BackupWoodtec HA2030 Weihong NK105G3
Если у кого есть откликнетесь пожалуйста
Если у кого есть откликнетесь пожалуйста
В этом цикле продолжу рассказывать о полезных плагинах и своих находках в стеке Home Assistans. И начнем с важного, с бекапов.
Коротко: Если у вас Home Assistant, и вы ещё не ставили Time Machine и Google Drive Backup - вы живёте на краю без страховки. Первый даёт возможность откатиться, когда что-то поломали. Второй - спасёт, если Home Assistant вовсе не загрузится.
Этот модуль записывает историю изменений ваших YAML-файлов и конфигурации. Представьте: обновили аддон — и весь интерфейс посыпался. А Time Machine просто говорит:
«Хочешь вернуться в прошлое, где всё работало?»
Установка:
Settings -> Add-ons -> Add-on store
Добавляем репозитарий (три точки в верхнем углу -> Add-on store -> Repositories - https://github.com/saihgupr/HomeAssistantTimeMachine)
Находите Home Assistant Time Machine в Add-on store
Установите и перезапустите HA.
После этого в меню появится вкладка Time Machine, где можно выбирать дату и возвращаться к нужной версии.
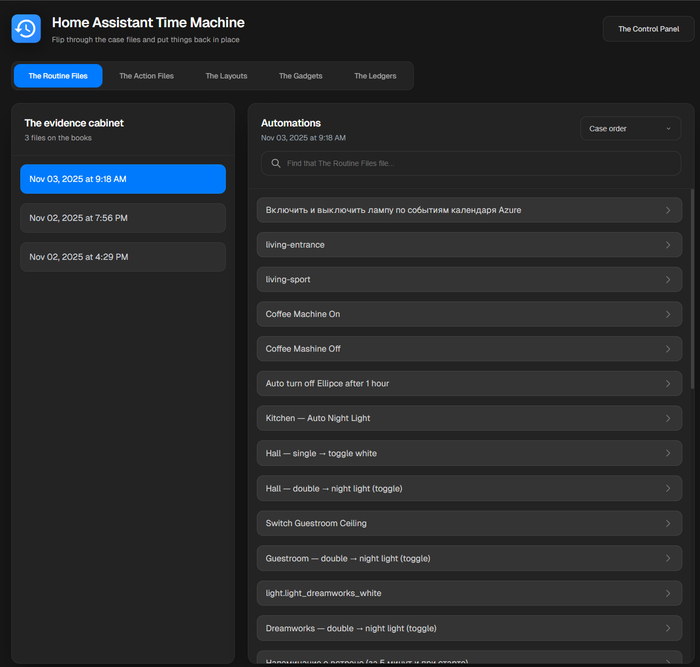
Совет: можно сделать автоснимок раз в день, чтобы не вспоминать, когда последний раз всё было “нормально”.
Этот модуль делает резервные копии всей системы и шлёт их в ваш Google Drive.
Если сервер сдох, SSD умер или кот выдёрнул кабель - просто ставите свежий HA и жмёте Restore from Drive. Всё вернётся, как было.
Установка:
Там же, в Settings -> Add-ons -> Add-on store указываете репозитарий https://github.com/sabeechen/hassio-google-drive-backup
Затем в Add-on store ищите Home Assistant Google Drive Backup.
После установки появится мастер подключения к вашему Google Drive.
Авторизуйтесь через Google, выберите папку для бэкапов.
Настройте расписание: например, ежедневно в 3:00 и хранить последние 5 копий.
