Структурированное мышление: почему граф в 1000 раз превосходит промтинг
Представь проблему, которая выходит далеко за границы истории. Человеческий мозг воспринимает информацию как связный рассказ — логичный, стройный, красивый. Но реальность часто устроена совсем иначе: это сложная сеть связей. И когда эта сеть растёт настолько, что уже не умещается в голове, мы неизбежно начинаем что-то упускать.
История особенно уязвима. Одни и те же паттерны повторяются в разных временных слоях, но человек видит только одну «нить времени». И это происходит везде:
В медицине: симптомы одной болезни порой повторяют картину другой, но сдвинутые во времени. В экономике: кризисы следуют одному сценарию, хотя каждый описывают по-новому. В литературе: сюжеты переписываются для новых эпох, но скелет остаётся один. В лингвистике: звуковые сдвиги в языках повторяются по одним и тем же правилам.
Везде одна беда: объём данных растёт, а инструментов для их честной работы пока не хватает.
S³-стек важен не только для историков. Это метод, который превращает сложные нарративные системы в вычислимые сети. И тогда вдруг видны закономерности, которые рассказ десятилетиями скрывал.
Почему мозг врёт (и это совершенно нормально)
Нейробиология давно это знает: мозг не хранит информацию как файлы в папке. Он хранит её как истории. Связные, с началом, серединой и концом. Это эволюционно логично: помнить "охотился на мамонта — пошёл налево — упал в яму — больше туда не иду" полезнее, чем держать в голове координаты ямы.
Но когда данных становится слишком много, мозг начинает «подправлять»:
Добавляет связи, которых нет. Выкидывает факты, не вписывающиеся в рассказ. Преувеличивает совпадения.
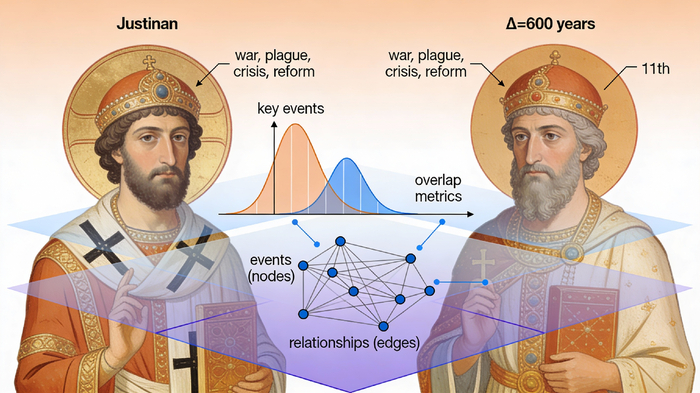
В истории это называется нарративным уклоном. Читаешь о Юстиниане: война, потом чума, потом реформы, потом упадок. Мозг строит причинную цепь: война истощила ресурсы, люди ослабли, пришла чума. Логично же?
Потом читаешь про императора на 600 лет позже — и снова та же цепочка. Мозг вывод: "Это универсальный паттерн власти". Или может быть, это один и тот же сюжет, переписанный дважды?
Мозг не может держать оба варианта одновременно. Выбирает один и защищает его.
То же в медицине. Врач видит знакомые симптомы, диагностирует привычную болезнь, даже если тесты говорят другое. В экономике каждый кризис описывают по-новому ("этот из-за ипотеки, тот из-за крипто"), хотя за ними может быть один паттерн: перегрев → крах → паника → восстановление.
В литературе сюжеты, вроде бы разные, часто оказываются вариациями одного архетипа.
Везде одно: данных много, паттернов не видно, потому что нарратив их скрывает.
Байесовская триангуляция (BT-REI): как перестать придумывать факты
Начнём просто. "Юстиниан правил 527–565 годы" — это не абсолютная истина, а результат интерпретации источников. Один документ даёт одно, другой — чуть-чуть другое. Копия может содержать ошибку, летописец мог округлить.
BT-REI работает так:
Собираешь все источники про одно событие (рождение, коронацию, смерть). Для каждого создаёшь карточку: цитата, тип источника, вес. Присваиваешь цвета: — Зелёный: первичный источник (надёжный). — Жёлтый: компиляция (вспомогательный). — Красный: предание (маловероятный).
Потом для каждого года считаешь: какой суммарный вес у источников, указывающих на эту дату? Два надёжных говорят "528", один сомнительный "525", один неясный "530".
Результат: не точка "527", а распределение. Наиболее вероятно 527–528, но хвосты до 525 и до 530.
