

Как я разрабатывал отказоустойчивый Промышленный Контроллер и SCADA под физические помехи.Ч1

Придумываем, рисуем и запускаем в моей SCADA Gatherlog - какой то тестовый сценарий.
Прошло три месяца с последних постов о ходе разработки, с того времени все кардинально изменилось в плане архитектуры. Это время я занимался - наукой, и определил направление работы дальше.
Сейчас перешел к общению с исследователями и научными руководителями. Пишу собственную научную работу по отказоустойчивым системам, но сам я - независимый исследователь, так как не работаю за счет фондов, институтов или организаций.
Кто читает впервые:
Я, автор , независимый исследователь, разработчик SCADA системы Gatherlog
А так же автор комплекса по разработке Промышленных Контроллеров под названием 3o|||sheet. Среда, IDE читается как Зошыт - тетрадь, но так как для компилятора и среды выполнения названия не придумал, пока все называю 3o|||sheet.
Ни SCADA ни Комплекс ПЛК - для коммерческого применения не готовы, хотя и рабочие как прототип. Остается много мелкой - рутины: кнопка туда - кнопка сюда, текстовые сообщения-предупреждения или ошибках...энтузиазма этим заниматься нет вообще.
3o|||sheet теперь использую для научного звания, по теме нового метода - отказоустойчивых систем. Собственный компилятор предоставляет широкое поле для экспериментов, а среда разработки с графической системой - делает демонстрации по всяким институтам - интереснее. В прошлых постах - есть все (описание компиляторов, и сред, концепций и прочее).
В этом посте расскажу как из простого микроконтроллера типа STM32G030 создать отказоустойчивую исполнительную систему внутри Промышленного Контроллера.
В прошлом посте частично коснулся разработанного мной метода отказоустойчивости -
Дивергентного Многоверсионного Выполнения Программ (DME). Суть ее в множественной N компиляции одной программы. Так называемая - программная (а если это на FPGA или многоядерных CPU) аппаратная избыточность типа Lockstep / TMR.
Как все начиналось
Чтоб сделать ПЛК который поддерживает много языков и функций (например - замена участков кода на лету и прочее) нужен собственный рантайм и компилятор который будет переводить любые языки ( LD FBD ST) в собственные инструкции. Первая версия моего компилятора давала сбой - то одно не верно посчитает, то другое. Я столкнулся "паразитными" смещениями по адресам, а точнее - в сложных местах программа могла не туда перейти, не то прочитать или не туда записать. Программа слетала, и не понятно в каком месте была ошибка - так как при тихом повреждении данных (silent corruption), и физическим вылетом могло пройти много времени, - замучаешься пошагово следить в отладке.
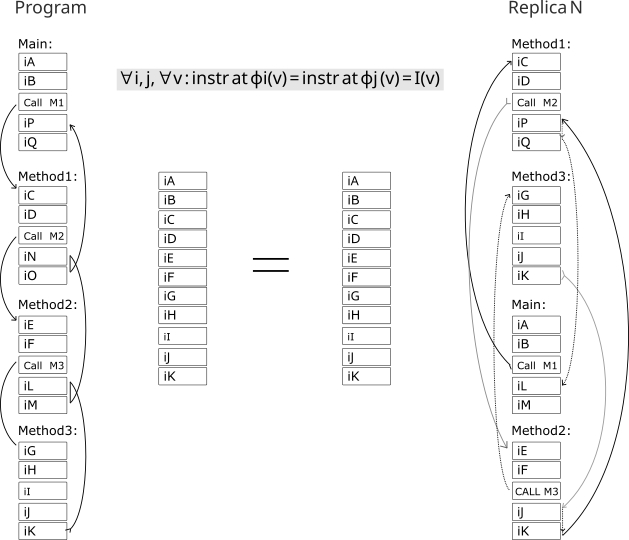
Структурная декорреляция адресного пространства копий одной программы.
Тут я подумал, а что если компилировать одну и ту же программу - два раза? Но вторую копию - перемешивать адреса функциям, блокам, переменным чтоб аналогичные по названиям переменные и функции второго экземпляра были не на том месте как в первой компиляции. Если компилятор все верно считает, нет никаких паразитных смещений, то каждая инструкция будет совпадать во всех копиях. Адреса у них хоть будут разные, но ход программы будет логически идентичен (смотри рисунок выше). А если адрес не верно просчитан - то в каждой копии программа запишет/прочитает или перейдет в логически разные - места. Тем самым детекция ошибки произойдет сразу.
Так и было, - две компиляции но разные структурно в памяти - все паразитные смещения из за бага компилятора - всплывали сразу. Так называемые silent corruption (скрытые ошибки) - стали наблюдаемы. Это позволило точно отточить алгоритмы просчета адресов, и больше компилятор не ошибался. Ну а дальше вы знаете: писал посты, тестировал разные микроконтроллеры как ПЛК.
