Вторая часть работы по моей разработке отказоустойчивых ПЛК.
Кто читает впервые:
Я, автор , независимый исследователь ( тот который не работает за счет фондов, институтов и организаций), разработчик SCADA системы Gatherlog.
А так же автор комплекса по разработке Промышленных Контроллеров под названием 3o|||sheet. Среда, IDE читается как Зошыт - тетрадь, но так как для компилятора и среды выполнения названия не придумал, пока все называю 3o|||sheet.
Приходится, одно и то же видео вставлять, так как люди читают, не переходя на прошлые посты, что и о чем у меня за проекты.
В прошлый раз, показал свой научный метод Дивергентного Многоверсионного Выполнения Программ для усиления ошибок, которые пропускают классические методы типа lockstep\TMR.
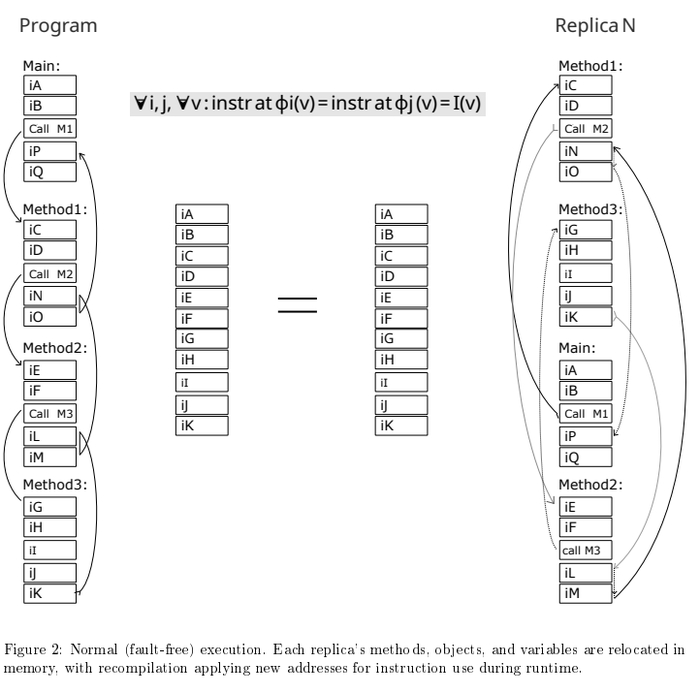
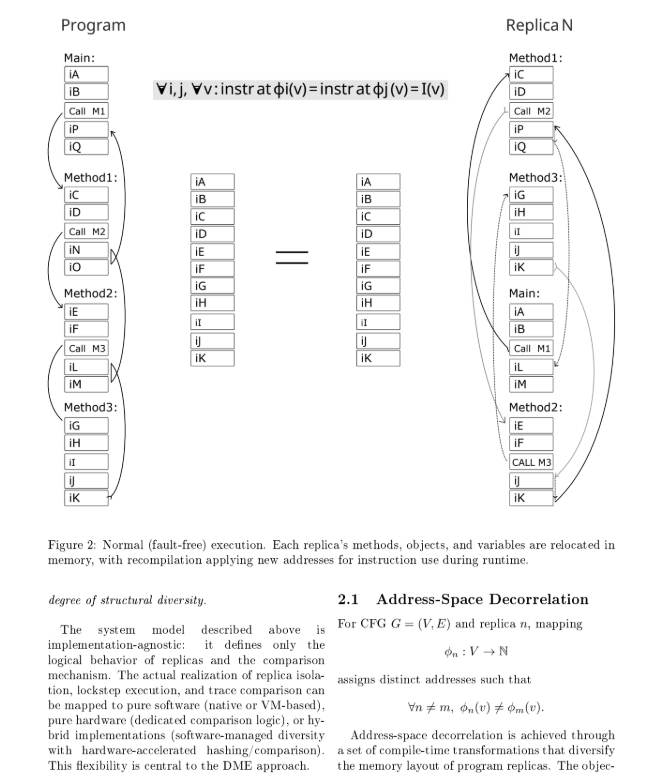
Суть моего метода в - декорреляции адресного пространства. Мы компилируем программу N раз (смотря сколько ядер или какую точность детекции выбрать) перемешав в памяти код: функции, блоки, и переменные. То есть, если на первом ядре функция Main будет по адресу 1000 то на втором ядре она будет по адресу 2000. Точно так же с переменными - они перемешиваются по разным местам (но не случайным образом).
В этом посте буду делать скрины из своей научной работы.
Это совершенно не влияет на ход программы. Каждое ядро, его счетчик команд, будет синхронно прыгать по своим адресам, но траектории программы - будут абсолютно одинаковы.
То есть, при корректной работе, - программы будут идентичны, а при сбое - каждое ядро будет сходить сума по своему из за декорреляции адресов. Это ключевой принцип, так как современные методы lockstep/TMR при сбое (одинаковом сбое всех ядер) сходят сума - одинаково, а значит согласовано, система не заметит сбоя. Это реальная проблема признанная в промышленности. Которую я решил.
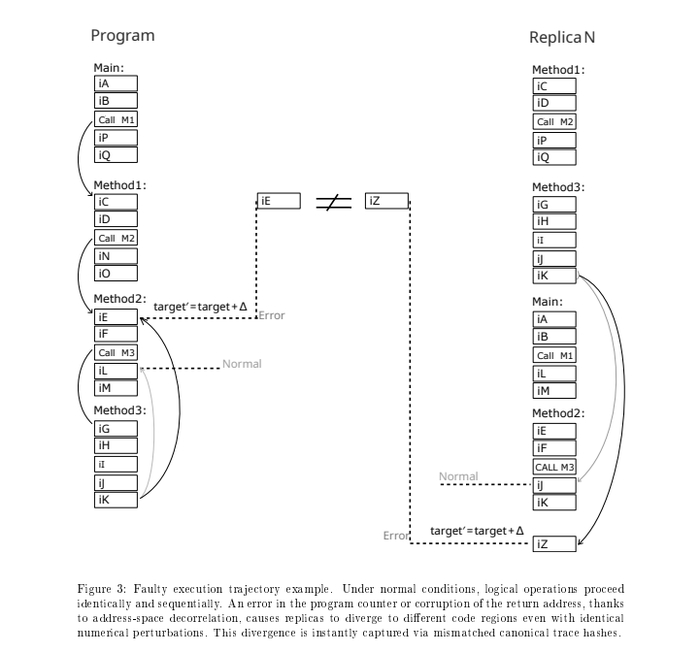
на этом изображении - самый тяжелый случай - обе реплики получили повреждения счетчика команд (переполнение буфера в стеке который затер адрес возврата, или физическая помеха) на одинаковую величину, но из за перемешанных адресов, каждое ядро прыгает в разную область, - мы это ловим.
В прошлом посте, были сообщения, что я все эти ошибки - придумал (радиацию, электромагнитные импульсы), и сам их победил. А в системе достаточно - таймера, который сбросит если все зависло. Так говорит - старая школа, но так было раньше. Почему старые процессоры x386 x486 выпускались 30 лет и до сих пор летают в самолетах? Грубый тех процесс более устойчив к физическим помехам (радиации и электромагнитным полям) на высоте 10 000 метров. Чувствительность современных микроконтроллеров и процессоров к физическим сбоям из за мелкого тех-процесса обсуждается, изучается и все признают эту проблему которая будет только увеличиваться.
Вот группа ученых, которые придумали и даже утверждают , что им в лаборатории удалось доказать , обход системы защиты - пин кода. Своими электромагнитами импульсами они заставили перепрыгнуть счетчик команд через 6 (шесть) инструкций который отвечал за сравнение пароля. Тестировали они на Atmega328 - обычный микроконтроллер.
В своей работе они описывают следующее:
Перевод: «С другими настройками (положением и амплитудой напряжения) мы подтвердили возможность увеличить количество последовательно пропущенных инструкций до шести»
Теперь, когда мы разобрались, что повреждение счетчика команд из за физического воздействия - не моя выдумка, а минимум выдумка еще несколько десятков профессоров,
перехожу к своей научной работе, и то как я предлагаю решать этот вопрос. В моей работе есть есть два раздела, первый - грубая диверсификация кода на уровне функций и логических блоков , о которой я выше упоминал.
Каждая функция и блок - в перемешанных адресах на каждом ядре.
