментов.
Открытия месяца (или то, что я снова понял):
ИИ — не волшебная палочка. Он хорош для рутины, но когда дело доходит до сложной логики (как с поворотом текстур у змейки) или архитектуры, он тупит и выдает дичь. Думание своей головой и бумажка в клетку все еще надежнее.
Прямой штурм крепости не работает. Погоня за VLDL и Critical Role была похожа на кавалерийский наскок на стены замка. Я получил ценные данные: этот канал коммуникации с ними не работает, по крайней мере, пока. Это не значит, что дверь закрыта навсегда. Это значит, что для следующего штурма понадобится осадная башня, а не просто громкие крики под стенами. Либо удача // обходной лаз в замок.
Персональный подход бессилен, если цель недосягаема. Усилия по созданию кастомного контента для зарубежных миллионников ушли в пустоту, потому что достучаться до них почти невозможно. Тот же подход сработал с Гайвером, потому что он — часть живого комьюнити, а не закрытая корпорация. Вывод: выбирать нужно не только метод, но и реалистичную цель.
Тщательно выбирать правильные мероприятия. Провал на выставке художников — отличный урок.
Ноябрь был месяцем, когда проект перестал быть просто “железкой с экранами” и начал превращаться в игровую платформу. Впереди декабрь, Игрокон и, надеюсь, первые полноценные играбельные прототипы.
P.S. Спасибо, что дочитали! Каждый ваш комментарий, даже самый гневный, помогает проекту двигаться вперед. Следить за разработкой в режиме реального времени можно в моем TG-канале, там я появляюсь каждый день.