PG_EXPECTO : Использование нейросети для анализа результатов нагрузочного тестирования СУБД PostgreSQL
Взято с основного технического канала Postgres DBA (возможны правки в исходной статье).

PG_EXPECTO: Когда нейросеть видит то, что скрыто в данных.
Нагрузочное тестирование — это не просто сбор метрик, а сложный процесс их интерпретации. Традиционный анализ требует значительного времени и опыта. Проект PG_EXPECTO демонстрирует, как современные нейросети могут стать мощным соавтором инженера, мгновенно выявляя узкие места, коррелируя данные из разных источников (СУБД, ОС, диски) и формулируя конкретные рекомендации. Эта статья — практический пример превращения сырых данных нагрузочного теста в готовый план действий с помощью искусственного интеллекта.
Задача
Протестировать результаты использования нейросети для анализа результирующих данных по производительности СУБД и инфраструктуры в ходе нагрузочного тестирования.
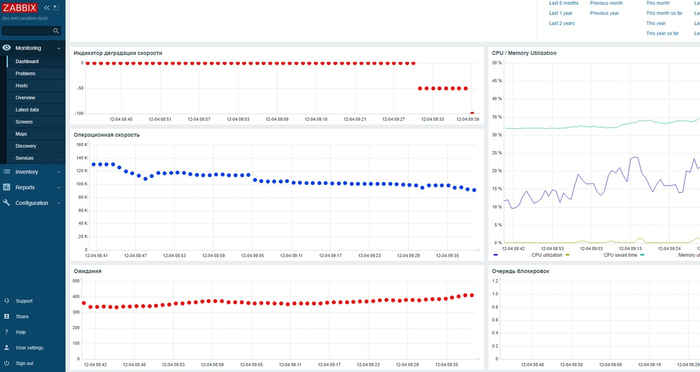
Шаг-1: Формирование файлов статистических данных и промптов для нейросети по окончании нагрузочного тестирования
cd /postgres/pg_expecto/sh/performance_reports
TIMESTAMP : 03-01-2026 15:10:17 : OK : ОТЧЕТ ПО НАГРУЗОЧНОМУ ТЕСТИРОВАНИЮ - НАЧАТ
…
TIMESTAMP : 03-01-2026 15:10:22 : OK : 1.ВХОДНЫЕ ДАННЫЕ ДЛЯ НЕЙРОСЕТИ - СУБД И VMSTAT/IOSTAT
TIMESTAMP : 03-01-2026 15:10:22 : OK : 2.ВХОДНЫЕ ДАННЫЕ ДЛЯ НЕЙРОСЕТИ - IO PERFORMANCE
TIMESTAMP : 03-01-2026 15:10:22 : OK : DEVICE = vdd
TIMESTAMP : 03-01-2026 15:10:22 : OK : DEVICE = vdc
TIMESTAMP : 03-01-2026 15:10:22 : OK : ОТЧЕТ ПО НАГРУЗОЧНОМУ ТЕСТИРОВАНИЮ - ВЫПОЛНЕН
Результирующие файлы:
Статистические данные по производительности СУБД и инфраструктуры : 1.summary.txt
Промпт для нейросети для формирования отчета по производительности СУБД и инфраструктуры : _1.prompt.txt
Статистические данные по производительности подсистемы IO: _2.io_performance.txt
Промпт для нейросети для формирования отчета по производительности подсистемы IO: _2.io_performance_prompt.txt
Шаг-2: Формирование итогового отчета по производительности СУБД и инфраструктуры
Промпт
Проанализируй данные по метрикам производительности и ожиданий СУБД , метрикам инфраструктуры vmstat/iostat. Подготовь итоговый отчет по результатам анализа.
1. Общая характеристика системы
PostgreSQL версия: конфигурация из postgresql.auto.conf
Аппаратные ресурсы:
CPU: 8 ядер (Intel Xeon)
RAM: 7.5 GB
Диски: отдельные разделы для данных (100GB), WAL (50GB), логов (30GB)Нагрузка: тестирование проводилось с 12:59 до 14:48, нагрузка возрастала с 5 до 22 единиц
2. Ключевые проблемы производительности
2.1. Дисковый ввод-вывод (I/O) — критическая проблема
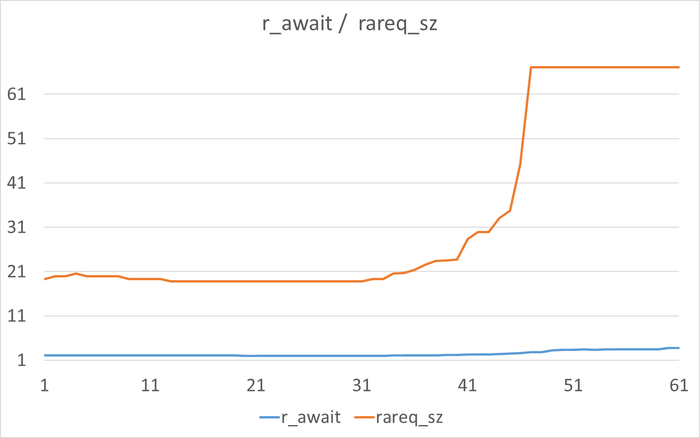
Ожидания IO составляют 99.93% от всех ожиданий СУБД
Основное событие ожидания: DataFileRead (чтение данных с диска)
В системных метриках (vmstat):
wa (ожидание I/O) постоянно превышает 44-50%
100% наблюдений имеют wa > 10% (крайне тревожный показатель)
Высокая корреляция (0.9755) между ожиданиями IO и процессами в состоянии непрерываемого сна (b)
Количество процессов в состоянии b возрастает с 5 до 14
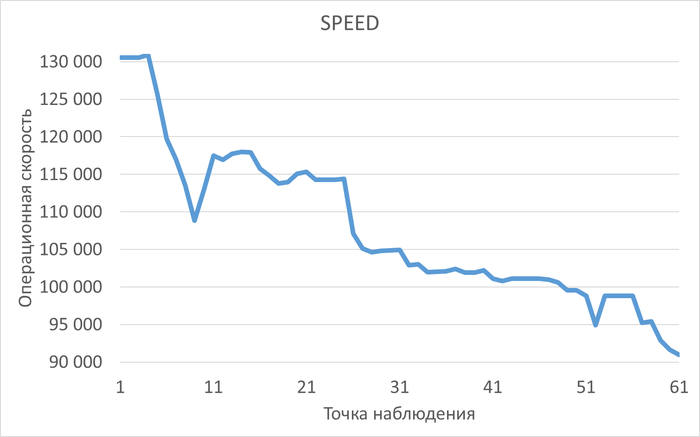
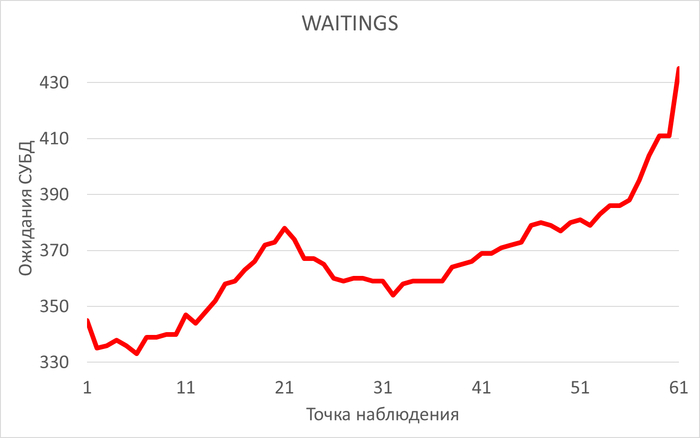
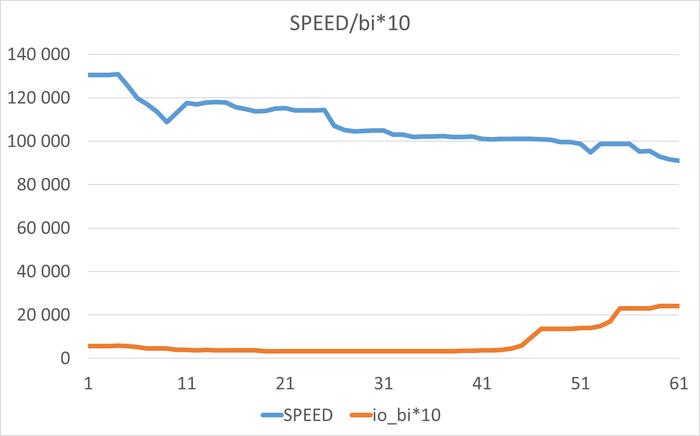
2.2. Падение производительности под нагрузкой
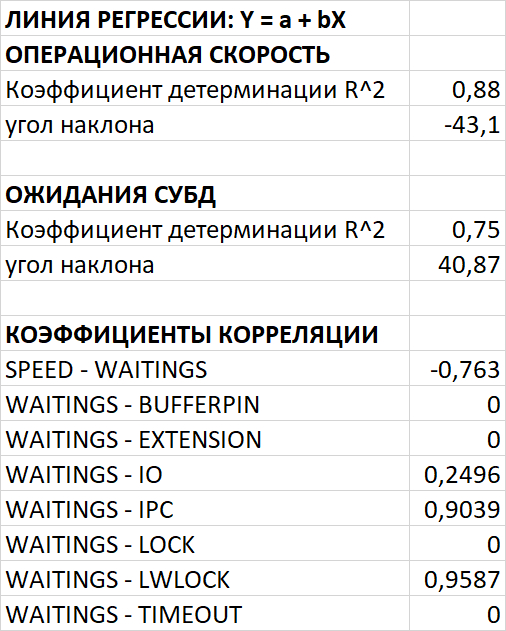
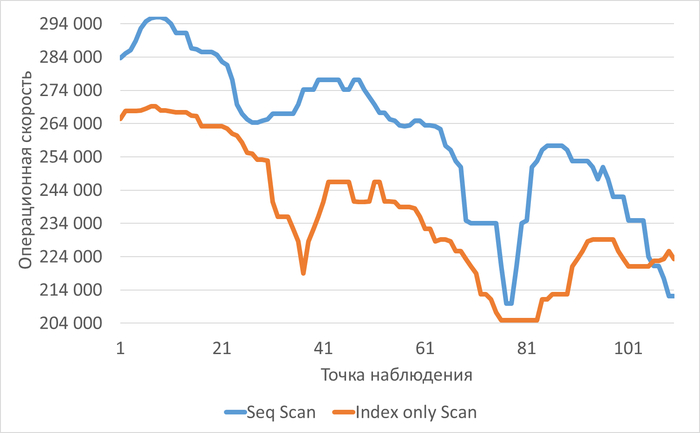
Производительность (SPEED) снизилась на ~5% (с 284,895 до 265,388)
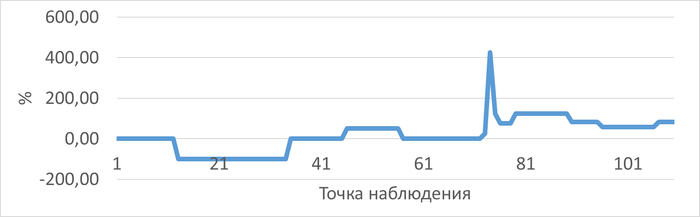
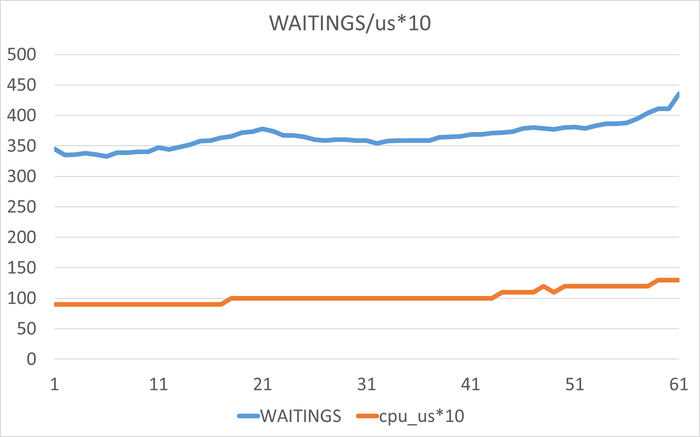
Ожидания (WAITINGS) выросли в 2.7 раза (с 27,055 до 72,905)
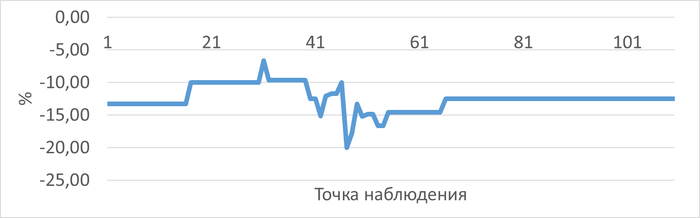
Сильная отрицательная корреляция (-0.71) между SPEED и WAITINGS
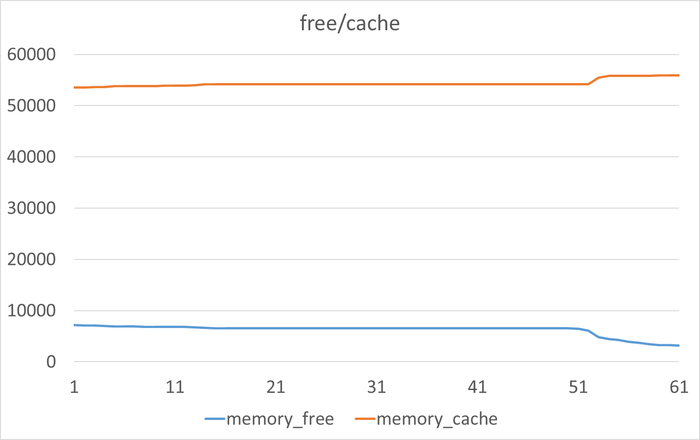
2.3. Проблемы с памятью
Свободной оперативной памяти менее 5% в 100% наблюдений
При этом свопинг не используется — вся память активно задействована
2.4. Конкуренция за ресурсы
Заметные ожидания по блокировкам:
Lock: extend (67.61%), transactionid (23.17%)
LWLock: ProcArray (51.61%), BufferContent (31.85%)Высокая корреляция (0.91) между LWLock и user time CPU
3. Анализ запросов
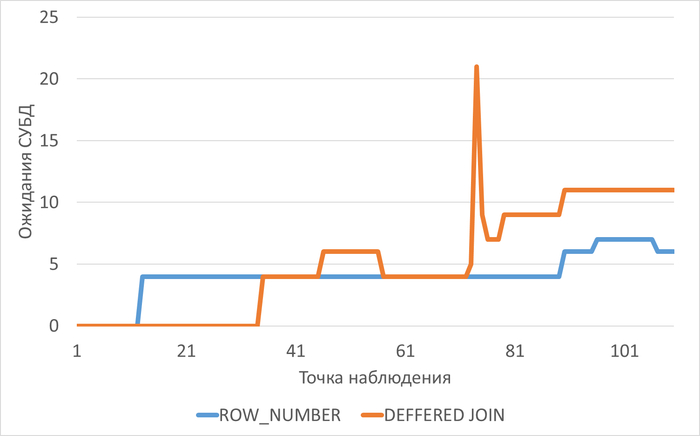
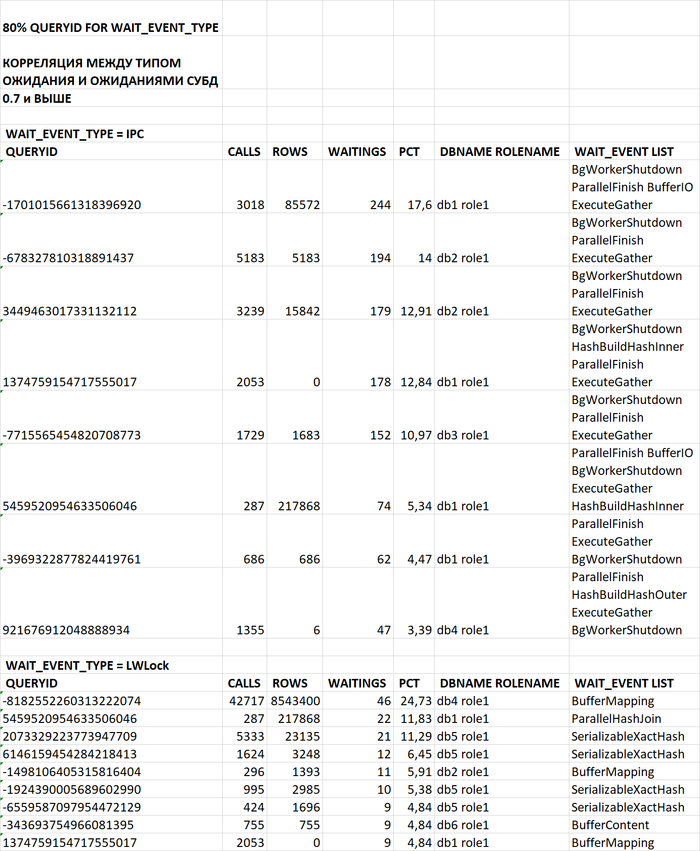
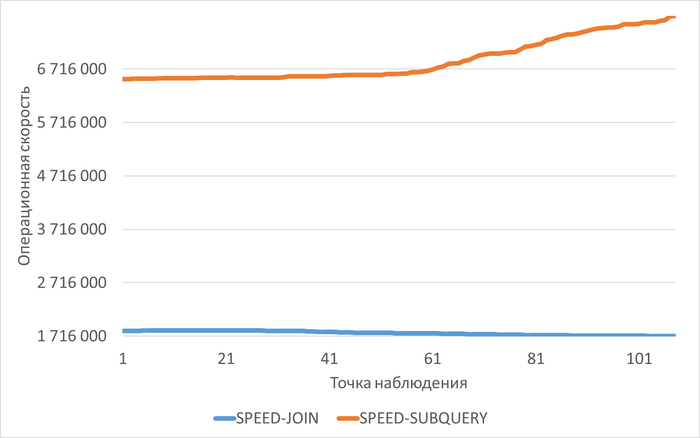
Три основных запроса вызывают 80% проблем:
scenario1 (queryid: 65003243407475111) — 80.18% ожиданий IO
scenario3 (queryid: 2179758041927844257) — проблемы с блокировками
scenario2 (queryid: -1379548677898522698) — также вносит вклад в ожидания
4. Конфигурационные проблемы PostgreSQL
4.1. Агрессивные настройки autovacuum
autovacuum_naptime = '1s' # Слишком часто
autovacuum_vacuum_cost_delay = '2ms' # Слишком мало
autovacuum_work_mem = '256MB' # Много для каждого воркера
Может создавать избыточную фоновую нагрузку на I/O.
4.2. Параметры памяти
work_mem = '32MB' — может быть недостаточно для сложных операций
shared_buffers = '2GB' — разумно, но стоит мониторить эффективность
5. Рекомендации
5.1. Оптимизация запросов (высший приоритет)
Сфокусироваться на оптимизации scenario1 (80% проблем с I/O)
Рассмотреть:
Добавление индексов для уменьшения полных сканирований таблиц
Оптимизацию JOIN-операций
Кэширование часто запрашиваемых данных
5.2. Настройка PostgreSQL
Увеличить work_mem до 64-128MB для уменьшения дисковых операций
Настроить autovacuum менее агрессивно:
Увеличить autovacuum_vacuum_cost_delay до 10-20ms
Увеличить autovacuum_naptime до 30s-1minПроверить эффективность shared_buffers и effective_cache_size
5.3. Инфраструктурные улучшения
Рассмотреть переход на более быстрые диски (SSD/NVMe)
Настроить параметры виртуальной памяти ОС (как указано в отчете):
Проверить и оптимизировать vm.dirty_background_bytes, vm.dirty_bytesРассмотреть увеличение оперативной памяти
5.4. Мониторинг и дальнейший анализ
Установить мониторинг дисковых задержек (latency)
Анализировать план выполнения проблемных запросов
Рассмотреть разделение нагрузки на несколько дисковых массивов
6. Заключение
Система упирается в производительность дискового ввода-вывода. При росте нагрузки диски не справляются с объемом операций чтения, что приводит к резкому росту ожиданий и падению производительности. Критически важна оптимизация запросов (особенно scenario1) и улучшение дискового подсистемы. Без этих мер дальнейшее увеличение нагрузки приведет к еще более серьезным проблемам с производительностью.