Тогда я даже сам не понял что я придумал, и широкие возможности применения своего метода DME.
Отказоустойчивые системы
Сделал свой комплекс разработки ПЛК : среда разработки, компилятор, и среда выполнения на железе. Задумался об отказоустойчивости, и познакомился с существующими подходами:
Lockstep - две копии (одинаковые бинарники) программы на двух процессорах работают и сверяют друг друга на каждом шаге.
TMR - три копии (одинаковые бинарники) программы на трех процессорах. Если одна отличается, происходит голосование , кто не прав и работа выполняется дальше.
Оба метода применяются в авиации, атомной энергетике и прочее. Стандарт.
Все хорошо, да только вот Lockstep и TMR - уязвимы к коррелированным сбоям. Методы эффективны только если система замечает разницу между копиями программы, сигналит об этом. Но если оба ядра ошибаются - система не заметит ошибки, и продолжит выполнять ошибочную программу.
И тут я заметил, мой метод с деккореляцией адресного пространства который я применял в отлаживании компилятора - решает эту задачу!
Если система Lockstep и TMR "одинаковость" воспринимают как ОК, мой метод наоборот - одинаковость воспринимает как как - осторожность. А разность - как нормальную работу. Но у моего метода есть два типа разности:
Допустимая разность - это адреса (адреса функций, счетчика команд, переменных и т.д).
Не допустимая разность - в последовательности инструкций ( семантика ).
То есть, в системах Lockstep и TMR сводится к 1/2 :
Либо одна из копий программы ведет себя по другому - это ошибка.
Либо ведут себя одинаково - значит все хорошо. Но тут и проблема одинаковых бинарников, если все копии выполняются одинаково не верно, система будет думать что все хорошо.
В моем методе DME, соотношение 1/3 . Где:
одинаковая логика/инструкции - это Хорошо.
одинаковость адресов -Плохо.
разная логика/инструкции - Плохо.
Я сделал более узким коридор для корректности , и расширил коридор для прохождения ошибок (усилил ошибку).
Lockstep и TMR - совсем не ловят программные ошибки. Если в компиляторе есть специфический баг из за оптимизации или просто программа так написана - это не покрывается. Копии идентичны и поведут себя одинаково , а значит система не заметит. Проблему решают N-Version Programming - когда нанимают две группы программистов, и они пишут программу по разным вариантам (Airbus/Boeing). Очень дорогое, и медленное удовольствие. В общем не для ПЛК за 30$.
В нашем методе DME , при двойной компиляции и перемешиванием адресов, одинаковый баг программы, компилятора, или ошибки из за физики - обязательно приведет к расхождению (Дивергенции).
Практика
Создаем - тестовый проект в языке LD. Моя среда поддерживает FBD но так же пока только внутри LD. ST язык я не реализовал в полной мере, но на каком бы языке программа ни была, она переводится в единый виртуальный ассемблер (собственный синтаксис и инструкции, см. прошлые посты) который выполняется внутри на голом железе Микроконтроллера, FPGA или любого CPU.
Интерфейс. Тяжелые функциональные блоки внутри LD прекрасно подходят под тесты отказоустойчивости
Несколько выполняющихся копий, на одном дешевом микроконтроллере, от чего может защитить? Против тяжелого поражения питания, это - не защитит(вопрос к аппаратной части), но стать устойчивее к программным ошибкам, радиации или умеренным временным электромагнитным помехам, сильно компенсируя аппаратную часть - получится.
