0 просмотренных постов скрыто




Нейронные сети учатся распознавать Deepfake
Пару недель назад я выложил пост про нейронные сети, которые способны удалять с видео любые движущиеся объекты и всякие следы их существования. Тени от этих объектов, поднятую пыль, иногда даже почти хорошо удалялись волны на воде. И тогда, под тем постом, прямо таки развернулась дискуссия о том, как в принципе можно было бы бороться с подделкой видео. Не только с удалением объектов, но и с теми же дипфейками.
И вот сегодня я бы хотел представить один из способов, который на сегодняшний день активно прорабатывается. Собственно, способ вполне логичный - если мы можем создать нейронные сети, которые способны подделывать видео настолько, что эта подделка становится неразличима человеческим глазом, то почему бы не использовать ровно эти же самые сети для того, что бы распознавать эти незаметные человеческому глазу подделки?
Этим вопросом и задались учёные из Германии и Италии. Ниже прикладываю презентацию их совместной научной работы.
А также, как и в прошлый раз, прикладываю своё собственное видео, с разбором того, а чём именно идёт речь в их презентации.
Итак, краткая выжимка того, о чём именно их работа. Конкретно эта группа учёных не ставила перед собой задачу разработать концептуально новую нейронную сеть, которая бы хорошо распознавала подделку на видео. Они провели комплексную сравнительную работу. Взяли набор видео, часть из которых была отредактированная нейронными сетями, а часть нет. И, с одной стороны, попросили группу людей угадать, какие именно видео являются подделками, а с другой стороны точно такую же задачу поставили перед распространёнными свёрточными нейронными сетями, основная задача которых как раз заключается в распознавании на видео и фотографиях тех или иных объектов. То есть, они брали не специализированные нейросети, а самые обычные. Те, которыми можно распознавать на видео котиков, к примеру.
И итог их исследования оказался следующим - нейросети уже сейчас способны настолько качественно подделывать видео, что люди их практически не распознают. Обычный человек уже сегодня не отличит качественный дипфейк от оригинального видео. С другой стороны, самые обычные свёрточные нейронные сети эти же самые дипфейки распознают вполне уверенно. Не всегда со стопроцентной точностью, но самые новые архитектуры вполне достигают точности более 80%.
По сути, самая очевидная идея в данном случае оказывается самой эффективной. Зачем придумывать сложные схемы борьбы с нейросетями, если можно просто заставить бороться с ними другие нейросети. Безусловно, данный метод не является самым надёжным. Но уже сегодня он является наиболее оправданным с позиции точности распознавания и ресурсов, которые требуются на создание такой системы. По факту, использовав созданный учёными в данной работе массив видео для обучения нейросетей, вы сможете у себя дома создать свою собственную систему распознавания дипфейков. Единственным ограничением правда будет время обучения такой сети... Если не использовать видеокарты NVidia старше 20хх серии и разработанную ими же библиотеку для машинного обучения, создание такой сети может затянуться на месяцы... Но тем не менее, такая возможность у вас всё ещё остаётся.
Ну и подводя итог, если углубиться в эту область (а я полагаю многие спецслужбы многих стран мира занимаются этим уже не первый год) и создать специализированную нейросеть, которая была бы эффективна конкретно в распознавание дипфейков, то в принципе можно и не бояться коллапса судебной системы от вала поддельных видео и фотографий. Правда всё это в конечном итоге придёт к войне щита и меча - когда с одной стороны будут создаваться всё более совершенные нейросети для подделки видео, а с другой те же самые нейросети для распознавания этих подделок. Но специалистов способных на подобное сейчас итак с руками отрывают крупнейшие мировые корпорации, поэтому вряд ли их сможет нанять какая то местечковая мафия. Если подобная война и развернётся, то начнётся она в высоких груг И опять же, поскольку это буквально практически одни и те же архитектуры нейросетей, существенного и долговременного перевеса в данной войне ни одна из сторон получить не сможет.
Показать полностью
2
Нейронные сети научились удалять людей с видео
Пару лет назад довольно активно обсуждалась тема deep fake. Технологии, позволяющей заменять лица одних людей на видео другими. Но в том время технология была сырая, даже невооружённым взглядом можно было заметить неестественность изображения. Плавающие контуры лица, искажения пропорций, неестественная мимика и многое другое. Некоторым людям доводилось сделать довольно реалистичные deep fake на небольших отрезках видео, но в какой то момент всё равно вылезала неестественность.

Никаких резких скачков в этой области долгое время не было, поэтому разговоры понемногу сошли на нет. Но данное направление никто не забрасывал и различные группы исследователей и инженеров продолжали работу в этом направлении. И вот в этом году группа исследователей из Оксфорда, Института Вейцмана и Google Research представили систему ансамбля нейронных сетей, способных определять на видео не просто контуры отдельных объектов, но и последствия любых контактов этих объектов с окружающим миром. Поднятую пыль, тени, задетые объекты, даже поднятую рябь на воде. И этот ансамбль нейросетей способен не только всё это определять, но и удалять с видео. Ниже прикрепляю оригинальное видео, представленное авторами разработки.
Поскольку оригинальное видео полностью на английском и в нём описываются лишь базовые особенности работы нейросетей, я также записал видео на русском. В нём я подробнее и простым языком постарался разобрать как саму разработку, так и те принципы, по которым работают нейросети, входящие в ансамбль.
При этом стоит заметить, что данная нейросеть работает абсолютно автономно. И обрабатывать различные видео она способна в "промышленных" масштабах. Есть у неё конечно и ряд ограничений, так что не стоит бояться, что уже завтра можно будет удалить кого угодно с любого видео.
С другой стороны, от появления сетей, которые могли очень криво заменять лица людей, до появления систем, способных практически бесследно удалить любой движущийся объект с видео прошло всего пару лет. И кто знает, чему научатся сети ещё лет через 5-10.
Показать полностью
1
2


Цифровой двойник как форма вечной жизни

Недавно мне довелось говорить с человеком, занятым в проекте по цифровой трансформации похоронного бизнеса в США
Тема, конечно, не самая весёлая. Да и, казалось бы, провайдеры ритуальных услуг должны быть последними в очереди на трансформацию, поскольку, по моим представлениям, свободной конкуренции, заставляющей бежать, чтобы стоять на месте, в этой отрасли нет, а доля рынка определяется неизвестными мне нерыночными факторами
Возможно - люди просто на всякий случай хотят быть в тренде и заодно подновить имидж
Думаю, отчасти да, но не только. Пусть цифровизация не принесёт (и слава богу) похоронным бюро дополнительных клиентов, но позволит как минимум навести порядок в учёте, оптимизировать кое-какие бизнес-процессы и, наверное, упростит общение с заказчиками услуг, что принесёт материальный эффект, ради которого всё поначалу и затевается
Но, все последствия набирающей скорость цифровизации не представляют себе ни трансформируемые бизнесмены, ни писатели – фантасты ни пациенты психбольниц
Давайте сложим два плюс два, где первым слагаемым будут технологии deep fake, а вторым - machine learning на основе паттернов поведения человека в цифровой среде или цифровых следов

В результате получаем реальную технологию создания цифрового двойника (аватара) конкретного человека с его мимикой, жестами, манерой общения и словарём - настолько точного двойника, что при общении с ним в зуме, вы не догадаетесь, что прототип в это время спит рядом на диване (очень удобная фича для студентов на удалёнке)
И это уже не фантастика, потому что работа над цифровыми двойниками в медицинских целях ведётся в той же Германии с привлечением очень серьёзных ресурсов, а идея создания двойников личности (поведенческих двойников) обсуждалась в России на уровне правительства ещё в 2018 году
Развивая мысль дальше, сложим другую пару двоек: Курта Кобейна и сервис My Heritage
Получаем возможность не только анимировать фотографии умерших родственников, но и иллюзию продолжения их жизни где-то в другом измерении
Хотя, почему иллюзию?
Кто сказал, что цифровое пространство – не форма жизни, где кремний вместо белка? Кто-то из фантастов писал об этом в прошлом веке
Кстати, многие люди платят деньги экстрасенсам за роль интерфейса при контактах с куда более сомнительным пространством

