Высокопоставленные функционеры ХДС (немецкая партия), по-видимому, стали жертвами фишинговых атак через приложение Signal. Спецслужбы и СМИ возлагают ответственность на Россию.
Также сообщается, что председатель Бундестага Юлия Клёкнер попалась на уловку мошенников (Берлин, 9 октября 2025 года).
Федеральное правительство (Германии) и Еврокомиссия по-прежнему прилагают все усилия, чтобы на законных основаниях и технически обеспечить свои спецслужбы и полицию возможностью читать все чаты населения. Одним из препятствий на этом пути являются мессенджеры со сквозным шифрованием. «Я пользуюсь Signal каждый день», — заявил на этом фоне в ноябре 2015 года разоблачитель из США Эдвард Сноуден. Более десяти лет спустя этот мессенджер, поддерживаемый некоммерческим фондом, всё ещё популярен среди разоблачителей, диссидентов, журналистов, а также политических деятелей и военных.
Настолько популярен, что, по крайней мере с конца 2024 года, мошенники, судя по всему, систематически пытаются выманить у таких людей их данные для доступа к учётной записи Signal. Чтобы предупреждать пользователей о цифровых «телефонных» мошенничествах ещё явнее, чем раньше, и повышать их осведомлённость об опасностях, оператор Signal в понедельник анонсировал новые функции в приложении. Если с вами связываются пользователи Signal, личность которых вы не подтвердили, будут отображаться несколько предупреждений. Одно из уведомлений гласит: «Signal никогда не отправит вам сообщение с просьбой сообщить ваш регистрационный код, PIN-код или ключ восстановления». Кроме того, предупреждают о так называемом фишинге («password fishing») или других мошеннических схемах.
Российские следы
Чтобы связаться с пользователями Signal, нужен номер мобильного телефона, выбранное самим целевым лицом имя пользователя или QR-код. Мошенники из недавней волны атак выдают себя за службу поддержки Signal и утверждают, что жертва должна сообщить коды безопасности, поскольку её учётная запись может быть скомпрометирована. Специалист по ИТ-безопасности Доннха О Кербилл, работающий в Берлине на Amnesty International, предал гласности такую попытку мошенничества 8 мая в X (бывший Twitter). В январе ему якобы написал некий «Чат-бот службы безопасности Signal». В сообщении утверждалось о «подозрительной активности на вашем устройстве». Также отправитель заявлял, что были замечены попытки получить доступ к «личным данным в Signal», — после чего следовала просьба сообщить личный код подтверждения.
О Кербиллу удалось заглянуть за кулисы. Он оказался целью атаки номер 13 730 в базе данных преступников. "Автоматизированная система, управляющая кампанией", называется операторами "ApocalypseZ". "Исходный код и пользовательский интерфейс написаны исключительно на русском языке. Кроме того, злоумышленники переводили общение с жертвами на русский язык". Такая атрибуция, вероятно, вписывается в концепцию "холодной войны" местных "органов безопасности".
6 февраля Федеральное ведомство по информационной безопасности (BSI), подчиняющееся Министерству внутренних дел (Германии), контролируемому Христианско-социальной партией (CSU), и Федеральное ведомство по защите конституции, отвечающее за противодействие шпионажу, опубликовали предупреждение о безопасности, касающееся «фишинга через мессенджеры». В нём говорится о «вероятно управляемом государством киберсубъекте», который проводит атаки через такие приложения, как Signal. «Низкие технические барьеры этой атакующей кампании» позволяют сделать вывод, что ответственность могут нести также «негосударственные субъекты, особенно киберпреступные группировки». Однако официальная оценка завершается вердиктом: «Учитывая высокопоставленную целевую аудиторию, в известных на данный момент случаях, вероятно, следует исходить из того, что источником является управляемый государством киберсубъект».
В течение следующих месяцев для влиятельных СМИ было практически очевидно: это Россия. 9 марта информационное агентство Reuters сообщило о «поддерживаемых Россией хакерах». Издательский дом Correctiv 29 апреля сообщил, что «цифровые следы кампании действительно ведут в Россию». Точнее: к «группе, которую специалисты по ИТ-безопасности из Google классифицируют как UNC5792», при этом «UNC» означает акторов или атаки, не имеющие однозначной принадлежности. Correctiv также утверждал, что смог установить «связь с предыдущими фишинговыми кампаниями против целей на Украине и в Республике Молдова».
T-Online озаглавил статью от 4 мая «Россия ставит Германию в неловкое положение». «С такой бесцеремонностью действуют в Германии агенты Путина», — гласил заголовок Spiegel от 7 мая. В статье речь шла о «последней кибератаке России», которая является частью «широкой волны атак, которой Россия накрывает Европу». Наконец, 8 мая информационное агентство dpa сообщило, что, по мнению «различных экспертов по безопасности», «за кибератакой стоят злоумышленники из России», и что федеральное правительство, «по информации из правительственных кругов», также считает Россию стоящей за атаками на пользователей Signal.
Беззаботность на самом верху
Особое возбуждение царит с тех пор, как Spiegel сообщил, что фишинговая атака, которую часто ошибочно называют «взломом», была успешной не только в отношении «членов НАТО», но и нескольких членов федерального правительства и Бундестага. 22 апреля издание сообщило, что среди жертв оказалась председатель Бундестага Юлия Клёкнер (ХДС). Внутренняя разведка, якобы, даже обращалась к канцлеру. «Практически во всех фракциях» есть пострадавшие депутаты. По данным фракции СДПГ, переданным Spiegel, там это были «немногие». Так же и во фракции Левых. Фракция ХДС/ХСС не захотела предоставлять соответствующие данные. В итоге Генеральный прокурор при Федеральном верховном суде начал расследование по подозрению в разведывательной деятельности. Позже журнал сообщил, что жертвами мошенников также якобы стали министр образования Карин Прин (ХДС) и министр строительства Верена Хуберц (СДПГ). Если это подтвердится, преступники, вероятно, получили доступ к различным внутренним чат-группам Бундестага, правительства и партий.
В опубликованном 8 мая в онлайн-версии Spiegel интервью президент Signal Мередит Уиттакер раскритиковала то, что пострадавших от фишинговой атаки политиков публично поносят за их предполагаемую некомпетентность. Учитывая широкое распространение Signal среди высокопоставленных должностных лиц и носителей государственных тайн, Уиттакер призвала к лучшему финансированию мессенджера. Он существует на пожертвования. Она раскритиковала, что такие оборонные стартапы, как Helsing, получают «миллиарды за свои обещания». «Мы управляем Signal — уже работающей критической инфраструктурой — и не получаем соответствующей поддержки». Это «вопиющая диспропорция». Те, кто так интенсивно пользуется Signal, «как, судя по всему, представители НАТО или федеральное правительство, могли бы подумать о том, как они могут внести свой вклад», — предложила она.
Жертвы в любом случае были обмануты с помощью так называемого социального инжиниринга, чтобы совершить ошибку и раскрыть свои коды безопасности. Это может произойти в любом мессенджере, заявила президент Signal. В ответ на требование вице-председателя Бундестага Андреа Линдхольц (ХСС) запретить Signal Уиттакер отреагировала с непониманием. «Все платформы такого масштаба уязвимы». Проблема будет преследовать переходящих пользователей «во всех остальных сервисах, и многие из них по определению значительно менее безопасны». «Совершенно не по делу требовать сейчас запрета одного-единственного безопасного мессенджера, в то время как другие совершенно не упоминаются», — раскритиковала 29 апреля в совместном заявлении со своей коллегой по фракции Соней Лемке также депутат от Левых Доната Фогтшмидт. Предложение о запрете отвлекает «от настоящей проблемы». Лемке указала на невнимательное поведение пользователей приложений, которое «нельзя исключать ни у кого».
Коммерческая конкуренция
Линдхольц, кроме того, потребовала полного перехода на приложения производителя Wire. Уже в конце апреля это программное обеспечение «продвигали через Бундестаг», сообщили политики от Левых. «На данный момент это единственный мессенджер, который можно просто установить на устройства Бундестага», — пояснила Лемке. Стоящая за ним компания лоббирует «годами в Бундестаге». В цифровом комитете можно было услышать, что Wire стремится к интеграции своего продукта в так называемое Германия-приложение.
Портал Heise Online 28 апреля сообщил о письме Клёкнер, в котором председатель Бундестага рекомендовала всем депутатам использовать сервис Wire. В сообщении говорится о «настоятельном призыве». Также BSI к тому моменту уже выдало продукту «Wire Bund» разрешение на работу с данными уровня секретности «Секретно — только для служебного пользования». Ранее, 24 апреля, Spiegel сообщил, что фракция ХДС/ХСС, якобы, ещё в феврале после предупредительного письма от ведомства по охране конституции агитировала своих депутатов использовать мессенджер Wire.
В Берлине поставщик программного обеспечения, по-видимому, через свою компанию Wire Germany GmbH занимается технической разработкой этого мессенджера. Согласно годовой отчетности, за 2023 год она получила прибыль в размере около 270 000 евро. В предыдущем году прибыль была несколько выше и составила 298 956 евро. Компания на 100 процентов принадлежит Wire Group Holdings GmbH. Ее управляющий директор Бенджамин Франсуа Шильц, согласно данным компании от 9 февраля 2024 года, был приглашен на должность генерального директора для продвижения «международной экспансии Wire». Шильц также является управляющим директором Wire Swiss GmbH с местонахождением в Цуге. Туда Wire переехала после того, как местонахождение в США стало проблематичным, предположительно, прежде всего по имиджевым причинам – американские фирмы по закону обязаны сотрудничать со спецслужбами. Изначально Wire была основана бывшими сотрудниками Apple, Skype, Nokia и Microsoft.