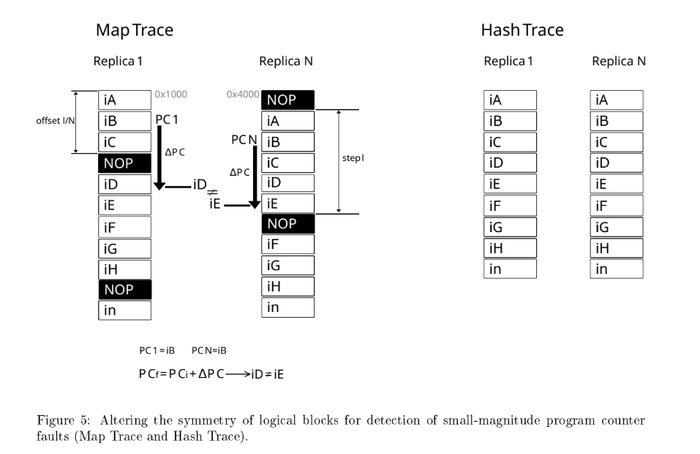
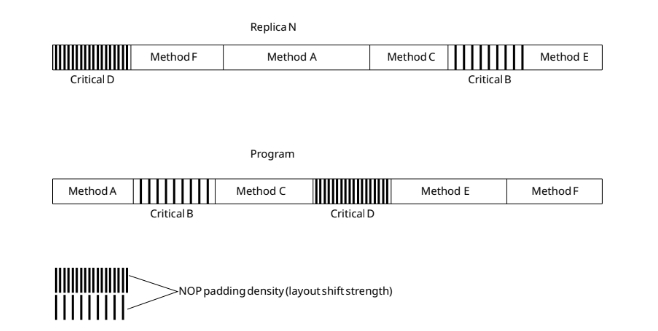
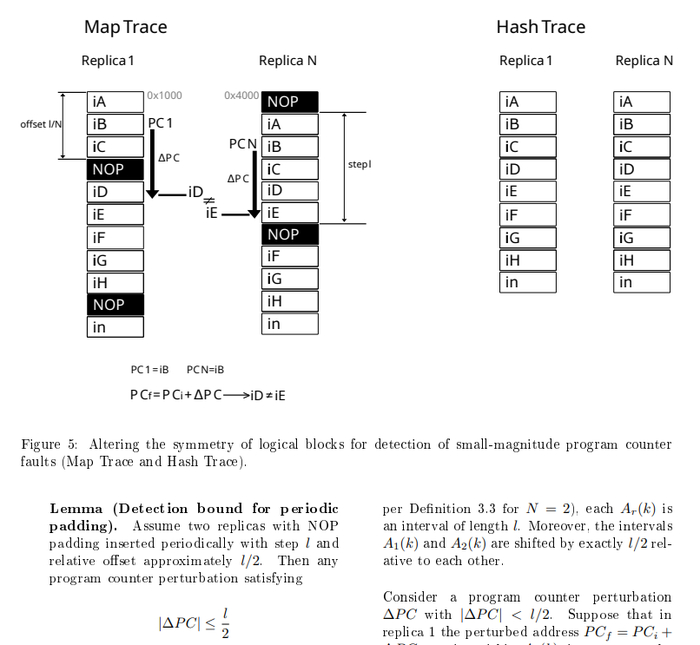
Второе дополнение под названием: Detection of Small-Magnitude Program Counter Faults. Где я предложил следующий подход. Наш компилятор - вставляет пустые инструкции NOP , периодически, и сдвинуты по фазе в разных репликах(ядрах).
Что это дает, это как раз мешает - пропуску инструкций если физическое влияние "застало" счетчик команд - внутри функций. Формула указан так:
Шаг этих вставок NOP соответствует - детекции пропуску инструкций. То есть, если бы ученые пытались взломать мой ПЛК, а я бы в настройках компилятора установил шаг 6(L)/2(N) - наша система бы зафиксировала пропуск 3 и больше инструкций.
В моем ПЛК в системе есть модуль канонизации инструкций (которая выбирает - что в 32 битной инструкции, какие биты отслеживаем в траектории программы). Этот модуль инструкции NOP просто игнорирует. NOP - инструкция ничего не делает, и их вставка не влияет на программу, но - раздвигает адреса. А теперь хитрость.
Хитрость в том что, если программа идет последовательно - все ядра покажут идентичный ход выполнения. Но , если было физическое воздействие, и счетчик перепрыгнул допустим на 3 три инструкции который вкладывается в формулу :
|∆P C| ≤ l/N
смотри рисунок, одно ядро окажется на инструкции iD а второе на инструкции iE . Пропуск будет детектирован и ошибка наблюдаема.
В моем методе есть недостатки, вставка NOP - увеличивает память, и в моем компиляторе есть возможность выбирать критические участки кода где это используется:
Разная плотность NOP - разная детекция пропуска иснтрукций.
То есть, мы можем перемешать адреса функций и блоков, и получить детекцию целого класса ошибок ( от бага компилятора, до кривой программы и и физических помех которые изменяют ход программы - при переходах между функциями и в стеках).
Но так же усиливаем бдительность в критических участках кода , переводя систему в безопасный режим, даже если будет пропущена 1 инструкция (ПИД регуляторы и другие какие то системы).
Наш интерфейс. Тяжелые функциональные блоки, в тестах мы выставляли режим Detection of Small-Magnitude Program Counter Faults.
И, что важно, никаких грубых методов типа WDT ( таймера) или выдернуть шнур питания на 10 секунд и перезагрузить. Решается вопрос сбоя программы тонко, а его детекция - быстро , в течении - наносекунд при первом же расхождении программной трассы.
В данный момент, я тестировал эти повреждения указателя программного счетчика - изменяя его программно. Система тестировалась на FPGA и исправно фиксировала каждый пропуск. На микроконтроллере это не имеет смысла так как программный счетчик - виртуальный, а этот метод может работать только в многоядерных системах или FPGA.
Тестируемые.
В следующий раз, когда вернусь к вопросу отказоустойчивости - проведем уже эксперимент с физическим воздействием.
Задавайте вопросы в комментариях и на почту zoshytlogic@gmail.com.
Попросили помочь с настройкой контроллеров под управлением стандартного приложения. Когда-то давно, году в 2012, плотно работал с этим оборудованием, вполне приличное для не-программиста, по воспоминаниям. Да и потом иногда попадались проекты с ним. Отдельная история для олдфагов "этожиоем", но у меня были инсайды и мне было пофиг на "политику Сименс" : ) Закономерным было дальнейшее обучение и работа с Desigo Xworks, тоже вполне приличная система, если принять как данность некоторые странности этой среды.
Но ближе к теме : ) Для работы пришлось поднять архив с прошивками, вспомнить очевидные вещи, самая главная из которых
Default IP POL638 192.168.97.42
Да, всё, что пишут в этих ваших интернетах, не подходит - 192.168.1.42 неправильно. Чтобы это узнать, пришлось ставить древнюю прошивку 13 года, подключать панель с гордой надписью VTS (кто помнит эту легенду про оем) и смотреть, как ползёт полоса "Загрузка объектов".
Собственно, для таких же, кто вдруг связался по старой памяти с этим оборудованием - на диске сборник прошивок, различная документация, а также непролеченные(!) версии Siemens Sapro и FactoryTalk . Имейте ввиду - программы ставятся на дефолтную ранее Win7 Ultimate x32, на х64 НЕ работает.
Было бы интересно почитать комменты тех, кому эта информация помогла : ).
Придумываем, рисуем и запускаем в моей SCADA Gatherlog - какой то тестовый сценарий.
Прошло три месяца с последних постов о ходе разработки, с того времени все кардинально изменилось в плане архитектуры. Это время я занимался - наукой, и определил направление работы дальше.
Сейчас перешел к общению с исследователями и научными руководителями. Пишу собственную научную работу по отказоустойчивым системам, но сам я - независимый исследователь, так как не работаю за счет фондов, институтов или организаций.
Кто читает впервые:
Я, автор , независимый исследователь, разработчик SCADA системы Gatherlog
А так же автор комплекса по разработке Промышленных Контроллеров под названием 3o|||sheet. Среда, IDE читается как Зошыт - тетрадь, но так как для компилятора и среды выполнения названия не придумал, пока все называю 3o|||sheet.
Ни SCADA ни Комплекс ПЛК - для коммерческого применения не готовы, хотя и рабочие как прототип. Остается много мелкой - рутины: кнопка туда - кнопка сюда, текстовые сообщения-предупреждения или ошибках...энтузиазма этим заниматься нет вообще.
3o|||sheet теперь использую для научного звания, по теме нового метода - отказоустойчивых систем. Собственный компилятор предоставляет широкое поле для экспериментов, а среда разработки с графической системой - делает демонстрации по всяким институтам - интереснее. В прошлых постах - есть все (описание компиляторов, и сред, концепций и прочее).
В этом посте расскажу как из простого микроконтроллера типа STM32G030 создать отказоустойчивую исполнительную систему внутри Промышленного Контроллера.
В прошлом посте частично коснулся разработанного мной метода отказоустойчивости -
Дивергентного Многоверсионного Выполнения Программ (DME). Суть ее в множественной N компиляции одной программы. Так называемая - программная (а если это на FPGA или многоядерных CPU) аппаратная избыточность типа Lockstep / TMR.
Как все начиналось
Чтоб сделать ПЛК который поддерживает много языков и функций (например - замена участков кода на лету и прочее) нужен собственный рантайм и компилятор который будет переводить любые языки ( LD FBD ST) в собственные инструкции. Первая версия моего компилятора давала сбой - то одно не верно посчитает, то другое. Я столкнулся "паразитными" смещениями по адресам, а точнее - в сложных местах программа могла не туда перейти, не то прочитать или не туда записать. Программа слетала, и не понятно в каком месте была ошибка - так как при тихом повреждении данных (silent corruption), и физическим вылетом могло пройти много времени, - замучаешься пошагово следить в отладке.
Структурная декорреляция адресного пространства копий одной программы.
Тут я подумал, а что если компилировать одну и ту же программу - два раза? Но вторую копию - перемешивать адреса функциям, блокам, переменным чтоб аналогичные по названиям переменные и функции второго экземпляра были не на том месте как в первой компиляции. Если компилятор все верно считает, нет никаких паразитных смещений, то каждая инструкция будет совпадать во всех копиях. Адреса у них хоть будут разные, но ход программы будет логически идентичен (смотри рисунок выше). А если адрес не верно просчитан - то в каждой копии программа запишет/прочитает или перейдет в логически разные - места. Тем самым детекция ошибки произойдет сразу.
Так и было, - две компиляции но разные структурно в памяти - все паразитные смещения из за бага компилятора - всплывали сразу. Так называемые silent corruption (скрытые ошибки)- стали наблюдаемы. Это позволило точно отточить алгоритмы просчета адресов, и больше компилятор не ошибался. Ну а дальше вы знаете: писал посты, тестировал разные микроконтроллеры как ПЛК.
Тогда я даже сам не понял что я придумал, и широкие возможности применения своего метода DME.
Отказоустойчивые системы
Сделал свой комплекс разработки ПЛК : среда разработки, компилятор, и среда выполнения на железе. Задумался об отказоустойчивости, и познакомился с существующими подходами:
Lockstep - две копии (одинаковые бинарники) программы на двух процессорах работают и сверяют друг друга на каждом шаге.
TMR - три копии (одинаковые бинарники) программы на трех процессорах. Если одна отличается, происходит голосование , кто не прав и работа выполняется дальше.
