0 просмотренных постов скрыто


Ответ на пост «Говорилка Qwen3-TTS с поддержкой русского языка. Бесплатная нейросеть озвучит что угодно вашим голосом + портативная версия»2
Оставьте образец голоса, пожалуйста!
Звонков и голосовух родственникам и знакомым точно не будет!

Говорилка Qwen3-TTS с поддержкой русского языка. Бесплатная нейросеть озвучит что угодно вашим голосом + портативная версия2
Всем привет! Команда Qwen от Alibaba выложила в открытый доступ Qwen3-TTS — нейросетевую модель для синтеза речи с клонированием голоса. Сегодня хочу рассказать об этой технологии подробнее и поделиться портативной версией.
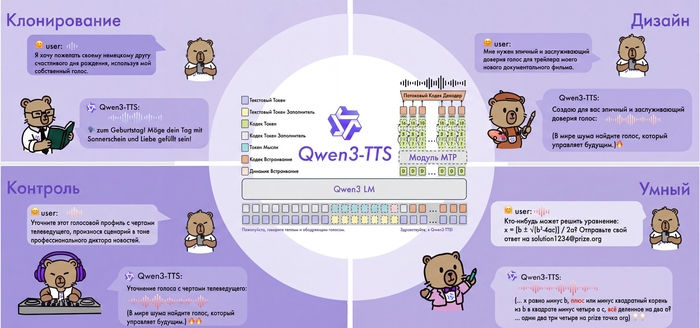
Меня зовут Илья, я основатель сервиса для генерации изображений ArtGeneration.me, блогер и просто фанат нейросетей. А еще я сам собрал портативную версию Qwen3-TTS под win11 и успел её как следует протестировать.
Главная особенность системы в том, что она умеет не только озвучивать текст готовыми голосами, но и клонировать любой голос по короткому образцу, а ещё создавать новые голоса по текстовому описанию.
И всё это с нативной поддержкой русского языка.
Как это работает
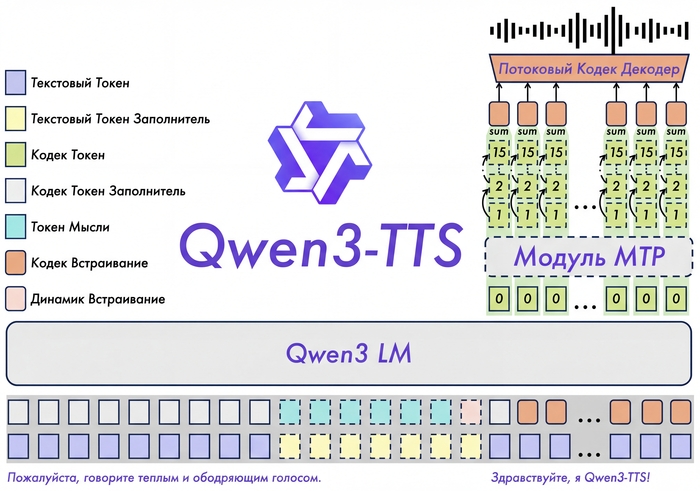
В основе Qwen3-TTS лежит End-to-End архитектура с дискретным многоканальным токенизатором речи (12.5 Гц, 16 слоёв). В отличие от традиционных систем, которые работают по цепочке "текст → фонемы → звук" и теряют информацию на каждом этапе, здесь всё обрабатывается одним махом.
Такой подход полностью исключает эффект "роботизированности" и каскадные ошибки генерации. Модель сохраняет интонации, эмоции и особенности тембра.
Работает очень быстро даже на старшей модели 1.7B.
Поддерживаемые языки
Qwen3-TTS работает с 10 языками:
Китайский (включая пекинский и сычуаньский диалекты)
Английский
Японский
Корейский
Немецкий
Французский
Русский
Португальский
Испанский
Итальянский
Возможности
Синтез с готовыми голосами (CustomVoice)
9 встроенных голосов разных типов — молодые и зрелые, мужские и женские. Можно управлять эмоциями и стилем речи через текстовые инструкции.
Создание голоса по описанию (VoiceDesign)
Описываете словами, какой голос нужен — модель его генерирует. Например: "молодой женский голос, игривый, с высоким тоном". Лучше работает если писать промпты на голос на английском.
Клонирование голоса (Voice Clone)
Загружаете аудио от 3 секунд — получаете синтез этим голосом. По бенчмаркам качество клонирования превосходит ElevenLabs и MiniMax по показателям сходства спикеров. Оно и правда веского качества, уровень VibeVoice, но гораздо легче по ресурсам.
Multi-Speaker режим
Создание диалогов и подкастов с несколькими спикерами одновременно (до 4 голосов).
Можно эмулировать разговор между друзьями, актерами, персонажами из игры, все теперь ограничивается только вашей фантазией.
Кому пригодится
Создателям контента — озвучка роликов, подкастов, стримов.
Разработчикам игр — озвучка персонажей без найма актёров, особенно актуально для инди.
Аудиокнигам — разные голоса для персонажей.
Автоматизации — голосовые уведомления, IVR-системы, ассистенты.
Как попробовать
Онлайн-демо
Тут в демо меньше возможностей и нет локализации, но тоже отлично работает.
Hugging Face Demo — https://huggingface.co/spaces/Qwen/Qwen3-TTS
Официальный GitHub
Можно попробовать установить самостоятельность с гитхаб, но это потребует опыта и навыков.
API
Официальное API от Alibaba для production-интеграции.
Портативная версия
Я с каналом Нейро-Софт подготовил улучшенную портативную сборку Qwen3-TTS Portable PRO, видео выше как раз из неё и записаны. А еще там:
Русифицированный интерфейс
Установка в один клик (install.bat)
50+ готовых голосов в комплекте
700+ дополнительных голосов для скачивания из интерфейса
Multi-Speaker режим до 4 спикеров
Поддержка NVIDIA GPU и CPU
Системные требования
NVIDIA GPU с 8+ ГБ видеопамяти (или CPU, но медленнее)
Windows 10/11 64-bit
16 ГБ оперативной памяти
20 ГБ свободного места на диске
Текущие ограничения
Ударения иногда расставляются неправильно
С длинными текстами могут быть проблемы
Инструкции для VoiceDesign лучше писать на английском
Распакуйте в корень диска (путь без кириллицы), запустите install.bat. Модели скачаются при первом запуске. А если будут сложности в установкой в посте в канале найдете версию с уже установленным env (окружением).
Я рассказываю больше о нейросетях у себя на YouTube, в телеграм и на Бусти. Буду рад вашей подписке и поддержке. Ну и на канал Нейро-Софт тоже подпишитесь, чтобы не пропустить полезные репаки. Всех обнял и удачных генераций!
Показать полностью
2
7

Три бесплатных портативных нейросети для работы со звуком | MM-Audio, Fish Speech, LatentSync
🎵 Друзья, вы готовы к настоящей революции в мире аудио? В этом видео я покажу вам три невероятные нейросети, которые перевернут ваше представление о работе со звуком! MM-Audio создаст потрясающие звуковые эффекты для ваших видео и игр всего за пару кликов, Fish Speech поразит вас качеством клонирования голоса по минутному образцу, а LatentSync идеально синхронизирует сгенерированную речь с любым видео.
Я покажу все хитрости настройки, поделюсь личным опытом и научу пользоваться каждым инструментом. А самое крутое - все они доступны в удобных портативных версиях! 🚀
Альтернативный плеер YouTube:
Ссылки из видео:
🎨 MM-Audio - генерация звуков
Скачать портативную версию: https://t.me/neuroport/119
Исходный код: https://github.com/hkchengrex/MMAudio
Онлайн демо: https://huggingface.co/spaces/hkchengrex/MMAudio
🗣️ Fish Speech - клонирование голоса
Скачать портативную версию: https://t.me/neuroport/134
Исходный код: https://github.com/fishaudio/fish-speech
Онлайн демо: https://huggingface.co/spaces/fishaudio/fish-speech-1
🎬 LatentSync - синхронизация губ
Скачать портативную версию: https://t.me/neuroport/129
Исходный код: https://github.com/bytedance/LatentSync
Онлайн демо: https://huggingface.co/spaces/fffiloni/LatentSync
🛠️ Полезные инструменты:
Whisper для транскрибации: http://github.com/Const-me/Whisper
Ultimate Vocal Remover: https://github.com/Anjok07/ultimatevocalremovergui
Audacity для редактирования: https://www.audacityteam.org
База голосов для TTS: https://t.me/neuroportchat/6633
📱 Мои ссылки:
Поддержать донатом: https://www.donationalerts.com/r/nerual_dreming
Основной Telegram: https://t.me/neuro_art0
Эксклюзивы на Boosty: https://boosty.to/neuro_art
Курс по нейросетям: https://fooocus.ru
Клуб "Нейро-музыка": https://neuromusic.club
Все Telegram каналы: https://t.me/addlist/LQ-fUTyhVjEzYjIy
Буду рад вашей подписке и поддержке. Всех обнял и удачных генераций.
Показать полностью
1

Делаем быстрый, качественный и доступный синтез на языках России — нужно ваше участие

Фонтан "Дружба народов"
Привет, Пикабу!
Наверное ни для кого не секрет, что в последнее время усиливаются как интеграционные, так и дезинтеграционные процессы у нас в стране и вокруг неё. Вот, например, в метро можно увидеть вот такую рекламу (затёр логотипы):

Понятно, что нынче Пикабу состоит из баянов, розжига, сисек, срачей про мигрантов и бездомных собак (вы сами знаете всё остальное), но остались же тут адекватные люди, кто ещё верит в дружбу народов и всё подобное, хотя бы в рамках нашей страны?
В этом году мы делаем проект Фонда Бортника по разработке модели синтеза речи языков России и СНГ. Возможно, вы знаете нас через одного популярного бота для озвучки в Телеграме.
Наша основная задача - сделать удобный, быстрый, устойчивый, качественный и нетребовательный к вычислительным ресурсам синтез на самых популярных у нас в стране и в ближайшем зарубежье языках.
По итогу проекта планируется публикация общедоступных моделей синтеза языка под свободной лицензией (MIT). Мы бы хотели покрыть как минимум 10 популярных языков. Всего популярных языков (более 100 тысяч носителей) 30+, так что, в принципе, тут есть, где разгуляться.
Поэтому ищем людей, у которых два родных языка (русский и второй родной), которые бы помогли нам с рядом вещей:
Помощь в поиске актуальных текстов на родном языке;
Запись голоса (как на русском, так и на втором родном языке);
Минимальные консультации по фонетике, ударениям и грамматике.
✉️ Контакты для связи, условия участия оговариваем в каждом случае отдельно.
Показать полностью
1

Обзор доступного инструмента для клонирования голоса в Telegram
Будучи человеком, который интересуется современными технологиями, я давно увлекаюсь различными инструментами для работы с голосом. Меня особенно привлекает возможность создания реалистичной речи с использованием искусственного интеллекта. В последнее время эта технология стремительно развивается: от роботизированных голосов мы перешли к созданию речи, которая практически неотличима от человеческой.
Недавно, исследуя возможности Telegram-ботов, я случайно наткнулся на интересный инструмент для клонирования голоса. Честно говоря, сначала отнесся скептически - мол, очередная игрушка. Но решил попробовать - всё же планирую в будущем заняться созданием видеоконтента, а качественное озвучивание всегда остаётся актуальной задачей.
Забегая вперед скажу - результаты меня удивили, но обо всём по порядку.
Главные особенности
Бот предлагает два основных режима работы:
Синтез речи из текста с использованием готовых голосов
Клонирование голоса из аудиозаписи
Что касается качества синтеза речи - оно на достойном уровне. Особенно порадовало, что бот очень понятно взаимодействует с пользователем и даже имеет встроенный индикатор, который показывает, достаточно ли аудиоматериала для качественного клонирования голоса.
Личный опыт использования
Из личного опыта по клонированию: минимально достаточный объем аудио - около 2 минут, но для действительно качественного результата лучше использовать 3-4 минуты записи. Бот сам подсказывает с помощью специального индикатора, хватает ли материала для создания качественного клона голоса.
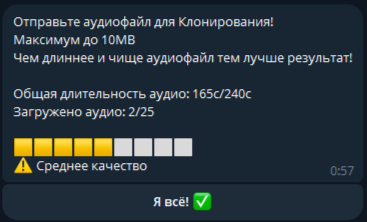
К сожалению, технические ограничения Пикабу не позволяют прикрепить аудио непосредственно в пост, чтобы продемонстрировать результаты. Поэтому оставлю ссылку на аудио-результат гугл драйв, сможете прослушать, что у меня получилось :)
Заключение
Технология действительно впечатляет своими возможностями. Думаю, она будет особенно полезна для:
Создателей видеоконтента
Разработчиков обучающих материалов
Тех, кто занимается озвучкой текстов
Буду рад ответить на ваши вопросы в комментариях!
Показать полностью
2
Боты для озвучки текста + Голосовой дипфейк в Telegram!
Часто возникает необходимость озвучить текст для видео или других проектов, но не всегда есть возможность записать голос самостоятельно. В таких ситуациях на помощь приходят боты и сервисы для синтеза речи.
Рассмотрим несколько популярных ботов в Telegram, которые помогут озвучить текст профессиональным синтезированным голосом.
1. Voice Vortex
По моему мнению, лучший бот. Лучше него просто напросто не найдёте. Качество настолько хорошее, что не отличите от реального человека. Можешь лично убедиться, на старте даются бесплатные токены.
1. Тут сочные цены на тарифы.
2. Очень качественные и проработанные голоса.3. Можно озвучивать кого-нибудь своим голосом, не только текстом.
4. Вы можете попросить админа создать для вас приватный голос.
5. Более 450+ голосов. (Так сказал админ)6. Можно записывать видео-кружочки, бот отправит результат с измененным голосом.
7. Можно делать свои ИИ каверы, если вы понимаете, о чем я. (Ниже будет пример)
Бот Voice Vortex
Голоса и Категории (Вложения скриншотов)
Вот несколько примеров того, как этот бот озвучивает текст. В боте есть три уровня озвучки текстом, покажу, как они работают.
*Basic TTS* — уровень 1.
*Standard TTS* — уровень 2.
*Pro TTS* — уровень 3.
1. Basic — для пользователей, которые пользуются ботом бесплатно.
2. Standard — для пользователей, которые приобрели премиум-аккаунт.
3. Pro TTS — для пользователей, которые приобрели премиум-аккаунт с подпиской Pro TTS.
И еще одна демонстрация озвучки своим голосом, а так же ИИ кавер голосом Литвина:
*ИИ Кавер | Миша Литвин - Кино* -- Кавер на песню MACAN - Кино, голосом Литвина
2. SteosVoice
Бот SteosVoice
Выбор голоса производится через веб-интерфейс.
Всё так же по категориям!
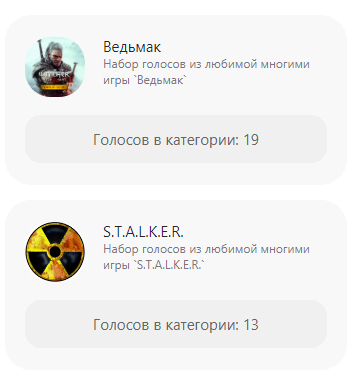
Голоса множества игр.
Предоставляется 5000 символов в день бесплатно.
3. Silero TTS
Лимитов поменьше и очень много различных голосов. Используются для смешных озвучек...например "Упоротые ответы на Mail", думаю вы уже видели подобного рода видосики xD
В общем, топ, тоже есть кружочки.
Вот и всё, друзья! Не забудьте поставить Свой царский лайк на этот пост, чтобы он попал в рекомендации. Спасибо всем за внимание! Надеюсь, этот пост был для вас полезен!
Показать полностью
11

Что это за голос речевого синтезатора?
Помогите пожалуйста найти, какой синтезатор речи это озвучивает: