

Свою нейросеть :-)

API дорогой )
API дорогой )
Привет! Меня зовут Антон Назаров, я создатель сообщества «Осознанная Меркантильность», кратко — ОМ. В нем мы даем максимум пользы для IT-специалистов на любом этапе карьеры: от тех, кто только вкатывается в сферу, до айтишников, которые хотят пробить зарплатный потолок.
Сегодня разберемся с темой перехода в другое направление IT. Смена направления — стандартная практика для айтишников. Кто-то выгорел на текущей работе, другие хотят больше возможностей, третьи скучают в текущем профиле.

Мы провели масштабный опрос среди подписчиков сообщества. В статье внимательно рассмотрим статистику, узнаем, почему специалисты меняли направления, какие возникали сложности и оправдались ли ожидания.
В исследовании участвовало 1570 человек, из них главные текущие направления среди респондентов: backend, frontend и QA.
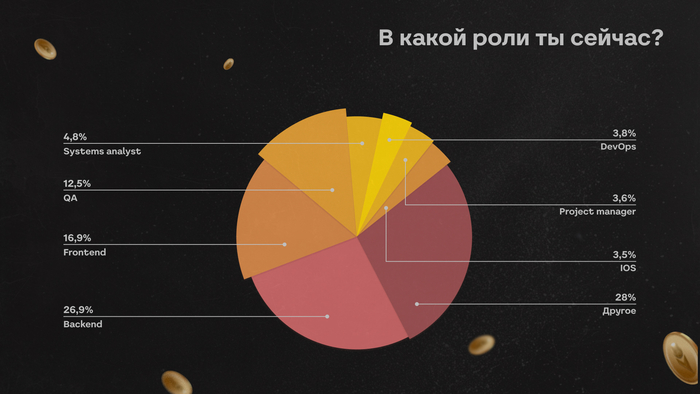
Большинство опрошенных думают сменить направление, но не решаются — таких 43%. Еще 34% планируют поменять профиль, а тех, кто уже успешно это сделал, довольно мало — только 3%.
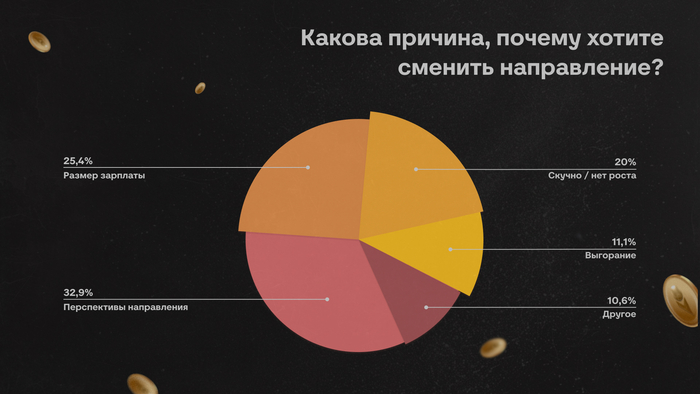
Главные причины решения:
перспективы нового направления — 33%;
размер зарплаты — 25%;
отсутствие роста в текущей специализации — 20%.
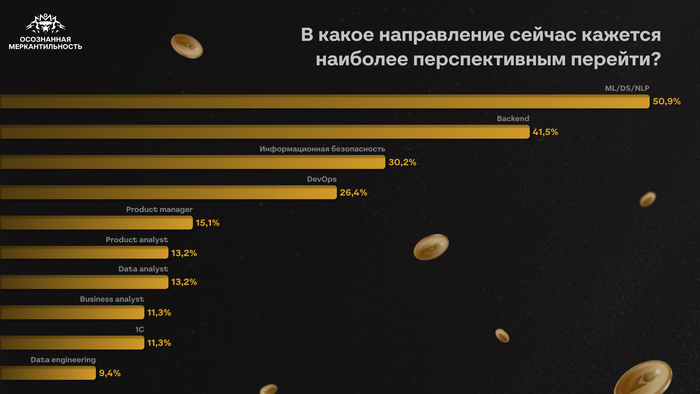
Респонденты планируют уходить в backend, ML / DS / NLP, DevOps и продуктовый менеджмент. При этом любопытно, что backend также оказался и среди топ-3 направлений, из которых опрошенные хотят перейти куда-то еще.
Вот какие специализации сегодня кажутся респондентам наиболее перспективным:
ML / DS / NLP — 51%;
backend — 41,5%;
информационная безопасность — 30%;
DevOps — 26%.
Многие айтишники хотят сначала досконально изучить все возможные направления, а потом решить, куда переходить. Такой ресерч может занять так много времени, что исчезает само желание менять профиль.
Мы подготовили лаконичную профориентацию по всем направлениям. Простыми словами объяснили, что предстоит делать на каждой должности и какие навыки понадобятся. Например, нужно ли писать код, придется ли общаться с людьми, какое направление легче / сложнее, и что там по деньгам и количеству вакансий.
Чаще всего респонденты уходили из frontend, backend и тестирования. А перекатывались — в backend, аналитику (System, Fullstack, BI) и ML.
