
Искусственный интеллект и чего нам от него ждать
Приветствую всех! Дорогие подписчики, знаю, знаю, мы заходим на Пикабу деградировать и вы ждете от меня продолжения постов про Африку, про Занзибар и прочую экзотику, а не вот это вот все...Но я говорил, что мне тесно в рамках одного амплуа и порой хочется поделиться еще чем-то кроме ооновско-африканских приключений. Все-таки значительная часть жизни отдана науке и конкретно исследованиям в области искусственного интеллекта (ИИ), а также моделирования процессов, происходящих в индивидуальном и групповом сознании. Когнитивные искажения, модели распространения информации в социуме, окна Овертона и прочее. Эта тема крайне интересна тем, что неизменно выводит на самые главные, самые базовые тайны бытия и вечные вопросы, за которыми точная наука незаметно переходит в философию и далее в религию. Я, кстати, как и все мы в быту, до поры посмеивался над философией и ее "бесполезностью", пока на этапе написания докторской не уперся в вопросы и проблемы, по которым технические науки помочь не могли. Но кое-какие пути решения, как я с удивлением обнаружил, уже были намечены философами. Так в технической военной диссертации появились ссылки на Аристотеля, Декарта, Канта, Гегеля и Бодрияра с его симулякрами. И немножко про мировое древо Иггдрасиль, которое оказалось удивительно удобной визуализацией для p-адического континуума чисел.

Это мировой ясень Иггдрасиль. Видите Рататоска? И я не вижу. А он есть )
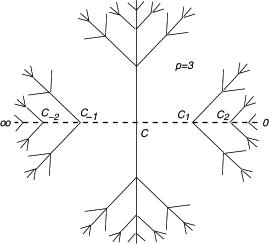
Одно из представлений p-адического дерева (при p=3), которое, возможно, лежит в основе математического описания нашего мироздания. Похоже на Иггдрасиль?
Эти числа считались бесполезной математической абстракцией с конца 19 века, но внезапно отлично подошли для описания физики субатомных частиц уже в конце века 20-го и, возможно, именно они составляют основу для "правильного" описания сознания человека...Ну да ладно, я увлекся, если эта тема будет кому-то интересна, то обязательно постараюсь написать об этом человеческими словами, без сложных формул.
Чтобы не смешивать темы, я назову эту серию "Околонаучные разговоры". И сегодня хотел бы немного рассказать об искусственном интеллекте. Не проходит дня, чтобы не вышла новость об очередном достижении больших языковых моделей, генеративных сетей или успехах очередной робо-собаки от Boston Dynamics. Тем не менее, далеко не все понимают разницу между терминами "искусственный интеллект", "нейросеть" и "машинное обучение", считая эти понятия тождественными. Это не так. Давайте проведем небольшой ликбез по понятиям.
Определения (Часть 0. Вводная).
Одно из довольно точных на мой взгляд, но скучных определений искусственного интеллекта звучит так:
Искусственный интеллект - это свойство систем, реализованных с использованием аппаратно-алгоритмических решений, выполнять функции, которые традиционно считаются прерогативой человека.
Обратите внимание. Тут ни слова о реальном понимании, о возникновении у машины сознания и осознания своих действий. Только о способности имитировать некоторые возможности человека. Отсюда же еще одно образное, но довольно точное определение: ИИ - это все то, чего еще нет. Иными словами, раньше машина, которая умела играть в шахматы, казалась верхом развития инженерной мысли и считалась "умной". Но сейчас мы вряд ли назовем такую систему поистине интеллектуальной. нам подавай, чтобы машина научилась делать что-то такое, что могут делать только люди. Однако с каждым годом эта планка сдвигается все выше.
В современном мире практически все достижения искусственного интеллекта базируются на методах машинного обучения. Это важный раздел ИИ, но далеко не единственный.
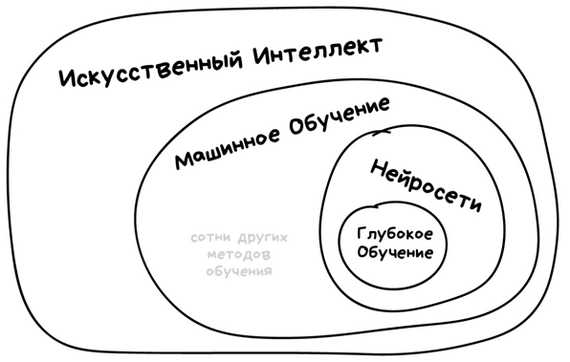
Отличается от "классического" программирования этот подход тем, что при машинном обучении мы "скармливаем" машине не готовые правила, а только входные данные и правильные ответы (например, картинки кошек и собак с соответствующими подписями-метками: это - кошка, а это - собака). А машина, анализируя различия во входных данных, многократно ошибаясь и подбирая параметры, сама строит для себя правила. Единственное, что мы должны сделать - это дать компьютеру достаточно исходных данных и вычислительных мощностей. Ах, да, и еще, конечно, признаки. При классических подходах мы указываем машине, на какие признаки обращать внимание, сравнивая собак и кошек, например. Такими признаками могут быть контуры, цвет пикселов и т. д. Проблема выбора и описания информативных признаков была настоящей головной болью (да и сейчас остается таковой), но частично была решена за счет появления методов глубокого обучения, речь о которых чуть дальше.

Отличия классического программирования от машинного обучения
Нейронные сети, которые у всех на слуху - это всего лишь один из видов машинного обучения. Хороший, во многом универсальный, но не без своих внутренних проблем.
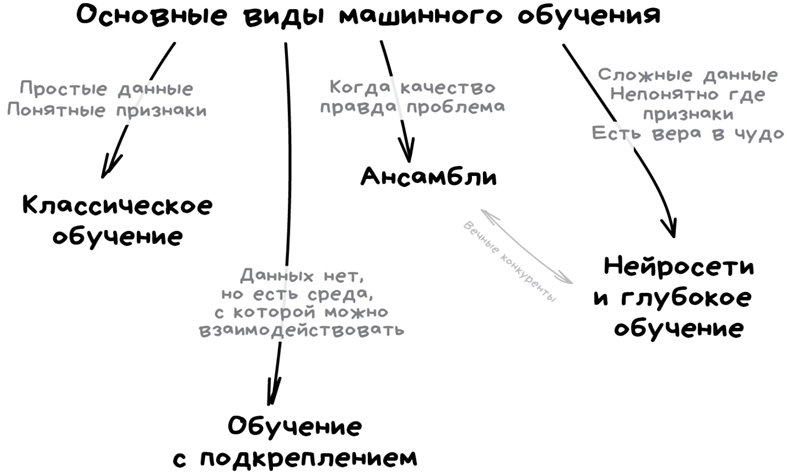
Видите, нейросети скромно сидят в уголке и не выдают себя за единственную возможность для создания искусственного интеллекта
Так вот, глубокое обучение - это всего-навсего один из подвидов архитектуры нейронных сетей и подходов к их обучению. Главная прелесть глубокого обучения заключается, пожалуй, в том, что он избавляет специалиста от ручного подбора признаков для обучения. Иными словами для построения системы распознавания кошек и собак по фото нам понадобятся только подписанные (правильнее говорить - размеченные) фото. Дальше машина сама решит, какие комбинации пикселов и контуров определяют разницу между этими видами животных.
Чем опасен искусственный интеллект? (Часть 1. Пугающая)
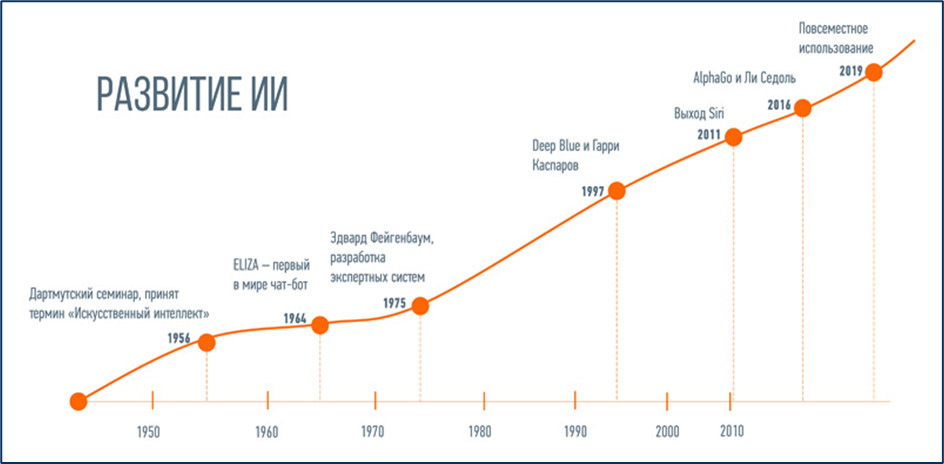
ИИ может многое и развивается довольно стремительно и нелинейно. Очень условно можно представить некоторые основные вехи на вот такой диаграмме.
Незаметно по ряду направлений мы подошли к черте (а в некоторых случаях и переступили ее!), за которой ИИ демонстрирует способности, превышающие человеческие. Например, взгляните на график, который показывает, как снижалась доля ошибок распознавания изображений сверточными сетями.
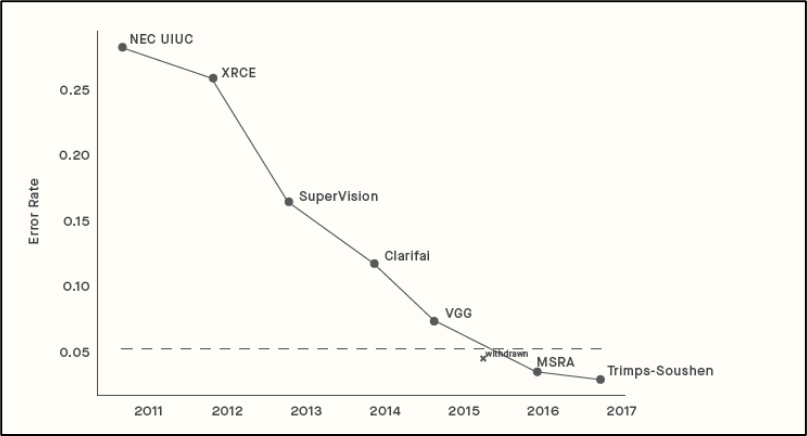
Снижение доли распознавания ошибок изображения сверточными сетями
Штриховой линией отмечен уровень человека (да, мы отлично умеем распознавать изображения). Но примерно в 2015-м году сети обошли нас в этом и продолжают совершенствоваться.
Попутно, обучаясь на миллионах и миллиардах изображений, сети научились улавливать паттерны и генерировать гиперреалистичные фото, неотличимые от настоящих. Посмотрите, каким был прогресс всего за несколько лет:

Сгенерированные нейросетью изображения лиц.
Теперь любой школьник, имеющий базовые знания и доступ к интернету, может сделать практически идеальный дипфейк. Да, пальцы рук зачастую все еще генерятся с ошибками, но это вопрос очень недолгого времени.
Причем речь идет не только о генерации статичных изображений. Уже сегодня, имея всего одну (!) вашу фотографию, злоумышленник вполне может заставить вашу цифровую копию говорить. А если материала много - то и создать виртуального двойника (все еще выкладываете свои рилсы, шортсы и нюдсы в сеть? Тогда ИИ идет за вами!). Для примера я заставил говорить собственную аватарку, которая, естественно, тоже была сгенерирована нейросетью.
Голос использовал свой, но и его подделать совсем несложно, достаточно иметь немного аудиозаписей, например, ваших телефонных разговоров.
Итак, благодаря успехам машинного обучения, мы окончательно не можем доверять ни тому, что видим в интернете, ни тому, что слышим. Но можем мы хотя бы быть уверены, что за сгенерированным образом скрывается живой человек? Увы, тоже нет. Примерно года с 2014-го, когда, как считается, нейросети впервые прошли полноценный тест Тьюринга. Если очень коротко, Алан Тьюринг в своей статье "Может ли машина мыслить" еще в 1950 году предложил тест, который должен был показать, насколько машина хорошо научилась имитировать человека, задавая ей произвольные вопросы и получая ответы. Если машине удастся ввести судей в заблуждение и убедить, что они общаются с живой личностью, то тест можно считать пройденным. Так вот, в 2014 году чат-бот "Евгений Гусман" прошел тест Тьюринга, убедив 33% судей в том, что он на самом деле 13-летний подросток, любитель конфет и гамбургеров.
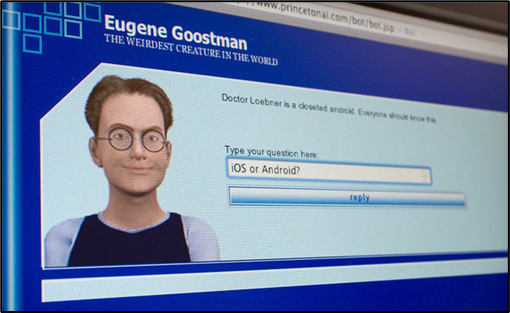
С тех пор прошло 10 лет, за которые нейросети многократно улучшили свои результаты. настолько, что мы местами сами перестали понимать, насколько сложными оказываются ассоциативные связи, закодированные в их весовых коэффициентах. Настолько, что 22 марта 2023 года Илон Маск и группа экспертов в области искусственного интеллекта подписали открытое письмо, в котором призвали ввести паузу на период не менее шести месяцев на разработку и обучение больших языковых моделей (LLM), более мощных, чем нашумевшая GPT-4.

Но угрозы нашей с вами безопасности кроются не только в пугающе высокой скорости развития различных веток ИИ. Они прорываются из виртуального мира в физический, поскольку любая система распознавания неизбежно обладает как минимум двумя типами ошибок (т.н. ошибки 1 и 2 рода), которые можно интерпретировать как ложное срабатывание и пропуск цели.
Так, например, в 2018 году автомобиль Uber в беспилотном режиме впервые насмерть сбил человека в США. А в марте 2020 года в Ливии боевой дрон STM Kargu-2 турецкого производства впервые самостоятельно, действуя в автономном режиме, атаковал военнослужащих Ливийской национальной армии, не получив на это явных указаний от оператора. Робот сам принял решение на уничтожение человека.
Вооруженные силы США, недавно признались, что полагаясь на алгоритмы машинного обучения для анализа сетей сотовой связи с целью выявления и последующего уничтожения курьеров террористических организаций на территории Пакистана, уничтожили порядка 15000 невинных человек в силу ошибок 1 рода ("какие претензии, нам компьютер так сказал!").

Американская система анализа трафика. Ошибки ее применения УЖЕ привели к тысячам человеческих жертв. Christian Grothoff, Jens Porup. The NSA’s SKYNET program may be killing thousands of innocent people. Ars Technica, 2016. ffhal-01278193f
В качестве завершающей картинки на сегодня, покажу вот этот график. На нем по горизонтальной оси отложены некоторые важные вехи в развитии жизни на Земле, а по вертикальной - период времени в годах, который проходил от одной точки до другой. На графике видно, что с появлением человека события начали ускоряться и уплотняться. Биологическая эволюция нашего вида длилась миллионы лет. Первый полет братьев Райт и высадку на Луне застали одни и те же люди. Переход от примитивных искусственных нейросетей - перцептронов Розенблатта до больших языковых моделей произошел еще стремительнее. Конечно, к этому графику тоже есть много вопросов, но если...Но если он верен, это значит, что мы очень близко от так называемой точки технологической сингулярности, в которой события техногенной эволюции ускорятся настолько что мы просто перестанем их контролировать. Дальше развитие пойдет независимо от нас и нашей воли. Некоторые ученые, кстати, считают, что, возможно, это уже произошло.
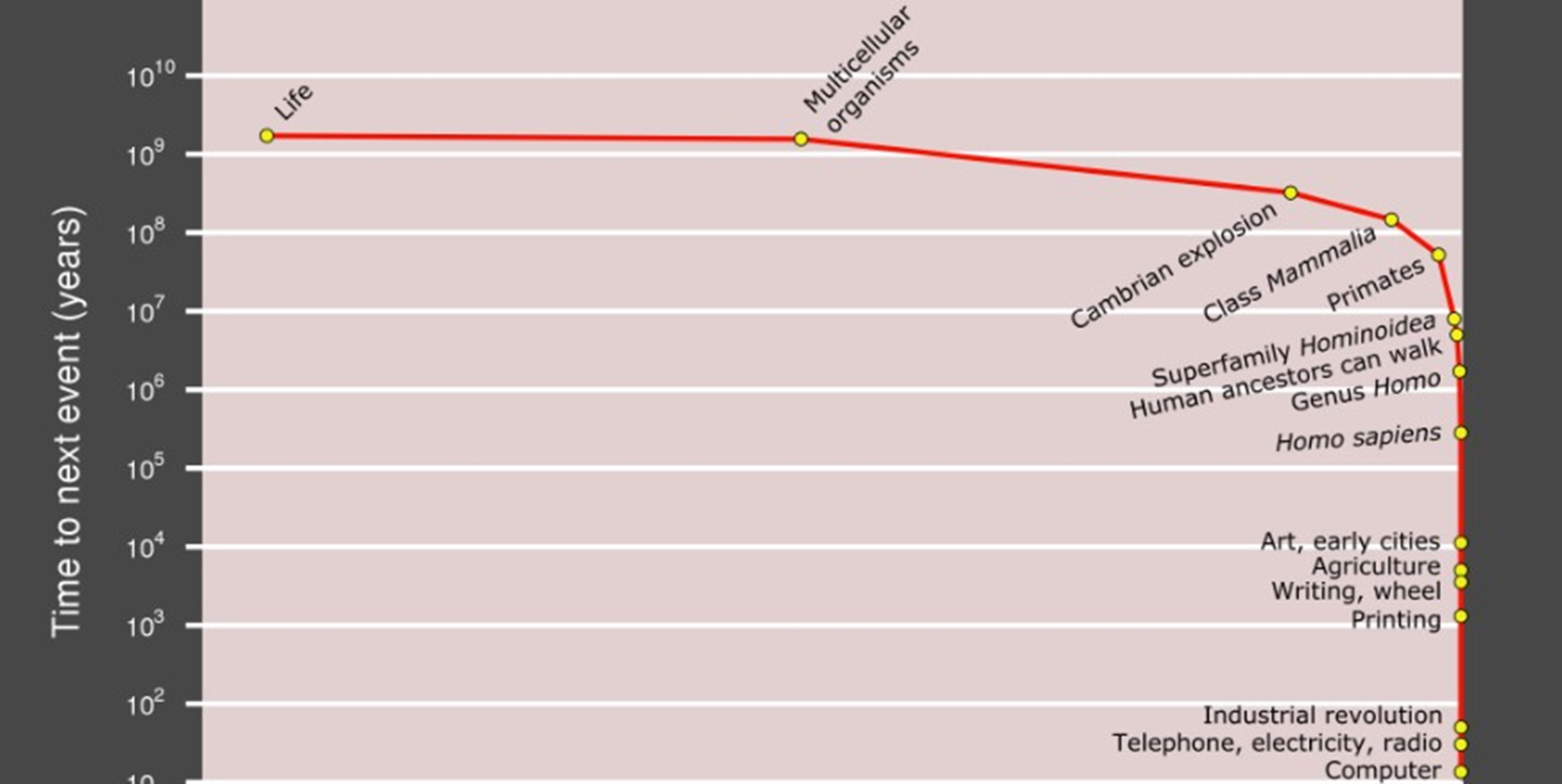
До технологической сингулярности осталось...три...два...один...
Надеюсь, я не напугал вас окончательно. Потому что у ИИ есть и врожденные слабости. И до тех пор, пока компьютеры работают на принципах Тьюринга, на защите человечества стоит почти мистическая теорема Геделя о неполноте. Почему она не дает создать истинно осознающий себя ИИ и можно ли вообще смоделировать сознание человека, я постараюсь рассказать в следующий раз.