Вы когда-нибудь задумывались, как опросники знают о вас столько деталей? Всё просто — они собирают данные из разных источников. Давайте разберём, откуда что берётся:
1. Вы сами всё рассказали
Регистрация в панели: возраст, пол, город, профессия — это базовая информация, которая формирует ваш профиль.
Анкеты-скрининги: вопросы вроде «Какими соцсетями пользуетесь?», «Есть ли дети?», «Как часто покупаете одежду?» — ваши ответы сохраняются и используются для подбора опросов.
2. Ваше поведение в опросах
Алгоритмы внимательно следят за тем, как вы участвуете:
Темы опросов: если вы часто участвуете в опросах про технологии, система запомнит ваш интерес. Вас будут чаще приглашать в такие исследования. Но иногда могут и не позвать — если, например, нужно собрать мнения новых людей, которые ещё не участвовали в похожих опросах.
Качество ответов: например, если вы пишете «ывлдаываыв» в открытых вопросах, система сделает пометку «некачественные ответы».
Скорость и активность: сколько времени вы тратите на ответы — это влияет на ваш «рейтинг активности».
3. Данные из соцсетей
Если вы регистрировались через VK, Yandex или другие платформы, опросник может получить:
ФИО, дату рождения, email, ID профиля.
Дополнительную информацию, которую вы указали в соцсетях.
4. Обогащение уже указанных данных
Опросники умеют «добывать» больше информации из того, что вы уже указали:
Дата рождения → возраст.
Почтовый индекс → регион, город, население города и даже район.
Как случайность помогает планировать проект, когда ничего не ясно
Это команда WEEEK — сервиса по управлению проектами. Нам нравится рассуждать о личной эффективности, планировании, а ещё о том, как не сойти с ума в попытках организовать жизнь. И мы знаем, как трудно бывает подступиться к своим планам.
Представь ситуацию: заказчик просит назвать срок релиза новой фичи. Команда новая, опыта совместной работы нет, объём задач до конца не понятен. Точный ответ дать сложно.
Вместо «посмотрим по ходу» можно использовать метод Монте-Карло. Он помогает получить вероятный результат и опереться на него в планировании. В этой статье разбираемся, что это за метод, зачем он нужен и как его применяют в проектах.
Что такое метод Монте-Карло
⚠️ Важно: метод Монте-Карло может быть очень сложным. Здесь — только базовая и упрощённая версия
Метод Монте-Карло — это способ решать задачи с помощью случайных чисел. Его придумали физики в середине XX века. Джон фон Нейман и Станислав Улам работали над задачами, связанными с ядерными реакциями. Было слишком много неизвестных, чтобы считать всё точно.
Станислав Улам позже вспоминал, что идея пришла ему в голову во время игры в пасьянс. Он задумался, как часто сходятся определённые комбинации, и понял: это можно считать через повторение и случай. Так метод стал инструментом для получения приближённых, но полезных результатов.
Если формула слишком сложная или точных данных нет, можно пойти другим путём: много раз подставить разные случайные значения и посмотреть, какие результаты встречаются чаще всего.
Смысл простой: мы заменяем сложные расчёты большим количеством попыток. Чем больше таких попыток, тем ближе результат к реальности.
Почему метод называется Монте-Карло
Название связано с казино в районе Монте-Карло в Монако. В азартных играх всегда есть шанс, но нет гарантии результата. Принцип похожий: каждый расчёт — это один случайный сценарий. В сумме они показывают, какие исходы встречаются чаще.
Есть и более личная версия: по словам фон Неймана, название прижилось из-за шутки про родственника Улама, который постоянно «срочно ехал в Монте-Карло».
Где применяют метод Монте-Карло
Метод используют во многих сферах, где есть неопределённость:
физика и инженерия
экономика и финансы
IT и разработка
бизнес и стартапы
логистика
маркетинг и реклама
Везде, где нужно принять решение без точных данных. В проектах метод помогает оценить риски и принять решение, даже если данных мало.
Вот примеры задач:
Сроки Какова вероятность закончить проект за два месяца?
Бюджет Хватит ли выделенных денег или лучше заложить запас?
Прибыль Какова вероятность, что проект окупится?
Метод не даёт точного ответа, но показывает вероятность. А этого часто достаточно, чтобы двигаться дальше. В общем виде метод отвечает на вопрос:
«Какова вероятность, что произойдёт нужное событие?»
Например: успеет ли команда закончить проект за 20 дней?
Пример: расчёт сроков проекта
Чтобы посчитать вероятность по методу Монте-Карло, нужны базовые знания и немного терпения. Сложных формул не потребуется, если задача не из ядерной физики.
Определи задачу — чётко сформулируй, что именно хочешь узнать и подходит ли тут Монте-Карло.
Подготовь данные — задай диапазоны значений или используй прошлые показатели.
Запусти моделирование — внеси данные в Excel, Python или другую программу и сгенерируй тысячи сценариев.
Проанализируй результат — собери данные и посмотри распределение вероятностей, обычно в виде графика.
Шаг 1. Формулируем задачу
Представь: нужно запустить онлайн-курс за 30 дней. Команда небольшая, часть подрядчиков новые, поэтому точные сроки по задачам никто назвать не может. Хочется понять, какова вероятность уложиться в месяц.
Проект состоит из четырёх этапов:
разработка программы курса
запись видео
монтаж и загрузка материалов
маркетинговый запуск
Каждый этап зависит от предыдущего, параллельно работать не получится.
Шаг 2. Задаём диапазоны значений
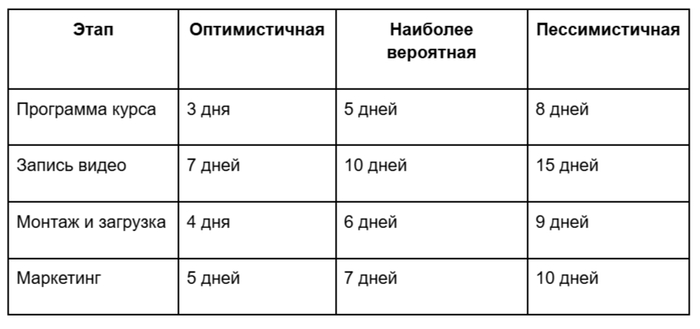
Для каждого этапа задаём три оценки: оптимистичную, наиболее вероятную и пессимистичную.
Эти значения станут основой для симуляций.
Шаг 3. Моделируем сценарии
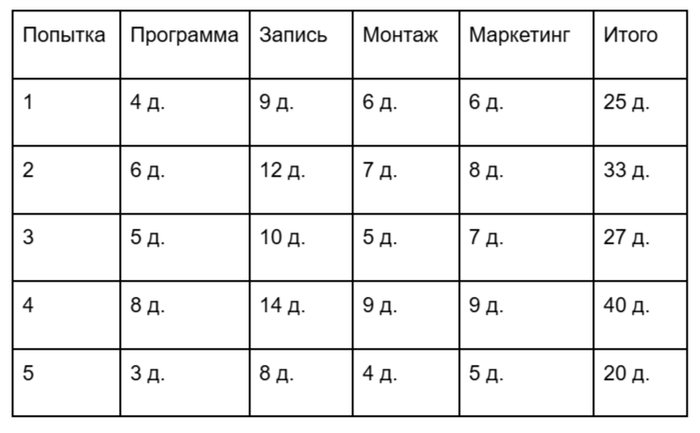
Программа 10 000 раз повторяет один и тот же процесс:
случайно выбирает длительность каждого этапа в заданном диапазоне
значения ближе к «наиболее вероятным» выпадают чаще
суммирует все этапы и получает общую длительность проекта
Примеры нескольких симуляций:
Шаг 4. Анализируем результат
После 10 000 прогонов получается распределение сроков.
Допустим:
симуляций, где проект уложился в 30 дней — 6 200
общее количество симуляций — 10 000
Вероятность = (6 200 / 10 000) × 100 % = 62 %
Это значит, что шанс запустить курс за месяц — около 62 %. При сроке в 35 дней вероятность вырастает почти до 90 %.
