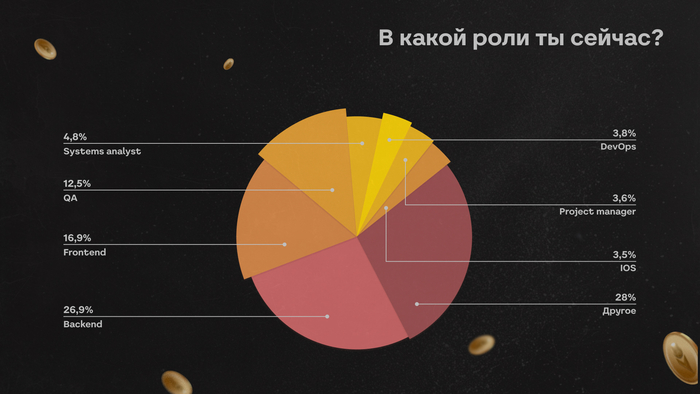
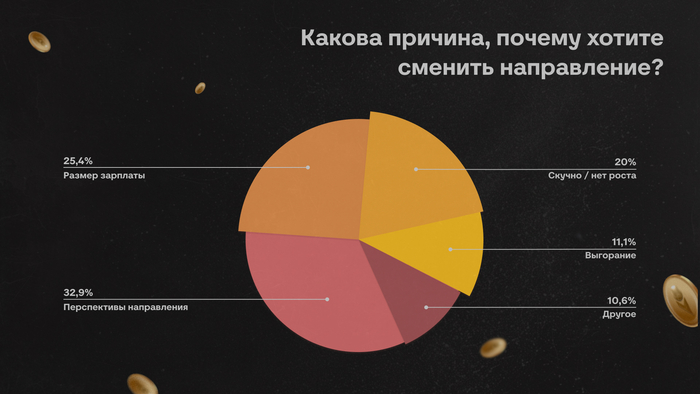
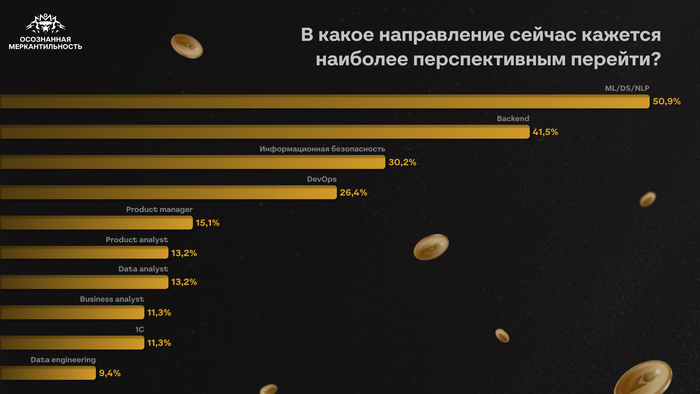
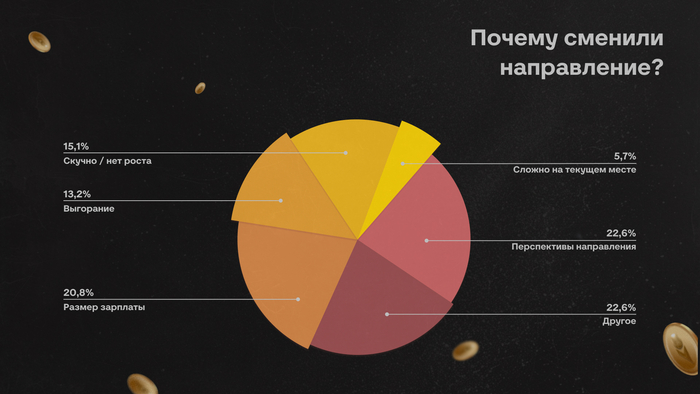
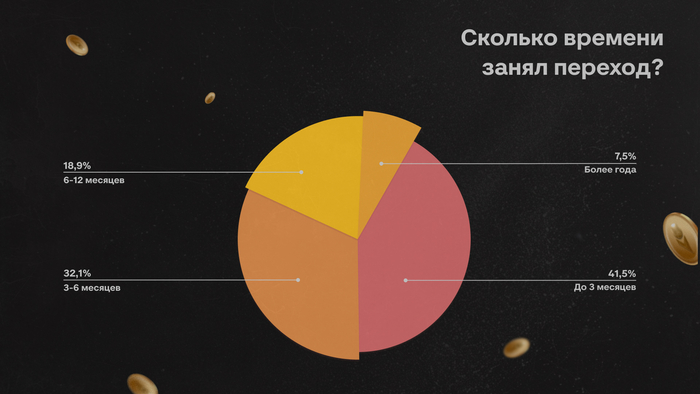
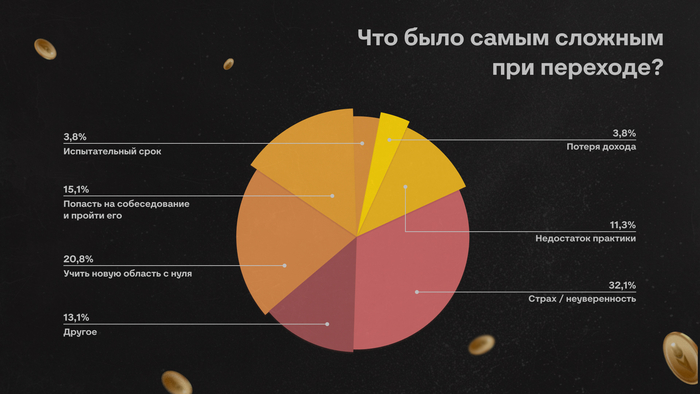
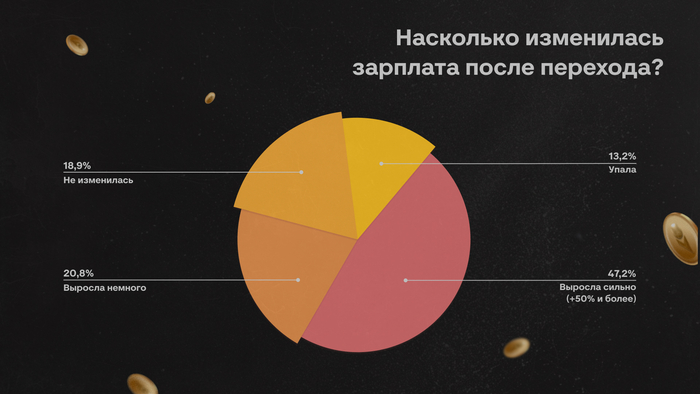
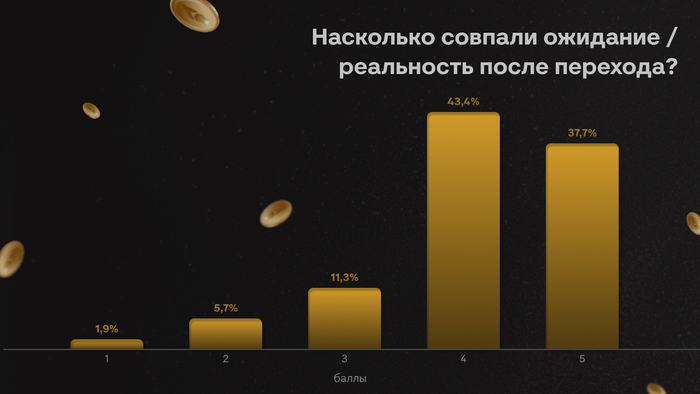
Многие до сих пор воспринимают собеседования примерно одинаково. Кажется, что всё решает техническая часть: насколько быстро ты соображаешь, как пишешь код, помнишь ли теорию, можешь ли объяснить сложность алгоритма или нарисовать архитектуру на доске.
На практике всё часто работает чуть иначе.
Да, техничка важна. Никто с этим не спорит. Но оффер нередко ломается не на алгоритмах, не на лайвкодинге и даже не на ошибке в каком-нибудь ответе. Очень часто всё решают вопросы, которые на первый взгляд выглядят максимально безобидно. Из серии: “кем вы видите себя через пять лет?”, “что вас мотивирует?”, “почему хотите уйти?” или “какой у вас был самый большой косяк?”.
И вот именно на них люди регулярно сыпятся.
Не потому что они глупые. И не потому что не умеют разговаривать. А потому что воспринимают эти вопросы как формальность. Как будто это просто обязательный HR-блок, который надо пережить перед чем-то действительно важным.
Хотя на деле именно там интервьюер часто и пытается понять главное: как вы мыслите, насколько вы устойчивы, чего хотите от работы и совпадает ли это с реальностью конкретной команды.
Сразу уточню важный момент. Я не пытаюсь доказать, что такие вопросы идеальны или что именно так и нужно проводить собеседования. У многих к ним вполне обоснованные претензии, и я их понимаю. Но пока рынок продолжает их задавать, полезно хотя бы понимать, что именно через них пытаются считать и почему на seemingly простом ответе иногда тихо умирает оффер.
Почему вообще такие вопросы так важны
Потому что технические ответы очень часто показывают только верхний слой.
Можно хорошо помнить теорию. Можно неплохо выступить на лайвкодинге. Можно уверенно пройти по стеку. Но при этом оставить после себя ощущение, что с человеком дальше будет тяжело: он быстро выгорит, упрётся в потолок роли, не совпадёт по темпу или просто уйдёт через полгода.
Именно поэтому рынок так любит эти странные вопросы, которые вроде бы не про технологии.
Они не проверяют знания. Они проверяют совместимость.
У работодателя сегодня часто десятки кандидатов на одну позицию. И в такой конкуренции не обязательно провалиться, чтобы не получить оффер. Иногда достаточно одного маленького сомнения. Без драмы, без явного фейла, без какого-то громкого “нет”. Просто в какой-то момент компания решает, что рядом есть кандидат чуть безопаснее, чуть понятнее и чуть лучше совпадающий с контекстом роли.
Обычно в такой ситуации человек думает, что ошибся где-то в техничке. Не вспомнил что-то важное, не добил задачу, не так ответил на вопрос по стеку.
Хотя на самом деле отказ мог начаться гораздо раньше — на одном из этих “простых” разговорных вопросов.
“Кем вы видите себя через 5 лет?”
Это один из самых банальных вопросов на рынке. Настолько банальный, что многие отвечают на него вообще не думая. Автоматически. Почти как на вопрос “расскажите о себе”.
Но проблема в том, что компания задаёт его не ради твоего жизненного плана. Всем более-менее очевидно, что через пять лет человек может оказаться где угодно. Особенно в IT, где всё меняется быстрее, чем успеваешь обновлять резюме.
На самом деле здесь пытаются понять более простую вещь: совпадает ли твой вектор с тем, что тебе реально смогут дать внутри этой роли.
Допустим, ты говоришь: “хочу стать тимлидом”. Сам по себе ответ нормальный. Амбиции — это не плохо. Но если в команде уже есть устойчивый лидер, рост внутри структуры медленный, а нанимают они middle, который нужен сюда и сейчас на стабильную долгую работу, то слышат они примерно следующее: “через какое-то время мне станет тесно, и я уйду”.
И всё. Этого уже достаточно, чтобы появился риск.
Здесь важно понимать неприятную вещь: компания редко оценивает твой ответ абстрактно, как красивую мысль о будущем. Она почти всегда прогоняет его через контекст текущей вакансии. Если им нужен человек, который будет методично закрывать задачи в продукте и не ждать повышения каждые полгода, то слишком агрессивный вектор роста для них — это не плюс, а потенциальная проблема.
Поэтому сильный ответ на такой вопрос обычно не про фантазии на тему “кем я стану”, а про понятное продолжение той роли, на которую ты идёшь.
Если вакансия техническая и без управленческого трека, нормально звучит ответ в духе: хочу углубляться в экспертизу, брать более сложные задачи, лучше понимать систему и закрывать более тяжёлые инженерные направления.
Если в роли реально есть перспектива архитектурного или лидерского роста, можно аккуратно говорить и про это — но без ощущения, что ты уже мысленно перешагнул текущую позицию и смотришь на неё как на временную пересадку.
Смысл здесь не в том, чтобы подстроиться. Смысл в том, чтобы показать: ты понимаешь, куда идёшь, и твой вектор не конфликтует с реальностью вакансии.
“Ваше самое большое достижение?”
Этот вопрос тоже звучит максимально формально. Но именно на нём очень хорошо видно, умеет человек вообще осмыслять свой вклад или нет.
Проблема большинства ответов в том, что они либо слишком размытые, либо полностью растворяются в коллективном “мы”.
“Мы улучшили процесс”.
“Мы ускорили регрессию”.
“Мы внедрили новый подход”.
Звучит вроде бы неплохо, но интервьюер в этот момент остаётся с простым вопросом: а что конкретно сделал ты?
И вот это как раз то, что он и пытается понять.
Такой вопрос редко проверяет, насколько грандиозным было достижение. Гораздо чаще он проверяет, замечаешь ли ты полезные изменения вокруг себя, умеешь ли брать на себя инициативу и можешь ли внятно объяснить, где именно проходила твоя зона ответственности.
Сильный ответ обычно строится очень просто: был контекст, была проблема, было твоё конкретное действие, был понятный результат.
Например, если рассказать, что подготовка тестовых данных раньше занимала несколько часов, ты увидел в этом рутину, собрал решение, согласовал его и в итоге сократил процесс до нескольких минут, — это уже хороший ответ. Он показывает и инициативу, и самостоятельность, и эффект.
А вот абстрактное “я хорошо выполнял свою работу” почти ничего не даёт. Это не достижение. Это базовое ожидание от любого сотрудника.
Поэтому здесь важно не “продать себя покрасивее”, а научиться без лишней скромности и без лишнего пафоса говорить о своих реальных результатах.
“Самый большой косяк?”
Вот здесь обычно начинается самое интересное.
Есть две крайности, в которые кандидаты регулярно улетают.
Первая — это люди, у которых ошибок никогда не было. Ни одной. За всю карьеру. Всё всегда шло идеально, решения принимались безупречно, прод не падал, косяков не случалось. Звучит это, мягко говоря, подозрительно. Не как профессионализм, а как отсутствие рефлексии.
Вторая крайность — это когда человек, наоборот, начинает слишком усердно себя закапывать. Формально он честен, но из ответа получается почти саморазоблачение: “я всё сломал, всё уронил, всех подвёл, потом ещё долго страдал и до сих пор помню это как главную трагедию жизни”.
Потому что вопрос тут не про то, был ли у тебя факап. У всех, кто реально работал, они были. Вопрос в другом: как ты с этим работаешь.
Сильный ответ обычно выглядит довольно спокойно. Да, была ошибка. Да, последствия были неприятные. Да, я её разобрал, исправил, сделал выводы и после этого что-то поменял в процессе, документации или подходе, чтобы ситуация не повторялась.
То есть интервьюер хочет увидеть не “идеального” человека, а зрелого.
Человека, который не отрицает ошибки и не разваливается под их весом. Который умеет признавать, анализировать и менять поведение после этого.
И вот это, на самом деле, куда важнее самой истории.
“Что вас мотивирует?”
Это вообще один из самых коварных вопросов. Потому что почти все знают набор социально одобряемых ответов.
“Интересные задачи”.
“Развитие”.
“Сильная команда”.
“Влияние на продукт”.
Формально всё правильно. Практически — это ни о чём.
Потому что такие ответы звучат слишком универсально. Они подходят вообще всем. А значит, не дают почти никакого сигнала о тебе как о человеке.
Интервьюер в этот момент пытается понять не то, насколько ты красиво умеешь говорить про вдохновение. Он пытается понять, что будет держать тебя в нормальном рабочем состоянии через несколько месяцев, когда эффект новой работы закончится и останется обычная реальность: дедлайны, легаси, коммуникации, приоритеты бизнеса, рутина и странные сюрпризы продакшена.
Поэтому сильный ответ здесь почти всегда завязан на понимание конкретной вакансии.
Если ты идёшь в продуктовую команду, логично говорить, что тебя драйвит работа с продуктом, постепенные системные улучшения, возможность влиять на пользовательский опыт, видеть результат своей работы и долго докручивать то, за что отвечаешь.
Если это история про сложную инженерную среду, можно говорить про глубокие технические задачи, сложные системы, нетривиальные интеграции и то, что тебя держит именно сложность.
Главное — не выдавать дежурный набор красивых слов, а показать, что ты реально понимаешь, что за работа перед тобой, и можешь объяснить, почему именно в такой среде тебе будет комфортно долго.
“Что вас демотивирует?”
Этот вопрос опасен по другой причине. На нём люди часто начинают говорить максимально общими словами, которые либо ничего не значат, либо работают против них.
“Токсичность”.
“Рутина”.
“Переработки”.
“Скучные задачи”.
Проблема не в том, что это неправильные вещи. Проблема в том, что они слишком расплывчатые.
Под токсичностью каждый понимает что-то своё.
Под рутиной — тоже.
Под скучными задачами вообще можно подписать половину реальной работы в любой большой компании.
Интервьюер здесь пытается понять не твои боли как таковые, а то, насколько твои рабочие ожидания совпадают с тем, что у них происходит на практике.
Если у компании много легаси, а ты говоришь, что тебя убивает работа со старыми системами и отсутствие “современного стека”, то дальше логика уже очевидна. Это просто не ваша среда. И лучше понять это на интервью, чем через месяц после выхода.
Если же ты спокойно объясняешь, что тебя выбивает хаос без приоритетов, постоянная смена направления без объяснений и отсутствие понятной логики в решениях, а компания как раз пытается строить более зрелый процесс, это, наоборот, хороший сигнал.
Сильный ответ здесь обычно звучит не как жалоба, а как описание среды, в которой ты работаешь устойчиво.
То есть ты не перечисляешь, что тебя бесит в жизни. Ты показываешь, какие условия помогают тебе быть нормальным специалистом и где ты, наоборот, начнёшь быстро разваливаться по мотивации.
“Почему хотите уйти с предыдущего места?”
Вот это, на мой взгляд, вообще один из самых важных вопросов всего интервью.
Потому что он почти всегда не про прошлое. Он про будущее. Про то, как ты принимаешь решения, почему двигаешься дальше и не повторится ли та же история у них через полгода.
Самая частая ошибка здесь — начать объяснять, откуда ты бежишь, вместо того чтобы показать, куда ты идёшь.
“Стало скучно”.
“Не нравятся процессы”.
“Перерос компанию”.
“Устал”.
“Надоело”.
Все эти ответы могут быть честными. Но проблема в том, что каждый из них вызывает у работодателя следующий вопрос: а почему у нас не станет точно так же?
И если на это нет убедительного продолжения, в голове интервьюера появляется очень неприятная мысль: человек уходит не к чему-то, а от чего-то. А значит, вполне может точно так же уйти и от нас.
Сильный ответ здесь обычно строится через логику перехода.
Не “у меня всё плохо, спасите”.
А “я понял, в какую сторону хочу двигаться, и ваша роль с этим совпадает”.
Например, если ты сейчас сидишь в поддержке легаси и хочешь перейти в продуктовую разработку с более живым влиянием на систему и процессы, это уже понятная история. Если ты ищешь среду с большей автономией, более прозрачной логикой принятия решений или более инженерным подходом к работе — тоже нормально.
Главное, чтобы в ответе было видно: ты не просто устал от старой компании, а действительно понимаешь, чего ищешь дальше и почему именно эта вакансия выглядит логичным следующим шагом.
Что в итоге
Парадокс собеседований в том, что самые простые вопросы часто оказываются самыми важными.
Они звучат дежурно, почти бытово и иногда даже немного раздражают. Кажется, что всё это вторично по сравнению с техничкой. Но именно через них интервьюер часто и пытается понять, насколько вы вообще совпадаете с ролью, командой и рабочей реальностью.
И да, никто почти никогда не скажет напрямую: “мы отказали вам из-за того, как вы ответили на вопрос про мотивацию” или “нас смутил ваш ответ про пять лет”.
Вместо этого будет что-то нейтральное. “Нашли более подходящего кандидата”. “Не до конца совпали по профилю”. “Продолжили с другим кандидатом”.
Но очень часто за такими формулировками скрывается одна и та же история: по технике вы были норм, а вот между строк показали, что вы и эта роль, возможно, не очень совместимы.
Поэтому относиться к таким вопросам как к бессмысленному HR-ритуалу — ошибка.
Пока рынок их задаёт, лучше понимать, что именно в них проверяют и почему “безобидный” ответ иногда весит не меньше, чем половина технички.
Когда это понимаешь, собеседования действительно становятся спокойнее. Не потому что появляется универсальный шаблон ответа, а потому что начинаешь видеть логику процесса. А это, как правило, уже сильно снижает количество случайных отказов.
В своем Телеграм-канале я регулярно пишу про рынок IT, тестирование, автоматизацию и карьеру в индустрии.