Хэллоу, друзья! Сегодня мы, команда Chad AI, расскажем, как технологии нейросетей упрощают сложное в E-commerce: предсказывают тренды, распознают визуальную информацию, персонализируют товары и даже поддержку клиентов.
Для начала немного освежим память.
В чём суть E-commerce: разбираем на пальцах
Если простыми словами, E-commerce — электронная коммерция. Такой вид бизнеса, в котором все процессы проходят через интернет. Кстати, переводы денег друг другу через банк тоже можно назвать E-commerce.
Кроме онлайн-оплаты, есть ещё одна особенность — возможность купить практически всё, без границ. Вы точно знакомы с такими маркетплейсами, как AliExpress, Taobao, Poizon, Amazon, Ebay.
Есть и более мелкие рыбы, у которых доставка только внутри страны. Они просто договариваются со службами доставки, чтобы организовать работу склада. Так у них остаётся бюджет на рекламу и развитие бизнеса.
В какие аспекты уже внедрили ИИ — главное
Пользовательская поддержка
Почти на каждом сайте есть чаты со специалистами. Как минимум, на первые вопросы в чате вам точно будет отвечать бот на базе ИИ. Он экономит деньги компании и по сути становится виртуальным кол-центром. Но и сами пользователи теперь могут рассчитывать на быстрый ответ, даже в два часа ночи.
Конечно, бот решит не все вопросы, и иногда нужен человек. Но нейросеть можно быстро обучить, так что со временем она будет справляться и с более сложными запросами.
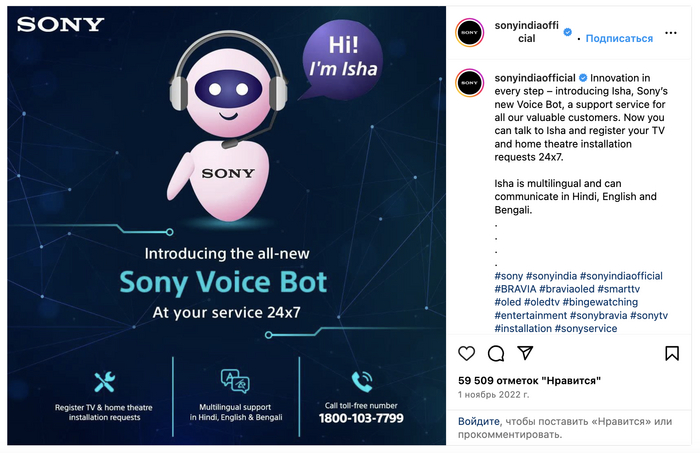
Например, Sony вывела свой сервис на рынок Индии. Голосовой ассистент Isha сильно упростил процесс, потому что говорит на разных языках.
Прогнозирование
Суть в том, что машины анализируют данные по динамике цен, транзакций, пользовательского поведения и другой статистике. Так, с помощью ИИ можно точно понять, что хочет получить потенциальный клиент. Но что ещё круче — распознать паттерны шопинга в истории покупок, спрогнозировать тренды рынка, спрос на продукцию и динамику формирования цен.
С этими данными компания может выпускать топ-товары с запасом, да и в целом строить весь маркетинг и ценообразование.
Вы ещё не устали читать? Если задушнили — вот вам сочный пример. Компания DHL, которая осуществляет перевозки, начала сотрудничать с IBM. Это такие ребята, которые занимаются разработкой программного обеспечения и вот этими всеми IT-штуками.
Так вот, в 2017 году их прогностическая модель ИИ предсказала бум спроса на спиннеры. В своём исследовании нейросеть опиралась на динамику поисковых запросов и просмотров вирусных видео. Получается, каждый наш просмотр смешного трендового видосика может кому-то увеличивать продажи? Получается, что так :)
Распознавание визуальной информации
Сейчас все поймут, о чём мы говорим. Ведь в повседневном онлайн-шоппинге эта функция используется постоянно. А именно — компьютерное зрение.
Оно полностью изменило паттерн поиска товара в сети. Теперь мы ничего не гуглим, а просто наводим камеру телефона на фото товара или сразу на товар на витрине. А искусственный интеллект находит для нас этот продукт и его аналоги за секунды.
Поиск по фото в приложении AliExpress
Такая функция есть на Wildberries или AliExpress в строке поиска. Но другие компании на этом не останавливаются и делают что-то вроде синергии между компьютерным зрением и дополненной реальностью. Так мы выходим на новую ступень шоппинга — возможность визуализировать мебель и предметы домашнего декора в своём доме, не вставая с дивана, как у Ikea.
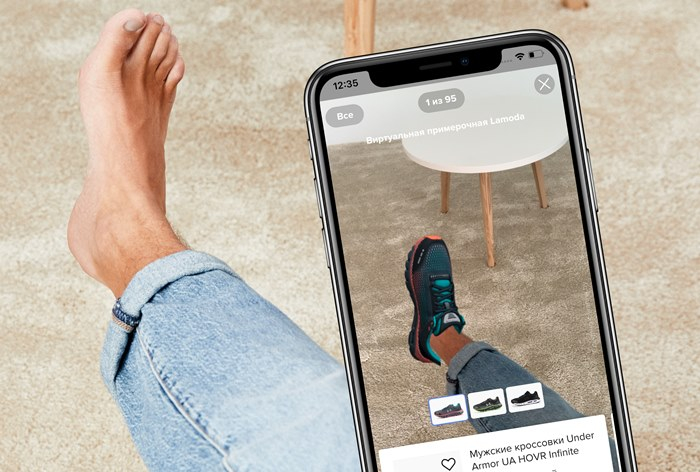
Ну или примерять кроссовки мечты, пока лежишь дома на диване, вместе с нашей Lamoda.
Дополненная реальность в приложении Lamoda
Дополненная реальность в приложении Ikea
Генерация контента И мы потихоньку дошли до той самой вишенки на торте — создания текстового, визуального, аудио- и видеоконтента. Сейчас любой человек может что-то сгенерить, например в Chad AI, чтобы упростить работу по ведению блога бренда в соцсетях.
Так, Nutella в 2017 году захотела упаковку поярче. С помощью нейросетки бренд создал 7 млн версий графического стиля Nutella и раскрасил им свои банки.
В Heinz пошли ещё дальше: в 2022 году запустили рекламную кампанию с изображениями бренда, которые полностью сгенерили ИИ. Да, идеальными картинки не назвать, но в этом и шарм.
Что будет дальше
Человек вряд ли может предсказывать будущее, поэтому мы решили спросить у Чадика, обладает ли он такой магической силой. Ответ заставил задуматься. Вот что мы выяснили.
Во-первых, роботизация складов и доставки. Уже сейчас на складах интернет-ритейлеров, таких как Amazon, работают тысячи роботов. В будущем ИИ возьмёт на себя ещё больше функций в управлении складской логистикой.
Во-вторых, создание виртуальных аватаров. Возможно, скоро мы все переведём себя в «цифру», когда будем создавать своего аватара на сайте бренда. Делать его похожим на себя, выбирать и примерять одежду вместе с ИИ-ассистентом.
Если вы не знаете популярные языковые модели, чем они отличаются друг от друга, и какую лучше применить для своих целей, то вам возможно будет интересно ознакомиться с моими статьями:
В интерфейсе Perplexity Labsпредставлены 18 генеративных моделей, включая Claude 3, Mixtral, Llava и Gemma. Даже нейросеть от Meta про которую так много говорили всю эту неделю - LLaMa 3, ее тоже можно использовать в этом же интерфейсе.
Что особенно приятно, что все эти модели доступны бесплатно и без VPN. Сайт к тому же прекрасно открывается с телефона.
Можно бесшовно в одном месте пообщаться с разными моделями чат-ботов, сравнить ответы, не суетясь и не создавая вкладок, классно. Можно использовать телефон,просто выберите нейросеть из списка и напишите свой запрос.