Оба метода применяются в авиации, атомной энергетике и прочее. Стандарт.
Все хорошо, да только вот Lockstep и TMR - уязвимы к коррелированным сбоям. Методы эффективны только если система замечает разницу между копиями программы, сигналит об этом. Но если оба ядра ошибаются - система не заметит ошибки, и продолжит выполнять ошибочную программу.
И тут я заметил, мой метод с деккореляцией адресного пространства который я применял в отлаживании компилятора - решает эту задачу!
Если система Lockstep и TMR "одинаковость" воспринимают как ОК, мой метод наоборот - одинаковость воспринимает как как - осторожность. А разность - как нормальную работу. Но у моего метода есть два типа разности:
Допустимая разность - это адреса (адреса функций, счетчика команд, переменных и т.д).
Не допустимая разность - в последовательности инструкций ( семантика ).
То есть, в системах Lockstep и TMR сводится к 1/2 :
Либо одна из копий программы ведет себя по другому - это ошибка.
Либо ведут себя одинаково - значит все хорошо. Но тут и проблема одинаковых бинарников, если все копии выполняются одинаково не верно, система будет думать что все хорошо.
В моем методе DME, соотношение 1/3 . Где:
одинаковая логика/инструкции - это Хорошо.
одинаковость адресов -Плохо.
разная логика/инструкции - Плохо.
Я сделал более узким коридор для корректности , и расширил коридор для прохождения ошибок (усилил ошибку).
Lockstep и TMR - совсем не ловят программные ошибки. Если в компиляторе есть специфический баг из за оптимизации или просто программа так написана - это не покрывается. Копии идентичны и поведут себя одинаково , а значит система не заметит. Проблему решают N-Version Programming - когда нанимают две группы программистов, и они пишут программу по разным вариантам (Airbus/Boeing). Очень дорогое, и медленное удовольствие. В общем не для ПЛК за 30$.
В нашем методе DME , при двойной компиляции и перемешиванием адресов, одинаковый баг программы, компилятора, или ошибки из за физики - обязательно приведет к расхождению (Дивергенции).
Практика
Создаем - тестовый проект в языке LD. Моя среда поддерживает FBD но так же пока только внутри LD. ST язык я не реализовал в полной мере, но на каком бы языке программа ни была, она переводится в единый виртуальный ассемблер (собственный синтаксис и инструкции, см. прошлые посты) который выполняется внутри на голом железе Микроконтроллера, FPGA или любого CPU.
Интерфейс. Тяжелые функциональные блоки внутри LD прекрасно подходят под тесты отказоустойчивости
Несколько выполняющихся копий, на одном дешевом микроконтроллере, от чего может защитить? Против тяжелого поражения питания, это - не защитит(вопрос к аппаратной части), но стать устойчивее к программным ошибкам, радиации или умеренным временным электромагнитным помехам, сильно компенсируя аппаратную часть - получится.
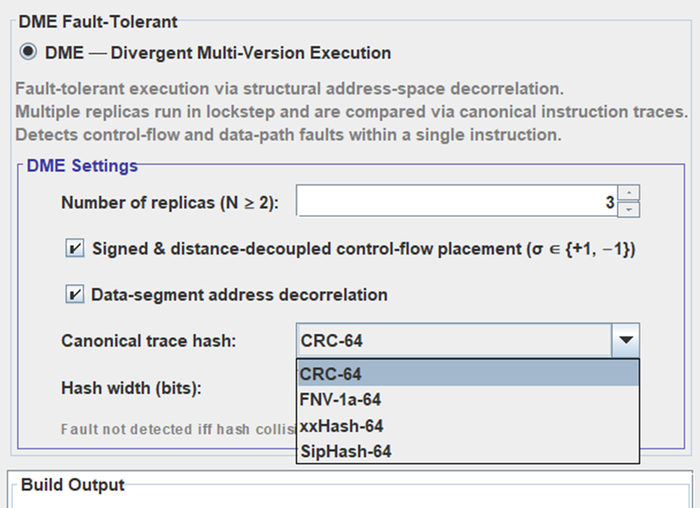
Настройка компиляции в 3o|||sheet:
Интерфейс с настройками - компилятору.
N - количество копий программы и количество соответственно компиляций. N Должно соответствовать количеству ядер, или ПЛК если они работают в режиме похожему на Lockstep\TMR. На STM32G030 эти ядра эмулируются, в чем смысл - дальше.
+1 -1 это команда разнесения адресов в разные по знаку стороны. Если в одной копии переход из функции А к функции Б изменяет программный счетчик например PC+=94, то в второй копии компилятор организует этот переход PC-=64. Усиливает декорреляцию адресного пространства, соответственно увеличивает область детектируемых программных багов и программных ошибок из-за физического влияния среды.
Canonical trace hash: Инкрементальный хеш выполнения программы (если есть аппаратный хеш как у Cortex M4) , но на слабом железе вместо хеша может подойти обычное сравнение каждой инструкции (опкода или результата) каждой копии программы простым "=", или хеш может быть банальным XOR с степенью ( за 2 такта, это + 10..20 наносекунд к выполнению инструкции, дешево ).
Тут принцип тот же что и Lockstep\TMR - N копий программы на ядрах, только в Lockstep\TMR сравниваются идентичные бинарники и состояние на каждом такте, у меня только логическая траектория, потому что адреса переменных и инструкций в копиях разные - они (адреса) исключаются из уравнений.
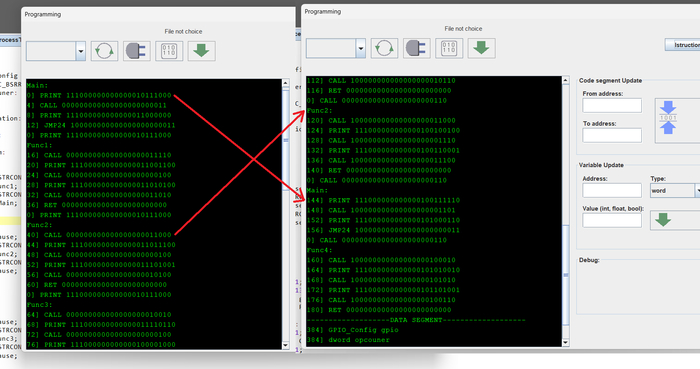
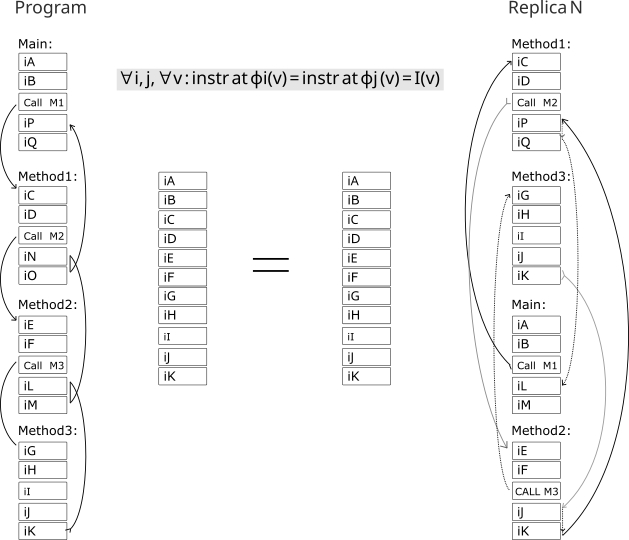
Любая программа, LD ST C++ не важно, состоит из блоков кода и функций. Мой компилятор их и перемешивает по разным адресам и разным знакам (+-) направлениям перехода. Если мы скомпилируем программу, то получим пространственные -разные версии одной программы:
N компиляций, и расположение программы в памяти. Один и тот же блок или функция - по разным адресам.
Если мы присмотримся к адресам функций на скрине, то увидим в одной копии например Main будет по адресу - 0 (ноль) в другой копии она же будет по адресу - 144. Так и со всеми остальными. Выполняется главный принцип DME - усиление ошибки программы через структурную декорреляцию адресного пространства.
На рисунке видно, несмотря на то что участки кода перемешаны (перемешаны на уровне функций и блоков кода имеется ввиду), и соответственно скомпилированы - траектория программы, логика будет идентичная (в штатном режиме работы).
Теперь, предположим в системе произошел коррелированый сбой, то есть такой который задевает все ядра или все копии программы. Чаще это возможно когда программа криво написана, затерла адрес возврата, или другого участка программы. Проблемы с питанием - тоже может повредить все ядра одинаково. Радиация, или помехи - риск минимален в атмосфере на Земле. В самолете на высоте 10 000м вероятность сильно возрастает, а в космических аппаратах бомбардировка процессоров частицами которые вызывают сбои происходит несколько десятков раз в сутки.
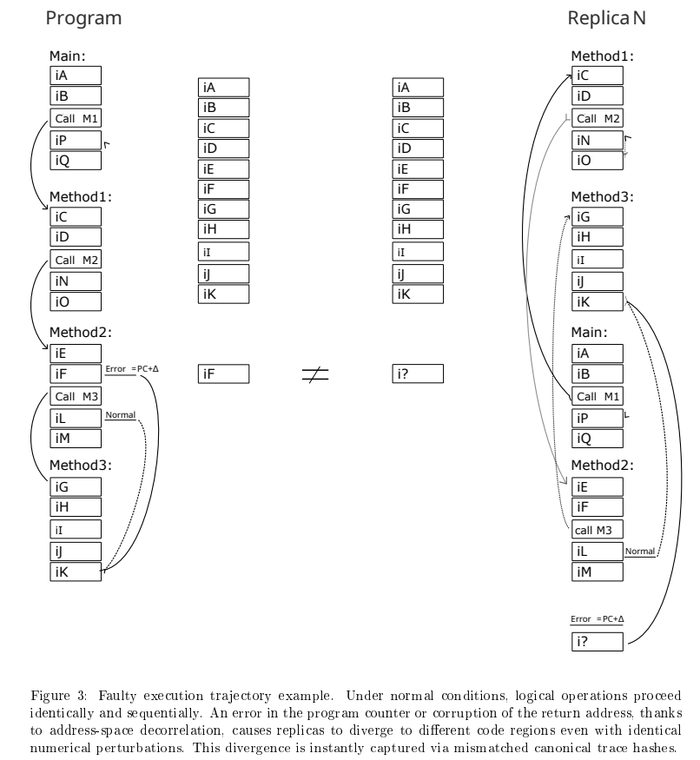
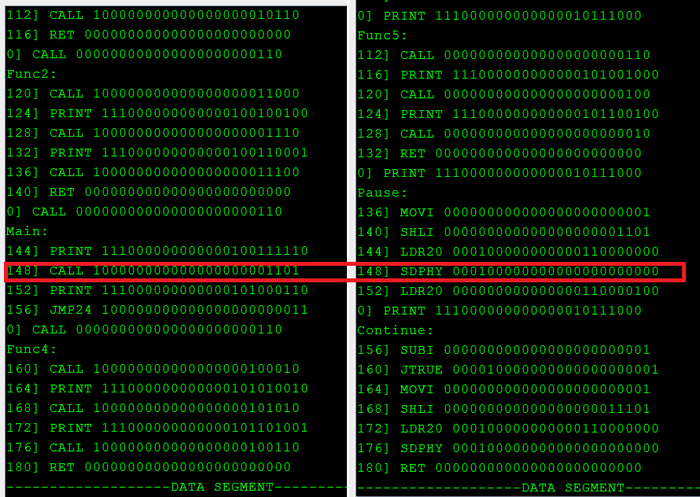
Давайте предположим, что сбой произошел (неважно по какой причине) , адрес возврата или какого либо перехода ветки , установлен в случайное значение 148:
Просмотр результата компиляции в 3o|||sheet. Одна программа - разные адреса ее компонентов.
Был бы это обычный отказоустойчивый ПЛК типа Lockset или TMR за 5000$ , они бы не заметили фатальной ошибки, так как бинарники одинаковы. Система бы увидела у всех копиях одинаковое значение и подумала что все хорошо.
Но наша система декоррелирована по адресам , это вызовет - Дивергенцию. Система фиксирует - две разные инструкции одновременно: CALL и SDPHY. Несовпадение. Компаратор вызовет программу X (типа обработчик ошибки) или осуществит переход в безопасное состояние.
Детекция - сразу, что очень важно, так как обычный ПЛК - слетит с концами и не успеет передать на каком месте авария. Либо вообще может слететь через какое то время долго притворяясь что все хорошо.
Ошибка может быть более сложной, напримеррадиация или электромагнитная помеха может не изменить весь адрес полностью, а только один бит (так называемый bit flip), тем самым добавив к адресу одинаковое - число. То есть, адреса продолжат быть разные, но смещенные на константу. Для этого мой компилятор и делает переходы с разными знаками между функциями и некоторые другие приемы для локальной асимметрии адресов..
Ошибка из за физических процессов: bit flip может привести к тому что в копиях, адрес изменится на константу. В методе DME это приведет к разным участкам кода, и ошибка будет детектированна.
Codesys, Siemens не имеют компиляторов с декорреляцией адресного пространства,их детекция ошибок сработает только если один ПЛК или ядро и отличаться от другого. А когда оба ошибаются - программа благополучно упадет и до этого может наделать много лишнего.
Что отказоустойчивого можно выжать с дешевого слабого МК STM32G030.
Одноядерный микроконтроллер выглядит полностью беспомощным, но интерпретация байткода в двух копиях сильно улучшает положение.
Time redundancy, EDDI/SWIFT
В моем методе DME, в одноядерной системе инструкции N копий выполняются по очереди псевдо-параллельно, а следовательно, каждая инструкция выполняется N раз и получается с задержкой по времени.
Есть такой метод отказоустойчивости Time redundancy - выполнения идентичных инструкций с задержкой по времени. Вот как это описывается:
Обнаружение ошибок: Программа или расчет выполняется дважды. Если результаты не совпадают, система фиксирует наличие ошибки.
Тип ошибок:Этот метод наиболее эффективен против кратковременных (перемежающихся) сбоев, вызванных внешними помехами (космические лучи, электромагнитные шумы).
EDDI и SWIFT - известные методы дублирования . Все эти Time redundancy, EDDI/SWIFT являются у нас побочным эффектом из псевдопарралельности нашего ПЛК в одноядерной системе. Наш ПЛК с DME перестаёт быть “чисто структурной” DME защитой с перемешанной памятью, а превращается в гибрид:
time redundancy + DME + семантический анализ и контроль данных
Таким образом, DME защищает программу от программных и коррелированных багов, которые не детектируются вообще Codesys, Siemens, а вторичный эффект Time redundancy, EDDI/SWIFT которые вытекают изпсевдо-параллельности дает устойчивость к физическим влияниям на систему. И делает наш ПЛК устойчивым к:
Transient faults (SEU, EMI, glitches) одиночный бит-флип в регистре, кратковременный сбой ALU, помеха на шине. Сработает эффект DME , Time redundancy, EDDI/SWIFT.
Memory corruption (stack/heap, out-of-bounds) переполнение буфера, повреждение указателя , повреждение данных в RAM. Сработает DME защита.
Повреждения данных\ переменных (для дешевых микроконтроллеров у которых нет ECC это критично).
Исследователи указывают что метод SWIFT имеет "чрезвычайный широкий охват детектируемых ошибок" , но SWIFT требует наличие в памяти коррекции ошибок ECC, которого нет в простых микроконтроллерах. Да и ECC поможет только если фзика изменила только один бит, если изменены несколько бит, ECC (а значит и SWIFT ) бессилен, потому что не восстановит данные. А еще, SWIFT в отличии от моего метода DME - не видит ложные переходы программы.
Понятно что никто не вставит дешевый микроконтроллер в управление атомной станцией. Но в космический аппарат, или в другую агрессивную среду - слабые но энергоэффективные микроконтроллеры - подходящее место. Уверен много кому пригодится ПЛК с повышенной отказоустойчивостью за дешево.
Производительность ПЛК на STM32G030 в режиме отказоустойчивости
У моего метода DME конечно есть недостатки (если он работает на одном ядре) . Дублирование программы на N реплик соответственно замедляет ПЛК в N раз.
Как то видел в домашних производителей ПЛК, STM32G030 использовался просто как микроконтроллер для модулей расширения вводов\выводов . А ведь этот Микроконтроллер производительнее ПК на i486 1992-1994 годов, и гораздо производительнее наверное чем вся электроника корабля летавшего на Луну.
Altera Cyclone |V EP4CE6E22C8, STM32F722, STM32G030C8
Скорость выполнения базовых логических операций в микросекундах:
Mitsubishi (китайский клон) STM32F103------------------------------------2.7---------------математика int 8.6
Allen Bradley Micro 810 -----------------------------------------------------------------2.5---------------математика int 8.5
Наш ПЛК, название не придумал , пишу с названия среды моей разработки 3o|||sheet.
В режиме отказоустойчивости, с циклом 10 миллисекунд, наш ПЛК 3o|||sheet STM32G030 отработаетпримерно 1100 операций: 550 - логические (контакты катушки) + 550 математические. Если брать ST, то математика и булевые операции так и остаются, а каждое условие типа if(a== > < ! b) займет в памяти и по времени выполнения - максимум как две логические операции (в зависимости от "регистрового давления", насколько далеко a, b в программе использовались до этого).
Я бы не сказал что это мало от микроконтроллера который другие компании ставят просто в качестве расширяющего вводы выводы. В этом отказоустойчивом режиме он производительнее обычных программируемых реле Siemens и Schneider .
Какие MCU в реле Siemens и Schneider неизвестно, может и 16 МГц ( в нашем STM32G030 64 MHz) , я только констатирую факт.
3o|||sheet STM32F722х - вытянет в быстрых (по меркам промышленности) ПИД регуляторах в режиме отказоустойчивости.
Altera Cyclone |V EP4CE6E22C8 даже на 50 МНz , в отказоустойчивом режиме, показывает впечатляющий результат, в цикле 1 миллисекунды отработает 8000 логических или математических (целочисленных) операций. .
Часто пишут что - главное не скорость, а надежность. Но чем быстрее выполнение инструкций, тем меньше можно сделать цикл, или тем сложнее программу можно втиснуть в один цикл.
Вернемся к отказоустойчивости. Интерпретируемость байткода дает серьезный отказоустойчивый эффект:
Если из за физического воздействия в месте X Нативных инструкций что то произошло в потоке программы, в нативном уровне где каждый такт это аппаратная инструкция - сразу может привести к вылету системы или серьезным последствиям.
В то время, 1 виртуальная инструкция "размазана" по нескольким десяткам или сотням тактов, и состоит соответственно из десятков нативных инструкций. Есть проигрыш в скорости, но воздействие в месте X изменит только логику самой инструкции (например 2+2 станет = 5, и переход на ветку В вместо А) но не повредит программу в целом. А так как у нас еще работает вторая копия программы , наш метод DME - зафиксирует и проконтролирует ошибку.
Из за дополнительного рантайма (например моего 3o|||sheet) память программ увеличивается на 45-50 килобайт, в отличии от программы которая допустим написана на СИ, и с точки зрения вероятности - возрастает событие из за помех которое что то подпортит внутри процессора.
Но, если и подпортит, то последствия не такие катастрофичные как если физика подпортит - нативный код, без контекста рантайма. Потому что "логическая плотность" нативного кода сильно ужата. Как петарда которая при взрыве разбросает плотно стоящие спичечные коробки (логику) возле эпицентра, но имеет меньше влияния если эти коробки далеко друг от друга и по площади дальше от эпицентра. Что то зацепит и упадет, но разрушимость логики не та, потому что 1 виртуальная инструкция, ее логика состоит из десятков нативных инструкций, а результат ее - всего лишь - одно число в конце, и его ошибочность будет замечено дальше.