Дальше решение за тобой:
рискнуть и оставить дедлайн 30 дней
заложить буфер и сразу пообещать 35 дней, чтобы снизить давление на команду
Коротко о главном
Методом Монте-Карло пользуются, когда много неизвестных
Он показывает вероятность, а не точный ответ
В проектах помогает оценить сроки, бюджет и риски
Используют Excel, Python и специализированные программы
Чем больше расчётов, тем точнее результат
Итог лучше анализировать через графики
Больше про методы работы с проектами можешь прочитать здесь:
Есть ситуация, знакомая почти каждому аналитику. К тебе приходит бизнес и говорит:
Нам нужен отчёт Посмотри цифры Что-то у нас не так, разберись
И на этом - всё.
Нет метрик. Нет определения "не так". Нет ответа на вопрос зачем.
Обычно, на такие вопросы у аналитика есть ответы, если он погружен в предметную область, уже сталкивался с такими кейсами, занимался данной задачей недавно (иногда аналитики на разных проектах параллельно работают и эти проекты не связаны)
А пока подписывайся на мой канала Аналитика FM. Его я веду с нуля подписчиков. В этом канале я публикую информацию об инструментах аналитика (SQL, Python) О мышлении аналитика, о метриках, об ошибках. Публикую чек-листы по стандартным видам работы аналитика. Присоединяйся!
Бизнес редко приходит с чётким запросом. Не потому что он глупый или ленивый. А потому что бизнес живёт ощущениями, а не формулами.
Продажи "просели". Конверсия "стала хуже". Клиенты "ведут себя странно".
Это язык боли, а не требований.
И тут аналитик хочет обезопасить себя со всех сторон: - написать запрос - вытащить все данные - построить отчёт "на всякий случай" - показать цифры и сказать: "Вот"
Но в реальности это почти всегда заканчивается одинаково: - "А это не совсем то" - "А можно по-другому?" - "А мы вообще не это имели в виду"
Когда бизнес не знает, что ему нужно, аналитик не исполнитель, аналитик - переводчик.
Ты начинаешь переводить бизнесовые ощущения в конкретные показатели, и смотреть как эти показатели подтверждают/опровергают эти ощущения. Ты переводишь эмоции в конкретные метрики. Подсознательное ощущение "что-то не так", ты переводишь в конкретные вопросы к данным.
И вот на этом этапе SQL становится не просто инструментом, а следствием мышления.
Очень часто проблема не в том, что запрос неправильный. А в том, что вопроса не существовало.
Например:
"Продажи упали" - относительно чего?
"Конверсия плохая" - на каком этапе?
"Клиенты уходят" - кто именно и когда?
Пока бизнес не ответил хотя бы на это - любой запрос будет случайным. Или аналитик с приличным бэкграундом, задаст их сам себе, задаст эти вопросы данным и получит развернутый ответ, чтобы у бизнеса были аргументированные показатели.
И это самый важный навык аналитика. Аналитик не должен просто писать сложные JOIN-ы, он должен уметь задавать вопросы так, чтобы: - стало понятно, что именно ищем - появилось ощущение направления - сузилось пространство неопределенности.
И да - бывает, что бизнес так и не может сформулировать запрос.
Тогда аналитик делает не отчёт, а гипотезу.
Я предполагаю, что проблема может быть здесь. Давайте проверим это.
Это нормальная практика. Гораздо честнее, чем молча строить отчёт "на всякий случай".
Самое важное: если бизнес не знает, что ему нужно - это не ошибка бизнеса.
Это точка, где аналитика становится ценностью!
Ну а в моем канале Аналитика FM не только об инструментах аналитика, но и об аналитическом мышлении, метриках, логики.
5 лет назад (Карл!!!) я начал вести бортовой журнал удаленщика началось все с копирайтинга и различных мелких подработок на фл и привело это меня в ту точку, где я начал кодить. Кароче, что я наделал. Ты пишешь в чате -
Т0йоттаа Л3нд КрузеРР 2016 г., диз, 4.5
Мiтсуbишии Пaджeррo 2013 г., диз, 3.2
А бот, вместо того чтобы послать тебя, принимает тебя таким какой ты есть, и говорит какое масло тебе лить в этот двигатель
Ну как я сделал. ChatGPT сделал для меня сервис по подбору моторного масла и об этом я уже писал здесь
Это был текст в первую очередь про мои эмоции. А эмоции меня захлестнули не случайно: для меня это реально выглядело как чудо. Я просто писал в чат свою задачу и в ответ получал готовые файлы. Не советы, не рассуждения, не пример кода, а именно файлы и архивы. Ты загружаешь их на сервер и у тебя работает целый сервис. Это была сырая версия и вот прошло 3 месяца.
В чём была проблема первой версии. Подбор масла осуществлялся на логике самого ChatGPT. Он пытался определить, какое масло подходит автомобилю, опираясь на свои чертоги памяти. А как мы знаем, в таких случаях он любит пи… фантазировать. На его языке это называется уровень креативности (температура,). То есть сервис работал ху плохо, доверять ему на сто процентов было нельзя.
Зачем вообще нужен ChatGPT в подборе масла. Продолжая эти изыскания, я понял одну простую вещь: ChatGPT вообще не нужен для того, чтобы выбирать масло. Он нужен для нормализации запросов.
Пользователь пишет в чате любую ересь по типу:
вольольксваген Туарегс 2 литра бенз 2020 года
Тойта Ленд Крузре 2018 г., дизель, 4.5 л
джип гранд чероки lbptkm 3 kbnhf 1990 ujlf
Криво, с ошибками. И вот тут ChatGPT незаменим имхо, ибо он умеет нормализовать запросы. Из этого текстового хаоса он может вытащить марку, модель, год выпуска автомобиля. И делает это гораздо лучше любого жёсткого фильтра или формы.
Почему Visual Studio и Codex всё изменили. Дальше началось то, что я с трудом называю словом вайб-кодинг. Всё-таки кодинг это когда ты реально пишешь код хоть и с помощью ИИ. А у меня это скорее разовые акции. Я установил Visual Studio и подключил к ней плагин Codex от ЧатГПТ. И здесь произошёл переломный момент. Проблема общения с ChatGPT в обычном чате в том, что чат конечен. Он разрастается, тупит, забывает контекст, начинает путаться. А Visual Studio с Codex это уже рабочая среда. Проект с файлами, структурой, логикой. Codex видит все файлы, обновляет их, понимает взаимосвязи и не теряет контекст. Сейчас можно дорабатывать это проект просто путем передачи одного текстового файла, можно просто скинуть ему логи, он проанализируем и внесёт правки в скрипт.
Новая логика: база масел вместо фантазии. Я изменил логику сервиса и добавил базу соответствия масел, которую взял у производителей. Теперь всё работает так: пользователь пишет свой запрос, каким бы упоротым он ни был. Система его нормализует, приводит в человеческий вид и дальше начинает искать неточные соответствия в базе. Мы ищем конкретную модель автомобиля с конкретным двигателем. Объём, тип топлива, параметры двигателя. Часть полей пока не используется, но они уже есть в базе. Главное здесь больше нет угадывания. Поиск уже идёт по реальным данным производителя.
Почему для меня это выглядит как чудо. В итоге ChatGPT буквально создаёт плагин. Настоящий, готовый архив - загружаешь его на сайт через админку и он работает. Если это не будущее, то я не знаю, что тогда будущее. Да, есть момент с настройкой базы данных. Но честно это не выглядит чем-то запредельно сложным.
Что получилось в итоге. Вот мой сервис по подбору масла Сервис, в котором не написано ни строчки кода живым человеком.
Отсюда, кстати, и довольно упоротый дизайн. Система показывает, как именно она распознала ваш запрос, какие допуски масла ему соответствуют, и ищет максимально точное пересечение всех параметров. В итоге вы получаете список конкретных масел (и допуски), которые подходят именно вашему автомобилю (двигателю). Важно то, что допуски берутся из базы производителей масел. Это не фантазия ГПТ, а реальные данные.
Про логи, ошибки и самообучение. Все запросы пишутся в логи. Абсолютно все и то, что вы написали, и то, что система ответила. Есть отдельные логи под ошибки и нулевые запросы. Эти логи анализирует всё тот же ChatGPT. Он открывает тхт файл и смотрит, где ответ не соответствует запросу и я раз в неделю вношу правки: в нормализацию запросов, в работу с базой, в логику поиска. Дебаггинг этой балалайки происходит в полуавтоматическом режиме, просто на основе тхт логов. Я ему логи, он мне файлы.
Что будет дальше. Во-первых, та самая хваленая нормализация тоже работает кривовато, например запросы типа
Lada Vesta 2019, бензин, 1.6
ему не даются, тк в базе это VAZ и это нужно доработать
Во-вторых, база данных содержит гораздо больше полей, чем мы используем сейчас. Конкретные модели двигателей, цилиндры, клапаны и много чего ещё. Когда мы доведём текущую версию до стабильного состояния (когда нормализация будет близка к идеальной), я начну подключать эти поля. Я уверен, что через пару месяцев получится реально мощный сервис подбора масла: ты просто пишешь, какая у тебя машина, а система точно говорит, какие допуски тебе подходят и какие масла им соответствуют. И всё это на актуальных базах данных производителя.
Зачем я вообще всё это пишу. Когда я начинал бортовой журнал удаленщика, я думал, что буду чаще писать про удалённую работу, копирайтинг, эксперименты на фл. Но, честно говоря, я даже представить не мог, что через пару лет мы будем говорить о таком софте. Как бы вы ни относились к этому, это рабочий инструмент. Да, кривоватый. Да, местами тупит. Но в большинстве случаев, он таки дает верный ответ.
Наверное, основное, что я хочу сказать- пробуйте и вы, не только лишь все теперь могут быть программистами. Это действительно новая и полезная технология. Она позволяет решать задачи, которые раньше казались сложными и недоступными. Я никогда не учил программирование и не собирался начинать это делать в сорок лет. Да и теперь мне это и не нужно. Это во-первых весело и всяко полезнее чем тик ток.
Сейчас я даже балуюсь с простыми играми на Питоне, чисто по фану. Делать такое руками я бы никогда не стал, потому что это заняло бы у меня нереальное количество времени. Но сейчас - почему бы и да. Всем мир!
Привет! Хочу попросить совет и мб помощь. Не могу уже долго как найти работу. Да и на бывших работах не особо везло, попадала под сокращения.
Я закончила мед универ, специальность мед кибернетика (когда поступала, много чего обещали о специальности и тогда еще не было ИИ). Специальность полутехническая и полуклиническая. Варианты по ординатуре мне не понравились, так как у этой специальности выбор ограничен. Пошла работать в Минздрав, там было совсем не то, что обещали в универе: маленькие зарплаты и работа, на которой может работать человек, закончивший курсы в колледже, была далеко не та статистика, максимум, что считали, это было количество умерших и родившихся за неделю. Ну и проверяли на правильность кодирование посмертных диагнозов по МКБ. Параллельно работала на проекте по внедрению МИС. Мне было дико скучно на такой работе, все было очень убого, я решила, что надо уходить в ИТ в аналитику данных. Прошла курсы по python и sql, меня взяли на работу на завод бизнес аналитиком, и все бы ничего, была джуном, проработала там почти год, далее в компании пошли сокращения, выбрали меня и просто надавили, чтобы я сама ушла. Потом пол года я снова была без работы, было много отказов. И наконец устроилась продуктовым аналитиком в EdTech. Все было круто, но пришел другой руководитель, привел с собой синьоров и меня также попросили уйти. Я снова без работы, опускаются руки. Сейчас на hh уже откликаюсь на обычные вакансии менеджера не в ИТ вообще, или вакансии мед представителей, но приходят отказы и я не знаю почему.
Как будто бы, должно быть преимущество в MedTech, что у меня есть высшее мед образование, опыт работы в минздраве и аналитики, но кажется, что я никому не нужна. Знаю также базу машинного обучения и как проводить аб тесты, но на работе не использовала ни разу эти знания, надо снова повторить все это.
Но что делать? Уже появились мыслы снова поступить в мед и отучиться на лечебном деле, чтобы пойти в нормальную ординатуру, но, конечно, это все огромные деньги и очень много времени. Или может есть шанс найти работу за рубежом? Но слышала, что в США, например, тоде есть проблемы с трудоустройством, а именно, люди тоже по году не могут найти работу в ит (слышала про фронтенд конкретно). Кажется, что наци везде сломан.
Привет. Последние несколько лет я руковожу проектами онлайн-панелей — тех самых платформ, через которые проводятся тонны опросов, что вы, возможно, иногда встречаете в интернете.
«Как часто вы покупаете товар марки Х?», «Оцените новый дизайн упаковки». Моя работа — чтобы тысячи людей могли участвовать в опросах, а их ответы превращались в чистые, работающие данные.
Я запускал и масштабировал такие панели и в России, и на международных рынках. Теперь хочу рассказать, как всё устроено на самом деле.
Почему? Потому что между вашим честным мнением и красивым графиком в презентации аналитика — целая вселенная технологий, экономики и человеческой психологии. А статьи, которые есть в интернете, обычно описывают взгляд участника опроса и не раскрывают внутренней кухни.
О чём я буду писать в этом блоге:
Механика изнутри. Как на самом деле работает подбор респондентов. Почему кто-то получает 5 опросов в день, а другого не пригласят никогда. Почему после скрининга вас отсеивают, хотя, казалось бы, вы идеально подходите.
Экономика опроса. Откуда берутся деньги для участников опросов. Почему опросы платят по-разному (или не платят вовсе)? Как панели зарабатывают и как отличить честную платформу от мошеннической.
Война с ботами и невнимательными. Это целый детектив. Я покажу, какими способами мы отсеиваем некачественных респондентов: от скрининговых вопросов и анализа времени ответа до сложных статистических методов. Вы удивитесь, насколько это серьёзная гонка вооружений.
Культурные коды и «русская специфика». Почему нельзя просто взять российскую панель и скопировать её для другой страны. Разное отношение к деньгам, к приватности, к самому процессу опроса. Буду сравнивать и рассказывать, что работает у нас, а что — нет.
Лайфхаки для респондентов. Хотите чаще проходить опросы и получать больше вознаграждений? Я дам советы, основанные на логике системы, а не на домыслах. Как заполнять профиль, как внимательно читать скринеры и как не попасть в бан.
Данные и приватность: что на самом деле собирают панели? Куда попадают ваши ответы на профильные вопросы? Кто их видит и как они защищены? Разберём, где грань между необходимой для исследований информацией и излишней слежкой.
Этот блог — не реклама какой-либо панели. Я хочу развеять мифы, существующие среди участников опросов, показать сложность этой экосистемы и, возможно, помочь тем, кто по другую сторону экрана — заказчикам исследований, маркетологам и социологам.
Если вам когда-либо было интересно, почему опрос внезапно оборвался или как из миллионов мнений рождается точный прогноз — вам сюда.
Друг недавно пошёл купить планку памяти на 16 ГБ и вернулся с ощущением, что железо скоро будут продавать в ипотеку.
Он зацепился за простую мысль: оперативка есть везде — в компьютерах, телефонах, приставках, серверах. Если память дорожает, значит очень быстро подорожает всё остальное железо.
Для разработчиков это неприятный звоночек. На мобилках и десктопах подход «и так сойдёт, железо вывезет» будет работать хуже: более дешёвые устройства, больше экономии на начинке — значит, снова придётся думать про оптимизации, вес приложений, количество абстракций и то, что реально нужно тащить в рантайм.
На бэке привычное временное решение «завалим проблему железом» (которое по традиции становится постоянным) тоже перестаёт быть очевидным. Если память, GPU и виртуалки дорожают, то горизонт «давайте просто докинем ещё один инстанс» превращается в всё более дорогой вид спорта.
С другой стороны, на всё это сверху уже наезжает волна сервисов и приложений на LLM, сделанных без особых мыслей про ресурсы. Если виртуалки и GPU подорожают, LLM‑API, скорее всего, тоже станут дороже, а значит, экономика части проектов, построенных по принципу «шлём всё в большую модель и не паримся», может просто перестать сходиться.
Разработка в итоге снова превращается в честный анализ критериев: что считать локально, что кешировать, какую модель брать, что выкинуть, чтобы продукт вообще жил в плюс, а не работал в минус ради красивых демо.
Вопрос к читателям: если железо и облака ещё подорожают, вы скорее пойдёте в жёсткую оптимизацию всего или просто заложите рост себестоимости в цену продукта?
Если такие разборы интересны, в Telegram делюсь ещё и практикой: как считаю экономику своих фич и LLM‑штук на реальных проектах.
Сейчас у аналитика для работы с данными есть два популярных "инструмента" - это SQL и Python.
Часто слышу, что SQL считают "жестким", а Python - "гибким" инструментом в аналитике.
На самом деле разница не в гибкости между этими языками, а в "модели выполнения"
Ниже сравним один и тот же пример реализованный SQL и Python. И проследим, что выполняется на каждом шаге.
А пока подписывайся на мой канала Аналитика FM. Его я веду с нуля подписчиков. В этом канале я публикую информацию об инструментах аналитика (SQL, Python) О мышлении аналитика, о метриках, об ошибках. Публикую чек-листы по стандартным видам работы аналитика. Присоединяйся!
Рассмотрим задачу.
Есть таблица заказов. Нужно:
Взять только оплаченные заказы
Посчитать сумму заказов по пользователям
Оставить пользователей, у которых сумма больше 10 000
Отсортировать по убыванию суммы
Как это выглядит в SQL
SELECT
user_id,
SUM(amount) AS total_amount
FROM orders
WHERE status = 'paid'
GROUP BY user_id
HAVING SUM(amount) > 10000
ORDER BY total_amount DESC;
Что происходит на самом деле?
Хотя запрос написан сверху вниз, выполняется он иначе:
FROM — база берёт таблицу orders
WHERE — отфильтровывает только status = 'paid'
GROUP BY — группирует строки по user_id
SUM(amount) — считает сумму внутри каждой группы
HAVING — отбрасывает группы с суммой ≤ 10 000
SELECT — формирует финальные колонки
ORDER BY — сортирует результат
SQL не идёт шаг за шагом как сценарий. Для него каждый запрос - это единый слепок результата
Ты не "живешь" внутри процесса, ты его декларируешь.
Теперь тот же самый запрос в Python (pandas)
Чтобы не увеличивать объем строк с подключением к БД, сделаем так, что наши данные мы читаем из CSV файла
Ты загружаешь данные. Ты их уже видишь. Они лежат в память, у них есть текущее состояние.
result = filtered.sort_values('total_amount', ascending=False)
result
Ключевая разница
SQL
- нет "текущего состояния" - каждый запрос - это новый расчет - описываем, что хотим получить - оптимизатор решает как
Python
- данные живут в памяти - каждый шаг меняет состояние - на каждом шаге можно остановиться, посмотреть, вернуться, ветвить логику
На практике аналитик: - думает как в Python - реализует как в SQL - и постоянно переключается между этими моделями
Получается, что SQL и Python - это два разных способа мышления. SQL говорит нам - вот результат Python - вот процесс.
Python - это процедурный подход. Аналитик говорит КАК делать: - возьми данные - отфильтруй - посчитай - отсортируй - покажи результат Здесь происходить управление процессом: мы ведем данные по шагам
SQL - декларативный подход. Аналитик не говорит КАК делать, он говорит, что хочет получить.
В разбираемом примере мы говори:
Хочу видеть сумму заказов по пользователям, только оплаченные, только больше 10 000
Для SQL есть входные данные, правила отбора, финальный результат. SQL не живет во времени, он живет в описании результата
Ну а в моем канале Аналитика FMне только об инструментах аналитика, но и об аналитическом мышлении, метриках, логики.