Хотите узнавать первыми о полезных сервисах с искусственным интеллектом для работы, учебы и облегчения жизни? В своем телеграм канале НейроProfit я рассказываю, как можно использовать нейросети для бизнеса
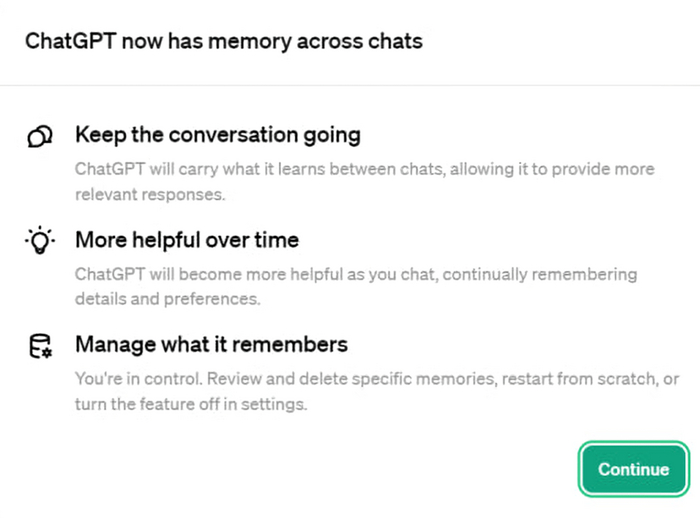
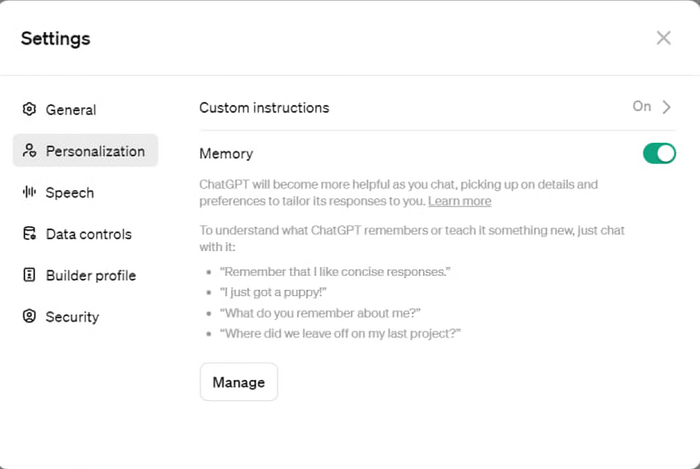
💬 Теперь ChatGPT будет запоминать ваши запросы и манеру общения между несколькими чатами, чтобы давать более персонализированные и релевантные ответы.
💱 Вообщем компания решила видоизменить секцию Custom Instructions, сделав ее автоматической. То есть теперь вам не нужно прописывать чем вы занимаетесь, каков ваш род деятельности, каковы ваши предпочтения и так далее - система будет это делать в автоматическом режиме.
❌ Eсли вы вдруг захотите выключить данную функцию — в настройках в разделе Personalization на против Custom Instructions и Memory поставьте — Off.
Сначала ты носишь свой код в коробках и борешься с коллегами за возможность сесть за клавиатуру (одну на всех), а потом ты просто говоришь машине, что делать. Или всё не так просто? Если присмотреться, то так ли много изменилось? Меняют ли что-то сегодня нейросети в работе, например, джуна или синьора?
Эта статья состоит из трех частей. Первая и вторая написаны по воспоминаниям программистов из Швеции и СССР: Марианны Эрнерфельд и Владимира Николаевича Орлова. И третья — из опыта работы с нейросетями.
Первые коды для дейтинга и железной дороги
Интервью с Марианной Эрнерфельд было опубликовано в июле 2019 в блоге ее сына. Оно более полное, особенно версия на шведском языке.
Девушка решила стать программистом в 1965 году. Тогда не было ни одного университета, обучающего программированию, но существовал годовой курс в Сольне (коммунна в Швеции), и на него могли выдать студенческий займ.
В то же время SJ (шведская государственная железнодорожная компания, на то время монополист) рекламировала годовую программу стажёрства, на которой можно было учиться работе в разных отделах компании. У SJ был компьютерный отдел, поэтому Марианна подала заявление и в эту программу, надеясь оказаться в нем.
На каждое место было по 14 кандидатов, а компания не хотела нанимать соискателей женского пола, но у Марианны (и нескольких других женщин) получилось успешно пройти все тесты.
