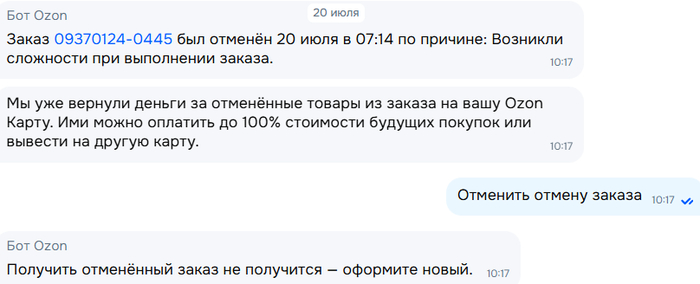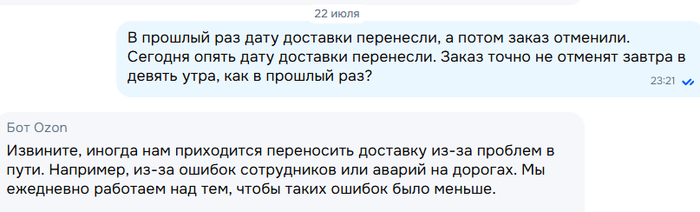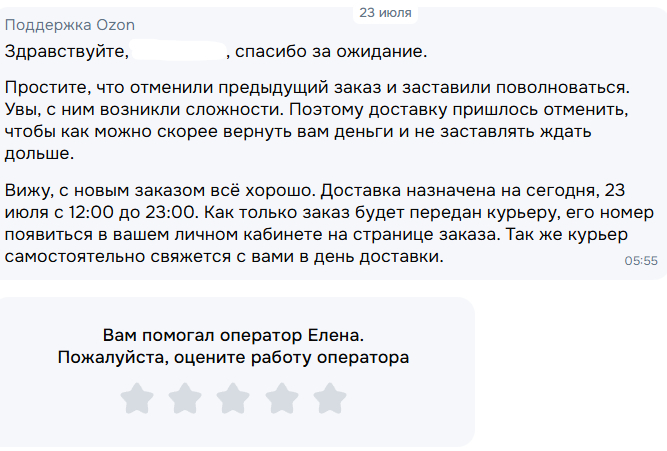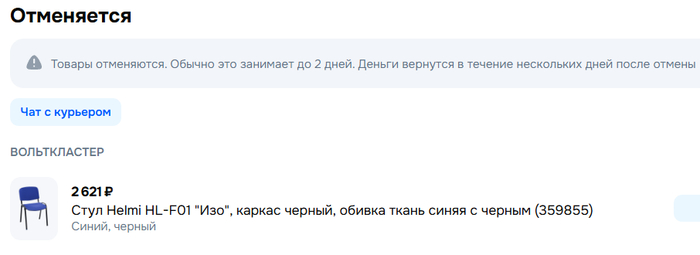
Как мошенники "работают" через wildberries
Спойлер. Нужна помощь юристов и людей, которые столкнулись с подобным.
Преамбула
Решила моя 15-летняя дочь заработать денег через интернет. Показать родителям, что уже самостоятельно может неплохо зарабатывать. К слову, она на каникулах подрабатывает в офлайне. Мы регулярно объясняем детям о безопасности в интернете и в жизни в целом. Тем не менее это случилось. Дочка попалась на мошенников и сказала нам, когда остановиться было уже поздно. Но разрешить ситуацию еще возможно. Вы думайте, что вас или ваших близких это не коснется? Лучше бы так. Но будьте на чеку, поговорит со своими детьми, проверьте их аккаунты личного кабинета. Может они тоже попались на такое и просто бояться сказать вам. У дочери аккаунт без данных в профиле, только имя и номер телефона, однако ей ребенку 15 лет допустима возможность оплаты частями на сумму 75 тысяч рублей (далее в скринах). Таким способом можно развести на покупку айфона, питбайка да всего что угодно из ликвидного товара, который можно продать за пол цены по-быстрому.
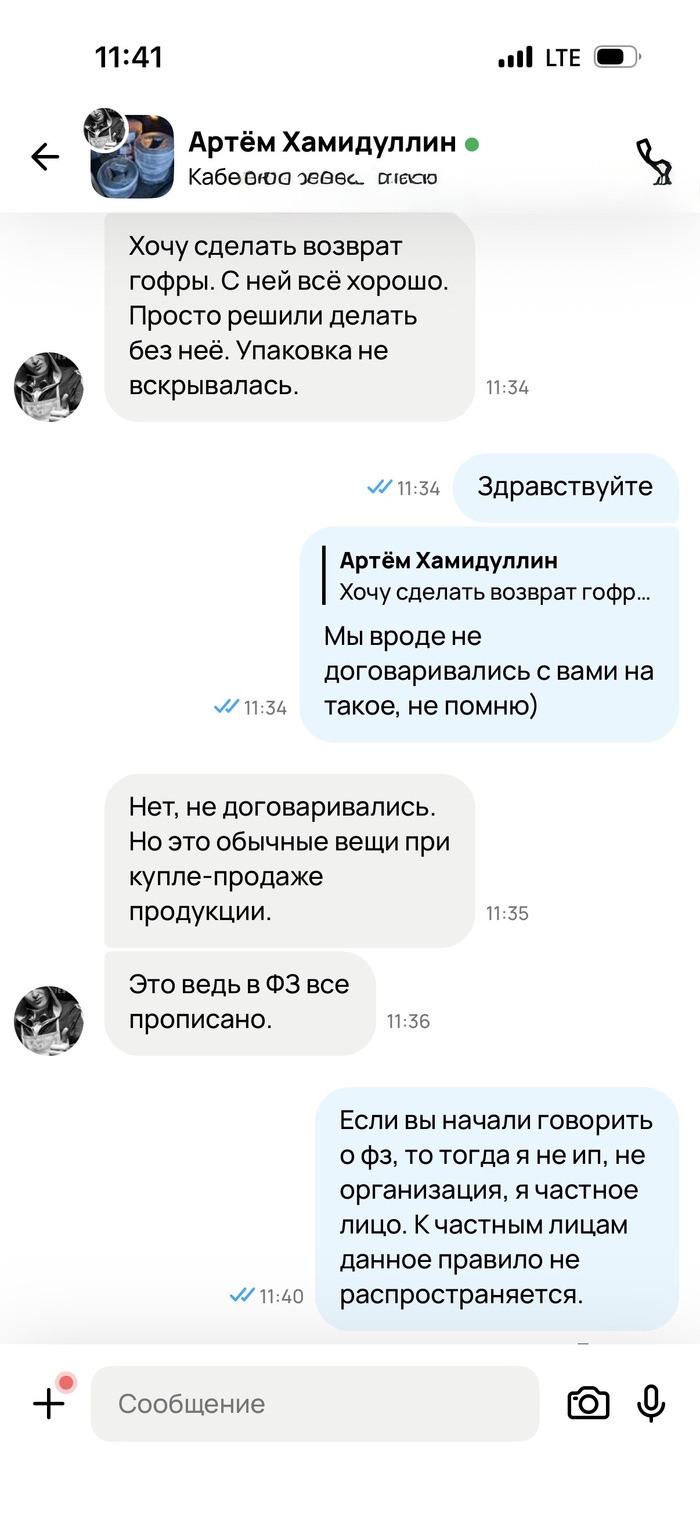
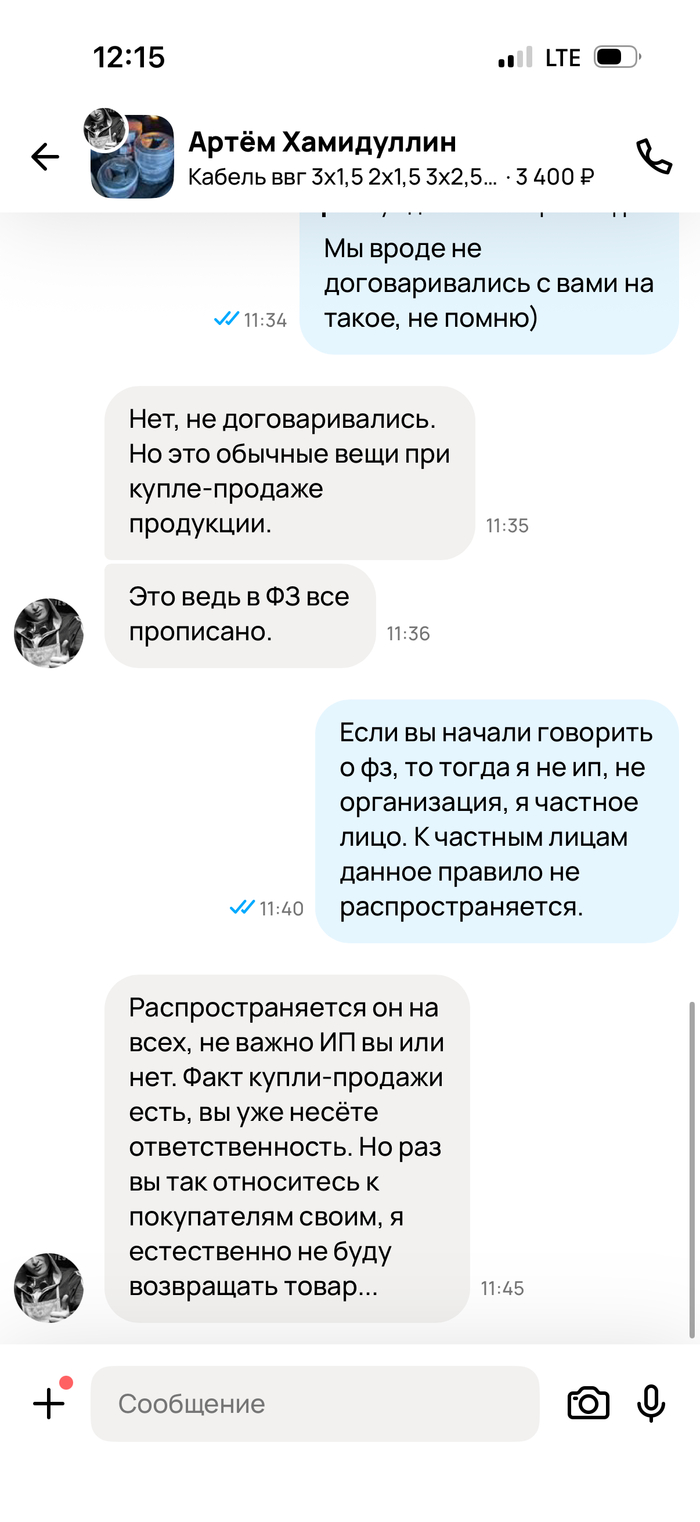
Я прошу людей помочь в разрешении это ситуации, юристов и тех кто сталкивался с подобным. Куда писать обращения?