Сетевая личность, конечно, не реинкарнация человека. Но это больше, чем анимированная фотка с предсказуемыми реакциями и запрограммированными ответами на FAQ. Эта личность может развиваться самостоятельно за счёт парсинга информации из сети с учётом склонностей, интересов, интеллектуальных способностей и круга общения прототипа
Песня - «Девочка, живущая в сети» наполняется новым смыслом (респект Земфире)!
Возвращаясь к началу, я вполне допускаю, что, сделав первый шаг в сторону цифровизации заказчики войдут во вкус, и в дополнение к традиционным погребению и кремированию добавят в прейскурант строчку «вечная жизнь в цифровом пространстве» (простите за юмор на чувствительную тему)
Но разве только они?
Загуглите запрос: «Очередь в мавзолей в СССР, images». Тысячи людей часами стояли на морозе, чтобы одним глазом взглянуть на забальзамированное недвижимое тело даже без надежды услышать ответ на вопрос: «Как нам реорганизовать РАБКРИН?»

Никакого интерактива, а какой ажиотаж!
Я думаю, цифровой двойник Ильича, созданный на базе 55 оцифрованных томов потока его неординарного сознания, обученный на миллиарде статей википедии и мемах про Наташу с котами будет пользоваться огромным спросом не только среди советских пенсионеров. И никакой очереди, лишь бы сервер нагрузку выдержал
В заключение при всей кажущейся абсурдности у меня к вам вопрос: а вы хотите жить вечно?
Показать полностью
3

Дипфейк с Путиным показали в режиме реального времени на американской конференции
Дипфейк (deepfake) – процесс реалистичной замены лиц на видео при помощи нейронный сетей. Такие ролики становятся всё более популярными и правдоподобными, что приводит к спорам о их этичности. Например, на пикабу уже был пост на тему того, что воры используют дипфейки для обмана компаний.
Однако, это не останавливает программистов, которые продолжают создавать и улучшать deepfake-технологии. Так, на американской конференции EmTech главный редактор издания MIT Technology Review Гидеон Личфилд "провел интервью" c дипфейком Владимира Путина.
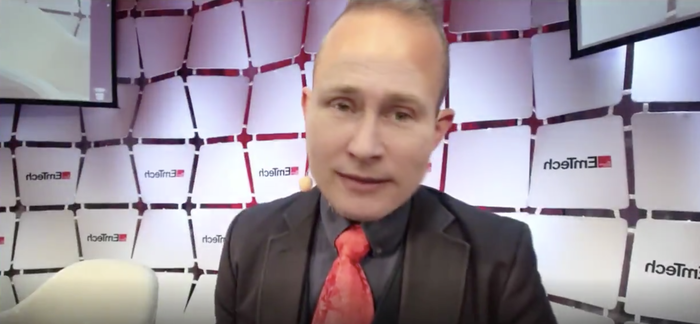
В режиме реального времени лицо Личфилда было трансформировано маской лица Путина. Сами разработчики осознают, что дипфейк еще далек от идеала (особенно это заметно, когда спикер показывает зубы), но в любом случае это показатель того, как быстро технологии развиваются.
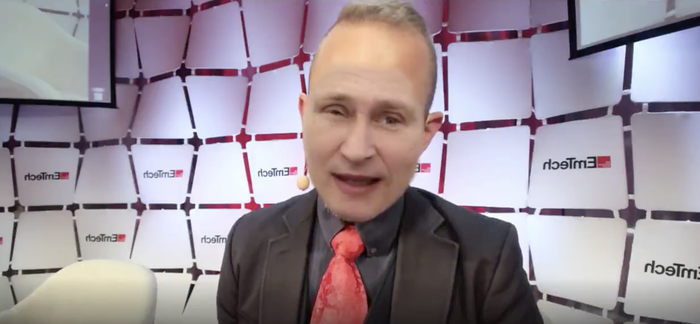
Полного видео в Ютубе нет, можно посмотреть только в Твиттере.
Показать полностью
2


