Народная карта бензина собрала почти 2 млн посетителей за три дня. Её навайбкодил один человек
Бэкенд кое-как держит нагрузку, но от нормальной монетизации автор отказывается из принципа — пока есть только донаты.
На фоне топливного кризиса появился ГдеБЕНЗ: народная карта, на которой водители сами в реальном времени отмечают, где топливо есть, где очередь, где машин мало и куда ехать уже бессмысленно.
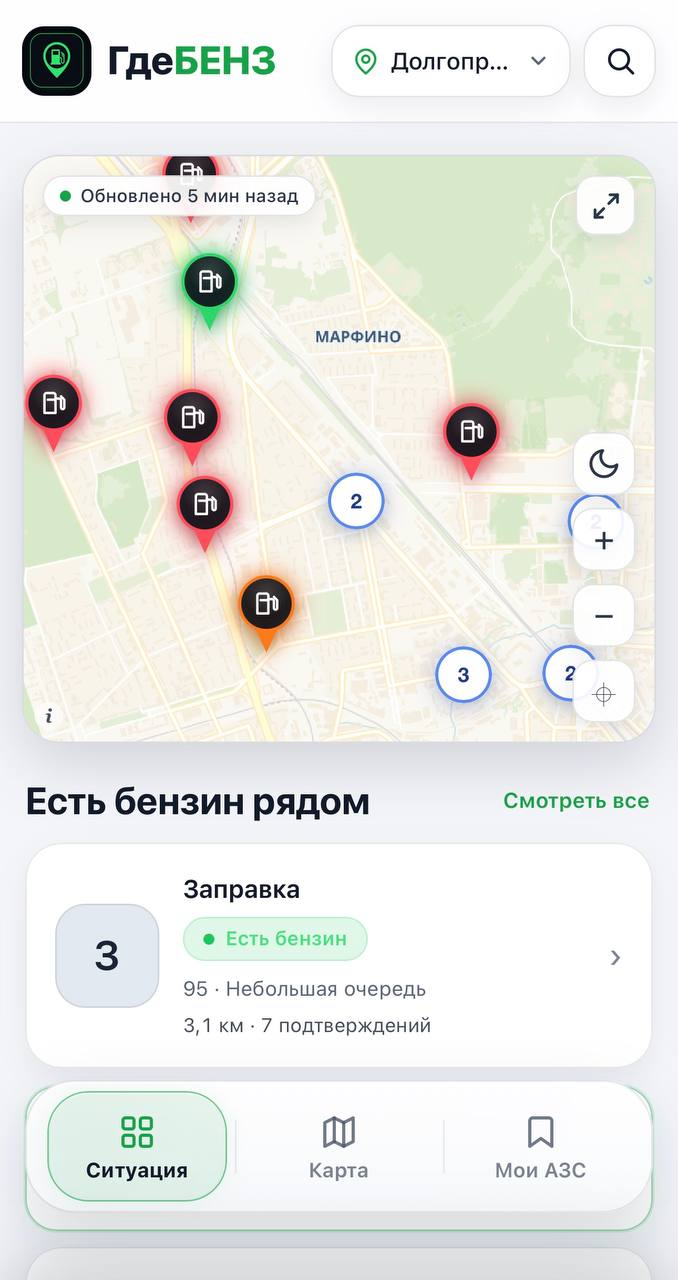
Логика простая до примитива: любой публичной заправке можно выдать эти четыре статуса, никакой регистрации нет, как и отдельного приложения, карта работает прямо в браузере. Один водитель отметил, что бензин появился, второй подтвердил, третий уточнил марку и очередь — и десятки людей рядом уже понимают, где стоит пытаться заправиться, а где нет.
За первые дни ГдеБЕНЗ собрал больше 100 тысяч отметок, 2 тысячи добавленных вручную заправок и 80 тысяч установок карты на главный экран.
Я поговорил с его автором Евгением Чудовым: судя по присланным скринам из Яндекс.Метрики, у проекта за трое суток — 1,8 млн уникальных посетителей, 3,5 млн визитов и 13,2 млн просмотров. Для сравнения: за первые двое суток было 812 тысяч уникальных пользователей. То есть сегодня у сервиса плюс миллион аудитории.
Чудов — маркетолог и предприниматель, основатель биржи рекламы Marketly в каналах MAX. Он ведёт сетку каналов на 2 млн+ подписчиков, сделал популярного бота автопостинга «Отложка» (им пользуются 30 тысяч+ каналов). Думаю, можно сказать, что он запускался не с нуля — у него уже были готовая дистрибуция, как и привычка строить инструменты самому под себя. ГдеБЕНЗ, по его словам, он придумал в самолёте, по приземлении накидал план — и к вечеру всё работало.
Сервис собран с помощью Claude. На вопрос про разработку Чудов ответил лаконично: «Токенов не счесть» — за эти дни он спалил почти два недельных лимита тарифа Claude Max (который даёт x20 к обычным лимитам).
Конечно, ГдеБЕНЗ работает не идеально. Первые сутки автор прыгал с сервера на сервер, наращивая мощность по чуть-чуть, чтобы сайт работал — потом увеличил ресурсы кратно, но лаги и недогруз карты у части пользователей остаются. Инфраструктура к такому наплыву готова не была, и это нормально для сервиса, которому всего несколько дней от роду.
Монетизировать ГдеБЕНЗ Чудов хочет, но «исключительно полезной рекламой»: говорит, скамеры и чёрная реклама уже набежали, и «лучше уйду в минус, чем буду толкать людям грязь». Пока — только добровольные чаевые на сервера. Самым диким событием за эти дни он назвал то, что криптаны на хайпе уже успели выпустить монету «ГдеБЕНЗ», а он к этому не имел отношения — пришлось публично открещиваться.
Отдельная примета — каналы ГдеБЕНЗ в MAX и Telegram уже насчитывают десятки тысяч подписчиков. В MAX их больше, чем в Telegram, что косвенно говорит о реальной популярности в регионах, а не только в столично-питерском пузыре.
На вопрос, сколько процентов заправок сейчас сталкиваются с нехваткой, Чудов отвечать отказался — по его словам, его и так подозревают, что проект «чей-то» и сделан не из благих побуждений. В одном из постов от ГдеБЕНЗ подробно развенчивалась конспирология, что проект — это OSINT для поиска объектов для нанесения ударов. Ну и из топливных компаний и регуляторов с ним пока никто не связывался; говорит, был бы рад, если бы написали те же Яндекс Заправки.
Нечасто случается, что вот прям резко и массово оказываются нужны такие узкоспециализированные коммуникационные сервисы — а когда такая потребность возникает, с инструментами типа Claude Code одинокий вайбкодер закрывает её быстрее, чем любая корпорация. И дело не только в скорости разработки (хотя в большой компании ты такое за три дня не выкатишь), но и в рисках того, чтобы показывать дефицит в реальном времени — сегодня это может быть социально радиоактивно.
Бензин из воздуха ГдеБЕНЗ, конечно, не создаёт. Но честно отвечает на единственный вопрос, который сейчас волнует полстраны: ехать или не стоит.
Такие посты чаще выходят у меня в Telegram-канале, где в основном пишу про AI и его применение.