Настройка компиляции в 3o|||sheet:
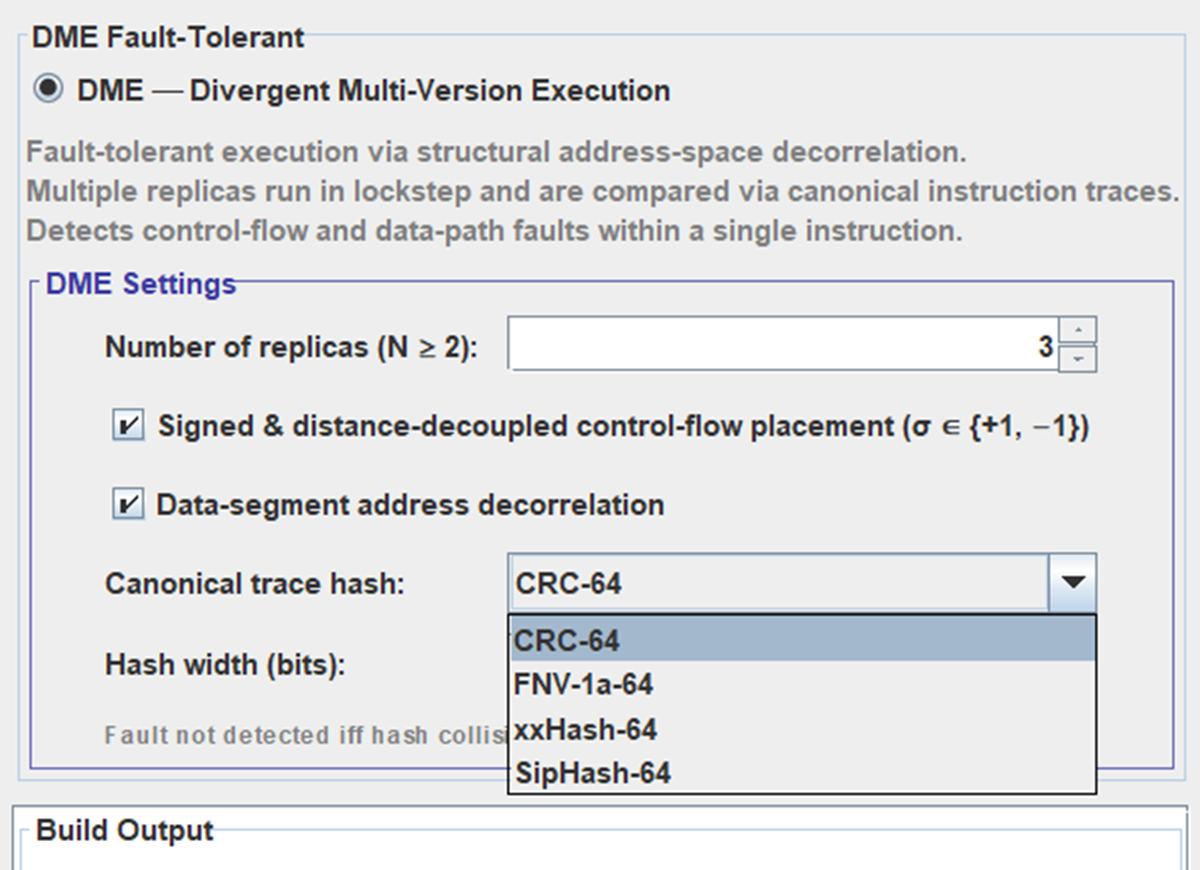
Интерфейс с настройками - компилятору.
N - количество копий программы и количество соответственно компиляций. N Должно соответствовать количеству ядер, или ПЛК если они работают в режиме похожему на Lockstep\TMR. На STM32G030 эти ядра эмулируются, в чем смысл - дальше.
+1 -1 это команда разнесения адресов в разные по знаку стороны. Если в одной копии переход из функции А к функции Б изменяет программный счетчик например PC+=94, то в второй копии компилятор организует этот переход PC-=64. Усиливает декорреляцию адресного пространства, соответственно увеличивает область детектируемых программных багов и программных ошибок из-за физического влияния среды.
Canonical trace hash: Инкрементальный хеш выполнения программы (если есть аппаратный хеш как у Cortex M4) , но на слабом железе вместо хеша может подойти обычное сравнение каждой инструкции (опкода или результата) каждой копии программы простым "=", или хеш может быть банальным XOR с степенью ( за 2 такта, это + 10..20 наносекунд к выполнению инструкции, дешево ).
Тут принцип тот же что и Lockstep\TMR - N копий программы на ядрах, только в Lockstep\TMR сравниваются идентичные бинарники и состояние на каждом такте, у меня только логическая траектория, потому что адреса переменных и инструкций в копиях разные - они (адреса) исключаются из уравнений.