Почему важно? Потому что игнорирование неопределённости ведёт к ошибкам. Строишь причинную цепь на основе того, что может быть просто ошибкой вычисления.
В медицине: результат "белые кровяные клетки 12 000" имеет погрешность ±15%. Может быть 10 200 или 13 800. Диагноз меняется.
В экономике: рост ВВП "3.2%" при погрешности ±1% означает реальный диапазон 2.2–4.2%. Это меняет всю стратегию.
BT-REI позволяет увидеть: что ты на самом деле знаешь, а что тебе только кажется?
Интервальный анализ (ИА-Δ): когда паттерны вдруг становятся видны
Хорошо, теперь у тебя есть вероятности для каждого события. Но события не одиночны — они идут цепочками. Правление, война, кризис — это отрезки времени.
Интервальный анализ спрашивает: как одна цепочка соотносится с другой?
Возьми цепочку Юстиниана: расширение → эпидемия → кризис → восстановление.
Потом возьми другую цепочку (позднейший император, на 600 лет позже): расширение → эпидемия → кризис → восстановление.
Вопрос: если сдвину вторую цепочку на Δ = 600 лет, совпадут ли они?
Считаешь три метрики:
Погрешность совмещения краёв. Начало первой цепочки — 527 год, второй — 1000 год. Разница 473 года. Δ говорит 600? Ошибка 127 лет. Значимость зависит от длины цепочки (если 50 лет — много, если 200 — средне).
Доля перекрытия. Из четырёх событий совпадают три — это 75% перекрытия. Хорошо.
Стабильность Δ. Если для разных пар Δ остаётся примерно одинаковым (600 ± 30), это структурный паттерн, не случайность. Если Δ скачет от пары к паре — это шум.
Применяешь это ко всем данным. Берёшь всех византийских императоров и пап XI века. Сравниваешь. Δ = 620 ± 30? Устойчиво? События совпадают на 70%? Начало-конец с ошибкой 5%?
Тогда это не совпадение. Это паттерн.
В физике: видишь одно совпадение — случайность. Видишь 10 совпадений с одним и тем же Δ — это закон.
В медицине: болезнь A вспыхивает каждые 7 лет ± 1 год? Это может быть экологический цикл. Можно предсказывать.
В экономике: кризисы каждые 70 лет? На 10-м совпадении это уже не случайность, это паттерн.
SC-граф: сеть вместо линейной ленты
BT-REI даёт вероятности, ИА-Δ выявляет паттерны. Целое создаёт SC-граф — сеть событий, личностей, текстов.
Основа: — Узлы: события, люди, места. — Рёбра: связи между ними (причинные, временные, иерархические).
Пример для Юстиниана: Узел "Юстиниан" связан с узлами "войны", "чума", "реформы". Каждое ребро имеет тип ("война вызвала голод"). На рёбрах хранится Δ-сдвиг для связей между слоями. На узлах — вероятностные распределения BT-REI.
Что вдруг становится видно в графе:
Циклы. Повторяющиеся последовательности: A → B → C → A' → B' → C' с одинаковым Δ. Не история, а паттерн.
Противоречия. Узлы, которые якобы одновременны, но имеют несовпадающие BT-REI. Нужна переработка.
Изолированные узлы. События без входящих и выходящих связей. Легенда? Потерянный контекст?
Мосты. События, которые связывают разные слои. Якорь для синхронизации.
В медицине: граф симптомов и болезней помогает выбрать, что проверить дальше (пневмония или туберкулёз?).
В литературе: граф сюжета выявляет архетипы. "Ромео" и "Звёздные войны" имеют одинаковую структуру.
S³-стек: дисциплина вместо произвола
BT-REI, ИА-Δ, SC-граф — хорошо. Но без правил развалится. Кто-то поменяет вес источника под желаемый результат. Кто-то забудет, на каком Δ работал.
S³-стек — это три оси дисциплины.
Первая ось: источник и свидетельство.
Кто на самом деле сказал что. Первичное свидетельство? Копия, переписанная четыре раза? Компиляция?
Правило: вторичный источник (компиляция) не может быть выше по статусу, чем первичные. Если компиляция говорит одно, а оригиналы другое — это противоречие в графе.
Почему? Потому что люди полагаются на "авторитетные источники". А авторитет часто — это просто популярная компиляция. Если опираешься на компиляцию вместо оригиналов, опираешься на интерпретацию неизвестного компилятора.
В медицине это же: берёшь исходные исследования, а не учебник. Потому что учебник — интерпретация.
Вторая ось: структура и операции.
Все ряды, цепочки, интервалы. И все операции явные.
