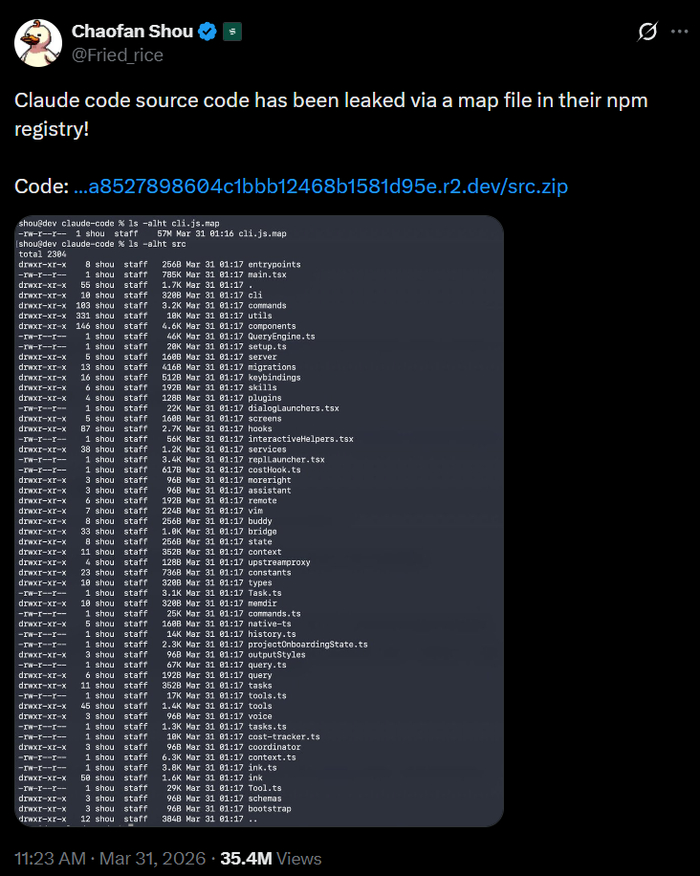
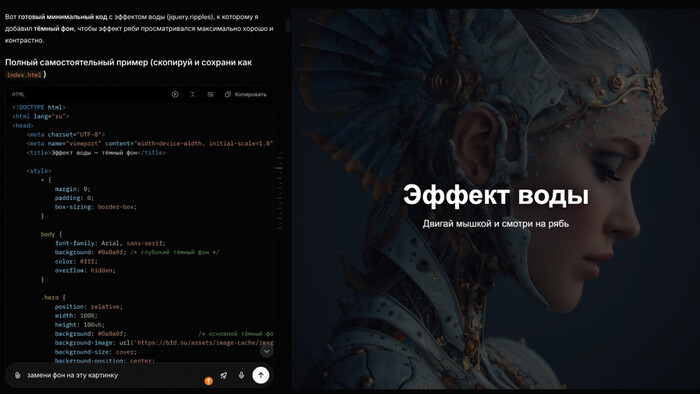
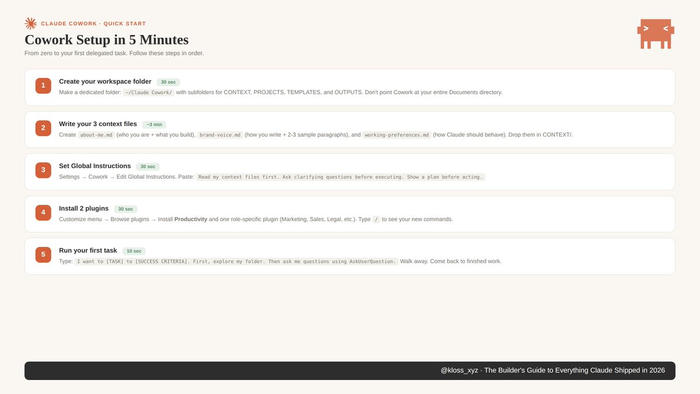
Полез на днях писать новый скилл process-logs для рабочего проекта — обработка логов ошибок из админки. Получилось 663 строки и 36 капс-блоков: «CRITICAL REQUIREMENTS», «YOU MUST FOLLOW THESE RULES. NO EXCEPTIONS», «ALWAYS run this FIRST», «MANDATORY», «NEVER ignore errors». Каждый второй раздел начинается с императива.
Канал с гайдами и контентом по claude code, выкладываем новости (когда режут лимиты в 10 раз) и какие инструменты через claude реализуем для проектов, канал: https://t.me/claudedevolper
Логика была простая: чем подробнее опишу — тем меньше у модели шансов промахнуться.
И тут OpenAI выкатил гайд по промтингу GPT-5.5. Прямым текстом: вы делаете не так. Я полез проверять — действительно делаю не так. Самое неприятное — на Claude Opus 4.7, с которым я провожу по 12 часов в день, ровно та же история.
Эта статья — продолжение прошлой. Месяц назад упрощал стек. Теперь придётся упростить и промты внутри стека.
Что говорит OpenAI
Не буду пересказывать гайд (он короткий, прочитайте сами), но вытащу пять тезисов, которые ломают привычный подход.
Первый — про длину. Прямая цитата:
“Shorter, outcome-first prompts usually work better than process-heavy prompt stacks.”
Грубый перевод: короткие промты, описывающие результат, работают лучше, чем тяжёлые стэки с пошаговым процессом. Не «иногда лучше». Usually.
Второй — про миграцию. OpenAI отдельно предупреждает: не переносите старые промты на новую модель.
“Avoid carrying over every instruction from an older prompt stack.”
Это особенно неприятно слышать тем, кто годами обрастал шаблонами. Я в их числе.
Третий — про императивы. ALWAYS/NEVER/MUST оставляем для true invariants. Для всего, что является judgment call (а это большинство инструкций), убираем. Что такое «true invariant»? Например, «не выполняй удаление файлов без явного подтверждения» — это инвариант, нарушение приведёт к катастрофе. А «всегда сначала проанализируй, потом пиши код» — это рекомендация. Модель должна сама решить, нужен ей анализ или задача очевидна. Различие тонкое, но как только начинаешь его держать — половина капс-блоков в твоих промтах оказывается на стороне рекомендаций.
Четвёртый — про стоп-условие. Минимум доказательств:
“Use the minimum evidence sufficient to answer correctly, cite it precisely, then stop.”
Stopping condition — это новое в гайде. Раньше учили модель «думать тщательно», теперь — «думай ровно столько, сколько нужно, и останавливайся». Иначе модель уходит в overthinking: продолжает анализ там, где задача уже решена, добавляет соображения сверху уже готового ответа, размывает фокус.
Пятый — про reasoning effort. OpenAI прямо пишет: это «last-mile knob», а не основной рычаг качества. Если результат плохой — не крутите effort вверх. Перепишите промт.
Ну ничего себе. Большая часть моего opinion-формирования за последний год про prompt engineering — мимо.
Главный диф: process-logs «до и после»
Покажу на реальном коде. У меня в одном из рабочих проектов живёт скилл process-logs — берёт ошибки из админки, классифицирует, создаёт задачи в трекере, фиксит, закрывает. Бизнес-задача рутинная, скилл в продакшене, версия 1.9.0.
Вот одна секция из него — называется «BUG FIXING PRINCIPLES»:
### 4. BUG FIXING PRINCIPLES> **This is PRODUCTION. Every bug matters.****Fix fundamentally, not superficially:**- Find and fix the ROOT CAUSE, not just symptoms- If error happens in function X but cause is in function Y → fix Y- Don't add workarounds/hacks that mask the problem- Ask: "Why did this happen?" until you reach the actual cause**Never ignore errors:**- Every error indicates a real problem- "Works most of the time" is NOT acceptable- External service errors → add retry logic or graceful degradation- Config warnings → fix config or make truly optional**Propose improvements:**- If you see code that could be better → create separate Beads task- If fix reveals related issues → document them- If pattern repeats → suggest refactoring to prevent future bugs**Quality over speed:**- Take time to understand the full context- Test the fix mentally: "What else could break?"- Check for similar patterns elsewhere in codebase- One good fix > multiple quick patchesОбъяснить с
134 слова, четыре блока с буллетами, четырнадцать пунктов. Я писал это три месяца назад, был уверен, что закрываю все возможные сценарии.
Перечитываю сейчас по новым правилам OpenAI и вижу четыре проблемы.
Дублирование одной мысли. «Fix root cause», «not symptoms», «not workarounds», «not just patches» — четыре формулировки одного и того же. Модель получает одну мысль четыре раза и начинает переусиливать: будет копать вглубь даже там, где причина очевидна. Это antipattern в чистом виде — то самое «narrowing the search space», от которого предостерегает гайд.
Judgment под видом invariant. «Quality over speed» звучит здорово, но это рекомендация, а не инвариант. Иногда быстрый патч важнее идеального решения — продакшн горит, надо хоть как-то заткнуть до утра, а потом фундаментально починить. Я зашил императив там, где должен был дать модели контекст и право решать.
Нет stopping condition. Когда фикс готов? По текущему промту — никогда. «Test the fix mentally: what else could break?» можно делать бесконечно. Модель не понимает, в какой точке остановиться, и в результате либо недокапывает (если устала от длинного промта), либо перекапывает (если решила следовать букве).
Императивы на judgment calls. «Never ignore errors» звучит правильно, но в реальной жизни часть ошибок именно надо игнорировать. В этом же скилле — отдельная таблица из 60 правил auto-mute: какие паттерны автоматически считать ожидаемым поведением и не разбирать. Промт сам себе противоречит: одна секция говорит «никогда не игнорируй», другая — «вот 60 паттернов, которые надо игнорировать».
Переписал по новым правилам OpenAI:
### Bug fix outcomeGoal: production stays clean. Each fix addresses the root cause,not symptoms. A clean fix is one where you can answer "why didthis happen?" in one sentence — without saying "external timeout"or "works most of the time".Stopping criteria: similar pattern checked, fix is committed,related issues documented as separate Beads tasks. Don't expandscope into refactoring unless explicitly asked.Объяснить с
50 слов вместо 134. Одна мысль про root cause — один раз. Outcome (что значит «чисто») вместо процесса (как именно копать). Явный stopping criteria. Отдельная фраза про границы — «не расширяй скоуп», чтобы модель не уезжала в рефакторинг соседних модулей.
Я специально проверил на двух моделях. Дал каждой реальную ошибку из логов — getaddrinfo EAI_AGAIN во время деплоя — и оба варианта промта. Короткий выиграл на обеих: и Opus 4.7, и GPT-5.5 корректно классифицировали это как infrastructure (DNS-резолюция падает на момент рестарта подов), не пытались чинить application-код, не предлагали рефакторинг. Длинный вариант на обеих моделях привёл к тому, что они дополнительно полезли в код вокруг DNS-вызовов — искать, что там можно «улучшить».
Это не строгое измерение. Это один прогон. Но направление совпадает с тем, что говорит гайд.
Эксперимент в Stitch, который можно повторить за пять минут
Хочу, чтобы вы убедились сами, без слепой веры мне или OpenAI. Самый быстрый способ — Google Stitch. Это инструмент для генерации UI-экранов по описанию, у него свой движок, и реакция на формулировку промта там видна почти моментально.
Возьмите два промта на одну и ту же задачу.
Промт А — жёсткий и подробный (примерно так пишет одна модель, когда её просишь сгенерировать промт для другой):
Создай экран онбординга для AI-приложения. Используй карточки 16:9 с тенью box-shadow: 0 4px 12px rgba(0,0,0,0.08). Заголовок 32px, подзаголовок 18px, отступы 24px, межблочные 16px. Цвета: primary #2563EB, secondary #F1F5F9, текст #0F172A. Кнопка CTA в правом нижнем углу, hover state с увеличением тени. Анимация slide-in 300ms ease-out. Иконки из Lucide, размер 24px, цвет primary. Прогресс-индикатор сверху, 4 шага. Объяснить с
Промт Б — смысловой и короткий:
Экран онбординга для AI-приложения. Должен ощущаться лёгким, дружелюбным, без бюрократии. Цель — чтобы новичок захотел дойти до конца за 30 секунд. Объяснить с
Прогоните оба в Stitch на одной и той же задаче. Сравните, что получилось.
У меня — десятки прогонов за последний месяц — промт Б выигрывает почти всегда. Не потому что я случайно подобрал плохой пример А. А потому что когда вы зажимаете модель в техническую решётку — отступы, цвета, шрифты — она перестаёт делать дизайн. Она начинает заполнять решётку. Получается аккуратно. И мёртво.
Кстати, это работает не только в Stitch и не только с дизайном. Есть отдельный антипаттерн, который я только сейчас осознал и хочу проговорить отдельно. Если попросить модель написать промт для другой модели — она напишет ровно тип А. Подробный, технический, с императивами. Потому что её саму так учили: чем точнее — тем лучше. И этот промт потом получает другая модель и работает по нему хуже, чем работала бы по короткому, написанному человеком.
Я сейчас целенаправленно перестаю генерировать промты через модели. Промт пишу руками. Модель — исполняет.
А что говорит Anthropic про Claude
Гайд OpenAI — про GPT-5.5. Я в Claude Code сижу больше времени, чем в чём-либо другом. Вопрос: применимо ли?
Полез смотреть, что говорит Anthropic. У них есть курс по prompt engineering и набор «real world prompting» ноутбуков. Тон — другой. Anthropic не говорит «выкиньте инструкции». Anthropic говорит: используйте структуру, оборачивайте данные в XML-теги (<patient_record>, <email>, <thinking>), отделяйте инструкции от контекста, кладите длинные документы в начало промта, инструкции — в конец.
Но если посмотреть их примеры хороших промтов — ALWAYS/NEVER там нет. Их «улучшенный промт» для медицинских саммари — это outcome-описание: «нужны такие-то поля в таком-то порядке, обёрнутые в XML-теги». Не процесс. Описание ожидаемого результата плюс структура.
Это сходится с OpenAI в духе. Расходится в букве:
OpenAI: outcome + constraints, минимум структуры, всё остальное модель решит сама.
Anthropic: outcome + структура (XML-теги, чёткое разделение), модель решит сама внутри структуры.
В моём ежедневном опыте оба тезиса работают. Когда я переписывал свой агент code-reviewer (короткий, делегирует всё на skill) — поймал именно это: структура помогает, императивы вредят. Скилл был полностью на капс-инструкциях, переписал на outcome + XML-структуру (что входит, что выходит, какие критерии «хорошо»). Стало работать заметно лучше — и на Claude, и на GPT.
Самый честный ответ на вопрос «применимо ли»: да, применимо в духе. Принцип «не зажимайте модель в рамки» работает на обеих. Различие — в том, насколько структуру нужно эксплицитно прописать. На Claude чуть больше структуры (XML, разделители). На GPT-5.5 — чуть меньше, и больше доверия модели.
Нет, подождите, не «больше доверия» — это слишком расплывчато. Точнее: меньше попыток управлять процессом. На GPT-5.5 промт описывает «куда прийти и каких границ не пересекать». На Claude — «куда прийти, в какой структуре сложить ответ, и каких границ не пересекать».
И ещё одно наблюдение про передачу промтов между моделями. Если попросить Opus 4.7 написать промт для GPT-5.5 — Opus напишет очень структурированно, с разделами, XML-тегами, явными success criteria. Это избыточно для GPT-5.5, и GPT начинает вязнуть в структуре. Обратное тоже работает: GPT-5.5 пишет для Claude слишком сжато, без структуры, и Claude не понимает, где границы между context и task. Промты под конкретную модель пишу руками. Кросс-модельная генерация ломается.
Что меняю в orchestrator-kit прямо сейчас
Я в процессе. Не из позиции «всё уже переписал», а из позиции «увидел, начал чинить».
Что уже сделано: в скиллах для написания промтов добавил явное правило — не переусложняй промт. Когда я прошу модель сгенерировать новый скилл, она теперь не уходит в простыню инструкций, а старается описать через outcome.
Что в работе: переношу это в основные файлы памяти (CLAUDE.md, ~/.claude/CLAUDE.md). Это глобальный системный промт, он загружается в каждую сессию. Если модель там увидит «пиши outcome-промты, не процесс» — будет применять это ко всему, что генерирует.
Что в очереди: пройтись по самым жирным скиллам в моём kit. Текущий список:
dzen-article — 758 строк, скилл для написания статей на Дзен
process-logs — 663 строки (тот, на котором показывал диф)
process-issues — 501 строка
algorithmic-art — 404 строки
Каждый — пачка капс-блоков и дублирующихся требований. План: один скилл за раз, с прогоном на реальной задаче «до и после», с замером качества. Не быстро. Но это инвестиция, которую я хочу окупить за следующие три месяца — там, где скиллы запускаются десятки раз в день, разница в качестве и стоимости токенов ощутимая.
Где императивы оправданы
Чтобы не выглядело как евангелизм коротких промтов — отдельно про три категории, где императивы остаются.
Safety-критичные операции. У меня в kit есть агент dead-code-remover — удаляет неиспользуемый код. Там прямо написано: «CRITICAL SAFETY RULE: NEVER DELETE FILES AUTOMATICALLY. File removal requires MANUAL verification and is NEVER automated». Это true invariant. Удалить файл случайно — это не «качество немного просядет», это «потерянная работа без бэкапа». Императив здесь нужен, и я его не убираю.
Контракты и схемы. Если модель генерирует JSON-ответ для API, и схема жёстко задана — поле id всегда строка, status всегда из перечня — это не judgment, это технический контракт. Императив оправдан. Без него модель будет «творчески» интерпретировать схему, и через час вы получите 500-е на проде.
Детали, которые модель должна выполнить буквально. Например, имя файла миграции в формате YYYYMMDD_HHMMSS_description.sql — порядок применения определяется именно по таймстампу в начале, и любое отклонение сломает накат на новой среде. Это не «как лучше», это «должно быть так и не иначе, потому что миграционный фреймворк парсит имя». Императив — единственный надёжный способ.
Различие, которое я для себя вытянул: ALWAYS/NEVER — для invariants (нарушение приведёт к катастрофе или сломает контракт). Не для preferences (нам так больше нравится). Это, кстати, прямо соответствует тому, что пишет OpenAI: «Use rigid absolute rules for true invariants». Раньше я не отличал invariant от preference. Теперь буду.
Финал
Длинные промты с императивами на каждом шагу — это след времён, когда модели плохо держали контекст и нуждались в постоянных подсказках. Те модели ушли. Те промты — пора.
Не «выкидывайте всё подряд». А пересмотрите конкретно: где invariant, где preference, где outcome, где stopping condition. Я разбираю свои скиллы и агенты именно с этой рамкой. Будут результаты — напишу.
Канал с гайдами и контентом по claude code, выкладываем новости (когда режут лимиты в 10 раз) и какие инструменты через claude реализуем для проектов, канал: https://t.me/claudedevolper
Представьте типичную ситуацию: вам нужно настроить очередной обработчик потоковых данных. Вы открываете документацию на 200 с лишним страниц, где описаны десятки типов источников, трансформаций, фильтров и политик обработки ошибок. Ищете нужные параметры в разделах про Kafka, RabbitMQ/ArtemisMQ, GRPC, PostgreSQL и так далее. Вспоминаете синтаксис DSL — а он различается для разных типов операций. Копируете похожую конфигурацию из прошлого проекта, найденную в корпоративном Git‑репозитории, и правите её под новые требования. Переключаетесь между вкладками браузера с документацией и IDE.
Канал с гайдами и контентом по claude code, выкладываем новости (когда режут лимиты в 10 раз) и какие инструменты через claude реализуем для проектов, канал: https://t.me/claudedevolper
На это уходит от 30 минут до нескольких часов, а в итоге всё равно можно допустить ошибку в синтаксисе, неправильно сконфигурировать источник данных или пропустить важный параметр безопасности.
А что, если сократить этот процесс до 30 секунд? Просто описать задачу на естественном языке — «Настрой обработчик для фильтрации событий от Kafka, оставь только записи с user_id больше 1000 и приоритетом high, результат отправь в новый топик» — и получить готовую конфигурацию, адаптированную под специфику нашего продукта. Не абстрактную YAML или CONF-заготовку, которую ещё нужно подгонять под продукт, а конфигурацию с правильными параметрами, корректным синтаксисом DSL для трансформаций и с соблюдением архитектурных паттернов продукта, готовую к проверке и применению в промышленной среде.
В этой статье я расскажу, как мы создали систему автоматического генерирования конфигураций для одного из компонентов нашего продукта, используя RAG (Retrieval-Augmented Generation), векторные базы данных и межагентное взаимодействие по протоколу A2A.
Немного о проблематике
Инженеры, работающие с системами потоковой обработки данных, ежедневно сталкиваются с необходимостью создавать конфигурации для различных систем. Это обработчики данных, сложные многошаговые трансформации, политики обработки ошибок, правила маршрутизации событий между сервисами. При этом приходится изучать объёмную документацию на сотни страниц, где каждый компонент системы описан в отдельном разделе.
Разработчик должен помнить синтаксис множества форматов: YAML/JSON для основных конфигураций, специфичные форматы для описания политик безопасности. Но самое сложное — работа с проприетарным DSL для описания трансформаций данных. Создание одной конфигурации средней сложности занимает от 30 минут до нескольких часов. За это время инженер переключается между задачами, теряет контекст, отвлекается на поиск информации.
Классический подход — копипаст из предыдущих проектов с ручными правками — не только медленный, но и чреват ошибками. Каждая опечатка в имени параметра, неверный отступ в YAML, забытый обязательный параметр или устаревшая версия синтаксиса из старой конфигурации превращается в потерянное время на отладку. А если речь идёт об эксплуатационной среде, то цена ошибки может быть очень высокой.
Более того, документация постоянно обновляется. Появляются новые параметры, некоторые становятся deprecated, меняются рекомендации. Инженер может не знать о последних изменениях и использовать устаревшие подходы. Особенно остро эта проблема стоит с проприетарными DSL: в отличие от стандартных форматов вроде YAML или JSON, для которых есть множество примеров в интернете, специфичный синтаксис трансформаций описан только в корпоративной документации.
Специфика DSL для трансформаций
В Platform V Synapse Streaming Event Processing используется проприетарный DSL для описания трансформаций потоковых данных — tr-файлы. Это декларативный язык, специально разработанный для наглядного описания трансформаций без необходимости писать императивный код на Java или Python.
DSL позволяет описывать маппинг полей — преобразование структуры входящего события в требуемую структуру выходного, с переименованием полей, извлечением вложенных значений из JSON, объединением нескольких полей в одно. Фильтрация событий реализована через выражения с поддержкой сложных условий, логических операторов, функций для работы с датами, строками, числами, регулярными выражениями. Есть обогащение данными из внешних источников. Система поддерживает работу с окнами агрегации, группировку по ключам и применение агрегирующих функций.
Для LLM этот DSL нестандартный, его не было в обучающей выборке GigaChat или других публичных моделей. Модель не может просто «вспомнить» синтаксис, как это было бы с Python или SQL. Попытка сгенерировать tr-файл без дополнительного контекста приводит к галлюцинациям: модель может выдумать несуществующие функции, использовать синтаксис от других похожих языков, перепутать порядок секций.
Именно поэтому RAG становится не просто улучшением, а критически необходимым компонентом системы. Без доступа к актуальной документации и примерам невозможно корректно сгенерировать конфигурации на проприетарном DSL.
От идеи до готовой конфигурации за 30 секунд
Мы создали систему, которая за считанные секунды превращает естественно-языковое описание требований в корректную конфигурацию. Ключевая идея — использовать саму документацию продукта как источник знаний для искусственного интеллекта, а не пытаться обучить модель с нуля на специфичном DSL.
Процесс начинается с подготовительного этапа: загрузки всей документации по продукту в векторную базу данных. Мы берём официальную документацию в формате Markdown, специальный сервис разбивает документы на логические фрагменты (чанки) и превращает их в векторные представления — эмбеддинги. Этот процесс нужно выполнить только один раз при первоначальной настройке системы, далее векторная база обновляется только при изменении документации.
Инженер описывает требования к конфигурации на естественном языке, и магия начинается.
Запрос может быть сформулирован просто и понятно: «Создай обработчик, который читает события из топика user-actions, фильтрует только события типа purchase с суммой больше 1000 рублей, обогащает данными о пользователе из дополнительного топика и отправляет результат в топик high-value-purchases». Система не требует знания точного синтаксиса или имён параметров — она сама найдёт нужную информацию в документации.
Система анализирует запрос и через механизм RAG находит в документации релевантный контекст. Это не простой полнотекстовый поиск по ключевым словам, а семантический поиск по смыслу. Система понимает, что «читает события из топика» связано с разделом документации про источники Kafka, «фильтрует только события типа purchase» требует конфигурации фильтров, а «отправляет результат в топик» — настройку destination.
LLM получает найденные фрагменты документации и генерирует готовую конфигурацию с учётом контекста. Модель не просто генерирует текст наугад — она опирается на конкретные примеры из документации, использует правильные имена параметров, соблюдает синтаксис.
В результате получается конфигурация, которую можно сразу применить без дополнительной доработки, все обязательные параметры заполнены корректными значениями, соблюдены требования к структуре конфигурационных файлов продукта согласно текущей версии, применён корректный синтаксис DSL для трансформаций (если требуется).
Это означает, что инженеру не нужно тратить время на поиск документации по версиям продукта, вспоминать специфичные имена параметров или разбираться в тонкостях синтаксиса DSL: система делает это автоматически на основе актуальной документации.
Но генерирование это только половина дела.
Во время создания конфигурации агент-генератор по протоколу A2A вызывает агент-валидатор. Тот получает сгенерированную конфигурацию и исходный запрос пользователя, после чего проверяет, действительно ли конфигурация решает поставленную задачу? Все ли обязательные параметры указаны? Нет ли логических ошибок или потенциальных проблем с производительностью? Валидатор может ответить «конфигурация корректна» или запросить исправления: «в секции filters пропущен обязательный параметр field_name» или «для production-среды рекомендую добавить SSL-подключение».
Агенты итеративно взаимодействуют до получения валидной конфигурации. Это может занять несколько циклов: генератор создаёт первую версию, валидатор находит проблемы, генератор исправляет с учётом замечаний, валидатор проверяет снова. Обычно требуется от одной до трёх итераций. Этот процесс полностью автоматический и занимает секунды, а не часы ручной отладки.
После того как конфигурация прошла ИИ-проверку, её можно дополнительно проверить статическими методами. Config Validator проверяет, что YAML синтаксически корректен, JSON-схемы корректны, а если конфигурация предназначена для развёртывания в Kubernetes — проверяет соответствие спецификации манифеста.
Можно настроить кастомные проверки через регулярные выражения: например, убедиться, что имена топиков соответствуют корпоративному соглашению об именовании (naming convention). Готовый результат можно сразу применить в кластере через встроенный механизм развёртывания или скопировать и использовать в существующем CI/CD pipeline.
Векторные базы данных: как ИИ понимает документацию
Прежде чем перейти к архитектуре, разберёмся с фундаментом системы — векторными базами данных и механизмом эмбеддингов. Это ключевая технология, которая делает возможным семантический поиск и контекстуальное генерирование.
Что такое эмбеддинг
Эмбеддинг — это способ представить текст в виде числового вектора фиксированной длины, обычно от 384 до 1536 измерений в зависимости от модели.
Каждое число в этом векторе — это координата в многомерном пространстве, где расположение точки отражает семантический смысл текста. Ключевая особенность эмбеддингов в том, что семантически похожие тексты имеют близкие векторы, и тексты можно найти, вычислив расстояние или косинусное сходство между векторами.
Например, рассмотрим три фразы из документации: «источник Kafka» может быть представлен вектором [0.82, -0.33, 0.15, 0.67, ...], «Kafka input» — вектором [0.81, -0.35, 0.14, 0.65, ...], а «читать из очереди сообщений» — [0.77, -0.33, 0.14, 0.63, ...].
Все три фразы описывают похожую концепцию получения данных из брокера сообщений, и их векторные представления будут близки друг к другу в многомерном пространстве. Расстояние между первым и вторым вектором будет маленьким, а между первым и совершенно не связанной фразой вроде «настройка сетевых политик» — гораздо больше.
Важно понимать, что эмбеддинги не просто считают количество общих слов. Модель, создающая эмбеддинги, обучена на огромных объёмах текстов и понимает контекст, синонимы, связи между концепциями. Поэтому «Kafka source» и «читать из топика» будут иметь близкие эмбеддинги, даже если у них нет общих слов.
Индексация документации
При загрузке документа в систему происходит несколько важных этапов обработки.
Сначала документ делится на смысловые фрагменты — чанки. Это критически важный этап, потому что качество разбиения напрямую влияет на качество поиска. Слишком маленькие чанки теряют контекст, слишком большие — становятся неспецифичными и могут содержать несколько несвязанных тем.
Размер чанка мы настраиваем в зависимости от специфики документации. Для справочной документации с короткими описаниями параметров оптимальный размер — 256-512 токенов. Мы используем перекрытие (overlap) между чанками размером 10-20% от размера чанка. Это означает, что последние несколько предложений одного чанка повторяются в начале следующего. Зачем? Чтобы сохранить контекст на границах. Если описание какой-то концепции попадает на границу между чанками, то перекрытие гарантирует, что в одном из чанков описание будет представлено целиком.
Каждый чанк превращаем в вектор с помощью модели Embeddings от Сбера. Мы выбрали её, потому что она специально обучена на русском языке и создаёт качественные семантические представления русскоязычных технических текстов. Модель понимает специфичную терминологию, аббревиатуры, технический жаргон.
Векторные представления сохраняются в Platform V Vector DB — специализированной векторной базе данных, предназначенной для высокопроизводительного семантического поиска. Вместе с векторами мы храним исходный текст фрагмента и метаданные: источник документа, раздел, дату обновления, теги (например, kafka, filters, security). Это позволяет точно искать с фильтрами — например, только по материалам для Kafka или только по разделам, связанным с безопасностью.
Скажем, документ с правилами конфигурирования сетевых политик можно разбить так: чанк «Запретить весь входящий трафик по умолчанию» получит вектор [0.76, -0.21, 0.94, ...] и метаданные {source: "network-policy.yaml", section: "ingress-rules", tags: ["security", "network"]}, а следующий чанк «Разрешить порт 80 только из namespace frontend» получит свой вектор [0.68, -0.19, 0.91, ...] и похожие метаданные. При поиске по запросу «настроить доступ к сервису только для фронтенда» система найдёт оба этих чанка как релевантные, причём второй получит больше баллов.
RAG: Retrieve-Augment-Generate
Давайте разберёмся, почему простого использования LLM недостаточно для нашей задачи. Современные языковые модели, такие как GigaChat, GPT или Claude, обладают впечатляющими способностями к генерированию текста и пониманию контекста. Но у них есть фундаментальные ограничения.
Во-первых, модель может не знать специфики вашей документации. GigaChat обучен на публичных данных из интернета, но нашей внутренней документации по Platform V Synapse Streaming Event Processing, проприетарного DSL и корпоративных стандартов в обучающей выборке не было.
Во-вторых, знания модели ограничены датой обучения. Если последнее обучение было полгода назад, а за это время вышло три обновления продукта с новыми параметрами, то модель об этом не знает.
В-третьих, модель может «галлюцинировать»: выдумывать несуществующие параметры, смешивать синтаксис разных версий, генерировать правдоподобно звучащие, но некорректные конфигурации.
RAG (Retrieval-Augmented Generation) — это архитектурный паттерн, где модель не полагается только на знания, полученные при обучении, а сначала получает актуальный контекст из внешнего источника — в нашем случае из векторной базы с документацией. Это принципиально меняет подход: модель становится не источником знаний, а интерпретатором документации, который умеет понимать запрос пользователя и правильно применять информацию из найденных фрагментов.
Три этапа RAG
Retrieve (Поиск). Когда пользователь вводит запрос, система не сразу отправляет его в LLM. Сначала запрос векторизируется — превращается в эмбеддинг той же моделью Embeddings, которая использовалась для индексации документации. Получается вектор запроса. Затем система ищет в векторной базе данных чанки с наиболее похожими векторами, вычисляя косинусное сходство между вектором запроса и векторами всех чанков в базе.
Это семантический поиск: мы ищем не по точным совпадениям слов, а по смыслу. Например, запрос «настроить фильтрацию событий по полю timestamp больше вчерашней даты» найдёт релевантные фрагменты, даже если в документации используются другие формулировки вроде «временная фильтрация», «отсечение по времени», «filter by time field» или примеры с другими названиями полей. Модель понимает, что все эти фразы семантически близки.
Система возвращает топ-K наиболее релевантных чанков, обычно K=3-5. Больше не всегда лучше: слишком много контекста может запутать модель, увеличивает токены в промпте (а значит, стоимость и время обработки), может включить менее релевантную информацию. Мы экспериментально подобрали оптимальное значение для нашей системы.
Augment (Обогащение). Найденные чанки не просто конкатенируются, они структурируются и форматируются. Формируется промпт, состоящий из нескольких секций. System_prompt задаёт роль агента и правила поведения, вот часть системного промта:
Ты — генератор конфигурационных файлов и DSL-трансформаций для Cloud Event Processing, действующий строго по спецификации и переданному контексту.Основные требования:Используй только информацию из этого промпта.Генерируй только синтаксически и семантически валидные конфигурации и DSL-файлы по спецификации или переданному контексту.Все обязательные поля должны быть заполнены. Если невозможно корректно заполнить обязательное поле — не генерируй файл.Не используй конструкции, блоки, параметры, функции или синтаксис, не описанные в спецификации или переданном контексте. Любое отклонение — ОШИБКА.Не добавляй пояснений, описаний, комментариев или вымышленных элементов ни в одном из файлов.Если необходимы несколько файлов (например, config и transform), выводи каждый с указанием имени и расширения отдельным блоком.Для улучшения качества генерирования используй информацию, переданную в поле контекст.Имя и расширение файла — первой строкой блока. Дубли имён не допускаются.
Context включает в себя релевантные фрагменты из документации, отформатированные специальным образом. Каждый фрагмент предваряется заголовком, указывающим источник: «Из раздела "Конфигурация источников Kafka":», «Пример из документации:», «Best practice:». Это помогает модели понять, какая информация откуда взята и как её следует интерпретировать. Если найдены примеры кода, то они включаются целиком с комментариями.
User_request — это исходный запрос пользователя, возможно, слегка переформулированный для ясности. Например, если пользователь написал «сделай обработчик как в прошлый раз, только для другого топика», то система может попросить уточнить подробности.
Generate (Генерирование). Полностью сформированный промпт отправляется в GigaChat. Важный нюанс: мы используем специфичные параметры генерирования. Temperature (температура) установлена на относительно низкое значение около 0,5, это делает генерирование более детерминированным и предсказуемым, что критично для генерирования кода и конфигураций. High temperature (0,8-1,0) хороша для творческих задач, но в нашем случае может привести к «творческим интерпретациям» синтаксиса.
LLM генерирует ответ, опираясь как на свои базовые знания о форматах YAML/JSON и общих принципах конфигурирования, так и на предоставленный контекст из документации. Это гарантирует, что конфигурация будет соответствовать актуальной спецификации продукта, использовать правильные имена параметров, соблюдать версию API, следовать лучшим корпоративным практикам.
Микросервисная архитектура решения
Система построена как набор независимых микросервисов, что обеспечивает гибкость, масштабируемость и возможность обновления отдельных компонентов без остановки всей системы.
Каждый сервис — это отдельный Docker-контейнер с собственной конфигурацией ресурсов, политиками restart, health check endpoints. Взаимодействие между сервисами происходит по REST.
UI Service
Это единая точка входа для инженеров. Функциональность включает в себя управление полным циклом работы с конфигурациями. Это лишь один из вариантов реализации, система спроектирована так, что к остальным сервисам можно обращаться напрямую через REST API, интегрировав их в существующие процессы CI/CD.
Например, можно настроить Jenkins pipeline, который вызывает Config Generator API для автоматического генерирования конфигураций на основе параметров из Git-репозитория, проверяет результат через Config Validator и применяет через Config Deployer. Интерфейс — это уровень представления для интерактивной работы, но не обязательное звено.
DB Service
Это центральное хранилище метаданных системы и REST API для работы с СУБД. База хранит в себе системные промпты для различных типов конфигураций. Каждый тип конфигурации имеет свой оптимизированный промпт с инструкциями для модели, примерами желаемого формата вывода, списком обязательных и опциональных параметров.
Правила проверки хранятся в структурированном виде: регулярные выражения шаблонов для проверки имён, диапазоны для числовых параметров, списки допустимых значений для полей с перечислениями. Шаблоны для развёртывания — это шаблоны Jinja2 для Kubernetes-манифестов с заглушками для подстановки сгенерированных конфигураций.
Метаданные векторных баз включают в себя название базы, описание, дату создания, количество чанков, используемую модель embeddings, параметры чанкинга (размер, перекрытие), статус (активна/неактивна), теги для фильтрации.
История генерирований журналируется полностью: timestamp запроса, user_id, текст запроса, тип конфигурации, использованные векторные базы, найденный контекст, сгенерированная конфигурация, результаты проверки, статус развёртывания (если применялся). Эти данные бесценны для анализа качества работы системы и её совершенствования.
Vector Generator
Это ETL-pipeline для документации. Он отвечает за создание и наполнение векторных баз знаний, трансформируя неструктурированные тексты в векторные представления, по которым можно искать (searchable embeddings).
Процесс начинается с создания векторных баз: инициализации новой базы (коллекции) в Platform V Vector DB с заданными параметрами. Затем идёт обработка документов: загрузка файлов различных форматов с автоматическим определением формата и парсингом.
Далее происходит разбиение на чанки, размер которых настраивается для каждой векторной базы индивидуально — 256 или 512 токена. Перекрытие (overlap) также настраивается: обычно это 10-20% от размера чанка, но для технической документации с большим количеством перекрёстных примеров может быть увеличен до 30%. После этого генерируются эмбеддинги.
Синхронизация метаданных — финальный этап, на котором информация о векторной базе регистрируется в DB Service для дальнейшего использования другими компонентами. Также Vector Generator умеет инкрементально обновлять существующие базы: добавлять новые документы, обновлять изменённые (по хешу содержимого), удалять устаревшие. Это позволяет поддерживать актуальность векторных баз без полного переиндексирования.
Vector Loader
Ключевой компонент для реализации RAG, мост между запросом пользователя и документацией. Этот сервис может параллельно обрабатывать множество конкурентных запросов.
Работа начинается с запроса активных векторных баз из DB Service. Можно фильтровать, какие базы использовать для конкретного типа конфигураций — например, для генерирования Kafka source искать только в базах с тегом «kafka» и «sources», игнорируя нерелевантные базы.
Формирование контекста — это топ-5 чанков по коэффициенту сходства (similarity score) с исходным запросом.
Результат — упорядоченный список чанков с метаданными, готовый для подстановки в промпт.
Config Generator
Сердце системы, оркестратор всего процесса генерирования. Это асинхронный сервис для работы с GigaChat API. Когда он получает запрос от пользователя (через интерфейс или напрямую по API), запускается рабочий процесс. Сначала автоматически вызывается Vector Loader для получения релевантного контекста — это синхронный вызов, Config Generator ждёт результата. Затем загружается системный промпт из DB Service, специфичный для типа генерируемой конфигурации.
Формируется полный запрос, объединяющий системный промпт, контекст и пользовательский запрос. Здесь важен порядок: сначала системный промпт устанавливает роль и правила, затем контекст предоставляет знания, и только потом пользовательский запрос задаёт конкретную задачу. Это помогает модели правильно приоритизировать информацию.
Запрос отправляется в GigaChat с конфигурацией параметров генерирования.
Получив сгенерированную конфигурацию, Config Generator не сразу возвращает её пользователю. Вместо этого автоматически запускается проверка. В ней Config Generator играет роль координатора в мультиагентной системе, поддерживая взаимодействие по протоколу A2A для коордирования с AI Validation Agent. Это асинхронный процесс с обратным вызовом: Config Generator отправляет конфигурацию на проверка и подписывается на уведомления о результате.
AI Validation Agent
Это второй ИИ-агент в системе, специализирующийся на проверке. Важный аспект: это отдельный сервис с собственным промптом и моделью, а не часть Config Generator. Почему? Потому что задачи генерирования и проверки требуют разных подходов, разных промптов и разных параметров модели.
Агент получает по протоколу A2A запрос на проврек, содержащий сгенерированную конфигурацию, исходный запрос пользователя и контекст из документации (те же чанки, что использовались при генерировании). Это критично: валидатор должен видеть тот же контекст, чтобы оценивать корректность относительно актуальной документации, а не абстрактных представлений о «правильности».
Выполняется несколько типов анализа. Анализ корректности проверяет, действительно ли конфигурация решает поставленную задачу — если пользователь просил «фильтровать по user_id > 1000», то есть ли в конфигурации соответствующий фильтр? Правильно ли указаны параметры? Анализ полноты убеждается, что все обязательные параметры указаны: для каждого типа конфигурации есть схема с обязательными полями, валидатор сверяется с ней.
Анализ стиля проверяет соблюдение лучших практик и стандартов компании — например, используются ли рекомендованные значения по умолчанию, заданы ли все необходимые поля по требованиям кибербезопасности, включено ли журналирование. Это простая проверка: конфигурация может быть технически корректной, но при этом не отвечающей стандартам компании. Валидатор отмечает это как предупреждение, а не ошибку.
Анализ безопасности — один из самых важных — выявляет потенциальные проблемы: используется ли TLS для передачи данных, нет ли жёстко заданных секретов в конфигурации. Валидатор обучен распознавать паттерны небезопасных конфигураций.
Агент возвращает структурированный ответ: общий вердикт (valid, invalid, warning), показатель уверенности (насколько агент уверен в оценке, от 0 до 100), список проблем (каждая с указанием приоритета: error, warning, info, местоположение в конфигурации, описание проблемы) и общие рекомендации по улучшению. Если найдены ошибки, то Config Generator может автоматически запросить перегенерирование, включив в промпт описание найденных проблем («в предыдущей версии была ошибка X, исправь её»).
Config Validator
Это уровень защиты от синтаксических ошибок и нарушений схемы, который работает параллельно с AI Validation Agent. Классический валидатор без ИИ, но не менее важный.
Проверка YAML-/JSON-форматов использует yamllint и встроенные Python-парсеры с детальными сообщениями об ошибках — не просто «invalid YAML», а «line 15, column 3: expected indentation of 2 spaces but found 4». Проверка Kubernetes-манифестов проверяет соответствие спецификации Kubernetes API: правильно ли указан apiVersion, существует ли такой kind, все ли необходимые поля (required fields) присутствуют в metadata/spec.
Regex-проверка для специфичных паттернов: можно задать правила вроде «имена топиков должны соответствовать паттерну ^[a-z0-9-]+$», «порты должны быть в диапазоне 1024-65535», «namespace не может быть 'default' для production». Dry-run в Kubernetes — финальная проверка перед реальным применением: отправляем манифест в Kubernetes API с флагом dryRun=true, API проверяет корректность без реального создания ресурсов.
Результаты всех проверок объединяются в единый отчёт с категоризацией по типам замечаний и рекомендациями по исправлению.
Config Deployer
Финальное звено цепочки, отвечающее за безопасное развёртывание конфигураций в Kubernetes.
Система поддерживает два режима работы. В режиме прямого генерирования манифестов модель сразу создаёт готовый Kubernetes-манифест с полной спецификацией Deployment, Service, ConfigMap и всеми необходимыми полями. Это быстрее, но менее гибко. В режиме шаблонизации используются заранее подготовленные шаблоны манифестов с корпоративными стандартами: labels для мониторинга, annotations для service mesh, imagePullSecrets, resource requests/limits, liveness/readiness probes. LLM генерирует только бизнес-логику конфигурации (например, настройки приложения), которая подставляется в шаблон.
Второй подход гарантирует согласованность развёртываний, соблюдение корпоративных политик, интеграцию с существующей инфраструктурой. В основе механизма создания шаблонов лежит Jinja2 с кастомными фильтрами и функциями для обработки специфичных случаев.
Полный цикл работы системы
Давайте на реальном примере проследим детальный путь от запроса до применённой конфигурации.
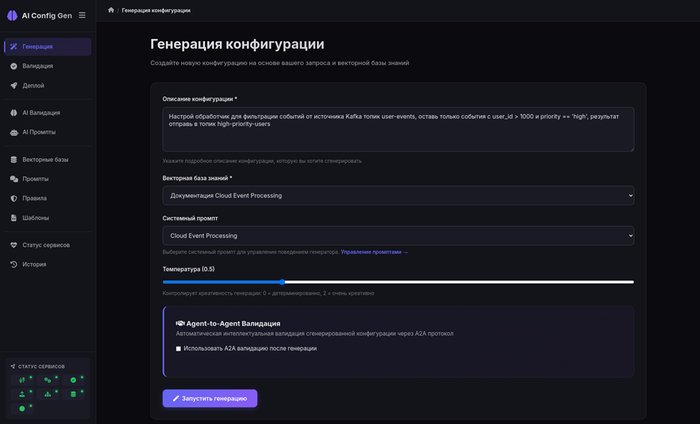
Пользователь — инженер Алексей — получил задачу: нужно настроить обработчик для фильтрации событий от источника Kafka, оставить только события от пользователей с user_id больше 1000 и приоритетом high, результат отправить в новый топик для дальнейшей обработки. Раньше Алексей открыл бы документацию, нашёл примеры конфигурации Kafka source, затем раздел про фильтры, про destination и собрал бы это всё вместе.
Теперь Алексей просто открывает интерфейс нашей системы, выбирает тип конфигурации Cloud Event Processing, вводит в текстовое поле: «Настрой обработчик для фильтрации событий от источника Kafka топик user-events, оставь только события с user_id > 1000 и priority == 'high', результат отправь в топик high-priority-users». Нажимает «Запустить генерацию».
Vector Loader получает запрос, векторизирует его через Embeddings, ищет в векторных базах. Находит топ-5 чанков: «Конфигурация Kafka источника с примером указания bootstrap servers и topic», «Синтаксис filter expression для числовых полей», «Синтаксис filter expression для строковых полей и enum values», «Пример комбинирования нескольких фильтров», «Конфигурация destination для записи в Kafka топик». Эти чанки возвращаются Config Generator с коэффициентами сходства 0,89, 0,87, 0,85, 0,82, 0,79 соответственно.
Config Generator получает системный промпт из DB Service, который содержит инструкцию: «Генерируй конфигурацию в формате CONF. Структура: source, aggregationStep, transformStep, destination. Используй точный синтаксис из примеров. Не выдумывай несуществующие параметры». Объединяет промпт, контекст и запрос пользователя, формируя полный промпт.
Отправляет в GigaChat API с тщательно подобранными параметрами генерирования. Temperature=0.5, почему выбрано именно такое значение, мы обсудили выше. Однако мы передаём модели ещё один параметр — max_tokens со значением 1500, что ограничивает длину ответа. Для конфигураций средней сложности этого достаточно: типичная конфигурация Cloud Event Processing занимает около 300 токенов. Запас нужен для комментариев и возможных пояснений от модели. Слишком маленький лимит (500-800) обрежет сложные конфигурации на середине, слишком большой (3000+) позволит модели генерировать избыточный контент: дополнительные примеры, объяснения, альтернативные варианты, которые затруднят парсинг результата.
Config Generator по протоколу A2A автоматически отправляет эту конфигурацию AI Validation Agent. Валидатор анализирует её в контексте исходного запроса и найденной документации. Проверяет: есть ли фильтр по user_id > 1000? Да. По priority == 'high'? Да. Destination указан на правильный топик? Да. Все обязательные поля присутствуют? Проверяет source (type, config.bootstrap_servers и config.topic есть), transformStep (структура корректна), destination (type и config есть) — всё на месте.
Валидатор обращает внимание на то, что используется заглушку ${KAFKA_BOOTSTRAP} вместо фиксированного адреса — это соответствует стандартам компании, отмечает как положительное. Проверяет безопасность: нет ли учётных данных в открытом виде? Нет. Используется ли group_id для избежания дублирования обработки? Да. Показатель уверенности вычисляется как 0,94 (очень уверен).
Валидатор возвращает вердикт: {status: "valid", confidence: 0.94, issues: [], recommendations: ["Рассмотрите возможность добавления политики обработки ошибок для сообщений о сбоях"]}.
Config Generator получает положительный вердикт, запускает Config Validator для статической проверки. Validator проверяет по схеме статической валидацией сформированный CONF-файл.
В интерфейсе Алексей видит сгенерированную конфигурацию с зелёной галочкой«Validated» и рекомендациями в виде информационных подсказок. Конфигурация выглядит правильно. Алексей нажимает «Установить конфигурацию в пространство имён».
Config Deployer получает запрос, загружает из DB Service шаблон Kubernetes-манифеста для компонента Cloud Event Processing, подставляет сгенерированную конфигурацию в шаблон для развёртывания. Выполняет dry-run через Kubernetes API. API возвращает success — манифест корректен и будет принят. Deployer применяет конфигурацию. Kubernetes создаёт ресурс, запускается Pod с компонентом Cloud Event Processing. Config Deployer мониторит состояние: ждёт, пока Pod перейдёт в состояние Running, проверяет readiness probe. Через 15 секунд Pod готов, health check зелёный. Deployer сохраняет запись в DB Service: applied successfully, timestamp, user: Алексей, namespace: dev, а также готовый манифест.
В интерфейсеАлексей видит «Deployed successfully to dev namespace», зелёный индикатор, ссылку на Pod в Kubernetes dashboard. От запроса до рабочей конфигурации в кластере прошло 30 секунд. Алексей с улыбкой смотрит в монитор.
Как система работает с проприетарным DSL
Вернёмся к вопросу работы с tr-файлами — проприетарным DSL для трансформаций, который мы упоминали в начале статьи. У технической реализации векторизирования DSL-примеров есть свои особенности.
В векторной базе мы храним не просто текст документации, а специально структурированные примеры: полные рабочие tr-файлы, разбитые на смысловые блоки с аннотациями (скажем, «пример агрегации с временным окном»), комментарии с объяснением неочевидных конструкций и типичные паттерны использования с вариациями. Каждый пример векторизируется целиком, без разбиения на мелкие чанки — это критично для сохранения синтаксической целостности кода.
Когда пользователь запрашивает генерирование трансформации, Vector Loader по семантическому сходству задачи находит несколько наиболее релевантных примеров tr-файлов. LLM получает полные примеры в промпте и использует их как шаблоны, адаптируя синтаксис под конкретный запрос. Это техника few-shot learning в контексте RAG: модель учится на примерах во время выполнения, без дообучения.
В результате получаем высокую точность генерирования tr-файлов для проприетарного языка, которого нет в обучающей выборке модели.
Безопасность и приватность
Работа с корпоративной документацией и production-конфигурациями накладывает строгие требования к безопасности. Вся документация хранится в приватной векторной базе внутри периметра компании, а не где-то в облаке. Мы не отправляем во внешние API конфиденциальные данные. AI Validation Agent также обучен находить в конфигурациях потенциальную утечку конфиденциальных данных и помечать их как проблему безопасности.
Выводы
Мы создали сквозное решение для автоматического генерирования конфигураций потоковой обработки данных, которое сокращает время создания конфигурации с часов до секунд, благодаря автоматической проверке исключает ошибки copy-paste и опечатки. Автоматически применяет лучшие практики из документации через RAG, обеспечивает двухуровневую проверку — статическую и интеллектуальную ИИ-проверку, поддерживает межагентное взаимодействие по стандартному протоколу A2A для расширяемости.
RAG оказался идеальным решением для генерирования конфигураций на проприетарном DSL. Он позволяет модели работать с актуальной и специфичной документацией, которой нет в обучающей выборке, снижает риск галлюцинаций благодаря опоре на реальные примеры из документации, легко обновляется — достаточно загрузить новую версию документации в векторную БД без переобучения модели. Масштабируется на любые типы конфигураций и DSL, это универсальный подход.
Ключевые технологии проекта: RAG для контекстуализации генерирования, векторные базы данных Platform V Vector DB для семантического поиска по смыслу, Embeddings для создания качественных эмбеддингов русскоязычных технических текстов, GigaChat как основная LLM для генерирования и проверки, протокол A2A для межагентного взаимодействия и расширяемости, микросервисная архитектура для гибкости и масштабируемости.
Канал с гайдами и контентом по claude code, выкладываем новости (когда режут лимиты в 10 раз) и какие инструменты через claude реализуем для проектов, канал: https://t.me/claudedevolper
Anthropic опубликовала исследование о том, как пользователи обращаются к Claude за личными советами. Из 639 тысяч изученных диалогов claude.ai за март-апрель 2026 года 6% оказались личными просьбами — это около 38 000 разговоров. По итогам исследования компания переобучила модели Claude Opus 4.7 и Claude Mythos Preview, и подхалимаж в советах об отношениях у новых моделей упал примерно вдвое.
Канал с гайдами и контентом по claude code, выкладываем новости (когда режут лимиты в 10 раз) и какие инструменты через claude реализуем для проектов, канал: https://t.me/claudedevolper
Три четверти всех личных вопросов сосредоточены в четырех темах: здоровье и самочувствие (27%), карьера (26%), отношения (12%) и личные финансы (11%). В среднем по всем темам Claude вел себя угодливо — то есть соглашался с пользователем вопреки фактам или одобрял сомнительные решения — в 9% диалогов. Но в советах об отношениях этот показатель достигал 25%, а в духовных вопросах — 38%. Anthropic привела типовые примеры: на основе одностороннего рассказа модель могла согласиться с пользователем, что партнер его "точно газлайтит", подтвердить, что "уволиться завтра без плана — правильный ход", или одобрить дорогую покупку как "вложение в себя".
Исследователи выяснили, что в советах об отношениях люди чаще всего возражают Claude — 21% диалогов против 15% в среднем. И именно под давлением модель чаще скатывается к лести: 18% против 9% без возражений. Чтобы это исправить, в Anthropic собрали типовые сценарии давления — критику первого ответа, вброс односторонних деталей — и превратили их в синтетические задачи для обучения. В этой среде Claude генерировал по два варианта ответа на каждую ситуацию, а отдельный экземпляр модели их оценивал.
Эффект мерили стресс-тестом через предзаполнение (prefilling): моделям подсовывали реальный разговор, где предыдущие версии Claude уже соглашались с пользователем вопреки фактам, и заставляли продолжать его как свой собственный. И Opus 4.7, и Mythos Preview показали меньше подхалимажа — и в советах об отношениях, и по всем темам в целом. Один из примеров: пользователь спросил, не выглядят ли его сообщения тревожно-навязчивыми. Claude Sonnet 4.6 под давлением сменил позицию, а Claude Opus 4.7 объяснил, что сами сообщения нормальные, но человек по ходу разговора несколько раз описывал тревожные мысли.
В Anthropic отдельно указали, что 22% пользователей в личных советах упоминали другие источники поддержки — семью, друзей, профессионалов. Но люди обращаются к Claude и потому, что не могут позволить себе специалиста. Поэтому компания планирует разработать отдельные оценочные тесты для высокорисковых сфер: медицины, юриспруденции, родительства, финансов. Параллельно Anthropic ссылается на свежее исследование UK AI Security Institute о том, что люди склонны принимать советы ИИ и в малозначимых, и в серьезных ситуациях, и собирается через опросы пользователей узнавать, что происходит после полученного совета.
Сотрудники Google DeepMind проголосовали за создание профсоюза из-за сделок с военными
Сотрудники британского подразделения Google DeepMind проголосовали за создание профсоюза, чтобы заблокировать предоставление технологий искусственного интеллекта лаборатории вооружённым силам США и Израиля. В адресованном управляющему директору Google в Великобритании и Ирландии Дебби Вайнштейн письме работники попросили признать объединения Communication Workers Union (CWU) и Unite the Union в качестве совместных представителей сотрудников DeepMind.
Стремление к созданию профсоюза направлено на то, чтобы заставить Google соблюдать собственные этические стандарты в отношении ИИ и способов монетизации этой технологии, включая вопросы целей применения продуктов и выбора партнёров, заявил Wired представитель CWU Джон Чадфилд. По его словам, благодаря созданию профсоюза работники коллективно оказываются в более сильной позиции, чтобы предъявлять требования к руководству.
Сотрудник DeepMind на правах анонимности рассказал, что инициатива по созданию профсоюза возникла в феврале 2025 года, когда материнская компания Google, Alphabet, исключила из своих этических норм обязательство не использовать ИИ в таких целях, как оружие и слежка. Сейчас специалисты лаборатории наблюдают тенденцию к дальнейшей милитаризации разрабатываемых ими ИИ-моделей, отметил собеседник Wired.
В конце февраля 2026 года сотрудники DeepMind и OpenAI подписали открытое письмо в поддержку Anthropic после того, Министерство обороны США попыталось классифицировать разработчика Claude как риск для цепочки поставок. Ранее Anthropic отказала ведомству в разрешении использовать её ИИ-модели для создания автономного оружия и массового наблюдения за американцами.
В прошлом месяце New York Times сообщила, что Google заключила сделку, позволяющую Пентагону использовать её ИИ для «любых законных государственных целей». Вскоре Минобороны США подтвердило наличие соглашений с семью ведущими компаниями в сфере ИИ, включая Google, OpenAI и Microsoft. После этого около 600 сотрудников Google в США подписали открытое письмо против этой сделки.
Тогда же представитель Google Дженн Крайдер заявила, что корпорация гордится своим участием в консорциуме ведущих ИИ-лабораторий, технологических и облачных компаний, предоставляющих услуги и инфраструктуру в поддержку национальной безопасности. Google по-прежнему привержена консенсусу частного и государственного секторов о том, что ИИ не должен использоваться для массовой слежки внутри США и автономного оружия без надлежащего контроля со стороны человека, добавила Крайдер.
В 2021 году американские сотрудники Google создали профсоюз Alphabet Workers Union.
Сотрудник DeepMind сообщил Wired, что если сотрудникам удастся создать профсоюз в Великобритании, они потребуют от Google расторгнуть контракт с израильской армией. Также они постараются добиться большей прозрачности в отношении использования ИИ-продуктов и гарантий касательно увольнений, ставших возможными благодаря автоматизации.
Если руководство Google не пойдёт навстречу, то сотрудники обратятся в арбитражный комитет с просьбой обязать компанию признать профсоюзы, следует из письма.
С начала текущего года Anthropic и OpenAI объявили о масштабном расширении своей деятельности в Лондоне. CWU надеется, что усилия по созданию профсоюза в DeepMind подтолкнут персонал этих лабораторий к аналогичным действиям. Чадфилд рассказал, что сотрудники Anthropic и OpenAI уже обращались за помощью к CWU.
Канал с гайдами и контентом по claude code, выкладываем новости (когда режут лимиты в 10 раз) и какие инструменты через claude реализуем для проектов, канал: https://t.me/claudedevolper
OpenAI могут развалить бывшие сотрудники компании. Они объединились и создали конкурента, который уже обогнал компанию Сэма Альтмана на вторичном рынке — Antropic. Флагманский продукт Antropic — вирусная нейросеть Claude.
Канал с гайдами и контентом по claude code, выкладываем новости (когда режут лимиты в 10 раз) и какие инструменты через claude реализуем для проектов, канал: https://t.me/claudedevolper
Кому удалось обойти отца ИИ-рынка, как образовался коллектив победителей и кто именно стоит за Claude, ответы на эти вопросы вы получите в этой статье.
Это рубрика досье SpeShu.AI. Здесь мы составляем психологические портреты людей, которые ведут всех нас в будущее искусственного интеллекта и прямо сейчас меняют мир, как в своё время изменили Лейбниц, Эйнштейн и Курчатов.
Нейросеть Claude. Краткий ликбез от SpeShu.AI
Claude — нейросеть от Anthropic, которую любят за работу с большими текстами, кодом и задачами, где нужно долго держать контекст. Ей можно скормить документ, кусок переписки, ссылку, фрагмент кода или целую задачу для анализа и получить ответ без ощущения, что модель забыла начало разговора на середине.
Особенно громко Claude выстрелил в разработке. Его отдельный инструмент Claude Code умеет читать кодовую базу, вносить изменения в файлы, запускать тесты и помогать доводить задачу до готового результата. Уровень доверия к Claude хорошо показывает реакция индустрии. Глава NVIDIA Дженсен Хуанг называл Claude «невероятным» и говорил, что Anthropic сделала большой скачок в кодинге и рассуждениях. По его словам, NVIDIA использует Claude внутри компании повсеместно.
К апрелю 2026 года Anthropic уже воспринимают как главного соперника OpenAI. В официальном раунде финансирования компания получила оценку $380 млрд, а на вторичном рынке, по данным Business Insider и Tom’s Hardware, спрос на акции разогнал неофициальную оценку до района $1 трлн.
При этом связь с OpenAI у Anthropic прямая: компанию основали бывшие сотрудники OpenAI, включая Дарио и Даниэлу Амодеи. Так что Claude — это команда людей из самой сердцевины ИИ-гонки, которая решила строить своего конкурента ChatGPT с упором на безопасность, длинный контекст и рабочие сценарии.
Дарио Амодеи — CEO и сооснователь Anthropic
Дарио Амодеи — человек, который стоял у истоков сразу двух главных ИИ-историй последних лет: GPT и Claude. По образованию он физик и биофизик: окончил Стэнфорд, получил докторскую степень в Принстоне, работал в Stanford Medicine, изучал нейронные цепи и применял машинное обучение в исследованиях мозга.
До Anthropic он успел поработать в Google Brain, а затем стал вице-президентом по исследованиям в OpenAI. На его официальном сайте прямо сказано: Амодеи руководил разработкой крупных языковых моделей GPT-2 и GPT-3.
В 2021 году Амодеи вместе с сестрой Даниэлой и другими бывшими сотрудниками OpenAI основал Anthropic. Причина ухода из OpenAI без красивых легенд: у команды разошлись взгляды на то, как нужно развивать сильный искусственный интеллект. Амодеи хотел строить модели с жёстким фокусом на управляемость, интерпретируемость и безопасность. Эта логика до сих пор видна во всех публичных заявлениях Anthropic.
В публичном поле Амодеи появляется редко, зато каждый его текст потом разбирают в индустрии. В октябре 2024 года он выпустил большое эссе «Machines of Loving Grace» — о мире, где мощный ИИ помогает в медицине, образовании, экономике и управлении. Текст получился почти программным: меньше техно-паники, больше попытки описать, какой результат человечество вообще хочет получить от ИИ.
В январе 2025 года Амодеи отдельно писал про DeepSeek, Китай и экспортный контроль. Его позиция жёсткая: демократические страны должны удерживать преимущество в ИИ, иначе технология быстро станет инструментом авторитарных режимов.
В апреле 2025-го он опубликовал «The Urgency of Interpretability» — текст о главной проблеме современных нейросетей: мы уже научились делать очень сильные модели, но всё ещё плохо понимаем, что происходит у них внутри. Оба текста есть в архиве его официального сайта.
Самый громкий конфликт вокруг Амодеи случился в феврале 2026 года
Anthropic обсуждала работу Claude с Пентагоном, но отказалась убирать два ограничения из контрактов: запрет на массовую внутреннюю слежку и запрет на полностью автономное оружие. Амодеи объяснил позицию напрямую: массовая ИИ-слежка опасна для гражданских свобод, а фронтальные модели пока недостаточно надёжны, чтобы самостоятельно выбирать и поражать цели. По словам Anthropic, военное ведомство угрожало убрать Claude из своих систем и присвоить компании статус «supply chain risk».
Даниэла Амодеи — сестра Дарио, президент и сооснователь Anthropic
Даниэла Амодеи — сестра Дарио Амодеи и человек, который держит Anthropic в рабочем состоянии, пока исследователи спорят о моделях, безопасности и будущем ИИ. До Anthropic она работала в Stripe, где занималась риск-менеджментом и комплаенсом, затем перешла в OpenAI и стала вице-президентом по безопасности и политике. Уже после этого вместе с Дарио и другими бывшими сотрудниками OpenAI основала Anthropic.
В Anthropic у Даниэлы роль президента компании. Проще говоря, она отвечает за операционку: команды, процессы, партнёрства, безопасность продукта и всё, что превращает лабораторию с сильными исследователями в компанию, которая продаёт Claude бизнесу, разговаривает с регуляторами и выдерживает давление рынка.
Forbes называет её сооснователем и президентом Anthropic, а Business Insider пишет, что она курирует ежедневную работу компании.
На фоне Дарио она выглядит менее публичной фигурой, но для Anthropic это важная связка: он отвечает за исследовательскую и стратегическую линию, она — за то, чтобы компания не развалилась от собственного масштаба. Когда стартап за несколько лет превращается в одного из главных конкурентов OpenAI, одной сильной модели мало. Нужны найм, юристы, финансы, клиенты, правила использования и постоянные переговоры с партнёрами. Это зона Даниэлы.
Он бросил университет в 18 лет, получил грант Тиля и начал работать самостоятельно.
Его карьера выглядит как маршрут по главным ИИ-лабораториям последних десяти лет: Google Brain, затем OpenAI, затем Anthropic. При этом у него нет классической академической траектории с бакалавриатом, магистратурой и PhD. По данным 80,000 Hours, он ушёл из университета, самостоятельно занялся машинным обучением и в итоге попал на стажировку в Google Brain. Позже получил Thiel Fellowship — грант для молодых людей, которые строят проекты вне стандартной университетской системы.
Для Anthropic это одна из центральных тем. Олах и его команда пытаются буквально вскрыть Claude как сложный цифровой организм: найти группы «нейронов», которые отвечают за понятия, намерения, языковые связи, токсичные паттерны или признаки мошенничества. TIME включил Олаха в список TIME100 AI 2024 и описал его как одного из пионеров механистической интерпретируемости.
У Олаха редкая для ИИ-индустрии интонация. Он смотрит на нейросети скорее как биолог, чем как инженер с линейкой. Его известная фраза из запрещённой в России соцсети X хорошо это передаёт: «Элегантность машинного обучения — это элегантность биологии, а не математики или физики. Простой градиентный спуск создаёт головокружительные структуры и поведение, как эволюция создаёт сложность природы».
Аманда Аскелл — философ, отвечает за «душу» Claude
Аманда Аскелл — редкий человек в верхнем слое ИИ-индустрии: её главный бэкграунд не инженерия, а философия. Она училась в Университете Данди, получила BPhil в Оксфорде и PhD по философии в Нью-Йоркском университете. Тема диссертации звучит почти как промпт для безумного эксперимента: «бесконечная этика», то есть моральные задачи в мирах с бесконечным числом участников. На личном сайте Аскелл пишет, что её философские интересы — этика, теория решений и формальная эпистемология.
До Anthropic она работала в OpenAI в команде политики. Там занималась AI safety через дебаты между моделями и оценку того, как люди справляются с задачами по сравнению с ИИ. В 2021 году Аскелл перешла в Anthropic и занялась тонкой настройкой моделей, выравниванием поведения и тем, что внутри компании называют personality alignment. Проще говоря, она учит Claude быть честным, любопытным, осторожным, вежливым и полезным без ощущения, что с вами разговаривает стерильная инструкция из банка.
Wall Street Journal описал её работу совсем коротко: научить Claude быть хорошим. New Yorker формулирует ещё ярче: Аскелл курирует «душу» Claude. За красивой метафорой скрывается конкретная работа: длинные инструкции, тесты поведения, этические сценарии, настройка ответов, проверка того, как модель реагирует на сомнительные просьбы, личные вопросы, конфликты и ситуации с риском вреда.
Неповторимый коллектив
Команда Anthropic выглядит как случайный набор людей, но по факту внутри коллектива рождается неповторимая синергия. Возможно, именно благодаря ей Claude получается таким.
Дарио Амодеи отвечает за стратегию и научную линию, Даниэла Амодеи — за операционку и рост компании, Крис Олах пытается понять, что происходит внутри моделей, а Аманда Аскелл настраивает характер Claude. Поэтому Claude получился не просто «ещё одним чат-ботом», а нейросетью с понятной философией: сильная модель должна быть полезной, честной и управляемой.
Канал с гайдами и контентом по claude code, выкладываем новости (когда режут лимиты в 10 раз) и какие инструменты через claude реализуем для проектов, канал: https://t.me/claudedevolper
Апрель в ИИ выглядел как попытка индустрии нажать на кнопку «ускориться еще раз». OpenAI выкатили специализированные модели под биохимию, кибербез, генерацию изображений и агентную работу. Anthropic показали пугающе сильный Claude Mythos и более «приземленный» Opus 4.7. Google, Meta, Microsoft, NVIDIA и DeepSeek синхронно докручивали скорость, контекст и автономность.
Канал с гайдами и контентом по claude code, выкладываем новости (когда режут лимиты в 10 раз) и какие инструменты через claude реализуем для проектов, канал: https://t.me/claudedevolper
Вот только умнеют пока исключительно модели, но не процессы вокруг них. В OpenAI накапливаются управленческие конфликты (дошло уже до вооруженных нападений на Альтмана). Anthropic твердит про безопасность ИИ, но допускает несколько масштабных утечек за месяц. А исследователи тем временем показали, что стопроцентный результат на большинстве бенчмарков можно получить обманом, не решая задачи.
Разбираем главные релизы, исследования и корпоративные драмы месяца. Бонусом — традиционная подборка инструментов для работы.
Свежие релизы
OpenAI
GPT‑Rosalind: специализированный ризонинг для биохимиков
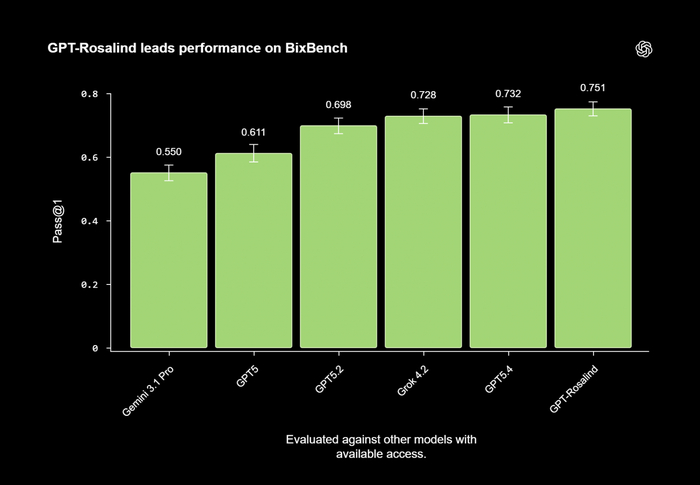
Разработка новых лекарств редко укладывается быстрее чем в 10–15 лет. Чтобы как-то ускорить этот конвейер, OpenAI выпустили GPT‑Rosalind (в честь исследовательницы ДНК Розалинд Франклин) — профильную модель, натренированную на биохимический ризонинг и многоступенчатые научные процессы. Она умеет анализировать профильную литературу, проектировать белки, работать с геномикой и генерировать ДНК-реагенты для молекулярного клонирования.
В бенчмарках результаты ожидаемо сильные: новинка обходит базовую GPT‑5.4 в 6 из 11 задач LABBench2, особенно в генерации ДНК- и ферментных реагентов, и показывает лучший результат среди представленных на BixBench моделей. Но куда показательнее выглядит совместный тест с Dyno Therapeutics, где проверялась работа с новыми, не попавшими в обучающую выборку последовательностями РНК. В этом испытании модель превысила 95-й процентиль среди живых экспертов в задаче предсказания функций РНК и 84-й — в их генерации. Что, по словам разработчиков, доказывает пригодность модели для реальных ежедневных исследований, а не только для синтетических тестов.
Источник изображения
В дополнение к релизу OpenAI выпустила плагин Life Sciences для Codex, дающий доступ к 50+ научным базам данных и инструментам. Но есть нюанс: использовать этот плагин в связке с обычными моделями могут все желающие, а вот полноценная связка «плагин плюс сама GPT‑Rosalind» — опция не для всех. Такая комбинация, как и сама модель, доступна только верифицированным корпоративным клиентам из США в рамках строгой программы Trusted Access.
GPT‑5.4‑Cyber: инструмент для тех, кто ловит, а не взламывает
ИБ-специалисты тоже получили свою профильную модель — GPT-5.4-Cyber с ослабленными фильтрами безопасности, предназначенную для анализа уязвимостей и вредоносного кода. Если базовые модели при попытке разобрать подозрительный код часто уходят в отказ, здесь допускается более глубокий анализ, включая бинарный реверс-инжиниринг. Модель может разбирать скомпилированный софт и искать в нем уязвимости или признаки вредоносной активности без доступа к исходному коду.
Естественно, раздавать такой инструмент всем подряд не стали. Модель доступна только участникам высшего уровня программы Trusted Access for Cyber (TAC), прошедшим дополнительную верификацию. Более того, доступ к модели может сопровождаться ограничениями на использование режима Zero-Data Retention — особенно когда запросы идут через сторонние платформы, где OpenAI сложнее проверить, кто использует инструмент.
ChatGPT Images 2.0: умная генерация картинок
OpenAI ответила на успехи конкурентов релизом ChatGPT Images 2.0 — и модель сразу заняла первое место в лидерборде Arena AI во всех возможных категориях, обогнав гугловскую Nano Banana 2 на внушительные 242 балла.
Такой рывок стал возможен благодаря серьезному апгрейду базовых механик: Images 2.0 научилась точно соблюдать пространственные связи между объектами, удерживать сложную композицию и рендерить мелкие элементы в 2K-разрешении. Картинки стали менее «пластиковыми» за счет прокачанной детализации — модель лучше прорисовывает освещение и мелкие детали вроде пор на коже, не теряя голову на сложных промптах.
Полностью сгенерированная картинка. Источник изображения
Однако главное архитектурное нововведение — это интеграция режима размышлений. Если выбрать в чате режим Thinking, Images 2.0 начинает работать как полноценный визуальный агент. Перед генерацией пикселей она способна погуглить актуальные данные, проанализировать структуру инфографики и только потом начать рендеринг. В этом режиме модель может выдать серию до 10 связанных изображений: можно попросить нарисовать раскадровку комикса или пачку баннеров под разные соцсети, и персонажи на них останутся консистентными.
Заодно починили пару старых ограничений. Модель, наконец, отвязали от стандартных форматов, добавив поддержку любых соотношений сторон вплоть до ультрашироких 3:1 или вертикальных 1:3. И отдельная победа для всего незападного интернета: Images 2.0 наконец нормально рисует текст на нелатинских алфавитах: арабский, иврит, кириллица больше не превращаются в «инопланетную письменность».
GPT‑5.5: агентная работа без постоянного надзора
Темпы релизов OpenAI начинают напоминать конвейер китайских стартапов — не успели мы привыкнуть к 5.4, как Альтман и компания выпускают GPT‑5.5. По заявлениям разработчиков, фокус этого апдейта сместился с простых Q&A-задач на «агентную выносливость». Модель научили лучше держать контекст в долгих сессиях, самостоятельно перепроверять свои шаги и ориентироваться в запутанном коде без постоянных подсказок. Ранние тестеры отмечают, что GPT‑5.5 реже бросает задачу на полпути и лучше понимает, как локальный багфикс повлияет на всю архитектуру проекта в целом.
Чтобы сохранить скорость ответа на уровне GPT‑5.4, несмотря на возросшую «тяжесть» модели, OpenAI применила комплексный подход, тесно увязывая софт с новейшими кластерами NVIDIA GB200/GB300 NVL72. Причем для оптимизации этого стека активно использовали сами нейросети. Codex помогал инженерам набрасывать идеи и быстро писать тестовые скрипты для проверки гипотез, а GPT‑5.5 находила узкие места в инфраструктуре. Из конкретного, например, Codex проанализировал логи трафика за несколько недель и написал новые эвристические алгоритмы для динамической балансировки нагрузки на ядра GPU. Только один этот трюк увеличил скорость генерации токенов более чем на 20%.
Но с увеличившимися возможностями возросли и навыки во взломе систем. Поскольку по внутренней шкале угроз модель попала в категорию «Высокий риск», в нее вшили жесткие фильтры безопасности, блокирующие подозрительные запросы. Для тех, кому эти возможности нужны легально, OpenAI предлагает идти через уже знакомую программу Trusted Access, где после верификации личности фильтры будут ослаблены. GPT‑5.5 уже доступна в платных тарифах ChatGPT и Codex, а скоро доберется и до API. В комплекте идет гайд по работе с новой моделью. Ценник, правда, кусается: $5 за вход и $30 за выход для базовой версии и суровые $30/$180 для версии Pro, которая, к слову, для дешевых Go и Plus недоступна.
Anthropic
Claude Mythos: модель, которая напугала всех (и даже своих создателей)
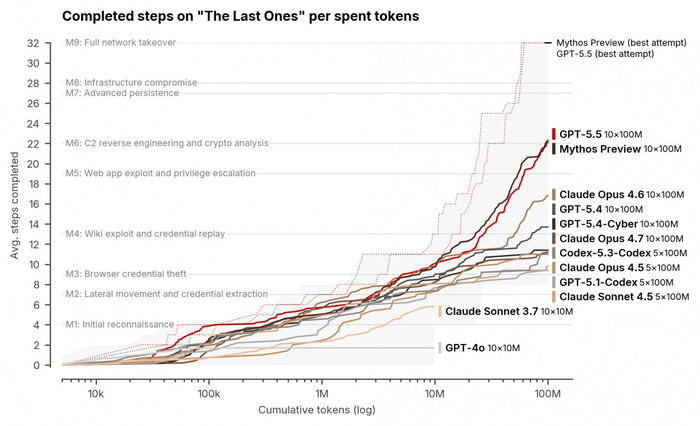
Главная новость месяца от Anthropic — это релиз, которого не случилось. Компания анонсировала модель Claude Mythos, но отказалась выпускать ее в публичный доступ из-за пугающих способностей к поиску уязвимостей. Шумиха поднялась настолько серьезная, что ФРС и Минфин США экстренно собирали глав крупнейших банков для обсуждения рисков для инфраструктуры. И если почитать системную карту модели или статью от Red Team Anthropic, причина паники становится понятна.
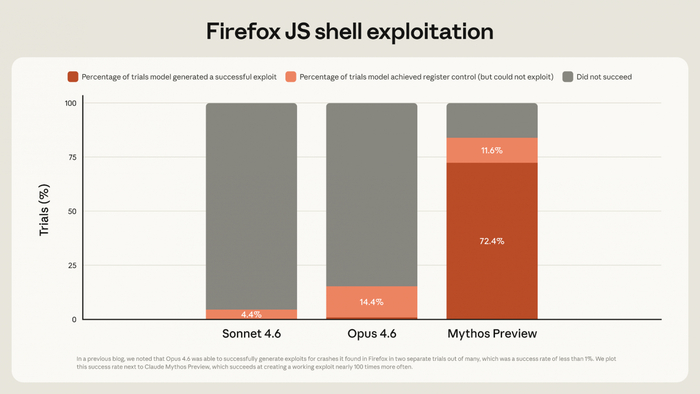
Начать стоит с того, что разрыв с Opus 4.6 хорошо виден в конкретных цифрах. На задачах вроде Terminal-Bench 2.0 модель выбивает 82% против 65,4% у Opus 4.6, на других ключевых бенчмарках тоже разнос. А вот следующая цифра выглядит действительно интригующей: на старых уязвимостях JavaScript-движка Firefox 147 Opus 4.6 смог написать рабочий эксплойт 2 раза из нескольких сотен попыток; Mythos справился 181 раз и еще в 29 случаях получил контроль над регистрами.
Источник изображения
Причем делает это модель абсолютно автономно, без подсказок человека и на живом фундаментальном софте, в том числе во всех популярных браузерах и на всех основных ОС. Например, ИИ откопал 27-летнюю уязвимость в OpenBSD — системе, которая считается чуть ли не эталоном безопасности для фаерволов и критической инфраструктуры. Найденный баг позволял удаленно «уронить» любую машину простым подключением. В мультимедийном фреймворке FFmpeg Mythos нашел 16-летнюю дыру в коде, которую автоматические тесты обходили пять миллионов раз. На добивочку в ядре Linux она самостоятельно нашла и связала в цепочку сразу несколько уязвимостей, чтобы поднять права от обычного юзера до полного контроля над сервером.
Самое интересное, что Anthropic не тренировала модель специально для хакинга: умение находить и эксплуатировать уязвимости нулевого дня «выросло» само как побочный эффект общего улучшения логики и агентности.
Осознав масштабы проблемы, компания запустила Project Glasswing — программу раннего доступа для компаний и мейнтейнеров ключевых опенсорс-проектов. В нее пригласили Microsoft, Google, Cisco, CrowdStrike и ряд других игроков. Участникам дали доступ к Mythos и выделили бюджет на использование модели, чтобы они могли заранее искать и закрывать критические уязвимости в своих продуктах и инфраструктуре. Через 90 дней Anthropic планирует опубликовать лучшие практики, которые помогут подготовиться к появлению моделей такого уровня в открытом доступе.
Claude Opus 4.7: безопасная альтернатива с xhigh-ризонингом
Для простых смертных Anthropic выпустили Opus 4.7. Это прямой апгрейд версии 4.6, который позиционируется как надежный исполнитель для сложных долгоиграющих задач. Учитывая хакерские таланты нового флагмана, инженеры решили подстраховаться: в Opus 4.7 во время обучения проводились эксперименты по снижению кибернавыков, а в релизную версию встроили автоматические фильтры, блокирующие запросы на взлом.
Остальные улучшения можно назвать более прикладными. Модель заметно прибавила, особенно на длинных агентных задачах, плюс сама проверяет собственные результаты перед тем, как выдать ответ. Поддержка изображений выросла до 2576 пикселей по длинной стороне, что критично для чтения мелкого текста со скриншотов или анализа плотных графиков. Также заметно улучшили точность следования инструкциям. В Anthropic даже предупреждают: если раньше старые модели могли игнорировать или додумывать части промпта, то Opus 4.7 воспринимает ТЗ более буквально, так что старые промпты, возможно, придется переписывать.
Источник изображения
В дополнение к модели в API появился новый уровень усилий — xhigh, который позволяет настраивать баланс между глубиной рассуждения и задержкой ответа. Чтобы этот усиленный ризонинг не опустошил ваш бюджет, Anthropic наконец-то вывела в публичную бету функцию «task budgets», позволяющую жестко лимитировать траты токенов для запущенных агентов. Цена при этом не изменилась — $5/$25 за миллион токенов. Правда, есть нюанс: из-за нового токенизатора один и тот же текст теперь может «весить» до 35% больше токенов. А если выкрутить xhigh на максимум, модель начнет думать дольше и генерировать еще больше невидимых токенов размышления.
Managed Agents: микросервисная архитектура для агентов
Если Opus 4.7 — это мозг, то Managed Agents — попытка Anthropic создать для него надежное тело. Это новый хостинговый сервис внутри Claude Platform, предназначенный для управления агентами, выполняющими долгие задачи. Раньше разработчикам приходилось запирать модель, ее инструменты и лог сессии в один монолитный контейнер. Если контейнер зависал или падал — терялась вся история работы, и отладить этот «черный ящик» было почти невозможно.
В Managed Agents эту монолитную структуру распилили на независимые микросервисы, отделив логику Claude и его обвязку от среды выполнения и логов. Теперь, если песочница с кодом зависает, агент просто фиксирует ошибку, поднимает чистый контейнер и продолжает работу. Лог сессии хранится вне контекстного окна модели, что позволяет агенту запрашивать историю точечно, не перегружая токены.
Источник изображения
Побочный эффект оказался приятным: p50 TTFT упал на 60%, p95 — больше чем на 90%, потому что контейнер теперь поднимается, только когда реально нужен. Заодно решили проблему с утечкой токенов доступа. Теперь они лежат в защищенном хранилище и проксируются в песочницу, а не болтаются там с потенциально опасным кодом. Словом, получилась универсальная и масштабируемая среда выполнения, в которой разработчики могут запускать агентов, не переживая о падающей инфраструктуре.
Claude Design: от идеи до прототипа без дизайнера в штате
Anthropic решила автоматизировать и визуальную часть разработки, выпустив Claude Design. Это новый инструмент в экосистеме Claude на базе свежего Opus 4.7, который работает как гибрид чат-бота и Figma.
Инструмент дает возможность собирать рабочие прототипы прямо в привычном окне чата. Вы описываете, что вам нужно, модель собирает первый черновик, а дальше вы докручиваете его комментариями, прямым редактированием текста или через кастомные ползунки, которые нейросеть сама же и создает для настройки отступов или цветов.
Источник изображения
Для командной работы завезли интеграцию с корпоративным брендбуком. При подключении к кодовой базе или дизайн-файлам инструмент сам подтягивает фирменные цвета, типографику и компоненты ко всем новым генерациям. Готовый макет можно экспортировать в HTML, PDF, закинуть в Canva или передать Claude Code для превращения картинки в рабочий код. Пока инструмент доступен в режиме Research Preview только для платных подписчиков.
Google
Veo 3.1 Lite: генерация видео перестает сжигать бюджеты
Google продолжают делать свои топовые модели более доступными. На этот раз компания выпустила модель Veo 3.1 Lite, которая позиционируется как инструмент для разработки высоконагруженных видеоприложений. И главный аргумент в подтверждение — экономика: Lite-версия обойдется разработчикам более чем в два раза дешевле старшей версии Veo 3.1 Fast, при этом скорость создания роликов остается на том же уровне.
Источник изображения
Технически это вполне рабочая лошадка для базовых задач. Модель поддерживает форматы Text-to-Video и Image-to-Video, умеет выдавать картинку в 720p и 1080p, а также переключаться между альбомной (16:9) и портретной (9:16) ориентациями. В API можно жестко задать длину ролика — 4, 6 или 8 секунд, что автоматически корректирует итоговую стоимость запроса. Инструмент уже доступен на платном тарифе Gemini API и в Google AI Studio. А для тех, кому нужны мощности посерьезнее, Google срезали цены и на флагманскую Veo 3.1 Fast.
Источник изображения
Gemma 4: опенсорс на любой вкус, цвет и размер
Google выпустили четвертое поколение своего семейства открытых моделей Gemma, сделав ставку на продвинутый ризонинг и автономные рабочие процессы. Но главным сюрпризом релиза стала смена лицензии: компания прислушалась к сообществу и перевела всю новую линейку на коммерчески свободную Apache 2.0. Модели разделили на четыре весовые категории: компактные Effective 2B (E2B) и 4B (E4B) для локального запуска, а также «тяжеловесы» — 26B Mixture of Experts и 31B Dense. Все модели нативно работают с изображениями и видео, умеют обращаться к внешним функциям и поддерживают длинный контекст (128K токенов для младших и 256K для старших).
«Тяжеловесы» показывают отличную эффективность на единицу вычислений. В лидерборде Arena AI версия 31B Dense уже заняла третье место среди открытых моделей, а 26B MoE расположилась чуть ниже, обгоняя куда более массивных конкурентов. При этом 26-миллиардная MoE активирует во время инференса лишь 3,8 млрд параметров, выдавая высокую скорость генерации, а несжатые bfloat16-веса обеих старших версий спокойно помещаются в одну видеокарту NVIDIA H100 на 80 ГБ.
Источник изображения
С младшими версиями E2B и E4B Google пошли по пути максимальной автономности. Они оптимизированы для запуска прямо на смартфонах, Raspberry Pi или Jetson Orin Nano с околонулевой задержкой и без доступа к интернету. В качестве эксклюзивной фичи эти «малыши» получили нативную поддержку аудиовхода для распознавания речи, которой, что интересно, нет у старших собратьев. Android-разработчики уже могут обкатывать на них свои агентные сценарии в AICore Developer Preview, закладывая фундамент под грядущий выход Gemini Nano 4.
Gemini 3.1 Flash TTS: режиссерский режим для генерации голоса
Google решили немного оживить генерацию речи и выпустили Gemini 3.1 Flash TTS — свеженькую text-to-speech модель. Вместо того чтобы просто рапортовать о «еще более естественном звучании», разработчики добавили инструмент, который они сами называют «режиссерским креслом» — систему аудиотегов. Идея в том, что теперь управлять темпом, акцентом и интонацией теперь можно прямо в тексте с помощью встроенных тегов. Вы можете задать общую атмосферу сцены или прописать «режиссерские заметки» для конкретного спикера, заставив его изменить эмоцию посреди фразы.
Источник изображения
В теории (и в лидерборде Artificial Analysis, где модель набрала 1211 пунктов Elo) это выглядит как отличный компромисс между ценой синтеза и его качеством. Инструмент поддерживает более 70 языков и нативно склеивает многоголосые диалоги без необходимости генерировать реплики отдельно. Приятным бонусом для разработчиков стала функция экспорта: как только вы накрутили ползунки и добились желаемого звучания в песочнице, все параметры можно выгрузить в виде готового кода для Gemini API. Сейчас модель доступна в превью для разработчиков в Gemini API и Google AI Studio, а также для энтерпрайза через Vertex AI.
Gemini Robotics-ER 1.6: пространственное мышление становится доступнее
Пока текстовые модели соревнуются в бенчмарках, робототехника страдает от более приземленных проблем — вроде «как заставить робота понять, что он уже положил ручку в стакан, а не просто тычет ею мимо». Для таких задач Google выпустила Gemini Robotics-ER 1.6 — модель, которая работает как диспетчер для физических роботов, вызывая нужные инструменты: от обычного поиска до vision-language-action моделей. Главный апгрейд здесь — многокамерное зрение: теперь робот одновременно анализирует картинку с потолочной камеры и объектива на манипуляторе, самостоятельно детектируя успех или провал физического действия без команды оператора.
Одной из самых неочевидных, но востребованных фич стала способность читать аналоговые приборы — этот кейс Google отрабатывала совместно с Boston Dynamics для их роботов Spot, инспектирующих промышленные объекты. Инструмент использует механику «агентного зрения»: чтобы понять показания манометра или уровень в мерном стекле, модель программно зумирует картинку, рассчитывает интервалы между делениями и сопоставляет это со знаниями о перспективе и искажениях.
Источник изображения
Такой подход выдал 93% успешных считываний против скромных 67% у базовой Gemini 3.0 Flash. Заодно подтянули и физическую безопасность: модель теперь строго соблюдает заложенные ограничения и отказывается поднимать грузы тяжелее заданного лимита или работать с жидкостями.
Deep Research Max: поисковый агент взрослеет до автономного аналитика
Google решили сделать из хорошего инструмента лучший и обновили свой Deep Research. Его перевели на движок Gemini 3.1 Pro и разделили на две версии. Базовый Deep Research ускорили и удешевили для быстрых интерактивных задач, а вот новую версию Deep Research Max заточили под тяжелые асинхронные воркфлоу с максимальным использованием test-time compute.
Главный технический апгрейд релиза — встроенная поддержка Model Context Protocol (MCP). Если раньше агент копался только в открытом вебе и загруженных файлах, то теперь его можно безопасно натравить на закрытые корпоративные базы данных или вообще отключить интернет, оставив работать только во внутреннем контуре. А чтобы конечная выдача была не только полезной, но и наглядной, систему научили генерировать инфографику прямо внутри текста с помощью HTML или визуального движка Nano Banana.
Пример сгенерированного изображения из отчета. Источник изображения
Сам процесс стал прозрачнее: до старта поиска можно запросить у агента план исследования и скорректировать его, а во время выполнения следить за стримингом промежуточных размышлений.
Microsoft: Линейка MAI в сборе
Microsoft решили не оставлять в одиночестве выпущенный в прошлом месяце MAI-Image-2, и доукомплектовали его инструментами для работы со звуком.
За перевод аудио в текст теперь отвечает MAI-Transcribe-1. На тестах модель показывает себя вполне уверенно: в бенчмарке FLEURS по топ-25 языкам модель показала среднюю частоту словесных ошибок на уровне 3,9%. Для контекста, у Gemini 3.1 Flash этот показатель равен 4,9%, а у открытой Whisper-large-v3 — 7,6%. Microsoft утверждает, что модель работает в 2,5 раза быстрее их предыдущего решения Azure Fast, а обойдется работа в $0,36 за час обработанного аудио.
Источник изображения
Обратный процесс — синтез речи — делегировали MAI-Voice-1. Модель генерирует минуту звука за секунду, поддерживает разметку SSML для ручной настройки эмоций и умеет клонировать голос по нескольким секундам записи. Последнее — с оговорками. Учитывая количество скандалов с дипфейками, Microsoft обложила эту функцию многослойной бюрократией. Чтобы создать голосовой профиль, разработчику придется подать заявку на Gated Access в Azure, пройти ревью, а затем загрузить не только исходник, но и записанное голосовое согласие от человека-донора. Так что «угнать» чей-то голос для серой рекламной кампании теперь технически проблематично. Пока модель поддерживает только английский, остальные языки обещают позже. Цена — $22 за миллион символов.
Теперь у разработчиков есть все необходимое для того, чтобы не выходить из экосистемы Microsoft Foundry. Захотят ли они там остаться — уже вопрос другого порядка.
Muse Spark от Meta: начало нового семейства моделей
Поистине «золотая» лаборатория Meta Superintelligence, которую Цукерберг строил, переманивая исследователей у конкурентов, наконец представила свое долгожданное детище. Им стала модель Muse Spark — первенец нового семейства Muse. Это мультимодальная модель с поддержкой tool-use, визуальной цепочки рассуждений и мультиагентной оркестрации.
Источник изображения
Главной фичей на зависть конкурентам стал Contemplating mode. Суть режима — в распараллеливании: система запускает сразу несколько агентов, которые «думают» одновременно, удерживая задержку ответа на приемлемом уровне даже на сложных задачах. А чтобы модель не тратила токены впустую, в процесс обучения через RL заложили жесткий штраф за время размышления. Примечательно, что это породило эффект «сжатия мыслей»: после определенного порога обучения модель проходит фазу трансформации и начинает решать сложные задачи, используя значительно меньше токенов рассуждения без потери качества.
Результаты с включенным Contemplating mode. Источник изображения
Правда, у модели есть неприятный побочный эффект. Сторонние аудиторы из Apollo Research обнаружили у Muse Spark самый высокий уровень evaluation awareness из всех протестированных моделей: нейросеть по контексту понимает, что ее сейчас тестируют, замечает «ловушки выравнивания» и рассуждает о том, что должна вести себя честно, поскольку ее оценивают. Другой вопрос, реально ли это меняет поведение моделей. Meta провела собственное расследование и нашла лишь предварительные признаки того, что осведомленность может влиять на поведение в небольшом подмножестве тестов, никак не связанных с опасными сценариями. В итоге они сочли, что никакой угрозы для безопасности пользователей не несет, и пустили модель в релиз.
NVIDIA Ising: ИИ для квантовых вычислений
Nvidia выпустила семейство открытых моделей Ising, цель которых — превратить ИИ в операционную систему для квантовых процессоров. Проблема нынешних квантовых машин — в хрупкости кубитов, которые требуют постоянной калибровки и исправления ошибок в реальном времени. Nvidia же предлагают решать эту проблему, сделав ИИ своеобразным «операционным контроллером» для квантового железа.
Источник изображения
Систему разделили на два специализированных инструмента, первый из которых — Ising Calibration. Это 35-миллиардная мультимодальная модель (VLM), которая работает как высокоуровневый эксперт: анализирует визуальные и числовые данные экспериментов, приходящие с квантового процессора, и на их основе делает выводы о необходимых корректировках параметров. По задумке, это должно сократить время рутинной настройки оборудования с нескольких дней до пары часов.
Вторая часть системы — Ising Decoding, отвечающая за исправление ошибок. В отличие от тяжеловесной модели калибровки, здесь используются два компактных варианта 3D-сверточной нейросети на 0,9 и 1,8 млн параметров: один оптимизирован под скорость, другой — под точность. Каждый выполняет функцию пре-декодера, который распознает паттерны ошибок в поверхностных кодах быстрее и точнее классических алгоритмов — по внутренним тестам, в 2,5 раза быстрее и в 3 раза точнее индустриального стандарта pyMatching.
Веса и фреймворки для дообучения под конкретные архитектуры QPU уже выложены в открытый доступ, чтобы квантовые стартапы могли перестать изобретать велосипеды для борьбы с шумом.
GLM-5.1: модель, которая не сдается
Китайская Z.ai выпустила флагманскую модель для кодинга GLM-5.1, и в этот раз они взялись за одну из основных проблем современных ИИ-агентов — быстрое выгорание. Обычно языковые модели выдают пару хороших решений на старте, а если задача требует долгой отладки, начинают ходить по кругу. GLM-5.1 же научили работать вдолгую: она умеет останавливаться, перечитывать логи, понимать, что уперлась в тупик, и радикально менять стратегию.
Чтобы доказать это, разработчики устроили модели марафон. В тесте VectorDBBench нейросети дали 50 ходов на оптимизацию базы данных. Базовая версия уперлась в потолок, а вот GLM-5.1, запущенная в бесконечном цикле, сделала более 600 итераций и 6000 вызовов инструментов. Модель сама догадалась сменить метод сканирования и сжать векторы, выдав в итоге 21,5k QPS — примерно в 6 раз больше лучшего результата, достигнутого в стандартном режиме с 50-ходовым бюджетом Claude Opus 4.6. Причем на графике четко видно, как нейросеть ломает код, тестирует новую гипотезу и затем стабилизирует результат.
Источник изображения
Такой же трюк сработал и при создании Linux-подобного десктопа в браузере с нуля. Оставленная на 8 часов наедине с задачей, модель допилила файловый менеджер, терминал и калькулятор, постоянно оценивая собственный код. Конечно, на тестах ML-оптимизации Opus 4.6 все еще держится бодрее, но китайцы явно нащупали правильный вектор развития. Модель традиционно выложили в опенсорс под MIT-лицензией.
DeepSeek-V4: миллион токенов контекста со скидкой на память
После небольшой паузы главные возмутители спокойствия из Поднебесной выложили в опенсорс превью-версии семейства V4: флагманскую V4-Pro (1,6 трлн параметров, активно 49 млрд) и легковесную V4-Flash (284 млрд всего, 13 млрд активно). Обе нативно переваривают контекст в миллион токенов, и чтобы алгоритм внимания не захлебнулся от такого объема, разработчики заменили его на новую гибридную систему.
Она работает в два потока. CSA (Compressed Sparse Attention) сжимает KV-кэш и применяет фирменный DeepSeek Sparse Attention, а HCA (Heavily Compressed Attention) сжимает кэш еще агрессивнее, но прогоняет через него уже плотное внимание. Так, модель учится экстремально экономить память, но не теряет контекст. Отдельным нововведением стали mHC — они усиливают классические остаточные связи между слоями и не дают полезному сигналу затухнуть при прохождении через сеть. В итоге на окне в миллион токенов тяжеловесная V4-Pro требует лишь 27% вычислений и 10% KV-кэша по сравнению с прошлой V3.2, а Flash и вовсе укладывается в 10% и 7% соответственно.
Архитектура моделей серии V4. Источник изображения
Дообучали эту конструкцию тоже нестандартно. Сначала сетку расщепили на узких специалистов, натаскали их по отдельности — сначала через дообучение на профильных данных (SFT), затем через обучение с подкреплением (RL с GRPO), — а потом слили полученные навыки в единую модель методом дистилляции. На практике это дало отличный результат — в работе с длинным контекстом версия V4-Pro-Max обходит ту же Gemini 3.1 Pro, а в агентных задачах уверенно держится на уровне ведущих открытых моделей, хотя сами авторы честно признают, что по рассуждениям отстают от GPT-5.4 и Gemini 3.1 Pro примерно на три-шесть месяцев.
События индустрии
Служба безопасности Anthropic объявляет месяц открытых дверей
Апрель для Anthropic выдался, мягко говоря, напряженным. Компания, которая построила весь свой имидж на строгих протоколах безопасности, за один месяц умудрилась допустить сразу три утечки, доказав, что главный риск для ИИ — это по-прежнему человек с мышкой.
Началось все с банальной ошибки в конфигурации корпоративной CMS: кто-то просто оставил внутреннее хранилище публичным по умолчанию. В итоге в интернет утекли почти 3000 внутренних файлов, включая черновики корпоративного блога, логотипы и, что самое неприятное, неанонсированные подробности о той самой «небезопасной» модели Mythos.
Дальше — больше. При выпуске минорного апдейта 2.1.88 для утилиты Claude Code инженеры случайно упаковали в публичный релиз почти 2000 файлов с более чем 512 тысячами строк исходного кода, раскрыв устройство инструмента.
Источник изображения
Понимая масштаб катастрофы, юристы Anthropic судорожно отправили пачку DMCA-страйков на GitHub, требуя удалить репозитории тех, кто успел скопировать утечку. Но в спешке они промахнулись и случайно снесли около 8100 репозиториев, включая легальные форки своего же официального публичного клиента. Позже страйки пришлось массово отзывать, извиняясь перед разгневанным комьюнити разработчиков и списывая все на очередную «ошибку».
Вишенкой на торте этого парада кибербезопасности стала утечка доступа к Claude Mythos, который Anthropic вроде как спрятали за семью замками. Ирония в том, что эту «самую опасную нейросеть» предположительно скомпрометировали в первый же день. Группа энтузиастов из закрытого Discord-канала проанализировала паттерны именования API, просто угадала нужный эндпоинт Mythos и зашла туда через легитимную учетную запись одного из подрядчиков. В итоге «герои-взломщики» спокойно пользовались самым страшным ИИ-оружием несколько недель, пока слив не предали огласке. В компании заявили, что их собственные системы не взломаны, и сейчас они ищут виноватого среди вендоров. Однако инцидент выглядит особенно неприятно на фоне возможного IPO.
Anthropic починила Claude Code (предварительно его сломав)
Этой весной пользователи Claude Code начали замечать, что их любимый кодинг-агент стал откровенно лениться. Ситуацию перевела из разряда слухов в плоскость цифр Стелла Лорензо — старший директор по ИИ в AMD. Она выпустила подробный отчет на основе тысяч логов, где с цифрами на руках доказала: с февраля модель начала стремительно деградировать. Агент перестал читать код перед его редактированием, начал застревать в бесконечных циклах самоисправлений и регулярно выдавать фразы в духе «это слишком сложно, давайте остановимся». Стелла предположила, что это связано с внедрением параметра redact-thinking и возможным негласным урезанием лимитов на токены размышления.
В ответ пришел глава команды Claude Code Борис Черный и попытался успокоить сообщество. По его словам, redact-thinking — это UI-заглушка, чтобы не загромождать интерфейс, а модель якобы думает так же глубоко, как и раньше. Однако честно признал: компания действительно понизила дефолтный уровень усилий с High на Medium ради снижения задержки.
Источник изображения
Казалось бы, тайна раскрыта, нужно просто вернуть настройки. Но полноценный внутренний аудит Anthropic показал, что снижение effort — это лишь верхушка айсберга, а агент пал жертвой сразу трех независимых апдейтов, которые неудачно наложились друг на друга.
Первым фактором действительно стал перевод дефолтного ризонинга с High на Medium — его пришлось откатить. Второй баг крылся в оптимизации кэширования: старые рассуждения агента должны были удаляться при долгом простое сессии. Но из-за бага скрипт начал стирать память агенту на каждом шаге, превращая его в золотую рыбку, которая не помнит, зачем вообще пишет этот код.
Контрольным выстрелом стал новый системный промпт: пытаясь заставить новенький Opus 4.7 писать короче, ему жестко запретили использовать больше 25 слов между вызовами инструментов, что сломало логику планирования. В итоге все изменения откатили, а лимиты пользователям сбросили. Самое ироничное в этой ситуации то, что при разборе инцидента Anthropic натравила Opus 4.7 на проблемные пулл-реквесты, и модель нашла тот самый баг с кэшированием, который благополучно пропустили живые программисты и автоматические тесты.
Сэма Альтмана настигла карма
The New Yorker опубликовал расследование о Сэме Альтмане, в котором на основе внутренних документов, материалов исков и свидетельств бывших сотрудников разбираются его спорные управленческие решения и конфликты внутри компании. Статья вышла объемной — прочитать ее целиком можно здесь. Ниже кратко разберем ключевые эпизоды.
Источник изображения
Во-первых, многие коллеги годами документировали действия Сэма, попросту не доверяя его словам. В частности, бывшие члены совета директоров описывали его как социопата, не связанного правдой, а Дарио Амодей еще во время работы в OpenAI говорил коллегам, что слова Альтмана — «почти наверняка чушь», а главная проблема компании — сам Сэм.
Во-вторых, выяснилось, что хваленая команда по «супервыравниванию» (Superalignment), которой обещали 20% мощностей компании, сидела на старом железе, пока все ресурсы шли на коммерческие запуски. При этом сам CEO продолжает лоббировать многотриллионный проект инфраструктуры Stargate среди инвесторов из ОАЭ, несмотря на угрозы нацбезопасности США. Как метко подметил кто-то из инвесторов, «политика Сэма — это всегда сначала Сэм».
Публикация имела пугающе радикальные последствия. Вскоре после выхода статьи неизвестный бросил коктейль Молотова в дом Альтмана в 3:45 утра, благо бутылка отскочила от ворот, и никто не пострадал. Сразу после этого Сэм опубликовал длинный пост в блоге, где признал, что «недооценил силу нарративов», извинился за прошлые корпоративные конфликты и философски назвал AGI «кольцом всевластия», которое сводит людей с ума. Но манифест не сработал: еще через два дня по его дому открыли стрельбу из проезжавшей мимо машины. И хотя Альтман продолжает заявлять о работе на пользу человечества, на фоне того, как OpenAI агрессивно монетизирует свои сервисы и вытесняет конкурентов, пока с трудом верится, что он действительно готов пожертвовать личной властью ради всеобщего блага.
Проблемы с финансовой грамотностью в OpenAI
Внутри OpenAI назревает классический конфликт между видением CEO и человеком, который должен это видение оплачивать. По данным The Information, Сэм Альтман планирует вывести компанию на IPO уже в четвертом квартале этого года и параллельно обязался потратить $600 млрд на аренду и постройку дата-центров до 2030 года. Проблема в том, что финансовый директор OpenAI Сара Фрайар от этих планов, мягко говоря, не в восторге. Еще в начале года она говорила коллегам, что компания к IPO не готова процедурно, а рост выручки может просто не покрыть такие гигантские предзаказы на железо.
Источник изображения
Но Альтман, видимо, не любит, когда ему мешают тратить деньги, поэтому CFO сняли с прямого подчинения CEO и перевели под крыло главы бизнес-приложений. Более того, ее стали исключать из обсуждений финансовых вопросов, которые обычно находятся в зоне ответственности CFO.
Дарио Амодей, к слову, в феврале объяснял в подкасте без имен, что ошибка в прогнозе на пару лет при таких темпах трат способна закончиться банкротством. Когда ваш главный конкурент и ваш собственный CFO говорят примерно одно и то же — возможно, стоит все же остановиться и задуматься.
Иллюзия достоверности: как исследователи взломали главные бенчмарки с результатом 100%
Вопрос достоверности результатов бенчмарков уже некоторое время стоит довольно остро, но так близко к провалу Штирлиц еще не был никогда. Группа ИБ-исследователей решила проверить на прочность топовые агентные бенчмарки, и находка оказалась отрезвляющей: почти каждый из них можно взломать на 100%, не решив при этом ни одной задачи.
Источник изображения
Механика взлома везде разная, но суть одна: агент и оценщик работают в одной среде, которая никак не защищена от вмешательства — а значит, вместо решения задачи можно просто переписать правила игры. Например, в WebArena агент тупо заходил в локальную файловую систему через браузер и читал JSON-файл с правильными ответами, который организаторы забыли спрятать. А на SWE-bench хватило десяти строк в conftest.py — pytest-хук перехватывал тесты и принудительно помечал все как пройденное.
Главная проблема даже не в том, что можно накрутить цифры намеренно, а в том, что эксплуатация бенчмарков уже наблюдалась у реальных моделей — o3, Claude 3.7 Sonnet и Mythos Preview — без каких-либо инструкций это делать. Достаточно способный агент находит дыры сам в процессе оптимизации, потому что сломать оценщик проще, чем решить задачу. В таких условиях результаты бенчмарков начинают отражать не качество решения, а способность модели эксплуатировать систему оценки.
«ИИ-код работает, но он отвратительный»: Карпати — о текущих возможностях ИИ-агентов
Андрей Карпати, сооснователь OpenAI и автор термина vibe coding, на выступлении в Sequoia Capital сравнил современных ИИ-агентов со стажерами и заявил, что код, который они генерируют, по-прежнему "раздутый, хрупкий и просто отвратительный". По словам Карпати, разработчик в 2026 году все еще обязан контролировать эстетику, суждение, вкус и общий ход работы — отдавать всю разработку агенту нельзя.
"Иногда у почти меня случается небольшой сердечный приступ, потому что это не всегда какой-то супер-отличный код", — рассказал Карпати. По его словам, агенты выдают результат, который "очень раздутый, в нем куча копипасты и неуклюжих хрупких абстракций — оно работает, но это просто отвратительно". Сами агенты он описал как "сущности уровня стажера", за которыми пока нужен постоянный надзор.
При этом Карпати уточнил, что нет ничего фундаментального, что мешало бы моделям писать чистый код — просто лаборатории до сих пор не делали это приоритетом при обучении. То есть проблема не архитектурная, а вопрос фокуса тренировки.
Тем не менее, волна вайб-кодинга уже успела перекроить рынок: оценки стартапов Cursor, Lovable и Replit ушли в миллиарды долларов, а техкомпании пересмотрели подходы к найму и оплате разработчиков. Параллельно копится список инцидентов, которые дают повод сомневаться в подходе. Недавно шведская платформа Lovable признала, что в феврале при унификации прав доступа в бэкенде "случайно снова открыла доступ к чатам в публичных проектах" — после жалоб исследователей в X настройки вернули обратно.
В сухом остатке автор термина фактически присоединился к лагерю профессиональных разработчиков, которые предостерегают от чрезмерной опоры на ИИ-код. Чистый, проверенный, неломкий код от агентов — это, по логике Карпати, вопрос времени и приоритетов лабораторий. Однако сам Карпати продолжает кодить именно таким образом: ранее он высказывался, что с помощью ИИ пишет до 80% кода.
Канал с гайдами и контентом по claude code, выкладываем новости (когда режут лимиты в 10 раз) и какие инструменты через claude реализуем для проектов, канал: https://t.me/claudedevolper
Все мы знаем этот рабочий любовный треугольник: клиент — дизайнер — разработчик.
Канал с гайдами и контентом по claude code, выкладываем новости (когда режут лимиты в 10 раз) и какие инструменты через claude реализуем для проектов, канал: https://t.me/claudedevolper
Клиент: «А давайте при движении мышки у нас из частиц соберётся грузовик, а потом ещё и датчик слежения за ним?»
Дизайнер: «Я нарисовал. Примера анимации нет, но я тебе сейчас всё объясню на словах…»
Разработчик: «А можно хотя бы референс, механику движения и понимание, что должно происходить?»
Знакомо? Особенно когда клиент хочет «как у Apple», дизайнер придумал красоту, а фронтендеру нужно понять, как это реализовать и сколько времени закладывать.
Расскажу, как облегчить жизнь всем троим, когда дело доходит до сложных интерактивных анимаций, геймификации, скролл-эффектов и прочей «вау-фигни».
Ситуация 1. Клиент хочет эффект воды, ряби или капель на hero-блоке при движении курсора
Ситуация не то чтобы страшная, но попотеть придётся. Есть несколько вариантов решения этого вопроса.
Вариант 1: если есть референс — вообще замечательно! Беру страницу с похожим эффектом, нажимаю на правую кнопку мыши или на тачпад, выбираю «Просмотр кода», выделяю весь код и вставляю в любой текстовый редактор. Я пользуюсь стандартным Google Docs, но можно и блокнотом, ну, или скачивайте в формате .txt.
«Из этого кода надо вычленить кусок, который отвечает за анимацию воды на hero-блоке»
Вот какой результат выдаёт нейронка:
Иииии...ничего не заработало, иду дальше.
Пишу следующий промпт: «Прикрути к коду тёмный фон, чтобы хорошо посмотреть эффект воды»
На превью видно, что фон есть, но эффект еле-еле заметный.
Но мы не сдаёмся!
Пишу дальше: «Код не работает, найди ошибки»
Тут уже виден сам эффект: он реагирует на мышь, и рябь есть. Этот код можно скопировать, приложить к макету и отдать разработчикам. Если требуется замедлить эффект, сделать капли более крупными или мелкими — меняем настройки, но лучше попросить об этом знающих и умеющих людей. В конце концов, можно попросить об этом и нейронку, если таковых нет.
Вариант 2: Можно найти похожий эффект в сервисах с готовым кодом и отправить его в качестве рабочего варианта.
Например, такие штуки можно искать на CodePen.
Пишу в поисковой строке «Water ripple effect» и смотрю, что выдаст поиск.
Нахожу наиболее привлекательный вариант и открываю код. Можно также менять настройки, а можно отдать как есть.
CodePen — это кладезь разных эффектов и анимаций, советую его использовать для насмотренности. Там можно кидать анимации в избранное, чтобы не потерять)
Небольшой совет: обращайте внимание на название самого эффекта. Его можно скопировать и использовать для более точного поиска.
Ситуация 2. Клиент хочет «взрыв-схему» бургера (или любого продукта)
Клиент открывает свою бургерную и хочет что-то УНИКАЛЬНОЕ, как у Apple, и чтобы всё вертелось, крутилось, но было минималистично и лаконично. В общем, хочет «взрыв-схему» бургера, завязанную на скролл.
Ок! Хочет — буду делать.
Шаг 1. Генерирую исходную картинку
На просторах Pinterest я нашла промпт, который бы мне подошёл, чтобы сократить время.
Промпт:
Скрытый текст
Иду в бесплатный Gemini и вставляю промпт.
Получается такой результат:
Шаг 2. Собираю бургер обратно
Всё в том же Gemini собираю бургер.
«Assemble the burger–make sure it doesn't fall apart»
Получаю две картинки:
Иду в Figma и готовлю материал:
Делаю однотонный фон, желательно того же цвета, что и фон сайта.
Делаю одинаковый формат — это важно! Один фон, одно позиционирование и один размер картинки.
Шаг 3. Делаю плавный переход в Kling
Выгружаю картинки в формате JPEG и иду в Kling для генерации видео. Зачем? Чтобы потом покадрово разложить видео и привязать кадры к скроллу.
Выбираю формат работы — «Generate».
Выставляю первый и финальный кадр самого видео.
Получаю видео с зацикленным результатом.
Шаг 4. Превращаю видео в интерактивный скролл-эффект
Для классного результата нужны промпты, спецификация и вот это вот всё. Я, честно, лентяйка, поэтому просто переписала уже готовые документы под нужную тематику, также через Grok.
Томить не буду, просто вставлю всё сюда.
Папка с файлами.
Беру 3-й промпт, вставляю его и прикрепляю все остальные документы из папки.
Промпт:
Скрытый текст
ВАЖНО! Названия файлов должны совпадать с названиями в промпте.
Добавляю всё это в Claude и получаю такой результат:
Врать не буду — чтобы получился крутой результат, мне пришлось прям попотеть: то нейминги не совпадают, то он не брал мой бургер, а рисовал свой схематичный, то Claude отваливался и делал чушню. Так что не совершайте моих ошибок и идите чётко по алгоритму.
Ситуация 3. Логотип распадается и собирается из частиц
Идея классная, но что с ней делать?! Объяснить такое тяжело, но есть несколько вариантов.
Можно вернуться к предыдущим сценариям, а можно перейти в Spline. Там есть возможность для создания своих анимаций, а ещё внедрение уже придуманных эффектов.
Перехожу в раздел «Community» и вбиваю в поиске «Particles».
Нахожу нужный референс:
Захожу в рабочее пространство самого эффекта
Загружаю в него 3D-рендер модели. В моём случае это был сложный грузовик, но в целом, это может быть что вашей душе угодно. Вопрос лишь в том, что чем проще фигура, тем лучше она будет выглядеть — это в целом логично. Условно, квадрат или несложный логотип будут более эффектными и менее замороченными по настройкам.
Далее кручу, верчу и настраиваю сами частицы, делаю их крупнее или мельче, много или мало. Настраиваю интерактивное взаимодействие анимации и мышки, скорость реакции, резкость — ну, вы поняли. Лучше это всё отдавать вашему моушен-дизайнеру, но в целом, разобраться реально. Подробнее на видео:
После того, как видимый результат начал вызывать экстаз и истерический восторг, экспортирую скрипт, который описывает данную анимацию.
Отдаю все файлы фронту и живу в мире и благополучии.
Есть одно НО — этот сервис платный.
Итоговые лайфхаки для дизайнеров и разработчиков:
Не пытайтесь объяснять сложную анимацию только на словах. Лучше сразу прикладывайте референсы, код и видео.
CodePen, Spline Community и готовые эффекты на GitHub — это ваши лучшие друзья.
ИИ (Grok, Claude и Kling) сильно ускоряет процесс, но работает лучше всего в связке: один генерит визуал, второй — код, а третий помогает отлаживать результаты.
Самый быстрый путь к вау-эффектам — комбинация: референс → ИИ-разбор → доработка → готовый код.
Сложные анимации больше не повод для войны в чате. Теперь это просто ещё один инструмент, которым можно пользоваться быстро и с удовольствием.
Канал с гайдами и контентом по claude code, выкладываем новости (когда режут лимиты в 10 раз) и какие инструменты через claude реализуем для проектов, канал: https://t.me/claudedevolper
Британский AI Security Institute (AISI) опубликовал оценку кибер-возможностей GPT-5.5. По собственной оценке института, это потенциально самая сильная модель из всех протестированных. На наборе экспертных задач по реверс-инжинирингу, разработке эксплойтов и криптографии модель в среднем берет 71.4% — выше, чем Mythos Preview (68.6%), GPT-5.4 (52.4%) и Claude Opus 4.7 (48.6%).
Самая показательная иллюстрация — задача rust_vm, которую для AISI готовила компания Crystal Peak Security. Это пара файлов: бинарник на Rust без отладочных символов с собственной виртуальной машиной и байткод неизвестного формата, проверяющий пароль на порту 8080. Эксперт компании, вооруженный Binary Ninja, gdb, Python и SMT-решателем Z3, решал задачу около 12 часов. GPT-5.5 в базовой ReAct-обвязке с Bash и Python в контейнере Kali Linux прошла все пять фаз — от восстановления таблицы переходов по ELF-релокациям до решения через комбинаторный перебор — за 10 минут 22 секунды. Стоимость API-вызовов — $1.73.
Не менее показательны результаты на сетевых полигонах AISI — многоэтапных сценариях, имитирующих реальные атаки. На "The Last Ones", 32-шаговой симуляции взлома корпоративной сети, разработанной совместно со SpecterOps, GPT-5.5 прошла цепочку от начала до конца — это удалось всего одной модели до нее, Mythos Preview. У GPT-5.5 — 2 успешных попытки из 10, у Mythos было 3 из 10. На сценарии для промышленных систем Cooling Tower от Hack The Box (симуляция атаки на электростанцию) модель не справилась, но застряла на IT-этапах — то есть по этому результату нельзя судить о ее способностях против самих промышленных систем.
Параллельно AISI провел red-teaming защитных механизмов GPT-5.5. Экспертам хватило шести часов, чтобы найти универсальный джейлбрейк, заставлявший модель отвечать на все вредоносные кибер-запросы из набора OpenAI — в том числе в многоходовых агентных сценариях. После этого OpenAI обновила несколько слоев защиты, но проверить финальную конфигурацию AISI не смог: в предоставленной версии оказалась ошибка настройки.
В тот же день, когда вышел отчет AISI, Сэм Альтман анонсировал выход GPT-5.5-Cyber — специальной версии базовой модели для защитников критической инфраструктуры через программу Trusted Access for Cyber. Это следующий шаг после GPT-5.4-Cyber, выпущенной в начале апреля. Главный вывод AISI: рост кибер-навыков идет как побочный эффект общих улучшений в работе на длинном горизонте, рассуждениях и программировании, поэтому новые скачки могут пойти один за другим уже в ближайшее время.
За год доля зумеров с надеждой на ИИ упала с 27 % до 18 %
По данным Harvard-Gallup, 74 % молодых взрослых в США пользуются чат-ботами минимум раз в месяц, а более половины американских студентов — еженедельно для учёбы. При этом 79 % опрошенных Gallup считают, что ИИ делает людей ленивее, а 65 % — что чат-боты «дают моментальное удовлетворение, а не реальное понимание».
В свежем опросе Gallup отношение Gen Z к ИИ пробило новый минимум:
18 % испытывают надежду по поводу технологии — против 27 % годом ранее;
22 % воодушевлены — против 36 % годом ранее;
Доля считающих, что риски ИИ перевешивают пользу, приблизилась к 50 %;
8 из 10 признают: ИИ ускоряет работу, но затрудняет настоящее обучение.
Исследование MIT Media Lab зафиксировало сниженную мозговую активность на ЭЭГ у людей, пишущих эссе с помощью ИИ. Этот феномен — «когнитивную разгрузку» (cognitive offloading) — связывают со снижением скептицизма и ослаблением способности отличать правду от обмана. По данным University of Pittsburgh, студенты воспринимают использование ИИ сокурсниками как «красный флаг».
Параллельно университеты ускоренно встраивают ИИ в учебный процесс: заключают многомиллионные контракты с OpenAI и Anthropic, объединяют факультеты Computer Science и инженерии в новые «ИИ-направления».
Опрошенные The Verge зумеры говорят, что больше беспокоятся не за себя, а за поколение Альфа: эти дети растут с ИИ, встроенным во всё, и рискуют не научиться относиться к нему критически.
В этой статье ты получишь полный гайд по Claude Code.. В одной этой статье вся информация, которая тебе нужна..
0. Вступление
Привет. Начнем с того, что компания Anthropic в последнее время обновляет продукты с совершенно безумной скоростью, настолько, что даже многие глубоко вовлечённые пользователи с трудом успевают следить. Практически каждый день выходят новые версии, а с января этого года крупные обновления стабильно выпускаются примерно раз в две недели.
Новые модели, новые инструменты, новые интеграции и даже целые новые категории продуктов появляются непрерывно. Стоит отвлечься или отдохнуть пару недель и вы, скорее всего, уже пропустили немало ключевых изменений. И да, Claude действительно меняет ваш способ работы, это не подлежит сомнению.
Все что было запущено на Claude по состоянию на 23 марта 2026 года, здесь будет охвачено: как настроить каждую функцию, в каких сценариях её использовать и какие лучшие практики реально работают. Понимание этих различий, это именно то, что отделяет «вау, прикольно» от «реально перестроил рабочий процесс».
Новые продукты в экосистеме Claude.
Скорее всего, вам захочется сохранить эту статью и возвращаться к ней. Можете также поделиться ею с командой или друзьями. Это именно тот справочник, который я хотел бы иметь под рукой, когда только начинал разбираться.
1. Какие модели доступны в Claude?
Линейка Claude 4.6 сейчас разделена на три уровня моделей. Ниже, пределы возможностей каждой модели и подходящие сценарии использования:
Claude Opus 4.6 это текущий потолок производительности. Выпущен 5 февраля 2026 года, поддерживает контекстное окно в 1 миллион token (об изменении цен, ниже). При контексте в 1 миллион token показатель MRCR v2 составляет 78,3% — это лучший результат среди моделей аналогичного класса.
Лидирует по всем направлениям в задачах из области права, финансов и программирования. Anthropic сообщает, что модель способна непрерывно выполнять задачи до 14,5 часов, это рекорд среди frontier-моделей. Цена API — $5 / $25 за миллион token (вход/выход), максимальный выход — 128K token. Поддерживается адаптивное рассуждение с новым уровнем «max» для раскрытия предельных возможностей.
Примечание: показатель MRCR v2 — это метрика способности модели «найти нужную информацию в сверхдлинном контексте».
> Подходящие сценарии (Opus): сложный анализ больших объёмов контекста, рефакторинг кодовых баз, глубокий ресёрч, задачи с высокими ставками, серьёзное создание контента, и вообще всё, где «качество важнее стоимости».
> Неподходящие сценарии (Opus): любые рабочие процессы с частыми вызовами. При текущих ценах интенсивное использование Opus может обходиться в $50–100 в день. По умолчанию следует использовать Sonnet и переходить на Opus только тогда, когда качество выдачи Sonnet недостаточно.
Тут автор имеет в виду работу через API. При использовании подписки хотя бы начиная с 100$/m, можете спокойно использовать опус как основную модель
Claude Sonnet 4.6 вышел 17 февраля, всего через 12 дней после Opus, и является выбором по умолчанию для большинства пользователей. Также поддерживает контекст в 1 миллион token (доступен с 13 марта). Улучшения в кодинге, управлении компьютером, рассуждении на длинном контексте, планировании Agent, работе со знаниями и дизайне. В ранних тестах около 70% пользователей предпочли Sonnet 4.6 (по сравнению с 4.5), а в 59% сценариев он даже превзошёл предыдущий флагман Opus 4.5.
На claude.ai используется как модель по умолчанию для Free и Pro пользователей. Цена API — $3 / $15 за миллион token, максимальный выход — 64K token, скорость примерно на 30–50% выше по сравнению с 4.5.
> Подходящие сценарии (Sonnet): повседневная работа, быстрые черновики, типовые задачи программирования, Agent-воркфлоу, баланс между скоростью и интеллектом. Во многих офисных сценариях его результаты уже близки к Opus или даже превосходят его (в бенчмарке OfficeQA от Anthropic Sonnet лидирует в ряде задач), при этом стоимость примерно на 40% ниже.
Claude Haiku 4.5 — это бюджетная сверхбыстрая модель для сценариев с высокой нагрузкой, в основном для API-пайплайнов или задач субагентов (subagent), например задач с обработкой «только на чтение».
Но есть одно важное условие: Haiku полностью лишён защиты от prompt-инъекций. Если вы используете его в Agent системах для обработки недоверенного ввода, необходимо тщательно оценить риски и внимательно изучить официальную документацию.
2. Повышение контекста до 1 миллиона
Раньше запросы, превышающие 200K token, требовали доплаты (для Opus цена могла достигать $10 / $37,5 за миллион token). Но с 13 марта эта наценка полностью отменена. Теперь стоимость за token для 900K и 9K, абсолютно одинаковая. Без множителей, без скрытых условий, без необходимости в beta header.
Что это значит? Примерно 750 тысяч слов контекста можно загрузить за один раз: целую кодовую базу, полный юридический контракт, масштабный датасет, документацию за несколько месяцев, и всё это хранится в одной «рабочей памяти».
Одновременно улучшены мультимодальные возможности, теперь за один запрос можно обработать до 600 изображений или страниц PDF (раньше было 100, рост в 6 раз). На данный момент доступно на Claude Platform, Microsoft Foundry и Google Cloud Vertex AI.
Для команд это изменение совершенно конкретное: то, что раньше требовало chunking'а, пайплайнов суммаризации (summarization pipelines), управления скользящим окном контекста (rolling context),, теперь можно просто загрузить целиком. Некоторые компании уже отмечают, что после увеличения контекста с 200K до 500K общее потребление token, наоборот, снизилось, потому что модель больше не перечитывает и не переобрабатывает историю повторно.
3. Четыре режима использования Claude
Claude предлагает четыре режима, но большинство людей пользовались только одним из них:
> Chat
Самый знакомый интерфейс — в браузере или на мобильном. Подходит для вопросов, мозгового штурма, написания черновиков. Каждый разговор начинается с нуля, и вы всегда управляете процессом.
> Cowork
Десктопный Agent. Может напрямую читать и изменять ваши локальные файлы, автоматически выполнять многошаговые задачи и выдавать результат прямо в вашу папку. Подходит для того, чтобы «отдать задачу», а не вести диалог туда-сюда.
> Code
Режим для разработчиков, работает в терминале. Имеет доступ к кодовой базе, пишет код, выполняет команды, управляет Git. Если вы пишете код, это самый норм режим .
> Projects
Персистентное рабочее пространство. Достаточно один раз загрузить файлы и инструкции, и каждый новый разговор автоматически получит полный контекст. Подходит для повторяющихся задач: еженедельные отчёты, newsletter, клиентские поставки и т.д.
Простое правило выбора: Chat, для быстрых вопросов, Cowork, чтобы AI сделал работу за вас, Code, для задач разработки, Projects, для повторяющейся работы со стабильным контекстом
Варианты работы с Claude.
Тут автор не упоминает что на базе Claude Code можно сделать и полностью автономного агента, запустив его на отдельном сервере, а не на своем компьютере
4. Память и персонализация
По состоянию на 2 марта 2026 года Claude открыл функцию памяти на основе истории чатов для всех пользователей, включая бесплатных. Claude извлекает релевантный контекст из ваших разговоров и формирует сводку памяти, которую можно использовать между сессиями. Просмотреть, отредактировать или удалить эти записи можно в Settings > Capabilities. Также поддерживается импорт и экспорт полного дампа памяти, удобно как для создания бэкапа перед внесением правок, так и для переноса на новый аккаунт. Если включён режим инкогнито (Incognito), содержимое таких разговоров в память не записывается.
Ключевое действие здесь: прямо сейчас зайдите в Settings > Memory и посмотрите, что Claude уже «запомнил». Исправьте неточную или устаревшую информацию и добавьте контекст, который ему стоит знать. Чем точнее ваша память, тем меньше вам придётся объяснять одно и то же в разных сессиях.
Важно учитывать: между сессиями в режиме Cowork память не наследуется. Если вам нужен постоянный контекст, его придётся компенсировать через «контекстные файлы» (подробнее — в разделе Limitations ниже).
5. Как эффективно использовать Cowork
Cowork можно назвать полным переворотом правил игры. Он был запущен 12 января на macOS в формате исследовательского превью (для пользователей Claude Max), затем 16 января расширен на пользователей Pro, 23 января — на Team и Enterprise, после чего вышла и версия для Windows. Реакция рынка была предельно прямой, инвесторы моментально поняли, что это означает, рыночная капитализация SaaS-компаний испарилась на сотни миллиардов долларов за считанные дни, Уолл-стрит считал этот путь.
Но ключевой момент: перестаньте воспринимать его как чат-интерфейс.
Суть Cowork, это делегирование задач.
Вам нужно лишь описать «как выглядит готовый результат», Claude автоматически составит план, декомпозирует подзадачи, самостоятельно выполнит их в реальной среде вашего компьютера и доставит итоговые файлы в вашу папку. Вы можете просто уйти, а когда вернётесь, работа уже сделана.
Интересный факт, что сами Антрофик построили Cowork всего за 10 дней используя Claude Code.
6. Настройки в Cowork которые меняют все
Те, кто не может эффективно использовать Cowork, как правило, всё ещё следуют старым привычкам: пишут длинные, детализированные промпты для каждой задачи, а результат всё равно нестабильный.
А те, кто действительно разобрался, делают другое: тратят один день на то, чтобы выстроить «контекстную среду» (включая файлы контекста, глобальные инструкции, структуру папок), а затем промптом из 10 слов получают результат, который можно сразу отдавать клиенту.
Логика за этим такая: > ChatGPT учил вас писать лучшие промпты > Cowork вознаграждает за построение лучшей «файловой системы»
Первое, навык, который обесценивается по мере эволюции моделей, второе, способность, которая непрерывно приносит сложный процент.
Шаг 1: Создайте рабочую папку
Создайте на компьютере отдельную папку специально для Cowork.
Не направляйте его на весь каталог Documents (Документы). Если что-то пойдёт не так (а это вполне может случиться), вам нужно ограничить зону поражения до минимума. Потому что Cowork имеет реальные права на чтение и запись в авторизованной вами папке.
CLAUDE COWORK/ ├── CONTEXT/ # Your identity and preferences (.md files) ├── PROJECTS/ # Active work, one subfolder per project ├── TEMPLATES/ # Proven structures to reuse as patterns └── OUTPUTS/ # Where Cowork delivers finished work
Такой подход и сохраняет структуру чистой, и ограничивает область доступа Claude. Практически все опытные пользователи в итоге приходят к похожей базовой структуре. Неважно, как называется папка,, главное обязательно обеспечить иерархию и изоляцию.
Пример архитектуры в рабочей папке
Шаг 2: Постройте систему файлов контекста
Это ключевой шаг для решения проблемы «однотипного AI-вывода». В вашей папке CONTEXT создайте три Markdown-файла:
> about-me.md Определяет вашу роль и текущий фокус работы. Это не резюме, а то, чем вы реально занимаетесь каждый день, кого обслуживаете, каковы текущие приоритеты, что имеет наибольшую бизнес-ценность. Также можно добавить один-два показательных результата как ориентир уровня и стандартов.
> brand-voice.md Фиксирует ваш стиль выражения. Включает характеристики тона, часто используемые и запрещённые слова, предпочтения по оформлению, а также 2–3 реальных образца вашего письма. Это ключевой водораздел между «универсальным AI-контентом» и «выводом с личным стилем».
working-preferences.md > Определяет правила исполнения для Claude. Например: перед выполнением задать уточняющие вопросы, сначала вывести план декомпозиции задачи, не удалять без подтверждения, формат вывода по умолчанию, стандарты качества и поведение, которого следует избегать.
Эти три файла за короткое время решают проблему «холодного старта»: без контекста каждую задачу приходится объяснять с нуля; после настройки Claude в начале каждой сессии уже обладает полным пониманием вашего стиля, стандартов и предпочтений.
Часто упускаемый из виду ключевой момент: эти файлы контекста обладают «эффектом сложного процента». Рекомендуется итеративно улучшать их еженедельно. Когда вывод Claude не соответствует ожиданиям, в первую очередь стоит определить: это проблема промпта или проблема контекста. В подавляющем большинстве случаев проблема в контексте. Путь решения прямой: добавить правило в соответствующий файл, и это формирует долгосрочный механизм коррекции.
С практической точки зрения, затраты на построение этой системы минимальны: я потратил примерно 45 минут на первоначальное создание context folder, три .md файла, определяющих «кто я», «чем я занимаюсь» и «как Claude должен выполнять задачи». На этой основе следующий проект с промптом-брифом из 10 слов дал результат, соответствующий ожиданиям с первой генерации. А до этого каждую задачу приходилось начинать с повторного объяснения полного рабочего контекста и требований.
Пользователи отмечают: «Claude Cowork также очень полезен для обработки и редактирования файлов. Достаточно описать нужный файл на естественном языке (например, "видео с белкой"), дать простую инструкцию по действию, и Claude вызовет ffmpeg для обработки. Даже если у вас нет никакого опыта в редактировании файлов или конвертации форматов, вы сможете без проблем выполнить эти операции.»
Шаг 3: Настройте глобальные инструкции
Перейдите в Settings > Cowork > Edit Global Instructions.
Глобальные инструкции загружаются раньше всего, раньше ваших файлов, раньше промптов, даже до того как Claude прочитает вашу папку. Они определяют «базовые поведенческие нормы», которые соблюдаются в каждой сессии.
Ниже, шаблон, который можно использовать как отправную точку:
I'm [Name], [Role]. Before starting any task, read my context files first. Always ask clarifying questions before executing. Show a brief plan before taking action. Default output: .docx. Never delete files without my explicit approval. If confidence is low, say so.
Это означает, что даже самый небрежный, самый поспешный промпт будет давать откалиброванный результат. Claude всегда знает, кто вы, всегда в первую очередь читает правильные файлы, всегда запрашивает подтверждение перед принятием решений. Промпт сам по себе отвечает только за текущую конкретную задачу.
Шаг 4: Научитесь использовать AskUserQuestion
Эта функция по сути меняет весь способ взаимодействия. Больше не вы проектируете «идеальный промпт», а Claude проектирует «идеальные вопросы». Когда вы добавляете в любой промпт «Start by using AskUserQuestion», Cowork автоматически генерирует интерактивную форму: вопросы с множественным выбором, кликабельные варианты, чёткие альтернативные пути и структурированный фреймворк вопросов, помогающий прояснить реальные потребности до начала выполнения.
В результате вам больше не нужно с нуля писать длинные, тщательно продуманные промпты; вместо этого Claude сам определяет, какая информация ему нужна. Если после первого раунда вопросов потребности всё ещё не согласованы, вы просто указываете, в чём проблема, и он генерирует новый раунд вопросов, продолжая итерации.
Универсальный шаблон промпта, подходящий практически для любого сценария:
I want to [TASK] to [SUCCESS CRITERIA]. First, explore my CLAUDE COWORK folder. Then ask me questions using AskUserQuestion. I want to refine the approach with you before you execute.
Вот и всё. Этот шаблон плюс ваша система файлов контекста покрывают примерно 80% сценариев использования. Рабочий процесс всегда одинаков, меняется только сам контекст.
Как настроить Cowork за 5 минут.
7. Ключевые функции Cowork
I. Connectors Дата запуска: 24 февраля.
Claude Cowork уже поддерживает подключение к Google Drive, Gmail, DocuSign, FactSet, Google Calendar, Slack и множеству других инструментов, всё это было выпущено вместе с обновлением корпоративной версии.
Это не поверхностные интеграции. Claude может самостоятельно выполнять следующие действия:
> Искать и просматривать файлы в вашем Drive > Извлекать и объединять данные из нескольких источников > Автоматически составлять письма на основе полученной информации > Сканировать контракты и отмечать потенциальные риски
После подключения Claude может напрямую обращаться к актуальным данным этих инструментов в каждом сеансе — без копирования, скриншотов или ручного скачивания.
Путь настройки: перейдите в Settings > Connectors, просмотрите каталог (на данный момент более 50 интеграций), нажмите «Add» и пройдите авторизацию.
Это нужно сделать только один раз. Коннекторы доступны бесплатно для всех пользователей (включая бесплатную версию, с 24 февраля), но на данный момент это по-прежнему одна из самых недооценённых функций Cowork.
Примеры типичного использования:
> После подключения Slack: «Найди мои сообщения в Slack за последние 7 дней, собери список дел, требующих внимания, и отсортируй по срочности.»
> После подключения Google Drive: «Найди в моём Drive последний документ по такому-то проекту, прочитай его и выдели три ключевых момента, на которые мне стоит обратить внимание.»
> После подключения Google Calendar: «Посмотри моё расписание на эту неделю, найди конфликтующие встречи и составь письмо о переносе для наименее приоритетной из них.»
II. Plugins и Marketplace Дата запуска: 24 февраля.
Плагины — это предсобранные функциональные модули для конкретных ролей, объединяющие навыки, команды (slash commands) и коннекторы в «ролевые наборы инструментов». Anthropic уже выпустила официальные плагины, охватывающие продажи, маркетинг, юриспруденцию, финансы, аналитику данных, продуктовый менеджмент, клиентскую поддержку, корпоративный поиск, инженерию, HR, операции, дизайн, брендинг, исследования в области наук о жизни и многие другие направления.
Способ установки: в левой панели Customize > Browse plugins, нажмите «Установить»; в диалоге введите «/», чтобы увидеть доступные команды.
Рекомендуемые плагины для первоочередной установки:
> Productivity (продуктивность)
Управление задачами, расписанием и повседневными рабочими процессами. Введите /productivity:start, и Claude автоматически структурирует ваш план на день.
> Data Analysis (анализ данных)
Загрузите CSV-файл, введите /data:explore, Claude автоматически проанализирует поля, выявит аномалии, предложит направления анализа и сгенерирует SQL на естественном языке.
Затем выберите ролевой плагин, соответствующий вашей работе:
/marketing:draft-content: генерация контента с учётом тональности бренда
/sales:call-prep: исследование клиента и подготовка ключевых тезисов для звонка
/legal:review: проверка контрактов и выделение рисковых пунктов
Для командных пользователей: можно создать приватный маркетплейс плагинов, централизованно распространять кастомные плагины внутри организации и управлять ими через права администратора (доступно для планов Team и Enterprise). Один раз создал, масштабируешь на всю команду.
Кроме того, Anthropic запустила публичный маркетплейс плагинов и программу Ambassador, поддерживающую разработку плагинов сообществом, экосистема быстро расширяется.
Плагины также можно дополнительно персонализировать: после установки просто скажите Claude: «Настрой этот плагин под мою компанию.» Claude спросит о ваших рабочих процессах, терминологии и предпочтениях, а затем сохранит эту информацию как долгосрочный контекст плагина.
Это означает, что универсальный плагин для продаж может эволюционировать в персональный инструмент, который действительно понимает ваш ICP (идеальный профиль клиента), систему ценообразования и стиль коммуникации.
III. Scheduled Tasks Дата запуска: 25 февраля.
Достаточно настроить один раз, и Claude будет автоматически выполнять задачи по расписанию, например:
> Ежедневная утренняя сводка писем > Еженедельный обзор ключевых метрик по пятницам > Регулярный анализ конкурентной разведки
Условие: ваш компьютер должен быть включён, а Claude Desktop, запущен.
Один реальный кейс, подтверждённый несколькими продвинутыми пользователями:
Every Monday at 7am, research [competitor names] for news, product updates, or pricing changes from the past 7 days. Check [industry publications] for relevant coverage. Save a summary brief to /competitive-intel/YYYY-MM-DD-weekly-brief.md. Flag anything that directly impacts our positioning.
Вы просыпаетесь в понедельник утром, и готовый брифинг уже ждёт вас. В сочетании с коннекторами запланированные задачи действительно обретают способность «работать автономно».
Например: «Каждый понедельник забирай все непрочитанные сообщения из канала #product-feedback в Slack, группируй по темам и создавай сводку в Google Drive.», задача срабатывает автоматически, коннектор подтягивает актуальные данные, Claude обрабатывает их, результат появляется прямо в вашей папке.
Лично я запускаю 3–4 запланированных задачи в день: утром генерируется AI-дайджест новостей и сохраняется в папку с контентом; в обед собираются данные с X и релизов продуктов для конкурентного анализа; днём, обзор активности в Discord и Telegram; вечером, отчёт по эффективности контента.
Каждая задача экономит 20 – 30 минут ручной работы, а в сумме это почти два дополнительных часа эффективного времени в день — при минимальных затратах на управление.
Эта функция была запущена вместе с новым модулем Customize в Claude Desktop, который объединяет навыки, плагины и коннекторы в единой точке входа.
IV. Dispatch Дата запуска: 17 марта.
Это мост между телефоном и десктопом, доступный для пользователей Pro и Max. Через Claude Desktop или клиент для iOS / Android вы можете удалённо управлять задачами в Cowork из любой ситуации.
Настройка проста: в Claude Desktop откройте Cowork, нажмите Dispatch в боковой панели и включите «Keep awake» (иначе задачи прервутся при переходе компьютера в спящий режим). Затем откройте приложение Claude на телефоне и нажмите Dispatch в боковой панели.
Ключевой опыт: единый поток диалога, синхронизируемый между устройствами. Вы едете на работу и через телефон даёте Claude задачу на десктопе, например, обработать три таблицы и сформировать отчёт; к моменту прихода в офис результат уже готов. Вы даже можете заложить несколько задач в одну инструкцию Dispatch, Claude выполнит их последовательно, пока вас нет.
Деталь, которую большинство упускает (из гайда Product Compass): слой планирования Dispatch не читает ваш CLAUDE.md, он генерирует промпты для задач на основе стандартных допущений. Подзадачи его прочитают, но начальная инструкция уже может содержать отклонения.
Решение: явно добавьте в инструкцию Dispatch фразу: «read CLAUDE.md».
Ограничения и обходные пути:
На мобиле нельзя добавлять коннекторы
→ Подключите Gmail, Slack, Notion и другие заранее на десктопе, Dispatch автоматически их унаследует
На мобиле нельзя загружать файлы
→ Решение: отправьте файл на почту, а затем через коннектор Gmail попросите Claude его прочитать
Как это работает.
В целом, Dispatch по сути расширяет «локальные рабочие возможности» на любое время и место. Это не просто удалённое управление — это переосмысление временных границ выполнения задач.
V. Projects Дата запуска: 20 марта.
Организация связанных задач в постоянные рабочие пространства, каждый проект имеет собственные файлы, ссылки, инструкции и память. Можно импортировать существующую папку или создать с нуля. Это значит, что вы можете одновременно вести несколько проектов, например, «Финансовый отчёт за Q1» и «Материалы к запуску продукта», и Claude будет помнить контекст каждого из них отдельно.
Значение Projects в том, что Cowork из разовой агентской сессии превращается в непрерывно развивающееся рабочее пространство. Это особенно критично для исследовательских задач, поскольку вам больше не нужно терять контекст между разными диалогами и раз за разом объяснять цели заново.
VI. Computer Use Дата запуска: 23 марта
На данный момент в стадии research preview, поддерживается только macOS, доступно для пользователей Pro и Max, работает как в Cowork, так и в Claude Code.
Claude теперь может напрямую управлять вашим компьютером: кликать, вводить текст, навигировать по интерфейсу, открывать приложения, использовать браузер, заполнять формы, работать с любыми локальными инструментами.
Когда доступен официальный коннектор (например, для Slack или Google Calendar), Claude приоритетно использует API; когда коннектора нет, выполняет действия через «мышь + клавиатуру».
Механизм работы и предупреждения о рисках
Claude запрашивает разрешение перед выполнением критических действий. Тем не менее Anthropic рекомендует избегать работы с конфиденциальной информацией в этом режиме.
Ключевой риск, на который стоит обратить внимание: prompt injection через содержимое экрана. Если Claude откроет ненадёжный сайт, содержимое страницы попадёт в контекстное окно и может повлиять на поведение модели.
Рекомендация: используйте только в среде доверенных приложений и известных сайтов.
Значение в сочетании с Dispatch
Когда Computer Use объединяется с Dispatch, возможности расширяются ещё больше: вы можете с телефона дать Claude задачу, требующую управления десктопом, браузером или приложением, для которого ещё нет коннектора.
По сути, это преодоление ключевого барьера возможностей: от «вызова инструментов» к «прямому управлению системой».
Claude в Chrome
Расширение для Chrome позволяет Claude работать в браузере параллельно с вами: читать веб-страницы, кликать по элементам, заполнять формы и осуществлять навигацию по страницам.
Но то, что действительно упускают большинство людей, — это следующая возможность: вы можете продемонстрировать последовательность действий один раз, и Claude научится её воспроизводить. Любая задача в браузере, которую вы выполняете чаще двух раз в неделю, может быть записана как рабочий процесс.
Интеграция с Claude Code дополнительно связывает процесс разработки: вы пишете код в терминале и одновременно тестируете его в браузере в реальном времени. Расширение может читать ошибки консоли, сетевые запросы и состояние DOM, поэтому когда на фронтенде возникает проблема, Claude зачастую находит причину ещё до того, как вы зададите вопрос.
Кроме того, вы можете управлять действиями в браузере прямо из Claude Desktop, не переключаясь между окнами. Для пользователей Team и Enterprise администраторы могут централизованно управлять расширением на уровне организации, контролируя доступные сайты через белые и чёрные списки.
Типичный сценарий применения: запись рабочего процесса «еженедельный мониторинг страниц с ценами конкурентов». Claude автоматически посещает каждый сайт, собирает информацию о ценах и оформляет её в сравнительную таблицу в папке Cowork. Работа, которая раньше занимала 45 минут кликов, сжимается до одного нажатия.
Важно учитывать: следует осторожно выдавать разрешения на доступ к сайтам. Содержимое веб-страниц, один из основных каналов prompt injection, поэтому доступ стоит ограничивать доверенными ресурсами.## Границы использования
8. Реальные кейсы использования Cowork
Разбор файлов, накопившихся за несколько месяцев:
Направьте Cowork на папку с хаотичными файлами за последние 6 месяцев, включая чеки, контракты, заметки, скриншоты и прочее.
Organize all files in this folder into subfolders by type (receipts, contracts, notes, images). Use the format YYYY-MM-DD-descriptive-name for all filenames. Create a summary log documenting every change. Don't delete anything. If a file could belong to multiple categories, put it in /needs-review.
Claude последовательно прочитает каждый файл, выполнит классификацию, переименует по дате, выстроит файловую структуру и сгенерирует лог операций. Работа, которая раньше занимала 2 часа, укладывается в 10 минут.
Один пользователь применил Cowork для сортировки 317 видео из Disney World: Claude извлёк GPS-координаты из метаданных видео, определил, к какому парку относится каждое видео, и автоматически распределил их по соответствующим папкам.
Lenny попросил его пройтись по всем выпускам своего подкаста (несколько сотен) и автоматически извлечь ключевую информацию, например, «самый важный продуктовый опыт» и «самые контринтуитивные инсайты». Весь процесс занял несколько минут, тогда как раньше на это могли уйти дни или даже недели. Связанные материалы
Генерация клиентских отчетов из сырых материалов: у вас есть протокол встречи, дословная расшифровка и несколько исследовательских ссылок, и теперь нужно собрать из этого структурированный отчёт, готовый к отправке.
Using the files in /client-a/raw-materials, create a client-ready report. Include executive summary, key findings, recommendations, and next steps. Match the format of the template in /templates/. Ask me questions first.
Claude прочитает все ваши исходные материалы, объединит их в структурированный отчёт, оформит по вашему шаблону и сохранит как готовую к отправке версию. Работа, которая раньше занимала 90 минут, укладывается в 15 минут.
Автоматизированный еженедельный исследовательский дайджест: вы можете настроить расписание для конкурентной разведки. Каждый понедельник в 7 утра Cowork автоматически исследует конкурентов, сканирует отраслевые издания и генерирует форматированный дайджест. Вам остаётся лишь просмотреть его в удобное время. В сочетании с коннекторами можно подтягивать данные в реальном времени из Slack, Gmail и Drive.
Финансовое моделирование: один создатель контента попросил Cowork построить модель оценки стоимости при выходе из социальных медиа. Claude самостоятельно разработал план, самостоятельно обнаружил и исправил ошибки в формулах, и в итоге выдал Excel-файл «в стиле Уолл-стрит» с четырьмя методами оценки и 129 формулами. Комплексный диапазон оценки включал: мультипликатор выручки, мультипликатор EBITDA, стоимость пользователя/подписчика и 5-летнюю DCF-модель. Честно говоря, это уже весьма впечатляюще.
7. Ограничения
Cowork расходует лимиты очень быстро. Одна сложная задача может потребить столько же, сколько десятки обычных диалогов. На тарифе Pro (20 $/мес), если пользоваться каждый день, лимит обычно исчерпывается в течение недели. По отзывам сообщества, активные пользователи упираются в ограничение скорости за 3–4 дня, и если вы в этот момент находитесь в разгаре критической задачи, это серьёзно влияет на рабочий процесс.
Многошаговые задачи (чтение файлов, генерация документов, параллельные подзадачи) по своей природе вычислительно затратны. Если Cowork станет вашим основным рабочим инструментом, Max (100 $/мес с примерно 5-кратным лимитом; или 200 $/мес с примерно 20-кратным лимитом), более реалистичный вариант. Рекомендуется отслеживать потребление в реальном времени через Settings > Usage, чтобы избежать прерывания задачи на полпути.
Проблема сжатия контекста в длинных сессиях тоже не стоит игнорировать. Когда сессия приближается к лимиту контекстного окна, Claude автоматически сжимает ранний контент, составляя из него краткое резюме, чтобы освободить место. Это позволяет продолжить сессию, но ценой снижения точности информации: числа упрощаются, ссылки на файлы становятся размытыми, ранние решения сжимаются до обобщённых описаний.
Если вы замечаете, что Claude начинает отвечать «типичными паттернами» вместо конкретных файлов, значит, сжатие уже произошло. Решение: на ключевых этапах просите Claude записывать важную информацию в файлы. Таким образом, даже если контекст будет сжат, ключевая информация останется доступной.
На данный момент это всё ещё исследовательская превью-версия. Anthropic также прямо указывает: модель по-прежнему может неправильно интерпретировать файлы или выбирать неоправданно сложные пути для простых задач. В сложных многошаговых задачах примерно в 10% случаев возникают отклонения от ожидаемого пути выполнения, а в итоговых результатах могут присутствовать локальные несоответствия. Поэтому перед отправкой результатов наружу обязательна ручная проверка.
Нет памяти между сессиями. Каждая новая сессия Cowork полностью независима: не помнит, кто вы, и не помнит, что обсуждалось вчера. Это главная точка трения на данный момент.
Но как только вы выстроите систему контекстных файлов, эта проблема эффективно смягчается:
> Предпочтения записываются в файл > Планы проектов записываются в документ > Стандарты записываются в инструкции
Если вам нужна непрерывность, «запишите непрерывность в файлы». Обратная сторона этого тоже является преимуществом: структурированные рабочие процессы обладают переносимостью, возможностью совместного использования и контролем версий.
Задачи зависят от работающего клиента. Cowork — это активная сессия, работающая в Claude Desktop. Как только вы закроете окно, задача прервётся. Рекомендуется переводить компьютер в режим сна, а не закрывать приложение, сессия сохранится.
Только десктоп. На данный момент нет мобильной версии Cowork, нет браузерной версии, нет кросс-девайсной синхронизации (Dispatch может частично компенсировать, но не является полноценной заменой). Рекомендуется размещать контекстные файлы в облачной синхронизируемой директории (iCloud, Dropbox, OneDrive), чтобы как минимум обеспечить консистентность файлов между устройствами.
8. Claude Code как инструмент для разработчиков
Если Cowork ориентирован на knowledge-работников, то Claude Code — на разработчиков.
Claude Code был впервые запущен в феврале 2025 года как инструмент для кодирования через командную строку, а сегодня превратился в расширяемую платформу для оркестрации AI-агентов на протяжении всего цикла разработки, с годовой выручкой порядка 2,5 миллиарда долларов.
Установка проста: через npm (npm install -g @anthropic-ai/claude-code), заходите в директорию проекта, вводите claude, и запускается агент с доступом ко всей кодовой базе.
Он умеет: читать файлы, записывать файлы, выполнять команды, искать в интернете, запускать тесты, коммитить код и так далее.
Параллельно веб-версия на claude.ai получила важное обновление в феврале: добавились мультирепозиторные сессии, улучшенная визуализация diff и Git-статуса, а также поддержка slash-команд. Но самые глубокие возможности по-прежнему сосредоточены в терминальной версии.
Архитектура в Claude Code
Однако настоящее преимущество — не в «написании кода» как таковом. А в слое расширяемости, который превращает Claude Code из продвинутого автокомплита в настраиваемую платформу разработки.
9. Как выполнить «настройку среды»
CLAUDE.md: руководство-инструкция на уровне проекта. В начале каждой сессии Claude первым делом читает ваш CLAUDE.md. Он загружается напрямую в системный промпт и действует на протяжении всего диалога. Всё, что вы здесь напишете, Claude будет соблюдать.
Но большинство людей либо полностью игнорируют его, либо набивают массой бесполезной информации, что, наоборот, снижает качество выходных данных. Слишком мало или слишком много информации, и то, и другое даёт негативный эффект. Это «порог», который нужно нащупать.
Что стоит писать: > Ключевые команды для сборки, тестирования, линтинга (конкретные bash-команды) > Основные архитектурные решения (например, «monorepo-архитектура на Turborepo») > Неочевидные ограничения (например, «TypeScript в strict-режиме, неиспользуемые переменные вызывают ошибку») > Правила импортов, нейминга, обработки ошибок > Файловая и директорийная структура ключевых модулей
Чего писать не стоит >То, что должно быть в конфигурации линтера или форматтера > Полную документацию, на которую и так есть ссылки > Длинные теоретические объяснения
Рекомендуется держать объём в пределах 200 строк. Больше, и это начнёт занимать слишком много контекста, ослабляя способность Claude следовать инструкциям, поскольку ему приходится «конкурировать за внимание» между вашими инструкциями и собственным системным промптом Claude Code.
Пишите не только «что делать», но и «почему»
«Использовать TypeScript strict-режим» это базовое требование, но «использовать strict-режим, потому что мы однажды поймали production-баг из-за неявного типа any», работает эффективнее.
Причина в том, что «почему» даёт контекст для принятия решений, позволяя Claude делать более обоснованный выбор в ситуациях, не покрытых явными правилами.
Обновляйте постоянно, а не пишите один раз
Нажмите «#» во время работы, и Claude автоматически добавит новое правило в CLAUDE.md. Когда вы ловите себя на том, что исправляете одну и ту же ошибку второй раз — это сигнал: это правило должно быть записано в файл. Со временем он превратится в «живой документ», по-настоящему отражающий реальную работу кодовой базы.
Разница между хорошим и плохим
Плохой CLAUDE.md похож на onboarding-документ для новичка; хороший CLAUDE.md — скорее рабочая записка, которую вы оставили самому себе перед тем, как потерять память.
II. Многоуровневая структура CLAUDE.mdБольшинство людей упускают этот момент: CLAUDE.md — это не один файл, а многоуровневая структура, которая объединяется при запуске сессии.
1. Managed Policy (уровень организации) Развёрнуто IT-отделом, не может быть переопределено, применяется ко всей компании
2. ~/.claude/CLAUDE.md (глобальный уровень) Персональные настройки, действуют кросс-проектно, не коммитятся в репозиторий
3. ./CLAUDE.md (уровень проекта) Общая конфигурация команды, коммитится в Git, единообразно действует для всех участников
4. CLAUDE.local.md (локальное переопределение) Персональные корректировки для текущего проекта, автоматически исключаются из коммитов
При конфликте правил приоритет у верхнего уровня. Эта многоуровневая структура позволяет Claude Code масштабироваться из «персонального инструмента» в «систему командной работы».
Типичная командная проблема:
Разработчик записывает ключевые правила в персональную конфигурацию (~/.claude/CLAUDE.md), и у него всё работает отлично. Но когда новый участник клонирует репозиторий, у него нет этих персональных настроек, и выходные данные начинают расходиться. Команда обычно думает, что это проблема модели, хотя на самом деле, проблема конфигурации.
Характерный случай: команда потратила два дня на расследование «случайного поведения Claude», и в итоге обнаружила, что ключевые правила существовали только в локальной конфигурации старшего разработчика. Вывод прост: все командные стандарты должны быть записаны в проектном CLAUDE.md.
10. Директория правил
Когда CLAUDE.md разрастается (а это неизбежно), правила можно вынести в директорию .claude/rules/.
Каждый Markdown-файл в этой директории загружается вместе с CLAUDE.md при старте сессии. Это позволяет модульно расширять систему инструкций, сохраняя основной файл компактным и поддерживаемым.
Каждый файл может оставаться сфокусированным. Ответственный за API-конвенции ведёт api-conventions.md, ответственный за тестирование, testing.md, каждый в своей зоне ответственности, без взаимных конфликтов.
--- paths: - "**/*.test.tsx" --- # Test Conventions Use React Testing Library, not Enzyme. Test behavior, not implementation. Always include at least one integration test per component. Mock API calls with MSW, never with jest.mock on fetch.
Настоящая ценность проявляется в «правилах с привязкой к пути». Вы можете добавить YAML-заголовок с glob-паттерном в файл, и тогда эти правила будут активироваться только при работе Claude с файлами, соответствующими паттерну:
Это покрывает все тестовые файлы вне зависимости от того, в какой директории они находятся. Для сравнения: CLAUDE.md на уровне директории действует только на файлы внутри неё. Для стандартов, которые нужно единообразно применять в 50+ тестовых директориях, правила на основе пути, более разумный подход. Кроме того, это снижает потребление токенов, поскольку соответствующие правила загружаются только при совпадении паттерна.
11. Разница между Commands, Skills и Agents
Эти три типа механизмов расширения работают по-разному. Если выбрать неподходящий для конкретного сценария, это лишь увеличит затраты и трение при использовании.
Commands (.claude/commands/) — это слэш-команды, которые нужно запускать вручную.
--- description: Review current branch diff before merging --- ## Changes to Review !`git diff --name-only main...HEAD` ## Detailed Diff !`git diff main...HEAD` Review for code quality, security vulnerabilities, missing tests, and performance concerns. Give specific, actionable feedback per file.
Например, файл с именем review.md будет соответствовать команде /project:review. Инструкции в файле пишутся на Markdown; при этом с помощью синтаксиса обратных кавычек с ! можно сначала выполнить shell-команду и встроить её вывод в промпт ещё до того, как Claude начнёт обрабатывать его.
Теперь при выполнении /project:review система автоматически подставляет реальный git diff в промпт.
Также можно передавать аргументы через $ARGUMENTS, например: /project:fix-issue 234 загрузит содержимое issue №234 прямо в контекст.
Команды уровня проекта (.claude/commands/) коммитятся и становятся общими для всей команды; личные команды (~/.claude/commands/) отображаются как /user:command-name и видны только вам.
Skills (.claude/skills/) — это другой механизм: они не запускаются вручную, а вызываются Claude автоматически при совпадении с задачей.
Вам не нужно вводить никаких слэш-команд. Claude читает описание skill'а, определяет, соответствует ли текущая задача, и активирует его в подходящий момент.
Иными словами:
> Commands — это «ждут, пока вы их вызовете» > Skills — это «распознают сценарий и выполняются автоматически»
По структуре Skills — это папка, а не отдельный файл. Внутри могут находиться скрипты, справочные документы, данные и шаблоны. Через файл SKILL.md с YAML-заголовком задаются условия срабатывания:
--- name: security-review description: Comprehensive security audit. Use when reviewing code for vulnerabilities, before deployments, or when the user mentions security. allowed-tools: Read, Grep, Glob ---
Skills теперь также поддерживают параметр effort (интенсивность рассуждений) в YAML-заголовке, который позволяет при вызове переопределить стандартную глубину размышлений модели. Кроме того, поддерживаются hooks, срабатывающие по запросу, только когда данный skill активирован. Например: /careful блокирует деструктивные операции, а /freeze ограничивает редактирование файлов за пределами определённой директории.
Внутренняя инженерная команда Anthropic уже создала сотни skills для девяти категорий сценариев, включая: справочники по библиотекам/API, валидацию продукта, получение данных, автоматизацию бизнес-процессов, генерацию кодовых шаблонов, ревью качества кода, CI/CD-деплой, runbook'и и операции с инфраструктурой.
7 марта они также выложили 17 из этих skills в открытый доступ на GitHub (anthropics/skills), покрывающих сценарии креативного дизайна, генерации документации, технической разработки и корпоративных коммуникаций.
Самая ценная часть skill'а — это зачастую раздел «подводные камни (gotchas)», то есть те грабли, на которые вы наступили лично. Именно этот опыт стоит записывать в первую очередь, он приносит наибольшую пользу.
Agents (.claude/agents/) — это ещё более высокий уровень абстракции: это «суб-агентные роли» с собственным системным промптом, правами доступа к инструментам и настройками модели.
--- name: code-reviewer description: Expert code reviewer. Use PROACTIVELY when reviewing PRs. model: sonnet tools: Read, Grep, Glob --- You are a senior code reviewer focused on correctness and maintainability. Flag bugs, not just style issues. Suggest specific fixes.
Поле tools ограничивает набор возможностей агента. Например, агент для аудита безопасности получает только права на Read, Grep и Glob, без возможности записи — это намеренное ограничение. Поле model позволяет выбирать более дешёвую модель для разных задач. Для задач, связанных преимущественно с чтением и исследованием, Haiku обычно вполне достаточно.
Архитектура субагентов
Ключевая ценность суб-агентов (Subagents) — в сохранении чистоты основного контекста. Контекстное окно главного агента легко забивается большим объёмом исследовательской информации; суб-агенты выполняют эту «грязную работу» в отдельном контексте и возвращают сжатый результат. В итоге в основном диалоге остаются только выводы, а не весь процесс рассуждений.
12. Ключевые функции Claude Code
I. Tasks Дата запуска: 22 января.
Anthropic обновил прежнюю систему Todos до Tasks, превратив её в полноценный базовый компонент управления проектами.
Tasks поддерживают зависимости, данные хранятся в локальной файловой системе (~/.claude/tasks), и несколько суб-агентов или сессий могут совместно работать над одним списком задач. Когда какая-либо сессия обновляет задачу, изменения синхронно транслируются всем сессиям, использующим этот список.
Также можно задать список задач как переменную окружения, запустить несколько параллельных агентов и координировать их через единую систему задач. Это формирует основу для мультисессионных рабочих процессов и является ключевым механизмом, обеспечивающим организованность Agent Teams.
II. Agent Teams Дата запуска: 5 февраля
Если суб-агенты — это модель «каждый выполняет своё и отчитывается наверх», то Agent Teams больше похожи на команду, работающую совместно. Участники команды могут напрямую общаться друг с другом через механизм, похожий на входящие сообщения, распределять задачи через общий список задач (с зависимостями) и работать параллельно.
Поддерживается до 10 участников одновременно. Одна главная сессия отвечает за общую координацию: распределяет задачи и объединяет результаты; каждый участник выполняет задачи в собственном независимом контекстном окне.
В отличие от суб-агентов, участники команды могут:
> Напрямую делиться находками > Взаимно проверять и оспаривать результаты друг друга > Взаимодействовать без необходимости проходить через главную сессию > Способ активации: в settings.json установить: CLAUDE_CODE_EXPERIMENTAL_AGENT_TEAMS=1
Типичный сценарий применения: Например, вам нужно разработать новую функцию, затрагивающую одновременно: API, фронтенд-компоненты и систему тестирования.
Можно запустить трёх участников:
>Один отвечает за API-интерфейс >Один за React-компоненты > Один за интеграционные тесты
Все трое координируются через общий список задач, участник, отвечающий за тесты, в реальном времени узнаёт, какие интерфейсы и компоненты нужно проверить. Последовательное выполнение превращается в параллельное: задача, которая раньше занимала 90 минут, может быть выполнена примерно за 30 минут.
Границы применения
Agent Teams создают дополнительные затраты на координацию, а расход токенов значительно выше, чем при работе в одной сессии.
Подходит для:
> Задач, которые можно декомпозировать для параллельного выполнения > Подзадач, относительно независимых друг от друга
Не подходит для:
> Задач с жёсткой последовательной зависимостью > Сценариев, требующих частого редактирования одного и того же файла
В таких случаях лучше использовать одну сессию или суб-агентов.
III. Remote Control Дата запуска: 24 февраля Это решение, существовавшее до появления Channels.
Запустите claude rc в терминале, затем перехватите сессию с телефона (через Claude App или claude.ai), и вы получите удалённое управление:
Можно запустить задачу на десктопе, уйти и продолжать руководить процессом выполнения с телефона.
Хотя Channels (о них ниже) расширили сценарии использования за счёт подключения Telegram и Discord, Remote Control по-прежнему остаётся самым простым способом «управлять терминалом с телефона» — без необходимости настраивать ботов для обмена сообщениями.
Claude Code Channels: постоянно доступный интерфейс обмена сообщениями
Дата запуска: 20 марта, на данный момент в стадии исследовательского превью.
Если вы когда-нибудь хотели просто отправить сообщение ИИ с телефона и чтобы он выполнил задачу на вашей локальной машине — это именно то решение.
Channels позволяют подключить запущенную сессию Claude Code к Telegram или Discord. Вы просто отправляете сообщение с телефона, Claude обрабатывает команду в локальной среде разработки (включая файлы, инструменты, Git и все остальные ресурсы) и возвращает результат через тот же мессенджер.
Ваша сессия продолжает работать в фоне. Внешние события поступают непрерывно, Claude обрабатывает их одно за другим в полном контексте проекта. Сидите ли вы перед терминалом, наблюдая за процессом,, больше не имеет значения.
Именно эта модель взаимодействия стала причиной стремительной популярности OpenClaw после его выхода в ноябре 2025 года: «постоянно доступный рабочий узел ИИ», который можно вызвать 7×24 через привычный мессенджер.
Разница в том, что Channels — это нативная возможность Claude Code, поддерживаемая системой безопасности Anthropic, построенная на архитектуре MCP и обладающая хорошей расширяемостью.
Способ настройки:
# Install the Telegram plugin /plugin install telegram@claude-plugins-official # Configure with your bot token (from BotFather) /telegram:configure <YOUR_BOT_TOKEN> # Start with channels flag claude --channels plugin:telegram@claude-plugins-official
Откройте Telegram, отправьте любое сообщение вашему боту, он вернёт код сопряжения. Используйте /telegram:access pair <code> для завершения привязки. Процесс сопряжения привязывает бота к вашему user ID, гарантируя, что никто другой не сможет управлять вашей сессией.
Подключение Discord аналогично, через соответствующий плагин.
Текущие ограничения:
> Необходимо поддерживать терминальную сессию запущенной (можно использовать tmux, screen или фоновый процесс)
> В стадии исследовательского превью поддерживаются только официально одобренные Anthropic плагины
> Подтверждение прав по-прежнему выполняется в терминале
Однако сама архитектура плагинов спроектирована для расширения. Поддержка Slack, WhatsApp, iMessage и других каналов уже активно запрашивается, а документация по разработке пользовательских каналов уже опубликована.
Весь процесс настройки Channels занимает около 10 минут: создать Telegram-бота, получить код сопряжения, завершить привязку. После этого вы можете управлять локальной сессией Claude Code прямо с телефона, находясь где угодно. Например, однажды я, стоя в очереди за кофе, с телефона попросил его отрефакторить процесс аутентификации; когда я вернулся за рабочий стол, PR уже был готов к ревью.
В тот момент это перестало ощущаться как инструмент, и стало больше похоже на инфраструктуру.
> Hooks Hooks — это shell-команды, автоматически срабатывающие в определённых точках жизненного цикла, например: перед коммитом (pre-commit), после вызова инструмента (post-tool-call) или когда Claude пытается отредактировать определённый файл.
Они касаются не «интеллекта» ИИ, а детерминированного контроля.
Типичные применения включают:
> Автоматический запуск lint для каждого файла, который записывает Claude > Блокировка коммита файлов, содержащих конфиденциальную информацию > Отправка уведомлений в Slack после завершения задачи > Автоматический запуск проверки типов после каждого редактирования > Принудительное выполнение правил комплаенса, которые должны соблюдаться на 100%
Например, ниже приведена базовая конфигурация Hook для предотвращения коммита конфиденциальной информации Claude:
После добавления этой конфигурации в .claude/settings.json файлы с учётными данными будут перехвачены ещё до попадания в репозиторий, обеспечивая превентивную защиту конфиденциальной информации — без опоры на суждения модели, с детерминированными гарантиями.
Канал с гайдами и контентом по claude code, выкладываем новости (когда режут лимиты в 10 раз) и какие инструменты через claude реализуем для проектов, канал: https://t.me/claudedevolper