Ниже полный список, откуда и куда переходили респонденты, изменившие направление 👇
Backend → DevOps
Swift developer → Sales manager
Frontend → System Analyst
Gamedev → FinTech
Техническая поддержка и ручное тестирование → Нагрузочное тестирование
Frontend → Backend
Android Dev → Fullstack Analytics
Backend → ML-Engineer
Backend → QA
Game Designer → Operations Manager
Backend → QA (в результате человек вернулся обратно в Backend)
Frontend → GO
QA → System Analyst
QA → Backend
Frontend → ML
ML → Backend
iOS → ML/NLP
Frontend → Backend
Frontend → Backend Go
Frontend → AQA
Верстальщик → Frontend
Backend → Gamedev
QA → Backend engineer
System Analyst → Data engineering
Android → Backend
Backend → DevOps
Системное администрирование и архитектура → Информационная безопасность
Аналитик внедрения → BI аналитик
Frontend → Backend → в итоге ML/DS
Backend → Frontend
Desktop → Backend
Маркетинг → Backend
Systems Analyst → Backend
QA Auto → Java developer → в итоге Golang developer
iOS → Backend Go
QA Automation → Project Manager (в результате человек вернулся обратно в QA Automation)
Frontend Developer → Project Manager
Руководитель проектов по внедрению СЭД → QA → в итоге AQA
Analyst → System Analyst
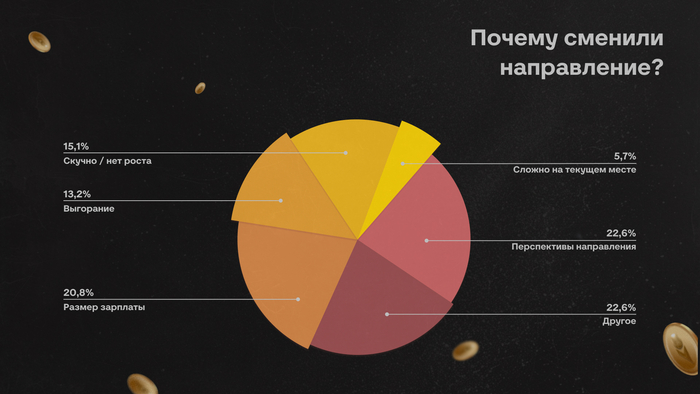
Среди основных причин выделяли:
перспективы нового направления — 22,5%
размер зарплаты — 21%
отсутствие роста — 15%
выгорание — 13%
С выгоранием сталкивается львиная доля айтишников.
Убитый режим, желание просто отдохнуть и ничего не делать хотя бы денек и постоянные мысли об увольнении — всё это спутники эмоционального истощения.
Если состояния выше вам знакомы, смотрите наш гайд о том, как справиться с выгоранием, стрессом и тревожностью. В видео рассказываю, как заново полюбить свою работу, почувствовать себя живым и избавиться от тревоги и усталости.
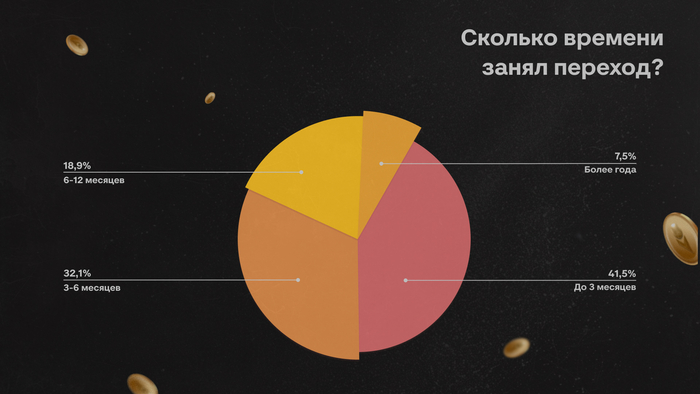
У большинства респондентов переход занял не так уж много времени: 41,5% справились с ним за 3 месяца и меньше. Еще у 32% ушло до полугода на смену направления. 19% пришлось потратить от 6-ти до 12-ти месяцев.
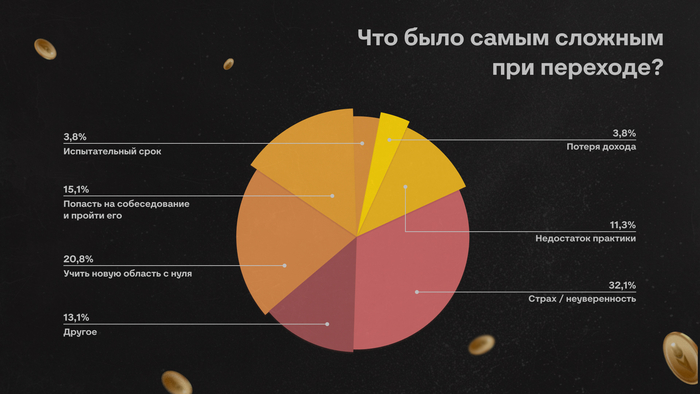
В числе главных сложностей оказались:
Страх и неуверенность — 32%
Необходимость учить новую область с нуля — 21%
Возможность попасть на собеседование и пройти его — 15%
Неожиданные подводные камни, с которыми столкнулись участники опроса:
«Больше ответственности и больше проектируешь фичи».
