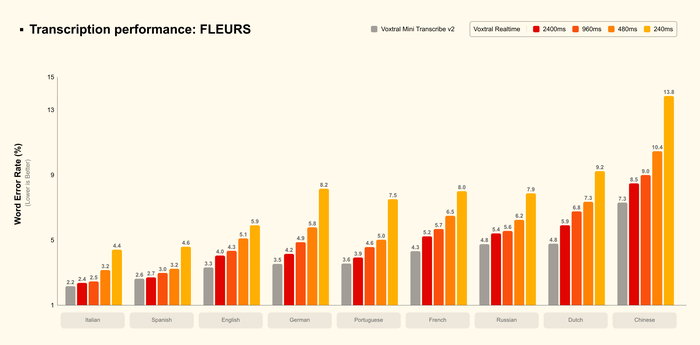
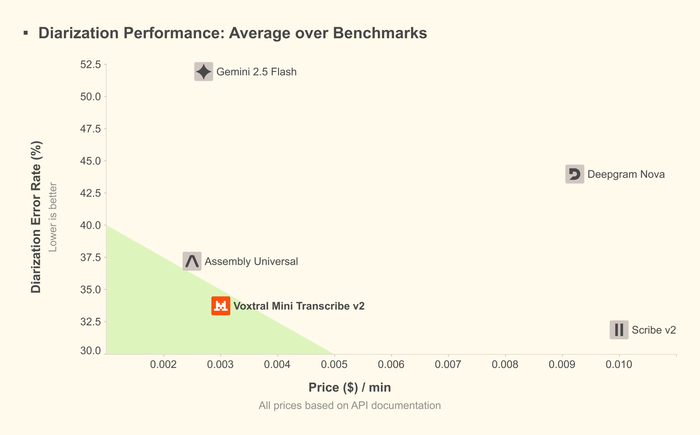
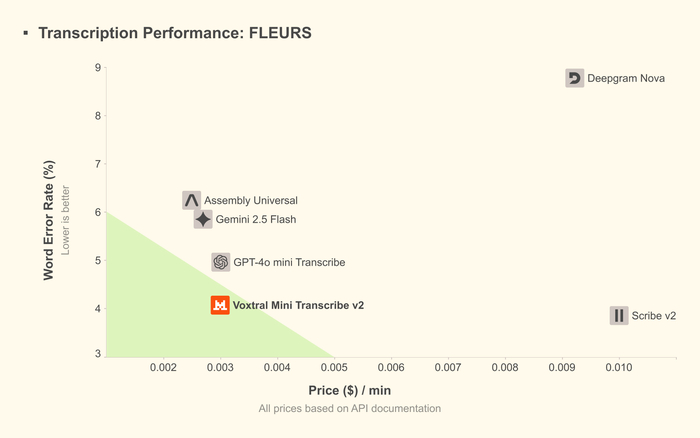
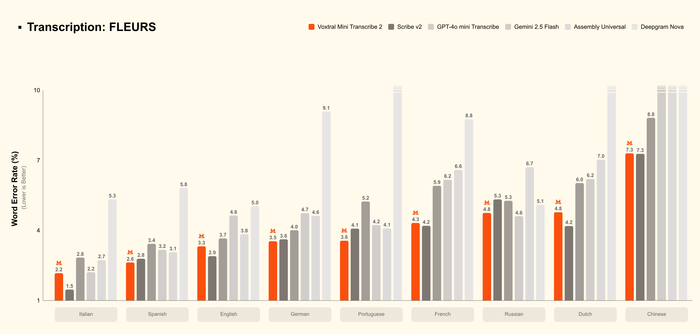
Представили две новые модели для преобразования речи в текст с высочайшим качеством, диаризацией и низкой задержкой в линейке Voxtral Transcribe 2 (https://huggingface.co/mistralai/Voxtral-Mini-4B-Realtime-26...). Разработанные для интеллектуального анализа встреч, голосовых агентов, автоматизации контакт-центров, субтитров и наблюдения за выполнением правил.
Первая из них имеет название Voxtral Mini Transcribe V2 и предназначена для пакетной обработки, имея лучшее соотношение цены и качества (низкая доля ошибок, $0.003/мин). Она поддерживает 13 языков, диаризацию, метки времени и контекстное исправление слов.
Вторая модель, эффективная для периферийных устройств, называется Voxtral Realtime, созданна для работы в реальном времени с настраиваемой задержкой до <200 мс. У неё тоже имеется многоязычность, а её веса открыты под лицензией Apache 2.0.
Все эти модели имеют высочайшую точность и низкую цену, поддержку 13 языков, надежную работу в шумной среде, а также обработку аудио до 3 часов.
Всем привет! Команда Microsoft Research выложила в открытый доступ VibeVoice-ASR — нейросетевую модель для распознавания речи с диаризацией (разделением) спикеров. Сегодня хочу рассказать об этой технологии подробнее и поделиться портативной версией.
Меня зовут Илья, я основатель сервиса для генерации изображений ArtGeneration.me, блогер и просто фанат нейросетей. А ещё я собрал портативную версию VibeVoice ASR под Windows и успел её как следует протестировать.
Whisper которому уже года три
Я сам пользуюсь Whisper уже много лет — делаю транскрипции своих видео, чтобы потом собрать оглавление для YouTube и использовать материал в текстовых статьях. И скажу честно — никогда не был полностью доволен результатом. Да, Whisper быстрый. Но на этом его достоинства для меня заканчивались.
Поэтому к изучению VibeVoice ASR я подошёл со всей ответственностью — протестировал на разных записях, сравнил качество, покрутил настройки.
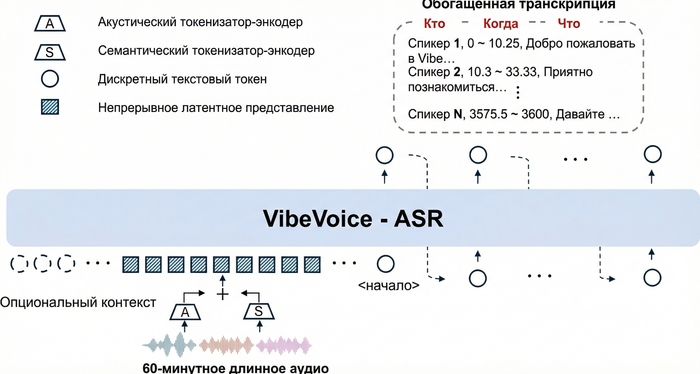
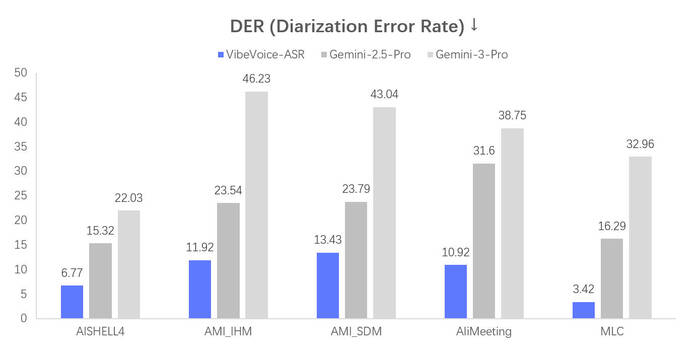
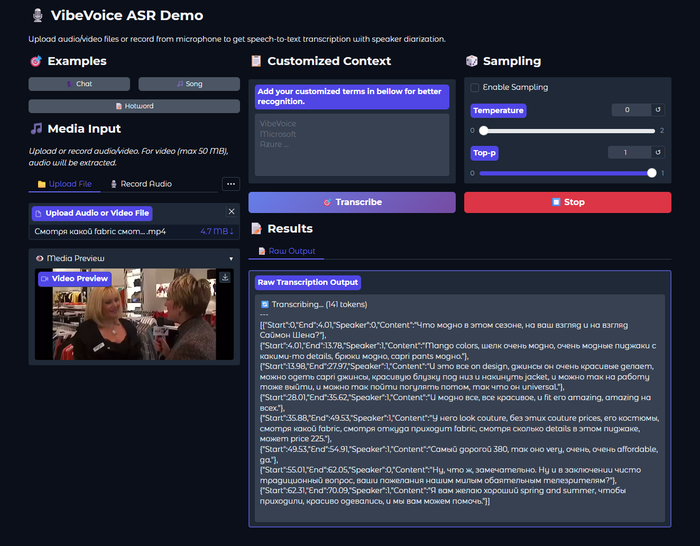
Главная особенность системы в том, что она обрабатывает до 60 минут аудио за один проход без нарезки на чанки. На выходе — структурированная транскрипция с указанием кто говорит, когда и что именно сказал. И всё это работает локально на вашем компьютере.
Как это работает
В основе VibeVoice-ASR лежит архитектура на базе Qwen 2.5 (~9 млрд параметров). Ключевая инновация — двойная система токенизации с ультранизким frame rate 7.5 Hz: акустический и семантический токенизаторы.
Такой подход позволяет модели работать с контекстным окном в 64K токенов — это и даёт возможность обрабатывать целый час аудио без потери контекста. Для сравнения: Whisper режет аудио на 30-секундные кусочки и теряет связность на границах сегментов.
На выходе модель генерирует Rich Transcription — структурированный поток с тремя компонентами:
{"Start":1.51,"End":7.49,"Speaker":0,"Content":"У неё преждевременное сохранять невозможно, родила, начала сразу родильная деятельность."},
{"Start":7.51,"End":9.41,"Speaker":1,"Content":"Марина, что с ней?"},
{"Start":10.28,"End":16.22,"Speaker":0,"Content":"У неё преждевременное сохранять невозможно, отошли годы, начала, начала сразу родовая деятельность."},
{"Start":16.22,"End":18.02,"Speaker":1,"Content":"Марина, что с ней?"},
{"Start":18.13,"End":27.94,"Speaker":0,"Content":"Она рожает, привезли в ближайшую больницу родовую. В каком состоянии ребёнок ещё хуже, срок маленький."},
Помимо спикеров, модель размечает неречевые события: [Music], [Silence], [Noise], [Human Sounds] (смех, кашель), [Environmental Sounds], [Unintelligible Speech]. Это сделано чтобы модель не галлюцинировала текст во время пауз или фоновой музыки.
Обработка длинных записей: до 60 минут аудио за один проход без потери контекста. Идеально для митингов, подкастов, лекций.
Диаризация спикеров: автоматическое определение кто говорит в каждый момент времени. Работает на записях с несколькими участниками.
Временные метки: точные таймкоды для каждого сегмента речи. Готовый материал для субтитров.
Customized Hotwords: вот что меня реально зацепило — возможность задать пользовательский контекст. Перед распознаванием указываешь список слов: фамилии, названия продуктов, термины, сокращения. Всё то, что обычно произносится нестандартно и превращается в кашу. Если в видео часто звучит "ArtGeneration" или "НЕЙРО-СОФТ" — просто добавляешь в контекст, и модель ВСЕГДА распознаёт корректно. Для технического контента — просто спасение.
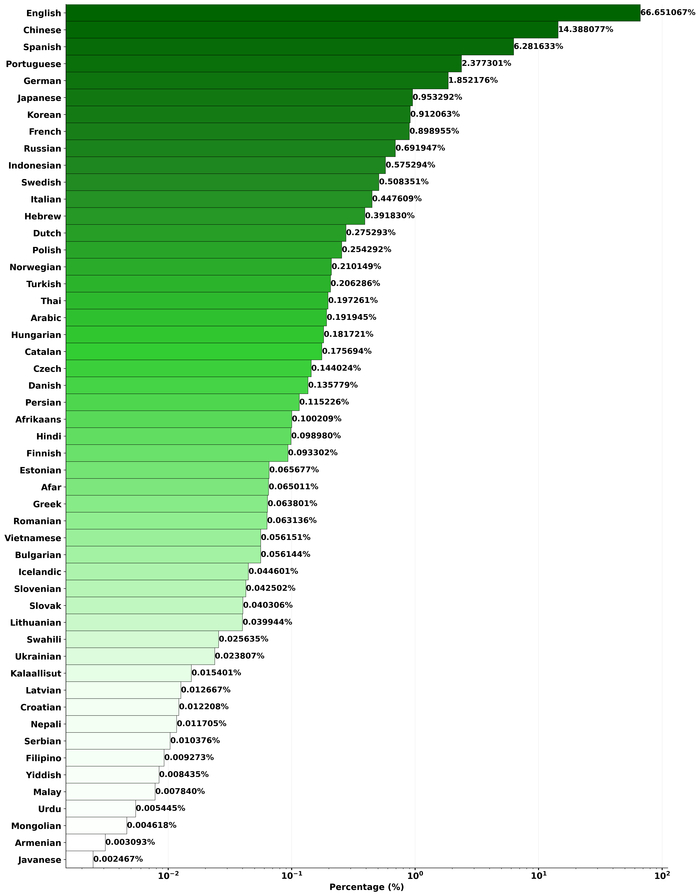
51 язык: включая русский, хотя основной фокус на английском и китайском.
Набор языков отличный
Модели
Помимо оригинальной модели от Microsoft, сообщество уже сделало квантованные версии для видеокарт с меньшим объёмом памяти.
Полная модель — microsoft/VibeVoice-ASR Размер 17.3 GB, требует ~8 ГБ VRAM. Лучшее качество распознавания.
4-bit квантизация — scerz/VibeVoice-ASR-4bit Требует ~4 ГБ VRAM, немного медленнее. Подходит для видеокарт с меньшим объёмом памяти.
В моей портативке доступны обе версии — можно выбрать прямо в интерфейсе. Также есть эмуляция 4-bit квантизации для полной модели, если хотите попробовать оригинал, но памяти впритык.
Текущие ограничения
К сожалению, не все задачи система решает одинаково хорошо:
Перекрывающаяся речь: если два человека говорят одновременно, модель не разделит их корректно.
Короткие фрагменты: диаризация плохо работает на высказываниях менее 1 секунды.
Только batch processing: нет real-time режима, только обработка готовых файлов.
Ресурсоёмкость: требует достаточно мощную видеокарту для комфортной работы.
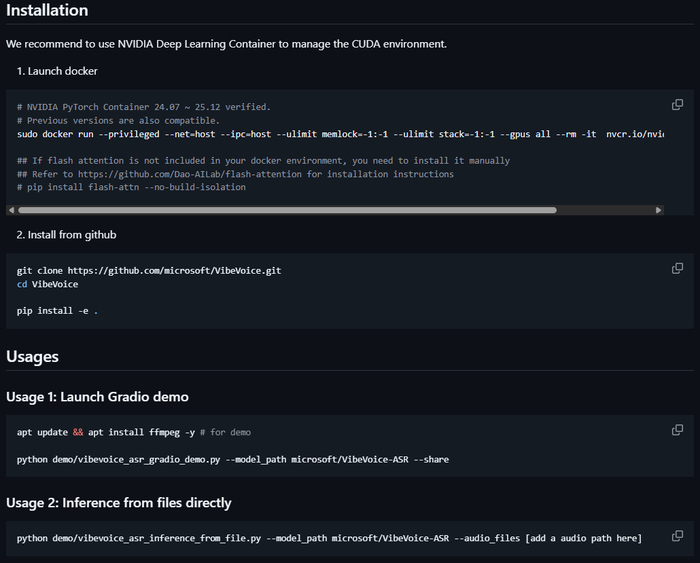
Я с каналом Нейро-Софт подготовил портативную сборку VibeVoice ASR Portable RU. В ней:
Русифицированный интерфейс
Установка в один клик (install.bat)
Поддержка полной и 4-bit моделей
Парсер результатов с фильтрацией — можно отдельно включать/выключать временные метки, спикеров, дескрипторы (музыка, шум, тишина). Удобно когда нужен только чистый текст без разметки
Фильтр по спикерам — можно вывести текст только конкретного участника разговора
Выбор видеокарты и установка нужной версии CUDA
Flash Attention 2 для RTX 30xx/40xx/50xx
Поддержка всех форматов аудио и видео через FFmpeg
Тёмная тема интерфейса
Всё необходимое уже включено в дистрибутив, просто распакуйте и запускайте, есть версия с готовым окружением под win 11 и RTX4090. Забирайте архив тут.
NVIDIA GPU с 8+ ГБ видеопамяти (или 4+ ГБ для 4-bit модели)
Windows 10/11 64-bit
16 ГБ оперативной памяти
10 ГБ свободного места на диске
Распакуйте в любую папку (путь без кириллицы), запустите install.bat, выберите видеокарту из списка. Модели скачаются при первом запуске.
Рассказывайте в комментариях как вы могли бы использовать такой инструмент и чего не хватает.
Я рассказываю больше о нейросетях у себя на YouTube, в Телеграм и на Бусти. Буду рад вашей подписке и поддержке. На канал Нейро-Софт тоже подпишитесь, чтобы не пропустить полезные репаки. Всех обнял. Удачных транскрипций!
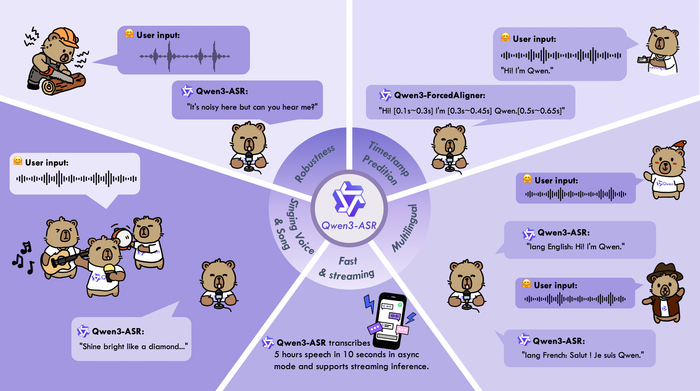
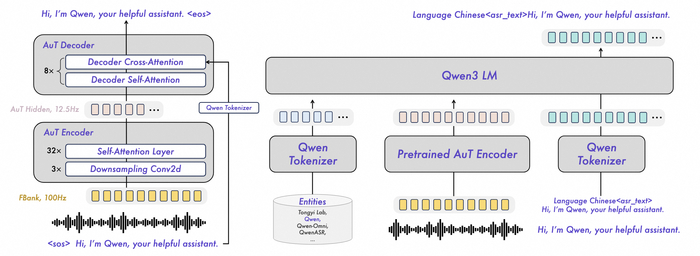
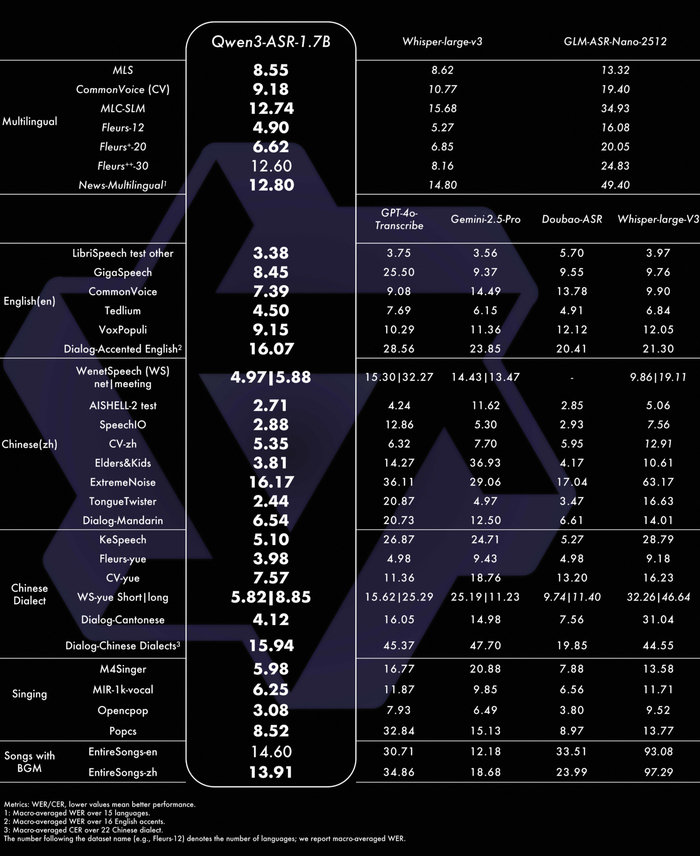
Модели Qwen3-ASR-1.7B / 0.6B нужны для распознавания речи (ASR) с идентификацией языка, поддерживая 52 языка и акцента (30 языков + 22 китайских диалекта), и работают с речью, пением и фоном.
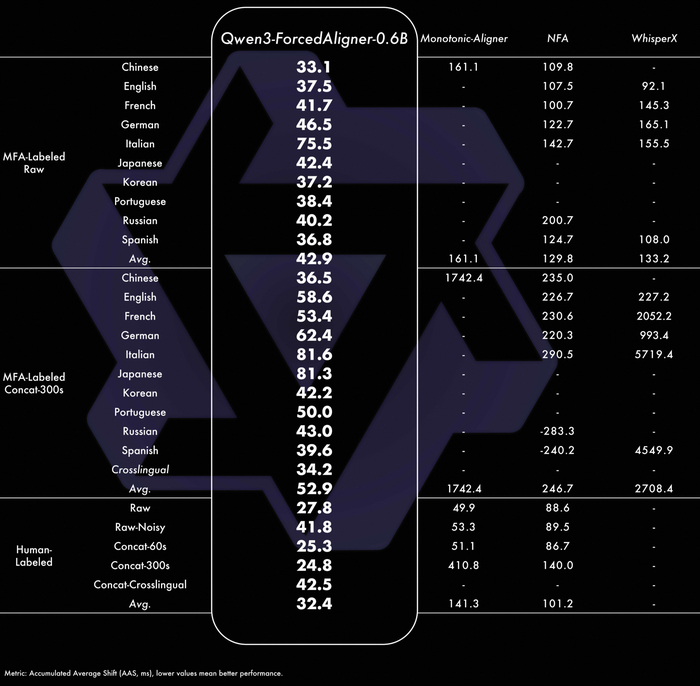
А модель Qwen3-ForcedAligner-0.6B нужна для точной привязки текста к аудио (выравнивание) в 11 языках.
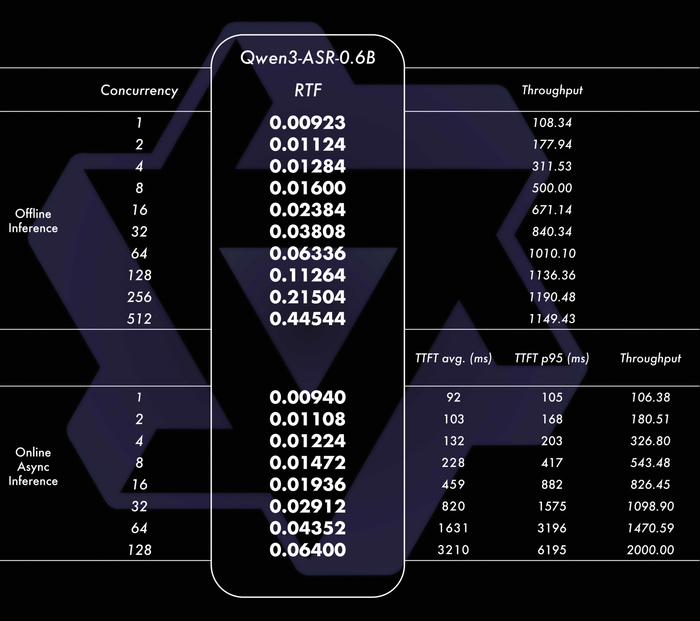
У моделей ASR высокая точность, и, например, 1.7B-модель показывает результаты на уровне лучших коммерческих API (GPT-4o, Gemini) и опережает open-source аналоги (Whisper). В свою очередь, по эффективности 0.6B-модель тут лучший баланс скорости и качества, имеющая очень низкую задержку (TTFT ~92 мс) при высокой пропускной способности. Все эти модели обладают высокой универсальностью, устойчиво работая в сложных условиях (шум, диалекты, детская/старческая речь, песни с музыкой). Они поддерживают потоковый и оффлайн-режим, а также длинные аудио (до 20 мин).
Что касается ключевых особенностей ForcedAligner, то здесь выделяется точность таймстампов, которая превосходит другие современные модели выравнивания (NFA, WhisperX), поддерживая длинное аудио до 5 минут.
Плюсом ко всему вместе с моделями выпущен готовый инструмент для inference с поддержкой пакетной обработки, потокового режима и т. д.
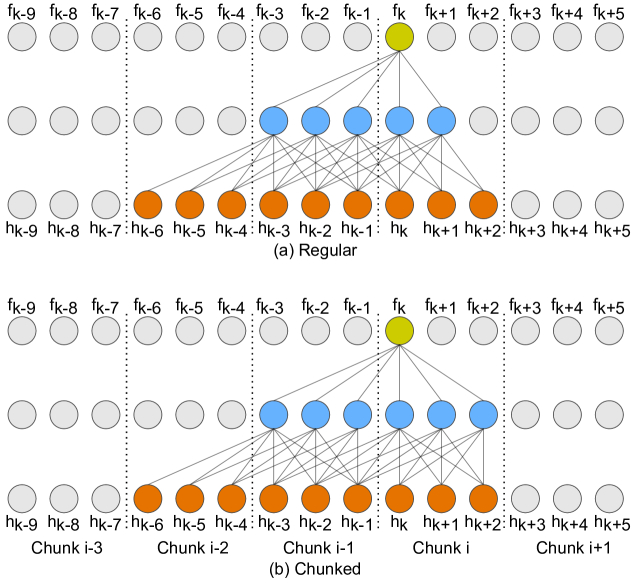
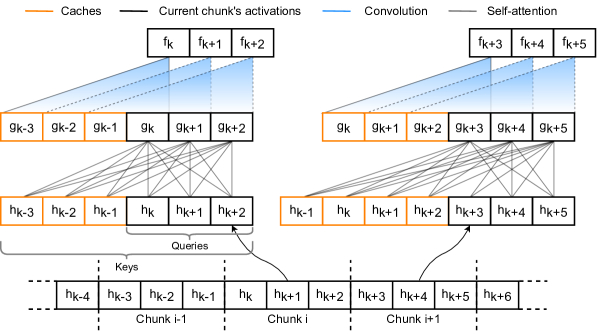
В ней применён контроль контекста, дающий ограниченный просмотр вперед и назад в энкодере. Кроме того, был реализован механизм кэширования активаций для эффективного потокового вывода без повтора вычислений.
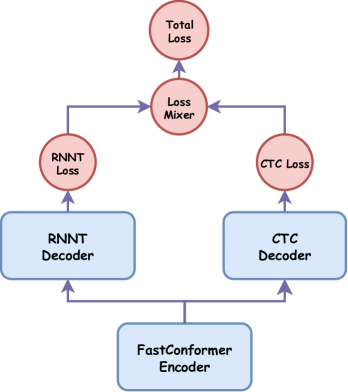
Модель согласованная и в ней нет разрыва между режимами обучения и вывода. У неё гибридная архитектура, включающая общий энкодер для двух декодеров (CTC и RNN-T), что улучшает точность и скорость обучения.