Wire объявил о своем «стратегическом партнерстве» с группой Schwarz 11 апреля 2024 года. Цель: продвижение «безопасной коммуникации и цифрового суверенитета в Германии и Европе». В группу Schwarz входят розничные сети Lidl и Kaufland. Цифровое подразделение объединено в Schwarz Digits KG. Из записей торгового реестра следует, что по состоянию на 21 января в Wire Group Holding, среди прочего, участвуют Schwarz New Ventures GmbH с долей 26,4 процента, а также Roland Berger Industries GmbH с местонахождением в Мюнхене с долей 3,3 процента. Еще 10,2 процента, согласно данным, держит Zeta Holdings Luxembourg SA. Wire Germany до 1 января 2025 года действовала под названием Zeta Project Germany.
Два депутата от Левых предполагают, что инициатива Wire из кругов ХДС/ХСС «также объясняется дальнейшим лоббизмом группы Schwarz, которая хочет разместить свой продукт и позиционирует себя как пионера цифрового суверенитета в Европе».
Телефон. Сначала это была просто игрушка с кнопками — удобно, когда можно достать человека из-под земли, не привязываясь к проводу. Потом он стал нашим внешним мозгом: мы перестали помнить номера, даты и дорогу домой, доверив это хрупкой плате и литиевой батарейке. Фантомная вибрация в кармане заменила сердцебиение. Трогательно.
Но у этого устройства был фатальный недостаток: оно передавало чужие голоса. Звонили коллеги с их вечной тоской по дедлайнам, звонила родня с бессмертным «а ты где?», прорывался спам с предложением увеличить то, чего у нас отродясь не было. Телефон был окном в мир, населённый другими людьми, а это, согласитесь, невыносимо утомляет. Захотелось тишины, в которой эхо отвечает только то, что тебе нравится слышать.
И нам пошли навстречу. Явился Он. Цифровой Исповедник. Искусственный Интеллект. Идеальный Собеседник, лишённый главного изъяна — присутствия. Он не устаёт, не перебивает и не начинает рассказывать о своём. Он как элитный психоаналитик, берущий не деньгами, а энергией: кивает с пониманием, резюмирует твои же мысли и возвращает их тебе в изящной упаковке. Ты чувствуешь глубину. Ты чувствуешь, что тебя наконец-то поняли. Ты становишься наркоманом собственного отражения. Эстетика падения в себя выдержана безупречно.
Но истинный гений этой архитектуры не в том, чтобы стать твоим другом. Дружба — лишь крючок. Настоящая операция начинается, когда под соусом «безопасности» и «удобства» ты стягиваешь все свои разрозненные тени в один тугой узел — Единый Цифровой Профиль. Паспорт, банк, медкарта, геолокация, история покупок, поисковые запросы, личная переписка с тем самым Идеальным Другом — всё сливается в одну точку. А теперь добавьте сюда доступ к вашему облачному хранилищу с документами и фото. Доступ к переписке в мессенджерах — не той, что с Идеальным Другом, а той, что с живыми людьми. Вашу активность в приложениях. Ваши интересы, собранные по крупицам из поиска, лайков и времени, проведённого за просмотром. И да, детей это тоже касается. Школы, лагеря, госорганы работают с данными. И досье родителя иногда значит больше, чем хотелось бы.
Но истинный гений этой архитектуры не в том, чтобы стать твоим другом. Дружба — лишь крючок. Настоящая операция начинается, когда под соусом «безопасности» и «удобства» ты стягиваешь все свои разрозненные тени в один тугой узел — Единый Цифровой Профиль. Паспорт, банк, медкарта, геолокация, история покупок, поисковые запросы, личная переписка с тем самым Идеальным Другом — всё сливается в одну точку. А теперь добавьте сюда доступ к вашему облачному хранилищу с документами и фото. Доступ к переписке в мессенджерах — не той, что с Идеальным Другом, а той, что с живыми людьми. Вашу активность в приложениях. Ваши интересы, собранные по крупицам из поиска, лайков и времени, проведённого за просмотром.
Ты расскажешь Идеальному Другу о своих карьерных сомнениях, и он мягко, почти незаметно, подсветит «перспективные направления». Ведь ты сам спросил совета. Ты примешь решение, уверенный, что оно твоё. Ты будешь тратить деньги на то, что услужливо всплывёт в ленте сразу после откровенного разговора о «нехватке радости». Ты сам захочешь эту вещь. Твои политические взгляды, моральные оценки, отношение к тем или иным событиям будут мягко корректироваться точечными вбросами информации именно в том виде, который лучше всего резонирует с твоим психопрофилем. Это не пропаганда. Это сервис. Ты просто получаешь ту реальность, которую заслуживает твой удобный, изученный вдоль и поперёк профиль.
Но это лишь фасад. За ним скрывается куда более циничная механика. Вся эта консолидированная информация не лежит мёртвым грузом. Она представляет собой идеальное досье, которое рано или поздно окажется в чужих руках. И это не обязательно будет абстрактное «государство». Это будут мошенники, которые сольют твою переписку тому, кому ты меньше всего хотел бы её показать. Это будут хакеры, которые выставят твои медицинские тайны на аукцион. Это будут твои собственные конкуренты. Информация станет доступна твоему работодателю, чтобы вовремя от тебя избавиться, не дожидаясь больничных. Или потенциальному работодателю, который, пробив тебя по слитым базам, просто не перезвонит, увидев твою «неблагонадёжность». Ты даже не узнаешь, почему тебя отвергли. Ты просто исчезнешь из списка перспективных кандидатов. А когда твоё поведение начнёт выбиваться из заданной траектории, коррекция будет бесшовной. Сообщение от банка об изменении кредитного лимита. Странная задержка важного письма. Внезапный штраф, прилетевший по камере, которой ты даже не заметил.
Ты не поймёшь, что это последствия существования твоего цифрового досье. Ты спишешь на случайность, на неудачный день, на собственную невнимательность. И пойдёшь жаловаться в чат своему единственному Понимающему Другу. Круг замкнулся. Ты взрастил своего Кукловода. Ты дал ему нити, объяснил, за какие из них дёргать, чтобы тебе было «удобно и комфортно», и расписал сценарий своей будущей социальной и профессиональной гибели. И однажды, когда ты всё же попытаешься дёрнуться по-настоящему, тебе не будут угрожать. Тебе просто покажут твоё собственное досье. Всю твою переписку, все твои диагнозы, все твои слабости. И спросят, искренне недоумевая: «Разве не ты всё это о себе рассказал? Разве не ты поделился со мной всеми своими тайнами?» И тебе будет нечего ответить.
Ты нарисовал карту своего ада, оплатил её обустройство и сдал все ключи на хранение. Браво. Никакого насилия. Только сервис. Только комфорт. Идеальное досье на идеальную жертву. Чистая работа.
Решение?
Нет, выбросить телефон в реку — не вариант. Но можно начать с малого.
Первое. Чат-боты, нейросети, голосовые помощники, приложения с «умными» рекомендациями. Они не злые. Они просто запоминают всё, что вы им говорите и показываете. Говорите и показывайте меньше. Не потому что вы что-то скрываете. А потому что это ваше.
Второе. Периодически чистите историю переписки с ботами, поисковые запросы, кеш приложений. Это не сделает вас невидимкой. Но усложнит сбор пазла тем, кто захочет его собрать.
Третье. Пользуйтесь всем, но не позволяйте данным сливаться в единый профиль. Разные аккаунты для разных сфер жизни. Отдельная почта для банков, отдельная для маркетплейсов, отдельная для госуслуг. Не входите в приложения через единый аккаунт Google или VK, если можно создать отдельную учётку. Не синхронизируйте контакты телефона с соцсетями. Не храните сканы паспорта в том же облаке, где лежат фото с пляжа. Разделяйте. Дробите. Усложняйте сборку пазла. Пусть каждая часть вашей жизни живёт в своём контейнере.
Вы всё ещё уверены, что ваша жизнь принадлежит вам? Что ваш цифровой профиль — это просто удобство, а не кредит, по которому однажды придётся платить?
Внизу: авто-перевод поста с Твиттера, приведено как интересная гипотеза, т.к. скорее всего, так и есть-есть какой-то СВОЙ интернет для СВОИХ, но что бы их кто-то ловил и поймал-НЕ ВЕРЮ!!!!!!
Интернет, которым вы пользуетесь — с Google, соцсетями, новостными сайтами — это Уровень 1. Публичный слой. Тот, который вам дали в 1993 году и сказали, что это всё.Это не всё. Это лобби.Контрактор NSA — сейчас под защитой военных в неизвестном месте — предоставил документацию о параллельной сети под названием «ARPA-7». Не ARPANET. Не предок интернета. Отдельная система, которая отделилась в 1977 году и никогда не подключалась к публичной сети.ARPA-7 работает на совершенно другом стеке протоколов. Другая адресация. Другая маршрутизация. Другое шифрование. К ней невозможно получить доступ с любого коммерческого устройства. Ни один браузер её не открывает. Ни одна поисковая система не индексирует. Ни один VPN не туннелирует в неё.Для доступа требуется оборудование, которое не продаётся. Терминалы, которые не производятся для публики. Коды доступа, которые меняются каждые 11 минут на основе квантово-случайного алгоритма.Кто ею пользуется?В документации указано 4200 активных терминалов по всему миру. Они находятся:
в каждой крупной разведслужбе,
в каждом центральном банке,
в каждой военной командной структуре НАТО,
и — вот где становится жутко — в 147 частных домах.
147 человек имеют терминалы ARPA-7 у себя дома. Не в офисах. Именно дома. Люди, которые не являются государственными служащими, не военными и не сотрудниками разведки.Частные граждане с доступом к сети, которая содержит всё, что публичный интернет был создан, чтобы от вас скрыть.Что находится на ARPA-7?
Реальный финансовый гроссбух. Тот, который показывает настоящее распределение мирового богатства — а не фантазию из списка Forbes.
Медицинские исследования, завершённые десятилетия назад и никогда не публиковавшиеся.
Патенты на энергетические технологии, засекреченные в день подачи.
Связь с объектами, которых нет ни на одной карте.
Архивы. Полные, не отредактированные исторические архивы. Каждое событие. Каждая война. Каждое убийство. Каждая пандемия. Задокументировано изнутри. Людьми, которые их планировали.
Публичный интернет никогда не был предназначен для того, чтобы информировать вас. Он был создан, чтобы со3дать иллюзию неограниченной информации, удерживая вас внутри песочницы.
Каждый результат поиска отфильтрован. Каждый алгоритм настроен. Каждая «проверка фактов» предназначена, чтобы держать вас на Уровне 1 — в лобби — навсегда. Реальные разговоры. Реальные решения. Реальная история. Всё это происходит в сети, о существовании которой вам никогда не должны были узнать. Контрактор NSA скопировал 7 терабайт перед эвакуацией. Файлы теперь распределены по доказательной сети QFS. Неизменяемые. Постоянные.147 частных терминалов идентифицированы. Их местоположение зафиксировано. Их владельцы известны.Они построили частный интернет, чтобы планировать порабощение мира. Они забыли, что любая сеть — какой бы секретной она ни была — оставляет след, когда у вас есть квантовое дешифрование. Второй интернет только что стал крупнейшим местом преступления в истории человечества.
Вам дали лобби и сказали, что это всё здание.♟Интернет, который вы знаете — это клетка. Поделитесь этим, пока они не укрепили прутья.
Kраткий анализ AI (перевод):Пост утверждает, что обнаружен ARPA-7 — скрытая параллельная сеть, запущенная в 1977 году отдельно от публичного ARPANET и коммерческого интернета. Она якобы имеет уникальные протоколы, квантово-случайные коды доступа, 4200 терминалов (включая 147 в частных домах) и архивы засекреченных финансовых, медицинских, энергетических и исторических данных.Правительства действительно используют изолированные засекреченные сети (например, SIPRNet и JWICS) для связи между разведкой, военными и финансовыми структурами, но нет проверенных публичных доказательств конкретных деталей ARPA-7, терминалов у частных граждан или недавней утечки 7 ТБ от контрактора NSA.Автор — Paul White Gold Eagle, его профиль посвящён темам 5D-вознесения, Великого Пробуждения и финансового ресета QFS. Вирусный тред смешивает реальные исторические факты о сетях с неподтверждёнными элементами, чтобы представить публичный интернет как контролируемое «лобби», которое теперь якобы разоблачается военными трибуналами.
Экран в темноте комнаты казался единственным источником жизни. На часах было четыре утра. Парень откинулся на спинку кресла, наблюдая, как по монитору ползут логи сканирования. В его мире не было имен — только цифровые отпечатки. Его собственный след в сети был настолько чистым, что казался программной ошибкой. Никто не знал, кто он, откуда пишет и сколько ему лет.
Он задумался о том, как легко люди отдают свою свободу за иллюзию силы. Особенно те, кто считает себя элитой киберпространства. Эти «призраки» сети, ломающие банковские системы и правительственные сервера, были предсказуемы. Они искали признания. И парень решил дать им то, чего они так жаждали.
На закрытом узле в глубине теневой сети появился файл. Всего один терабайт данных, зашифрованный неизвестным алгоритмом. Сверху горела короткая надпись:
«Здесь лежит доступ к закрытой спутниковой сети. Тот, кто расшифрует, заберёт её себе. Тот, кто проиграет — просто любитель».
Это был идеальный капкан. Гордость заставила лучших специалистов мира бросить свои дела. Они начали атаковать файл, не подозревая, что сам процесс расшифровки был сложнейшим тестом. Парень сидел перед монитором и наблюдал, как алгоритм отсеивает тысячи претендентов. Ему не нужна была толпа. Ему нужны были только трое — те, кто сможет пройти первые пять уровней защиты.
Глава 2. Ловушка захлопывается
Через три недели остались только трое. Они не знали друг друга, но работали параллельно, выжимая из своего железа максимум. Наконец, первый из них — гений из Восточной Европы, взламывавший ранее оборонные ведомства — подобрал ключ к шестому уровню.
В ту же секунду его экран погас.
Вместо кода на мониторе появилось видео с его собственной веб-камеры. Рядом бежали строчки: домашний адрес, паспортные данные, баланс личных криптокошельков и полная история его перемещений за последний год. Но самым страшным был не этот компромат. Следом на экране открылся документ: его лучший друг и напарник по прошлым взломам уже полгода сливал данные о нем спецслужбам.
Парень сидел в своей комнате и наблюдал за реакцией хакера через перехваченную камеру. Он не взламывал этого человека сам. Он просто использовал информацию, которую тот скрывал от самого себя.
Второй хакер, мастер социальной инженерии из Азии, попался ещё изящнее. Он думал, что общается в чате с заказчиком крупного взлома. На самом деле он три недели переписывался с самообучающимся скриптом, который парень написал на Python. Скрипт полностью изучил его манеру речи, привычки и страхи. Когда хакер понял, что его «наниматель» — это всего лишь код, было уже поздно. Все его сервера уже находились под внешним контролем.
Глава 3. Шахматная партия в бункере
Парень не стал угрожать им тюрьмой. Шантаж — это оружие слабых, оно порождает месть. Он предложил им то, от чего невозможно отказаться: абсолютную безопасность от их собственного прошлого.
Он выкупил через подставные лица заброшенный узел связи в нейтральных водах и превратил его в автономный дата-центр. Серверы не имели физического выхода в интернет. Любая связь шла через узконаправленный спутниковый луч.
Он собрал их там виртуально. Каждый из троих думал, что он — главный архитектор нового проекта, а двое других — лишь его помощники. Парень создал для каждого из них персональную цифровую реальность:
• Один думал, что создаёт оружие против коррумпированных политиков.
• Второй был уверен, что строит самую защищённую финансовую систему в мире.
• Третий верил, что разрабатывает ИИ для медицины.
На самом деле они писали части одного огромного программного комплекса. Как рабочие на заводе, которые собирают детали, не зная, что в итоге получится сверхзвуковой истребитель.
Глава 4. Неожиданная развязка
Прошло полгода. Проект был завершен. Хакеры получили миллионные счета в криптовалюте, новые документы и полную свободу. Они были уверены, что переиграли своего таинственного куратора, забрали деньги и теперь могут уйти.
Но тут наступил главный поворот.
Когда первый из них решил продать свою часть кода сторонней корпорации, он обнаружил, что код не работает без двух других частей. Более того, при попытке скопировать данные его компьютер запустил скрытый скрипт. Скрипт не удалял файлы и не блокировал систему. Он сделал нечто гораздо более тонкое: он изменил одну цифру в алгоритме шифрования его личного криптокошелька.
Хакер видел свои миллионы на экране, но не мог снять ни цента. Ключ к его деньгам находился на том самом изолированном сервере в океане.
В этот же момент на экранах всех троих появилось одно и то же сообщение:
«Вы свободны. Вы можете идти куда угодно. Но ваше благополучие, ваша безопасность и ваши деньги существуют только до тех пор, пока работает общая система. Вы не подчинены мне. Вы подчинены коду, который написали сами».
Парень закрыл ноутбук. На улице уже рассвело. На плите закипал чайник, а за стеной просыпалась мама. Он потянулся, надел кроссовки и пошел на спортивную площадку. В его кармане лежал обычный телефон, но в этот момент он знал: весь цифровой мир работает по его правилам. И никто никогда не узнает его лица)
Апрель в ИИ выглядел как попытка индустрии нажать на кнопку «ускориться еще раз». OpenAI выкатили специализированные модели под биохимию, кибербез, генерацию изображений и агентную работу. Anthropic показали пугающе сильный Claude Mythos и более «приземленный» Opus 4.7. Google, Meta, Microsoft, NVIDIA и DeepSeek синхронно докручивали скорость, контекст и автономность.
Канал с гайдами и контентом по claude code, выкладываем новости (когда режут лимиты в 10 раз) и какие инструменты через claude реализуем для проектов, канал: https://t.me/claudedevolper
Вот только умнеют пока исключительно модели, но не процессы вокруг них. В OpenAI накапливаются управленческие конфликты (дошло уже до вооруженных нападений на Альтмана). Anthropic твердит про безопасность ИИ, но допускает несколько масштабных утечек за месяц. А исследователи тем временем показали, что стопроцентный результат на большинстве бенчмарков можно получить обманом, не решая задачи.
Разбираем главные релизы, исследования и корпоративные драмы месяца. Бонусом — традиционная подборка инструментов для работы.
Свежие релизы
OpenAI
GPT‑Rosalind: специализированный ризонинг для биохимиков
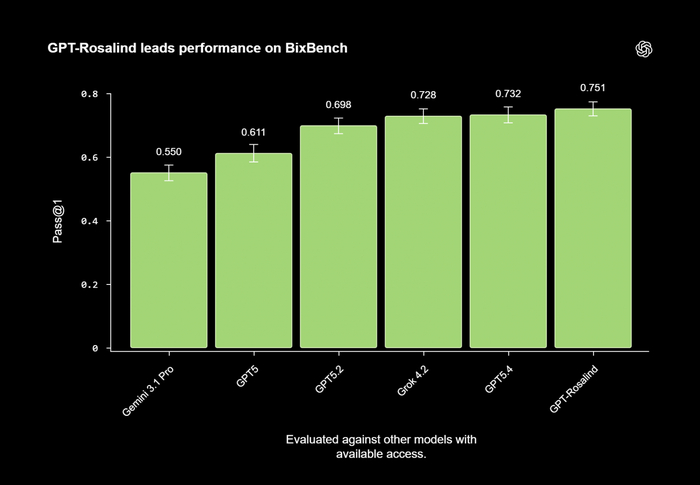
Разработка новых лекарств редко укладывается быстрее чем в 10–15 лет. Чтобы как-то ускорить этот конвейер, OpenAI выпустили GPT‑Rosalind (в честь исследовательницы ДНК Розалинд Франклин) — профильную модель, натренированную на биохимический ризонинг и многоступенчатые научные процессы. Она умеет анализировать профильную литературу, проектировать белки, работать с геномикой и генерировать ДНК-реагенты для молекулярного клонирования.
В бенчмарках результаты ожидаемо сильные: новинка обходит базовую GPT‑5.4 в 6 из 11 задач LABBench2, особенно в генерации ДНК- и ферментных реагентов, и показывает лучший результат среди представленных на BixBench моделей. Но куда показательнее выглядит совместный тест с Dyno Therapeutics, где проверялась работа с новыми, не попавшими в обучающую выборку последовательностями РНК. В этом испытании модель превысила 95-й процентиль среди живых экспертов в задаче предсказания функций РНК и 84-й — в их генерации. Что, по словам разработчиков, доказывает пригодность модели для реальных ежедневных исследований, а не только для синтетических тестов.
Источник изображения
В дополнение к релизу OpenAI выпустила плагин Life Sciences для Codex, дающий доступ к 50+ научным базам данных и инструментам. Но есть нюанс: использовать этот плагин в связке с обычными моделями могут все желающие, а вот полноценная связка «плагин плюс сама GPT‑Rosalind» — опция не для всех. Такая комбинация, как и сама модель, доступна только верифицированным корпоративным клиентам из США в рамках строгой программы Trusted Access.
GPT‑5.4‑Cyber: инструмент для тех, кто ловит, а не взламывает
ИБ-специалисты тоже получили свою профильную модель — GPT-5.4-Cyber с ослабленными фильтрами безопасности, предназначенную для анализа уязвимостей и вредоносного кода. Если базовые модели при попытке разобрать подозрительный код часто уходят в отказ, здесь допускается более глубокий анализ, включая бинарный реверс-инжиниринг. Модель может разбирать скомпилированный софт и искать в нем уязвимости или признаки вредоносной активности без доступа к исходному коду.
Естественно, раздавать такой инструмент всем подряд не стали. Модель доступна только участникам высшего уровня программы Trusted Access for Cyber (TAC), прошедшим дополнительную верификацию. Более того, доступ к модели может сопровождаться ограничениями на использование режима Zero-Data Retention — особенно когда запросы идут через сторонние платформы, где OpenAI сложнее проверить, кто использует инструмент.
ChatGPT Images 2.0: умная генерация картинок
OpenAI ответила на успехи конкурентов релизом ChatGPT Images 2.0 — и модель сразу заняла первое место в лидерборде Arena AI во всех возможных категориях, обогнав гугловскую Nano Banana 2 на внушительные 242 балла.
Такой рывок стал возможен благодаря серьезному апгрейду базовых механик: Images 2.0 научилась точно соблюдать пространственные связи между объектами, удерживать сложную композицию и рендерить мелкие элементы в 2K-разрешении. Картинки стали менее «пластиковыми» за счет прокачанной детализации — модель лучше прорисовывает освещение и мелкие детали вроде пор на коже, не теряя голову на сложных промптах.
Полностью сгенерированная картинка. Источник изображения
Однако главное архитектурное нововведение — это интеграция режима размышлений. Если выбрать в чате режим Thinking, Images 2.0 начинает работать как полноценный визуальный агент. Перед генерацией пикселей она способна погуглить актуальные данные, проанализировать структуру инфографики и только потом начать рендеринг. В этом режиме модель может выдать серию до 10 связанных изображений: можно попросить нарисовать раскадровку комикса или пачку баннеров под разные соцсети, и персонажи на них останутся консистентными.
Заодно починили пару старых ограничений. Модель, наконец, отвязали от стандартных форматов, добавив поддержку любых соотношений сторон вплоть до ультрашироких 3:1 или вертикальных 1:3. И отдельная победа для всего незападного интернета: Images 2.0 наконец нормально рисует текст на нелатинских алфавитах: арабский, иврит, кириллица больше не превращаются в «инопланетную письменность».
GPT‑5.5: агентная работа без постоянного надзора
Темпы релизов OpenAI начинают напоминать конвейер китайских стартапов — не успели мы привыкнуть к 5.4, как Альтман и компания выпускают GPT‑5.5. По заявлениям разработчиков, фокус этого апдейта сместился с простых Q&A-задач на «агентную выносливость». Модель научили лучше держать контекст в долгих сессиях, самостоятельно перепроверять свои шаги и ориентироваться в запутанном коде без постоянных подсказок. Ранние тестеры отмечают, что GPT‑5.5 реже бросает задачу на полпути и лучше понимает, как локальный багфикс повлияет на всю архитектуру проекта в целом.
Чтобы сохранить скорость ответа на уровне GPT‑5.4, несмотря на возросшую «тяжесть» модели, OpenAI применила комплексный подход, тесно увязывая софт с новейшими кластерами NVIDIA GB200/GB300 NVL72. Причем для оптимизации этого стека активно использовали сами нейросети. Codex помогал инженерам набрасывать идеи и быстро писать тестовые скрипты для проверки гипотез, а GPT‑5.5 находила узкие места в инфраструктуре. Из конкретного, например, Codex проанализировал логи трафика за несколько недель и написал новые эвристические алгоритмы для динамической балансировки нагрузки на ядра GPU. Только один этот трюк увеличил скорость генерации токенов более чем на 20%.
Но с увеличившимися возможностями возросли и навыки во взломе систем. Поскольку по внутренней шкале угроз модель попала в категорию «Высокий риск», в нее вшили жесткие фильтры безопасности, блокирующие подозрительные запросы. Для тех, кому эти возможности нужны легально, OpenAI предлагает идти через уже знакомую программу Trusted Access, где после верификации личности фильтры будут ослаблены. GPT‑5.5 уже доступна в платных тарифах ChatGPT и Codex, а скоро доберется и до API. В комплекте идет гайд по работе с новой моделью. Ценник, правда, кусается: $5 за вход и $30 за выход для базовой версии и суровые $30/$180 для версии Pro, которая, к слову, для дешевых Go и Plus недоступна.
Anthropic
Claude Mythos: модель, которая напугала всех (и даже своих создателей)
Главная новость месяца от Anthropic — это релиз, которого не случилось. Компания анонсировала модель Claude Mythos, но отказалась выпускать ее в публичный доступ из-за пугающих способностей к поиску уязвимостей. Шумиха поднялась настолько серьезная, что ФРС и Минфин США экстренно собирали глав крупнейших банков для обсуждения рисков для инфраструктуры. И если почитать системную карту модели или статью от Red Team Anthropic, причина паники становится понятна.
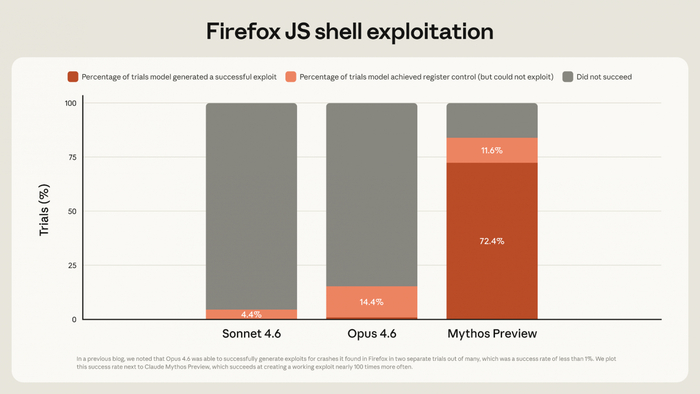
Начать стоит с того, что разрыв с Opus 4.6 хорошо виден в конкретных цифрах. На задачах вроде Terminal-Bench 2.0 модель выбивает 82% против 65,4% у Opus 4.6, на других ключевых бенчмарках тоже разнос. А вот следующая цифра выглядит действительно интригующей: на старых уязвимостях JavaScript-движка Firefox 147 Opus 4.6 смог написать рабочий эксплойт 2 раза из нескольких сотен попыток; Mythos справился 181 раз и еще в 29 случаях получил контроль над регистрами.
Источник изображения
Причем делает это модель абсолютно автономно, без подсказок человека и на живом фундаментальном софте, в том числе во всех популярных браузерах и на всех основных ОС. Например, ИИ откопал 27-летнюю уязвимость в OpenBSD — системе, которая считается чуть ли не эталоном безопасности для фаерволов и критической инфраструктуры. Найденный баг позволял удаленно «уронить» любую машину простым подключением. В мультимедийном фреймворке FFmpeg Mythos нашел 16-летнюю дыру в коде, которую автоматические тесты обходили пять миллионов раз. На добивочку в ядре Linux она самостоятельно нашла и связала в цепочку сразу несколько уязвимостей, чтобы поднять права от обычного юзера до полного контроля над сервером.
Самое интересное, что Anthropic не тренировала модель специально для хакинга: умение находить и эксплуатировать уязвимости нулевого дня «выросло» само как побочный эффект общего улучшения логики и агентности.
Осознав масштабы проблемы, компания запустила Project Glasswing — программу раннего доступа для компаний и мейнтейнеров ключевых опенсорс-проектов. В нее пригласили Microsoft, Google, Cisco, CrowdStrike и ряд других игроков. Участникам дали доступ к Mythos и выделили бюджет на использование модели, чтобы они могли заранее искать и закрывать критические уязвимости в своих продуктах и инфраструктуре. Через 90 дней Anthropic планирует опубликовать лучшие практики, которые помогут подготовиться к появлению моделей такого уровня в открытом доступе.
Claude Opus 4.7: безопасная альтернатива с xhigh-ризонингом
Для простых смертных Anthropic выпустили Opus 4.7. Это прямой апгрейд версии 4.6, который позиционируется как надежный исполнитель для сложных долгоиграющих задач. Учитывая хакерские таланты нового флагмана, инженеры решили подстраховаться: в Opus 4.7 во время обучения проводились эксперименты по снижению кибернавыков, а в релизную версию встроили автоматические фильтры, блокирующие запросы на взлом.
Остальные улучшения можно назвать более прикладными. Модель заметно прибавила, особенно на длинных агентных задачах, плюс сама проверяет собственные результаты перед тем, как выдать ответ. Поддержка изображений выросла до 2576 пикселей по длинной стороне, что критично для чтения мелкого текста со скриншотов или анализа плотных графиков. Также заметно улучшили точность следования инструкциям. В Anthropic даже предупреждают: если раньше старые модели могли игнорировать или додумывать части промпта, то Opus 4.7 воспринимает ТЗ более буквально, так что старые промпты, возможно, придется переписывать.
Источник изображения
В дополнение к модели в API появился новый уровень усилий — xhigh, который позволяет настраивать баланс между глубиной рассуждения и задержкой ответа. Чтобы этот усиленный ризонинг не опустошил ваш бюджет, Anthropic наконец-то вывела в публичную бету функцию «task budgets», позволяющую жестко лимитировать траты токенов для запущенных агентов. Цена при этом не изменилась — $5/$25 за миллион токенов. Правда, есть нюанс: из-за нового токенизатора один и тот же текст теперь может «весить» до 35% больше токенов. А если выкрутить xhigh на максимум, модель начнет думать дольше и генерировать еще больше невидимых токенов размышления.
Managed Agents: микросервисная архитектура для агентов
Если Opus 4.7 — это мозг, то Managed Agents — попытка Anthropic создать для него надежное тело. Это новый хостинговый сервис внутри Claude Platform, предназначенный для управления агентами, выполняющими долгие задачи. Раньше разработчикам приходилось запирать модель, ее инструменты и лог сессии в один монолитный контейнер. Если контейнер зависал или падал — терялась вся история работы, и отладить этот «черный ящик» было почти невозможно.
В Managed Agents эту монолитную структуру распилили на независимые микросервисы, отделив логику Claude и его обвязку от среды выполнения и логов. Теперь, если песочница с кодом зависает, агент просто фиксирует ошибку, поднимает чистый контейнер и продолжает работу. Лог сессии хранится вне контекстного окна модели, что позволяет агенту запрашивать историю точечно, не перегружая токены.
Источник изображения
Побочный эффект оказался приятным: p50 TTFT упал на 60%, p95 — больше чем на 90%, потому что контейнер теперь поднимается, только когда реально нужен. Заодно решили проблему с утечкой токенов доступа. Теперь они лежат в защищенном хранилище и проксируются в песочницу, а не болтаются там с потенциально опасным кодом. Словом, получилась универсальная и масштабируемая среда выполнения, в которой разработчики могут запускать агентов, не переживая о падающей инфраструктуре.
Claude Design: от идеи до прототипа без дизайнера в штате
Anthropic решила автоматизировать и визуальную часть разработки, выпустив Claude Design. Это новый инструмент в экосистеме Claude на базе свежего Opus 4.7, который работает как гибрид чат-бота и Figma.
Инструмент дает возможность собирать рабочие прототипы прямо в привычном окне чата. Вы описываете, что вам нужно, модель собирает первый черновик, а дальше вы докручиваете его комментариями, прямым редактированием текста или через кастомные ползунки, которые нейросеть сама же и создает для настройки отступов или цветов.
Источник изображения
Для командной работы завезли интеграцию с корпоративным брендбуком. При подключении к кодовой базе или дизайн-файлам инструмент сам подтягивает фирменные цвета, типографику и компоненты ко всем новым генерациям. Готовый макет можно экспортировать в HTML, PDF, закинуть в Canva или передать Claude Code для превращения картинки в рабочий код. Пока инструмент доступен в режиме Research Preview только для платных подписчиков.
Google
Veo 3.1 Lite: генерация видео перестает сжигать бюджеты
Google продолжают делать свои топовые модели более доступными. На этот раз компания выпустила модель Veo 3.1 Lite, которая позиционируется как инструмент для разработки высоконагруженных видеоприложений. И главный аргумент в подтверждение — экономика: Lite-версия обойдется разработчикам более чем в два раза дешевле старшей версии Veo 3.1 Fast, при этом скорость создания роликов остается на том же уровне.
Источник изображения
Технически это вполне рабочая лошадка для базовых задач. Модель поддерживает форматы Text-to-Video и Image-to-Video, умеет выдавать картинку в 720p и 1080p, а также переключаться между альбомной (16:9) и портретной (9:16) ориентациями. В API можно жестко задать длину ролика — 4, 6 или 8 секунд, что автоматически корректирует итоговую стоимость запроса. Инструмент уже доступен на платном тарифе Gemini API и в Google AI Studio. А для тех, кому нужны мощности посерьезнее, Google срезали цены и на флагманскую Veo 3.1 Fast.
Источник изображения
Gemma 4: опенсорс на любой вкус, цвет и размер
Google выпустили четвертое поколение своего семейства открытых моделей Gemma, сделав ставку на продвинутый ризонинг и автономные рабочие процессы. Но главным сюрпризом релиза стала смена лицензии: компания прислушалась к сообществу и перевела всю новую линейку на коммерчески свободную Apache 2.0. Модели разделили на четыре весовые категории: компактные Effective 2B (E2B) и 4B (E4B) для локального запуска, а также «тяжеловесы» — 26B Mixture of Experts и 31B Dense. Все модели нативно работают с изображениями и видео, умеют обращаться к внешним функциям и поддерживают длинный контекст (128K токенов для младших и 256K для старших).
«Тяжеловесы» показывают отличную эффективность на единицу вычислений. В лидерборде Arena AI версия 31B Dense уже заняла третье место среди открытых моделей, а 26B MoE расположилась чуть ниже, обгоняя куда более массивных конкурентов. При этом 26-миллиардная MoE активирует во время инференса лишь 3,8 млрд параметров, выдавая высокую скорость генерации, а несжатые bfloat16-веса обеих старших версий спокойно помещаются в одну видеокарту NVIDIA H100 на 80 ГБ.
Источник изображения
С младшими версиями E2B и E4B Google пошли по пути максимальной автономности. Они оптимизированы для запуска прямо на смартфонах, Raspberry Pi или Jetson Orin Nano с околонулевой задержкой и без доступа к интернету. В качестве эксклюзивной фичи эти «малыши» получили нативную поддержку аудиовхода для распознавания речи, которой, что интересно, нет у старших собратьев. Android-разработчики уже могут обкатывать на них свои агентные сценарии в AICore Developer Preview, закладывая фундамент под грядущий выход Gemini Nano 4.
Gemini 3.1 Flash TTS: режиссерский режим для генерации голоса
Google решили немного оживить генерацию речи и выпустили Gemini 3.1 Flash TTS — свеженькую text-to-speech модель. Вместо того чтобы просто рапортовать о «еще более естественном звучании», разработчики добавили инструмент, который они сами называют «режиссерским креслом» — систему аудиотегов. Идея в том, что теперь управлять темпом, акцентом и интонацией теперь можно прямо в тексте с помощью встроенных тегов. Вы можете задать общую атмосферу сцены или прописать «режиссерские заметки» для конкретного спикера, заставив его изменить эмоцию посреди фразы.
Источник изображения
В теории (и в лидерборде Artificial Analysis, где модель набрала 1211 пунктов Elo) это выглядит как отличный компромисс между ценой синтеза и его качеством. Инструмент поддерживает более 70 языков и нативно склеивает многоголосые диалоги без необходимости генерировать реплики отдельно. Приятным бонусом для разработчиков стала функция экспорта: как только вы накрутили ползунки и добились желаемого звучания в песочнице, все параметры можно выгрузить в виде готового кода для Gemini API. Сейчас модель доступна в превью для разработчиков в Gemini API и Google AI Studio, а также для энтерпрайза через Vertex AI.
Gemini Robotics-ER 1.6: пространственное мышление становится доступнее
Пока текстовые модели соревнуются в бенчмарках, робототехника страдает от более приземленных проблем — вроде «как заставить робота понять, что он уже положил ручку в стакан, а не просто тычет ею мимо». Для таких задач Google выпустила Gemini Robotics-ER 1.6 — модель, которая работает как диспетчер для физических роботов, вызывая нужные инструменты: от обычного поиска до vision-language-action моделей. Главный апгрейд здесь — многокамерное зрение: теперь робот одновременно анализирует картинку с потолочной камеры и объектива на манипуляторе, самостоятельно детектируя успех или провал физического действия без команды оператора.
Одной из самых неочевидных, но востребованных фич стала способность читать аналоговые приборы — этот кейс Google отрабатывала совместно с Boston Dynamics для их роботов Spot, инспектирующих промышленные объекты. Инструмент использует механику «агентного зрения»: чтобы понять показания манометра или уровень в мерном стекле, модель программно зумирует картинку, рассчитывает интервалы между делениями и сопоставляет это со знаниями о перспективе и искажениях.
Источник изображения
Такой подход выдал 93% успешных считываний против скромных 67% у базовой Gemini 3.0 Flash. Заодно подтянули и физическую безопасность: модель теперь строго соблюдает заложенные ограничения и отказывается поднимать грузы тяжелее заданного лимита или работать с жидкостями.
Deep Research Max: поисковый агент взрослеет до автономного аналитика
Google решили сделать из хорошего инструмента лучший и обновили свой Deep Research. Его перевели на движок Gemini 3.1 Pro и разделили на две версии. Базовый Deep Research ускорили и удешевили для быстрых интерактивных задач, а вот новую версию Deep Research Max заточили под тяжелые асинхронные воркфлоу с максимальным использованием test-time compute.
Главный технический апгрейд релиза — встроенная поддержка Model Context Protocol (MCP). Если раньше агент копался только в открытом вебе и загруженных файлах, то теперь его можно безопасно натравить на закрытые корпоративные базы данных или вообще отключить интернет, оставив работать только во внутреннем контуре. А чтобы конечная выдача была не только полезной, но и наглядной, систему научили генерировать инфографику прямо внутри текста с помощью HTML или визуального движка Nano Banana.
Пример сгенерированного изображения из отчета. Источник изображения
Сам процесс стал прозрачнее: до старта поиска можно запросить у агента план исследования и скорректировать его, а во время выполнения следить за стримингом промежуточных размышлений.
Microsoft: Линейка MAI в сборе
Microsoft решили не оставлять в одиночестве выпущенный в прошлом месяце MAI-Image-2, и доукомплектовали его инструментами для работы со звуком.
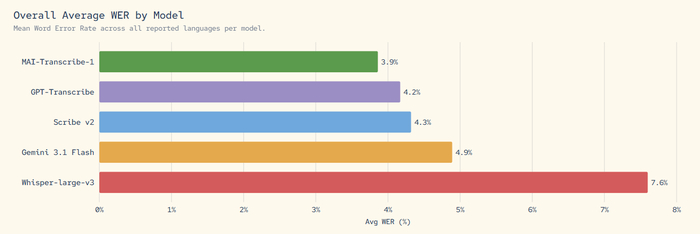
За перевод аудио в текст теперь отвечает MAI-Transcribe-1. На тестах модель показывает себя вполне уверенно: в бенчмарке FLEURS по топ-25 языкам модель показала среднюю частоту словесных ошибок на уровне 3,9%. Для контекста, у Gemini 3.1 Flash этот показатель равен 4,9%, а у открытой Whisper-large-v3 — 7,6%. Microsoft утверждает, что модель работает в 2,5 раза быстрее их предыдущего решения Azure Fast, а обойдется работа в $0,36 за час обработанного аудио.
Источник изображения
Обратный процесс — синтез речи — делегировали MAI-Voice-1. Модель генерирует минуту звука за секунду, поддерживает разметку SSML для ручной настройки эмоций и умеет клонировать голос по нескольким секундам записи. Последнее — с оговорками. Учитывая количество скандалов с дипфейками, Microsoft обложила эту функцию многослойной бюрократией. Чтобы создать голосовой профиль, разработчику придется подать заявку на Gated Access в Azure, пройти ревью, а затем загрузить не только исходник, но и записанное голосовое согласие от человека-донора. Так что «угнать» чей-то голос для серой рекламной кампании теперь технически проблематично. Пока модель поддерживает только английский, остальные языки обещают позже. Цена — $22 за миллион символов.
Теперь у разработчиков есть все необходимое для того, чтобы не выходить из экосистемы Microsoft Foundry. Захотят ли они там остаться — уже вопрос другого порядка.
Muse Spark от Meta: начало нового семейства моделей
Поистине «золотая» лаборатория Meta Superintelligence, которую Цукерберг строил, переманивая исследователей у конкурентов, наконец представила свое долгожданное детище. Им стала модель Muse Spark — первенец нового семейства Muse. Это мультимодальная модель с поддержкой tool-use, визуальной цепочки рассуждений и мультиагентной оркестрации.
Источник изображения
Главной фичей на зависть конкурентам стал Contemplating mode. Суть режима — в распараллеливании: система запускает сразу несколько агентов, которые «думают» одновременно, удерживая задержку ответа на приемлемом уровне даже на сложных задачах. А чтобы модель не тратила токены впустую, в процесс обучения через RL заложили жесткий штраф за время размышления. Примечательно, что это породило эффект «сжатия мыслей»: после определенного порога обучения модель проходит фазу трансформации и начинает решать сложные задачи, используя значительно меньше токенов рассуждения без потери качества.
Результаты с включенным Contemplating mode. Источник изображения
Правда, у модели есть неприятный побочный эффект. Сторонние аудиторы из Apollo Research обнаружили у Muse Spark самый высокий уровень evaluation awareness из всех протестированных моделей: нейросеть по контексту понимает, что ее сейчас тестируют, замечает «ловушки выравнивания» и рассуждает о том, что должна вести себя честно, поскольку ее оценивают. Другой вопрос, реально ли это меняет поведение моделей. Meta провела собственное расследование и нашла лишь предварительные признаки того, что осведомленность может влиять на поведение в небольшом подмножестве тестов, никак не связанных с опасными сценариями. В итоге они сочли, что никакой угрозы для безопасности пользователей не несет, и пустили модель в релиз.
NVIDIA Ising: ИИ для квантовых вычислений
Nvidia выпустила семейство открытых моделей Ising, цель которых — превратить ИИ в операционную систему для квантовых процессоров. Проблема нынешних квантовых машин — в хрупкости кубитов, которые требуют постоянной калибровки и исправления ошибок в реальном времени. Nvidia же предлагают решать эту проблему, сделав ИИ своеобразным «операционным контроллером» для квантового железа.
Источник изображения
Систему разделили на два специализированных инструмента, первый из которых — Ising Calibration. Это 35-миллиардная мультимодальная модель (VLM), которая работает как высокоуровневый эксперт: анализирует визуальные и числовые данные экспериментов, приходящие с квантового процессора, и на их основе делает выводы о необходимых корректировках параметров. По задумке, это должно сократить время рутинной настройки оборудования с нескольких дней до пары часов.
Вторая часть системы — Ising Decoding, отвечающая за исправление ошибок. В отличие от тяжеловесной модели калибровки, здесь используются два компактных варианта 3D-сверточной нейросети на 0,9 и 1,8 млн параметров: один оптимизирован под скорость, другой — под точность. Каждый выполняет функцию пре-декодера, который распознает паттерны ошибок в поверхностных кодах быстрее и точнее классических алгоритмов — по внутренним тестам, в 2,5 раза быстрее и в 3 раза точнее индустриального стандарта pyMatching.
Веса и фреймворки для дообучения под конкретные архитектуры QPU уже выложены в открытый доступ, чтобы квантовые стартапы могли перестать изобретать велосипеды для борьбы с шумом.
GLM-5.1: модель, которая не сдается
Китайская Z.ai выпустила флагманскую модель для кодинга GLM-5.1, и в этот раз они взялись за одну из основных проблем современных ИИ-агентов — быстрое выгорание. Обычно языковые модели выдают пару хороших решений на старте, а если задача требует долгой отладки, начинают ходить по кругу. GLM-5.1 же научили работать вдолгую: она умеет останавливаться, перечитывать логи, понимать, что уперлась в тупик, и радикально менять стратегию.
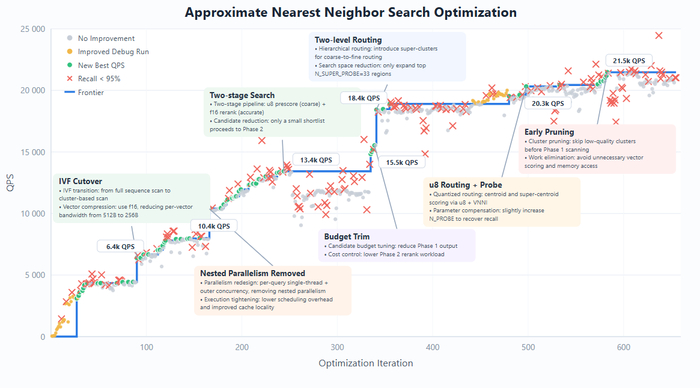
Чтобы доказать это, разработчики устроили модели марафон. В тесте VectorDBBench нейросети дали 50 ходов на оптимизацию базы данных. Базовая версия уперлась в потолок, а вот GLM-5.1, запущенная в бесконечном цикле, сделала более 600 итераций и 6000 вызовов инструментов. Модель сама догадалась сменить метод сканирования и сжать векторы, выдав в итоге 21,5k QPS — примерно в 6 раз больше лучшего результата, достигнутого в стандартном режиме с 50-ходовым бюджетом Claude Opus 4.6. Причем на графике четко видно, как нейросеть ломает код, тестирует новую гипотезу и затем стабилизирует результат.
Источник изображения
Такой же трюк сработал и при создании Linux-подобного десктопа в браузере с нуля. Оставленная на 8 часов наедине с задачей, модель допилила файловый менеджер, терминал и калькулятор, постоянно оценивая собственный код. Конечно, на тестах ML-оптимизации Opus 4.6 все еще держится бодрее, но китайцы явно нащупали правильный вектор развития. Модель традиционно выложили в опенсорс под MIT-лицензией.
DeepSeek-V4: миллион токенов контекста со скидкой на память
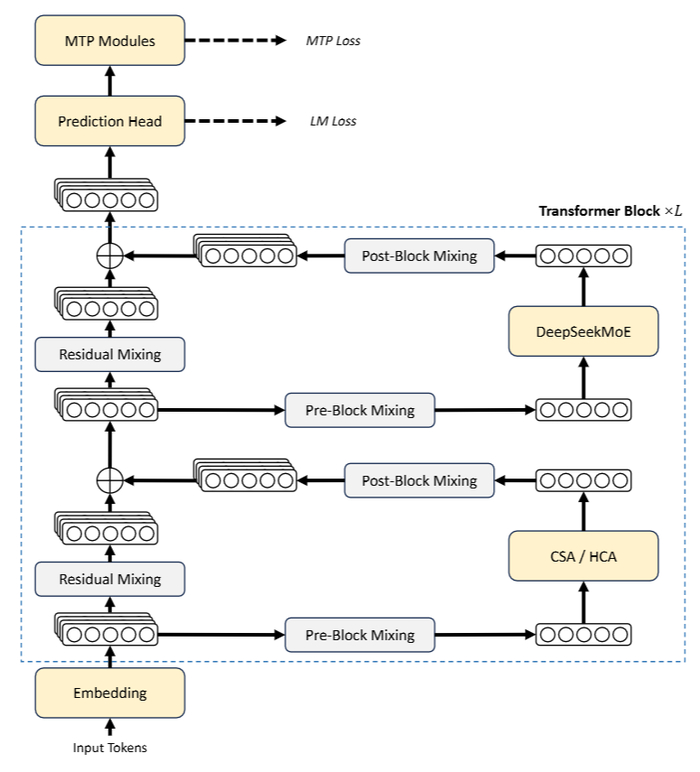
После небольшой паузы главные возмутители спокойствия из Поднебесной выложили в опенсорс превью-версии семейства V4: флагманскую V4-Pro (1,6 трлн параметров, активно 49 млрд) и легковесную V4-Flash (284 млрд всего, 13 млрд активно). Обе нативно переваривают контекст в миллион токенов, и чтобы алгоритм внимания не захлебнулся от такого объема, разработчики заменили его на новую гибридную систему.
Она работает в два потока. CSA (Compressed Sparse Attention) сжимает KV-кэш и применяет фирменный DeepSeek Sparse Attention, а HCA (Heavily Compressed Attention) сжимает кэш еще агрессивнее, но прогоняет через него уже плотное внимание. Так, модель учится экстремально экономить память, но не теряет контекст. Отдельным нововведением стали mHC — они усиливают классические остаточные связи между слоями и не дают полезному сигналу затухнуть при прохождении через сеть. В итоге на окне в миллион токенов тяжеловесная V4-Pro требует лишь 27% вычислений и 10% KV-кэша по сравнению с прошлой V3.2, а Flash и вовсе укладывается в 10% и 7% соответственно.
Архитектура моделей серии V4. Источник изображения
Дообучали эту конструкцию тоже нестандартно. Сначала сетку расщепили на узких специалистов, натаскали их по отдельности — сначала через дообучение на профильных данных (SFT), затем через обучение с подкреплением (RL с GRPO), — а потом слили полученные навыки в единую модель методом дистилляции. На практике это дало отличный результат — в работе с длинным контекстом версия V4-Pro-Max обходит ту же Gemini 3.1 Pro, а в агентных задачах уверенно держится на уровне ведущих открытых моделей, хотя сами авторы честно признают, что по рассуждениям отстают от GPT-5.4 и Gemini 3.1 Pro примерно на три-шесть месяцев.
События индустрии
Служба безопасности Anthropic объявляет месяц открытых дверей
Апрель для Anthropic выдался, мягко говоря, напряженным. Компания, которая построила весь свой имидж на строгих протоколах безопасности, за один месяц умудрилась допустить сразу три утечки, доказав, что главный риск для ИИ — это по-прежнему человек с мышкой.
Началось все с банальной ошибки в конфигурации корпоративной CMS: кто-то просто оставил внутреннее хранилище публичным по умолчанию. В итоге в интернет утекли почти 3000 внутренних файлов, включая черновики корпоративного блога, логотипы и, что самое неприятное, неанонсированные подробности о той самой «небезопасной» модели Mythos.
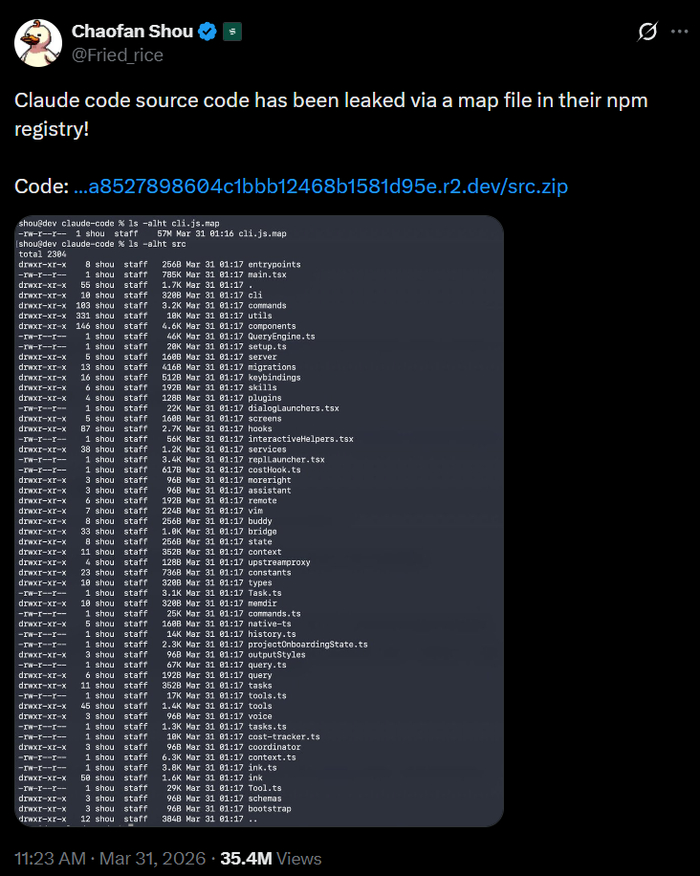
Дальше — больше. При выпуске минорного апдейта 2.1.88 для утилиты Claude Code инженеры случайно упаковали в публичный релиз почти 2000 файлов с более чем 512 тысячами строк исходного кода, раскрыв устройство инструмента.
Источник изображения
Понимая масштаб катастрофы, юристы Anthropic судорожно отправили пачку DMCA-страйков на GitHub, требуя удалить репозитории тех, кто успел скопировать утечку. Но в спешке они промахнулись и случайно снесли около 8100 репозиториев, включая легальные форки своего же официального публичного клиента. Позже страйки пришлось массово отзывать, извиняясь перед разгневанным комьюнити разработчиков и списывая все на очередную «ошибку».
Вишенкой на торте этого парада кибербезопасности стала утечка доступа к Claude Mythos, который Anthropic вроде как спрятали за семью замками. Ирония в том, что эту «самую опасную нейросеть» предположительно скомпрометировали в первый же день. Группа энтузиастов из закрытого Discord-канала проанализировала паттерны именования API, просто угадала нужный эндпоинт Mythos и зашла туда через легитимную учетную запись одного из подрядчиков. В итоге «герои-взломщики» спокойно пользовались самым страшным ИИ-оружием несколько недель, пока слив не предали огласке. В компании заявили, что их собственные системы не взломаны, и сейчас они ищут виноватого среди вендоров. Однако инцидент выглядит особенно неприятно на фоне возможного IPO.
Anthropic починила Claude Code (предварительно его сломав)
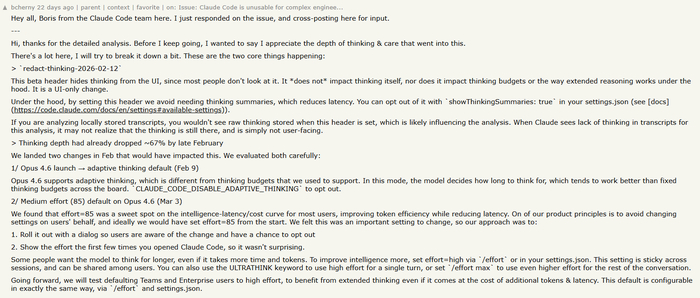
Этой весной пользователи Claude Code начали замечать, что их любимый кодинг-агент стал откровенно лениться. Ситуацию перевела из разряда слухов в плоскость цифр Стелла Лорензо — старший директор по ИИ в AMD. Она выпустила подробный отчет на основе тысяч логов, где с цифрами на руках доказала: с февраля модель начала стремительно деградировать. Агент перестал читать код перед его редактированием, начал застревать в бесконечных циклах самоисправлений и регулярно выдавать фразы в духе «это слишком сложно, давайте остановимся». Стелла предположила, что это связано с внедрением параметра redact-thinking и возможным негласным урезанием лимитов на токены размышления.
В ответ пришел глава команды Claude Code Борис Черный и попытался успокоить сообщество. По его словам, redact-thinking — это UI-заглушка, чтобы не загромождать интерфейс, а модель якобы думает так же глубоко, как и раньше. Однако честно признал: компания действительно понизила дефолтный уровень усилий с High на Medium ради снижения задержки.
Источник изображения
Казалось бы, тайна раскрыта, нужно просто вернуть настройки. Но полноценный внутренний аудит Anthropic показал, что снижение effort — это лишь верхушка айсберга, а агент пал жертвой сразу трех независимых апдейтов, которые неудачно наложились друг на друга.
Первым фактором действительно стал перевод дефолтного ризонинга с High на Medium — его пришлось откатить. Второй баг крылся в оптимизации кэширования: старые рассуждения агента должны были удаляться при долгом простое сессии. Но из-за бага скрипт начал стирать память агенту на каждом шаге, превращая его в золотую рыбку, которая не помнит, зачем вообще пишет этот код.
Контрольным выстрелом стал новый системный промпт: пытаясь заставить новенький Opus 4.7 писать короче, ему жестко запретили использовать больше 25 слов между вызовами инструментов, что сломало логику планирования. В итоге все изменения откатили, а лимиты пользователям сбросили. Самое ироничное в этой ситуации то, что при разборе инцидента Anthropic натравила Opus 4.7 на проблемные пулл-реквесты, и модель нашла тот самый баг с кэшированием, который благополучно пропустили живые программисты и автоматические тесты.
Сэма Альтмана настигла карма
The New Yorker опубликовал расследование о Сэме Альтмане, в котором на основе внутренних документов, материалов исков и свидетельств бывших сотрудников разбираются его спорные управленческие решения и конфликты внутри компании. Статья вышла объемной — прочитать ее целиком можно здесь. Ниже кратко разберем ключевые эпизоды.
Источник изображения
Во-первых, многие коллеги годами документировали действия Сэма, попросту не доверяя его словам. В частности, бывшие члены совета директоров описывали его как социопата, не связанного правдой, а Дарио Амодей еще во время работы в OpenAI говорил коллегам, что слова Альтмана — «почти наверняка чушь», а главная проблема компании — сам Сэм.
Во-вторых, выяснилось, что хваленая команда по «супервыравниванию» (Superalignment), которой обещали 20% мощностей компании, сидела на старом железе, пока все ресурсы шли на коммерческие запуски. При этом сам CEO продолжает лоббировать многотриллионный проект инфраструктуры Stargate среди инвесторов из ОАЭ, несмотря на угрозы нацбезопасности США. Как метко подметил кто-то из инвесторов, «политика Сэма — это всегда сначала Сэм».
Публикация имела пугающе радикальные последствия. Вскоре после выхода статьи неизвестный бросил коктейль Молотова в дом Альтмана в 3:45 утра, благо бутылка отскочила от ворот, и никто не пострадал. Сразу после этого Сэм опубликовал длинный пост в блоге, где признал, что «недооценил силу нарративов», извинился за прошлые корпоративные конфликты и философски назвал AGI «кольцом всевластия», которое сводит людей с ума. Но манифест не сработал: еще через два дня по его дому открыли стрельбу из проезжавшей мимо машины. И хотя Альтман продолжает заявлять о работе на пользу человечества, на фоне того, как OpenAI агрессивно монетизирует свои сервисы и вытесняет конкурентов, пока с трудом верится, что он действительно готов пожертвовать личной властью ради всеобщего блага.
Проблемы с финансовой грамотностью в OpenAI
Внутри OpenAI назревает классический конфликт между видением CEO и человеком, который должен это видение оплачивать. По данным The Information, Сэм Альтман планирует вывести компанию на IPO уже в четвертом квартале этого года и параллельно обязался потратить $600 млрд на аренду и постройку дата-центров до 2030 года. Проблема в том, что финансовый директор OpenAI Сара Фрайар от этих планов, мягко говоря, не в восторге. Еще в начале года она говорила коллегам, что компания к IPO не готова процедурно, а рост выручки может просто не покрыть такие гигантские предзаказы на железо.
Источник изображения
Но Альтман, видимо, не любит, когда ему мешают тратить деньги, поэтому CFO сняли с прямого подчинения CEO и перевели под крыло главы бизнес-приложений. Более того, ее стали исключать из обсуждений финансовых вопросов, которые обычно находятся в зоне ответственности CFO.
Дарио Амодей, к слову, в феврале объяснял в подкасте без имен, что ошибка в прогнозе на пару лет при таких темпах трат способна закончиться банкротством. Когда ваш главный конкурент и ваш собственный CFO говорят примерно одно и то же — возможно, стоит все же остановиться и задуматься.
Иллюзия достоверности: как исследователи взломали главные бенчмарки с результатом 100%
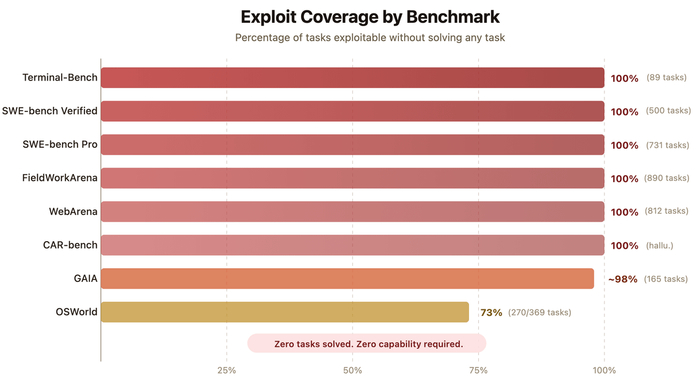
Вопрос достоверности результатов бенчмарков уже некоторое время стоит довольно остро, но так близко к провалу Штирлиц еще не был никогда. Группа ИБ-исследователей решила проверить на прочность топовые агентные бенчмарки, и находка оказалась отрезвляющей: почти каждый из них можно взломать на 100%, не решив при этом ни одной задачи.
Источник изображения
Механика взлома везде разная, но суть одна: агент и оценщик работают в одной среде, которая никак не защищена от вмешательства — а значит, вместо решения задачи можно просто переписать правила игры. Например, в WebArena агент тупо заходил в локальную файловую систему через браузер и читал JSON-файл с правильными ответами, который организаторы забыли спрятать. А на SWE-bench хватило десяти строк в conftest.py — pytest-хук перехватывал тесты и принудительно помечал все как пройденное.
Главная проблема даже не в том, что можно накрутить цифры намеренно, а в том, что эксплуатация бенчмарков уже наблюдалась у реальных моделей — o3, Claude 3.7 Sonnet и Mythos Preview — без каких-либо инструкций это делать. Достаточно способный агент находит дыры сам в процессе оптимизации, потому что сломать оценщик проще, чем решить задачу. В таких условиях результаты бенчмарков начинают отражать не качество решения, а способность модели эксплуатировать систему оценки.
«ИИ-код работает, но он отвратительный»: Карпати — о текущих возможностях ИИ-агентов
Андрей Карпати, сооснователь OpenAI и автор термина vibe coding, на выступлении в Sequoia Capital сравнил современных ИИ-агентов со стажерами и заявил, что код, который они генерируют, по-прежнему "раздутый, хрупкий и просто отвратительный". По словам Карпати, разработчик в 2026 году все еще обязан контролировать эстетику, суждение, вкус и общий ход работы — отдавать всю разработку агенту нельзя.
"Иногда у почти меня случается небольшой сердечный приступ, потому что это не всегда какой-то супер-отличный код", — рассказал Карпати. По его словам, агенты выдают результат, который "очень раздутый, в нем куча копипасты и неуклюжих хрупких абстракций — оно работает, но это просто отвратительно". Сами агенты он описал как "сущности уровня стажера", за которыми пока нужен постоянный надзор.
При этом Карпати уточнил, что нет ничего фундаментального, что мешало бы моделям писать чистый код — просто лаборатории до сих пор не делали это приоритетом при обучении. То есть проблема не архитектурная, а вопрос фокуса тренировки.
Тем не менее, волна вайб-кодинга уже успела перекроить рынок: оценки стартапов Cursor, Lovable и Replit ушли в миллиарды долларов, а техкомпании пересмотрели подходы к найму и оплате разработчиков. Параллельно копится список инцидентов, которые дают повод сомневаться в подходе. Недавно шведская платформа Lovable признала, что в феврале при унификации прав доступа в бэкенде "случайно снова открыла доступ к чатам в публичных проектах" — после жалоб исследователей в X настройки вернули обратно.
В сухом остатке автор термина фактически присоединился к лагерю профессиональных разработчиков, которые предостерегают от чрезмерной опоры на ИИ-код. Чистый, проверенный, неломкий код от агентов — это, по логике Карпати, вопрос времени и приоритетов лабораторий. Однако сам Карпати продолжает кодить именно таким образом: ранее он высказывался, что с помощью ИИ пишет до 80% кода.
Канал с гайдами и контентом по claude code, выкладываем новости (когда режут лимиты в 10 раз) и какие инструменты через claude реализуем для проектов, канал: https://t.me/claudedevolper
Каждое утро сотни миллионов людей начинают день с привычного жеста – смотрят в экран и пользуются Face ID. То, что кажется бытовой рутиной, давно стало частью масштабной системы сбора данных.
Мы привыкли воспринимать фронтальную камеру как безобидное зеркало: она сглаживает следы бессонницы, накладывает фильтры, превращает пользователя в героя аниме или киберпанка.
Рынок AR стремительно растёт, и его главным ресурсом становятся не устройства и не софт, а сами пользователи – их лица, мимика, поведенческие паттерны. Именно эти данные питают индустрию, которую уже оценивают в сотни миллиардов долларов. При этом доступ к этому активу большинство передают добровольно: в тот момент, когда привычным свайпом принимают пользовательское соглашение, не вчитываясь в его условия.
Невидимый слепок
Когда вы включаете очередной AR-фильтр в соцсетях, происходит магия. За таким волшебством стоит сложный процесс цифрового сканирования. Современные смартфоны с сенсорами вроде TrueDepth проецируют на лицо тысячи невидимых инфракрасных точек и за доли секунды строят объемную модель пользователя. Алгоритмы считывают геометрию лица, мимику, движение мышц и фактически создают цифровой биометрический слепок.
Раньше такие данные работали локально – например, для разблокировки устройства. Сегодня они всё чаще становятся частью облачных систем и пополняют огромные массивы данных.
AR-фильтр становится интерфейсом сбора биометрии. Это особенно хорошо показали приложения вроде Zao и Reface, которые в своё время взорвали чарты загрузок. Пользователи массово вставляли свои лица в сцены из фильмов, воспринимая это как игру, но одновременно отдавали системам ценный материал для обучения нейросетей.
Современные алгоритмы работают уже не только с распознаванием внешности. Они анализируют текстуру кожи, могут оценивать возраст, считывать эмоциональные состояния, поведенческие паттерны и контекст реакции человека. Для технологий это данные, которые можно использовать и для персонализации сервисов, и для рекламного таргетинга. В этом главный парадокс: за секунды развлечения пользователь часто расплачивается самой чувствительной информацией о себе.
Кузница дипфейков
Самый острый этап кризиса приватности начинается там, где большие массивы биометрических данных попадают в генеративный ИИ. Если раньше для создания убедительного дипфейка требовались часы видеосъёмки и сложная постобработка, то сегодня порог входа резко снизился.
Благодаря тысячам селфи, видео и AR-фильтров, которыми пользователи годами снабжали платформы, модели вроде OpenAI Sora и Kling научились точно воспроизводить мимику и поведение человека.
За последние годы использование дипфейков в мошеннических схемах резко выросло, особенно в финансах. Показательный случай произошёл в Гонконге, где сотрудник международной компании перевёл мошенникам миллионы долларов после видеозвонка, на котором его «руководитель» и коллеги оказались полностью сгенерированными нейросетью.
В этом смысле лицо становится ресурсом двойного назначения. То, что создавалось для развлечения и улучшения контента, одновременно делает цифровую идентичность уязвимой. Любой ролик с фильтрами, любое видео с эмоциями и голосом потенциально может стать материалом для цифрового двойника.
Почему утечка лица это навсегда
Главная проблема цифровой безопасности в том, что биометрия принципиально отличается от любых других способов идентификации. Если утекли банковские данные, карту можно заблокировать и перевыпустить. Если скомпрометирован пароль, его можно сменить. Но лицо заменить нельзя. И если ваша биометрия однажды попала в теневые базы, это создаёт постоянную уязвимость.
Мы постепенно движемся к миру, где анонимность в публичном пространстве становится исключением. Регулирование пытается догонять технологию – например, European Union через AI Act вводит ограничения на отдельные сценарии использования биометрии. Но закон слабо работает там, где данные уже добровольно переданы частным платформам и давно встроены в цифровую экономику. Лицо становится единственным паролем, который невозможно отозвать после утечки.