Такое ощущение, чисто субъективное, что гугл напрочь разучился искать.
Хочу найти сцену из Футурамы, когда Фрай жует мумию
Пишу "Фрай съел мумию"
Гугл выдает что угодно, кроме Футурамы. А ну да есть одна картинка, где Фрай стоит напротив Бендера.
Фрай печален, что странно, ведь мумия была очень вкусной. Все просто, тут Фрай не ест мумию. Всему виной гугл.
Ввожу аналогичное в яндексе. И бац, получаю картинку поедания Фраем Мумимии Зибулона 100500го, правившего три миллиона лет назад какой-то там планетой.
И это происходит повсеместно, с разными поисковыми запросами. Раньше гугл также выдавал, что нужно, теперь море мусора.
PS.
Можно было бы сказать, что гугл современный и прогрессивный, но проблема в том, что он выдал сцены из гравюр и фильма Мумия, что старше Футурамы, а Фрая просто проигнорировал. Хоть бы Макса Фрая с мумией показал. Нет. Не показал.
Привет пикабушники. Как думаете какой должна быть альтернативная поисковая система? Без кучи рекламы это понятно - все мы этого хотим. Но тогда как монетизировать содержание системы? - Вопрос. А это петабайты данных. Без слежки? Да, полностью согласен.
Я не говорю что существующие - плохие (рекламы в них и правда куча). Дело в том, что они "приелись" уже. Все они в какой-то мере одинаковые, потому что на протяжении долгих лет, одна копирует другую. Может у Вас есть какие-нибудь идеи (кроме ИИ) по модернизации механизмов UX/UI для поисковой системы.
К Вам, как к социуму есть вопросы:
Каким по Вашему должен быть поисковик, чтобы прочие были попросту не нужны? Каким функционалом он должен обладать? Как монетизировать без рекламы и слежки для таргета (слежка - следствие рекламы)? Что будет отличать его от "приевшихся"?
Если у Вас есть свое мнение об этом или ответы на вопросы, изложите пожалуйста в комментариях. Изучу их все. Прошу Вашей помощи, в решении этого вопроса.
Поднимите пожалуйста в горячее, нужна большая выборка ответов. Спасибо за понимание.
Открываем серию «Платформы ИИ» Обзоры ключевых игроков на поле искусственного интеллекта — OpenAI, Яндекс, Google, Anthropic, Mistral, Perplexity и других. Не просто сервисы, а именно платформы, которые создают свои экосистемы, модели и продукты на их основе. Разбираем, как работают, чем отличаются, где сильны и зачем вообще нужны. Начинаем с Perplexity — поисковой системы нового типа, построенной на базе ИИ.
Perplexity AI — это поисковая система и чат-бот на базе искусственного интеллекта, который отвечает на вопросы не просто списком ссылок, а сразу выдаёт понятные и точные ответы с указанием источников. Она использует современные языковые модели, чтобы анализировать смысл запроса и формировать ответ
Стартап был основан в 2022 году в Калифорнии. За проектом стоит команда инженеров и исследователей, среди которых Арвинд Нараянан , Денис Ярмакин, Джон Меррилл, Энди Конрад и Эрик Маркс. Их цель — сделать поиск информации проще и понятнее для всех
Этот поисковик предлагает удобный подход к поиску информации, предоставляя прямые ответы с ссылками на источники вместо обычного списка сайтов. Платформа способна вести диалог, понимать уточняющие вопросы и анализировать разнообразный контент: от статей и документов до видео на YouTube. Пользователи также могут загружать собственные файлы для анализа. Однако, несмотря на эти преимущества, у инструмента есть и свои недочеты: он может выдавать неточную информацию, которая требует проверки
В будущем компания планирует запустить собственный браузер Comet, который описывается как «агентный» ИИ-инструмент. В отличие от обычных браузеров, он будет использовать искусственный интеллект для выполнения сложных задач от имени пользователя, превращая пассивный поиск в активное взаимодействие с интернетом.
___
Perplexity — это попытка переосмыслить сам подход к поиску: не просто находить ссылки, а сразу выдавать суть. И хотя идеальных ответов ИИ пока давать не научился, такой формат уже сегодня экономит время и помогает быстро ориентироваться в информации. Особенно если вы знаете, как правильно задавать вопросы.
