Я купил игровую консоль и написал для неё BIOS2

Осторожно: Статья написана максимально простым языком. Так что если вы гик, но не умеете программировать - вам всё равно будет интересно!
Недавно я наткнулся на DIY-игровую консоль за 1.500 рублей - Waveshare GamePi13. Когда гаджет приехал ко мне, я запустил примеры игр от производителя... и оторопел от 5 FPS в Pong - это ж как плохо нужно код писать!
Не желая мириться с этим, я открыл схему устройства, даташит на RP2040 и принялся писать свой собственный BIOS. Если вам интересно узнать, как работают DIY-консоли «изнутри», можно ли запускать внешние программы на микроконтроллерах из RAM, как реализованы различные подсистемы BIOS, а в конце даже написать «Змейку» - добро пожаловать под кат!
❯ Предисловие
Иногда китайские производители выпускают на рынок дешевые гаджеты с ориентиром исключительно на гиков. Чего-уж говорить, с какой-нибудь R36s чего только не сделали: и кастомные прошивки, и порты игр с ПК, и даже достаточно сложные аппаратные модификации. Однако в тусовке DIY'щиков обычно всё куда хардкорнее...

«Андерграундные» консоли выходят чуть ли не каждый день, но лишь единицы из них становятся хоть сколь либо популярными и попадают на массовый конвейер. От «больших» консолей их отличает простая схемотехника, использование распространенных и дешевых микроконтроллеров общего назначения и полная свобода творчества — что хочешь, то и твори! По характеристикам они чаще всего близки к оригинальному GameBoy или GameBoy Advance, а покупают их инженеры, демосценеры и ретро-энтузиасты, которые не только играют во что-то готовое, но и пишут небольшие игрушки сами!

Самые известные консоли такого формата — это нашумевший Playdate и чуть менее известный Arduboy. Обе консоли сильно ограничены в характеристиках и это подстегивает интерес гиков к постоянной оптимизации кода и попыткам впихнуть «невпихуемое». Выделился даже российский «Микрон», представив свою DIY-консоль «для хардкорных ардуинщиков» — некий MikBoy на базе своего же МИК32 «Амур»!

Я уверен что Микроновцы будут читать эту статью... Если вдруг всё получится и MikBoy пойдёт в серию — то напишите мне пожалуйста сообщение :)
Подобным «ардуинщиком» являюсь и я. Ещё со школьных лет меня нереально тянет к микроконтроллерам и Embedded-электронике в целом. О консоли собственной разработки я мечтаю с 14 лет, при этом мне не просто хочется собрать прототип и «забить», но и запустить мелкосерийное ручное производство и продавать устройства подписчикам! К своим 24-годам я сделал два прототипа и развел три платы, но все эти проекты так или иначе откладывались в долгий ящик...

Один из ранних-ранних прототипов, предназначенный для обкатки драйвера дисплея.
И вот, 25 сентября мне стукнуло 24 годика. Уже взрослый мальчик получил в качестве подарка донат от постоянного читателя и пошёл изучать маркетплейсы в поисках интересного железа. По ключевым словам «tft lcd diy» был найден «ESP32 Bitcoin Miner V2» (выгодный девкит с 2.8" и ESP32-S2), девкит ESP32 с 4.3" дисплеем и емкостным тачскрином, а также некий Waveshare GamePi13, о котором мы сегодня с вами и поговорим!
Отдельное спасибо хотелось бы сказать тем самым подписчикам. Без вашей поддержки этой статьи бы не было!
Waveshare — знаменитый в кругах энтузиастов SBC производитель. В основном компания занимается дисплеями, модулями расширения и одноплатными компьютерами.
В тот же день я заказал устройство, и уже через 3 недели трепетного ожидания, GamePi13 оказался у меня на столе. На первый взгляд консоль показалась очень маленькой: её 1.3" дисплей был даже меньше, чем у Nokia 6230i, а кнопки оказались расположены непривычно близко друг к другу. Ко всему прочему, у консоли не было предусмотрено вообще никакого корпуса: ни «болванки» от производителя, ни STL-файлов для печати. Что-ж, это только придаёт брутальности нашему устройству!

Оба устройства помещаются в одну ладошку... А ведь когда-то 6230i казался реально большим!
Как вы уже могли заметить, консоль состоит из двух независимых модулей: платы разработки Waveshare RP2040-PiZero и «бутербродного» геймпада с дисплеем, который подключается к гребёнке основной платы. В этом и кроется главный секрет устройства: геймпад изначально рассчитан именно для «одноплатников» Raspberry Pi, но поскольку Waveshare также выпускает плату RP2040 с Pi-совместимой гребёнкой, они решили заодно адаптировать его и для PiZero.

❯ Что внутри?
Хоть PiZero и похожа на референсную плату в лице Raspberry Pi Pico, у неё есть несколько серьёзных отличий:
Во первых, на плате установлена SPI-флэшка объёмом аж в 16МБ. Это максимальный объём, который поддерживает XIP-контроллер в RP2040. В RPi Pico же используется флэш-память объёмом всего в 2МБ.
Далее внимание привлекает использование менее эффективного ULDO RT9193 вместо полноценного DC-DC преобразователя в оригинальном Pico. Сам микроконтроллер сможет работать при разрядке аккумулятора ниже 3.6В, а вот периферия — под вопросом. Иными словами, мы не сможем использовать «все соки» из аккумулятора и нам придётся реализовывать отсечку по напряжению.
На плате распаяна микросхема-чарджер литий-ионных аккумуляторов ETA6096 с током зарядки аж в 1А. Если захотите использовать аккумулятор меньшей емкости — стоит подобрать резистор ISET большего номинала, иначе есть риск перегрева.
Из разъёмов распаян HDMI (да, я тоже в шоке), слот для MicroSD (под него отдали весь SPI0) и два Type-C: один для аппаратного USB-контроллера в RP2040, второй для USB через PIO. В общем, пытались угодить всем.
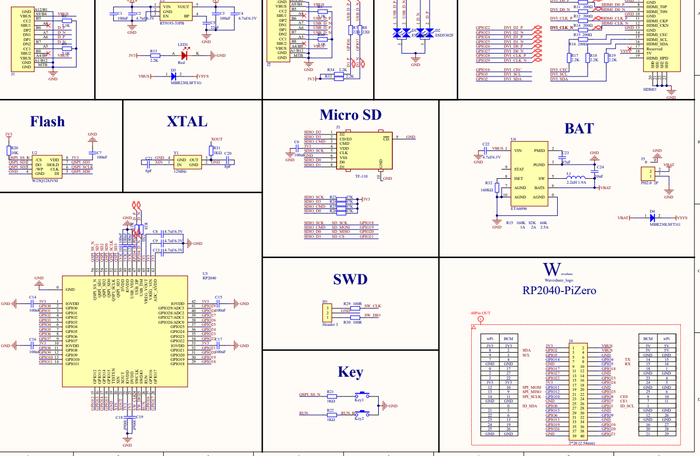
Плата с геймпадом не менее интересная. С фронтальной стороны у нас расположилось 10 кнопок и 1.3" IPS-дисплей с разрешением 240x240, использующий контроллер ST7789. Вообще, для такой диагонали разрешение дисплея крайне избыточно: оно не только съедает драгоценные килобайты оперативной памяти для фреймбуфера, но и значительно грузит DMA-контроллер и всю шину SPI. Я бы на месте инженеров установил бы сюда «золотой стандарт» — недорогой 1.8" 128x160. Все кнопки подключены к отдельным пинам без сдвигового регистра и занимают значительную часть доступных GPIO.

Я бы сделал лучше!
С обратной стороны расположился небольшой динамик, усилитель, построенный на базе NS8002, 3.5мм джек для подключения наушников, а также токоограничивающий резистор подсветки и обвязка для дисплея. Подсветка подключена напрямую к VSYS и рассчитана на питание от 3.3В, так что никакой регулировки яркости и продвинутых режимов сна!

Производитель платы — компания SpotPear.
Ну что-ж, собираем наш бутерброд обратно, подключаем Type-C и смотрим на одну из представленных демо-игр — Тетрис!
Нет, это не пережатая гифка, игра действительно идёт буквально в 1 FPS и с мерцанием — и это на микроконтроллере с ядром Cortex-M0+ на частоте аж в 150МГц! Я напомню, что N-Gage с процессором TI OMAP на более старом ядре ARM926EJ-S с частотой 104МГц умудрялся тянуть первый Tomb Raider с полностью программным рендерингом в 25 FPS!!!

Далее я решил открыть официальный вики Waveshare и изучить информацию о консоли, где нашел несколько примеров игр для неё, одной из которых был Pong. Какое же было моё разочарование, когда я узнал, что обе игры написаны полностью на Python: игровая логика, маршалинг данных, работа с «железом» — всё это было на интерпретируемом языке и более того, написано плохо и крайне неэффективно!
class hardware():
def init():
spi0=SPI(1,baudrate=900000000, phase=0, polarity=0,
sck=Pin(game_kit.lcd_sck, Pin.OUT),
mosi=Pin(game_kit.lcd_sda, Pin.OUT))
display = st7789.ST7789(spi0, 240, 240,
reset=Pin(game_kit.lcd_rst, Pin.OUT),
dc=Pin(game_kit.lcd_dc, Pin.OUT),cs=Pin(game_kit.lcd_cs, Pin.OUT),
xstart=0, ystart=0, rotation=0)
# 初始界面,提示游戏开始
display.fill(st7789.BLACK)
display.text(font2, "Pong!", 90, 90)
display.text(font2, "Let's go!", 60, 140)
time.sleep(1)
hardware.display = display
class pong():
def __init__(self):
# bgm
self.bgm = p_music(p_music.song2, tempo=1, duty=500, pins=[
Pin(game_kit.buzzer, Pin.OUT)])
# 控制音乐暂停和播放的键start
self.key_start = button(game_kit.key_start, self.key_start_callback)
# led
self.led = Pin(game_kit.led_sta, Pin.OUT)
Ни о каком подобии SDK или библиотеки для абстрагирования работы с железом даже речи не шло, практически всё, кроме номеров пинов, было захардкожено прямо в коде игры. О хорошей архитектуре тоже речи не идёт: один класс на всю логику с глобальными переменными... В общем, сэмплы писал либо новичок, либо прожженный эмбеддер :)
Драйвер дисплея даже не пытается использовать DMA, из-за чего даже Понг, состоящий из трёх прямоугольников умудряется тормозить.
def blit_buffer(self, buffer, x, y, width, height):
"""
Copy buffer to display at the given location.
Args:
buffer (bytes): Data to copy to display
x (int): Top left corner x coordinate
Y (int): Top left corner y coordinate
width (int): Width
height (int): Height
"""
self.set_window(x, y, x + width - 1, y + height - 1)
self.write(None, buffer)
Звуковая подсистема, состоящая из одноканальной тональной пищалки на аппаратном ШИМ-контроллере, тоже была со своими «приколами». Например «тишина» — это 0, то есть магнит всегда прижат к нижней части, хотя должно быть PWM_MAX / 2.
Под впечатлением от такого кода, я решил попробовать написать SDK для этой консоли сам. Однако моё видение идеальной DIY-консоли сильно отличалось от того-же Arduboy или Playdate!
❯ Архитектура
При проработке архитектуры будущего «BIOS», я сразу же поставил для себя несколько чётких задач:
Во первых, BIOS должен быть достаточно абстрактным для того, чтобы скрывать от игры детали реализации конкретного «железа». Иными словами, игра оперирует не DMA-контроллерами, FPU-сопроцессором и SPI, а набором простых и понятных подсистем: графика, ввод, звук, хранилище. Кроме того, это позволяет легко портировать игры для такого BIOS'а на другие платформы: можно без проблем реализовать симулятор (не эмулятор!) консоли на ПК или портировать её на ESP32 с минимальными изменениями.
Во вторых, мы ставим производительность в основной приоритет при разработке устройства. В конце-концов это же позорище, что простейшая игра тормозит и мерцает на мощном микроконтроллере, но при этом тетрисы с трёхмерной графикой вполне шустро работали на телефонах Sony Ericsson 2005 года. Именно поэтому для написания игр используются не скриптовые языки по типу Lua или JS, а самый обычный «C с классами».
В третьих, сам BIOS должен быть легко портируем между разными платами (у SpotPear есть вторая похожая плата — уже с 1.5" и стиком) и даже аппаратными платформами. Этот проект может стать основной прошивкой для консоли уже моей разработки и иметь вот такую «кроссплатформу» было бы отнюдь не лишним!