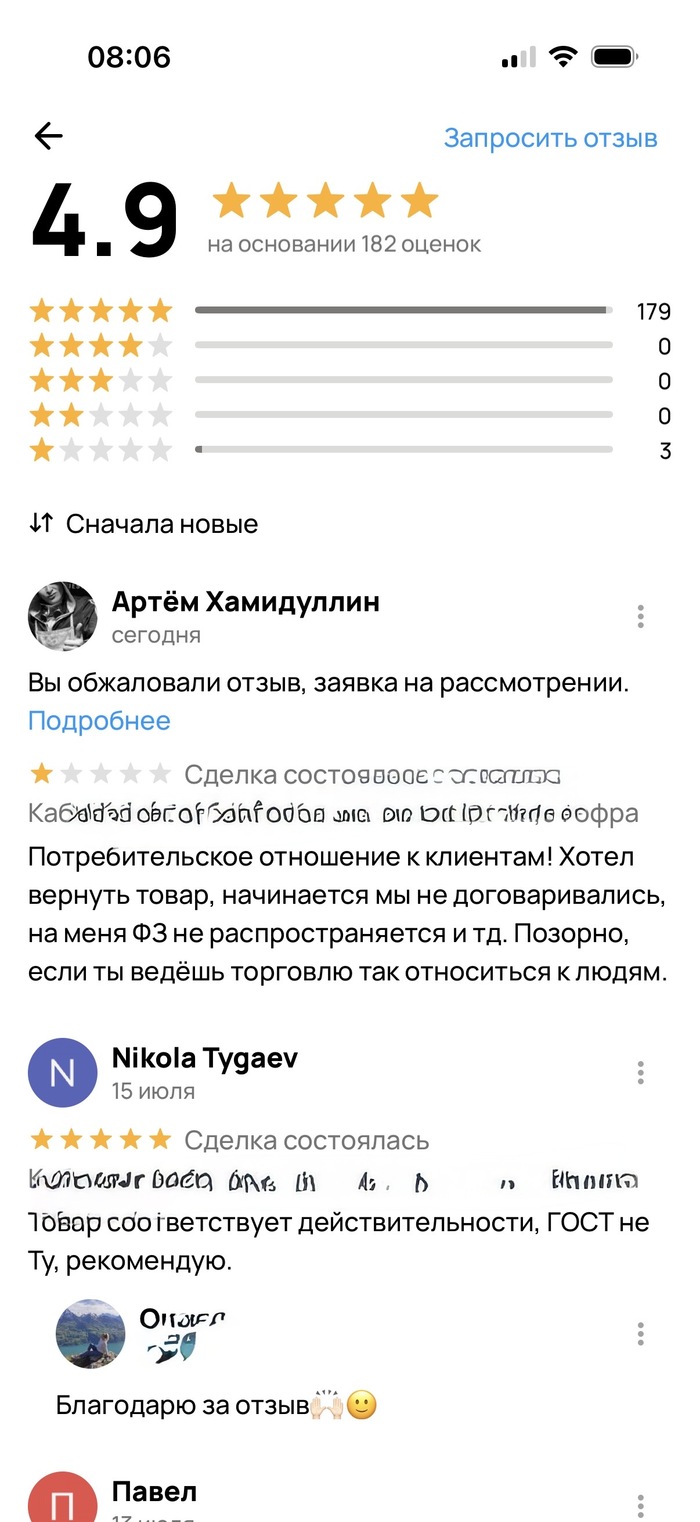
Представители @Wildberries, я могу дать вам всю историю переписки (скриншотов много все разместить здесь не получится) и надеюсь на благополучное разрешение ситуации. Я знаю, что запись с камер видеонаблюдения в пвз хранится 90 дней. У вас серьезная служба безопасности, они могут все просмотреть и найти зацепки. Плохо когда