Была когда-то давно (лет 10 назад) у меня в разработке такая программа для мобильных телефонов на яве и смартфонов на андроиде под названием PaintCAD Mobile (Паинткад Мобайл).
В ней можно было рисовать пиксель арт, GIF анимации, PCF растровые шрифты и писать ими на своих же рисунках. Причем управление было не пальцем по экрану, как во многих современных графических редакторах, а, в основном, курсором по рисунку. С помощью клавиатуры или виртуальной клавиатуры перемещался курсор, и с помощью него ставились точки нужного цвета в нужные места, проводились линии и эллипсы, вставлялся текст в нужное место. Эдакий MS Paint для телефонов с ручным клавиатурным управлением.
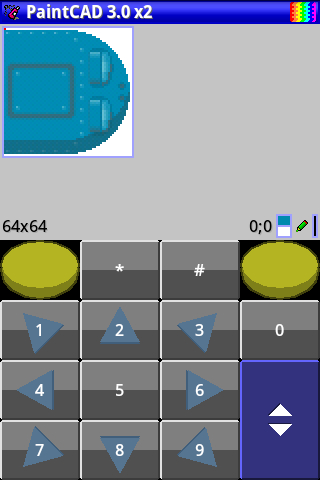
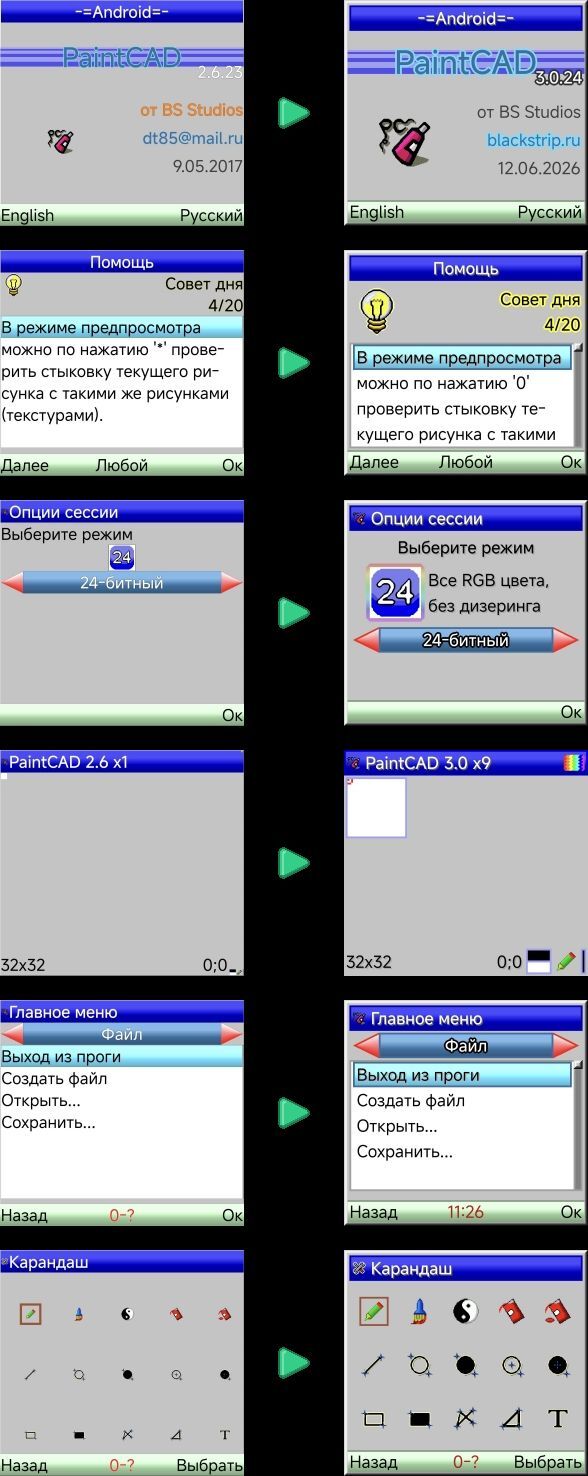
Но она разрабатывалась под мелкие экраны старых телефонов типа 132х176 или 240х320 пикселей. И когда сегодня смартфоны уже имеют экраны по 1000х2000 пикселей - она стала выглядеть так себе: мелкие линии в интерфейсе, мелкие значки, ничего не видно, ничего не понятно.