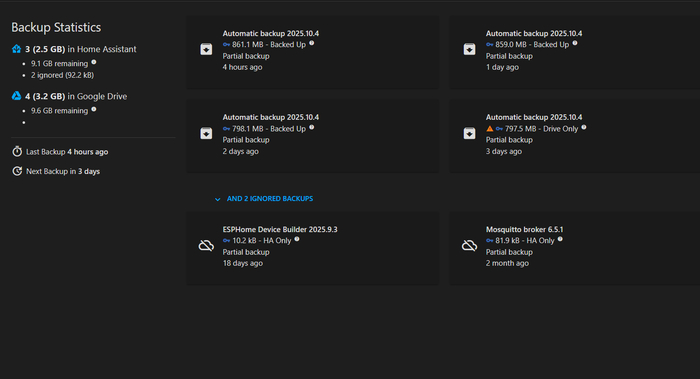
Бонус: можно включить автоудаление старых бэкапов и уведомления в Telegram, если вдруг резервное копирование не удалось
Оба модуля ставятся за 10 минут, но могут спасти часы (или дни) восстановления. Лично мне - уже не раз спасали.

Вернусь позже с другими полезными плагинами. Ну и делитесь своими в комментах или в отдельных постах сообщества
У меня очень много старых и некоторых новых игр, просто мне порой лень прописывать каждый отдельный путь к сейву, чтобы сохранить в облаке.
Желательно с поддержкой Яндекс Диска, Облака Mail.ru или хотя-бы по WebDAV.
На днях случились две занимательные истории про бекапы.
История первая.
Послушайте!
Ведь, если ЦОДы зажигают —
значит — это кому-нибудь нужно?
В Южной Корее сгорел ЦОД - G-Drive Fire Destroys 125,000 Officials' Data. Бекапов не было.
Все бы ничего, но это было официальное корейское государственное облако.
Согласно официальной части «просто загорелись литиевые батареи при переносе».
Неофициально злые языки говорят, что облако давно взломали или северные корейцы, или китайцы, и слили оттуда все, что было интересного, поэтому
Все было ясно. Дом был обречен. Он не мог не сгореть. И, действительно, в двенадцать часов ночи он запылал, подожженный сразу с шести концов.
Объемы данных заявлены как 858 терабайт. Бекапы, а что бекапы, ну не смогли:
The actual number of users is about 17% of all central government officials. According to the Ministry of the Interior and Safety, as of last August, 125,000 public officials from 74 ministries are using it. The stored data amounts to 858TB (terabytes), equivalent to 449.5 billion A4 sheets.
Вся эта история, конечно, вранье.
Система хранения данных 5 летней давности (из 2020 года), даже среднего сегмента, то есть обычная, серийная, продаваемая в розницу – это 36 SSD дисков формата PALM, размещаемые в систему хранения высотой 2 юнита, включенных через NVME.
Например, Huawei dorado 5000 v6 с дисками Huawei 15.36TB SSD NVMe Palm Disk Unit(7")
Или, система из того же ценового диапазона, 8 летней давности (из 2017 года) - HPE Nimble Storage All Flash Array AF60 или AF80, с заявленной емкостью системы хранения от 1.8 до 3.7 петабайт, с SSD дисками комплектом в 24 штуки - HPE Nimble Storage AF40/60/80 All Flash Array 184TB (24x7.68TB) FIO Flash Bundle.
Диски 2.5 и по 7.68TB Тб, так что потребуется больше дисков, больше места, и больше денег. Старая система, ничего не поделать.
В 2025 году петабайт, да еще с учетом сжатия и дедупликации, это даже не половина стойки.
Все современные системы хранения данных, кроме уж совсем SOHO (small office - home office):
и продаваемые как системы хранения данных,
и продаваемые как программно-определяемые системы хранения данных,
и продаваемые как гиперконвергентые среды (Storage space direct, vSAN) для гиперскейлеров и частных облаков,
Все они:
Во первых имеют в составе функционал репликации на «другой удаленный ЦОД» - то есть функционал метрокластера, синхронный или асинхронный. Это не бекап, это только репликация, но она спасет от пожара, потопа, и так далее (лицензируется отдельно).
Во вторых, так или иначе, интегрируются с системами резервного копирования, в том числе с офлайн хранением – с классическими ленточными библиотеками (LTO) или их эмуляцией, Virtual Tape Library (тот же QUADstor).
Что-то там еще пытаются рассказать, что такие объемы записать на кассеты нельзя .. ну что ж. Посчитаем.
Кассета Quantum LTO-9 – это 18 терабайт не сжатых данных.
10 кассет – 180 терабайт. 100 кассет – 1800 терабайт, 2.5 раза выполнить полный бекап этих 850 Тб
Расширяемая ленточная библиотека HPE Storage MSL3040 Tape Library идет с комплектом на 40 слотов, расширяется до 640 слотов.
Сам привод для дисков (стример), например HPE Storage LTO Ultrium Tape Drives, точнее HPE StoreEver MSL LTO-9 Ultrium 45000 Fibre Channel Drive Upgrade Kit (R6Q74A) какой-то странный, я что-то не пойму, почему везде пишут, что он не FC, а SAS 12G.
Но, какая разница. Для библиотеки (HPE StoreEver MSL 3040 Tape Library) заявлена скорость:
Maximum Data Transfer (Native) 22.5 TB/hr (21 LTO-9 drives)
Maximum Data Transfer (Native) 51.4 TB/hr (48 LTO-9 drives)
Источник: QuickSpecs, официальный сайт HPE.
То есть для «обычных» 4 приводов скорость составит около 4 терабайт \ час, 98-100 Тб\сутки. 850 заявленных терабайт можно было записать за 8-10 дней на 4 дисках, или, для записи «за сутки» потребовалось бы 35 приводов из максимум 48.
Деление полученного бекапа на несколько потоков для записи, Aux copy with Maximum streams для Commvault (не путать с Multiplexing, он не для этого) – функционал не очевидный, и возможно что-то надо покрутить – подпилить, но решаемый.
Так что, было бы желание, а коммерческие решения есть на рынке очень давно. Но, желания не было.
История вторая
Летом 2025 года Газпромбанк торжественно отчитался, цитата:
Москва, 18 июня 2025 года – Газпромбанк успешно завершил один из самых масштабных ИТ-проектов последних лет — переход на полностью импортозамещённую автоматизированную банковскую систему (АБС) ЦФТ, в основе которой лежит программно-аппаратный комплекс Скала^р (продукт Группы Rubytech) для построения доверенной ИТ-инфраструктуры финансового сектора на базе технологии Postgres Pro Enterprise.
Официальный сайт Газпромбанка, статья Газпромбанк завершил переход на импортозамещённую автоматизированную банковскую систему
Перешел и перешел, молодцы. Но попалась мне на глаза реклама ООО «Постгрес Профессиональный», под видом статьи Как Газпромбанк перешел на российскую СУБД. Поскольку это реклама под видом «колонки» (то, что реклама написано внизу, серыми буквами), то дата не проставлена.
Понравилась мне оттуда цитата:
Приведу пример с резервным копированием и восстановлением данных. Высокая скорость этих процессов была для нас одним из ключевых требований, потому что при наступлении фатальной ошибки критически важно быстро восстановиться из резервной копии. Postgres Pro Enterprise делает это за два часа, иностранные решения, которые мы тестировали, — за 14.
Возникает вопрос, как так это у них получается.
Если (по неизвестным причинам) использовать не средства резервного копирования (которые все равно используют RMAN), а сам RMAN, то он, если я правильно прочитал, позволяет выполнять параллельное восстановление, цитата:
As long as there are many backup pieces into a backup set, RMAN will use an appropriate number of channels - if allocated - to restore the database.
Ex:
7 backup pieces and 6 channels allocated - RMAN will use the whole 6 channels in parallel
6 backup pieces and 6 channels allocated - RMAN will use the whole 6 channels in parallel
5 backup pieces and 6 channels allocated - RMAN will use only 5 channels - one will be IDLE
rman restore datafile : how to force parallelism ?
Если говорить про Microsoft SQL, то там есть SMB multichannel, и давным давно есть Accelerated database recovery, ADR и Multi-Threaded Version Cleanup (MTVC)
Accelerated Database Recovery enhancements in SQL Server 2022
У Postgre тоже есть параллельное исполнение:
By using multiple concurrent jobs, you can reduce the time it takes to restore a large database on a multi-vCore target server. The number of jobs can be equal to or less than the number of vCPUs that are allocated for the target server.
Best practices for pg_dump and pg_restore for Azure Database for PostgreSQL
Но не в 7 же раз разница.
Заключение
Не знаю, как после первой истории не вспомнить загадку про трех черепах:
Три черепахи ползут по дороге. Одна черепаха говорит: “Впереди меня две черепахи”. Другая черепаха говорит: “Позади меня две черепахи”. Третья черепаха говорит: “Впереди меня две черепахи и позади меня две черепахи”. Как такое может быть?
Вторая история просто интересная.
PS. И про первую историю, пишут что: Gov't official in charge of state computer network dies after fall at Sejong complex.
Как говорил один мой знакомый, покойник: я слишком много знал.

PS. Тега commvault нет
Как-то на сервере предприятия решили проапгрейдить систему хранения. От бедности или жадности это был и сервер БД, и приложений, и прод, и дев - всё в одном.
В выходные остановили сервер, винты сняли, воткнули для клонирования и решили целевую группу разбить на разделы.
Не буду ходить вокруг да около: переразбили исходные диски вместо новых - перепутали.
Когда меня вызвонили, я отдыхал с шашлыками и алкоголем, но от такой новости как-то внезапно протрезвел)) Когда я добрался до работы, в кабинете висел плотный туман с запахом кофе и сигарет, все нервно курили.
Выяснилось, что ошибку заметили практически сразу - диски переразбили, попытались склонировать, а разделов-то для клонирования и нету) И сразу выключили. Это несло неплохие шансы на восстановление и я взялся за disk editor (NU или от resource kit первых windows NT - уже не помню). Вспомнили примерную карту дисков, я нашёл бут-сектора и по ним вычислил точные адреса разделов, наваял вручную MBR по шаблонам, найденным где-то в FIDO - интернеты тоже были тогда нечастым гостем, и вуаля - всё восстановлено и даже загружается. Но седых прибавилось.
В другой раз на другом предприятии недозвонились и "компьютерщик", найденный по объявлению, вместо того, чтобы восстановить загрузку ОС, решил её переставить. Ну и правильно, конечно, так думать меньше надо. 1С он уже видел и даже что-то забэкапил. Но, к сожалению, он видел только базовые версии, а про клиент-сервер ему хоть и сказали, но он пропустил мимо ушей.
В итоге, база магазинчика за три года оказалась уничтоженой. Всякие "форенсик" ковыряния ничего уже не принесли, т.к. поверх уже была накачена ОС вместе с офисом и прочим хламом. И даже заботливо перенесенная 1С была, но без серверной части.
Хозяйке магазина не позавидуешь - впереди предстоял ввод последней отчетности и инвентаризация, что означало двухнедельную паузу в деятельности.
В современности же, для бедных можно настроить автоматический бэкап в облако. Богатые же вполне могут это делать и локально, и на удаленные NAS, и даже сохраняя неприкосновенность данных.
А свежих бэкапов нет.
Ну посмотрим, что завтра скажут девопсы.
Сраный Atlassin. Просто пздц.
Обращаюсь за помощью подскажите как загрузить бэкап PMC файлов на стойку, есть бэкап файлов pmc-ra.000 pmc-ra.prm pmc-sb.prm, ещё cncparam.DAT, кто сможет описать последовательность действий? Sram бэкап я загрузил уже
Drush 8
В командной строке используем команду:
drush ard
Вручную
Если вы используете Drupal Project, то, скорее всего, у вас будет установлен Drush 9, где команда drush ard будет недоступна.
Выгружаем БД:
drush sql-dump > dump.sql
Архивируем папку с сайтом:
zip -r backup.zip site
Файл с базой данных должен находиться в папке, которую вы архивируете.
Это два способа, которыми я пользуюсь на данный момент. Если вы знаете более правильные/простые/быстрые — пишите. Освою, допишу статью.