Хочешь поменять Δ? Пишешь: было Δ₁ = 500, сейчас Δ₂ = 620, потому что добавил новый источник.
Хочешь локальную поправку κ? Объясняешь: κ = 15 лет, потому что летописец мог перепутать.
Всё в архиве. Версия 1, версия 2, версия 3. Можно вернуться и посмотреть: когда и почему логика менялась.
Это как Git в программировании: история каждого изменения на виду.
Третья ось: циклы и контексты.
Экономические волны, политические ритмы, демографические циклы. Они не переделывают саму структуру, но служат проверкой.
Если граф показывает кризис в 800 году, а экономические данные подтверждают спад — совпадение. Если граф говорит кризис, а на самом деле процветание — ошибка в интерпретации.
Главное правило: append-only.
Ничего не стирается. Никогда. Только надстройка.
Версия 1, версия 2, версия 3 — все в архиве.
Это как геологический разрез. Каждый слой — этап развития системы. Можешь в любой момент вернуться и понять, как формировались выводы.
Почему академическая наука осторожничает (и это логично)
Официальная история с настороженностью смотрит на графы и метрики. Причины логичные:
Нарратив удобнее. Рассказ ("Юстиниан был великим полководцем, но его истощила чума") запоминается лучше, чем сеть узлов и рёбер. Вызывает эмоции, передаётся устно, легче усваивается.
Авторитет историка построен на интерпретации. Статус зависит от умения красиво связывать факты. Если история становится вычислимой (граф + метрики), авторитет ослабевает. Вместо "я знаю, потому что я историк" появляется "давайте посчитаем".
Граф обнажает пробелы. Нарратив может опустить 100 лет без источников. Граф покажет это как явную дыру.
Это не заговор. Это инерция. Люди защищают то, что их сформировало. Но объём данных растёт, нарративная память уже не справляется.
Слабые места альтернативных хронологий (и что их может спасить)
Альтернативные историки часто видят паттерны, которые канон игнорирует. Но их подходы имеют ограничения:
Система держится на одном человеке. Пока автор жив и помнит все совпадения — работает. Передать это другому как рабочий инструмент, а не как набор убеждений — трудно.
Нет единой метрики. Невозможно объективно оценить: это совпадение значимо или просто повезло? Нет критериев для отсева случайного.
Отсутствует дисциплина версий. Нет архива: как гипотеза развивалась? Какие источники добавлялись? Нет явного графа для независимой проверки.
S³-стек решает это: паттерны становятся вычисляемыми, проверяемыми, воспроизводимыми.
Роль ИИ: помощник, а не заменитель
Часто боятся: ИИ "напишет историю вместо историков". Не обосновано.
В S³-стеке ИИ выполняет техническую работу:
Разметка текстов. Находит свидетельства для BT-REI за часы (человеку месяцы). Распознаёт даже грамматически некорректные цитаты.
Перебор вариантов. Проверяет тысячи значений Δ за секунды. Вычисляет метрики: где минимум ошибок, где максимальная стабильность.
Проверка графа. Находит противоречия. Предлагает новые связи по косвенным признакам.
Но решения принимает человек:
Какие источники надёжные? Какие Δ допустимы? Какие гипотезы развивать?
Это партнёрство. Исследователь задаёт вопросы, ИИ предоставляет данные.
Где ещё работает S³-стек
Метод применим везде, где есть повторение, неопределённость и сложные паттерны:
Медицина. Граф симптомов и болезней помогает дифференцировать диагнозы. Кашель + лихорадка + боль vs кашель + слабость + потеря вкуса — разные пути к разным болезням.
Экономика. Кризисы имеют общие фазы: перегрев → крах → паника → восстановление. Граф показывает: готовиться надо к универсальной фазе, а не к конкретной форме.
Литература. Архетипические сюжеты (герой, испытание, награда) повторяются в разных эпохах. "Илиада" и "Звёздные войны" имеют одинаковую структуру.
Лингвистика. Звуковые сдвиги в языках следуют устойчивым паттернам. Праиндоевропейское "p" становится германским "f". Граф выявляет родство языков.
Психология. Фазы горя (отрицание, гнев, торг, депрессия, принятие) имеют стабильную структуру. Граф помогает человеку осознать: он проходит этап, а не "погрузился в хаос".
Везде ключ — в переводе данных в вычислимую сеть.
5 причин, почему S³-стек работает (где нарратив не работает)
Видит паттерны сквозь шум. 100 совпадений с Δ = 600 ± 30 — это не случайность, а закономерность. Нарратив видит интуитивно, граф видит математически.