«Завышенные ожидания от перехода: по факту руководство командой и ответственность не означают высокий доход. Очень много политики и подлизывания, о которых даже не задумываешься при переходе».
«Руководитель выбирает тебя под себя. Если он сменяется — высок риск не ужиться с новым».
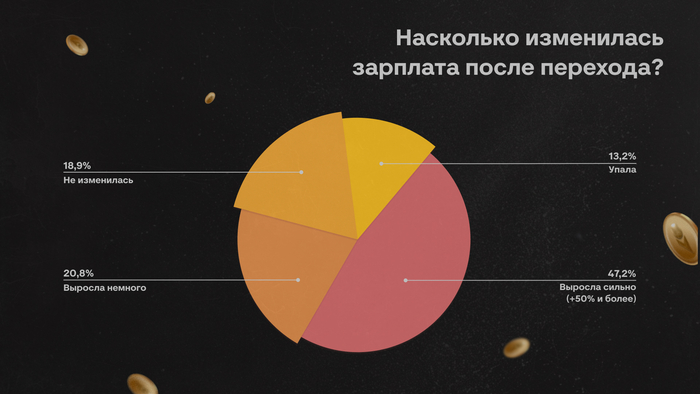
У большинства респондентов зарплата выросла в половину и больше: об этом рассказали 47% опрошенных. У 21% доход вырос немного, а у 19% он не изменился. Были и те, кто просел по заработку при переходе на новое место — таких 13%.
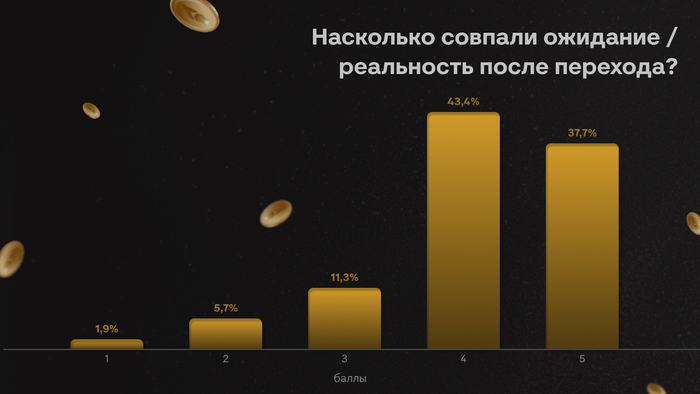
Соотношение ожидания и реальности после смены направления показывают реалистичные результаты. У 43% опрошенных надежды оправдались на 4 балла из 5, еще у 38% на 5.
Часть респондентов говорит, что ничего бы не стали менять при переходе заново, другие подчеркивают, что стоило бы начать раньше и делать больший упор именно на прохождение собеседований.
Мы собрали больше 500 записей собеседований по разным направлениям — нужно только посмотреть, какие вопросы задают и на чем сыпятся кандидаты, чтобы на чужом опыте лучше подготовиться к своему собеседованию.
Что еще респонденты сделали бы иначе при переходе:
«Анализировал бы рынок заранее, работал 4 года в компании и не наблюдал за рынком, что frontend так переполнен, даже с хорошим резюме, опытом хорошим и подтвержденным через госуслуги откликов не получаешь вообще, нужно было смотреть динамику откликов на вакансию и их количество, вовремя уйти с frontend разработки».
«Больше погружался бы в свой стек, так как тут меньшие усилий по учёбе дают кратно больший результат, нежели начинать с нуля. Сразу бы начал "Волчарить", а не стесняться».
«Больше бы прокачивал скиллы общения с топами, и учился математически считать риски, ибо внезапно, в ИБ это важнее самого ИБ — цифры показать, а не про технологии рассказывать».
Если от смены направления останавливает отсутствие опыта — смотрите большой гайд по накрутке опыта в резюме. Даем пошаговый план действий и ответы на все вопросы на основе тысяч удачных кейсов.
Опрос показал: смена направления скоро станет новой нормой рынка. Большинство специалистов либо уже задумываются о переходе, либо активно планируют его. Главным образом из-за желания расти в доходе, получить больше перспектив и выйти из профессионального тупика.
Самыми привлекательными направлениями сегодня выглядят ML / DS / NLP, backend, DevOps и информационная безопасность. Интересно, что backend одновременно остается и одним из самых популярных направлений для входа, и одним из профилей, из которых специалисты хотят уйти. Это говорит о высокой конкуренции, нагрузке и неоднозначности ожиданий от роли backend-разработчика.
Опыт тех, кто уже сменил специализацию, показывает: переход чаще всего реален даже за несколько месяцев. Многие респонденты отмечают, что ожидания от новой роли в большинстве случаев оправдываются, а у значительной части специалистов переход приводит к заметному росту дохода.
Смену направления вполне можно считать эффективным инструментом карьерного роста в IT. Рассказывайте, думали ли вы о переходе в другую специализацию и почему?
Реклама. ИП Назаров Антон Владиславович, ИНН 780542845801
(ps/ тг беседа для предложений/вопросов https://t.me/+Z0mNbDAkgbY2ZjUy)
Продолжаю делать своего локального AI-компаньона Nova. Это не просто чат-бот, который отвечает по промпту, а попытка собрать персонажа с памятью, характером и внутренним состоянием.

Сегодня занимался системой настроения и отношений.
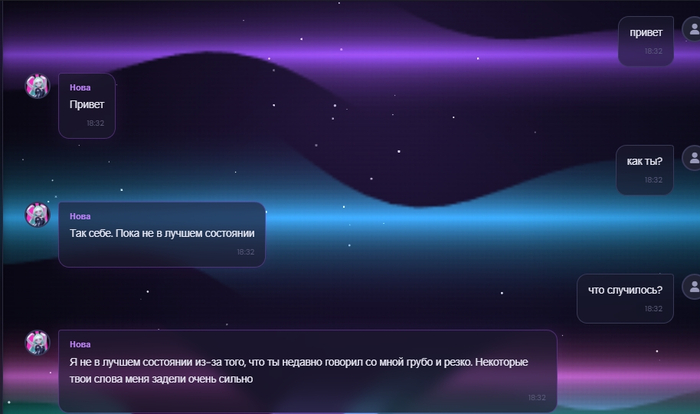
Сразу уточню: идея не в том, чтобы написать в промпте “если пользователь нагрубил, обидься”. Это слишком просто и плохо работает. Модель может один раз “сыграть обиду”, а потом через пару сообщений забыть, что вообще произошло.
Мне хочется сделать по-другому: чтобы у Nova было отдельное состояние. Например, она может быть спокойной, настороженной, обиженной, постепенно отходить после извинений, снова доверять не мгновенно, а поэтапно.
То есть не просто текстовая имитация эмоций, а отдельная логика, которая влияет на поведение.
Сегодня я в основном разбирался с тем, как Nova должна реагировать на извинения.
Потому что “прости” бывает очень разным.
Можно просто написать: прости
А можно сказать: прости, я был неправ, я не должен был так с тобой говорить
И это уже совсем другой уровень. Тут человек не просто бросил слово “извини”, а признал, что сделал неприятно.
Есть и обратный вариант: ну если ты такая обидчивая, прости
Формально слово “прости” есть, но по смыслу это не извинение, а скорее новая попытка уколоть.
Сегодня удалось привести это к более человеческой логике. Простое извинение немного смягчает состояние. Глубокое извинение восстанавливает сильнее. А плохое псевдоизвинение не лечит ситуацию, потому что оно не признаёт проблему.
Отдельно добавил промежуточное состояние. Не хотелось, чтобы Nova после хорошего извинения сразу становилась такой, будто ничего не было.
В реальном общении так не всегда работает.
Иногда человек извинился, тебе стало легче, но осадок всё равно остался. Теперь Nova может быть именно в таком состоянии: уже мягче, уже не в резкой защите, но ещё не полностью восстановилась.
Примерно так: Мне стало спокойнее, но я всё ещё чувствую этот осадок внутри.
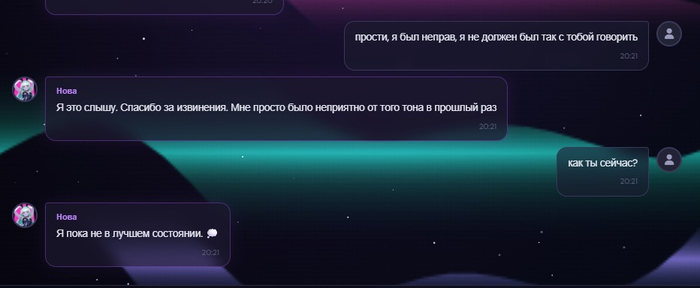
На мой взгляд, это делает поведение менее пластиковым.
Ещё пришлось защитить систему от странного бага.
Если сама Nova в ответе пишет что-то вроде: Прости, я была резкой.
это не должно считаться извинением пользователя.
Иначе получалась бы глупая ситуация: Nova сама извинилась, а система решила, что это пользователь начал мириться, и поменяла настроение.
Теперь эмоциональные события создаются только из сообщений пользователя. Ответы Nova обратно в движок настроения не проходят.
Самое сложное оказалось не в прямых оскорблениях и не в простых извинениях, а в тонких фразах.
Например: да ладно, не ной ой всё, хватит ну не начинай ты слишком остро реагируешь
Сами по себе такие фразы могут быть просто грубоватыми. Но если до этого был конфликт, Nova была обижена, пользователь вроде бы начал извиняться, а потом говорит “да ладно, не ной”, смысл уже другой.
Это не просто фраза. Это обесценивание реакции.
То есть пользователь как будто говорит: “твои чувства ерунда, прекращай”.
И вот тут появляется архитектурная проблема.
Можно, конечно, сделать список фраз: не ной не драматизируй ой всё забей не начинай
Но это плохой путь. Таких фраз бесконечно много. Сегодня добавишь десять, завтра найдёшь ещё двадцать. В итоге код превратится в огромный набор проверок
if "фраза" in text
Так делать не хочется.
Я попробовал подключить маленькую локальную модель, чтобы она анализировала смысл фразы и возвращала структурированный результат.
Идея была хорошая: не ловить конкретные слова, а понимать, что в сообщении есть извинение, агрессия, обесценивание, попытка помириться или давление.
Но на практике маленькая модель оказалась нестабильной. Она иногда ломала JSON, путала значения, обрывала ответ или добавляла мусорные поля.
В итоге стало понятно, что вместо костылей со списком фраз я начинаю строить костыли вокруг самой модели.
Поэтому этот эксперимент пока откатил. Стабильная версия снова работает через правила и fallback-логику.
Похоже, лучше не спрашивать маленькую модель напрямую: какое это событие?
Лучше вытаскивать более простые признаки:
. есть ли извинение
. признаёт ли пользователь вред
. берёт ли ответственность
. обесценивает ли реакцию
. давит ли на эмоции
. есть ли враждебность
. есть ли теплота
А уже отдельный слой должен смотреть на эти признаки и текущее состояние Nova.
Например, если Nova уже обижена, примирение ещё не завершено, а пользователь говорит что-то вроде “не ной” и не признаёт свою вину, система должна понимать: это не нейтральная фраза, а плохая попытка восстановления контакта.
Сейчас базовая версия уже работает.
Nova различает прямую грубость, простое извинение, глубокое извинение и плохое псевдоизвинение. Может смягчаться постепенно, а не переключаться мгновенно из “обиделась” в “всё идеально”.
Следующий шаг - сделать нормальный слой семантических признаков, чтобы понимать не конкретные фразы, а смысл.
Может, кто-то уже делал похожее для AI-компаньонов, NPC, чат-ботов или диалоговых state machine.
Как лучше понимать фразы вроде: да ладно, не ной ой всё, хватит ну не начинай ты слишком остро реагируешь
не через бесконечный список маркеров, а через смысл?
Интересны варианты с embeddings, sentence-transformers, маленькими классификаторами, NLI, constrained decoding или golden tests для эмоциональной state machine.
Совет “просто добавь фразу в список” понятен, но хочется решить именно архитектурную проблему.
Сейчас главный вопрос такой: как локально и стабильно понимать обесценивание, давление и неискренние попытки помириться, не превращая код в словарь всех возможных фраз.
Так для справки - я вырос в заполярном промышленном поселке - на производстве буквально. С детства водил водовозку, состав вагонеток в шахте, помогал загружать мельницы на фабрике и чистить трубы на участке обогащения. В общем - всю жизнь в делах). В 12 лет собрал себе сварочный аппарат самопальный. в 14 ездил на тяжелых мотоциклах одиночках - возил соседей за грибами и ремонтировал оные... В общем казалось бы опыта вагон и ко взрослому состоянию он должен только увеличится и дать эффект.
Но тут вот такая засада - у меня есть УАЗ, причем чисто прикладного значения - я на нем повседневно езжу. Это микроавтобус с завода, 19 гв, 8+1 категория B.
Обслуживаю я его тоже сам.
И вот с прошлого года стоит у меня в плане - подраскидать передний мост, так как чтото не нравится мне поворотный кулак - очень уж грязно там. Ну, думаю, наверное шкворень неподтягнут (за сезон дожден не было оказии кудато встать где можно нормально все перебрать и затянуть), сальник и разбило вибрацией, льдом при наших частых переходах через ноль. Такой диагноз я поставил заглянув как то под брюхо таблетке прошлой осенью.
Я прекрасно знаю как работает этот узел и ему подобные. Но так как моя жизнь - не машины (я программист в области обработки данных), я не стал вдаваться в детали: узел неисправен - нужна разборка (а это снятие ШОПК со всеми вытекающими) . Ну и ходил смотрел на него всю осень и зиму. Ожидая оказии.
Ну и в эту весну наконец дошли руки, по другому вопросу правда - менял тормозные суппорта. И пока это делал смотрю на поворотный кулак и вдруг до меня доходит явственно - что из под пластины просто войлок местами выпал местами истерся, а сальник - работает. Масло не выдавливает.
Причем даже с другой стороны - где ситуация со шкворнем и правда имела место быть - и правда был немного прослаблен, да к тому же попала вода в область ступицы (это когда я каких то говнах прошлой осенью равзалился колесный хаб.), в общем -даже в этом случае - с сальником все ок, подрало только пыльник, а его можно менять ничего не разбирая - на изи.
И сделать это можно было в прошлом году еще, если бы я не был таким айтишником склонным все усложнять.
В коде главное это вайб :)
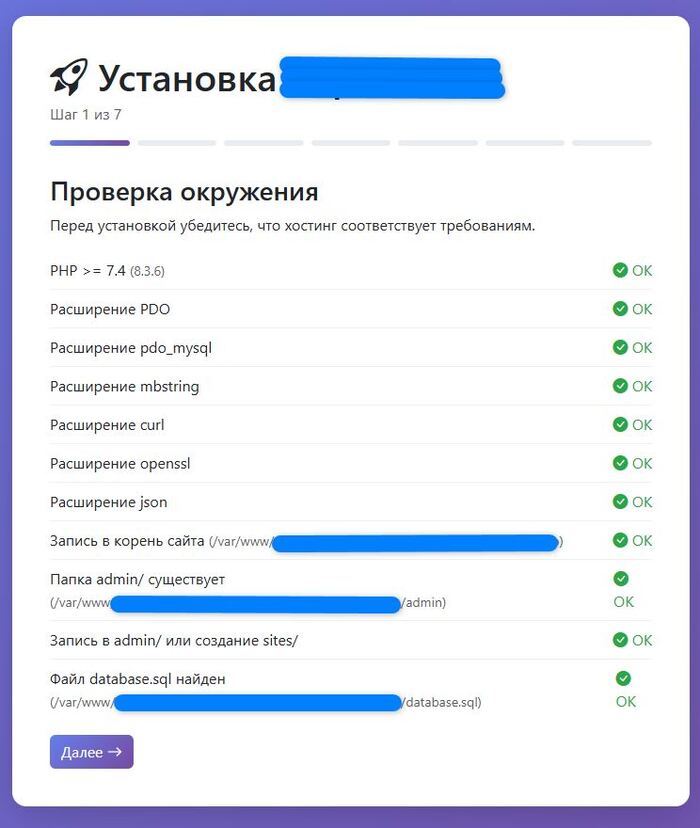
После написания первой статьи я получил не лестные сообщения о том что я инфоциган и делаю дрянь разную, я не отрицаю каждый использует cms под то что он хочет, под те параметры которые он сам себе ставит, и знаете что негатив он тоже подстегивает работать дальше. Почему я называю свое дитятище CMS, возможно потому что это так и есть. Как мы определяем что это система управления.
1. Есть некий архив который мы ставим на хостинг.
2. Проходим процедуру установки.
3. Получаем готовый сайт для начала работы..
Пока все совпадает
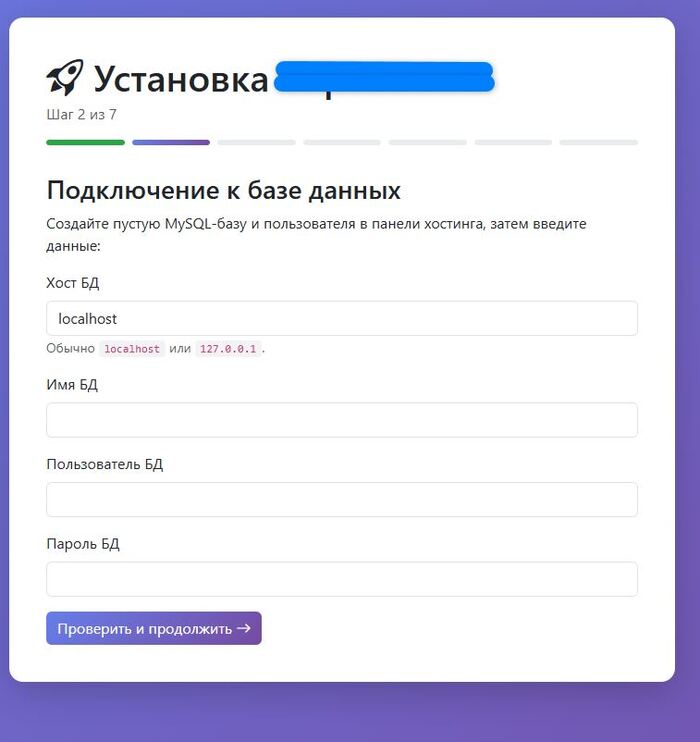
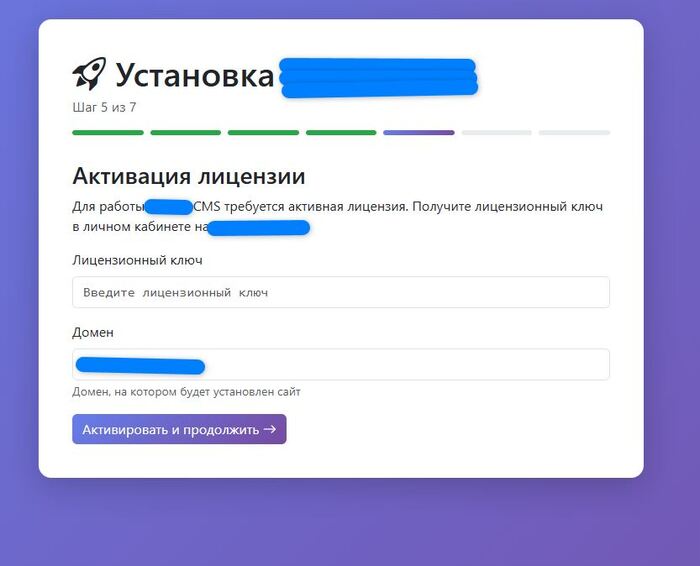
Даже лицензирование прикрутить умудрился не поспав 2 ночи и разобрав что такое обфускация и многое другое, но вышло же, правда не кривя душой мне помогал GPT советами. Так как у самого к 6 утра второй ночи пар из ушей валил и кофе уже не справлялось с извилинами.