Руководствуясь критериями выше, я решил писать BIOS на C++ (на деле C с классами) с активным использованием интерфейсов и VMT. Это позволяет не только удобно структурировать модули и повышает читаемость кода игры, но и избавляет от необходимости вручную составлять таблицу системных вызовов к API. Тем не менее, в таком подходе есть один серьёзный нюанс: когда у подсистем появляются новые методы или добавляются перегрузки к прошлым, их необходимо по порядку добавлять в конец интерфейса, иначе VMT ломается.
vtable for CTest:
.word 0
.word typeinfo for CTest
.word CTest::Test()
.word CTest::Abc()
vtable for ITest:
.word 0
.word typeinfo for ITest
.word __cxa_pure_virtual
.word __cxa_pure_virtual
В своё время Microsoft решила эту проблему в COM с помощью QueryInterface и миллиона вариаций этих самых интерфейсов: IDirectSound8, IDirectDraw7 и т.д, но мы можем не изобретать велосипед, а просто предоставлять «старым» играм такие же «старые» версии VMT.
Основным объектом в BIOS'е является CSystem, который содержит в себе ссылки на другие подсистемы консоли, а также на информацию о текущей аппаратной платформе:
/// @brief Primary system service, supplied to both games and system modules.
class ISystem
{
public:
virtual CSystemInfo* GetSystemInfo() = 0;
virtual void* Alloc(uint32_t size) = 0;
virtual void Free(void* ptr) = 0;
virtual IGraphicsService* GetGraphicsService() = 0;
virtual IInputService* GetInputService() = 0;
virtual IDebugService* GetDebugService() = 0;
};
Несмотря на кажущуюся «динамическую» натуру системы, никаких IID я переизобретать не стал. BIOS должен реализовывать ровно тот минимальный функционал системы, который нужен. Экземпляр CSystem создаётся так называемым «портом» на конкретную плату, который должен заполнить структуру с указателями на реализации подсистем — прямо как machine-файлы в Linux! И RAII не нарушили, и полный контроль без костылей сохранили — ляпота!
void InitializePlatform()
{
CommManager = new CCommunicationManager();
CDebugService* dbgSvc = new CDebugService();
/* Print some userful debug information */
CJEDECFlashID* flashId = FlashManager.GetFlashID();
dbgSvc->Print("Initializing platform");
dbgSvc->Print("Flash memory manufacturer: 0x%x, capacity: %dKb", flashId->Manufacturer, flashId->Capacity / 1024);
dbgSvc->Print("CID: %d", FlashManager.GetCID());
dbgSvc->Print("First available: %d", FlashManager.GetFirstUserSector());
/* Service initialization */
InputService = new CInputService(dbgSvc);
GraphicsService = new CGraphicsService(dbgSvc);
/* Platform description info */
PlatformInfo.DebugService = dbgSvc;
PlatformInfo.GraphicsService = GraphicsService;
PlatformInfo.InputService = InputService;
System = new CSystem(&PlatformInfo);
}
int main() {
InitializePlatform();
while (true) {
/* Tick all platform-depend services here */
CommManager->Tick();
PowerStateManager.Tick();
InputService->Tick();
System->Tick();
}
}
В целом, базовая архитектура примитивная и понятная. Перейдем же к деталям реализации конкретных модулей.
❯ Графика
Первая подсистема, которую я реализовал — была графической. Концептуально она разделена на два отдельных модуля: драйвер дисплея, который позволяет получить его параметры и в будущем управлять его состоянием, а также модуль для рисования на поверхностях. Прямо как в DirectDraw:
struct CFrameBufferInfo
{
uint16_t Width;
uint16_t Height;
CColor* Pointer;
uint32_t Size;
};
class IDrawingSurface : public ISystemService
{
public:
virtual void Clear(CColor color) = 0;
virtual void DrawBitmap(CBitmap* bitmap, int x, int y) = 0;
virtual void DrawBitmapEx(CBitmap* bitmap, int x, int y, CSpriteInfo* spriteInfo) = 0;
virtual void DrawRect(CColor color, int x, int y, int width, int height) = 0;
virtual void FillRect(CColor color, int x, int y, int width, int height) = 0;
virtual void DrawLine(CColor color, int x1, int y1, int x2, int y2) = 0;
virtual void DrawString(CColor color, int x, int y, CAnsiChar* str) = 0;
};
class IGraphicsService : public ISystemService
{
public:
virtual void SetPowerState(bool isPowerEnabled) = 0;
virtual void SetBacklightState(bool isBacklightEnabled) = 0;
/* Maybe some controller-related functions in future? Like BIAS and HW rotation? */
virtual CFrameBufferInfo* GetFrameBufferInfo() = 0;
virtual IDrawingSurface* GetDrawingSurface() = 0;
virtual void Flush() = 0;
};
Сам драйвер дисплея классический: в его задачи входит инициализация контроллера, выделение памяти под фреймбуфер и регулярное обновление изображения на матрице. Поскольку в таких устройствах используются стандартные MIPI DBI экраны с набором команд DCS, часть кода инициализации и работы с дисплеем стало возможным унифицировать:
/* Perform hardware reset */
gpio_put(PIN_LCD_RST, 0);
sleep_ms(DISPLAY_INIT_SLEEP_TIME);
gpio_put(PIN_LCD_RST, 1);
sleep_ms(DISPLAY_INIT_SLEEP_TIME); /* Wait for display controller to complete initialization */
Reset(); /* Perform software reset to maintain default register state */
SendCommand(cmdSLPOUT, 0, 0); /* Disable sleep mode */
SendCommand(cmdCOLMOD, 0x05); /* Set color format and decoding*/
SendCommand(cmdINVON, 0, 0); /* Disable inversion */
SendCommand(cmdNORON, 0, 0); /* Enable normal mode */
SendCommand(cmdMADCTL, cmdMADCTL_RGB); /* Set pixel size */
uint8_t windowSize[] = { 0 >> 8, 0, DISPLAY_WIDTH >> 8, DISPLAY_WIDTH }; /* Set display window (note this is not safe for displays with sides not equal in size) */
SendCommand(cmdCASET, windowSize, 4);
SendCommand(cmdRASET, windowSize, 4);
SetPowerState(true); /* Enable display */
Вероятно читатель может спросить: «зачем выделять целых 115КБ под фреймбуфер, если можно использовать команды CASET/RASET и рисовать отдельные спрайты прямо в память дисплея?». Дело в том, что в таком случае скорость отрисовки будет падать обратно пропорционально размеру и числу рисуемых изображений. Если мы попытаемся нарисовать параллакс-фон, состоящий из трёх картинок с размерами 240x240, то нашим узким местом станет не только цена обращения к XIP-кэшу, но и производительность SPI-контроллера (который напрямую тактируется от системного PLL) и мы получим те самые 1-2 FPS. Кроме того мы потеряем возможность использования DMA и нам придётся ждать каждой транзакции на экран: это проблема многих «самодельных» консолей, которую, впрочем, можно решить обратившись к опыту предков — а именно PPU.

В своём проекте я решил активно задействовать DMA-контроллер для отправки фреймбуфера на дисплей. Концепция простая: мы указываем ему переслать фреймбуфер, начинаем подготавливать следующий кадр и если транзакция ещё не завершена - то дожидаемся её окончания, дабы картинка оставалась целостной. Однако если обновление логики следующего кадра завершается быстрее, чем DMA-контроллер успевает отправить сканлайны - мы можем получить эффект тиринга.
/* Setup DMA for SPI */
dmaChannel = dma_claim_unused_channel(true);
dmaConfig = dma_channel_get_default_config(dmaChannel);
channel_config_set_transfer_data_size(&dmaConfig, DMA_SIZE_8);
channel_config_set_dreq(&dmaConfig, spi_get_dreq(spi1, true));
channel_config_set_read_increment(&dmaConfig, true);
channel_config_set_write_increment(&dmaConfig, false);
...
if(!dma_channel_is_busy(dmaChannel))
{
uint8_t cmdByte = cmdRAMWR;
gpio_put(PIN_LCD_CS, 0);
gpio_put(PIN_LCD_DC, 0);
spi_write_blocking(spi1, &cmdByte, 1);
gpio_put(PIN_LCD_DC, 1);
dma_channel_configure(dmaChannel, &dmaConfig, &spi_get_hw(spi1)->dr, frameBufferInfo.Pointer, frameBufferInfo.Size, true);
}
Далее переходим к фактической отрисовке изображений. На данный момент поддерживается только один формат пикселей — RGB565, поскольку нет особого смысла использовать 8-битную палитру для изображений 32x32 (но есть смысл использовать 4х-битную, как на NES). Процесс рисования называется блиттингом и поскольку реализация полноценного альфа-блендинга слишком дорогая для реалтайм графики на микроконтроллерах, для описания прозрачности используется техника колоркеев.

Взято с pinterest
ColorKey — это как ChromaKey, но для описания прозрачного цвета используется только базовый цвет, а не цвет + порог допустимых цветов. Помните как в играх 90-х были картинки с розовым фоном цвета Magenta? Вот это оно самое :)
for(int i = 0; i < min(y + bitmap->Height, frameBufferInfo->Height) - y; i++)
{
CColor* bitmapScanline = &bitmap->Pointer[i * bitmap->Width];
CColor* scanline = &frameBufferInfo->Pointer[(y + i) * frameBufferInfo->Width + x];
for(int j = 0; j < min(x + bitmap->Width, frameBufferInfo->Width) - x; j++)
{
uint16_t sample = *bitmapScanline;
if(sample != bitmap->ColorKey)
*scanline = sample;
scanline++;
bitmapScanline++;
}
}
Рисование текста реализовано знакомым для Embedded-инженеров способом: шрифты описываются в формате 8x8, где 8 битов каждого байта обозначают наличие или отсутствие пикселя в текущей позиции. Такие шрифты не только занимают очень мало места, но их также очень легко и быстро рисовать, а также масштабировать под различные разрешения экранов. На данный момент я задумываюсь — стоит ли добавлять в консоль поддержку полноценного UTF-16, если учесть что основной таргет на русскоязычную аудиторию, где и CP866 хватает с головой?

Какой же дисплей чёткий...
❯ Ввод
Далее мы плавно переходим к реализации драйвера ввода. Как я уже говорил выше, все кнопки подключены к своим отдельным GPIO без использования сдвигового регистра или I/O Expander'а, что с одной стороны и хорошо (некоторые китайские производители реализовывают консоли с кнопками, основанными на матричном (!!!) принципе), а с другой — отъедает большинство GPIO у RP2040. Свободными пинами мы могли бы выполнять множество полезной работы: получать уровень заряда аккумулятора у Fuel Gauge, управлять уровнем подсветки с помощью ШИМ-контроллера и ключа, или, в конце-концов, сделать порт для подключения периферии... но нет так нет.
Сам по себе драйвер ввода до жути примитивный: он позволяет получить состояние отдельных кнопок, осей (как Input.GetAxis в Unity) и проверить, нажата ли хоть какая-то кнопка:
class IInputService : public ISystemService
{
public:
virtual EKeyState GetKeyState(EKeyCode keyCode) = 0;
virtual int GetAxis(EInputAxis axis) = 0;
virtual bool IsAnyKeyPressed() = 0;
};
Для удобства и портабельности BIOS'а между платами, кнопки геймпада маппятся к соответствующим GPIO в отдельной таблице трансляции, которая также содержит состояния этих самых кнопок:
// Should be layouted in order of EKeyCode enum
CButtonState ButtonMapping[] = {
{
PIN_KEY_LEFT
},
{
PIN_KEY_RIGHT
},
{
PIN_KEY_UP
},
{
PIN_KEY_DOWN
},
{
PIN_KEY_A
},
{
PIN_KEY_B
},
{
PIN_KEY_X
},
{
PIN_KEY_Y
},
{
PIN_KEY_LEFT_TRIGGER
},
{
PIN_KEY_RIGHT_TRIGGER
}
};
Дело в том, что в нашем проекте недостаточно иметь лишь одно булево: нажата-ли кнопка или нет, для компенсации дребезга кнопок у нас также реализуется задержка перед следующей проверкой и дополнительное состояние для удобства реализации меню — «только что отпущена».
void CInputService::Tick()
{
timeStamp = get_absolute_time();
for(int i = 0; i < ButtonMappingCount; i++)
{
CButtonState* buttonState = &ButtonMapping[i];
bool gpioState = !gpio_get(buttonState->GPIO); // Buttons are pull-up to high when not pressed
// Check if there was elapsed enough time
if(timeStamp > buttonState->LastStateChange)
{
if(buttonState->State == EKeyState::ksReleased)
buttonState->State = EKeyState::ksIdle;
if(buttonState->State == EKeyState::ksIdle && gpioState)
buttonState->State = EKeyState::ksPressed;
if(buttonState->State == EKeyState::ksPressed && !gpioState)
buttonState->State = EKeyState::ksReleased;
buttonState->LastStateChange = timeStamp + KEY_DEBOUNCE_THRESHOLD;
}
}
}
Таким образом, мы получаем куда более удобную подсистему ввода, чем условная битовая маска с обозначением каждой кнопки и ручной обработкой её состояний в игре...
EKeyState CInputService::GetKeyState(EKeyCode keyCode)
{
uint32_t code = (uint32_t)keyCode;
if(keyCode >= ButtonMappingCount)
return EKeyState::ksIdle; /* Maybe we should throw an exception? */
return ButtonMapping[code].State;
}
int CInputService::GetAxis(EInputAxis axis)
{
EKeyCode a = EKeyCode::keyLeft;
EKeyCode b = EKeyCode::keyRight;
if(axis == EInputAxis::inputAxisVertical)
{
a = EKeyCode::keyUp;
b = EKeyCode::keyDown;
}
return GetKeyState(a) == EKeyState::ksPressed ? -1 : (GetKeyState(b) == EKeyState::ksPressed ? 1 : 0);
}
А вот и результат:
❯ Запуск программ
Вот мы и подошли к, возможно, самой интересной подсистеме в нашем BIOS'е. Думаю многие читатели так или иначе интересовались тем, как же компилятор и линкер превращают исходный код и объектный файлы в пригодные для выполнения программы и библиотеки. Вопрос запуска нативных программ на микроконтроллерах интересовал и меня — я даже написал целых три статьи об этом: в первой мы поговорили о ESP32 и Xtensa, а во второй реализовали BinLoader путём реверс-инжиниринга и хакинга кнопочного телефона, а в третьей сделали полу-универсальный ElfLoader для нескольких моделей телефонов на разных платформах.
Но начнём мы с простого. Каждая программа делится на три основных секции:
.text — содержит в себе машинный код функций и так называемые Literal pools. Может быть как в ROM, так и в RAM. На системах, где есть возможность выполнять код и в ROM, и в RAM, есть отдельная секция - .iram.
.data — содержит инициализированные переменные, которые обычно попадают в оперативную память. Для статических констант есть отдельная секция, называемая .rodata.
.bss — содержит в себе не-инициализированные переменные, обычно это нули. В исполняемый файл секция .bss напрямую не записывается, остаётся лишь информация о том, каков её размер, а саму секцию затем выделит динамический линкер.
Куда попадут части программы определяет специальная утилита — линкер, которая на основе специального скрипта «раскладывает» данные по нужным секциям. Благодаря этому скрипту, мы можем, например, перенести часть функций в оперативную память для более быстрого исполнения или добавить в начало программы заголовок с описанием приложения.
В моём случае, я решил загружать игры в SRAM и дабы не реализовывать нормальный динамический линкер и релокации, решил выделить под игру фиксированный кусочек оперативной памяти объёмом в 128КБ. Для этого я отредактировал скрипт линкера Pico C SDK так, чтобы сразу после вектора прерываний шла наша программа:
. = ALIGN(4);
.ram_vector_table (NOLOAD): {
*(.ram_vector_table)
} > RAM
iram_program_reserve_size = 128K;
.iram_program (NOLOAD) : {
. = ALIGN(4);
PROVIDE(iram_program_origin = .);
. += iram_program_reserve_size;
} > RAM
.uninitialized_data (NOLOAD): {
. = ALIGN(4);
*(.uninitialized_data*)
} > RAM
Для компиляции программы также используется кастомный скрипт для линкера и особый Makefile, где после сборки программы мы копируем все её секции в выходной файл в «сыром» виде. Поскольку программа собирается под выполнение из конкретного адреса — пока речь идёт о переносимости только между одной аппаратной платформой. На RP2040, RP2350 и возможно STM32 такое «прокатит», но вот на других ARM-процессорах — большой вопрос!