А чем твой ПЛК отличается от других. Или про изобретения велосипедов.
Это частый вопрос гастролирующего читателя. Вот в каждом комментарии есть такое.
Во первых, китайцев существующие немецкие велосипеды Codesys, Siemens не останавливали, китайцы начали делать свои ПЛК (наверно разработчикам в Китае трудно было всем отвечать, зачем делать ПЛК создавая велосипеды, если уже были готовые где то в Германии).
Что касается домашних существующих конкурентов - то в плане отказоустойчивости я вообще не вижу ни в одной компании ничего особого - обычные ставки на резервирование со всеми вытекающими. В самолет я б лучше сел в котором установлен - мой ПЛК, чем чей то.
Извиняюсь за нескромность, но я не вижу себе конкурентов по инновациям в этом направлении, в первую очередь среди местных производителей. Я видел их сертификаты SIL3 SIL4 , но вряд ли там что то новое чем Lockstep/ TMR.
У меня проработан, конкретный , особенный, нигде ранее не встречающийся метод DME.
Во вторых - в Beremiz , китайских клонах Mitsubishi, и прочих дешевых ПЛК до 100$ ( а может и до 500$) близко нет никакой отказоустойчивости.
Устойчивость к коррелированным сбоям - вообще ни один ПЛК ни одного мирового бренда не имеет , в мире этот вопрос решается - дорогими специальными CPU - разнесением ядер на кристалле максимально удаленно друг от друга. Или N Variant Programming с разными группами программистов. Мой метод первый решает эту задачу структурно/программно (то есть - дешево).
В следующий раз расскажу часть моего метода DME "Periodic Layout Diversity" , который призван бороться с малыми глюками потока программ, тот самый Periodic Layout Diversity , когда из за внешнего воздействия может быть пропуск инструкции или несколько инструкций. Ни одна система в мире такое не детектирует, а это критично если в ПИД регуляторе или каком то автомате будет пропуск команды.
Внесение малой асимметрии адресов в критические участки кода, для гарантированной наблюдаемости ошибки в случае возникновения
В ней четко прописана математика. Больше всего у меня претензии к мировым и домашним брендам, по - доказательствам надежности. У них это - тесты в лабораториях, которые не факт что будут соответствовать на 100% рабочей обстановке. Я подошел к вопросу - математически, что кстати дешевле и легче для сертификации так как легче доказать надежность.
Мой метод DME , гарантирует математически - либо код отработает корректно, либо сразу остановится и контролировано перейдет в безопасное состояние. Но никакого неопределенного поведения.
Еще вопросы можно задавать в комментариях и на почту zoshytlogic@gmail.com
Привет, Пикабу! Честно говоря, не знаю насколько тут популярна техническая тематика, но я все-таки попробую представить вам небольшую статью о моем Modbus терминале.
Я знаю, опытные инженеры не раз видели такие заголовки и, возможно, сами писали подобные приложения. Но... тогда почему я постоянно сталкиваюсь с нехваткой хорошего инженерного софта? :) Хотя с другой стороны, небольшой и весьма консервативный рынок способствует дальнейшему дефициту решений...
Где-то года четыре назад я начал замечать за собой, что пишу очень много одноразовых или временных приложений для отладки, тестирования или изучения какого-либо оборудования. Также на моем рабочем ПК стояло около пяти разных терминалов. Каждый из них был удобен в своих сценариях. И не было среди них того, который закрывает хотя бы половину потребностей.
Тогда то я принял решение написать свой велосипед костыль вариант Modbus терминала.
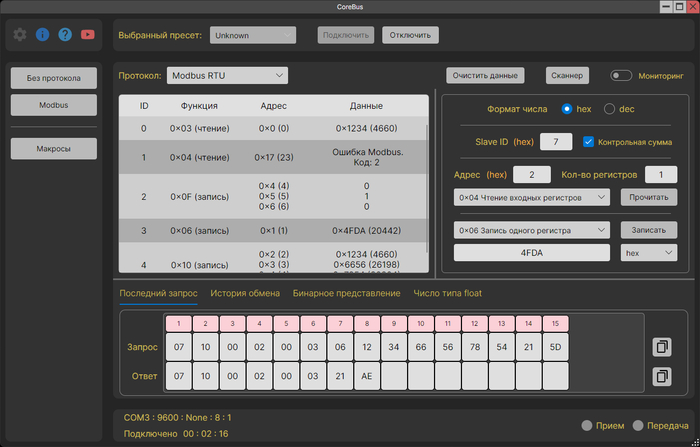
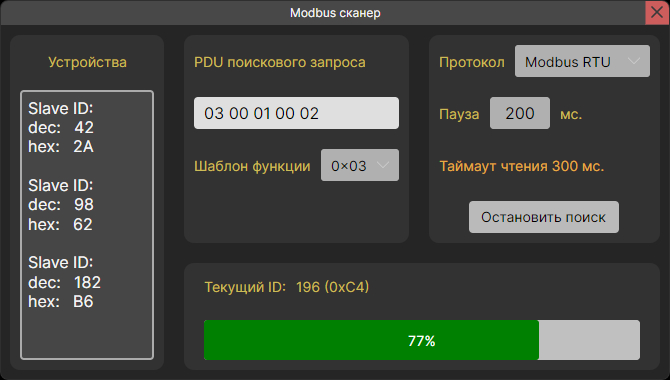
Внешний вид приложения. Режим "Modbus"
Итак, а что же умеет мой терминал?
Вот его основные возможности:
Три режима работы: "Без протокола", "Modbus" и "Modbus мониторинг".
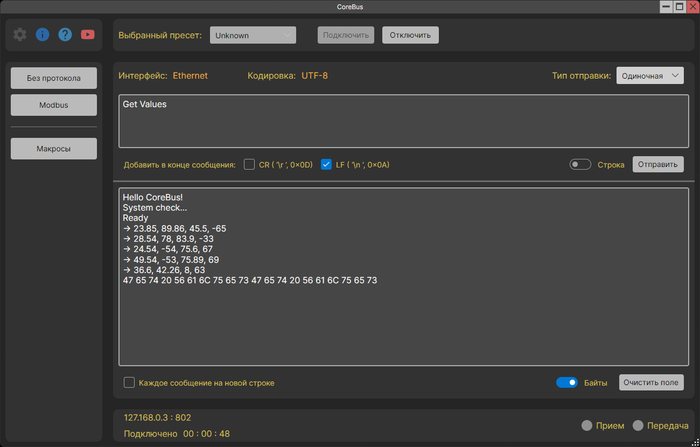
«Без протокола»:
Работа с данными в строковом или байтовом формате.
Поддержка разных кодировок.
Три режима отправки: одиночная, цикличная, отправка файла.
“Modbus”:
Поддержка различных вариаций протокола Modbus: TCP, RTU, ASCII и RTU / ASCII over TCP.
Удобная работа с функциями записи.
Возможность работы с числами типа float.
Возможность работы с бинарными данными.
Modbus сканер, который осуществляет поиск устройств на линии связи.
"Modbus мониторинг":
Удобное отображение регистров.
Конвертация в числовые типы (Int16/32, float, и др.).
Преобразования по заданной формуле.
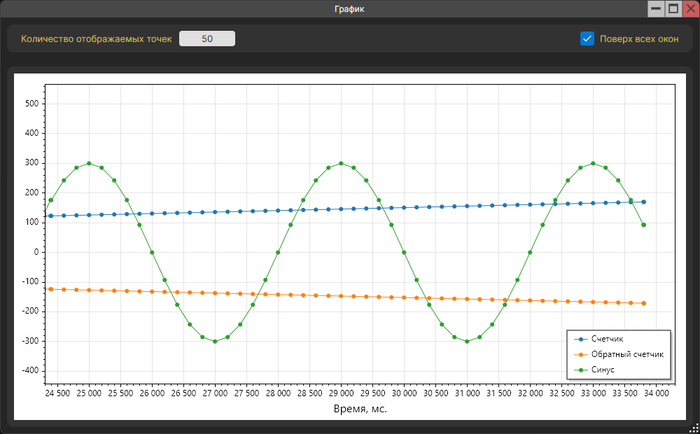
Построение графика в реальном времени.
Логгер.
Макросы:
Отдельные макросы для каждого режима работы.
Макрос состоит из неограниченного количества команд (действий).
Для Modbus макросов предусмотрена возможность выставления общего Slave ID для всего макроса.
Импорт и экспорт макросов.
Темная и светлая темы приложения.
Пресеты с пользовательскими настройками.
Руководство пользователя.
Кроссплатформенность: Windows, Linux.
Хорошо, а почему его можно назвать универсальным? Какие потребности он закрывает?
Глобально тут есть несколько режимов работы. И чтобы ответить на вопрос обсудим каждый режим по подробнее.
Режим "Без протокола"
Это по сути обычный "сырой" терминал. Работает со строками и байтами. Полезно, когда нужно вручную сформировать пакет, поработать с не Modbus протоколом, отладить какое-то внешнее устройство, воспроизвести баг и т.д.
Есть три режима отправки: одиночная, цикличная и отправка файлов.
Режим "Без протокола"
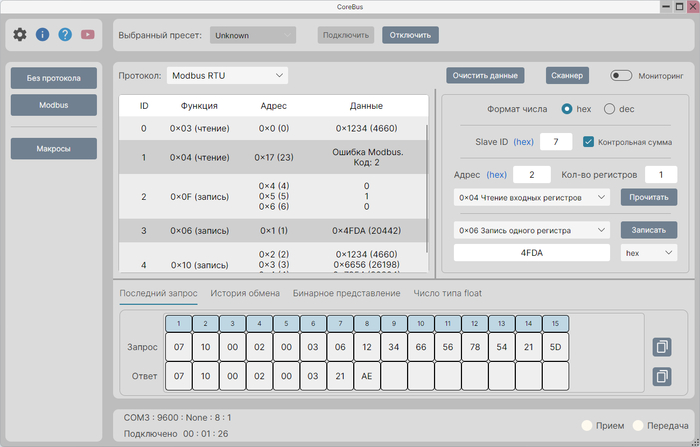
Режим "Modbus"
В этом режиме приложение значительно упрощает пользователю работу с протоколом Modbus. А также позволяет более детально рассматривать пакеты. Работает через запрос - ответ. Удобно использовать для изучения, отладки или управления подключенным устройством.
