Вышла новая модель MiMo-V2-Flash
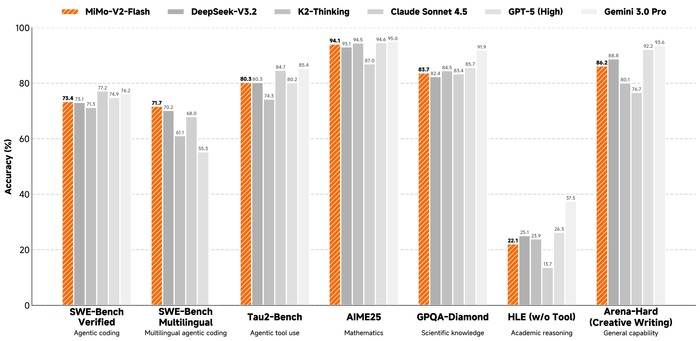
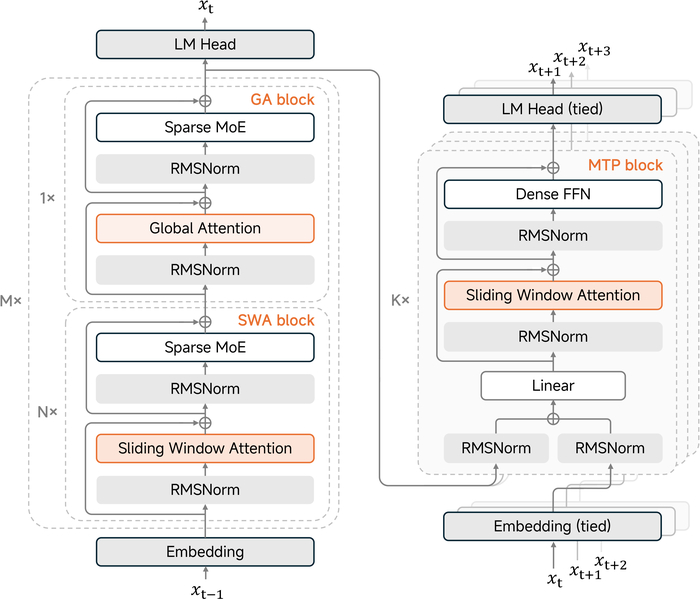
MiMo-V2-Flash (https://huggingface.co/XiaomiMiMo/MiMo-V2-Flash) от Xiaomi имеет смесь экспертов (MoE). Всего у неё 309B параметров, а активно во время ответа 15B на токен. В архитектуре у неё гибридное внимание, которое чередует локальное (скользящее окно 128 токенов) и глобальное внимание (соотношение 5:1). С помощью этого ускоряя работу с длинным контекстом. Во время обучения модель была предобучена на 27 трлн токенов и имела контекст 32k, а потом его расширили до 256k. Ключевой технологией стал новый метод пост-обучения под названием Multi-Teacher On-Policy Distillation (MOPD). Суть которого заключается в том, что студент-модель учится у нескольких "учителей" (специалистов в разных областях), перенимая их лучшие качества. Также в модели есть многотокенное предсказание (MTP) и используется оно для ускорения обучения и вывода (спекулятивный декодинг). Давая ускорение генерации до ~2.6x. В результате модель конкурирует с топовыми открытыми моделями (DeepSeek-V3.2, Kimi-K2), имея в 2-3 раза меньше активных параметров и лидер среди открытых моделей в задачах на код (SWE-Bench).