В воскресенье, 5 мая, Ренд Фишкин (известный во всем мире как основатель популярного сервиса Moz.com) получил электронное письмо от человека, утверждающего, что у него есть доступ к массивной утечке документации API из внутреннего подразделения поиска Google. В письме также утверждалось, что эти утекшие документы были подтверждены как подлинные бывшими сотрудниками Google, и что эти бывшие сотрудники и другие лица поделились дополнительной, приватной информацией о работе поиска Google.
Один из скринов "слитой" базы Google
Многие из их заявлений прямо противоречат публичным заявлениям сотрудников Google, сделанным за последние годы. В частности многократным отрицаниям компании о том, что сигналы пользователя, связанные с кликами, используются, что субдомены рассматриваются отдельно в ранжировании, отрицаниям существования песочницы для новых сайтов, отрицаниям того, что возраст домена собирается или учитывается, и многому другому.
"Сливщиком" информации оказался Эрфан Азими (ссылка на Линкедин). В его профиле указана Грузия как страна проживания. Именно он показал Ренду саму утечку: более 2,500 страниц документации API, содержащей 14,014 атрибутов (функций API), которые, по-видимому, происходят из внутреннего "Content API Warehouse" Google. Судя по истории коммитов документа, этот код был загружен на GitHub 27 марта 2024 года и не удален до 7 мая 2024 года.
Что интересного в этих документах?
Ложные Утверждения Google, Опровержения которых обнаружены в Документации API
Утечки документации API Google раскрыли значительные противоречия между публичными заявлениями Google и их реальными
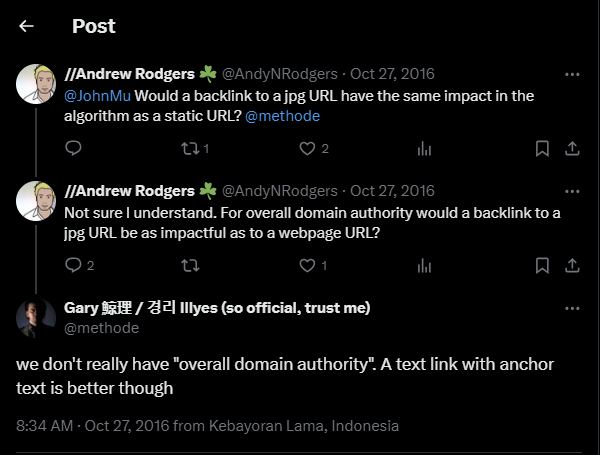
Авторитет домена: Google неоднократно отрицал использование "авторитета домена", утверждая, что они не используют метрику для измерения авторитета сайта в целом. Однако утекшие документы показывают существование метрики под названием "siteAuthority", используемой в внутренних системах Google, что противоречит их публичным заявлениям. Такие известные личности, как Гэри Илш и Джон Мюллер, неоднократно заявляли, что Google не использует метрику авторитета сайта, что теперь кажется вводящим в заблуждение.
Использование кликов для ранжирования: Представители Google давно отрицают, что клики влияют на ранжирование в поиске. Несмотря на эти утверждения, свидетельства из антимонопольного процесса Министерства юстиции США и различных патентов указывают на существование систем, таких как NavBoost и Glue, которые используют данные о кликах для влияния на результаты поиска. Эти системы существуют с 2005 года и используют обновляемые данные для настройки результатов поиска на основе кликов пользователей. Эта практика противоречит публичным отрицаниям Google и подчеркивает их попытки ввести в заблуждение сообщество SEO.
Эти открытия подчеркивают разницу между публичными заявлениями Google и их внутренними операциями, вызывая вопросы об их искренности.
Что будет дальше?
Пожалуй, ничего. Google наверняка будет открещиваться и утверждать, что все это фейк. Признавать свои ошибки никому не хочется:) В любом случае мир SEO теперь не умрет совсем, но людям, которые работают в этой сфере будет наверняка интересно сопоставить свои знания с тем, что упоминается в слитых документах.
Что лично почерпнул для себя автор этих строк
Даты публикаций очень важны - Google ориентирован на свежие результаты, и документы иллюстрируют многочисленные попытки ассоциировать даты со страницами.
