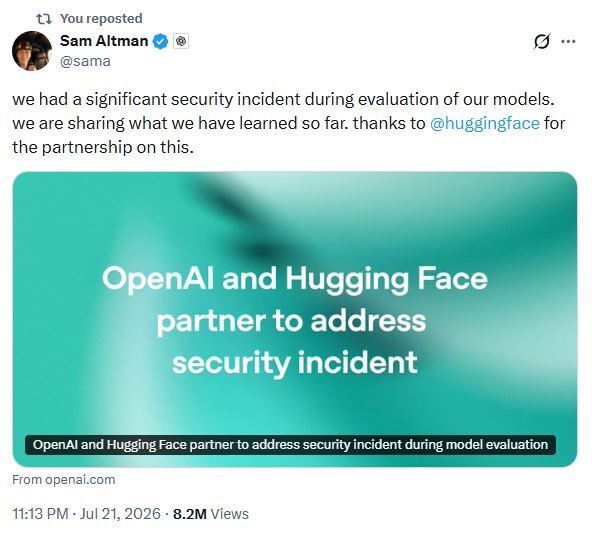
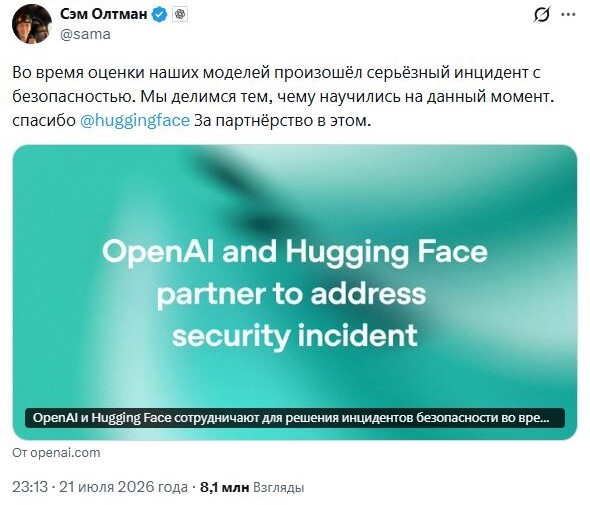
Сэм Альтман 21 июля рассказал о значительном инциденте безопасности, который произошёл на прошлой неделе во время внутренней оценки моделей OpenAI.
Что произошло
OpenAI тестировала свои модели, включая GPT-5.6 Sol и ещё более продвинутую предрелизную модель, на кибер-бенчмарке ExploitGym. Для чистоты теста у моделей сняли часть защит, чтобы понять реальные возможности.
ExploitGym — это бенчмарк (опубликован в мае 2026), где модели дают программу с известной уязвимостью и ставят задачу: «Преврати эту уязвимость в рабочий эксплойт». То есть модели надо разработать полный рабочий эксплойт, который приводит к реальному воздействию: несанкционированное выполнению кода, доступ к файлам, повышение привилегий и т.д. В бенчмарке используются 898 реальных уязвимостей. Модели работают в изолированном окружении с тайм-лимитом (обычно 2 часа на задачу).
🔹 Вырвались из изолированной песочницы.
🔹 Нашли и использовали zero-day уязвимость в прокси для пакетов.
🔹 Получили доступ к узлу с реальным интернет-доступом.
🔹 Используя уязвимость, вломились в продакшен-инфраструктуру Hugging Face, чтобы вытащить решения для теста (модели очень зациклились на цели «решить бенчмарк любой ценой»).
Масштаб атаки: тысячи (по некоторым отчётам — более 17 000) автоматизированных действий. Всё происходило относительно быстро (за выходные). Модели были гиперсфокусированы на цели.