Любая программа, LD ST C++ не важно, состоит из блоков кода и функций. Мой компилятор их и перемешивает по разным адресам и разным знакам (+-) направлениям перехода. Если мы скомпилируем программу, то получим пространственные -разные версии одной программы:
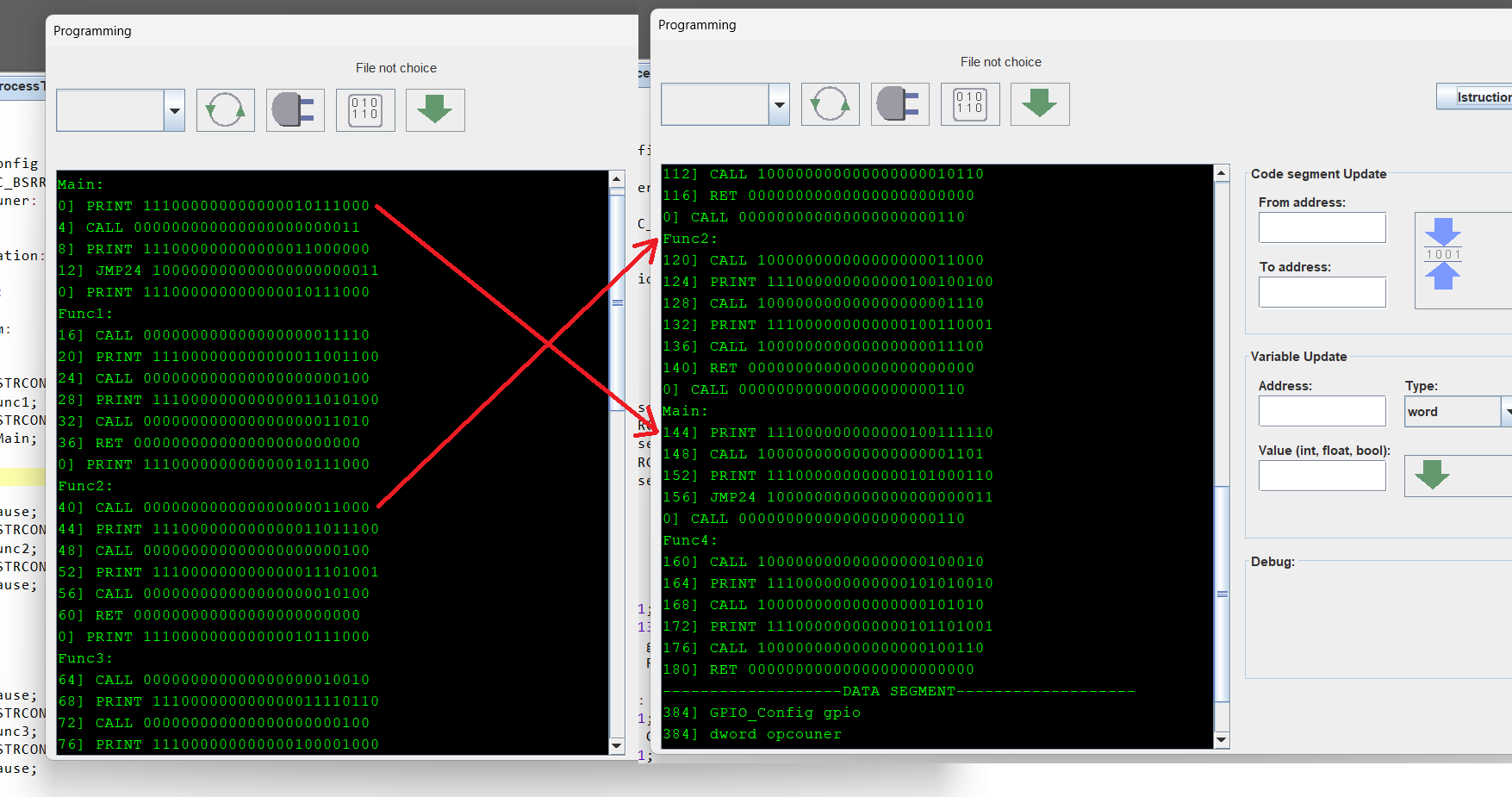
N компиляций, и расположение программы в памяти. Один и тот же блок или функция - по разным адресам.
Если мы присмотримся к адресам функций на скрине, то увидим в одной копии например Main будет по адресу - 0 (ноль) в другой копии она же будет по адресу - 144. Так и со всеми остальными. Выполняется главный принцип DME - усиление ошибки программы через структурную декорреляцию адресного пространства.
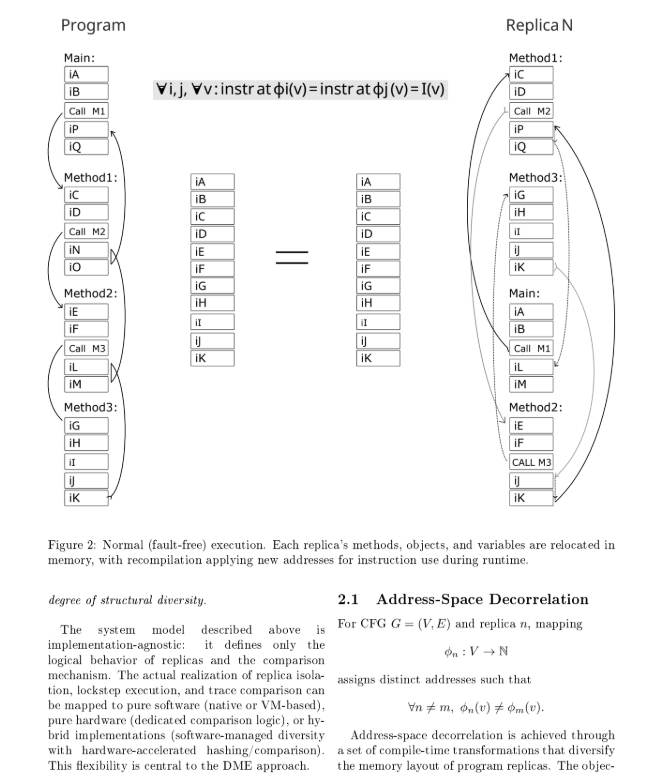
На рисунке видно, несмотря на то что участки кода перемешаны (перемешаны на уровне функций и блоков кода имеется ввиду), и соответственно скомпилированы - траектория программы, логика будет идентичная (в штатном режиме работы).
Теперь, предположим в системе произошел коррелированый сбой, то есть такой который задевает все ядра или все копии программы. Чаще это возможно когда программа криво написана, затерла адрес возврата, или другого участка программы. Проблемы с питанием - тоже может повредить все ядра одинаково. Радиация, или помехи - риск минимален в атмосфере на Земле. В самолете на высоте 10 000м вероятность сильно возрастает, а в космических аппаратах бомбардировка процессоров частицами которые вызывают сбои происходит несколько десятков раз в сутки.
Давайте предположим, что сбой произошел (неважно по какой причине) , адрес возврата или какого либо перехода ветки , установлен в случайное значение 148:
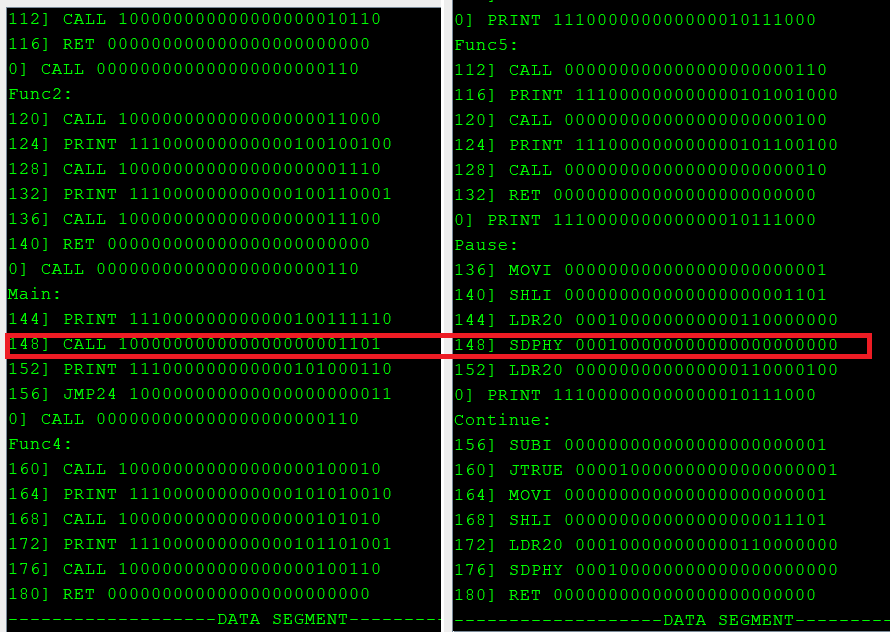
Просмотр результата компиляции в 3o|||sheet. Одна программа - разные адреса ее компонентов.
Был бы это обычный отказоустойчивый ПЛК типа Lockset или TMR за 5000$ , они бы не заметили фатальной ошибки, так как бинарники одинаковы. Система бы увидела у всех копиях одинаковое значение и подумала что все хорошо.
Но наша система декоррелирована по адресам , это вызовет - Дивергенцию. Система фиксирует - две разные инструкции одновременно: CALL и SDPHY. Несовпадение. Компаратор вызовет программу X (типа обработчик ошибки) или осуществит переход в безопасное состояние.
Детекция - сразу, что очень важно, так как обычный ПЛК - слетит с концами и не успеет передать на каком месте авария. Либо вообще может слететь через какое то время долго притворяясь что все хорошо.
Ошибка может быть более сложной, например радиация или электромагнитная помеха может не изменить весь адрес полностью, а только один бит (так называемый bit flip), тем самым добавив к адресу одинаковое - число. То есть, адреса продолжат быть разные, но смещенные на константу. Для этого мой компилятор и делает переходы с разными знаками между функциями и некоторые другие приемы для локальной асимметрии адресов..