И вот год назад была начата разработка ее улучшенной версии, хотелось чтобы она сама масштабировалась на большие экраны современных смартфонов с большими экранами.
Каждое окошко по очереди масштабировалось, в нужные места и с нужными масштабами расставлялись значки и элементы интерфейса.
И вот спустя год, буквально вчера, эта версия была завершена и выпущена: PaintCAD Mobile версии 3.0.24.
Кто рисовал в ней на яве во времена господства ява-телефонов - может теперь потестить ее и на андроиде от версии 2.3 и новее. Да и для явы она еще выпускается, например, на Nokia C2-01, продающейся на каком-нибудь озоне за жалкую тыщу рублей она тоже работает в виде ява-мидлета.
На скриншотах видно как масштабировались некоторых из окошек старой версии 2.6.23 от 2017 года до новой современной версии 3.0.24.
Теперь она научилась, наконец-то, в андроиде фоткать, а также вытаскивать кадры из MP4/3GP/AVI-видеофайлов (хотя успешность вытаскивания кадров из видео зависит он версии андроид, были протестированы андроиды от 2.3 по современный 16 андроид, в каждой версии андроид одни из форматов читаются и кадры извлекаются, а другие - не извлекаются вовсе или извлекается зашумленная картинка).
Теперь она может открыть старые BMX анимации с запыленных сименсов и превратить их в аналогичные анимированные GIF. Их даже можно раскрасить и превратить из черно-белых в цветные.
Изменение размера рисунка (функция 'Размер растра') и поворот (функция 'Повернуть') теперь могут использовать три метода: Обычный (быстрый и простой), Умный (более точный расчет для пиксель-арта) и Сглаженный (масштабирование/поворот рисунков со сглаживанием линейной интерполяцией), как это раньше уже делалось в Windows-версии PaintCAD)
Во многих окнах, где рисунок на весь экран (выделение, вставка, выбор прозрачного цвета для эффекта и т.п.), было мелкое изображение, которое на современных экранах смартфонов размером 5х5 мм. И вот теперь во все эти окошки по нажатию кнопки '*' добавлено включение отображения области масштабирования 11x11 пикселей вокруг курсора чтобы было видно куда ты едешь курсором и где выбираешь подходящий пиксель.
Весь интерфейс теперь рисуется в виртуальных пикселях. И их количество на экране примерно соответствует 100-200 точкам по ширине/высоте экрана (в зависимости от пропорций экрана).
Также были добавлены из Windows-версии редактора разнообразные палитры цветов (ZX Spectrum, DOS VGA и прочие). Если в окне палитры нажать '0', то можно выбрать другую палитру и даже 'Внедрить' ее в рисунок, перерисовав его цветами из палитры.
Там в меню настроек в "Чем рисуем..." теперь можно назначить любые физические клавиши любых ява/андроид-устройств, и на любом телефоне/смартфоне управлять паинткадом.
Потестить обновленную версию Паинткада можно здесь (программа без рекламы, как в старые добрые времена расцвета j2me программ для телефонов):
(сайт HTTP а ля Web1.0, поэтому с HTTPS-сайтов только правой кнопкой мыши по ссылке и "Сохранить как...")
Для Java2ME MIDP2.0 с Java-памятью 2 Мбайт и более:
- весь интерфейс теперь автоматически масштабируется под большие экраны с мелкими пикселями и рисуется в "виртуальных пикселях", эмулируя экран телефона шириной/высотой около 100-200 точек (зависит от размера экрана)
- во всех окнах вставки, выделения, выбора цвета: по кнопке "*" можно включить область увеличения 11x11 пикселей в левом нижнем углу экрана и гигантскую крестовину вместо мелкого курсора для более точного прицеливания
- во многих других окнах кнопка "*" включает режим масштабирования чтобы развернуть на весь экран и лучше рассмотреть рисунок в предпросмотре, в файловом менеджере, символ в обзоре шрифта и т.д.
- в окне выбора масштаба "Лупа" максимальный доступный масштаб увеличен до x100, и теперь дополнительно можно:
а) кнопками "ДжойВверх"/"ДжойВниз" выбирать масштаб в виртуальных пикселях,
б) кнопкой джойстика автоматически подобрать максимальный масштаб в реальных пикселях чтобы рисунок отображался без прокрутки,
в) зеленой кнопкой "Снять трубку" - такой максимальный масштаб в виртуальных пикселях без прокрутки,
г) кнопками "*"/"#" установить минимальный и максимальный масштаб в виртуальных пикселях
- функции "Размер растра" и "Повернуть" теперь работают как в PaintCAD 4Windows: Обычным (простой и быстрый), Умным (для пиксель-арта) и Сглаженным (со сглаживанием) методами, а еще "Повернуть" теперь поворачивает выделение на любой угол и может добавить закручивание углов
- палитру теперь можно сохранять в PAL файлы и загружать из PAL файлов (даже в 24-битном режиме), при загрузке можно сразу внедрить ее на рисунок, перерисовав его в цветах загруженной палитры
- в окне палитры можно нажать "0" и выбрать одну из стандартных палитр (ZX Spectrum, DOS VGA и др.), а также сразу внедрить ее на текущий рисунок, перерисовав его в цветах выбранной палитры (это тоже доступно и в 24-битном режиме тоже)
- функция "Мозаика" может раскладывать изображения не только рядами по сетке, но и раскидывать случайно
- новые эффекты "Цветная шерсть", "Цвета из буфера"
- эффект "Сканлайн" в меню эффектов заменен на "Расширитель" из PaintCAD 4Windows, внутри него 22 эффекта увеличения/обработки изображений включая бывший сканлайн
- новая функция "Области", позволяющая добавлять выделенную область в список и потом выделять эту область на других рисунках просто выбирая ее из списка сохраненных областей
- под андроидом заработали съемка фото с камеры и (с ограничениями, зависящими от версии андроида) съемка кадров из MP4/3GP/AVI видеофайлов, плеер для съемки кадров из видео доработан и теперь может снимать кадры как в файлы, так и сразу импортировать в паинткад
- BMX-анимации в 8-битном режиме можно превратить в анимированные GIF файлы прямо из "Плеера BMX", сам плеер BMX тоже доработан и стал похож на плеер для съемки кадров из видео
- пункт настроек "Чем рисуем...", а также долгое нажатие любой физической клавиши при запуске паинткада открывают настройку клавиш, где можно попытаться автоматически определить или вручную назначить любые физические клавиши любых экзотических java/android-устройств чтобы управлять паинткадом на любом из них
- виртуальная клавиатура стала более объемной (рельеф кнопок масштабируется с размером экрана) и теперь рисует разные значки на своих кнопках, зависящие от текущего окна (например, в плеерах показываются функции перемотки, а в функции "Повернуть" при выборе угла поворота - функции поворота на разный шаг и т.п.)
- в меню "Помощь" вместо проверки объема памяти добавлен пункт "Инфо о системе", показывающий информацию о платформе, на которой запущен паинткад, о параметрах экрана, о текущем количестве свободной оперативной памяти и о файловой системе
- окно "Обновление" теперь показывает последнюю релизную версию и бета-версию, а под андроидом можно даже их скачать сразу из окна обновлений