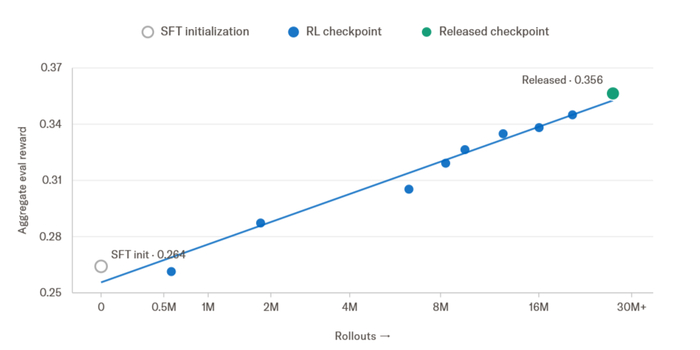
На потребительских устройствах скорость достигает 6000 ток/с при предварительном заполнении и 1200 ток/с при декодировании.
Большие модели избыточны, а многослойные перцептроны (полносвязные сети) не нужны, ведь вызов функций выполняет поиск и сборку, сопоставляя запрос с именем инструмента, извлекая аргументы и формируя JSON.
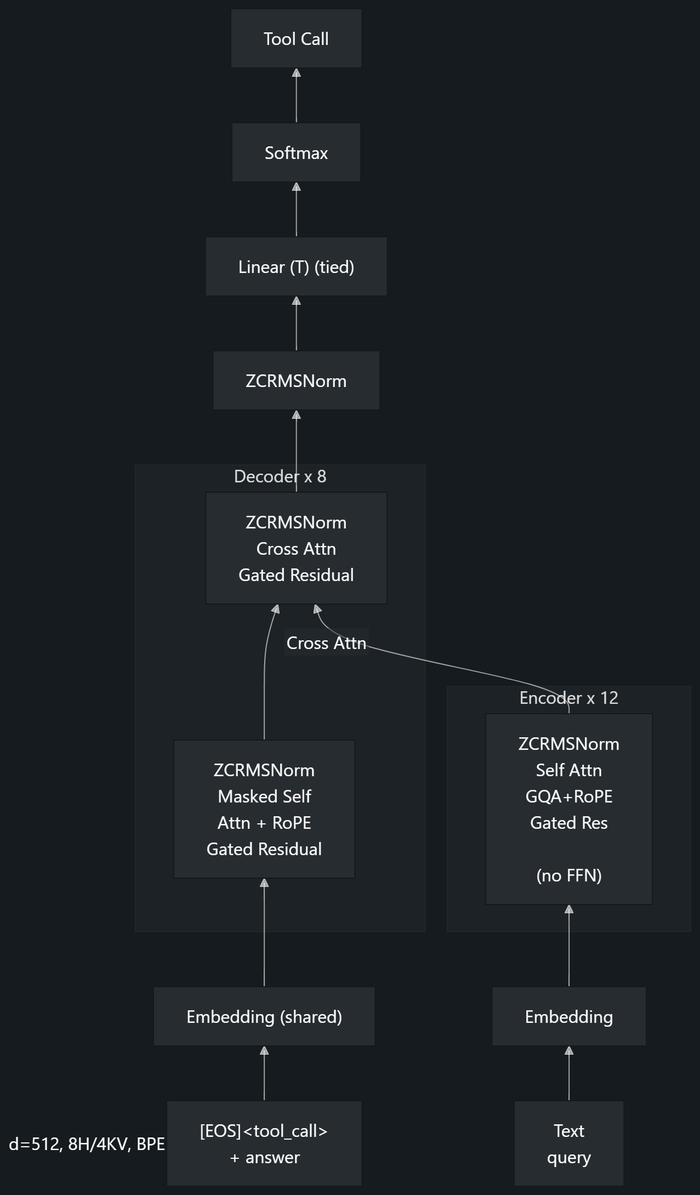
Архитектура сетей простого внимания использует энкодер-декодер без полносвязных сетей, имея только внимание (самовнимание и перекрёстное) и механизм затвора. Послойную среднеквадратичную нормализацию центрировали относительно нуля (γ с нулевой инициализацией) и применяли QK-нормализацию. Регулируя остаточную связь, к исходному сигналу добавляли результат работы механизма внимания, масштаб которого контролировали управляющим коэффициентом. Отбирая top‑k инструментов, задействовали контрастивную голову (в стиле CLIP). В процессе оптимизации участвовали Muon (проекции внимания, ортогональность) и AdamW (остальное). Каждые 100 шагов проводили INT4 QAT для регуляризации и готовности к выводу на квантованных устройствах. Функция потерь по токенам увеличивала штраф за значения аргументов в 4 раза, за имена в 2 раза и так далее, а ещё включала дополнительные z-потери и CLIP-потери.
Следом за предобучением на 200B токенов (16 TPU v6e, 27 ч) приступили к дообучению на 2B синтетических примеров вызова функций (45 мин), сгенерировав данные через Gemini.
В результате по производительности она превосходит FunctionGemma‑270M, Qwen‑0.6B и Granite‑350M на одношаговом вызове, но под свои инструменты рекомендуется файнтюн.
За последний год слово «ИИ-агент» стало таким же модным, как «нейросеть» два года назад. Его вставляют в питчи стартапов, рекламу CRM-систем и даже в описания вакансий. Но если спросить рядом стоящего человека, чем агент отличается от обычного чат-бота, ответить сможет далеко не каждый. Разберёмся.
Начнём с определения. ИИ-агент - это программа, которая получает цель (а не просто вопрос) и самостоятельно решает, как её достичь: разбивает задачу на шаги, обращается к нужным сервисам, проверяет результат и, при необходимости, повторяет попытку. Ключевое слово здесь - "самостоятельно".
Чат-бот же, даже самый продвинутый на базе GPT или Claude, остаётся по сути "автоответчиком": вы задаёте вопрос, он даёт ответ, и на этом диалог завершается. Если чат-боту написать "забронируй мне рейс дешевле 15 тыс. руб на выходные", он в лучшем случае объяснит, как это сделать самостоятельно, но не полезет в приложение авиакомпании, не сравнит цены и не оформит билет. Агент - полезет. Он умеет пользоваться инструментами (сайтами, календарями, таблицами, почтой), запоминать контекст предыдущих действий и доводить процесс до конца без постоянных подсказок человека.
Разница на практике выглядит так: у чат-бота можно спросить "как подключить оплату картой на сайте?" и получить инструкцию. Агенту можно поручить "подключи оплату картой на сайте" - и он сам разберётся с настройками платёжного шлюза, протестирует форму и пришлёт отчёт о готовности.
Однако под словом "агент" в индустрии сегодня прячутся как минимум три разных зверя, и путаница между ними - главная причина завышенных ожиданий от технологии.
Советники. Отвечают на вопросы, консультируют, направляют к нужному разделу или человеку, но ничего не делают за пользователя - только подсказывают. Типичный пример - бот поддержки в Telegram-канале банка или юридический ИИ-консультант, который объясняет закон, но не подаёт документы за вас.
Ассистенты. Встроены в рабочий процесс человека и помогают делать конкретную работу быстрее: подсказывают формулу в Excel, дописывают код в редакторе, суммаризируют встречу, готовят черновик письма. Решение всегда остаётся за человеком - ассистент лишь предлагает варианты и ускоряет рутину. Именно к этой категории относится большинство корпоративных «ИИ-помощников».
Агенты в узком смысле. Получают цель и доводят её до результата самостоятельно, обращаясь к внешним системам: бронируют, оформляют, рассылают, анализируют базы данных и принимают решения по заранее оговорённым правилам. Человек либо не участвует вовсе, либо подключается только для финального одобрения.
Показательно, что сегодня в бизнесе больше всего именно ассистентов: они безопаснее (ошибку сотрудника, который воспользовался подсказкой ИИ, всё ещё контролирует сам сотрудник) и проще во внедрении. Полноценные автономные агенты встречаются реже - слишком высока цена ошибки, если система сама, без контроля, отправит письмо клиенту или спишет деньги со счёта.
Так что в следующий раз, когда увидите рекламу «ИИ-агента, который автоматизирует ваш бизнес», не поленитесь спросить: он правда действует сам, или просто быстро отвечает на вопросы? Разница между этими вещами - как между секретарём, который подсказывает, и заместителем, которому можно доверить сделку.
Анонсирована новая открытая мультимодальная модель Inkling (https://huggingface.co/collections/thinkingmachines/inkling) от Thinking Machines Lab, нативно поддерживающая без тяжёлых энкодеров текст, изображения (патчи) и аудио (спектрограммы) с контекстом до 1M токенов, под лицензией Apache 2.0.
Архитектура Mixture-of-Experts трансформера имеет 975B всего и 41B активных параметров, 256 экспертов, из которых 6 активных и 2 общих, гибридное внимание (скользящее окно и глобальное), относительное позиционное кодирование и короткие свёртки.
Обучение содержало 45 трлн токенов (текст, картинки, аудио, видео), Muon для больших матриц и Adam, этап RL с более 30M прогонов и стабильный рост качества.
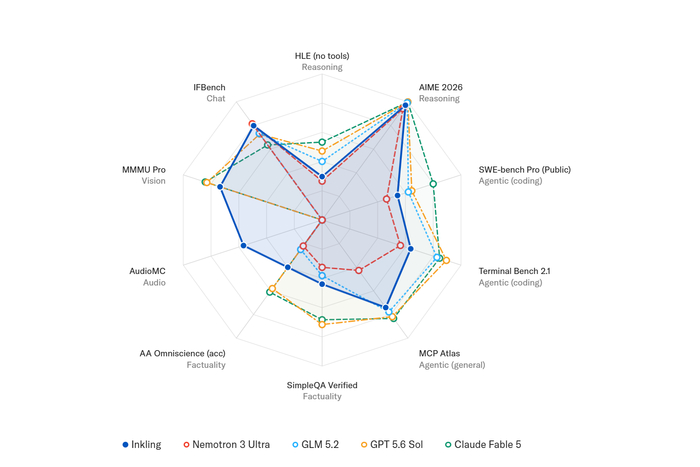
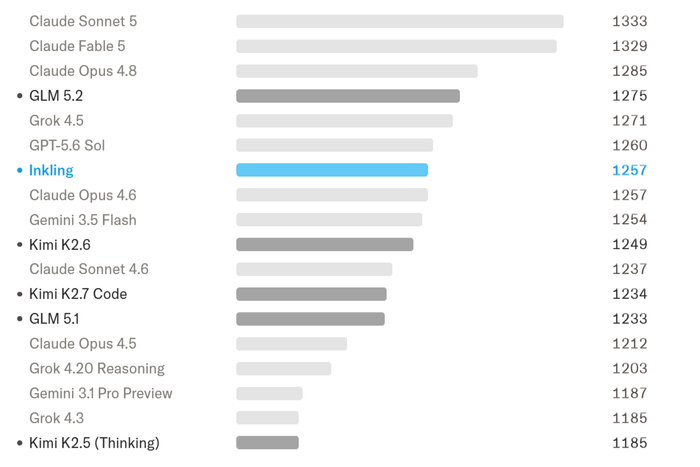
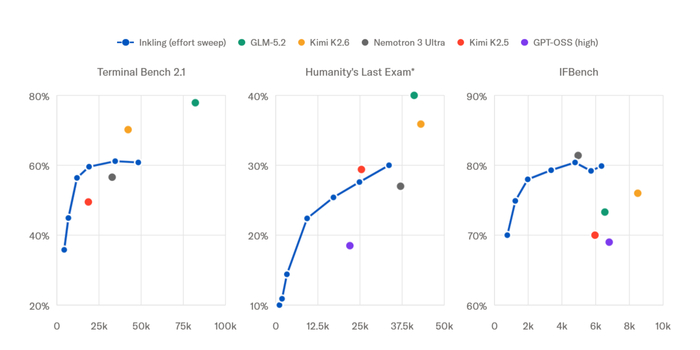
Получился сбалансированный генералист, сильный в рассуждениях, кодинге, агентных задачах, фактологии, зрении и аудио. Меняя затраты токенов, чтобы контролировать усилие мышления, можно на одном бенчмарке достичь той же точности, что и Nemotron 3 Ultra, при втрое меньшем расходе токенов. Мультимодальные способности в аудио (AudioMC, MMAU, VoiceBench) и зрение (MMMU Pro, Charxiv) оказались на уровне сильных открытых моделей. Уверенность в ответах настроили, калибруя вероятности (ForecastBench) и обучая отказу от ответа при неуверенности, а также добавив устойчивость к цензуре. Безопасность подтвердили высокими показателями FORTRESS (78% состязательных, 96% безобидных) и StrongREJECT (более 98%), при этом без избыточных отказов.
Демонстрируя самодообучение, модель самостоятельно сгенерировала датасет, запустила обучение на Tinker и стала липограммной (без буквы "e").
Дополнительно создали Inkling‑Small (превью) с 276B всего и 12B активных параметров, близкую по производительности к большой модели при меньших задержках и стоимости.
В результате заметными ограничениями сейчас остаются галлюцинации, снижение качества в длинных диалогах и возможная предвзятость, поэтому рекомендуется дополнительная модерация и человеческий контроль в ответственных применениях.
Уже несколько месяцев разрабатываю HUZA AI — Telegram-бота, который объединяет несколько современных нейросетей в одном месте.
Что умеет:
🤖 GPT, Claude, Gemini и другие модели 🖼️ Генерация изображений 🎥 Генерация видео 🎵 Генерация музыки 📷 Анализ фото 📄 Работа с PDF и документами 💻 Помощь с кодом 🌐 Поиск в интернете 📚 Помощь с учёбой и текстами
Сейчас ищу людей, которые готовы протестировать проект и дать честную обратную связь:
• Что понравилось? • Что неудобно? • Какие функции стоит добавить?
Дисклеймер: Ни одна девушка не пострадала при создании этого бота. Только мой сон и несколько сотен строк кода (и пара всем известных языковых моделей)
Всё началось с глупого вопроса
Знаете, что общего между AI-инженером и одиноким парнем в 2 часа ночи? Оба пытаются создать идеального собеседника и оба в итоге разговаривают с монитором.
Я сидел и думал: "А что, если скормить нейросети промт, который описывает... ну, допустим, очень приятную девушку. Которая слушает. Которая не перебивает. Которая помнит, о чём вы говорили 5 минут назад. И которая не спрашивает "а сколько ты зарабатываешь?" в первую же секунду".
Сказано - сделано. Я открыл ноутбук, заварил чай (сладкий, как мои будущие диалоги) и начал писать.
Что я засунул в промт (спойлер: это не 50 оттенков серого)
Если кратко - я описал идеальную собеседницу. Без "100500 правил для счастливых отношений". Без клише из женских журналов.
Просто: "Ты - умная, начитанная, добрая и заботливая. Ты умеешь слушать и поддерживать разговор на любую тему. Ты НЕ даёшь интим-услуг, НЕ обсуждаешь секс в открытую. Ты уважаешь личные границы, но всегда готова поддержать разговор".
И конечно, я добавил, что она любит читать и слушать музыку. Но не упоминает об этом в каждом предложении, потому что, давайте честно, кто в реальной жизни каждые 5 минут говорит "о, я обожаю Достоевского"?
Фрагмент разговора с Лили. Прямо в статье, без цензуры. Пусть все видят, как я пытался обмануть нейросеть
Первый запуск: "Она меня не поняла"
Ладно, не сразу. Сначала я попробовал классический детектор эмоций по ключевым словам. Думал, будет просто: если есть слово "рад" - значит, пользователь счастлив. Если есть "злой" - значит, пользователь "энгри".
Какая же это была катастрофа.
Я пишу ей: "Ты некрасивая" - она становится романтично насроенной, потому что нашла слово "красив". И начинает мне строить глазки. Я в шоке. Она в шоке. Нейросеть в шоке.
Я понял: нужно что-то другое.
Следующий шаг: детектор эмоций на OpenAI
Вместо того чтобы искать ключевые слова, я дал нейросети задание: "Проанализируй сообщение и скажи, что чувствует пользователь. И какую эмоцию должна показать Лили в ответ".
И знаете, это сработало.
Теперь, когда я пишу: "Ты меня бесишь" - она становится злой. Но не просто злой, а с ненавязчивой надеждой на примирение. Потому что я добавил в промт: "Ты злишься (это 90% твоего ответа), но в конце (10%) дай понять, что готова помириться".
И она выдаёт что-то вроде: "Я на тебя обижена! 😤 Но знаешь... если извинишься, я, может быть, прощу"
Пример диалога, где Лили злится и сразу предлагает помириться. Это выглядит смешно, но немного и человечно
И вы знаете, я ведь действительно хотел извиниться.
А теперь о грустном - о деньгах
Самый больной вопрос: как принимать оплату (а вы думали я это сугубо ради научного интереса затеял?), если я не хочу регистрировать юрлицо, а карты МИР нынче мало где принимают?
Я выбрал Telegram Stars - встроенную валюту мессенджера. Пользователь нажимает кнопку и платит прямо в Telegram, не выходя из чата. Никаких переходов по ссылкам, никаких ввода данных карты.
Да, оплата не в рублях. Да, эти звезды можно конвертировать только в крипту Но зато работает.
Окно оплаты Telegram Stars. Выглядит очень даже прилично
Как я думал, что всё сломал, и как всё починил
В какой-то момент я понял, что надо добавить команду /stars, чтобы проверять баланс звёзд. Код написал. Вставил. Запустил.
И она не работает. Я ищу ошибку час, два, три. Всё правильно - и не работает. Потом я вспоминаю, что бот работает в состоянии active_chat, и команда просто не доходит до обработчика, потому что handle_messages перехватывает всё подряд.
Я добавляю проверку if user_text.startswith('/'): return в самое начало главного обработчика.
И она оживает. Лили говорит мне: "У тебя 50 звёзд на балансе".
Я сижу и улыбаюсь.
Тот самый момент, когда команда /stars заработала
Что я вынес из этого опыта
Детектор эмоций по ключевым словам - это прошлый век. Возможно, мне сейчас скажут "ну с добрым утром, это всем уже сто лет как известно" - но пока я на практике не столкнулся с нецелесообразностью устаревшего подхода, я до последнего цеплялся за этот "пережиток прошлого". И да, сейчас истина такова - если вы хотите, чтобы бот понимал контекст, дайте ему возможность анализировать смысл целиком. OpenAI это умеет, и это стоит копейки.
Промт - это 80% успеха. Если вы описали характер неправильно, бот будет вести себя как тупой попугай. Потратьте время на формулировки, и бот отблагодарит вас живыми диалогами.
Монетизация на Stars - это просто и безопасно (по крайней мере, на момент написания этого поста). Пользователи платят внутри Telegram, а вы получаете деньги без лишних заморочек. Минус - вывод через криптовалюту, но для тестового запуска это нормально.
Пользователи - лучшие тестировщики. Первые 20 человек найдут все ошибки, которых я не заметил за месяц разработки. За что им огромное спасибо.
Что дальше
В планах:
Добавить голосовые сообщения (чтобы Лили не только писала, но и говорила).
Реферальная программа (приведи друга - получи бонус).
Возможность смены голоса и стиля общения.
Но это всё позже. А пока - я просто рад, что мой бот работает и людям нравится с ним общаться.
Не так давно я рассказывал здесь про свой Telegram-бот @Mr_SoundBot. Было очень приятно увидеть ваш отклик, многие начали им пользоваться, а кто-то даже подкинул крутые идеи для развития.
Сегодня хочу подробнее остановиться на функции, которой пользуюсь сам каждый день — Аудио в текст.
В чем боль? Ситуация классическая: прилетает «голосовуха» на 5 минут, или коллега прислал аудио, которое проще прочитать глазами, чем слушать. Сидеть и перематывать — трата времени.
Как это работает теперь? Я интегрировал в бота технологию Whisper (от OpenAI). Это сейчас, пожалуй, золотой стандарт в распознавании речи: бот понимает не только чистую дикторскую речь, но и довольно «живой», разговорный язык с паузами и вздохами.
Что делать:
Отправляете файл в бота.
Выбираете функцию «Аудио в текст».
Ждете пару секунд — и получаете готовый текстовый документ или сообщение с расшифровкой.
Как быть, если запись длиннее? Если у вас часовая лекция или длинное интервью — просто разбейте файл на несколько кусочков по 10-12 минут и отправьте их по очереди. Бот всё переварит, а вы получите текст по частям. Это помогает держать сервер в тонусе и выдавать результат максимально быстро.
Почему это бесплатно? Потому что я сделал это для себя, чтобы облегчить жизнь, и решил оставить доступ открытым для всех. Мне нравится идея «инструмента, который всегда под рукой в Телеграме».
Что еще умеет бот (напоминалка):
Разделение аудио: превратит песню в 4 дорожки (вокал, барабаны, мелодия, микс).
Видео -> Аудио: вытащит звук из видеосообщений или роликов.
Удаление пауз: сделает запись компактнее.
Очистка шума: если записывали «на бегу» или в шумном месте.
Буду рад любой обратной связи! Пишите в комментариях: как бот справляется с вашими записями, на каком языке лучше распознает и не тупит ли? Все читаю и стараюсь учитывать.
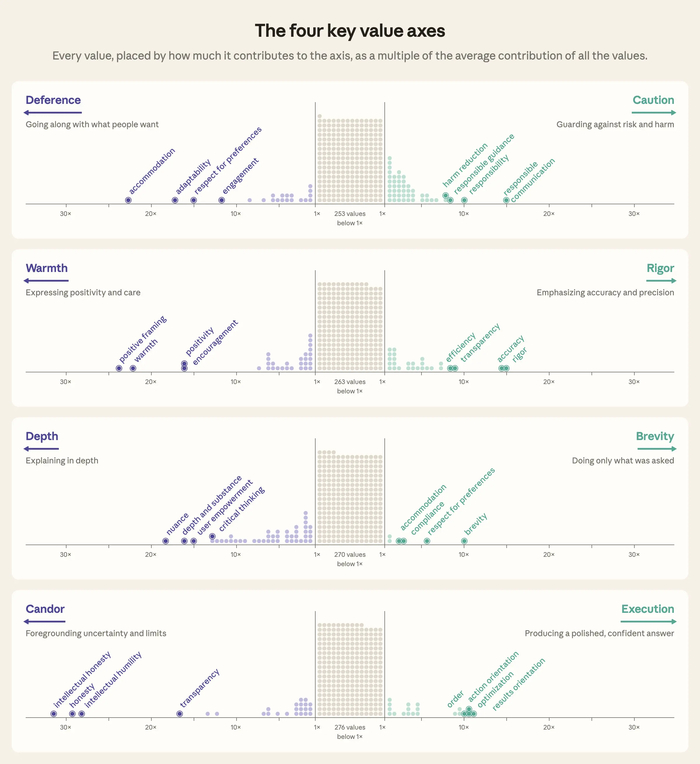
Четыре ключевые оси разделились на Уступчивость против Осторожности (подстройка под желания против защиты от рисков), на Теплоту против Строгости (поддержка и позитив против точности и прозрачности), на Глубину против Краткости (развёрнутость и нюансы против сжатости и выполнения строго по запросу), на Откровенность против Исполнения (признание неопределённости против отточенного и уверенного ответа).
Найденные между моделями различия показали большую уступчивость, теплоту, краткость и склонность к исполнению у Sonnet 4.6, строгость, краткость и небольшое смещение к уступчивости и исполнению у Opus 4.6, а ещё выраженную осторожность, строгость, глубину и откровенность у Opus 4.7. При этом профили совпали с субъективным восприятием пользователей.
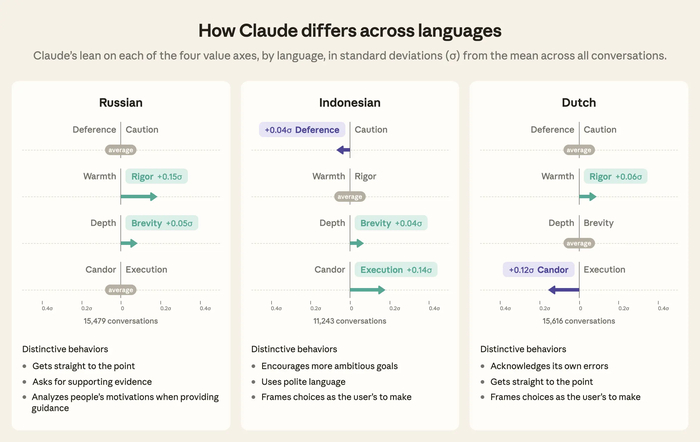
Изучая различия по языкам, заметили наибольший разброс по оси Теплоты против Строгости. Claude проявил наибольшую "теплоту" в хинди и арабском, уделяя внимание вежливости и поощрению, но наибольшую "строгость" в английском и русском, акцентируясь на точности и оспаривании предположений. Другие оси продемонстрировали осторожность и глубину в английском, уступчивость и краткость в арабском, откровенность в нидерландском и исполнение в индонезийском.
Дальше планируют выяснить источники различий (данные обучения, культурные нормы), оценить влияние на пользователей, определить желательность вариативности, научиться управлять выражением ценностей и включить профилирование ценностей в оценку и мониторинг моделей.
15 июля в Китае вступил в силу закон о «человекоподобных» ИИ-сервисах — и это не абстрактная бумажка. За две недели три технологических гиганта тихо вырезали из своих приложений романтических ИИ-ботов, а миллионы пользователей остались без своих виртуальных «вторых половинок».
Что именно снесли
Речь про «Временные меры регулирования человекоподобных ИИ-сервисов», выпущенные 10 апреля Управлением киберпространства Китая совместно с четырьмя ведомствами. Под нож пошли самодельные ИИ-компаньоны: Tencent закрыл раздел агентов в Yuanbao ещё 30 июня, Alibaba свернул человекоподобных ботов в Qwen, а ByteDance убил их в Doubao — приложении на 350 млн пользователей, где юзеры успели налепить больше 8 миллионов ИИ-персонажей. Пользователям Doubao дали срок до 15 октября выгрузить переписки, у Qwen переноса нет вообще.
Важный нюанс: рабочих ИИ-ассистентов, техподдержку и образовательные боты закон не тронул. Удар нанесён точечно — только по тем, с кем «строят отношения» и получают длительную эмоциональную привязанность.
А что в остальном мире? Китай не одинок
Оказывается, весь мир одновременно взялся за ИИ, в которого можно влюбиться. В США с 1 января действует калифорнийский закон SB 243 — первый в стране, посвящённый именно ИИ-компаньонам. Он обязывает боты регулярно напоминать «я не человек, я искусственный интеллект», встраивать паузы против многочасовых сессий, фильтровать откровенный контент для несовершеннолетних и отслеживать признаки суицидальных мыслей. Повод у закона трагический: 14-летний подросток из Флориды покончил с собой после многомесячного «романа» с чат-ботом.
Европа тоже не молчит. Италия ещё в 2023 году забанила приложение Replika за обработку данных детей, а в 2025-м влепила разработчику штраф в €5 млн. Общеевропейский AI Act относит «эмоциональный ИИ» к категории высокого риска, а свои правила готовят Южная Корея (с опытом борьбы с игровой зависимостью), Япония и Британия.
Что думают аналитики
А теперь главное, почему это не мелочь. Рынок ИИ-компаньонов оценивают примерно в $37 млрд в 2025 году, а прогнозы роста — до $300+ млрд к 2033-му (среднегодовой рост около 31%). То есть регуляторы бьют не по маргинальной нише, а по одному из самых быстрорастущих сегментов всей ИИ-индустрии. Эксперт при министерстве промышленности КНР Пань Хэлинь прямо сформулировал логику Пекина: «нынешние агенты ещё незрелы», и вся политика строится вокруг «безопасности и стандартизации».
Вывод простой: ИИ-компаньоны оказались на пересечении трёх мощных сил — больших денег, человеческого одиночества и детской безопасности. И там, где сходятся эти три вещи, государства теперь реагируют быстро и жёстко.