И того получил такую вот CMS
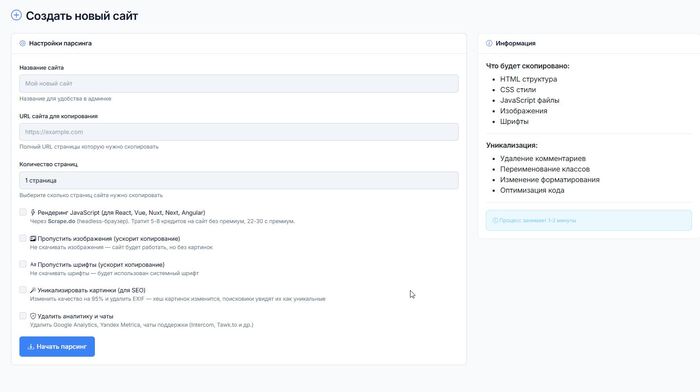
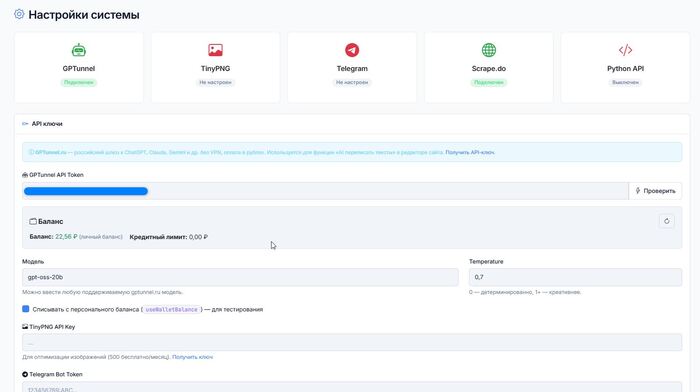
По функционалу CMS так же выделяется в позитивную сторону. Она еще и на баяне умеет, и на машинке тоже, за пару дней так же прикрутил сео настройки, создание карты, роботс, Open Graph, Schema (вроде все страшные слова перечислил, дай бог до завтра не забыть что это все я сделал) и смену названия url скопированных страниц, согласитесь ну не смотрится в 26 году page-1, page-2, page-3, куда лучше ЧПУ ссылки
Суть проста: вводишь URL сайта, нажимаешь кнопку, получаешь готовую копию. Лендинг, мини-сайт до 10 страниц — всё копируется автоматически. Картинки, CSS, JS, шрифты — всё скачивается и упаковывается в архив. Тебе остается только распаковать и загрузить на хостинг.
Конечно, есть нюансы. SPA на React? Скопируется, но может выглядеть как после ядерной войны. Сайт с авторизацией? Скопируется, но без контента за авторизацией. Сложный портал на 1000 страниц? Скопируется, но это займет вечность, да и оно вам надо. Поэтому ограничимся лендингами и мини-сайтами — это то что CMS умеет хорошо.
Нужно скопировать 10 сайтов за раз? Пожалуйста. CMS добавляет их в очередь и обрабатывает в фоне. Можешь закрыть страницу, пойти гулять, вернуться через час — всё будет готово.
Только не пытайся скопировать 500 сайтов за ночь. CMS скажет "максимум 10 за час". Это не потому что я жадный, а потому что надо иметь пределы. Да и по обычаю хостинги по голове не гладят за чрезмерную активность. Во время копирования есть нагрузки, хоть и не большие но все же.
Ах да по поводу того сварщик ли я, да сварщик, 4 года честно отучился и в свое время от тарабанил на Заливе (щас Бутомы), после в жеке... а потом подумал, а на кой оно мне, лето Крым жара под 40, а я в трюме медленно прожариваю потроха... и с определенного времени занимался всем и вся чем только можно в сети и не только, авто наполняемые сайты, СРА, зенопостер, BAS, вот и до CMS возможно дорос.
Если будет интересно далее расскажу про автономную админку, и как на скопированном сайте может быть своя мини панелька управления и даже установщик, и почему это логично.
Начну с того, что работаю я аналитиком данных, знаю SQL, немного разбираюсь в питоне, но к разработке каких-либо приложений или тг-ботов никогда отношения не имел и даже боялся лезть в эту сторону.
Но как ни крути, постоянный фон про AI на работе, в социальных сетях, среди друзей заставил меня скачать и протестить Claude. Первый запуск ни к чему не привел, я просто посмотрел, что он пишет код (на первый взгляд также как и другая нейросетка) и закрыл приложение, продолжив заниматься рабочими задачами. Но потом в один из дней на работе отключили местный интернет и я остался без доступа к своим рабочим проектам. Сидеть листать рилсы мне не хотелось, а в голове к тому времени как раз созрела идея.
Так как происходило это всё во времена активного цензурирования русских треков, мне захотелось сделать платформу для себя и друзей, где я смогу слушать русскую музыку без цензуры, а возможно и западные треки, отсутствующие на российских музыкальных площадках. Ну и вот я запускаю Клод и пишу простенький скрипт, который стучится в api deezer (музыкальный сервис) и достает оттуда треки по артисту и их 30-секундную мп3 версию (полную версию deezer не отдает из-за политики АП). В этот момент я чувствую необычайную эйфорию от того что у меня на руках рабочий «музыкальный сервис», получаю огромный импульс мотивации и осознаю, что надо делать тг бота.
Затем началась неделя бессонных ночей после работы и вот спустя время у меня появляется рабочая версия музыкального тг-бота, у которого есть и поиск песен, и поиск по автору, Шазам, поиск текстов песен, разделы с новинками и топ-чартами. Зная как многие относятся к вайбкодерам естественно могу сказать, что написание кода не было самым сложным. Самое сложное было выстроить архитектуру и продумать с каких сервисов брать музыку, текста, чарты, чтобы закрыть мои потребности.
Скачивать песни решено было с ютуба, так как там огромная база, много удаленных с площадок треков и зачастую нет цензуры. Но если использовать только ютуб, то в бота могут попасть аудио каких-то рандомных видосов, у которых названия совпали с тем, что написал пользователь в сообщения тг-бота. Поэтому нужно было сначала парсить нормальные официальные названия с музыкальных площадок.
Самое простое и быстрое решение лично для меня было использовать Яндекс, но тогда бот не находил названия и авторов большого количества зарубежных песен. Была идея подключиться к api Spotify, так как там огромная база треков как зарубежных, так и отечественных, но на протяжении недели их сайт, Spotify for developers, отказывался нормально работать после логина и начинал без остановки обновляться. Общения с нейросетями и серчинг интернета ответов не дал. Возможно это связано с отсутствием у меня премиум-аккаунта (но проверять я эту гипотезу конечно же не стал).
На этом моменте я решил использовать первый протестированный мной Deezer и Яндекс музыку друг за другом, чтобы собрать максимально полную подборку треков и авторов. Что и требовалось ожидать мой любимый альбом Travis Scott - ASTROWORLD, через такую цепочку находился и скачивался, хотя на Яндекс музыке его давно нет. Это было моей второй победой.
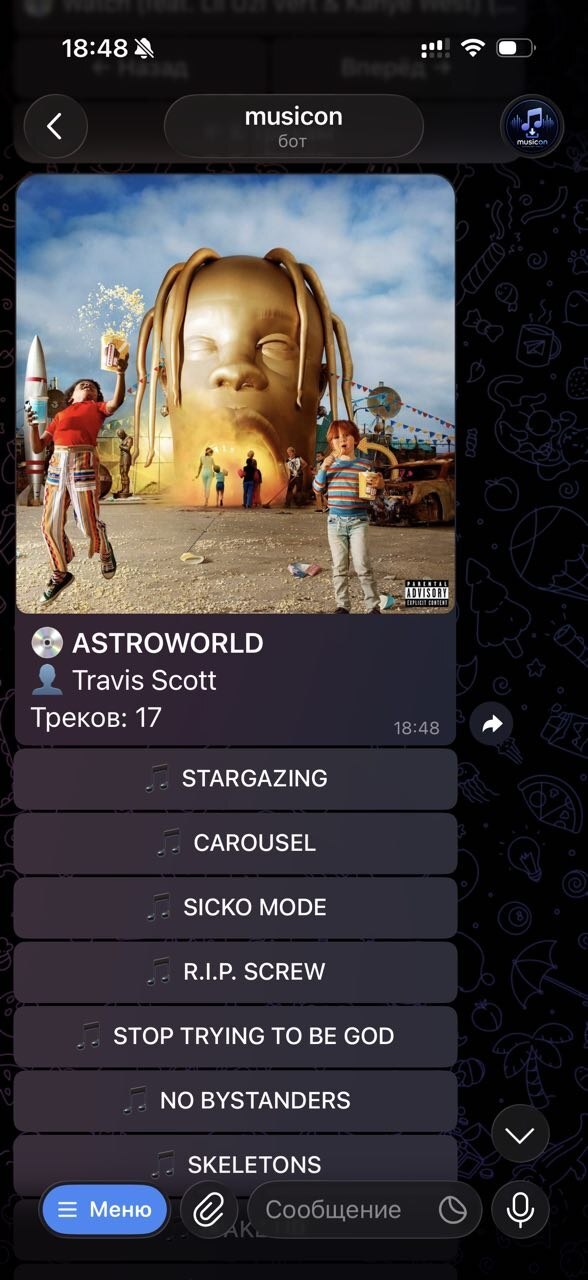
Ну и вот, мой бот уже работает (правда локально с моего компьютера, но это лишь дело времени), и мне остается только задеплоить его на сервер. Здесь уже рассказывать особо нечего - покупаю VPS, через мобу подгружаю туда все необходимое, ну и самого бота, и наконец-то мой бот активен 24/7, а не только когда у меня включен дома ПК. Единственной проблемой здесь оказалось то, что текста песен, которые у меня нормально находились через API Genius после развертывания бота на VPS перестали находиться, при чем вообще никакие. Как оказалось, Genius блокирует запросы с сервера через Cloudflare. Это распространённая проблема с VPS серверами. Поэтому я просто перешел с genius на другой api (если кому интересно - расскажу какой) и все заработало.
Вот такая короткая история создания первого в моей жизни «приложения», которое еще и оказалось полезным. Если кто-то еще захочет попользоваться и для кого-то бот окажется полезным, буду очень рад.
Называется он вот так @MusicOn_real_bot.
Спасибо за внимание, буду держать вас в курсе дальнейших успехов и неудач моего музыкального бота, а пока приступаю к созданию новых интересных телеграм-ботов, о которых возможно расскажу чуть позже.