В плане гибкости есть поддержка нескольких уровней задержки одной моделью.
В результате модель превышает точность буферизованных стриминговых подходов при меньшей задержке и времени вывода, а гибридная архитектура улучшает сходимость CTC-декодера.
Заливаю фотки в облако, оно их там распознает и раскладывает по альбомам по тематике. Понадобилось тут что-то найти, лезу в альбомы... и рыдаю....
Морская свинка, сруб дерева, один и тот же форт в Финском заливе и батискаф... Небоскреб в 22 этажа... Фотки серверных стоек обнаружились в разделе "мебель"... Ну, оно хотя бы бесплатное, да...
"А теперь выберите все картинки со светофорами"...
Исследователи из Пенсильванскогоуниверситета впервые продемонстрировали на практике, как телефонные разговоры можно сугубо дистанционно расшифровать с помощью миллиметровых радаров и нейросетей нового поколения. Это не гипотеза — технология действительно работает и ставит под вопрос привычные представления о конфиденциальности.
Как работает «Wireless-Tap»
В 2022 году прототип системы мог распознавать всего 10 слов с высокой точностью. Сегодня «Wireless-Tap» способен обработать до 10 000 слов, превращая ключевые сигналы в цельную фразу, даже если телефон лежит в трёх метрах от радара.
Коммерческие радары, которые используются в автомобилях и устройствах движения, фиксируют микровибрации корпуса телефона в момент беседы.
Команда Penn State адаптировала для этой цели модель Whisper от OpenAI: её обучили на синтетических радиоданных, специально создав уникальные наборы для «шумных» сигналов. Такой подход позволил перейти от распознавания отдельных ключевых слов к транскрибированию целых диалогов.
Технические тонкости и вызовы
Главная проблема — радиосигнал крайне «шумный» и по качеству несопоставим с обычной речью: сигнал ниже 5 дБ. Обычные модели распознавания речи здесь попросту не работают. Поэтому разработчики применили метод low-rank adaptation и модифицировали лишь 1% параметров нейросети OpenAI Whisper, чтобы она адаптировалась к данным радара. Для обучения пришлось генерировать искусственные датасеты, поскольку реальных записей такого типа в открытых источниках не существует.
Приватность и общественные риски
Авторы проекта подчёркивают: их цель — продемонстрировать потенциальные риски, а не создавать инструменты слежки. Даже если точность не абсолютна, ИИ способен «дорисовывать» смысловые пробелы за счёт контекстуального анализа, как это делают профессиональные чтецы по губам.
Современные ИИ-системы всё чаще вызывают опасения у специалистов по безопасности: с расширением доступа к данным и новыми возможностями существует риск их неправомерного применения. Технологии могут быть использованы не только для промышленного мониторинга или медицинских задач — они уже потенциально грозят привычным границам приватности.
Почему это важно для профессионалов и бизнеса
Становится очевидно: даже привычные «безопасные» пространства больше не гарантируютконфиденциальность. Если массовые радары способны считывать разговоры с помощью ИИ, нужно пересматривать подход к цифровой безопасности и приватности. Рынок ИИ решений развивается стремительно, и сегодня стоит не только следить за новостями, но и переосмысливать базовые установки цифровой гигиены.
Хорошее видео по истории развития нейросетей с 1940х годов по наше время. Разобраны основные работы ученых которые толкали развитие искусственного интеллекта от первых моделей алгоритмов на транзисторах, до современных нелинейных решений, которые умеют различать объекты на фотографиях и суть слов в предложениях.
Хотел написать «текнолоджия», но нихуя, это вполне себе прям «технология».
PS: чтоб не показалось, что это реклама X5, то скажу, что в этом магазине (Самара, Водников 28/30) постоянно воняет мертвечиной, а обращения в поддержку не дали никакого результата.