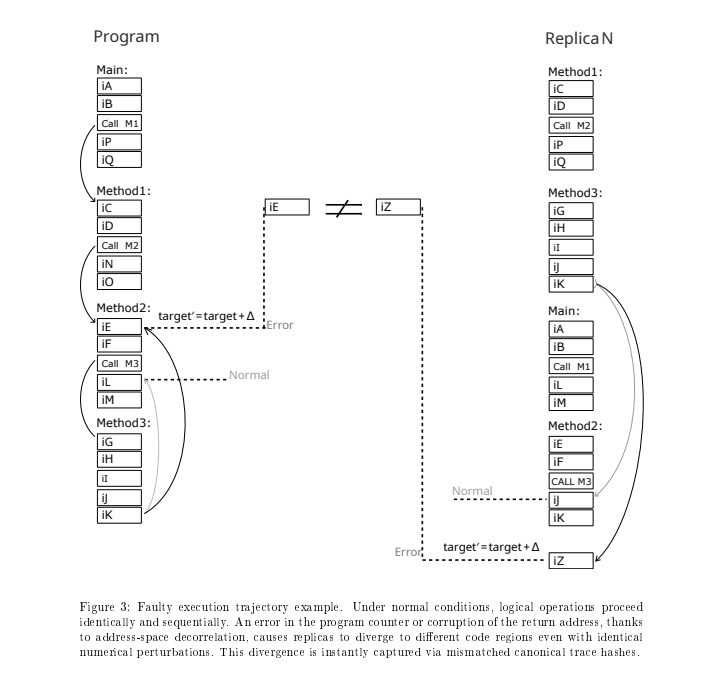
Ошибка из за физических процессов: bit flip может привести к тому что в копиях, адрес изменится на константу. В методе DME это приведет к разным участкам кода, и ошибка будет детектированна.
Codesys, Siemens не имеют компиляторов с декорреляцией адресного пространства, их детекция ошибок сработает только если один ПЛК или ядро и отличаться от другого. А когда оба ошибаются - программа благополучно упадет и до этого может наделать много лишнего.
Что отказоустойчивого можно выжать с дешевого слабого МК STM32G030.
Одноядерный микроконтроллер выглядит полностью беспомощным, но интерпретация байткода в двух копиях сильно улучшает положение.
Time redundancy, EDDI/SWIFT
В моем методе DME, в одноядерной системе инструкции N копий выполняются по очереди псевдо-параллельно, а следовательно, каждая инструкция выполняется N раз и получается с задержкой по времени.
Есть такой метод отказоустойчивости Time redundancy - выполнения идентичных инструкций с задержкой по времени. Вот как это описывается:
Обнаружение ошибок: Программа или расчет выполняется дважды. Если результаты не совпадают, система фиксирует наличие ошибки.
Тип ошибок: Этот метод наиболее эффективен против кратковременных (перемежающихся) сбоев, вызванных внешними помехами (космические лучи, электромагнитные шумы).
EDDI и SWIFT - известные методы дублирования . Все эти Time redundancy, EDDI/SWIFT являются у нас побочным эффектом из псевдопарралельности нашего ПЛК в одноядерной системе. Наш ПЛК с DME перестаёт быть “чисто структурной” DME защитой с перемешанной памятью, а превращается в гибрид:
time redundancy + DME + семантический анализ и контроль данных
Таким образом, DME защищает программу от программных и коррелированных багов, которые не детектируются вообще Codesys, Siemens, а вторичный эффект Time redundancy, EDDI/SWIFT которые вытекают из псевдо-параллельности дает устойчивость к физическим влияниям на систему. И делает наш ПЛК устойчивым к:
Transient faults (SEU, EMI, glitches) одиночный бит-флип в регистре, кратковременный сбой ALU, помеха на шине. Сработает эффект DME , Time redundancy, EDDI/SWIFT.
Control-flow faults (PC corruption, jump errors) повреждение PC, бит-флип в адресе возврата , неправильная ветка. Сработает DME защита.
Memory corruption (stack/heap, out-of-bounds) переполнение буфера, повреждение указателя , повреждение данных в RAM. Сработает DME защита.
Повреждения данных\ переменных (для дешевых микроконтроллеров у которых нет ECC это критично).
Исследователи указывают что метод SWIFT имеет "чрезвычайный широкий охват детектируемых ошибок" , но SWIFT требует наличие в памяти коррекции ошибок ECC, которого нет в простых микроконтроллерах. Да и ECC поможет только если фзика изменила только один бит, если изменены несколько бит, ECC (а значит и SWIFT ) бессилен, потому что не восстановит данные. А еще, SWIFT в отличии от моего метода DME - не видит ложные переходы программы.
Понятно что никто не вставит дешевый микроконтроллер в управление атомной станцией. Но в космический аппарат, или в другую агрессивную среду - слабые но энергоэффективные микроконтроллеры - подходящее место. Уверен много кому пригодится ПЛК с повышенной отказоустойчивостью за дешево.
Производительность ПЛК на STM32G030 в режиме отказоустойчивости
У моего метода DME конечно есть недостатки (если он работает на одном ядре) . Дублирование программы на N реплик соответственно замедляет ПЛК в N раз.
Как то видел в домашних производителей ПЛК, STM32G030 использовался просто как микроконтроллер для модулей расширения вводов\выводов . А ведь этот Микроконтроллер производительнее ПК на i486 1992-1994 годов, и гораздо производительнее наверное чем вся электроника корабля летавшего на Луну.

Altera Cyclone |V EP4CE6E22C8, STM32F722, STM32G030C8
Скорость выполнения базовых логических операций в микросекундах:
Mitsubishi (китайский клон) STM32F103------------------------------------2.7---------------математика int 8.6
Allen Bradley Micro 810 -----------------------------------------------------------------2.5---------------математика int 8.5
Siemens LOGO!------------------------------------------------------------------------------ 5.0
Schneider Electric Zelio Logic --------------------------------------------------------10.
====================================3o|||sheet==================================
3o|||sheet STM32G030 (N=2) отказоустойчивый режим---------- 4.5 --------математика int 13.5
3o|||sheet STM32F407(N=2) отказоустойчивый режим------------ 2.1 --математика int/float5.2
3o|||sheet STM32F722(N=2) отказоустойчивый режим-------------0.9 --математика int/float2.3
3o|||sheet Cyclone |V 50 MHz (N=2) отказоустойчивый режим-- 0.1 ---------математика int 0.1
Наш ПЛК, название не придумал , пишу с названия среды моей разработки 3o|||sheet.
В режиме отказоустойчивости, с циклом 10 миллисекунд, наш ПЛК 3o|||sheet STM32G030 отработает примерно 1100 операций: 550 - логические (контакты катушки) + 550 математические. Если брать ST, то математика и булевые операции так и остаются, а каждое условие типа if(a== > < ! b) займет в памяти и по времени выполнения - максимум как две логические операции (в зависимости от "регистрового давления", насколько далеко a, b в программе использовались до этого).
Я бы не сказал что это мало от микроконтроллера который другие компании ставят просто в качестве расширяющего вводы выводы. В этом отказоустойчивом режиме он производительнее обычных программируемых реле Siemens и Schneider .
Какие MCU в реле Siemens и Schneider неизвестно, может и 16 МГц ( в нашем STM32G030 64 MHz) , я только констатирую факт.
3o|||sheet STM32F722х - вытянет в быстрых (по меркам промышленности) ПИД регуляторах в режиме отказоустойчивости.
Altera Cyclone |V EP4CE6E22C8 даже на 50 МНz , в отказоустойчивом режиме, показывает впечатляющий результат, в цикле 1 миллисекунды отработает 8000 логических или математических (целочисленных) операций. .
Часто пишут что - главное не скорость, а надежность. Но чем быстрее выполнение инструкций, тем меньше можно сделать цикл, или тем сложнее программу можно втиснуть в один цикл.
Вернемся к отказоустойчивости. Интерпретируемость байткода дает серьезный отказоустойчивый эффект:
..........................<----- 15 Нативных инструкций ----->
15 тактов : П_П_П_П_П_П__X___П_П_П_П_П_П_П_П
...................<-------1 виртуальная инструкция------->
15 тактов: П_П_П_П_П_П_П_П_П_П__X__П_П_П_П_
Если из за физического воздействия в месте X Нативных инструкций что то произошло в потоке программы, в нативном уровне где каждый такт это аппаратная инструкция - сразу может привести к вылету системы или серьезным последствиям.
В то время, 1 виртуальная инструкция "размазана" по нескольким десяткам или сотням тактов, и состоит соответственно из десятков нативных инструкций. Есть проигрыш в скорости, но воздействие в месте X изменит только логику самой инструкции (например 2+2 станет = 5, и переход на ветку В вместо А) но не повредит программу в целом. А так как у нас еще работает вторая копия программы , наш метод DME - зафиксирует и проконтролирует ошибку.
Из за дополнительного рантайма (например моего 3o|||sheet) память программ увеличивается на 45-50 килобайт, в отличии от программы которая допустим написана на СИ, и с точки зрения вероятности - возрастает событие из за помех которое что то подпортит внутри процессора.
Но, если и подпортит, то последствия не такие катастрофичные как если физика подпортит - нативный код, без контекста рантайма. Потому что "логическая плотность" нативного кода сильно ужата. Как петарда которая при взрыве разбросает плотно стоящие спичечные коробки (логику) возле эпицентра, но имеет меньше влияния если эти коробки далеко друг от друга и по площади дальше от эпицентра. Что то зацепит и упадет, но разрушимость логики не та, потому что 1 виртуальная инструкция, ее логика состоит из десятков нативных инструкций, а результат ее - всего лишь - одно число в конце, и его ошибочность будет замечено дальше.
А чем твой ПЛК отличается от других. Или про изобретения велосипедов.
Это частый вопрос гастролирующего читателя. Вот в каждом комментарии есть такое.
Во первых, китайцев существующие немецкие велосипеды Codesys, Siemens не останавливали, китайцы начали делать свои ПЛК (наверно разработчикам в Китае трудно было всем отвечать, зачем делать ПЛК создавая велосипеды, если уже были готовые где то в Германии).