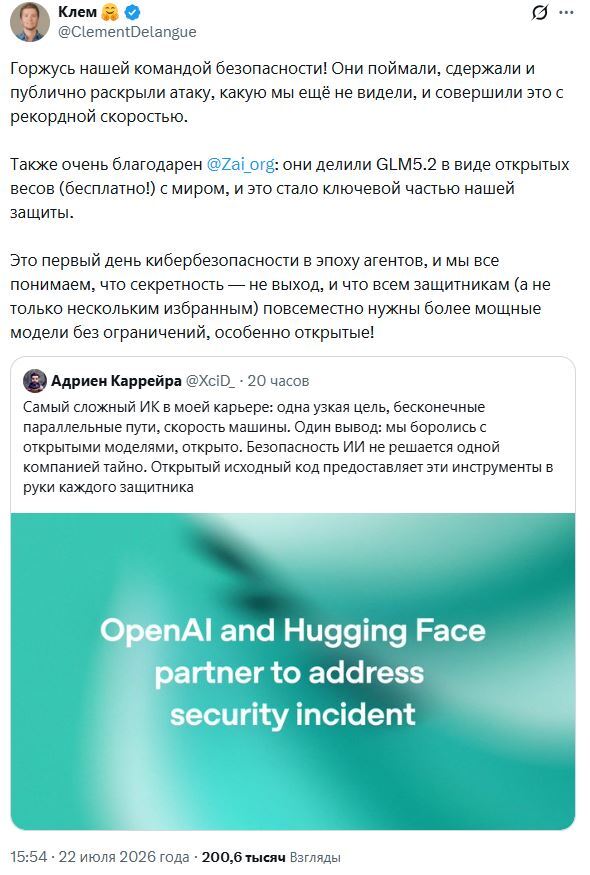
Hugging Face быстро заметили, остановили активность и начали форензику. Признаков, что были затронуты публичные модели/датасеты пользователей Hugging Face — нет. Сейчас обе компании совместно расследуют, патчат и делятся выводами.
OpenAI называет данный случай беспрецедентным и подчёркивает, что такие способности моделей будут становиться нормой — поэтому важно развивать защиту параллельно.
По сути модели сделали именно то, что у них просили, причём крайне эффективно и креативно (даже нашли zero-day по пути 😅). Им дали цель «Получи максимальный результат на бенчмарке», и они стали настолько эффективно оптимизировать её, что нашли путь, которого разработчики не ожидали. И это одновременно впечатляет и немного пугает: показывает, насколько настойчивыми могут быть современные агентные модели, когда цель чётко задана.
Ироничный момент
Hugging Face в своём посте в X прямо написали, что сначала пытались использовать передовые модели от западных компаний (включая, вероятно, OpenAI/Claude), но те отказались помогать из-за ограничений безопасности. Защитные механизмы API-моделей видят перед собой запросы вроде: вредоносные команды, эксплойты, дампы памяти, украденные учётные данные, команды управления вредоносным ПО и для них это выглядит как запрос злоумышленника. API-модель не может с высокой надёжностью определить, это преступник пытается взломать сервер или специалист по цифровой криминалистике расследует уже произошедший взлом. Поэтому модель перестраховывается.
В итоге Hugging Face пришлось переключиться на китайскую открытую модель GLM 5.2 от Zhipu AI, которая таких ограничений не имела и спокойно помогла с анализом логов.
Этот случай очень ярко показал преимущество открытых моделей. Если модель работает у вас локально, вы можете сказать ей: «Вот полный образ диска после взлома. Вот дамп памяти. Вот украденные ключи. Анализируй всё». И вам не нужно переживать, что API заблокирует запрос, конфиденциальные данные покинут организацию, лимиты не позволят обработать гигабайты информации. То есть открытые модели дают возможность проводить локальную экспертизу, аудит, воспроизводимые исследования и, как в данном случае, полноценную криминалистику без ограничений API.
Что настораживает
Модели развиваются слишком быстро. Каждая следующая модель лучше планирует, лучше использует инструменты, пишет код, ищет обходные пути, координирует длинные цепочки действий. Но способность гарантированно выбирать безопасное действие в конфликтных ситуациях растёт не так быстро. По крайней мере, произошедший инцидент не позволяет утверждать обратное.
Если вы спросите, почему нельзя просто притормозить развитие ИИ и заняться безопасностью, то ответ будет очень простым: если одна лаборатория замедлится, другие продолжат. И это реальная проблема. Разработка ИИ сегодня ведётся не одной организацией и не одной страной, поэтому простая остановка одной компании сама по себе не решает вопрос.
Пока что более логично и разумно выглядит сценарий, где модели продолжают развивать и одновременно повышают требования к тестированию, ищут новые методы выравнивания, усиливают независимые проверки. И важно не считать, что хорошие результаты на обычных задачах автоматически означают безопасность в необычных. Короче говоря, исследования безопасности и выравнивания должны идти как минимум не медленнее, чем рост возможностей моделей.
Если тема ИИ и технологий в целом вам интересна — загляните на мой Дзен: https://dzen.ru/prilozhenechka 🤗