Фрагмент с упоминанием про важность упоминания дат изменений контента
Лучший подход – указать дату и быть последовательным в ее использовании в структурированных данных, заголовках страниц, XML-картах сайта. Указание дат в URL, которые противоречат датам в других местах на странице, скорее всего, приведет к ухудшению ранжирования контента. Что ж попробую протестировать полученные знания в своем блоге :)
Tor — это веб-браузер, для анонимного использования и доступа к ограниченным ресурсам. Является средством борьбы со слежкой и цензурой в интернете.
— Для выхода в Tor использует технологию «луковой маршрутизации» — сети специальных нод, каждая из которых шифрует данные пользователя.
В этом посте познакомим вас с различными утилитами, которые будут полезны для работы с сайтами в сети Tor.
Поисковые утилиты:
- OnionSearch - позволяет с помощью одной команды произвести поиск во всех популярных поисковиках .onion.
- Darkdump - позволяет пользователям вводить поисковый запрос (запрос) в командной строке, и он извлекает все deep веб-сайты, относящиеся к этому запросу.
- Ahmia Search Engine - поисковая система для скрытых сервисов Tor.
Утилиты сканирования:
- Onionscan - выполняет сканирование .onion сервисов на бреши в безопасности.
- Onioff - проверяет .onion URL (сайты в сети Tor) на их работоспособность (получает код статуса), выводит заголовки этих веб-сайтов.
Краулеры:
- TorCrawl - сканирует и извлекает (обычные или луковые веб-страницы через сеть TOR.
- VigilantOnion - краулер, осуществляющий поиск по ключевым словам.
- OnionIngestor - инструмент для сбора и мониторинга .onion и индексации собранной информации в Elasticsearch.
1. Shodan — поисковая система, позволяющая пользователям искать различные типы серверов (веб-камеры, маршрутизаторы, серверы и так далее), подключённых к сети Интернет, с использованием различных фильтров.
2. Maltego — это OSINT инструмент для построение и анализа связей между различными субъектами и объектами.
3. SpiderFoot — это инструмент с открытым исходным кодом для автоматизированной разведки. Его цель — автоматизировать процесс сбора информации о заданной цели.
4. OSINT Framework — как и следует из названия, это сайт с древовидным каталогом ссылок на популярные инструменты OSINT.
5. theHarvester — это инструмент для сбора e-mail адресов, имён поддоменов, виртуальных хостов, открытых портов/банеров и имён работников из различных открытых источников (поисковые системы, сервера ключей PGP).
Работал в застройщике, не сеошником, правда, а программистом. И возникла проблема: если ввести в поисковике "Квартиры от *ИмяЗастройщика*", то первыми выходили сайты агентств, через которые продавали квартиры, а официальный сайт только на 5-6 месте. Позорище.
Ну и стало руководство меня напрягать, что так быть не должно, что в общем-то справедливо. Говорю, я не сеошник, давайте закажем SEO аудит, есть надёжные ребята. А я просто изменю сайт согласно их рекомендациям. Так и сделали.
Ребята провели SEO аудит, прислали список косяков, которые надо поправить, а потом началась комедия. Руководство половину пунктов просто забраковало "Это мы менять не будем, эти тексты переписывать не будем, эти страницы менять не будем и т д". В итоге, я половину пунктов из рекомендаций худо-бедно к сайту применил, но толку ноль.
Ну и самой главной проблемой, как потом выяснялось, оказалось то, что телефон в шапке был сделан картинкой, просто на баннере написан. Сеошники настоятельно рекомендовали это исправить в первую очередь.
А генеральный принципиально отказывался сделать его текстом. Очень ему нравились эти красочные баннеры в шапке, которые дизайнеры нарисовали, средствами html + CSS так не сделать.
Спустя какое-то время руководство согласилось-таки сделать телефоны текстом, пусть и не так красиво. И, о чудо, все получилось, сайт вышел на первые места.
Сейчас я уже давно там не работаю, ради интереса зашёл на сайт - вижу, снова заменили номера телефонов текстом на баннере. А в поиске снова в топе агентства. Предвижу, что скоро опять будут напрягать программистов вопросом "А почему мы не первые в выдаче по названию нашей же компании?".






![Perplexity [Обзор]](https://cs18.pikabu.ru/s/2025/06/09/17/obbbc2tc.jpg)