OUTPUT_FORMAT("elf32-littlearm")
SECTIONS
{
. = 0x200000c0;
.program_info : {
*(.program_info*)
}
.text : {
*(.vtable*)
*(.text*)
*(.rodata*)
*(.data*)
*(.bss*)
}
/DISCARD/ : {
*(.ARM.*)
*(.comment*)
}
}
Каждое приложение, как и базовая система, предполагает использование ООП и поэтому представляет из себя реализацию класса IApplication. Для этого нам нужна некоторая runtime-поддержка: аллокатор, функция для создания экземпляра приложения, а также указатель на ISystem. Именно поэтому каждая программа должна экспортировать специальный заголовок, где содержится указатель на функцию-инициализатор:
#define PROGRAM_HEADER 0x1337
#define PROGRAM_INFO(name, clazz) int test; CAllocator* __Allocator; IApplication* __createInstance(CAllocator* allocator, ISystem* systemPtr) { __Allocator = allocator; return new clazz(systemPtr); } \
CProgramInfo __program_info __attribute__ ((section(".program_info"))) = { PROGRAM_HEADER, BIOS_VERSION, name, &__createInstance };
struct CProgramInfo
{
uint32_t Header;
uint32_t BIOSVersion;
CAnsiChar Name[32];
CreateApplicationInstanceFunction CreateApplicationInstance;
};
...
PROGRAM_INFO("Blink", CBlinkApplication)
Таким образом, для выполнения нашей программы и вызова её обработчиков событий нам достаточно лишь загрузить файл по адресу 0x200000c0 и создать экземпляр IApplication. Всё очень просто и понятно!
CAllocator allocator;
allocator.Alloc = malloc;
allocator.Free = free;
IApplication* app = ((CProgramInfo*)ptr)->CreateApplicationInstance(&allocator, System);
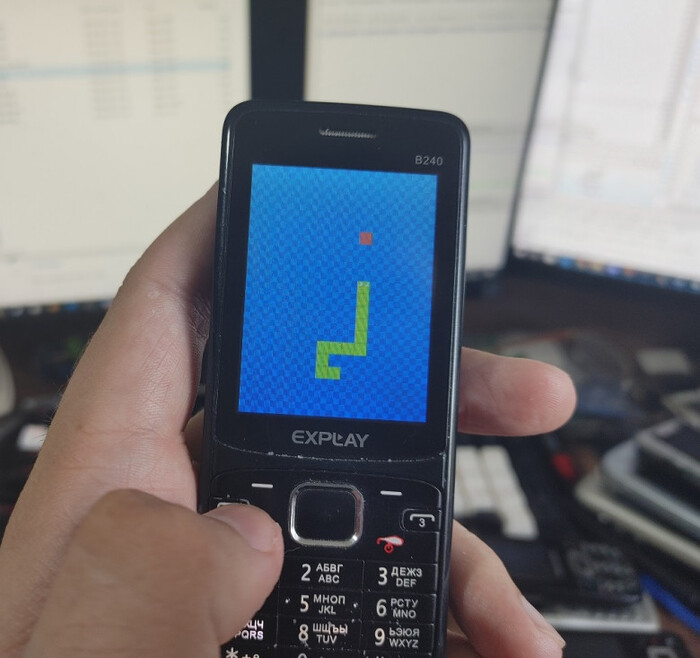
Но "моргалка" ведь слишком просто, согласитесь? Поэтому мы с вами напишем ремейк классической игры Змейка, которая работает в настоящие 60 FPS!
❯ Заключение
Вот таким нехитрым образом я понемногу реализовываю свою мечту детства: «андерграунд" консоль собственной разработки. Конечно здесь ещё много чего нужно доделывать перед тем, как начинать разводить свою плату, но начало ведь положено! В контексте GamePi13, я считаю что моя реализация SDK для консоли всё таки немного лучше, чем то, что предлагает производитель «из коробки».
Я понимаю что мой не совсем трушный эмбеддерский подход может вызвать разные ощущения у читателей: так что приглашаю всех заинтересованных в комментарии, обсудим с вами «сломанный Branch-prediction из-за виртуалов», «UB из-за того, что порядок указателей на реализации в VMT может отличаться» и «какого фига игры у тебя оказались в SRAM, а высокопроизводительный код на Flash, если у XIP кэш всего в 16КБ!».
А если вам интересна тематика ремонта, моддинга и программирования для гаджетов прошлых лет — подписывайтесь на мой Telegram-канал «Клуб фанатов балдежа», куда я выкладываю бэкстейджи статей, ссылки на новые статьи и видео, а также иногда выкладываю полезные посты и щитпостю. А ролики (не всегда дублирующие статьи) можно найти на моём YouTube канале.
Если вам понравилась статья...
И у вас появилось желание что-то мне задонатить (например прикольный гаджет) - пишите мне в телегу или в комментариях :) Без вашей помощи статьи бы не выходили! А ещё у меня есть Boosty.