маркетплейса используют в мошеннических целях ведь это влияет на репутацию и прибыль.
Ну, а пока мысли такие, впереди заявление в полицию, диалог с wildberries, а там уже видно будет. Считаю, что отстаивать свои права нужно.
Поднимите пожалуйста в топ, плюсаните пост.
P.S. Все, что вы скажете к примеру: - куда смотрели, сами виноваты и т.п. это все правомерно. Это наша оплошность я с этим согласен.
К делу
Насмотрелась в тиктоке про способ заработать на отзывах к товарам, купленных на вб. Перешла по ссылке и там описание описание вакансии на ворк-зилле. Связалась с человеком в тг, тот с "посредником", и он тоже описывает вакансию.
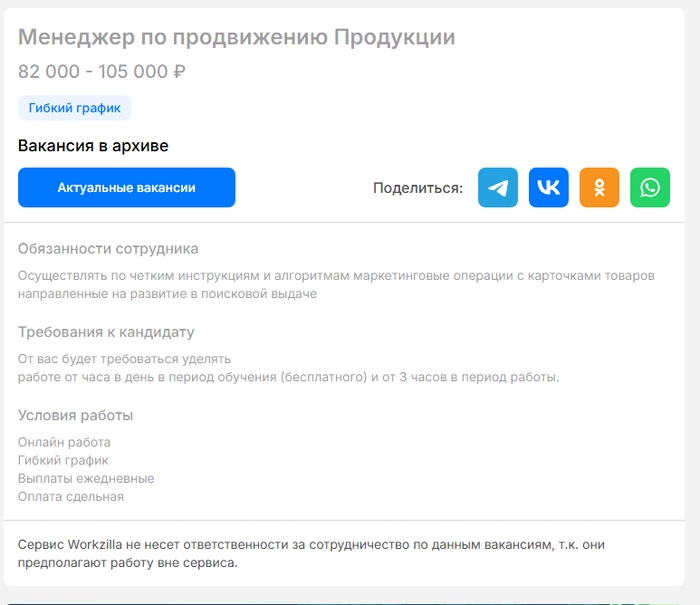
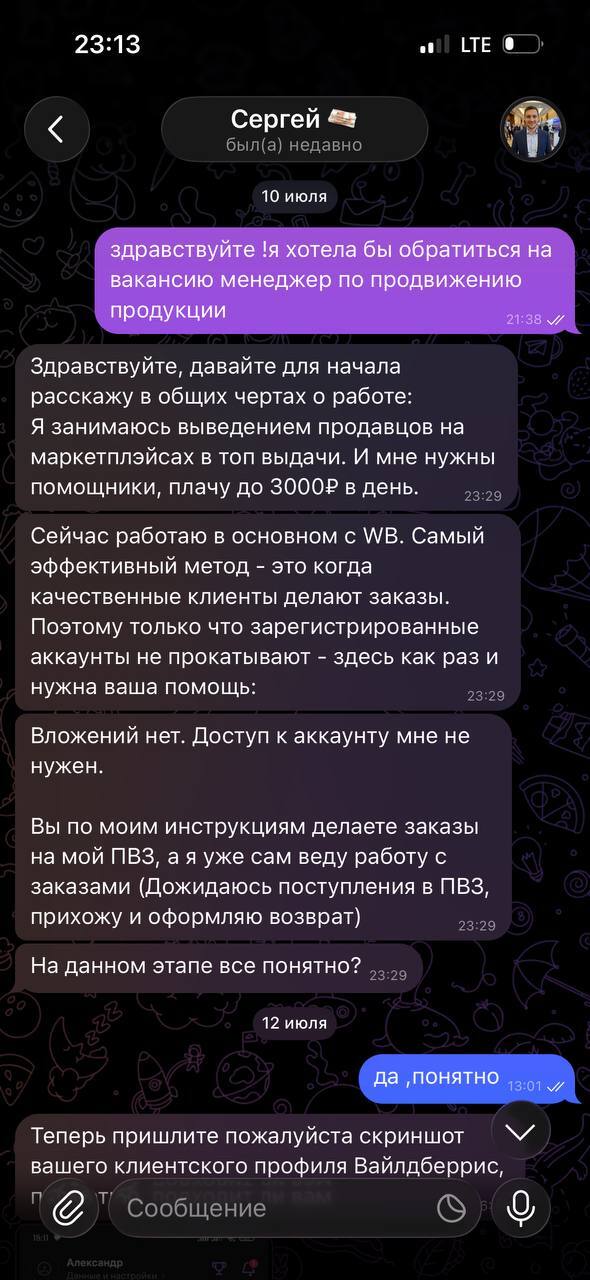
Здесь он предлагает условия
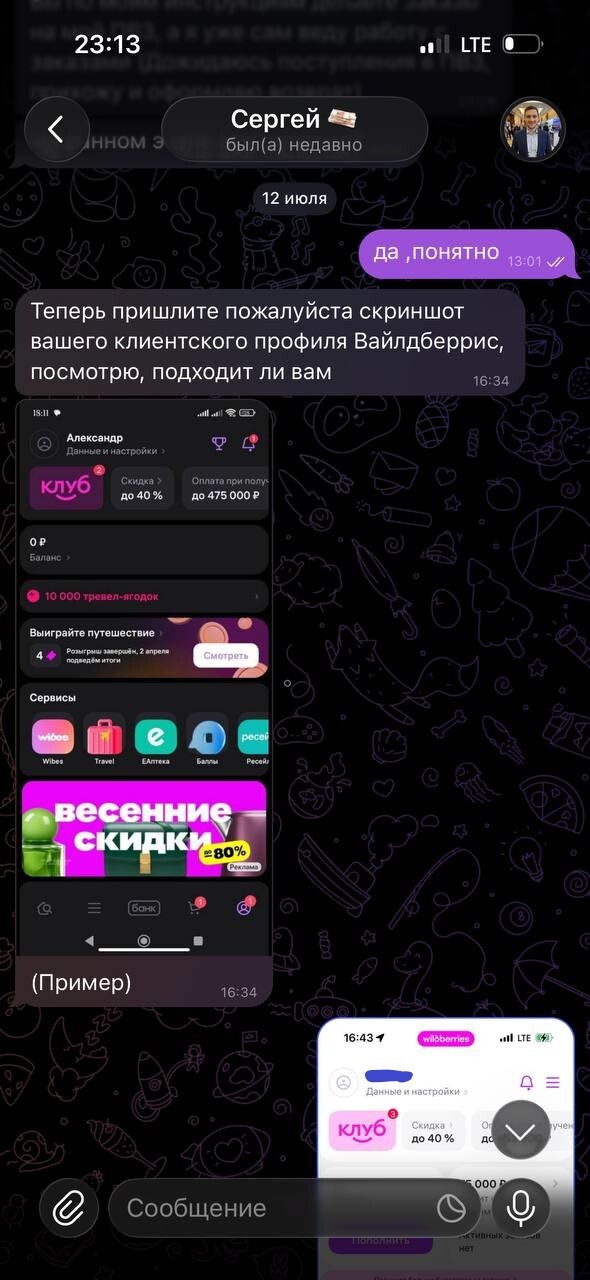
Просит скриншот клиентского профиля
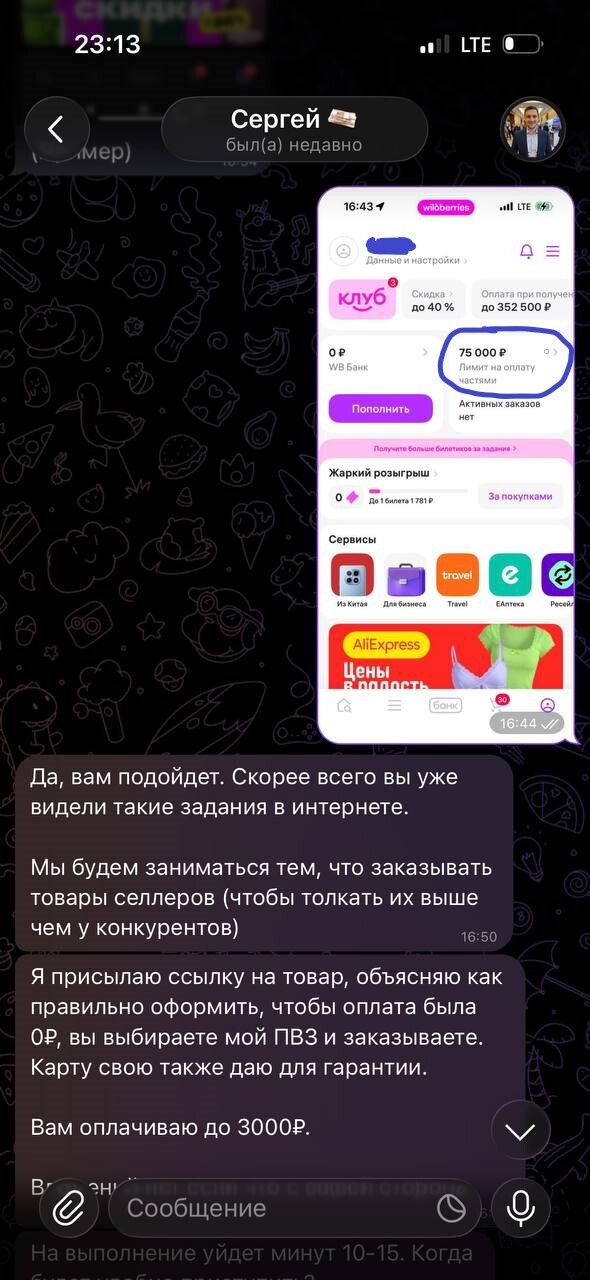
Профиль одобрен
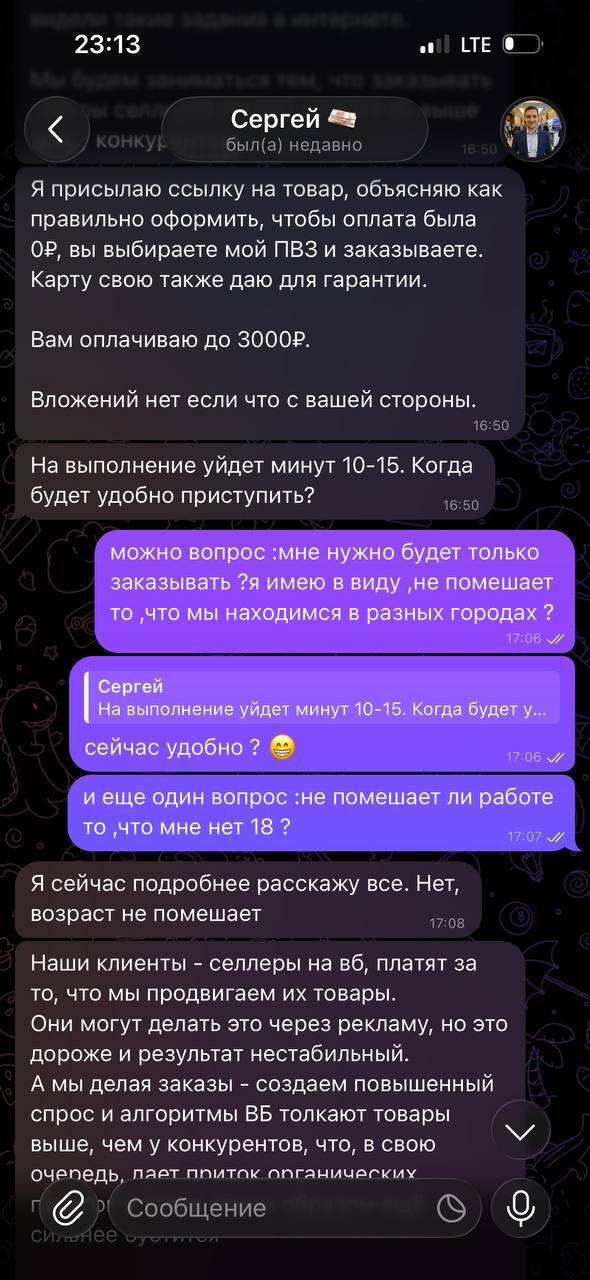
Описание дальнейших действий
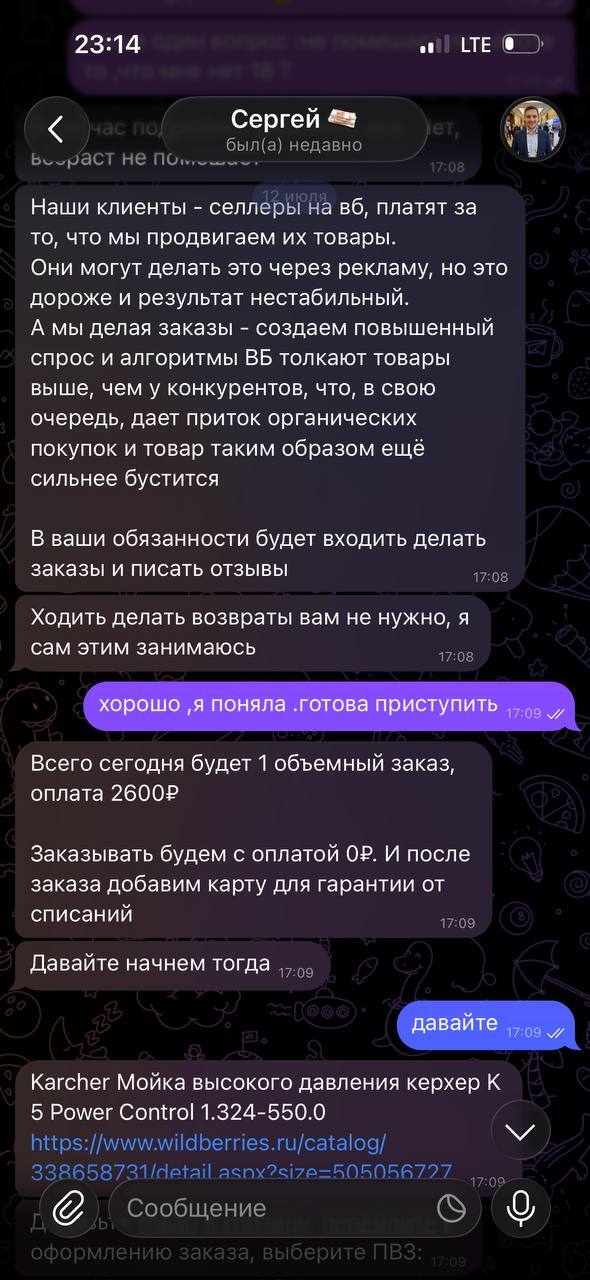
Товар
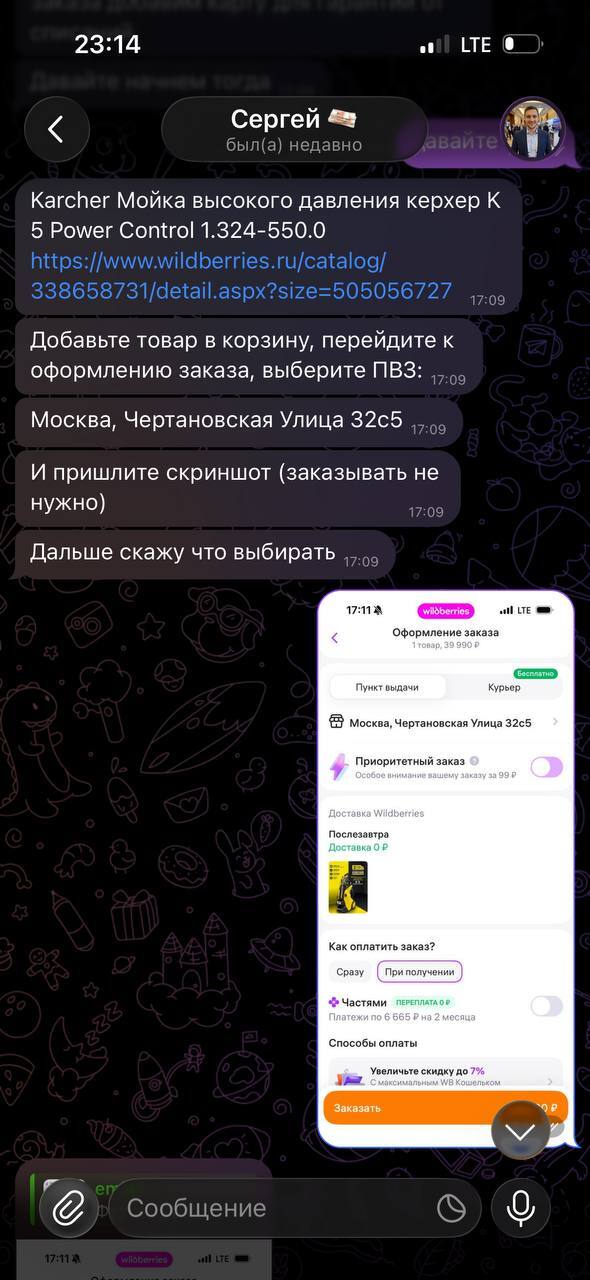
Адрес пвз
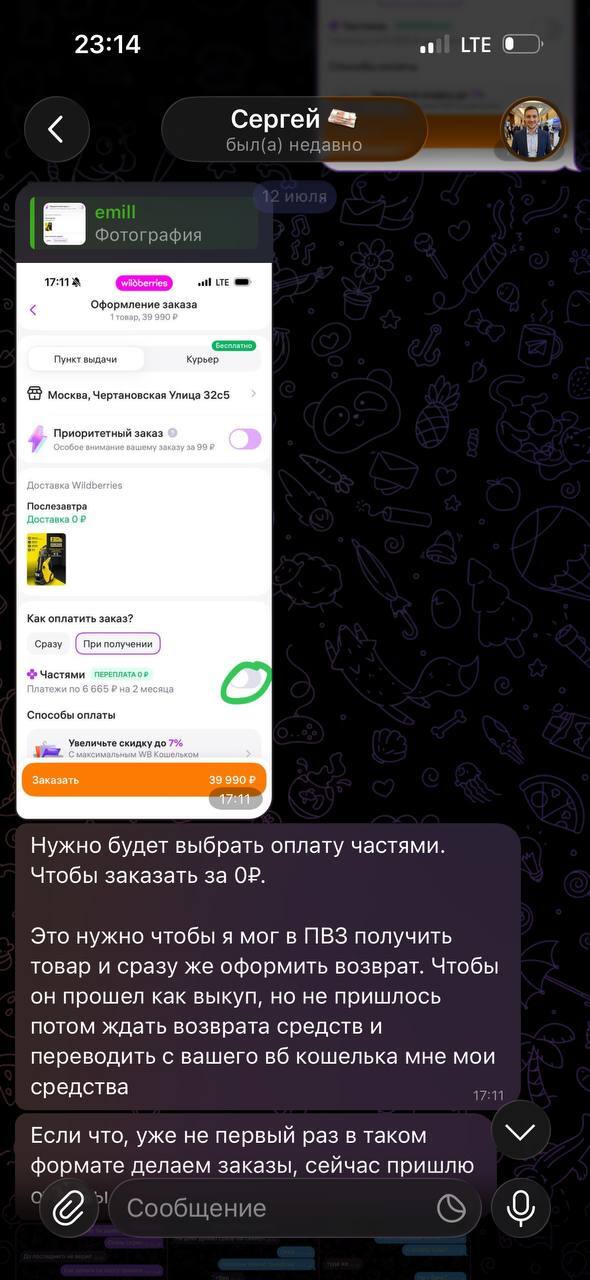
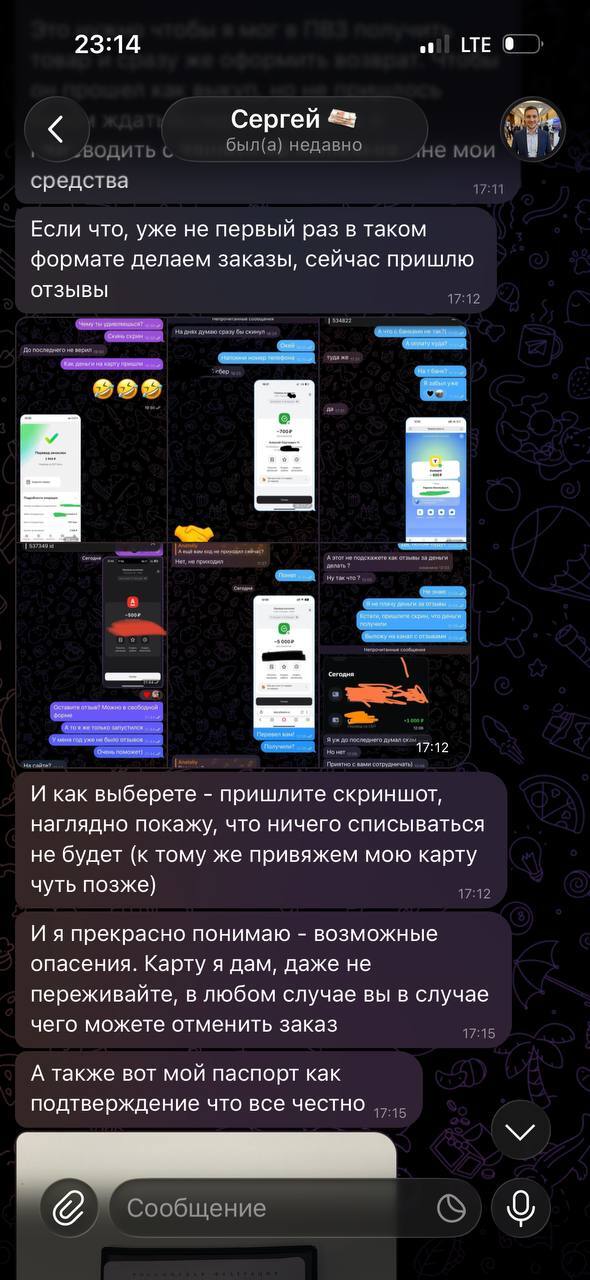
Лже отзывы
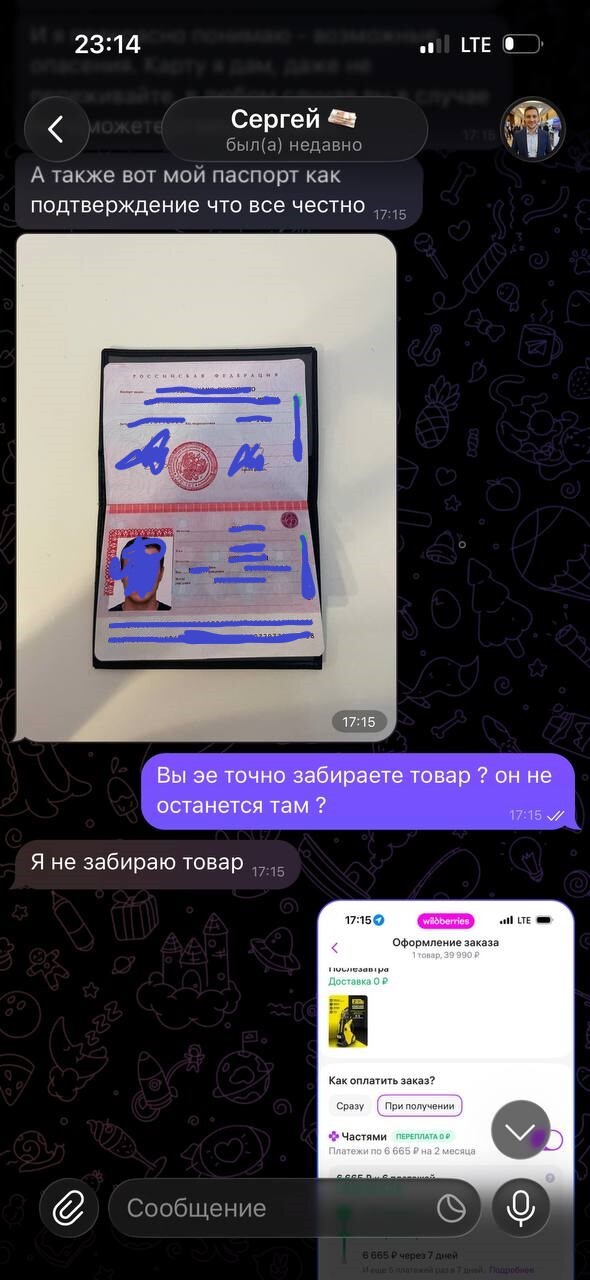
Паспорт подделка
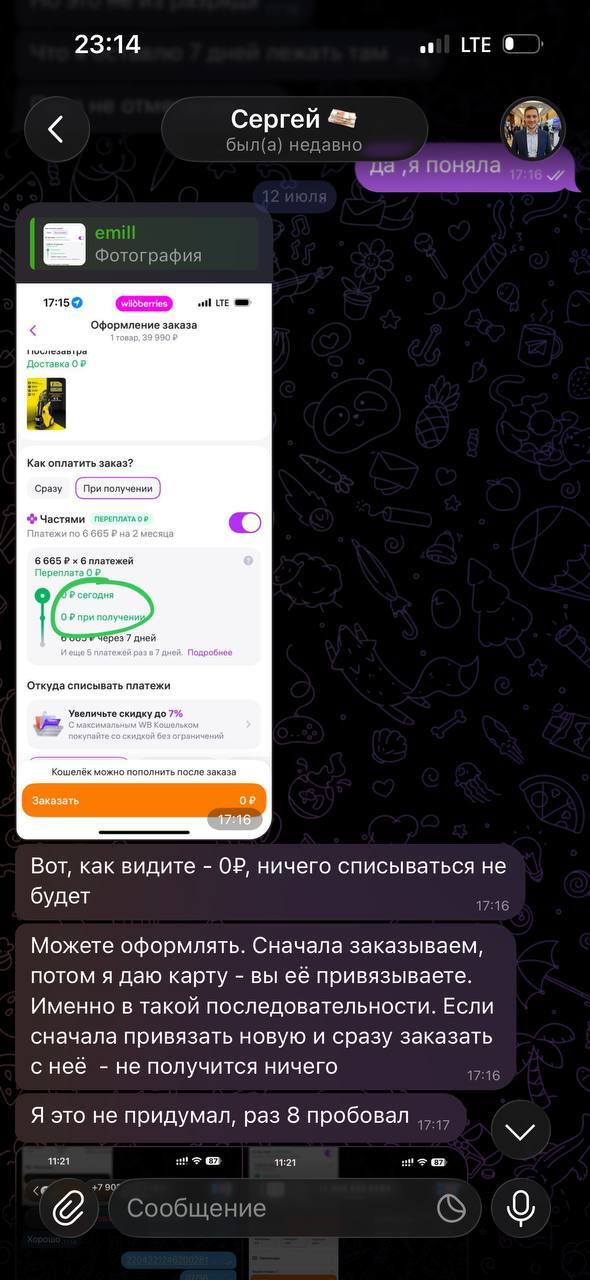
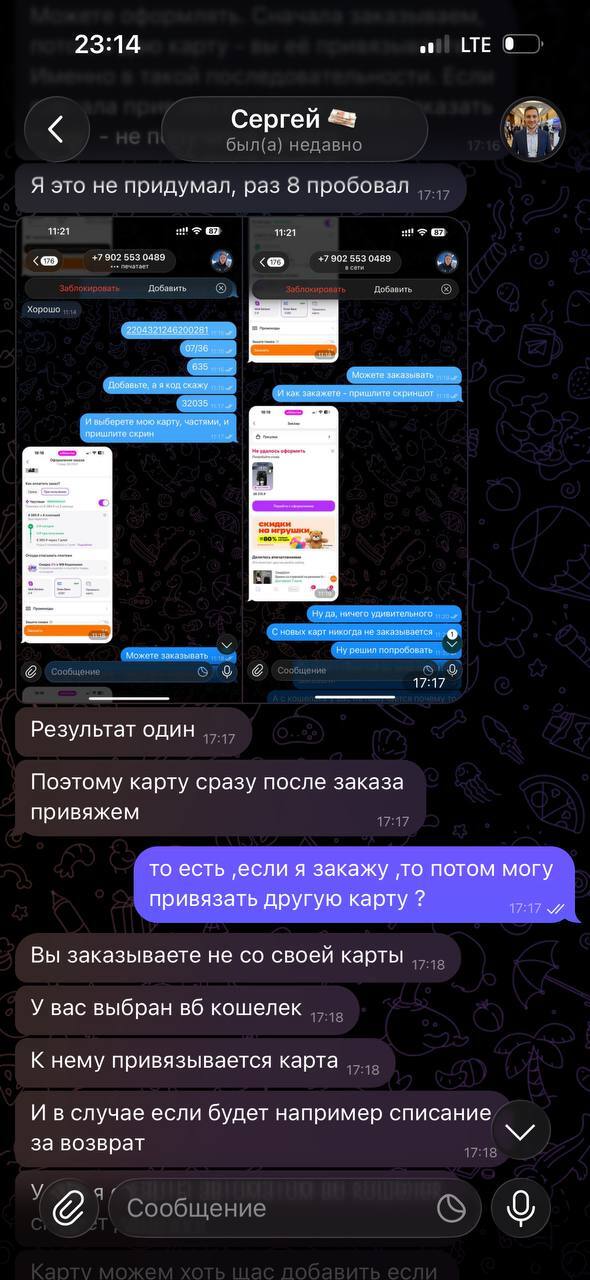
На которой рублей 10 для проверки
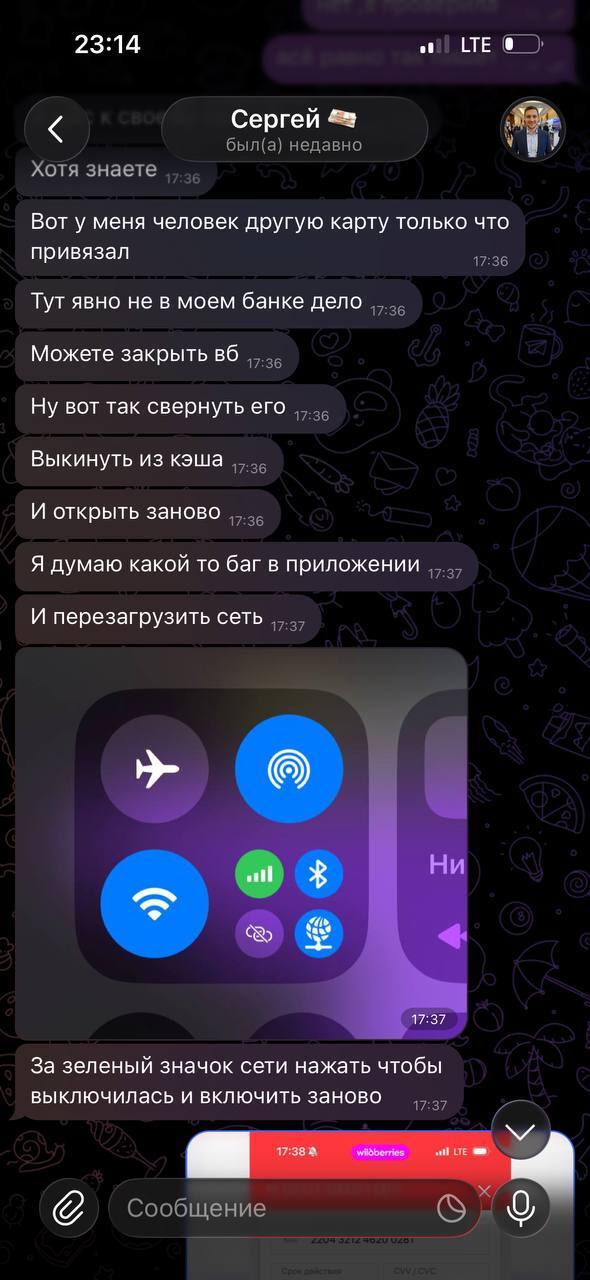
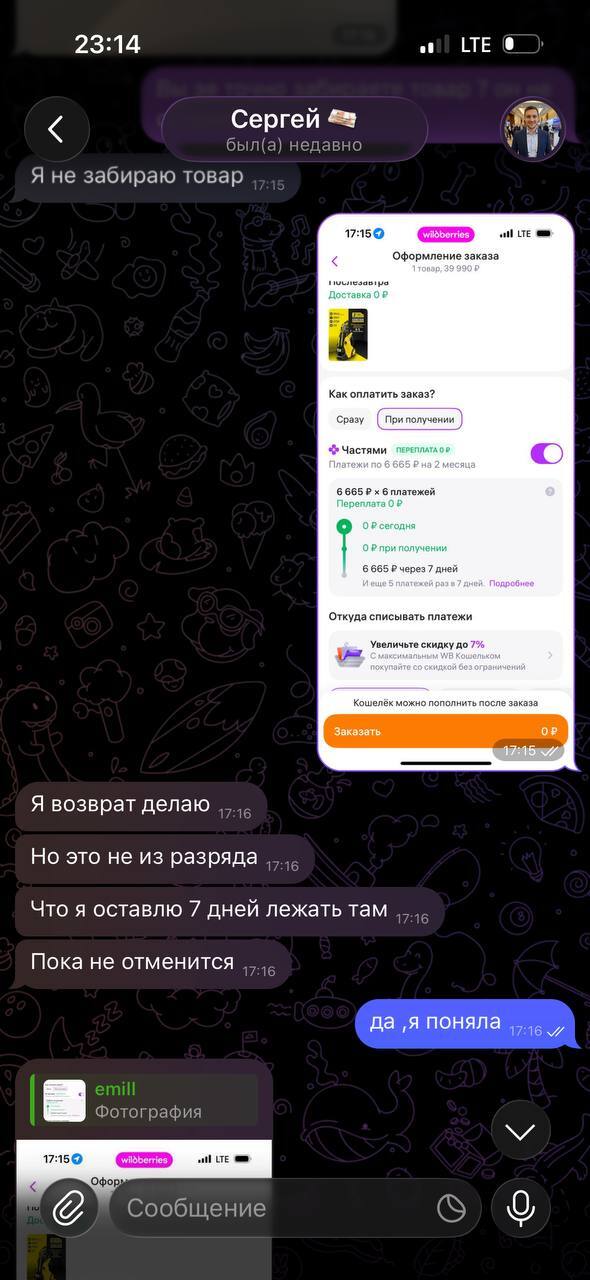
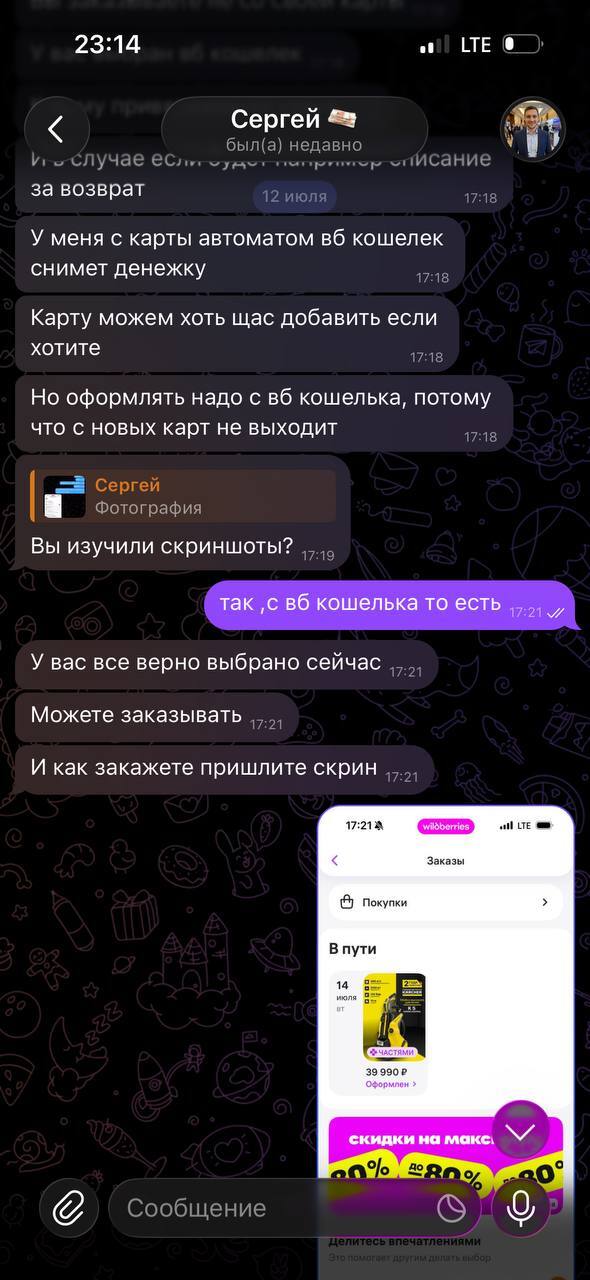
Далее он дает несколько карт для привязки, естественно они не вяжутся. Только на следующий день это удалось сделать опять таки по его инструкции
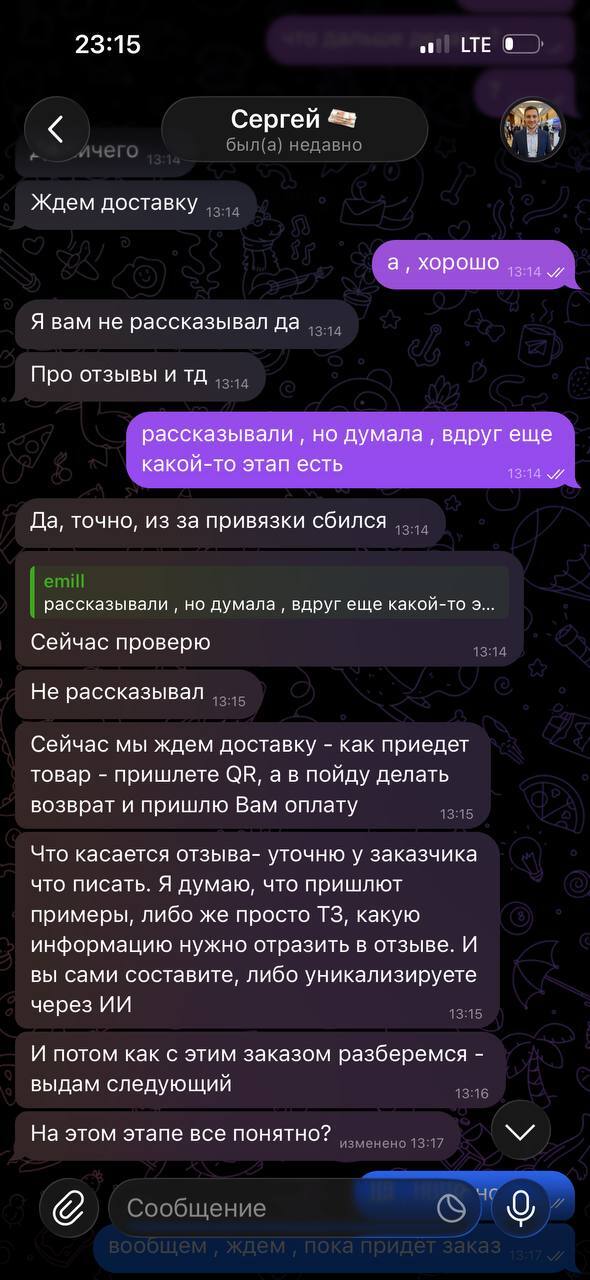
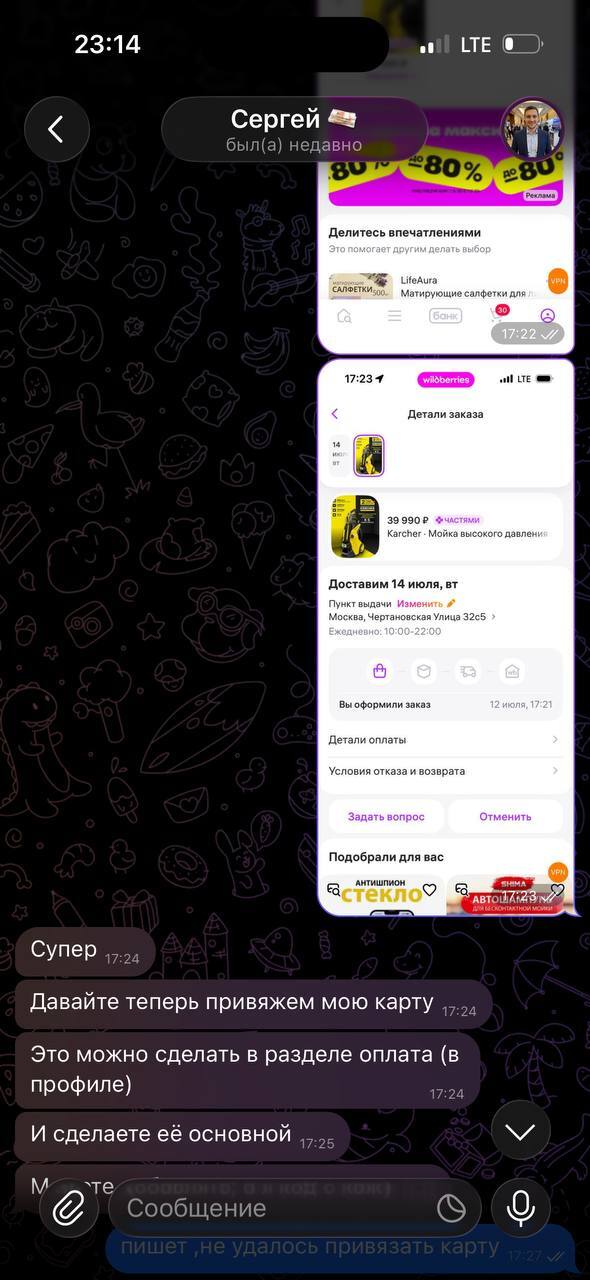
Дальнейшие инструкции
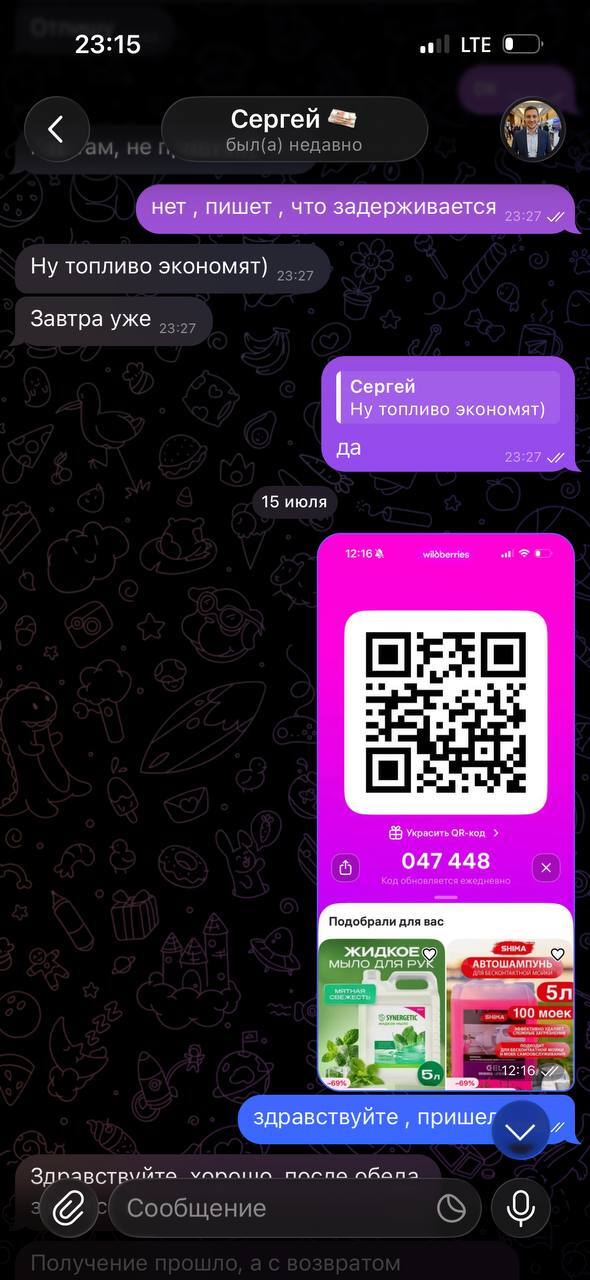
Точка невозврата
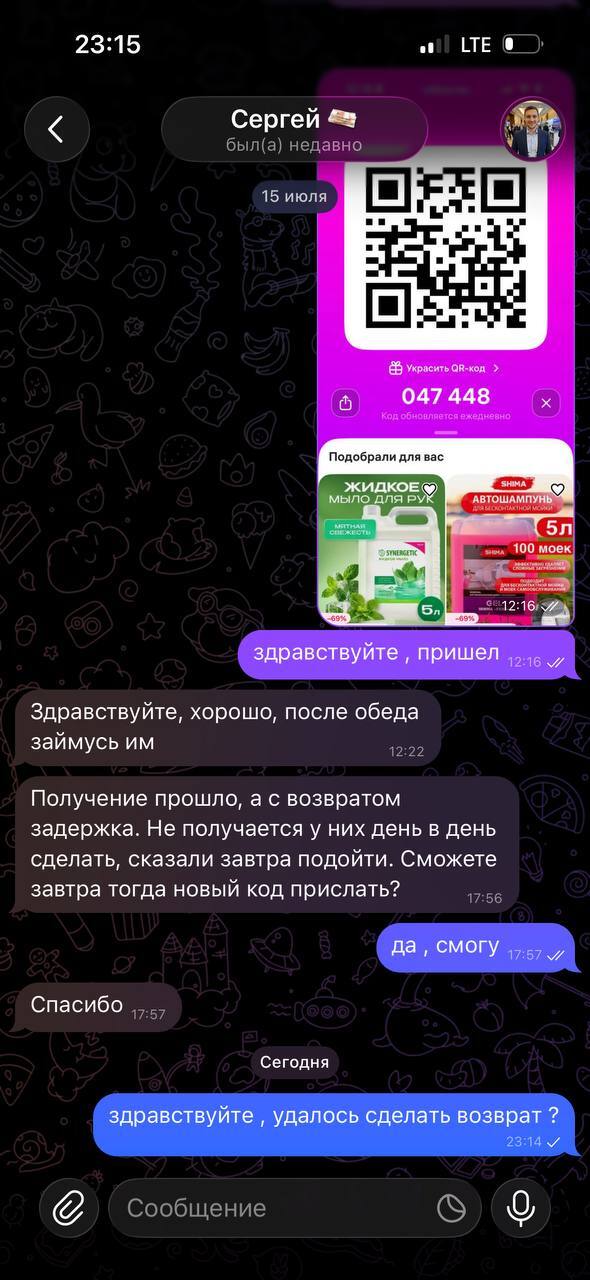
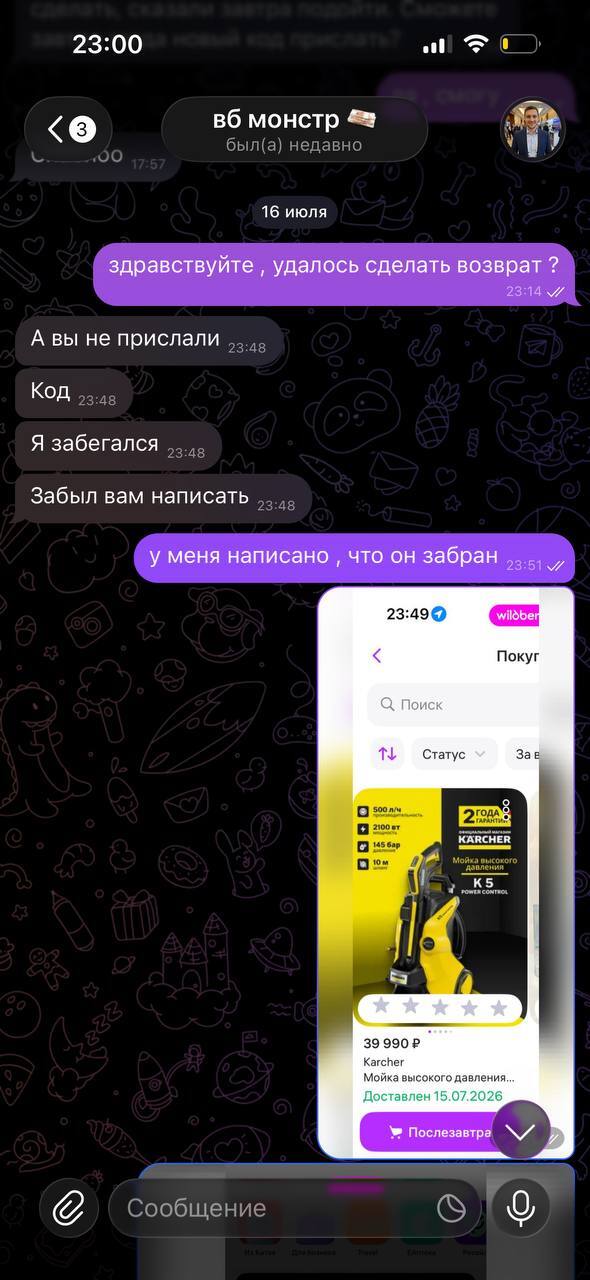
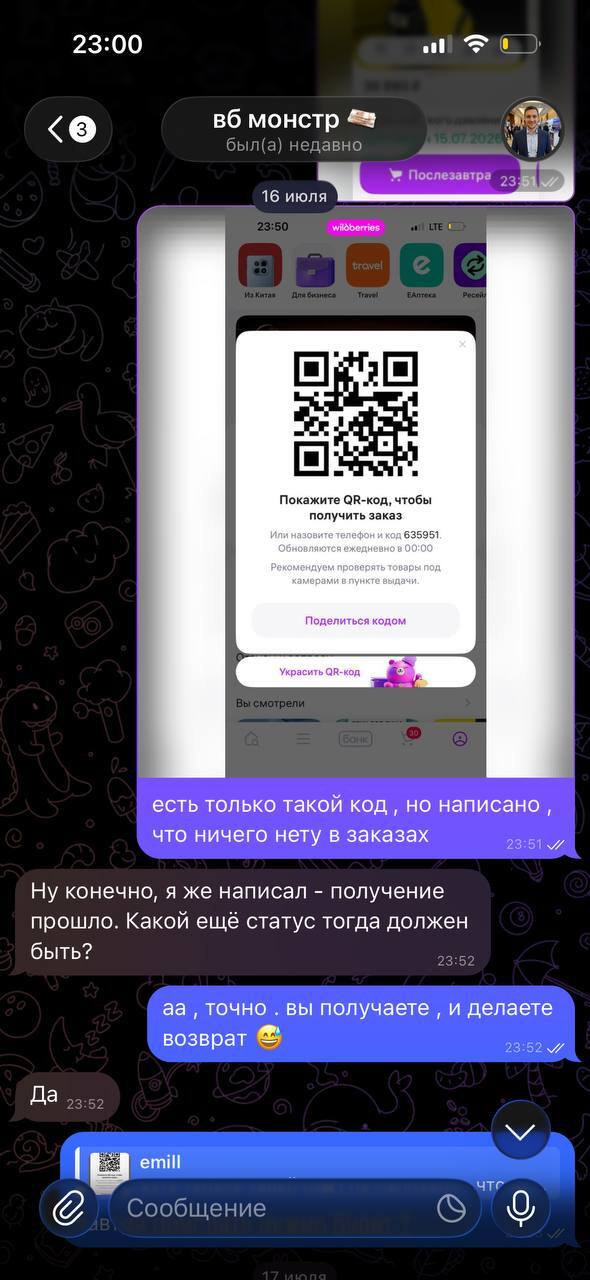
К слову он не писал, что получение прошло
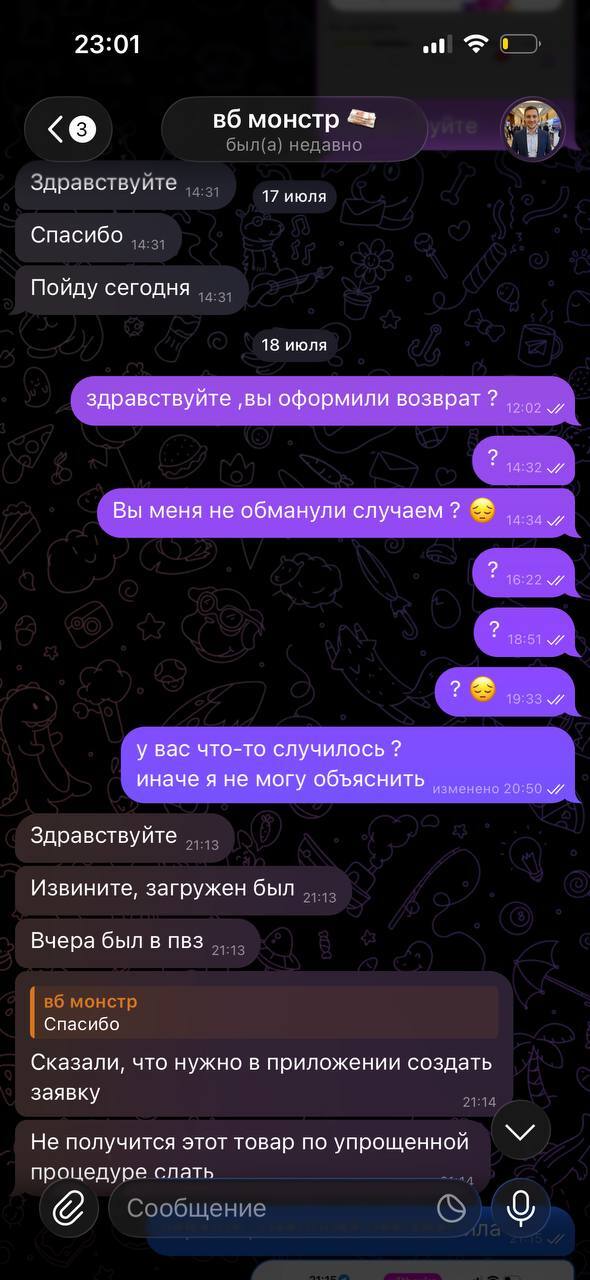
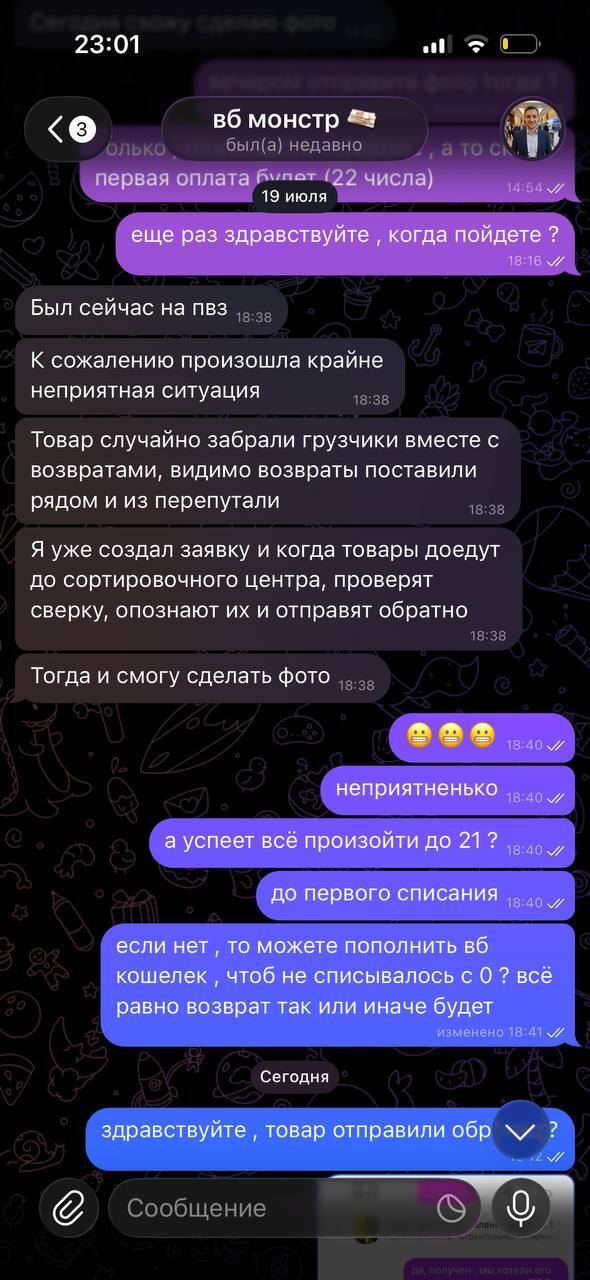
Ну и нелепое описание произошедшего
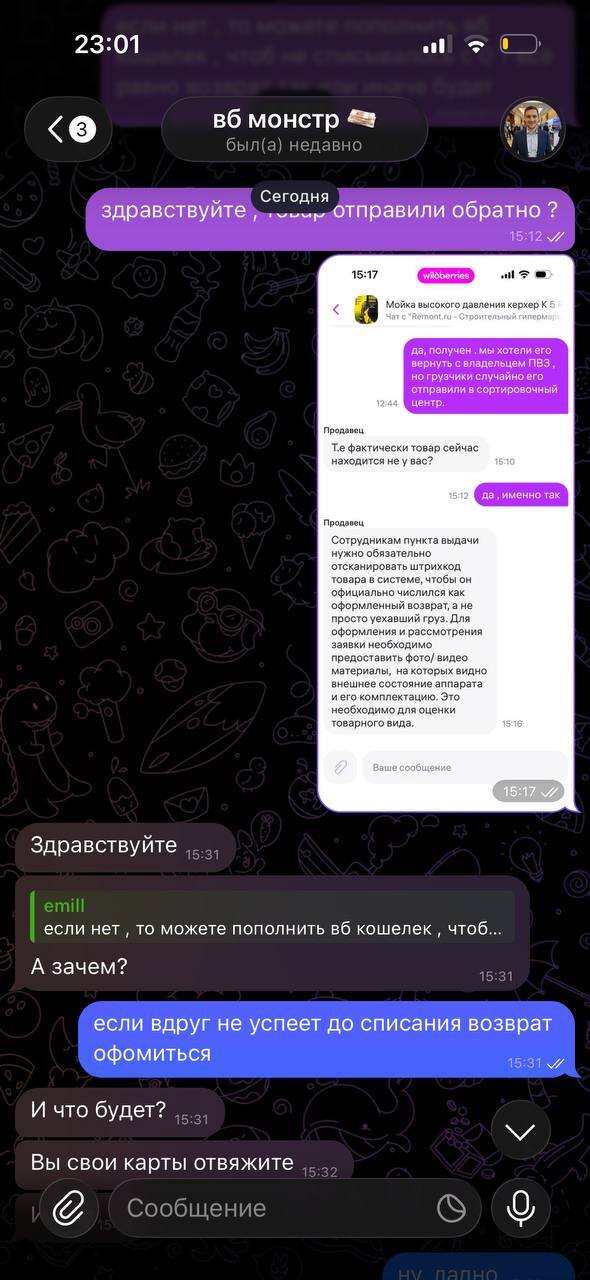
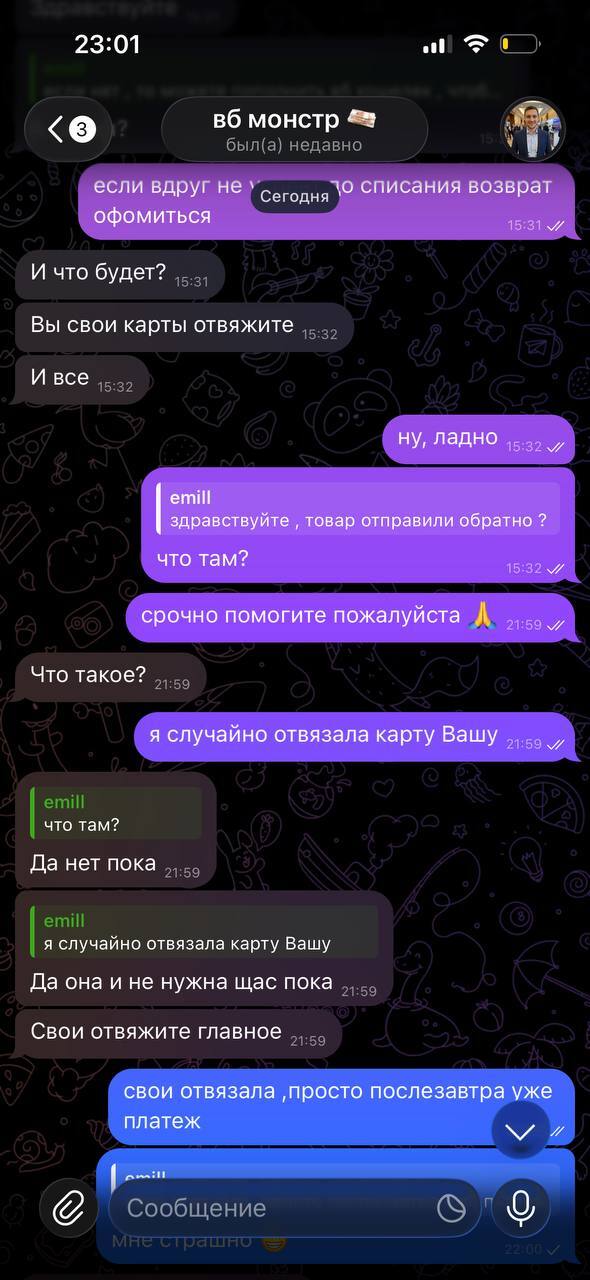
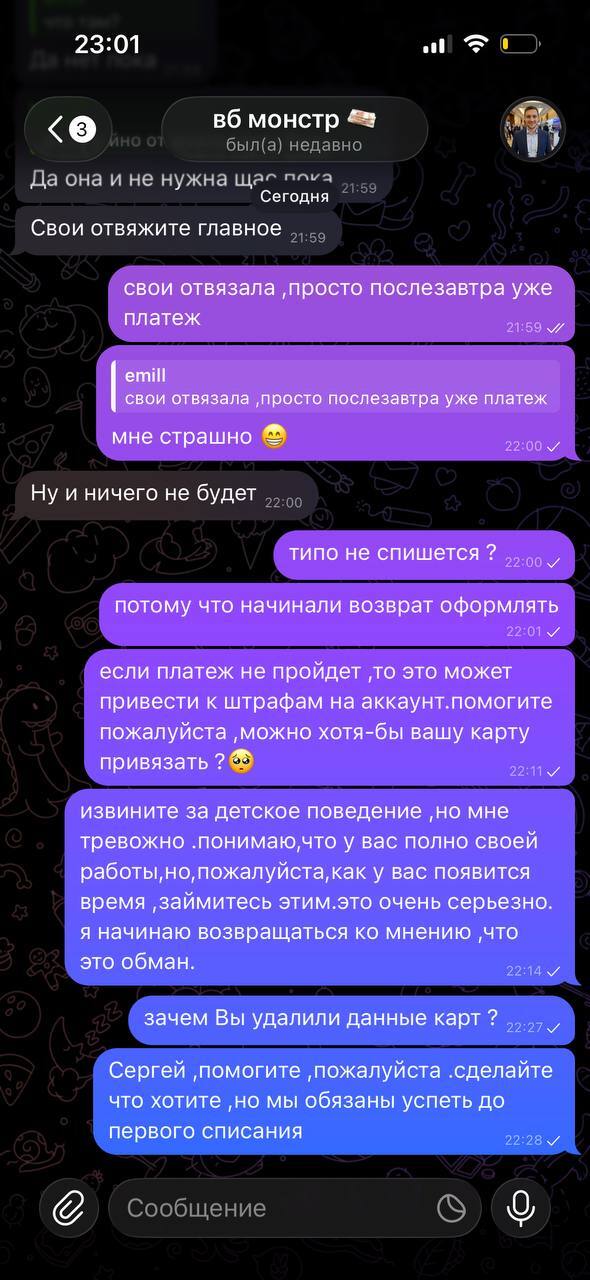
После этого дочь нам все рассказала