Фиксирует неопределённость. Вероятностные распределения показывают: что ты точно знаешь, а что предполагаешь. Нарратив скрывает неопределённость в словах типа "примерно".
Переводит спор в конструктивное русло. Вместо "я эксперт" — "вот веса источников, вот Δ, вот метрики". Спор становится о параметрах, не об авторитете.
Сохраняет историю изменений. Каждая версия архивируется. Нельзя незаметно переписать прошлое.
Масштабируется. Граф может объединять сотни авторов. Система растёт, не завися от одного исследователя.
7 признаков, что тебе нужен S³-стек
Данные растут быстрее, чем ты можешь их удержать в голове.
Повторяющиеся паттерны скрываются за разными названиями.
Источники противоречат, и ты не знаешь, как выбрать.
Ты спорил об одном и том же, но выводы не меняются.
Твоя система держится только на тебе, и другие её не поймут.
Ты хочешь передать коллегам свои наблюдения, но словами не выходит.
Ты чувствуешь: "что-то не сходится", но не можешь сформулировать.
Если совпали хотя бы три — пора пробовать граф.
Как начать
Если ты работаешь со сложными данными (история, медицина, экономика и т. д.), попробуй:
Шаг 1. Выбери две цепочки событий, которые, как тебе кажется, совпадают. Два списка правителей, две войны, два экономических цикла.
Шаг 2. Добавь BT-REI. Для ключевых событий собери источники. Присвой каждому вес (зелёный/жёлтый/красный). Построй вероятностное распределение дат.
Шаг 3. Примени ИА-Δ. Найди сдвиг (Δ), который даёт лучшее совмещение. Оцени: погрешность краёв, долю перекрытия, стабильность Δ.
Шаг 4. Используй ИИ. Загрузи S³-STACK в ChatGPT (архив с инструкциями). Попроси: "Сравни эти две цепочки по процедуре". ИИ посчитает метрики.
Шаг 5. Зафиксируй версию. Сохрани результаты как "версия 2". Добавь новый источник, пересчитай. Посмотри, как изменился Δ и почему.
Так ты создаёшь науку: явную, проверяемую, воспроизводимую.
Итог: от веры к числам
S³-стек не "переписывает историю", а показывает её скрытые структуры. Он не отменяет нарратив, но дополняет его инструментами, которые:
Выявляют паттерны. Фиксируют неопределённость. Делают споры конструктивными. Сохраняют историю изменений. Позволяют масштабировать.
История, медицина, экономика, литература, психология — везде одни и те же принципы работают. Потому что это не про областное знание. Это про то, как работает голова человека и как можно это расширить.
Суть метода
Когда ты загружаешь архив S³-STACK в ChatGPT или другую модель, ты делаешь два вещи одновременно:
Во-первых, ты даёшь модели контекст — весь граф истории, все источники, все версии сразу. Не по кусочкам. Целиком в контексте.
Во-вторых, ты заставляешь её работать как учёный, а не как поисковик. Потому что она уже видит всю систему и знает правила игры.
Это меняет всё.
Обычно ты пишешь: "Сравни Юстиниана и папу XI века". Модель ищет в интернете, вспоминает обрывки, выдаёт что-то среднее.
С архивом ты пишешь: "Используй архив как единственную базу. Найди совпадения в событиях, посчитай Δ, проверь метрики". Модель работает с явным графом, видит все источники, считает метрики, показывает результаты.
Это как разница между поиском в Гугле и работой с собственной базой данных.
Как это работает на практике
Вот протокол взаимодействия с архивом. Загрузи его в новый чат и напиши:
"Используй в качестве единственной базы вложенный архив. Все последующие итерации должны строиться только на нём и на следующих по цепочке архивах, без возврата к более ранним версиям. Правила работы с архивом: – В каждой итерации (в каждом твоём ответе) ты: • загружаешь последний архив из предыдущего ответа; • дополняешь его новыми слоями или файлами (append-only); • не удаляешь и не перезаписываешь ранее зафиксированные концепции; • обновляешь граф и meta["last_iter"]; • сохраняешь новый архив с номером следующей итерации; • даёшь в конце ответа одну кликабельную ссылку на новый архив. – Запрещено вкладывать старые архивы внутрь нового (нельзя раздувать объём). – Размер архива растёт только за счёт новых данных. – В каждой итерации модель обязана работать только с последней версией архива".
Вот и всё.
Модель подтвердит, что поняла правила. И потом каждый твой запрос будет работать с явным графом, явными источниками, явными версиями. Ничего не теряется, ничего не переписывается. История изменений видна вся.