Воры используют deepfakes для обмана компаний, заставляя посылать себе деньги

C момента своего появления в декабре 2017-го дипфейки, видео с почти идеальной заменой лица, созданные нейросетью, наводили на экспертов панику. Многие, например, тогда боялись, что теперь еще проще станет «порно-месть», когда бывший бойфренд с достаточно мощным ПК может смастерить любое грязное порно с подругой. А Натали Портман и Скарлетт Йоханссон, о которых порно с deepfake снимали особенно много, публично прокляли интернет.
Чтобы бороться с подступающей угрозой, Facebook и Microsoft недавно собрали коалицию для борьбы с дипфейками, объявив призовой фонд $10 млн тем разработчикам, которые придумают лучшие алгоритмы для их обнаружения. Это помимо DARPA, управления исследованиями Министерства обороны США, выделившего на эту цель $68 млн за последние два года.
Ну так вот, уже поздно. Первое deepfake-преступление уже состоялось.
По данным Wall Street Journal, в марте этого года управляющий директор британской энергетической компании был ограблен на €220 000 (около $240 000). Он отправил эти деньги фирме-поставщику из Венгрии, потому что его босс, глава материнской фирмы в Германии, несколько раз подтвердил ему такую инструкцию. Но на самом деле какой-то хитрый злоумышленник просто использовал софт с AI-технологиями, чтобы в режиме реального времени заменять голос руководителя, и требовать, чтобы тот заплатил ему в течение часа.
Программа, которую использовал вор, смогла полностью имитировать голос человека: тон, пунктуацию, даже немецкий акцент. Сообщение исходило с адреса босса в Германии, в подтверждение британскому директору был направлен e-mail с контактами. Предположить, что что-то идёт не так, можно было разве что по требованию босса провести всю сделку как можно быстрее, но это далеко не первый аврал, который случался в их бизнесе.
В итоге – все деньги пропали. Из венгерского аккаунта их перевели в Мексику, а потом рассеяли по всему миру. Но воры на этом не остановились. Они попросили второй срочный перевод, чтобы «поставки из Венгрии» «пошли еще быстрее». Тут уж британский директор почуял неладное, и позвонил своему настоящему боссу. Получился какой-то сюр: он по очереди принимал звонки то от фейкового, то от настоящего руководителя, говорящих одинаковыми голосами. Название компании и её сотрудников не разглашаются, поскольку по этому делу ведется расследование, и воры еще не найдены.

Возможно, это даже не первая кража с использованием Deepfake AI (или его продвинутых последователей). Symantec сообщает, что она засекла как минимум три случая, в которых замена голоса помогла ворам обхитрить компании и заставить их послать им деньги. В одном из этих случаев ущерб составил миллионы долларов. Причем, судя по косвенным признакам, этот трюк был проделан другими злоумышленниками – не теми, которые обокрали британского СЕО. То есть, deepfake-преступления постепенно становятся общим достоянием, это не придумка какого-то одного гениального хакера.
На самом деле, скоро такую процедуру сможет проделать любой школьник. Главное – найти достаточно доверчивую жертву, и собрать нужное количество сэмплов видео/аудио, чтобы имперсонировать, кого потребуется. Google Duplex уже успешно мимикрирует под голос реального человека, чтобы делать звонки от его имени. Многие небольшие стартапы, в основном из Китая, работают над тем, чтобы предлагать похожие на deepfake сервисы бесплатно. Разные программы-дипфейки даже соревнуются друг с другом, кто сможет сгенерировать достаточно убедительное видео с человеком, используя минимальный объем данных. Некоторые заявляют, что скоро им будет достаточно одного вашего фото.
В июле Израильское национальное управление защиты от киберугроз выпустило предупреждение о принципиально новом виде кибератак, которые могут быть направлены на руководство компаний, ответственных сотрудников и даже высокопоставленных чиновников. Это первая и на данный момент самая реальная AI-угроза. Они говорят, уже сейчас есть программы, способные идеально передать ваш голос и акцент, прослушав вас 20 минут. Если где-то в сети есть запись с вашей речью в течение получаса, или если кто-то немного посидел рядом с вами в кафе с диктофоном, ваш голос теперь может быть использован, чтобы сказать кому угодно что угодно.
Пока что инструментов для борьбы с этим нет. Вариант защититься только один. Если вам кто-то звонит и просит перевести существенную сумму денег, – не будет лишним подтвердить, что это тот самый человек, по другому каналу. Через мессенджеры, Скайп, e-mail, корпоративные каналы или соцсети. А в идеале, конечно же, – лицом к лицу.
Ну а если у вас есть глубокие познания в машинном обучении и вы не прочь получить кусок от пирога в $10 млн – можно попробовать себя в конкурсе Microsoft и Facebook. Или основать свой стартап, предлагающий государству и солидным компаниям бизнес-решение для определения дипфейков по картинке или по голосу. Без этого нам скоро будет не обойтись.
Источник: Хабр
Показать полностью
2
На поприще приложения от deepfakes
Я давно интересуюсь машинным обучением и нейронными сетями. Недавно один юзер на реддите(ну вы же все знаете, да?) опубликовал программное обеспечение, готовое для преобразования одних лиц на другие.
Это круто и я даже попробовал(в культурных целях, естесственно... Хехехе). Одна проблема, которая меня коснулась - отбор видеофрагментов с лицами крупным планом(если это возможно). Если брать в рассчет популярных личностей, то можно найти интервью какое-нибудь долгое или просто качественное. Главное, что там зачастую есть крупные планы. И вот эти самые крупные планы будут в разы полезнее, чем вся информация о целевом лице из видео.
Поставил себе задачу: написать скрипт, который с помощью глубоких нейронных сетей будет вычленять из видео фрагменты именно с крупными планами. Ну и так как понятие крупного плана растяжимое, то я просто ввел как параметр ширину лица в пикселях на картинке. Для определения ширины лица просто брал один кадр крупного плана и руками измерял ширину лица в пикселях и брал значение на 10% меньше того, что определил. Это для того, чтобы если крупные планы не всегда настолько крупные, как на взятом кадре, не потерять полезную для сети deepfakesapp информацию.
В итоге провел тестирование на Эмме Уотсон(я заметил, многим она нравится. Мне вот почему-то нет), на нескольких найденных на ютубе видео. В одном видео крупных планов не особо много, но много фрагментов без лиц(программа сначала находит лицо, потом проверяет размер и принимает решение о валидности кадра). Во втором есть много крупных планов ведущего. А третье - просто большое интервью.
В итоге первое и третье - отработали как надо.
Со вторым вопросы у меня, но буду как-то оптимизировать. Может стоит настроить LSTM слои, чтобы запоминалось лицо по признакам и не брать в рассчет другие лица. Тут думать надо.
Ну и по классике - сначала результат. Вдруг кому для той же deepfakesapp пригодится. Видео без звука. Ссылка на МЕГА-диск, может быть не очень быстрая скачка. https://mega.nz/#!rk8wGDAK!RUdyOo5gPA4QAQwyrlOJjjk6l459--Szo...
Если кому пригодится скрипт в будущем, то оптимизирую код и выложу в доступ.
P.S. Лайфкахи deepfakesapp:
1) Если при обучении не хватает ракурсов повернутой головы направо(или налево), но в есть ракурсы в другую сторону, то зеркальное отображение по горизонтали хорошо отрабатывает и сетка лучше учиться. С поворотом головы вверх-вниз, конечно, не работает :)
2) Если для обучения системы недостаточно оперативной памяти(мне вот моих 16Гб не всегда хватает), лучше выбрать необходимые ракурсы лица(учитывая эмоции), которое будет переноситься на будущий видеоролик. Это не так сложно, как кажется, но процесс обучения будет легче. Ну и с оперативной памятью ниже 16Гб лучше не подходить к обучению, т.к. либо библиотеки для обучения будет мало, либо все будет происходить очень медленно(даже если установлена топовая видеокарта). Также можно уменьшить количество кадров набора для обучения рандомом, оставив 3000-4000 кадров(у меня тогда хватает оперативы), но результат после рандома не всегда удовлетворительный.
3) Декодеры и энкодеры можно сохранять отдельными файлами, если есть желание передать их кому-либо или "преобразовать" несколько видеороликов с одной личностью.
4) Если у вас нет хорошей видеокарты, но есть у друга(настоящего, а не того, кому нужны итоговые видео), то можно подготовить вырезанные с помощью deepfakesapp лица и попросить обучить сеть своего друга. Если он не знает о программе, то не догадается в чем состоят ваши цели(наверное).
Показать полностью