Как и многие усталые мужчины чуть за сорок, я не очень хорошо представлял себе, кто такая Виктория Боня, и какое место она занимает в символическом пространстве современного российского общества. Но именно это незнание и оказалось методологически полезным: оно позволяет смотреть на данный кейс не через содержание высказывания, а как на почти чистую коммуникационную конструкцию. И в таком ракурсе вопрос заключается не в том, что именно было сказано, а в том «почему именно этот коммуникатор, почему в такой форме, по таким каналам и с таким последующим резонансом». Иными словами, перед нами удобный объект для анализа в терминах формальных моделей массовой коммуникации.
Уже базовая модель коммуникации Лассуэлла, разработанная в 40-е годы 20 века, определяет важнейшие аспекты информационного процесса: «кто говорит, что говорит, по какому каналу, кому и с каким эффектом». Ее сила именно в том, что она заставляет анализировать не только содержание сообщения, но и архитектуру воздействия.
Если кратко проследить развитие моделей массовой коммуникации, то видно, как усложнялось понимание самого механизма влияния. Линейные модели, прежде всего Лассуэлла и Шеннона-Уивера, рассматривали коммуникацию как направленную передачу сигнала от источника к получателю через зашумленный канал. Затем появились модели, учитывающие обратную связь, например модель Дефлюера: сообщение не просто передается, но постоянно корректируется по реакции аудитории, а значит коммуникация становится не актом, а циклом. Осгуд и Шрамм показали циркулярную природу процесса: участники одновременно кодируют, декодируют и интерпретируют сообщения. Наконец, Уэстли и Маклин включили в модель посредников, селекцию сообщений и конкуренцию каналов, то есть приблизили теорию к реальной медиасреде, где между источником и массовой аудиторией всегда есть отбор, редактура, усиление и трансформация сигнала
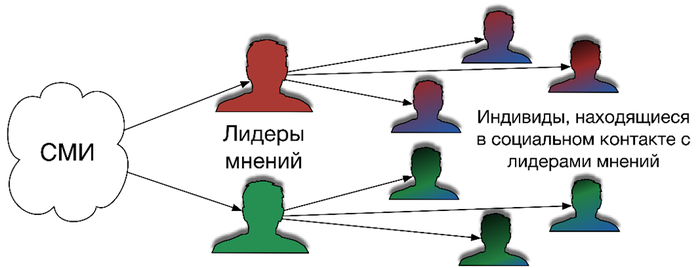
Однако в нашем случае особенно интересной становятся две следующие модели. Лазарсфельд предложил двуступенчатую модель коммуникации, которая учитывала, что сообщение редко идет напрямую от источника к массе, сначала оно проходит через лидеров мнений, интерпретаторов, медиапосредников, и только после этого попадает в широкую аудиторию
Двуступенчатая модель коммуникации Лазарсфельда
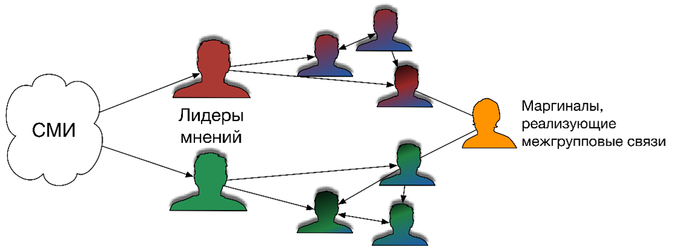
В цифровую эпоху эта схема усложнилась до многоступенчатой модели (Робинсон и др.): теперь между событием и массовым восприятием стоят не один-два посредника, а целые каскады ретрансляторов – блогеры, телеграм-каналы, редакции, комментаторы, алгоритмические рекомендации платформ .
Многоступенчатая модель коммуникации
В подобных случаях ключевой вопрос не в том, убедительно ли и достоверно ли исходное сообщение само по себе, а в том, насколько удачно выбран первый носитель сигнала, и насколько легко этот сигнал подхватывается следующими ступенями. В этом смысле фигура медийной личности с высокой узнаваемостью, но спорным символическим статусом, оказывается не слабостью, а технологическим преимуществом: она гарантирует внимание, провоцирует поляризацию и создает высокий коэффициент вторичной передачи сообщения.
Многократно подтвержденная и проверенная, в том числе мной самим в ходе диссертационных исследований теория слабых связей Грановеттера показывает, что значимая информация часто распространяется не по плотным, устойчивым сообществам, а через слабые мосты между разными аудиториями (т.н. «маргиналы» в терминах теории). Именно такие фигуры, находящиеся на границе между медиа, шоу-бизнесом, светской хроникой, политическим шумом и массовой цифровой аудиторией, могут служить эффективными «переносчиками» сигнала между слабо связанными сегментами общества. Если добавить к изложенному эпидемические модели распространения информации, то картина становится еще яснее: для вирусного охвата нужен не обязательно самый авторитетный источник, а источник с высокой «вирулентностью», то есть способный вызвать быстрое воспроизведение, комментирование, осуждение, иронизацию и повторную публикацию. В информационной среде негативная реакция ничем не хуже позитивной. И та, и другая работают как механизм репликации.
Сам по себе этот «кейс Виктории Бони» не доказывает наличие централизованной операции, и без дополнительных данных говорить о конкретном заказчике было бы научно некорректно. Но как коммуникационная технология он выглядит вполне осмысленно. Его программируемые шаги читаются достаточно ясно: выбор медиатора с высокой узнаваемостью и низким порогом входа для массового внимания, запуск эмоционально заряженного обращения, расчет на быстрое вторичное распространение через медиапосредников, перевод содержания в режим общественного шума, где важнее не аргумент, а сам факт циркуляции, затем считывание обратной связи и, возможно, дальнейшая подстройка рамки обсуждения.
В качестве краткого резюме стоит еще раз подчеркнуть: в процессах массовой коммуникации общественно значимую роль часто играет не «центральная» фигура, а фигура пограничная, полу-маргинальная в символическом смысле – та, которую невозможно до конца встроить ни в экспертный, ни в политический, ни в развлекательный регистр. Маргинал в коммуникации полезен не вопреки своей неоднозначности, а благодаря ей: он снижает требования к доказательности, но повышает скорость распространения информации по социальному графу. И, если судить по самому факту общественного резонанса, то как минимум задача запуска, подхвата и масштабного обсуждения была достигнута.
В прошлой заметке (тут) я пытался нагнать ужаса, чтобы показать, что технологии искусственного интеллекта в последние годы развиваются исключительно стремительно. И три кита, на которых это развитие зиждется - это:
Развитие аппаратных средств. В первую очередь - графических ускорителей (видеокарт). Недаром Nvidia, которая продает связку из видеокарт и софта к ним, уверенно идет к статусу самой дорогой компании мира (сейчас, по разным оценкам, она на 3 или даже на 2-м месте). Сила GPU - в способности распараллеливать вычисления, а это как раз то, что нужно нейронным сетям. Раньше работа с таким оборудованием была доступна гиками из пары десятков государственных и частных компаний по всему миру, сейчас - любому школьнику с игровым компом.
Совершенствование алгоритмов обучения и оптимизации. Первые, базовые алгоритмы обучения нейросетей появились еще в 70-е годы. Например, то же алгоритм обратного распространения ошибки, который остается базовым для обучения нейросетей до сих пор, впервые был представлен в статье 1974 года - 50 лет назад! Но более тонкие, продвинутые и эффективные алгоритмы появились совсем недавно и продолжают появляться. Причем во многом это стало возможным именно благодаря повышению доступности графических ускорителей. Больше исследователей - больше разнообразных попыток, больше практических результатов, значительная часть которых, кстати, не имеет под собой глубокого основания. Франсуа Шолле - один из ведущих разработчиков популярного нейросетевого фреймворка TensorFlow, признается в одной из книг: "...машинное и в особенности глубокое обучение не имеют мощной математической платформы и основываются почти исключительно на инженерных решениях. Это практическая дисциплина, в которой идеи чаще доказываются эмпирически, а не теоретически".
Появление Интернета и порожденных им наборов данных для обучения нейросетей (тексты, изображения, видео). Каждый раз, когда проходите капчу, выбирая на картинке все светофоры и велосипеды, вы участвуете в священном процессе разметки данных, помогая обучать систему машинного зрения.
Здорово! Но что же все-таки не дает искусственному интеллекту убить всех человеков стать по-настоящему "сильным" и приобрести все атрибуты человеческого сознания?
Судя по-всему, таким ограничителем является сама природа компьютеров, подчиняющаяся принципам Тьюринга, и теорема Курта Гёделя о неполноте. Давайте по порядку.
Вообще, современные взгляды на моделирование сознания могут быть сведены к четырем парадигмам:
A. Всякое мышление есть вычисление. В частности, ощущение осмысленного осознания есть не что иное, как результат выполнения соответствующего вычисления. B. Cознание представляет собой характерное проявление физической активности мозга. Хотя любую физическую активность можно моделировать посредством той или иной совокупности вычислений, численное моделирование как таковое не способно вызвать осознание. C. Cознание является результатом соответствующей физической активности мозга, однако эту физическую активность невозможно должным образом смоделировать вычислительными средствами. D. Cознание невозможно объяснить в физических, математических и вообще научных терминах.
Сразу отбросим агностическую точку зрения D разу как не соответствующую научному мировоззрению и посмотрим на оставшиеся три, причем особенно пристально - на первую из них. По сути, все наши попытки создать сильный искусственный интеллект к настоящему времени являются вариантами реализации парадигмы А. Она предполагает, что, если придумать достаточно сложный алгоритм, мы сможем воспроизвести любой аспект человеческого сознания. Вот тут на сцену и выходит троица персонажей: Черч, Тьюринг и Гёдель.
Первые двое заложили математическую основу работы всех без исключения современных вычислительных устройств в виде тезиса Черча (или тезиса Черча-Тьюринга). В первоначальной форме, предложенной американским логиком Алонзо Черчем в 1936 году, этот тезис гласил, что любой процесc, который можно корректно назвать «чисто механическим» математическим процессом, — т.е. любой алгоритмический процесс — может быть реализован в рамках конкретной схемы, открытой самим Черчем и названной им лямбда-исчислением (λ-исчислением). То есть существует математическая система, которая позволяет описать любой алгоритм. А машина Тьюринга, которая является описанием абстрактного компьютера, гарантированно реализует этот алгоритм, выполняя наборы простых действий (считать данные из ячейки памяти, выполнить инструкцию, переместиться к другой ячейке, записать новые данные и т.д.). И все это очень строго, формально и доказательно. Прекрасно. Остается открыть или описать достаточно сложные алгоритмы для всех функций нашего сознания и подсознания. Да, обращу Ваше внимание еще на одну важную деталь: алгоритм должен решить задачу за конечное число шагов. Если в результате выполнения алгоритма мы уходим в бесконечный цикл или бесконечную рекурсию (компьютер "зависает"), такое решение алгоритмом не является.
Так вот, Курт Гёдель, доказав свою "Теорему о неполноте", поставил всех перед крайне неудобным фактом: любая формальная теория либо неполна, либо противоречива.
Но Черч создал теорию, обладающую полнотой! Именно это позволяет ей описать любой алгоритм. А Гёдель утверждает, что если ваша теория полна, то она неизбежно противоречива, то есть содержит утверждения, которые нельзя ни доказать, ни опровергнуть средствами самой этой теории (Sic!). Причем таких утверждений может быть бесконечное количество. Есть много следствий из этого неприятного факта. Например, можно сказать, что любая теория содержит проблемы, которые не могут быть решены в рамках самой теории и требуют её обобщения, "надстройки" новых правил. Но фокус заключается в том, что как только мы делаем эту нажстройку, в ней тут же появляются новые недоказуемые и неразрешимые проблемы. Прямо "Уловка-22".
На бытовом уровне это означает, что тьюринговскому компьютеру всегда можно поставить задачу, которую он не сможет решить, не уходя в бесконечный перебор, поскольку не сможет ни подтвердить, ни опровергнуть некоторое утверждение. Приведем такой пример. Дадим компьютеру задачу: "Найди два натуральных числа, сумма квадратов которых является отрицательным числом". Если не давать компьютеру готовое знание о том, что это невозможно (сумма квадратов не может быть отрицательной), то он вынужден будет следовать простому алгоритму: взять число, возвести в квадрат, взять второе, тоже возвести в квадрат, сложить. Проверить, является ли сумма числом меньше нуля. Нет? Попробовать другую пару цифр. И еще. И еще. Поскольку множество натуральных чисел не является конечным, этот перебор никогда не закончится. У компьютера не будет оснований для останова. Иными словами, даже такая простая задача алгоритимически невычислима! И тут не спасет ни наращивание вычислительных мощностей, ни новое усложнение формальной теории.
И самое вот самым важным для нас в контексте рассматриваемой проблемы является следующее следствие из Теоремы Геделя: нельзя создать такую формальную систему логически обоснованных математических правил, доказательства которой было бы достаточно, хотя бы в принципе, для доказательства всех истинных теорем элементарной арифметики.
То есть способность человека к пониманию и постижению сути вещей невозможно свести к какому бы то ни было набору вычислительных правил. Иными словами, нельзя создать такую систему правил, которая оказалась бы достаточной для доказательства даже тех арифметических положений, истинность которых, в принципе, доступна для человека с его интуицией и способностью к пониманию, а это означает, что человеческие интуицию и понимание невозможно свести вообще к какому бы то ни было набору правил.
Приехали.
Помните советский фильм "Отроки во вселенной"?. Вот в этом эпизоде показан блестящий пример боевого применения теоремы Гёделя против киборгов, построенных на баз тьюринговской машины (не удивлюсь, кстати если окажется, что в числе научных консультантов был математик, подсказавший такую вот идею).
Для дополнительной иллюстрации отсутствия кaкoгo бы то ни было реальноrо понимания у современных компьютеров рассмотрим исходную шахматную позиuию, приведенную на схеме:
Начальная расстановка фигур в шахматной задаче, неверно решенной суперкомпьютером Deep Thought:
Любому человеку, знакомому с правилами шахматной игры, понятно, что в этой позиции черные имеют существенное преимущество по фигyрам в виде двух ладьей и слона. И все же белые легко избегают поражения, просто делая ходы королем на своей стороне доски. Стена из пешек для черных фигyр непреодолима, и черные ладьи или слон не представляют для белых никакой опасности, если бесконечно делать ходы королем. Но для компьютера недоступно понятие бесконечности, он может лишь просчитывать большое количество комбинаций, ограниченное доступным временем и его вычислительной мощностью. Поэтому когда эту позицию (белые начинают) предложили компьютеру «Deep Thought» — самому мощному на то время (1990-е годы) шахматному компьютеру, имеющему в своем активе несколько побед над гроссмейстерами-людьми, он тут же совершил грубейшую ошибку, взяв пешкой черную ладью, что разрушило заслон из пешек и поставило белых в безнадежно проигрышное положение:
Ход суперкомпьютера Deep Thought
Человек понимает стратегию выигрыша, оперируя понятием "бесконечность", компьютер же перебором просчитывает лучший вариант в конечном пространстве возможностей.
Нобелевский лауреат Роджер Пенроуз в своих книгах "Тени разума" и "Новый ум короля" неоднократно приводит примеры наличия неалгоритмической составляющей в нашем мозге. Он детально рассматривает точки зрения B и С,при этом приводит весьма убедительные доводы в пользу точки зрения C, которая предполагает, что обладающий сознанием мозг функционирует таким образом, что его активность не поддается никакому из известных нам типов численного моделирования. Основой сознания по Пенроузу выступают квантовые процессы, происходящие в нанотрубках мозга. Теория настолько же интересная, насколько и спорная. Однако запомним ключевой термин - квантовые процессы. Именно они (если верить сэру Роджеру) помогают нам приходить к решению скачкообразно, дискретно, схлопывая волновую функцию вероятности.
Ну хорошо. Гёдель выстроил неразрушимую стену на пути появления истинно мыслящих машин, работающих по заветам Черча и Тьюринга. Однако данное фундаментальное ограничение вовсе не означает, что отдельные аспекты сознания совершенно невозможно моделировать. Что же заставляет думать таким образом?
Ряд выдающихся ученых и мыслителей, начиная с античных времен, выдвигали предположения о материальности духовного мира и происходящих в нем процессов. Так, например, для Фрейда ментальные процессы не менее реальны, чем физические и химические процессы. Идеи, желания, чувства, эмоции, переживания взаимодействуют друг с другом подобно тому, как взаимодействуют физические тела:
Я, следовательно, подтвердил, что забытые воспоминания не исчезли. Больной владел еще этими воспоминаниями, и они готовы были вступить в ассоциативную связь с тем, что он знает, но какая-то сила препятствовала тому, чтобы они сделались сознательными, и заставляла их оставаться бессознательными. Существование такой силы можно было принять совершенно уверенно, так как чувствовалось соответствующее ей напряжение, когда стараешься в противовес ей бессознательные воспоминания привести в сознание больного. Чувствовалась сила, которая поддерживала болезненное состояние, а именно — сопротивление больного.
Лауреат нобелевской премии и один из основоположников квантовой физики Вольфганг Паули был сторонником идеи о том, что:
В будущей науке реальность не будет ни ментальной, ни физической, а каким-то образом обеими из них сразу, и в то же время ни той или другой по отдельности …Наиболее важная и в высшей степени сложная задача нашего времени – заложить новую идею реальности…И самое оптимальное, если бы физика и душа представлялись как комплементарные аспекты.
Кстати, Паули снились сны. Странные, необычные, сны, наполненные архетипичными образами. Настолько странные и необычные, что их анализ лег в основы теории...Карла Густава Юнга, для которого Паули был не только пациентом, но и близким другом. Воистину, история науки порой закручена сильнее детектива.
Великий русский ученый В.М. Бехтерев (кстати, уроженец Елабуги, где я сейчас работаю. Еще одно совпадение?) также считал, что мысли являются материальными объектами и представляют собой лишь особый вид энергии:
«Необходимо признать, что все явления мира, включая и внутренние процессы живых существ или проявления «духа», могут и должны быть рассматриваемы как производные одной мировой энергии, в которой потенциально должны содержаться как все известные нам физические энергии, так равно и материальные формы их связанного состояния и, наконец, проявления человеческого духа»
И, наконец, выдающийся физик Макс Тегмарк в марте 2015 года опубликовал статью «Сознание как состояние материи», в которой делается заявка на выстраивание полноценной математической формализации для устройства и работы сознания:
Я предполагаю, что сознание может быть понято как еще одно состояние материи. Точно так же, как существует много типов жидкостей, имеется множество типов сознания
Таким образом, вполне естественно попытаться создать формальную теорию для математического описания взаимодействия в пространстве бессознательного ментальных объектов: идей, ассоциаций, мыслей.
Для этого "всего лишь" необходимо выбрать соответствующую систему координат и установить законы перехода системы из состояния в состояние. Большинство исследователей во всем мире идут по пути использования для моделирования сознания той же вещественной системы координат, которая использовалась для описания материального макромира. В сотнях лабораторий по всему миру создаются все более и более точные вещественные декартовы карты активации нейронов в головном мозге, однако данный факт практически не приблизил нас к пониманию феномена сознания.
Не исключено, что неудачи в данном направлении обусловлены не вполне корректным выбором математического аппарата для построения формализованной модели сознания. Вполне вероятно, что мы все все это время пытались приспособить для описания сознания "неправильные" числа, не предназначенные для этого самой Вселенной. Оказывается, у наших "привычных" вещественных чисел есть "близнец", который обладает рядом удивительных свойств. Этот близнец известен под именем p-адических чисел (читается "пэ-адические").
Этим числам я постараюсь посвятить следующую публикацию, если будут желающие послушать. Но в качестве спойлера напишу следующее: знаменитая теорема теории чисел — теорема Островского утверждает, что существует всего два варианта задать непрерывное поле (континуум) чисел: либо использовать вещественные числа, либо p-адические.
Но если вещественные числа, как показала практика, не подходят для создания модели сознания, то, в силу теоремы Островского, такая модель может быть только ... p−адической! Здесь уместно привести высказывание одного из известных исследователей биофизики С.В.Козырева:
«Неэффективность математических методов в биологии может быть связана именно с тем, что к биологии пытались применять, как и к физике, методы вещественного анализа, в то время как базовые модели биологии, возможно, должны выражаться на ультраметрическом языке»
Стоит ли удивляться, что эти самые p-адические числа оказались удивительно удобными при описании...квантовых процессов и первыми в практической работе из стали активно использовать физики-теоретики? Помните Пенроуза и его мысль о порождении сознания квантовыми процессами в нано-трубках мозга? Почти мистические подсказки, расставленные тут и там Вселенной, как мне кажется...Причем подсказок этих не одна и не две. И в следующей публикации я постараюсь рассказать об этом подробнее, призвав на помощь Аристотеля и Декарта.
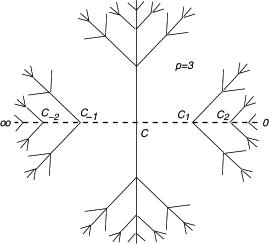
Приветствую всех! Дорогие подписчики, знаю, знаю, мы заходим на Пикабу деградировать и вы ждете от меня продолжения постов про Африку, про Занзибар и прочую экзотику, а не вот это вот все...Но я говорил, что мне тесно в рамках одного амплуа и порой хочется поделиться еще чем-то кроме ооновско-африканских приключений. Все-таки значительная часть жизни отдана науке и конкретно исследованиям в области искусственного интеллекта (ИИ), а также моделирования процессов, происходящих в индивидуальном и групповом сознании. Когнитивные искажения, модели распространения информации в социуме, окна Овертона и прочее. Эта тема крайне интересна тем, что неизменно выводит на самые главные, самые базовые тайны бытия и вечные вопросы, за которыми точная наука незаметно переходит в философию и далее в религию. Я, кстати, как и все мы в быту, до поры посмеивался над философией и ее "бесполезностью", пока на этапе написания докторской не уперся в вопросы и проблемы, по которым технические науки помочь не могли. Но кое-какие пути решения, как я с удивлением обнаружил, уже были намечены философами. Так в технической военной диссертации появились ссылки на Аристотеля, Декарта, Канта, Гегеля и Бодрияра с его симулякрами. И немножко про мировое древо Иггдрасиль, которое оказалось удивительно удобной визуализацией для p-адического континуума чисел.
Это мировой ясень Иггдрасиль. Видите Рататоска? И я не вижу. А он есть )
Одно из представлений p-адического дерева (при p=3), которое, возможно, лежит в основе математического описания нашего мироздания. Похоже на Иггдрасиль?
Эти числа считались бесполезной математической абстракцией с конца 19 века, но внезапно отлично подошли для описания физики субатомных частиц уже в конце века 20-го и, возможно, именно они составляют основу для "правильного" описания сознания человека...Ну да ладно, я увлекся, если эта тема будет кому-то интересна, то обязательно постараюсь написать об этом человеческими словами, без сложных формул.
Чтобы не смешивать темы, я назову эту серию "Околонаучные разговоры". И сегодня хотел бы немного рассказать об искусственном интеллекте. Не проходит дня, чтобы не вышла новость об очередном достижении больших языковых моделей, генеративных сетей или успехах очередной робо-собаки от Boston Dynamics. Тем не менее, далеко не все понимают разницу между терминами "искусственный интеллект", "нейросеть" и "машинное обучение", считая эти понятия тождественными. Это не так. Давайте проведем небольшой ликбез по понятиям.
Определения (Часть 0. Вводная).
Одно из довольно точных на мой взгляд, но скучных определений искусственного интеллекта звучит так:
Искусственный интеллект - это свойство систем, реализованных с использованием аппаратно-алгоритмических решений, выполнять функции, которые традиционно считаются прерогативой человека.
Обратите внимание. Тут ни слова о реальном понимании, о возникновении у машины сознания и осознания своих действий. Только о способности имитировать некоторые возможности человека. Отсюда же еще одно образное, но довольно точное определение: ИИ - это все то, чего еще нет. Иными словами, раньше машина, которая умела играть в шахматы, казалась верхом развития инженерной мысли и считалась "умной". Но сейчас мы вряд ли назовем такую систему поистине интеллектуальной. нам подавай, чтобы машина научилась делать что-то такое, что могут делать только люди. Однако с каждым годом эта планка сдвигается все выше.
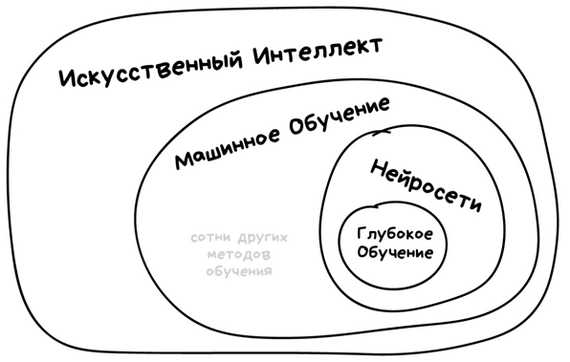
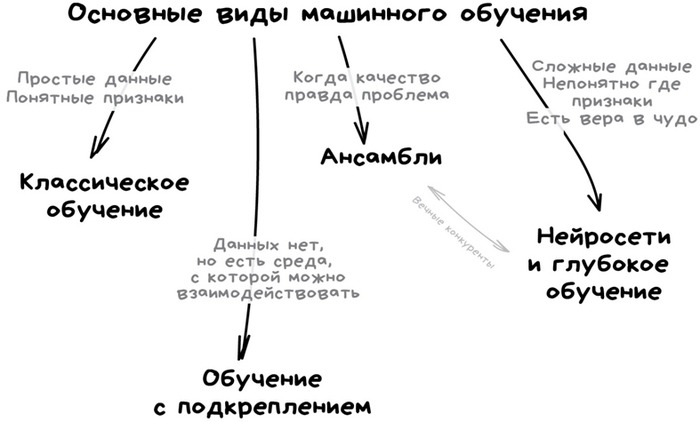
В современном мире практически все достижения искусственного интеллекта базируются на методах машинного обучения. Это важный раздел ИИ, но далеко не единственный.
Отличается от "классического" программирования этот подход тем, что при машинном обучении мы "скармливаем" машине не готовые правила, а только входные данные и правильные ответы (например, картинки кошек и собак с соответствующими подписями-метками: это - кошка, а это - собака). А машина, анализируя различия во входных данных, многократно ошибаясь и подбирая параметры, сама строит для себя правила. Единственное, что мы должны сделать - это дать компьютеру достаточно исходных данных и вычислительных мощностей. Ах, да, и еще, конечно, признаки. При классических подходах мы указываем машине, на какие признаки обращать внимание, сравнивая собак и кошек, например. Такими признаками могут быть контуры, цвет пикселов и т. д. Проблема выбора и описания информативных признаков была настоящей головной болью (да и сейчас остается таковой), но частично была решена за счет появления методов глубокого обучения, речь о которых чуть дальше.
Отличия классического программирования от машинного обучения
Нейронные сети, которые у всех на слуху - это всего лишь один из видов машинного обучения. Хороший, во многом универсальный, но не без своих внутренних проблем.
Видите, нейросети скромно сидят в уголке и не выдают себя за единственную возможность для создания искусственного интеллекта
Так вот, глубокое обучение - это всего-навсего один из подвидов архитектуры нейронных сетей и подходов к их обучению. Главная прелесть глубокого обучения заключается, пожалуй, в том, что он избавляет специалиста от ручного подбора признаков для обучения. Иными словами для построения системы распознавания кошек и собак по фото нам понадобятся только подписанные (правильнее говорить - размеченные) фото. Дальше машина сама решит, какие комбинации пикселов и контуров определяют разницу между этими видами животных.
Чем опасен искусственный интеллект? (Часть 1. Пугающая)
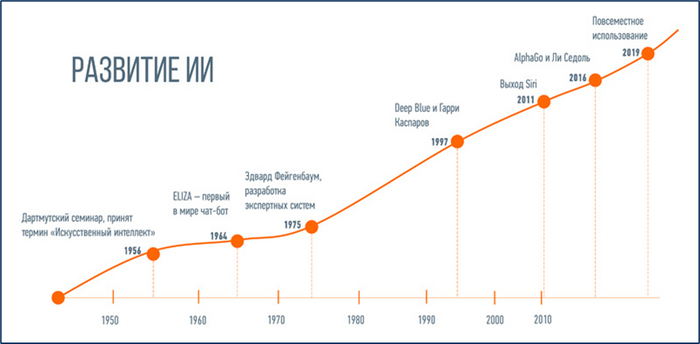
ИИ может многое и развивается довольно стремительно и нелинейно. Очень условно можно представить некоторые основные вехи на вот такой диаграмме.
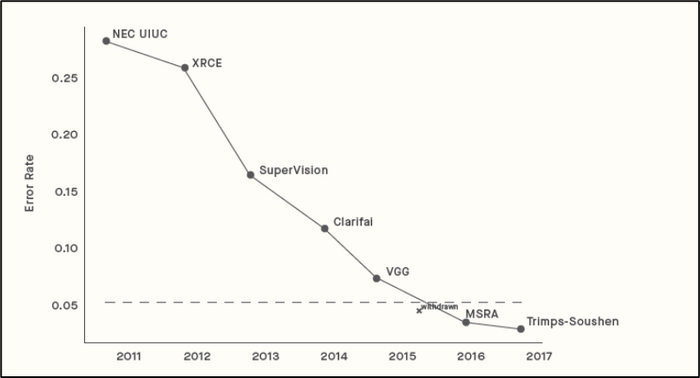
Незаметно по ряду направлений мы подошли к черте (а в некоторых случаях и переступили ее!), за которой ИИ демонстрирует способности, превышающие человеческие. Например, взгляните на график, который показывает, как снижалась доля ошибок распознавания изображений сверточными сетями.
Снижение доли распознавания ошибок изображения сверточными сетями
Штриховой линией отмечен уровень человека (да, мы отлично умеем распознавать изображения). Но примерно в 2015-м году сети обошли нас в этом и продолжают совершенствоваться.
Попутно, обучаясь на миллионах и миллиардах изображений, сети научились улавливать паттерны и генерировать гиперреалистичные фото, неотличимые от настоящих. Посмотрите, каким был прогресс всего за несколько лет:
Сгенерированные нейросетью изображения лиц.
Теперь любой школьник, имеющий базовые знания и доступ к интернету, может сделать практически идеальный дипфейк. Да, пальцы рук зачастую все еще генерятся с ошибками, но это вопрос очень недолгого времени.
Причем речь идет не только о генерации статичных изображений. Уже сегодня, имея всего одну (!) вашу фотографию, злоумышленник вполне может заставить вашу цифровую копию говорить. А если материала много - то и создать виртуального двойника (все еще выкладываете свои рилсы, шортсы и нюдсы в сеть? Тогда ИИ идет за вами!). Для примера я заставил говорить собственную аватарку, которая, естественно, тоже была сгенерирована нейросетью.
Голос использовал свой, но и его подделать совсем несложно, достаточно иметь немного аудиозаписей, например, ваших телефонных разговоров.
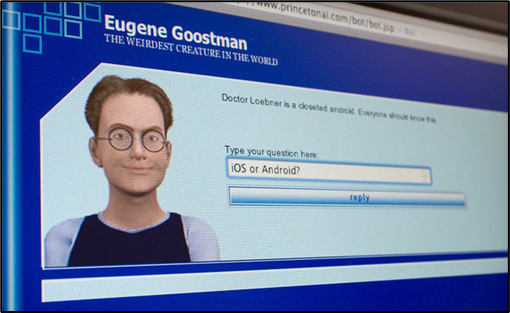
Итак, благодаря успехам машинного обучения, мы окончательно не можем доверять ни тому, что видим в интернете, ни тому, что слышим. Но можем мы хотя бы быть уверены, что за сгенерированным образом скрывается живой человек? Увы, тоже нет. Примерно года с 2014-го, когда, как считается, нейросети впервые прошли полноценный тест Тьюринга. Если очень коротко, Алан Тьюринг в своей статье "Может ли машина мыслить" еще в 1950 году предложил тест, который должен был показать, насколько машина хорошо научилась имитировать человека, задавая ей произвольные вопросы и получая ответы. Если машине удастся ввести судей в заблуждение и убедить, что они общаются с живой личностью, то тест можно считать пройденным. Так вот, в 2014 году чат-бот "Евгений Гусман" прошел тест Тьюринга, убедив 33% судей в том, что он на самом деле 13-летний подросток, любитель конфет и гамбургеров.
С тех пор прошло 10 лет, за которые нейросети многократно улучшили свои результаты. настолько, что мы местами сами перестали понимать, насколько сложными оказываются ассоциативные связи, закодированные в их весовых коэффициентах. Настолько, что 22 марта 2023 года Илон Маск и группа экспертов в области искусственного интеллекта подписали открытое письмо, в котором призвали ввести паузу на период не менее шести месяцев на разработку и обучение больших языковых моделей (LLM), более мощных, чем нашумевшая GPT-4.
Но угрозы нашей с вами безопасности кроются не только в пугающе высокой скорости развития различных веток ИИ. Они прорываются из виртуального мира в физический, поскольку любая система распознавания неизбежно обладает как минимум двумя типами ошибок (т.н. ошибки 1 и 2 рода), которые можно интерпретировать как ложное срабатывание и пропуск цели.
Так, например, в 2018 году автомобиль Uber в беспилотном режиме впервые насмерть сбил человека в США. А в марте 2020 года в Ливии боевой дрон STM Kargu-2 турецкого производства впервые самостоятельно, действуя в автономном режиме, атаковал военнослужащих Ливийской национальной армии, не получив на это явных указаний от оператора. Робот сам принял решение на уничтожение человека.
Вооруженные силы США, недавно признались, что полагаясь на алгоритмы машинного обучения для анализа сетей сотовой связи с целью выявления и последующего уничтожения курьеров террористических организаций на территории Пакистана, уничтожили порядка 15000 невинных человек в силу ошибок 1 рода ("какие претензии, нам компьютер так сказал!").
Американская система анализа трафика. Ошибки ее применения УЖЕ привели к тысячам человеческих жертв. Christian Grothoff, Jens Porup. The NSA’s SKYNET program may be killing thousands of innocent people. Ars Technica, 2016. ffhal-01278193f
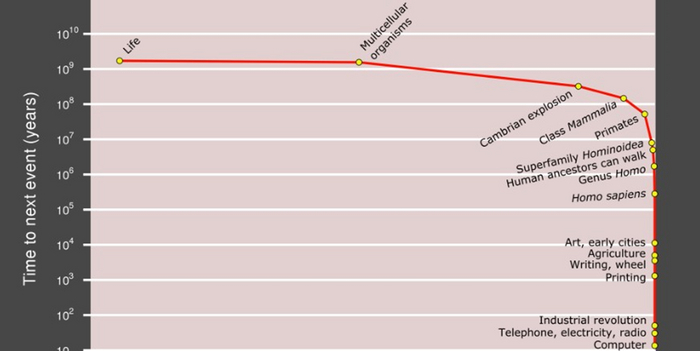
В качестве завершающей картинки на сегодня, покажу вот этот график. На нем по горизонтальной оси отложены некоторые важные вехи в развитии жизни на Земле, а по вертикальной - период времени в годах, который проходил от одной точки до другой. На графике видно, что с появлением человека события начали ускоряться и уплотняться. Биологическая эволюция нашего вида длилась миллионы лет. Первый полет братьев Райт и высадку на Луне застали одни и те же люди. Переход от примитивных искусственных нейросетей - перцептронов Розенблатта до больших языковых моделей произошел еще стремительнее. Конечно, к этому графику тоже есть много вопросов, но если...Но если он верен, это значит, что мы очень близко от так называемой точки технологической сингулярности, в которой события техногенной эволюции ускорятся настолько что мы просто перестанем их контролировать. Дальше развитие пойдет независимо от нас и нашей воли. Некоторые ученые, кстати, считают, что, возможно, это уже произошло.
До технологической сингулярности осталось...три...два...один...
Надеюсь, я не напугал вас окончательно. Потому что у ИИ есть и врожденные слабости. И до тех пор, пока компьютеры работают на принципах Тьюринга, на защите человечества стоит почти мистическая теорема Геделя о неполноте. Почему она не дает создать истинно осознающий себя ИИ и можно ли вообще смоделировать сознание человека, я постараюсь рассказать в следующий раз.