Шаг-3: Формирование итогового отчета по производительности подсистемы IO
Промпт
Подготовь итоговый отчёт по результатам анализа производительности подсистемы IO
1. Общая информация
Период анализа: 2026-01-03 12:59 - 2026-01-03 14:48 (109 минут)
Анализируемые устройства: vdd и vdc
CPU: 8 ядер, Intel Xeon Processor (Skylake)
2. Ключевые выводы по устройству vdd (/data)
Критические проблемы:
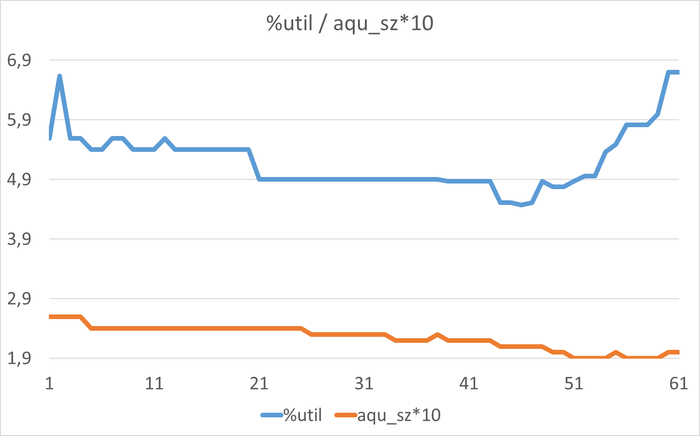
Постоянная 100% загрузка устройства - во всех 110 замерах %util = 100%
Высокая глубина очереди - 100% наблюдений с aqu_sz > 1 (до 18)
Неэффективное использование памяти:
Высокая корреляция (buff - wMB/s): 0.6776
Высокая корреляция (cache - r/s): 0.5023
Высокая корреляция (cache - w/s): 0.5183
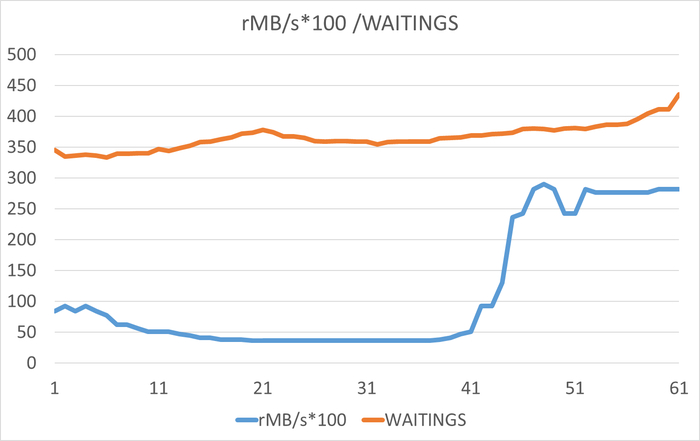
Производительность:
IOPS: 3949-4052 операций/сек
Пропускная способность: 36-40 МБ/сек
Latency чтения: 2-5 мс (в пределах нормы)
Latency записи: 2-5 мс (в пределах нормы)
Нагрузка на CPU (wa): 44-50% (высокая)
3. Ключевые выводы по устройству vdc (/wal)
Статус: Удовлетворительно
Умеренная загрузка: 42-53% utilization
Низкая глубина очереди: менее 25% наблюдений > 1
Latency в норме: w_await ≈ 1 мс
Корреляции в основном в норме
Производительность:
IOPS записи: 758-971 операций/сек
Пропускная способность: 6-8 МБ/сек
Нагрузка на CPU (wa): 44-50%
4. Рекомендации
Срочные меры для vdd:
Рассмотреть апгрейд диска - текущий диск работает на пределе
Оптимизировать использование кэша - выявлена неэффективность
Балансировка нагрузки - возможно перенести часть операций на другие диски
Увеличить память для улучшения кэширования
Оптимизационные меры:
Мониторинг - установить постоянный мониторинг загрузки vdd
Анализ паттернов доступа - понять причину высокой нагрузки
Настройка параметров IO - оптимизировать размеры блоков и очереди
5. Общий вердикт
Устройство vdd требует немедленного внимания - работает в режиме saturation
Устройство vdc функционирует в нормальном режиме
Система в целом имеет резерв по CPU (wa < 50%), но дисковый IO является узким местом
Приоритет: Высокий (необходимы срочные меры по оптимизации vdd)