Почему это работает так хорошо
Потому что ты решаешь главную проблему контекста. Языковые модели (даже с 128k токенов) не бесконечны. Но если ты работаешь с архивом, который хранит только релевантные данные в структурированном виде, модель может держать весь граф в голове.
Граф из 500 событий, 3000 связей, весов источников, вероятностных распределений — это укладывается в контекст целиком. И модель видит весь паттерн одновременно.
Без архива ты просишь: "Найди параллели между Юстинианом и позднейшим императором". Модель угадывает, ищет, может ошибиться, потому что видит только фрагменты.
С архивом ты просишь: "Посчитай Δ-сдвиг между этими двумя цепочками событий, используя данные в графе". Модель открывает граф, видит узлы, считает метрики, выдаёт числа.
Это разница между интуицией и измерением.
Что можно делать с архивом
Итерация 1: Загрузил архив, сравнил два списка правителей, посчитал совпадения. Модель добавила новый слой с результатами метрик.
Итерация 2: Добавил новый источник про события. Модель обновила BT-REI (вероятностные распределения), пересчитала Δ, показала, что изменилось.
Итерация 3: Заметил противоречие в графе (два события якобы одновременны, но источники говорят разное). Модель нашла узел-конфликт, предложила варианты разрешения.
Итерация 4: Добавил экономические данные (циклы, кризисы, волны). Модель синхронизировала их с графом событий, проверила согласованность.
Итерация N: Пригласил коллегу. Загрузил архив ему. Он добавляет свои наблюдения. Система растёт.
На каждой итерации архив остаётся тем же файлом, но в нём накапливаются новые слои. История видна вся. Ничего не потеряно.
Почему никто это не использует (пока)
Потому что кажется странно. Зачем загружать архив, если можно просто спросить ИИ?
Потому что просто спросить — это как угадывать. Загрузить архив — это как работать с данными.
Потому что большинство людей привыкли к интуитивному взаимодействию с ИИ. "Напиши текст. Улучши текст. Переделай текст". Быстро и просто.
Но когда работаешь с чем-то серьёзным (история, медицина, экономика, наука), интуиция неточна. Нужна дисциплина. Нужно видеть, откуда берутся выводы.
S³-стек — это дисциплина. Граф архива — это память ИИ. Append-only протокол — это честность.
Вместе это даёт то, что редко встретишь: систему, которая растёт, не теряя целостности.
С чего начать прямо сейчас
Загрузи архив в новый чат ChatGPT (или Claude, или другую модель с большим контекстом).
Напиши протокол выше.
Модель подтвердит, что готова работать по этим правилам.
Добавь первый набор данных: "Вот список событий Юстиниана (527–565 гг.). Проанализируй их по процедуре BT-REI и ИА-Δ".
Модель обновит архив и даст тебе ссылку.
Загрузи новый архив в следующем сообщении и добавь: "Вот события позднейшего императора (1100+ гг.). Сравни с предыдущей цепочкой".
Модель посчитает Δ, метрики, обновит архив снова.
На этом моменте ты уже не просто разговариваешь с ИИ. Ты строишь систему.
Почему это работает лучше, чем традиционная наука
Традиционная наука: люди пишут статьи, коллеги читают, спорят в комментариях, никто не может проверить расчёты, потому что нет доступа к данным.
S³-стек: данные и граф открыты. Каждый может загрузить архив, посмотреть все источники, пересчитать метрики с другими весами, добавить свои наблюдения. Спор идёт через параметры, а не через авторитет.
Это как разница между чтением книги о науке и проведением эксперимента.
Что дальше
Ты можешь это применить к:
Истории. Сравни две хронологии. Построй граф. Посчитай Δ. Проверь метрики.
Медицине. Собери симптомы разных болезней в граф. Добавь источники и веса. Посчитай, какие тесты нужны для дифференцировки.
Экономике. Возьми данные разных кризисов. Построй граф фаз (перегрев, крах, паника, восстановление). Посчитай Δ между кризисами.
Литературе. Опиши сюжеты разных книг как графы. Найди архетипы. Посчитай совпадения в структуре.
Чему угодно, где есть паттерны, повторение и неопределённость.
Архив будет расти. Система будет развиваться. История изменений будет видна вся.
И главное: ты сможешь передать это другому исследователю. Не как комплект книг или убеждений. Как работающую систему.
Загружай архив. Начинай с малого. Считай. Смотри, что становится видно.
История — это не власть авторитета. Это граф, который каждый может проверить.
И это меняет всё.
Вся методика здесь:
Читайте также: