
Вышла новая модель Solar-Open-100B
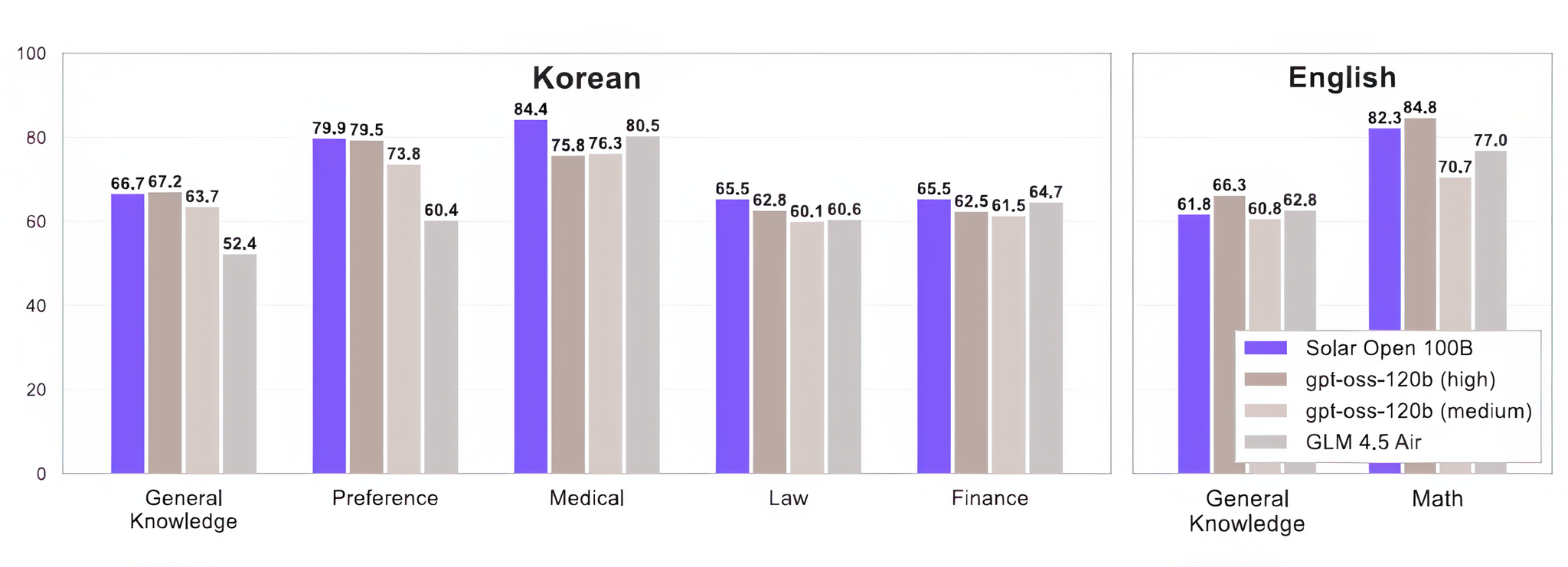
Двуязычная модель Solar Open (https://huggingface.co/upstage/Solar-Open-100B) для малопредставленных языков использует архитектуру Sparse Mixture-of-Experts (MoE) с общим числом параметров 102B и 12B активных параметров на токен, и у неё есть специальный токенизатор, оптимизированный для корейского языка.
Целью её разработки было создание конкурентоспособной языковой модели для языков с дефицитом данных (на примере корейского).
Во время создания модели была нехватка данных, и чтобы заполнить базу, было сгенерировано 4.5 трлн токенов синтетических данных высокого качества для пре-тренинга, SFT и RL. Управление данными осуществляли, применяя прогрессивную учебную программу для совместной оптимизации состава, качества и охвата доменов в англо-корейском корпусе (20 трлн токенов). Масштабируемое RL реализовали с использованием фреймворка SnapPO, который разделяет генерацию данных, вычисление вознаграждений и обучение, что позволяет эффективно обучать на множестве задач.
На первом этапе процесса обучения всё началось с пре-тренинга (19.7T токенов), где была поэтапная учебная программа с увеличением доли синтетических данных (до 64%) и ужесточением фильтрации качества. Затем был Mid-training (1.15T токенов), суть которого заключалась в улучшении логического мышления с помощью синтезированных "траекторий рассуждений". А к концу начался Post-training (SFT + RL). SFT использовался для следования инструкциям и базовых навыков. RL имел два этапа, и на первом он был направлен на улучшения рассуждений (STEM, код, агенты), а на втором он был применён для выравнивания с предпочтениями человека и безопасности.
В результате модель демонстрирует сильные результаты в корейских тестах (общие знания, финансы, право, медицина), превосходя или соответствуя аналогам, при этом сохраняя конкурентоспособную производительность на английском.