Что касается домашних существующих конкурентов - то в плане отказоустойчивости я вообще не вижу ни в одной компании ничего особого - обычные ставки на резервирование со всеми вытекающими. В самолет я б лучше сел в котором установлен - мой ПЛК, чем чей то.
Извиняюсь за нескромность, но я не вижу себе конкурентов по инновациям в этом направлении, в первую очередь среди местных производителей. Я видел их сертификаты SIL3 SIL4 , но вряд ли там что то новое чем Lockstep/ TMR.
У меня проработан, конкретный , особенный, нигде ранее не встречающийся метод DME.
Во вторых - в Beremiz , китайских клонах Mitsubishi, и прочих дешевых ПЛК до 100$ ( а может и до 500$) близко нет никакой отказоустойчивости.
Устойчивость к коррелированным сбоям - вообще ни один ПЛК ни одного мирового бренда не имеет , в мире этот вопрос решается - дорогими специальными CPU - разнесением ядер на кристалле максимально удаленно друг от друга. Или N Variant Programming с разными группами программистов. Мой метод первый решает эту задачу структурно/программно (то есть - дешево).
В следующий раз расскажу часть моего метода DME "Periodic Layout Diversity" , который призван бороться с малыми глюками потока программ, тот самый Periodic Layout Diversity , когда из за внешнего воздействия может быть пропуск инструкции или несколько инструкций. Ни одна система в мире такое не детектирует, а это критично если в ПИД регуляторе или каком то автомате будет пропуск команды.
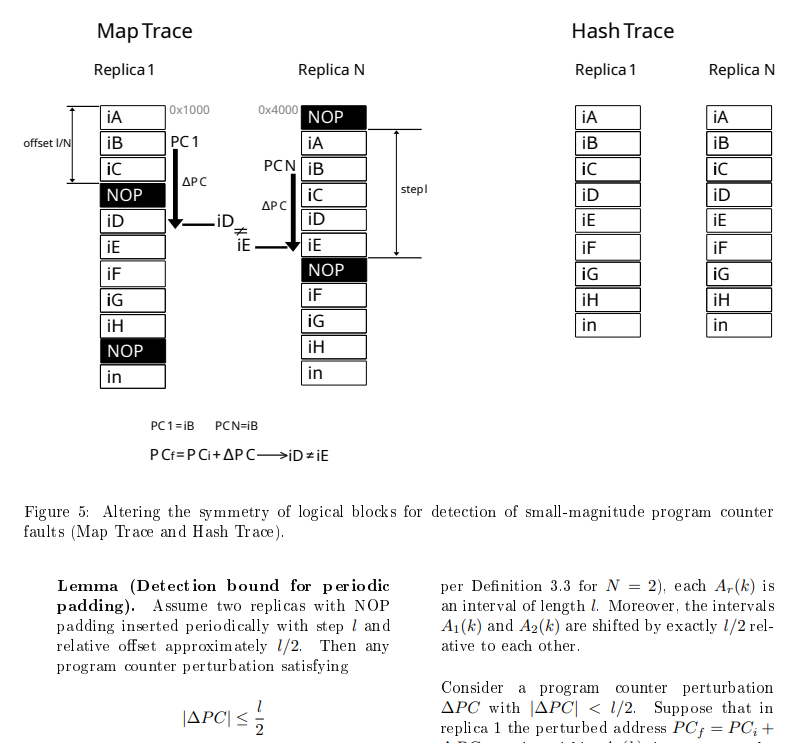
Внесение малой асимметрии адресов в критические участки кода, для гарантированной наблюдаемости ошибки в случае возникновения
В ней четко прописана математика. Больше всего у меня претензии к мировым и домашним брендам, по - доказательствам надежности. У них это - тесты в лабораториях, которые не факт что будут соответствовать на 100% рабочей обстановке. Я подошел к вопросу - математически, что кстати дешевле и легче для сертификации так как легче доказать надежность.
Мой метод DME , гарантирует математически - либо код отработает корректно, либо сразу остановится и контролировано перейдет в безопасное состояние. Но никакого неопределенного поведения.
Еще вопросы можно задавать в комментариях и на почту zoshytlogic@gmail.com
Arduino & Pi
1.5K пост20.9K подписчиков
Правила сообщества
В нашем сообществе запрещается:
• Добавлять посты не относящиеся к тематике сообщества, либо не несущие какой-либо полезной нагрузки (флуд)
• Задавать очевидные вопросы в виде постов, не воспользовавшись перед этим поиском
• Выкладывать код прямо в посте - используйте для этого сервисы ideone.com, gist.github.com или схожие ресурсы (pastebin запрещен)
• Рассуждать на темы политики
• Нарушать установленные правила Пикабу