Режим "Modbus" в светлой теме
Отдельно хочу отметить возможность переключения между темной и светлой темой.
Как по мне это чуть ли не киллер-фича. Объясню почему. Лично мне удобнее работать в темной теме. Так мои глаза меньше утомляются, и чувствую я себя лучше. Но как мы знаем не все приложения поддерживают темную тему (привет, CODESYS). И поэтому когда огромное черное окно терминала из раза в раз появляется на фоне светлой IDE... глаза устают еще больше. А если еще и в помещении недостаточно света, то это просто жуть... В идеале, все приложения на экране должны быть на одном уровне яркости. И переключение тем оформления в моем терминале может помочь сохранить здоровье ваших глаз.
Но вернемся к режиму "Modbus".
Как вы видите, внизу есть четыре разных вкладки. В них удобно просматривать содержимое запроса-ответа.
Визуализация данных Modbus
Также в этом режиме есть удобный Modbus сканер, который ищет подчиненные устройства на линии связи.
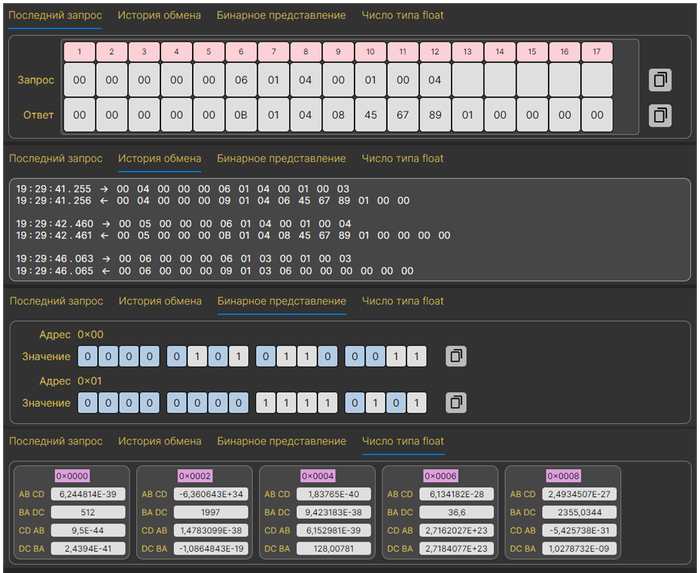
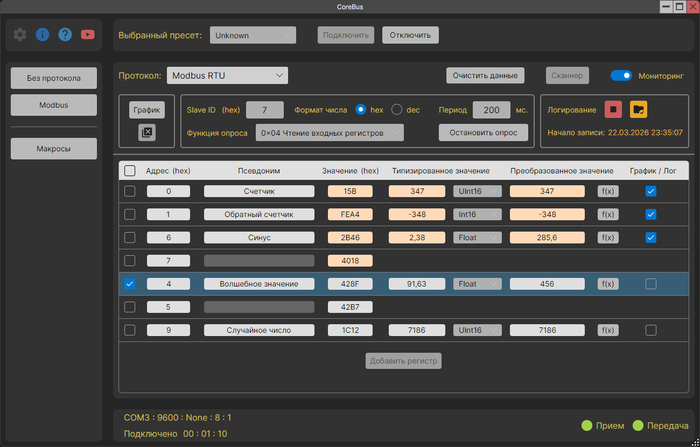
"Modbus мониторинг"
Специальный режим, предназначенный для визуального контроля подключенного устройства. Удобно использовать для контроля показаний датчиков или контроля состояния внешнего устройства. В этом режиме приложение может работать и в качестве логгера.
В этом режиме отображаются регистры Modbus. Значения регистров обновляются с заданным периодом. Полученные данные можно легко преобразовать: выбрать тип, применить формулу и отобразить результат в удобном виде или на графике.
Режим "Modbus мониторинг"
Мне иногда пишут пользователи. Задают вопросы, предлагают добавить что-то новое или доработать старое. Я всегда с интересом общаюсь. И вот идею этого режима меня просили реализовать довольно давно. Формировалась эта идея по-разному. В том числе и у меня в голове. И вот в конце прошлого года я наконец-то сформировал все идеи во что-то цельное и приступил к реализации. Результат выпустил в релиз буквально на днях.
Из красивых картинок касательно этого режима могу приложить еще разве эту)
Построение графика в реальном времени в режиме "Modbus мониторинг"
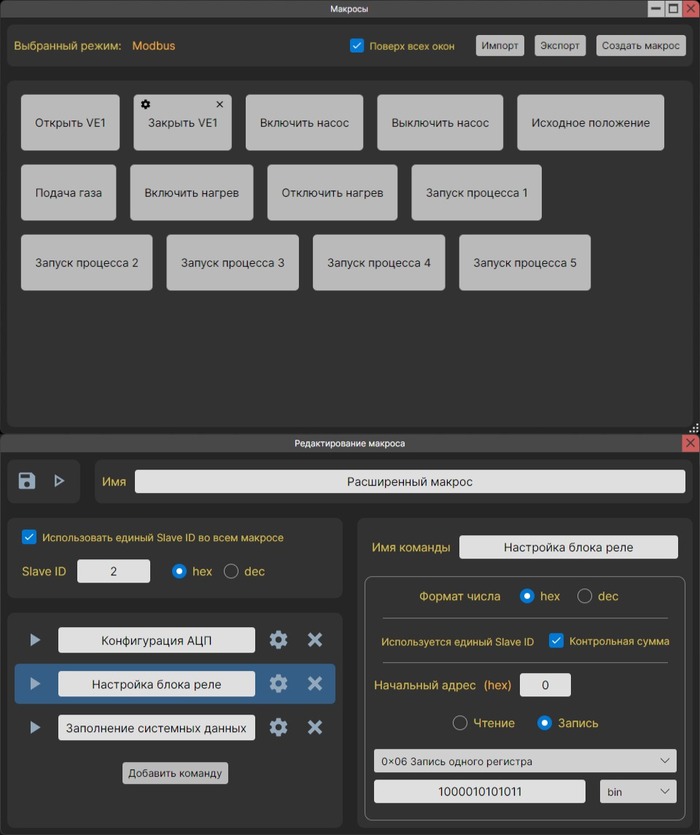
Макросы
Позволяют удобно собрать несколько действий в одну команду. Можно использовать как решение для автоматизации каких-то процессов: сложной инициализации устройства, управление группой оборудования и т.д.
Рабочее поле макросов (сверху) и окно редактирования макроса (снизу)
Как видно каждый макрос состоит из неограниченного количества команд. Команда - это отправка одного сообщения. В окне редактирования, команды можно отправлять по отдельности.
Расскажу пару случаев из свой практики, когда этот режим макросов мне очень пригодился.
Случай №1
Однажды, мне доводилось писать ПО для небольшого станка. ПЛК управлял группой оборудования: клапаны, задвижки, датчики и прочее. Первым делом, я определился с внешним API (если прям по-айтишному), т.е. с определением регистров Modbus, которые торчали наружу. А затем начал писать внутреннею логику. Для тестирования всего этого дела, а также для наладки оборудования я накидал несколько макросов, чтобы железяку можно было протестировать, до того момента, пока появится полноценное клиентское приложение.
P. S. просто брать и менять значения регистров в CODESYS оказалось неудобно и муторно. Проще нажать одну кнопку в макросе.
Случай №2
Однажды у нас в цеху у одного из станков вышел из строя контроллер серводвигателя. Это было печально, т.к. продукция этого станка была очень необходима. Что делать? Может просто купить в первом доступном магазине? Может даже в "Чип и Дип"? Ха-ха, так просто ничего не бывает, даже если цена вопроса не очень большая. Поэтому пока героическими усилиями отдела закупок (или как-то так) проводилась спецоперация по покупке нового оборудования, а затем с помощью не менее героических усилий механиков проводилась интеграция этого оборудования. Наш станок на протяжении n-ого количества времени (может недели, может месяцы, кто знает...) проработал с найденным где-то в старых запасах другим похожим контроллером. Естественно, у родного и подменного контроллеров карта регистров не совпадала. И в качестве временного решения, оператор использовал макросы для управления двигателем.
Видеоролики
Иногда вместо тысячи слов, лучше посмотреть пару коротких видео с демонстрацией работы приложения.
Вот тут можно посмотреть о режиме "Modbus мониторинг":
Я надеюсь, вам понравилась моя первая публикация на Пикабу. Будет здорово, если мое приложение CoreBus окажется вам полезным. Не забывайте обращаться к встроенному руководству пользователя.
Проект развивается благодаря обратной связи от пользователей и пожертвованиям, которые вы можете сделать, перейдя по этой ссылке:
Умный дом в рекламе выглядит как идеальная сцена: вы заходите, свет сам включается, температура ровная, вода перекрыта при протечке, а кофе начинает готовиться “по расписанию”. В жизни все упирается в другое. В то, что лампочка внезапно “отвалилась” от сети. В то, что датчик движения реагирует на кота, но не на вас. В то, что половина устройств живет в одном приложении, половина в другом, а сценарии держатся на облаке, которое сегодня решило обновиться.
Хорошая домашняя автоматизация не должна быть шоу. Она должна быть незаметной. И главное – предсказуемой: выключатель на стене должен работать всегда, протечка должна перекрыть воду даже при падении интернета, а климат не должен превращаться в вечную настройку “чуть теплее – чуть холоднее”.