Во время обучения студенты обучались всему: от поездов и путей и до того, как работали электрические и телефонные линии. В 1969 году SJ начинает программу внутреннего обучения программированию, и Марианна попадает в нее.
Компьютерный отдел SJ состоял примерно из 40 программистов и системных инженеров. Больше никаким другим образом научиться программированию в Швеции было нельзя — совершенно новая профессия. Некоторые из программистов раньше были машинистами локомотивов, и у большинства даже не было аттестатов о полном среднем образовании.
Обучение началось с объяснения, что такое компьютеры. Затем они прошли курсы в IBM, у которой в огромном здании в Стокгольме находилась «машина для обучения».
Одновременно на одном курсе было примерно 50-100 человек, но нас разделили, так что в каждом кабинете присутствовало по 8 студентов. Там мы смотрели на телеэкраны в передней части класса. Преподаватель и его доска транслировались на экраны из другого кабинета. У каждого преподавателя было примерно по 10 кабинетов со студентами, и каждый кабинет мог задавать вопросы при помощи микрофона, обращая на себя внимание нажатием кнопки. Это было сверхсовременно!
Сначала студенты узнали об IBM OS, а затем изучили собственный язык программирования IBM под названием PL/I. Это была более современная версия Кобола, обладавшая возможностями, которых у Кобола пока не было (но они появятся позже), например, создание таблиц и запросов.
После первого курса IBM Марианна вернулась в SJ для выполнения своих первых практических программ. Она и трое обучающихся создали программу для дейтинга — оператор вводит данные мужчин и женщин, их черты, а затем генерирует пары между ними при помощи изобретённого алгоритма. Позже программистка прошла ещё несколько курсов, например, изучала ассемблер (язык программирования).
Как же тогда кодили? Сначала рисовали блок-схемы, а затем писали карандашом код. Его передавали в отдел перфорирования, где код вбивали в перфокарты. Перфокарты состояли из 80 столбцов (72 под программу и 8 для последовательности), поэтому строка кода не могла содержать больше 72 символов.
Программисты должны были писать код чётко, чтобы работавшие на перфораторе женщины могли его читать. Спустя несколько лет работы в SJ им выделили человека для чтения кода. В остальном они по большей мере перфорировали карты данных: отчёты об отработанных часах в SJ, пробег каждого железнодорожного вагона (чтобы их можно было отправлять на обслуживание). Перфоратор выглядел как обычная печатная машинка, пробивающая отверстия с картах. Кроме того, над каждым столбцом она печатала обычным текстом букву.
«А ещё мы носили на перфокартах пирожные, так что они были довольно удобны»
Когда Марианна только начинала работу, программы были маленькими, но позже каждая могла занимать несколько коробок длиной по метру. Одна строка кода превращалась в одну перфокарту. Отдел перфорирования возвращал готовую программу (тысячи карт). Кроме того, приходилось создавать «контрольные карты», в которых кодировалось: должны ли перфокарты компилироваться или исполняться, на каком языке они были написаны и т.д. Контрольные карты имели собственный цвет. Первая карта была рабочей картой с именем на ней, чтобы отдел знал, кому их возвращать.
Еще карты возвращались вместе с «пижамной бумагой», содержащей списки кодов ошибок и номеров строк. У сотрудников был доступ к паре дыроколов, они могли вносить небольшие изменения самостоятельно.
Пижамная бумага с ошибками
Затем создавали тестовые файлы и смотрели, даёт ли программа ожидаемый результат. Если нет, то начинали «настольное тестирование» (с карандашом и бумагой), пытаясь разобраться, в чём ошибка. Для создания правильной программы требовалось много времени.
В машинном зале было примерно 10 операторов машин. Все они носили белые халаты, работали с ленточными накопителями, дисками и вставляли перфокарты. На входе висела табличка «Магазин закрыт», а программистам редко разрешалось посещать огромный машинный зал. Первые машины (IBM 1400) занимали 10-20 квадратных метров, а более новые были размером с холодильник.
Изначально у железнодорожной компании имелась IBM 360, а также более старые машины. Позже они получили IBM 370.
Ближе к концу 70-х появились терминалы. Все работали в общем зале с терминалами. Когда нужно было внести изменения в программу, приходилось сражаться за терминальное время. В компании пользовались жёлто-коричневыми терминалами Alfaskop. До самого увольнения из SJ в 1979 году у Марианны не было персонального терминала.
Alfaskop
Системные инженеры в основном работали со спецификациями, входными и выходными данными программ. Программисты были решателями задач, рисовали блок-схемы и думали, как выполнять задачи.
Какие коды писали? Например, онлайн-бронирование SG, работавшее 24/7. Это было современно по тем временам, а система целиком была написана на ассемблере. Благодаря этому SJ выделялась — ни одна другая компания в Швеции к этому и близко не стояла. Программисты создавали коды, а после завершения и тестирования отдавали их другим отделам. Их поддержкой занимались другие, отдел Марианны только писал новые.
В блоге Владимира Николаевича Орлова есть порядка 7 частей (и несколько отступлений) его автобиографичного рассказа о советском программировании. Дальше наш пересказ одного отрывка.
В 1976 году Владимир служил в Латвийском военном городе Вентспилс-8. Он был в числе первых, кто прошёл полный курс обучения по специальности «военный инженер-программист». Подготовка специалистов по ЭВМ и программированию велась с 1956 года.
Учились тогда прикладному программированию. Из студентов готовили IT-специалистов широкого профиля со знанием теории построения операционных систем, систем программирования, информационно-поисковых систем.
Обучение программированию начиналось с посещения машинного зала ЭВМ М-220.
За пультом ЭВМ М-220 старший лейтенант.
В те годы неотъемлемым атрибутом любого машинного зала (а для размещения ЭВМ М-220 требовалось не менее 100 квадратных метра) было присутствие в нем на стене портрета Джоконды (вспомните кинофильм «Служебный роман»):
Тогда Владимиру и другим обучающимся показали, как рождается портрет. В устройство для чтения перфокарт поставили колоду перфокарт, набрали команду на пульте управления ЭВМ и на АЦПУ стал появляться портрет Джоконды.
«Я окончательно понял, что поступил правильно, выбрав специальность программиста, а ЭВМ М-220 на ближайшие 7 лет стала моей рабочей лошадкой»
Это не означает, что Орлов не работал на других ЭВМ : к концу обучения в академии он был «на ты» с М-220, Минск-32, ЭВМ «Весна», СПЭМ-80, а также имел навыки работы на ЕС ЭВМ. Но главной машиной до 1979 года в Советском Союзе оставалась ЭВМ М-220.
Как тогда кодили? Программирование на М-220 серьёзно отличается от сегодняшнего программирования. Нужно обязательно знать машинные команды. Хотя бы те, которые позволяли загрузить программу с перфокарт, магнитных ленты и барабана в память машины и передать ей управление, чтобы она начала выполняться.
После Вентспилса я на всю жизнь запомнил команды ЭВМ М-220 для работы с внешними устройствами – 50 и 70. Все программы, которые я в итоге напишу в Вентспилсе, будут написаны в машинных кодах, никаких языков высокого уровня или даже автокода.
Одним из рабочих заданий была автоматизация кассы взаимопомощи.
Сначала информация по новым членам кассы взаимопомощи записывалась на бумажные бланки. С бланков данные набивались на перфокарты. Затем перфокарты вручную сортировались. Запускалась небольшая программа, которая данные с перфокарт записывала на магнитную ленту. После всего этого начинался процесс добавления новых членов в базу данных кассы взаимопомощи.
Для этого в лентопротяжки ставились три бобины, одна с новыми данными, вторая с данными, подготовленными ранее или текущей базой данных, и чистая, на которую переносилась информация, получаемая слиянием.
Неочевидное обучение программированию
Спустя 55 лет развития сферы программирования писать код можно даже не своими пальцами. Не работать на громоздких и медленных машинах, не запоминать команды. Можно и читерить: искусственный интеллект уже хорошо справляется со многими задачами. Вот модель GPT 4 — стандарт по умолчанию для создания контента, анализа, машинного перевода и, конечно, для решения задач.
GPT 4 можно использовать и для обучения программированию. Скормите чату условие своей задачки, а на выходе будет код программы на требуемом языке, часто еще и с объяснениями основных моментов в коде. Так можно создать себе персонального учителя.
Как можно использовать нейронку? Например, отправить в чат фрагмент или готовый код программы и промпт к нему:
расскажи, какую задачу решает код
объясни код по строкам
добавь комментарии в код
найди в коде синтаксические ошибки
найди в коде логические ошибки
оптимизируй код (уменьши расход памяти или ускорь выполнение)
уменьши сложность алгоритма
Не всегда, правда, код без глюков, а решения полные :( Главная проблема ИИ типа ChatGPT в том, что многие считают их универсальными. Из-за этого нередко либо результат не устраивает (завышенные ожидания), либо понимаешь, что проще и быстрее сделать самому.Чтобы апгрейднуть результат и сэкономить время, достаточно сделать очевидное: для каждой задачи использовать профильную нейронку.
В рамках API ограничения по получению ответа у GPT-4 составляет 4096 токенов, а у Claude 3 Opus около 128к токенов, в связи с этим и ответ получаемый от Claude 3 Opus будет больше. Плюс модели Claude 3 показывают себя более вдумчивыми.
Так мы справились с громоздкой задачей по программированию, сохранив себе пару часов для отдыха или другой задачи. Возьмем за пример задание из типовых курсов по программированию: написать мобильное приложение для сети клиник.
Возьмем эту задачу и декомпозируем ее. Разбить на более легкие шаги — это заведомо хорошая стратегия, чтобы нейронка не разваливалась и не отвлекалась.
У нас вышли такие шаги:
Составь функциональные требования, основанные на следующем описании: [полное описание из задания].
Теперь распиши полученные функциональные требования в виде User stories.
На основе полученных данных (Функциональных требований и user stories) составь сущности и атрибуты к ним с выделением первичных ключей.
Теперь на основе полученной информации составь plantUML.
Теперь составь BPMN TO-BE в виде кода.
Теперь составь полную спецификацию требований к этому ПО.
Теперь распиши каждый пункт спецификации подробнее, мне нужна готовая заполненная спецификация.
Составь документацию API с описанием всех методов системы на базе swagger.
И на все у Opus был ответ. Теперь проверим, исправим баги, если они есть — и готово! Конечно, не все так легко, как здесь читается, но работа над этими 8 пунктами своими руками была бы дольше в много-много раз.
🧑💻Листая ленту с новостями нашел такую интересную, а самое главное понятную градацию современных нейросетей. Обратите внимание, что самые "качественные" нейросети являются самыми медленными, давайте разбираться почему же это так.
⚡️Я приоткрою завесу тайн и скажу, что на самом деле любые нейросети могут генерировать ответ на любой ваш промпт практически мгновенно. Компании с огромным количеством пользователей намерено занижают скорость вывода ответа - для того, чтобы снизить нагрузку на их сервера.
💵И как мы видим по графику цен - в большинстве своем люди предпочитают получать более качественные ответы пусть и за большее время генерации.
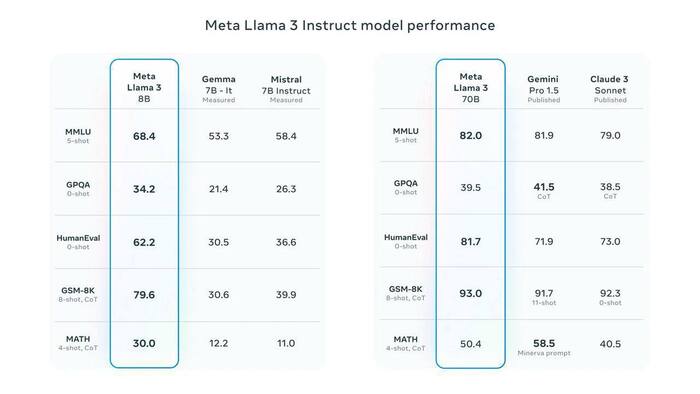
Компания Meta AI показала новое поколение больших языковых моделей с открытым кодомLlama 3 с параметрами 8B и 70B. По сравнению с предыдущими моделями, у новых улучшенная производительность и способность к рассуждению, а так же они лучше себя проявили в кодинге. Анонсировано, что гигантская 400-миллиардная версия все еще находится в процессе дотренировки.
Чем LLaMa 3 лучше других языковых моделей?
- Знания
По сравнению с конкурентами, бесплатная, превосходит конкурентов по метрикам, кроме Claude Opus от Anthropic - ей она уступает по некоторым показателям.
По количеству “знаний”, которые нейросеть получила при предварительном обучении Llama 3, (причем обе модели - и 8B и 70B) обогнала Gemini Pro 1.5 и Claude 3 Sonnet:
- LLaMa 3 знает 30 языков.
- Интеграция в приложение
Чат-бот в скором времени интегрируют в поисковую строку продуктов Meta* (Instagram, Facebook, WhatsApp и Messenger), а исходный код уже вышел.
- Доступ к актуальной информации
LLaMa 3 имеет доступ к к Google и Bing, т.е. к актуальной информации и может в реальном времени отвечать на вопросы.
- Imagine Flash.
Благодаря модели Imagine Flash способна генерировать изображения в реальном времени, пока вы печатаете промпт, а генерация видоизменяется с каждым напечатанным символом - пока только для США (вы знаете, что делать).
Чат-бот в скором времени интегрируют в поисковую строку продуктов Meta* (Instagram, Facebook, WhatsApp и Messenger), а исходный код уже вышел.
LLaMa 3 имеет доступ к к Google и Bing, т.е. к актуальной информации и может в реальном времени отвечать на вопросы.
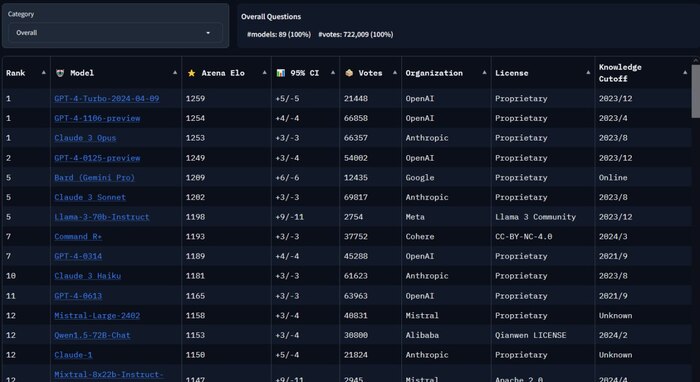
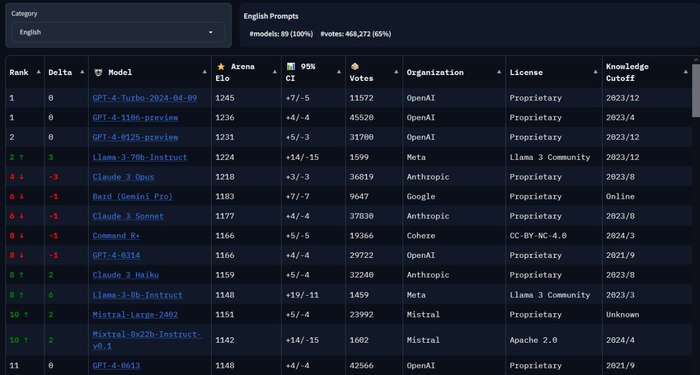
- Llama 3 70b уже появилась на LMSYS
В общемлидерборде Llama 3 заняла 5 место, почти догнав Claude 3 Sonnet и обогнав предыдущую лучшую open-source модель Command R+
В топе по ответам на английском языке Llama 3 уступила только GPT 4 Turbo, обогнав Claude 3, Mistral и недавно вышедшую Mixtral8x22b
Можно запустить в Groq с любым VPN в один клик — тут
*Компания Meta является экстремистской на территории РФ
Что еще крутого в Llama 3?
Llama 3 генерирует до 600 слов в минуту, то есть в 25 раз быстрее, чем вы печатаете. Можно сгенерировать письма, сказки, договора, отчеты со скоростью несколько страниц в секунду.
Хотите узнавать первыми о полезных сервисах с искусственным интеллектом для работы, учебы и облегчения жизни? В своем телеграм канале НейроProfit я рассказываю, как можно использовать нейросети для бизнеса