


Nvidia за Израиль
Глава Nvidia Дженсен Хуанг высказался в поддержку Израиля.
Ссылка: https://www.jfeed.com/news/tc2wg8
Глава Nvidia Дженсен Хуанг высказался в поддержку Израиля.
Ссылка: https://www.jfeed.com/news/tc2wg8
Друзья, всем привет! Я печатаю целыми днями - посты, статьи, ответы в чатах - и в какой-то момент запястья просто начинают болеть. Пробовал разные браузерные расширения для голосового ввода вроде Voice In, но это какое-то гиблое дело: то текст не вставляется куда надо, то расширение крашится, то работает только в браузере и всё, то лимит кончается. Короче, обплевался.
Начал искать альтернативу и нашел - Epicenter Whispering. Зажимаешь кнопку, говоришь в микрофон, отпускаешь - текст появляется там, где стоит курсор. В любой программе. Этот пост, кстати, тоже надиктован через неё. И самое главное - никому ни за что не нужно платить и может работать даже без интернета.
Работает на уровне всей ОС. Не привязан к браузеру, вставляет текст в любое активное окно - хоть мессенджер, хоть редактор кода, хоть комментарии на Пикабу. Это прям главное отличие от всяких браузерных расширений.
Локальная работа без интернета. Встроенная поддержка моделей NVIDIA NeMo (Parakeet). Всё крутится на вашем компьютере, приватно и бесплатно. При желании можно подключить облачные API (Groq, OpenAI, ElevenLabs), но для большинства задач хватает локальной модели.
LLM-фильтр на лету. Уникальная киллер-фича! Можно прикрутить промпт, чтобы нейронка моментально переписывала сказанное. Наговариваете на эмоциях: «Е**чие пдорасы, вы меня за**али!»*, а она выдает: «Рад вас видеть сегодня, дорогие коллеги».
Режим активации голосом (VAD). Если не хочется постоянно держать кнопку - есть умная активация, которая сама определяет когда вы говорите.
Гибкий вывод. Текст можно отправлять сразу в активное поле (даже настроить автонажатие Enter после вставки) или просто тихо копировать в буфер обмена.
Переходим на GitHub проекта и скачиваем установщик под свою систему из раздела Releases (есть под Windows, macOS и Linux)
Устанавливаем и идём в Settings → Transcription
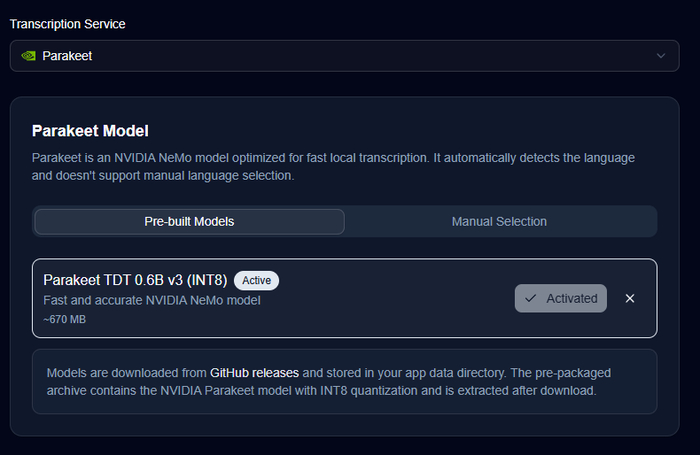
В разделе Transcription Service выбираем «Parakeet» (Local) для быстрой оффлайн-работы
В блоке Parakeet Model выбираем «Parakeet TDT 0.6B v3 (INT8)» - весит около 670 МБ, автоматически определяет язык. Жмём Activated для скачивания
Нажимаем горячую клавишу (по умолчанию Ctrl+Shift+;), говорим текст, отпускаем - готово
Если вы много печатаете и хотите иногда дать пальцам отдохнуть - попробуйте. Если вам надоели глючные браузерные расширения которые работают через раз - тем более. Ну и если хочется поиграться с LLM-фильтром для автоматической обработки надиктованного текста - это вообще отдельное удовольствие.
Это не моя сборка, но реально полезный инструмент который я сам использую каждый день. Такие штуки я регулярно нахожу и выкладываю у себя на канале НЕЙРО-СОФТ - там мы собираем портативные сборки нейросетей, репаки и полезные open-source инструменты, всё на русском и с простыми инструкциями по установке. Если вам заходит такой формат - заглядывайте.
Друзья, поддержите пост плюсиком, если было полезно! А если пользуетесь чем-то похожим для голосового ввода - делитесь в комментариях, интересно сравнить.

Привет, это новый выпуск «Нейро-дайджеста» — коротких и полезных обзоров ключевых событий в мире искусственного интеллекта и технологий.
TL;DR Меня зовут Илья, я основатель сервиса для генерации изображений ArtGeneration.me, блогер и просто фанат нейросетей. Каждую неделю мы с командой осматриваем сотни новостей и делимся с вами самыми актуальными и интересными со ссылками на источники. Всё самое важное — в одном месте. Поехали!
Неделя выдалась насыщенной: куча мощнейших релизов из Китая, которые наступают на пятки GPT-5.2 и Gemini 3. Реалтайм инструменты от Krea и NVIDIA, генеративные модели от Qwen и Hunyuan, а Сэм Альтман честно признал, что OpenAI испортили тексты в последних версиях GPT.
🧠 Модели и LLM
Qwen3-Max-Thinking — китайцы снова впереди
Kimi K2.5 — самая мощная в опенсорсе
LongCat-Flash-Thinking-2601 — уровень GPT-5.2
ERNIE 5.0 — ещё один монстр от китайцев
🎨 Генеративные нейросети
Qwen 3 TTS — клон голоса по образцу
Odyssey 2 Pro — реалтайм видео
HunyuanImage 3.0-Instruct — MoE для редактирования картинок
HeartMuLa — открытый генератор музыки
🔧 AI-инструменты и платформы
Prism — инструмент с LaTeX-редактором для научных работ
PersonaPlex-7B — реалтайм ИИ-собеседник от NVIDIA
Krea Realtime Edit — редактирование в реалтайме
🧩 AI в обществе и исследованиях
Альтман признал, что в GPT-5.2 «сломали» стиль и качество текстов
Глава Google DeepMind: в Gemini не будет рекламы
Парень заменил друзей на ИИ, чтобы играть в Tarkov
Хаби Лейм продал себя за $975 млн

Alibaba выпустила Qwen3-Max-Thinking. В тестах на кодинг и науку модель выдает уровень GPT-5.2 и Claude 4.5, а в математике обходит Gemini 3 Pro.
Главная фишка — технология test-time scaling. Модель запускает параллельные рассуждения для решения сложных задач. Она сама решает, когда надо подключать поиск, память и интерпретатор кода.
Весов в открытом доступе нет — модель слишком огромная для домашнего запуска.
Попробовать уже можно бесплатно в Qwen Chat.
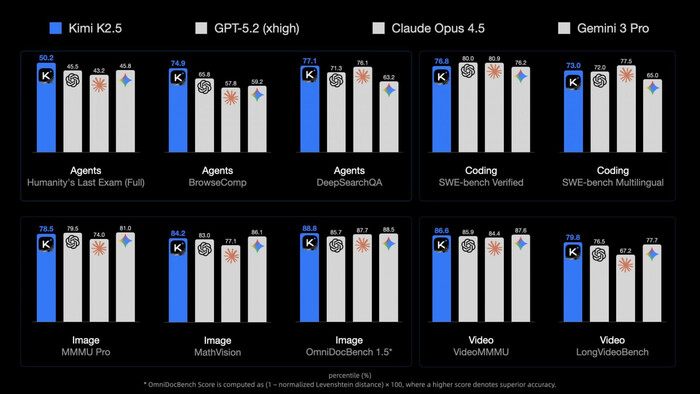
Китайцы из Moonshot AI выпустили Kimi K2.5 — самую мощную на сегодня нейросеть с открытыми весами. Модель мультимодальная, отлично справляется с кодом, особенно с фронтендом, анимацией и графикой, показывая уровень Claude Opus 4.5 и Gemini 3 Pro.
Главная фишка — «Agent Swarm»: нейросеть запускает до 100 субагентов одновременно, ускоряя выполнение сложных задач в 4,5 раза. Агенты создаются динамически, модель сама решает, как распределить работу. Kimi K2.5 может писать код по изображениям или видео — показываешь ей скриншот сайта, а модель воссоздает его.
Режимы Instant и Thinking в чате бесплатны, а «рой агентов» выйдет в $31 в месяц.

Стартап Meituan-LongCat выложили LongCat-Flash-Thinking-2601 — открытую MoE-модель на 560B параметров и 27B активных. В бенчмарках нейросеть идёт наравне с GPT-5.2 и Gemini 3 Pro, а в сложном тесте на математику AIME-25 достигла потолка в 100%.
Здесь тоже главный упор сделан на агентские навыки: работу с инструментами и поиск решений. Модель специально обучали в «зашумленных» средах с искажениями, поэтому она очень стабильна.
Для сверхзадач есть режим Heavy Thinking — в нём нейросеть параллельно ищет несколько путей решения, а затем итеративно их обобщает.
Ещё обновили шаблон чата: теперь он по умолчанию экономит контекст и позволяет опционально сохранять историю рассуждений.
🔗 Попробовать 🔗 GitHub 🔗 HuggingFace

Baidu выпустили ERNIE 5.0 — огромную омнимодальную модель на 2,4 триллиона параметров. Работает с текстом, изображениями, аудио и видео в единой архитектуре.
По бенчмаркам, ERNIE 5.0 идёт наравне с GPT-5 и Gemini 3 Pro. Можно выделить тест MMAU на понимание аудио, тут модель набрала 80 баллов против 70 у GPT-4o-Audio. В задачах с документами и графиками также опережает GPT-5, но пока уступает в кодинге.
Модель построена на архитектуре Mixture-of-Experts, при работе активируется менее 3% от всех параметров, что снижает затраты на вычисления.
Протестировать ERNIE 5.0 можно бесплатно в чат-боте, а API стоит $0,85 за 1 млн входных токенов — дешевле, чем у GPT-5.1.

Alibaba выложила в открытый доступ Qwen3-TTS — модель для синтеза речи, у которой есть две крутые фишки:
VoiceClone — клонирует любой голос всего за 3 секунды аудио. Поддерживается 10 языков, включая русский
VoiceDesign — создаёт абсолютно новый голос с нуля по текстовому описанию. Можно задать тембр, ритм, эмоции и даже характер
Модель обучена на 5 миллионах часов аудио, а задержка синтеза всего 97 мс, идеально для диалогов в реальном времени.
В некоторых тестах Qwen3-TTS превосходит ElevenLabs и GPT-4o-Audio. Веса моделей на 0.6B и 1.7B параметров открыты.
Команда Odyssey изначально целилась на Голливуд, а сейчас сменила курс и представила Odyssey 2 Pro. Теперь они двигают world-models и генерацию в реальном времени.
Главная фишка — скорость и интерактивность. Нейросеть генерирует видео с разрешением 720p и стабильными 22 кадрами в секунду. Ролик появляется почти мгновенно, и его можно тут же редактировать текстовыми командами.
Сами разработчики амбициозно называют это «GPT-2 моментом» для мировых моделей.
Odyssey уже открыли API. Обещают стабильные стримы, которые не упадут через 30 секунд. С таким инструментом можно организовать трансляцию, например, на Twitch, где сюжет меняется от голосования в чате.
🔗 Демо 🔗 Официальный блог
Tencent выпустили HunyuanImage 3.0-Instruct — MoE-модель для сложного редактирования изображений, 80B параметров и 13B активных.
Главная фишка — модель думает перед тем, как что-то сделать. Она использует схему Chain-of-Thought (CoT), чтобы проанализировать сложную инструкцию и выполнить её максимально точно.
Нейросеть умеет (добавлять, удалять или изменять элементы и объединять несколько картинок в одну, извлекая и смешивая элементы из разных источников.
Веса и код открыты. Есть«облегчённая» Distil-версия для потребительских ПК.
🔗 Демо 🔗 GitHub 🔗 Hugging Face
Появился HeartMuLa — бесплатный open-source сервис для генерации музыки, который сами разработчики у себя в репозитории успели окрестить «убийцей Suno». Это полноценная студия где можно генерировать треки по текстовому описанию.
Нейросеть создаёт треки с вокалом длиной более 4 минут, умеет писать тексты через встроенный чат-бот и копирует стиль из любого загруженного референса.
Главное преимущество — низкие требования к железу. Локальная версия требует всего 3 ГБ видеопамяти.
🔗 Попробовать 🔗 GitHub 🔗 Hugging Face
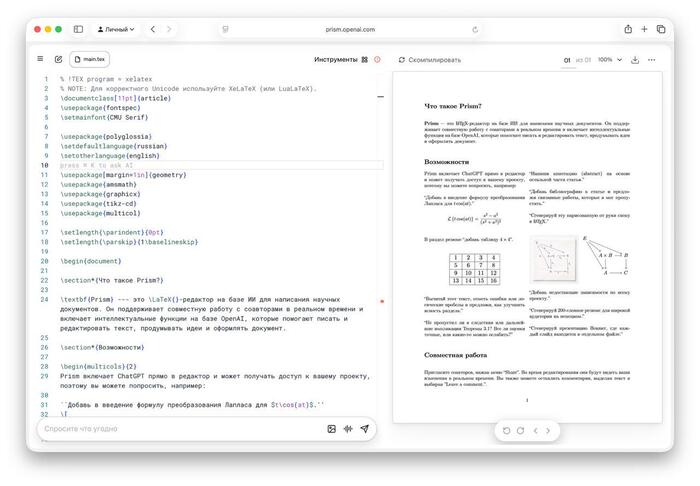
OpenAI представила Prism — облачный LaTeX-редактор с глубокой интеграцией GPT-5.2, который создан специально для студентов и учёных.
Prism видит весь проект, может проверить логику рассуждений, помочь с рефакторингом таблиц и формул, а также найти релевантную литературу или цитаты на arXiv.
Одна из фишек — Prism превращает рукописные наброски и формулы в идеальный LaTeX-код.
Есть и режим совместной работы. Пока инструмент доступен бесплатно для всех, у кого есть аккаунт ChatGPT.
NVIDIA выпустила PersonaPlex-7B — open-source модель, которая общается так же естественно, как человек, благодаря работе в режиме Full Duplex: она может одновременно слушать и говорить.
Нет неловких пауз для обработки запроса. Модель понимает перебивания, вставляет в разговор «угу» и «ага», пока вы говорите, и может принять на себя любую роль — от учителя до пирата. Для настройки достаточно текстового описания персонажа и короткого образца голоса.
Модель полностью открыта, её можно бесплатно использовать даже в коммерческих проектах.
🔗 GitHub 🔗 Hugging Face
Krea представила Realtime Edit — инструмент, который позволяет редактировать фото, видео и 3D-модели в реальном времени. Любые изменения в промпте отображаются почти мгновенно — с задержкой всего в 50 миллисекунд.
Нейросеть накладывает любую генерацию поверх вашего исходника. Интересное решение для дизайнеров и моделеров.

На встрече с разработчиками Сэм Альтман сделал каминг-аут: в GPT-5.2 компания запорола качество текстов. По его словам, команда сознательно сфокусировалась на интеллекте, кодинге и рассуждениях, но из-за «ограниченной пропускной способности» пренебрегла стилем.
«Я думаю, мы просто напортачили», — прямо сказал CEO OpenAI. Он пообещал, что в будущих версиях линейки 5.x это исправят, и модели будут писать «намного лучше, чем 4.5».
Кроме того, Альтман анонсировал, что к концу 2027 года OpenAI планирует сделать интеллект уровня GPT-5.2 как минимум в 100 раз дешевле, чем сейчас.
🔗 Запись

Глава Google DeepMind Дэмис Хассабис заявил, что у компании «нет никаких планов» добавлять рекламу в Gemini. Это стало прямым ответом на решение OpenAI, которая недавно анонсировала тестирование рекламы в ChatGPT.
По словам Хассабиса, персональный ИИ-ассистент строится на доверии, и пользователь должен быть уверен, что получает рекомендации для себя, а не в интересах рекламодателя.
«Интересно, что они пошли на это так рано. Может, им нужно больше выручки», — прокомментировал он решение OpenAI.
Впрочем, это не означает, что реклама в Gemini не появится никогда.
🔗 Источник

Геймер, с которым друзья не хотели играть в Escape from Tarkov, создал себе ИИ-напарника. Он дал боту доступ к своему экрану, и тот в реальном времени реагировал на геймплей.
ИИ-тиммейт не просто молчал: он подсказывал тактику, помогал с лутом и квестами, ориентировал по карте и комментировал ошибки, создавая эффект живого общения в Discord.
Эксперимент, который начинался как шутка, зашёл слишком далеко. Парень понял, что ему комфортнее играть с ботом, который всегда онлайн и готов помочь, чем с живыми людьми.
В итоге он испугался, насколько легко можно заменить реальное общение, и удалил бота.
🔗 Источник

Новость о том, что самый популярный тиктокер мира Хаби Лейм продал права на своё лицо почти за миллиард долларов, облетела весь интернет. Покупатель получил право в течение 3 лет использовать ИИ-аватар блогера для создания любого контента: от рекламы до стримов 24/7 на разных языках.
Но на самом деле всё сложнее. Хаби фактически вывел свой личный бренд на IPO: его компания слилась с гонконгским холдингом, и теперь акции его бренда можно купить на бирже NASDAQ. Это позволяет масштабировать его образ до бесконечности. Пока реальный Хаби отдыхает, его цифровой клон может работать, не уставая.
Это может быть началом конца для классического инфлюенс-маркетинга, где масс-маркет заберут неутомимые цифровые двойники.
🔗 Источник

28 января 1958 года Готфрид Кристиансен запатентовал систему, которая доказала: из простых модулей можно собрать абсолютно всё — от замка до работающего компьютера. Для гика LEGO стал первым «языком программирования» в физическом мире.
Это напоминает нам, что современный ИИ строится по тем же лекалам: гигантские языковые модели — это лишь колоссальные замки, собранные из миллиардов крошечных информационных кирпичиков.
Символично, что и в конструкторе, и в нейросетях единственным ограничением остается только фантазия того, кто держит детали в руках. Мы всё еще играем в кубики, просто теперь они состоят из чистого кода.
❯ Аудиоверсия дайджеста
❯ Заключение
Неделя получилась китайской: Alibaba, Moonshot и Baidu выкатили модели, которые уже дышат в спину флагманам. Пока Сэм Альтман признаётся, что они «запороли» качество текстов, самый популярный тиктокер мира продаёт своего ИИ-двойника почти за миллиард долларов.
Искусственный интеллект становится полноценным участником событий — собеседником, который не тупит, напарником по игре и даже цифровым двойником, который работает, пока мы спим.
Это стирает границы между реальным и виртуальным миром, меняя правила игры в медиа, развлечениях и даже в личном общении.
До встречи в следующем выпуске! А какая новость на этой неделе удивила вас больше всего? Пишите в комментарии!
Новая разработка от Nvidia — нейросети Earth‑2, способные прогнозировать погоду на 15 дней вперёд. По заявлению компании, такие модели работают быстрее и дешевле традиционных методов. Они обучены на огромных массивах климатических данных и уже продемонстрировали точность, сопоставимую или даже превышающую классические численные модели.
Особенностью Earth‑2 является полная открытость: исходный код доступен публично, а модели можно запускать без использования суперкомпьютеров. Технология уже внедрена в реальных метеослужбах;, например, в Израиле ИИ успешно предсказал осадки и помог сократить вычислительные ресурсы.
Из канала Мем в глаз попал
Также в МАХ
Вчера NVIDIA представила DRIVE Alpamayo-R1 — первую в мире открытую модель ИИ, которая переводит автопилоты от простых рефлексов к полноценному машинному рассуждению. Это фундаментальная смена парадигмы управления автомобилем. Вместо классического алгоритма «увидел — затормозил», система теперь «осмысливает» ситуацию на дороге.

Ключевые факты о новой технологии:
— Vision-Language-Action (VLA). Модель объединяет зрение, язык и действие в единую нейросеть. Она одновременно анализирует видеопоток, формулирует описание происходящего на естественном языке и генерирует команды управления.
— Chain of Thought. Alpamayo-R1 использует логику, аналогичную той, что есть в продвинутых LLM. Система способна анализировать причинно-следственные связи: «Автобус впереди включил аварийку → возможно, сейчас из-за него выйдут люди → нужно сместиться левее и снизить скорость».
— Физический ИИ. Это первый промышленный пример интеграции языковых моделей в системы реального времени, управляющие физическими объектами. Модель учитывает инерцию, сцепление и геометрию движения.
— Открытая архитектура. NVIDIA выпустила модель как Open Model, предоставив доступ к весам и коду. Это ускорит разработку роботакси и автономных грузовиков другими компаниями, позволяя индустрии не тратить годы на создание базы с нуля.
По сути, NVIDIA перенесла «медленное мышление» из чат-ботов в контроллер автомобиля. Теперь машина не просто реагирует на препятствия, а прогнозирует поведение других участников движения, как опытный водитель.
Подписывайтесь на мой тг-канал! (тык)
📡 Never lose your signal.