Давайте разберем, какие IoT-гаджеты действительно дают эффект, какие протоколы стоят за этой магией, что сегодня меняет рынок (спойлер: Matter и Thread), и как собрать систему так, чтобы она не раздражала.
С чего начинается умный дом: не с лампочки, а с “где живут правила”
Самая распространенная отправная точка – купить умную лампу “на пробу”. Она подключается, моргает всеми цветами, радует неделю, а потом выясняется, что дом не стал умнее. Он просто получил еще одно приложение и еще одну зависимость.
Сильный умный дом начинается с другого вопроса: где будет жить логика автоматизации. Если сценарии выполняются на серверах производителя, вы получаете удобство “из коробки”, но вместе с ним – зависимость: от интернета, от аккаунта, от того, не закроют ли сервис и не поменяют ли условия. Если логика исполняется локально, на хабе у вас дома, система остается работоспособной даже когда внешняя связь плохая или отсутствует.
В быту это ощущается просто: свет, протечки, базовые сценарии должны работать как обычная электрика и сантехника – надежно и без вопросов. А “дополнительные радости” вроде голосового управления, удаленного доступа и красивых отчетов можно оставить на облачный уровень.
Экосистемы и совместимость: почему Matter стал важным (и почему он не решает все мгновенно)
Долгое время умный дом развивался как набор “крепостей”: каждый крупный игрок строил собственную экосистему и старался удерживать пользователя внутри. Так появились ситуации, когда у вас датчики одной марки, лампы другой, а совместить их можно только через костыли или сторонние мосты.
Стандарт Matter оказался попыткой привести базовую совместимость к единому языку, чтобы устройства разных брендов могли нормально работать внутри разных экосистем. Его развивает Connectivity Standards Alliance.
Но важно не попадаться на маркетинговую ловушку. Matter – это не “новая радиосвязь”, а стандарт взаимодействия поверх IP. То есть устройства могут использовать Matter, но физически подключаться по разным каналам – чаще всего по Wi-Fi или через Thread. И здесь мы упираемся в протоколы.
Протоколы умного дома: Wi-Fi, Thread, Zigbee, Z-Wave и почему они ощущаются по-разному
Если объяснять на пальцах, то протоколы отличаются не “скоростью” как в смартфонах, а тем, как они ведут себя в реальном доме: как держат связь, как дружат с батарейками, насколько легко масштабируются, насколько зависят от вашего роутера.
Wi-Fi привычен всем. Он удобен для камер, домофонов, умных колонок, панелей и любых устройств, которые потребляют больше данных и обычно сидят на питании. Слабое место Wi-Fi в умном доме – батарейные датчики и массовость. Десятки устройств Wi-Fi могут начать нагружать домашний роутер, а мелкие сенсоры на батарейках на Wi-Fi живут не так долго и не так стабильно, как хотелось бы.
Thread задумывался как энергоэффективная mesh-сетка для небольших устройств, где важны батарейки и устойчивость связи. Это IP-сеть, которая хорошо подходит под философию Matter, но требует узла-посредника – Thread Border Router, который связывает Thread-мир с вашим обычным IP (Ethernet/Wi-Fi).
Zigbee – зрелая рабочая лошадка. Он тоже mesh, он широко распространен, у него огромная линейка датчиков, ламп и реле. Часто Zigbee требует координатор/хаб, но взамен дает устойчивую “сетку” для множества устройств. Zigbee и Matter сейчас развиваются параллельно: где-то производители переводят новые устройства на Matter, где-то Zigbee остается основой, а совместимость делается через мосты.
Z-Wave многие любят за ассортимент “домовых” устройств – особенно в сегменте реле, датчиков и замков. Он тоже про надежную сетку, но у него есть нюанс по региональным частотам и необходимость отдельного контроллера. В экосистеме Z-Wave активно развивают доступность стека и расширение поставщиков.
Bluetooth в умном доме чаще выполняет роль помощника: настройка устройств, локальное управление “рядом”, иногда – связь с отдельными гаджетами. Как основной каркас для всей автоматизации BLE обычно не выбирают, но без него вы все равно будете сталкиваться постоянно (особенно на этапе первичной настройки).
Если вы хотите простую инженерную эвристику: Wi-Fi оставьте для “тяжелого” и питаемого, а Thread/Zigbee/Z-Wave используйте как слой для датчиков и исполнительных устройств, где важны батарейки и устойчивость.
Какие IoT-гаджеты реально дают результат, а какие чаще остаются игрушкой
Самые полезные устройства умного дома – те, которые добавляют “органы чувств” и “руки”. То есть датчики и исполнительные механизмы. Именно они превращают квартиру в систему, которая реагирует на события, а не просто умеет включаться с телефона.
Освещение: почему умный выключатель обычно важнее умной лампы
Умная лампа – прекрасный вход в тему, но плохой фундамент для системы. Причина бытовая: люди продолжают пользоваться выключателем на стене. И если выключатель физически обесточил лампу, никакая “умность” больше не поможет.
Поэтому в устойчивой системе чаще делают наоборот: ставят умные выключатели, диммеры или реле, а лампы используют обычные. Тогда свет работает как нормальная электрика, а “ум” добавляется сверху: сценарии по времени, по движению, по освещенности, по “ночному режиму”.
Диммеры, кстати, часто дают больше комфорта, чем кажется. Когда свет вечером включается мягко, дом становится менее “резким”. И это тот эффект, который чувствуется каждый день.
Климат: термостаты, термоголовки и недооцененный датчик CO2
Автоматизация климата – одно из немногих направлений, где эффект можно измерить не только ощущениями, но и счетами. Умные термостаты и термоголовки помогают избегать ситуации “жарит без причины”, особенно если вы привязываете режим к присутствию дома или к расписанию.
Отдельная сильная штука – датчик CO2. Это не про “страшные вещества”, а про простую физиологию. Когда CO2 растет, появляется сонливость и ощущение тяжести воздуха. И если дом умеет подсказать “пора проветрить” или автоматически включает вентиляцию/приточку, качество жизни меняется заметнее, чем от очередной RGB-ленты.
Безопасность: протечки, дым, открытия и почему протечки почти всегда номер один
Если выбирать один класс устройств, который стоит установить почти всем, это датчики протечки – особенно в паре с электроклапаном перекрытия воды. У протечки плохая особенность: она редко бывает “немножко”. Обычно она либо ничего, либо дорого.
И именно здесь становится критично, где живет логика. Перекрытие воды должно сработать локально. Не “после того, как облако пришлет пуш”, а сразу.
Датчики открытия и движения тоже сильны, но не только как “охрана”. Это сенсорная база для комфортных сценариев: прихожая загорается, когда вы входите; ночью включается слабая подсветка, чтобы не слепило; если окно открыто, отопление может перейти в экономичный режим.
Энергия: умные розетки полезны, если ими не пытаться заменить электрощит
Умная розетка хороша как инструмент управления и мониторинга для умеренных нагрузок: торшер, роутер, увлажнитель, зарядки, мелкая бытовая техника. Но на мощных потребителях (бойлеры, теплые полы, кондиционеры) лучше думать инженерно: правильные реле/контакторы и корректная схема в щите. Иначе можно получить нагрев, нестабильность и проблемы с ресурсом.
Если хочется видеть энергопотребление, розетки с измерением мощности дают первые инсайты: какие устройства “едят” больше, чем вы думали. Но полноценная картина появляется, когда учет сделан по группам или по ключевым линиям.
Локальная автоматизация и облако: самый практичный компромисс
В реальности большинство людей хотят и то и другое: чтобы работало без интернета, но при этом чтобы можно было включить свет удаленно, посмотреть камеры из поездки и попросить голосового ассистента “сделай потише”.
Самая здоровая архитектура обычно такая: сценарии “должно работать всегда” исполняются локально, а облако используется как надстройка для удобств. Тогда умный дом остается функциональным, даже если у провайдера проблемы или у производителя идет обновление.
Почему умный дом чаще раздражает: три ловушки, которые встречаются постоянно
Первая ловушка – собрать зоопарк устройств, у которых нет общего центра. Разные приложения, разные учетные записи, разные “мосты” и вечная путаница. Противоядие простое: сначала выбираете ядро (экосистему/хаб/контроллер), потом покупаете устройства под него.
Вторая ловушка – конфликт с привычками. Самая частая история: умные лампы, которые выключаются обычным выключателем. У вас получается система, которая регулярно “ломается” ровно потому, что люди живут как люди. Если хотите стабильность, подстраивайте “ум” под привычное поведение, а не заставляйте домочадцев помнить, что “этот выключатель трогать нельзя”.
Третья ловушка – безопасность сети. Устройства умного дома – это часть вашей сети. И базовые меры тут очень помогают: отдельная сеть/гостевой Wi-Fi для IoT, сильные пароли, обновления прошивок, минимизация сомнительных облачных сервисов.
Куда движется рынок: меньше “религии брендов”, больше нормальной совместимости
Matter и Thread двигают рынок к более спокойной жизни: меньше барьеров совместимости, больше устройств, которые “просто подключаются”.
Но переход не произойдет за один сезон. Еще будут устройства “обещали Matter”, которые поддерживают его частично. Еще будут мосты между протоколами. Еще будут смешанные сети в одном доме. Поэтому зрелый подход сегодня – строить систему так, чтобы она переживала изменения: единое ядро, понятные протоколы, локальная логика, и только потом – украшения.
Итог: как собрать умный дом, который ощущается как удобство, а не как проект
Умный дом хорош не количеством гаджетов, а тем, что он предсказуем. Он не требует от вас “вспоминать, как работает” и не превращает свет в квест.
Если хотите короткую формулу, она такая: выберите ядро, определите протоколы под задачи, поставьте сенсорный слой (движение, открытия, протечки, климат), добавьте исполнительные устройства там, где это дает пользу (свет, вода, отопление). А потом уже расширяйте функциональность голосом, панелями, красивыми сценариями и аналитикой. Тогда автоматизация становится частью дома, а не хобби на бесконечной настройке.
Если сегодня инженер открывает SCADA и видит насосную станцию “как на ладони”, легко забыть, что когда-то на месте трендов и алармов были телефонные звонки, обходы и толстые журналы показаний. Логика была простой и жесткой: чтобы понять, что происходит на объекте, надо быть рядом. А если объект далеко, погодные условия плохие, персонал ограничен, а авария развивается быстро, “быть рядом” превращается в дорогую роскошь.
SCADA родилась не из моды на цифровизацию, а из необходимости. Промышленность и инфраструктура десятилетиями искали способ видеть удаленный процесс, получать измерения в реальном времени и иметь возможность вмешаться, не отправляя человека на место. По сути, вся мировая история SCADA – это история борьбы с расстоянием, неопределенностью и ценой реакции.
До SCADA: телеметрия как первый шаг к “удаленному глазу”
Раннее “супервизорное управление” появлялось в отраслях, где объекты распределены географически: энергетика, нефтегазовые магистрали, водоснабжение, транспортные узлы. Сначала это были разрозненные решения: дистанционные переключения, релейные схемы, телефония, первые каналы передачи измерений. В источниках по эволюции SCADA отмечается, что к концу 1950-х появились первые системы, которые уже можно считать предтечами SCADA, построенные на доступной на тот момент телеметрии и телефонных линиях.
В 1960-е телеметрия оформляется как практика: измерения и состояния начинают собираться автоматически и передаваться в диспетчерские пункты, чтобы принимать решения быстрее и надежнее, чем при ручных обходах. Важно понимать, что здесь не было “красивых интерфейсов”. Было главное: данные приходят сами, а не вместе с человеком.
Первые поколения SCADA: централизованный мозг и закрытые экосистемы
Первые SCADA в привычном смысле росли на вычислительной технике своего времени. Это была эпоха центральных машин и дорогих, часто выделенных каналов связи. Архитектура выглядела монолитной: один центр обработки, к нему подключены удаленные терминалы, обмен данными идет по ограниченным протоколам, а железо и программное обеспечение часто поставлялись “одним пакетом”.
Такой подход был логичен. Он давал предсказуемость и управляемость. Но одновременно формировал зависимость от поставщика и тяжелую модернизацию: заменить кусок системы без эффекта домино было сложно. Именно поэтому старые диспетчерские комплексы нередко живут десятилетиями: они надежны, пока их не пытаются “аккуратно обновить”.
В научных обзорах эволюции SCADA подчеркивают, что переход от простых supervisory-систем к SCADA был связан с развитием телеметрии, каналов связи и элементной базы, а далее архитектуры начинали усложняться по мере появления более доступных и компактных электронных устройств.
RTU и распределение функций: когда “поле” стало умнее
Следующий крупный шаг в мире SCADA связан с ростом роли полевых устройств. Появляются и развиваются RTU (remote terminal unit), а также специализированные устройства автоматики и защиты в энергетике. Идея проста: не обязательно тащить всю интеллектуальность в центр. Часть функций может жить ближе к объекту, особенно если канал связи нестабилен или дорог.
Это изменение особенно ярко видно в энергетике и инфраструктурных сетях, где возникла потребность в межвендорной совместимости. Так появляются и закрепляются телемеханические стандарты. Например, IEC 60870-5-101 как “companion standard” для базовых задач телемеханики опубликован в 1995 году и прямо нацелен на совместимость оборудования в задачах мониторинга и управления распределенными процессами.
В Северной Америке похожую роль занял DNP3. На сайте DNP Users Group описано, что в ноябре 1993 года ответственность за спецификации и развитие DNP3 была передана в сообщество пользователей и вендоров, а позднее протокол был принят как IEEE Std 1815. Это важно не только как “историческая дата”, а как признак зрелости: отрасль хотела не уникальные решения под каждого оператора сети, а общий язык для удаленных объектов.
PC и Windows: момент, когда SCADA стала массовой и визуальной
Дальше рынок автоматизации подхватил то, что обычно подхватывает: массовые вычислительные платформы. Появление и удешевление ПК, распространение Windows и графических интерфейсов резко изменили HMI/SCADA. Диспетчерская перестала быть закрытым миром дорогих терминалов и превратилась в привычную картинку с мнемосхемами, трендами и журналами событий.
Этот этап часто вспоминают как “демократизацию” SCADA: визуализация стала доступнее, внедрение быстрее, интеграция с офисной инфраструктурой проще. Но вместе с этим пришли и новые риски: обновления, драйверы, совместимость, а позднее и киберугрозы. Впрочем, именно PC-эпоха сделала SCADA тем, чем большинство инженеров ее помнят: системой, где оператор видит процесс в реальном времени и быстро управляет им.
Modbus и “общие слова” между устройствами: почему простота победила
В параллельной линии истории происходило не менее важное: стандартизация общения между устройствами. Если ранние системы строились на закрытых протоколах и “родных” интерфейсах, то рост числа устройств и производителей создал реальную боль интеграции.
Modbus стал одним из символов этой простоты. Schneider Electric в своем справочном материале прямо пишет, что Modbus был опубликован Modicon в 1979 году для ПЛК. Почему он выжил десятилетиями? Потому что он открыт, понятен и “достаточно хорош” для огромного числа задач. В результате Modbus стал одним из типовых мостов между RTU/ПЛК и SCADA, особенно в распределенных инфраструктурах.
В историческом смысле это важный момент: индустрия начала ценить не только функциональность, но и предсказуемость интеграции. Если протокол понятен и широко поддерживается, стоимость владения системой падает, а модернизация становится реальнее.
OPC: как индустрия перестала утопать в драйверах
К 1990-м стало ясно, что “драйвер на каждое устройство” не масштабируется. Разные ПЛК, разные протоколы, разные поставщики – и каждая SCADA вынуждена решать одну и ту же задачу: переводить десятки языков в общую модель данных. Именно на этом фоне появляется OPC.
OPC Foundation объясняет это максимально прямо: когда стандарт впервые выпустили в 1996 году, его задача была абстрагировать PLC-специфичные протоколы и дать SCADA/HMI унифицированный интерфейс через “middle-man”. Это стало поворотной точкой: SCADA начала отделяться от конкретного железа и превращаться в более модульную систему. Интеграция стала меньше зависеть от того, кто именно производитель контроллера, а больше – от того, как устроена модель данных и инфраструктура обмена.
Дальше OPC эволюционировал, но исторический смысл именно в “первом прыжке”: индустрия признала, что совместимость – это ценность уровня архитектуры.
Web-SCADA и платформа данных: диспетчерская выходит за стены завода
Следующий виток связан с сетевой эпохой. Сначала SCADA стала клиент-серверной внутри предприятия, затем появились web-клиенты, а позже – подход, где SCADA рассматривается не только как “экран оператора”, а как платформа данных для многих потребителей: эксплуатации, энергетиков, качества, техслужбы, аналитиков.
На уровне примеров новой волны часто упоминают Ignition, который был выпущен в январе 2010 года и позиционировался как интегрированная платформа, опирающаяся на OPC UA и серверную архитектуру. Важно даже не название, а сдвиг мышления: SCADA перестает быть “толстым клиентом на операторской машине” и все больше становится центральным узлом, где данные собираются, нормализуются, архивируются и раздаются по ролям.
Кибербезопасность как исторический перелом: после 2010 “изолированная сеть” перестала быть аргументом
Если попросить инженеров назвать событие, после которого разговоры о безопасности стали серьезными, многие вспомнят Stuxnet. В описаниях Stuxnet подчеркивают, что червь был связан с атакой на промышленную инфраструктуру и может рассматриваться как платформа для атак на современные SCADA/PLC-системы. Даже если не уходить в детали, важен итог: промышленность увидела, что цифровая атака может иметь физические последствия, и что “у нас технологическая сеть” больше не гарантирует спокойствия.
Параллельно оформляется стандартизация безопасности для промышленных систем. В истории IEC 62443 указывается, что в 2002 году ISA создала комитет ISA99, который начал выпускать документы по кибербезопасности систем автоматизации, а затем произошло сближение с IEC и развитие серии стандартов. Этот этап тоже часть истории SCADA, потому что современная SCADA – это почти всегда сеть, удаленный доступ, интеграции и, следовательно, необходимость проектировать безопасность так же инженерно, как питание или резервирование.
Что менялось на самом деле: не “картинка”, а доверие к данным
Если смотреть на историю SCADA без романтики, она сводится к одной линии: росту доверия к данным при росте сложности среды.
Сначала задача была просто “получить показания удаленно”. Потом “управлять удаленно”. Потом “сделать так, чтобы это работало между разными устройствами и поставщиками”. Потом “дать доступ большему числу ролей и систем”. Потом “сделать это безопасно”. И на каждом шаге индустрия упиралась в одно и то же: данные имеют ценность только тогда, когда понятны их происхождение, качество, контекст и ответственность за изменения.
Поэтому современная SCADA все чаще воспринимается как слой, который соединяет физику процесса и управленческие решения. И чем больше на этот слой опираются производство, учет и аналитика, тем важнее становятся дисциплины, которые в ранних системах могли быть вторичными: управление событиями, журналирование, контроль изменений, киберустойчивость, воспроизводимость.
Итог
Мировая история SCADA – это не история “одной технологии”. Это история эволюции инженерного ответа на удаленность и сложность: от телеметрии и телефонных линий к стандартам телемеханики, от монолитных центров к распределенным RTU, от закрытых драйверов к OPC, от локальных диспетчерских к web-платформам и экосистемам данных, и от наивной “изоляции” к зрелой кибербезопасности.
И если вынести из этой истории один практический вывод, он будет скучным, но полезным: SCADA становится лучше не тогда, когда на экране красивее, а тогда, когда системе можно доверять под нагрузкой – технической, организационной и внешней.