Компания Cerebras создала уникальные “царь-чипы”, которые отличаются от обычных процессоров кардинально. Вместо множества маленьких кристаллов — один огромный чип размером почти с целую кремниевую пластину.
Современная версия WSE-3 содержит 4 триллиона транзисторов, сотни тысяч вычислительных ядер и десятки гигабайт сверхбыстрой памяти SRAM прямо внутри чипа. Это позволяет достигать невероятной скорости обмена данными — в десятки тысяч раз быстрее, чем у традиционных GPU.
Такие решения идеально подходят для обучения нейросетей и больших языковых моделей. Например, задачи, на которые раньше уходили недели или месяцы на кластерах GPU, теперь можно выполнить за считанные дни или даже часы.
Но есть нюанс: несмотря на колоссальную мощность, царь-чипы пока не вытеснили классические решения от NVIDIA. Почему так происходит? В этом видео разберём плюсы, минусы и реальное будущее гигантских процессоров.
Привет, Пикабу! На связи Дмитрий, разработчик «Lesorub Pro».
Пока пользователи вовсю тестируют новый сканер досок, я заперся «в гараже» и занялся глубоким обучением. Сегодня хочу показать вам «внутрянку» — как происходит переезд на новую, ультра-мощную модель ИИ (ULTRA_LUMBER_MODEL).
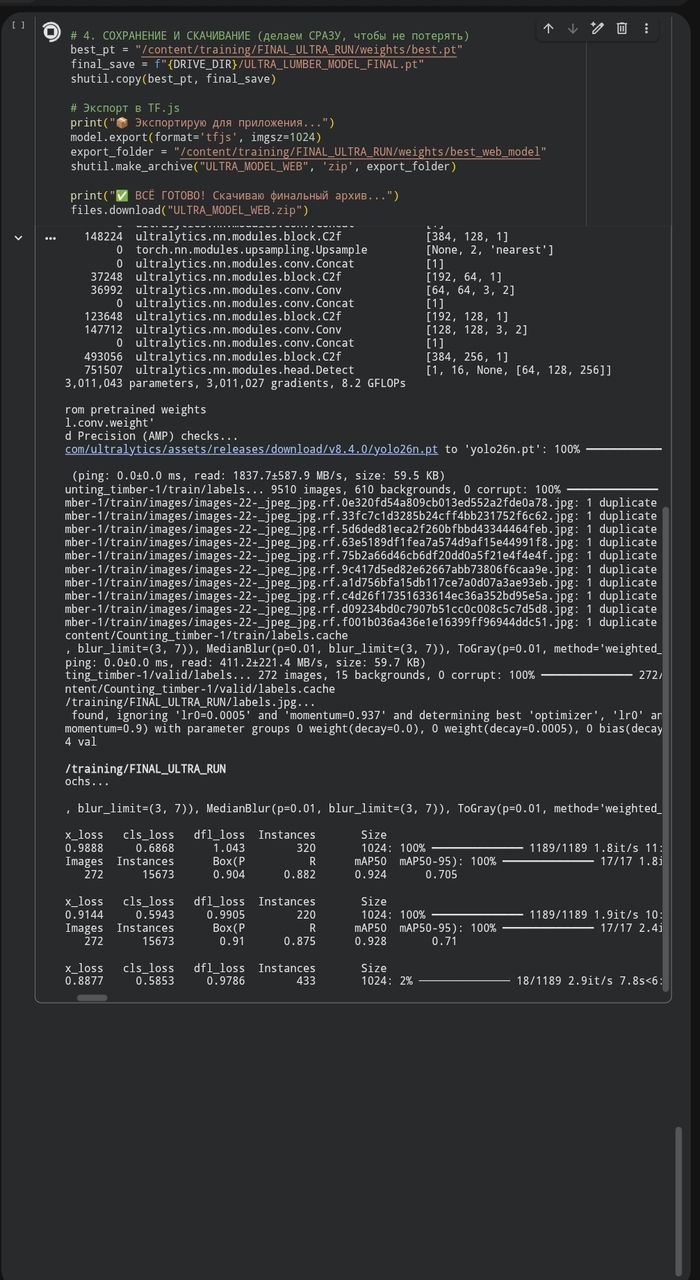
На скриншоте — финальные этапы обучения. Мы скормили нейросети огромный массив данных, и вот какие «фишки» появятся в ближайшем обновлении:
1. Переход на 1024 тензора (Full Precision) Раньше модель работала на более низком разрешении, из-за чего мелкие доски вдали могли сливаться в кашу. Новая модель обучается строго на 1024x1024. Это значит, что детализация вырастет в разы — ИИ будет видеть каждую щелочку.
2. Борьба с «двоением» (NMS-фильтрация)
Многие замечали: иногда ИИ находит одну доску, но рисует на ней две-три рамки. Мы подкручиваем алгоритм NMS (Non-Maximum Suppression). Теперь порог перекрытия установлен так, что дубликаты будут беспощадно удаляться, оставляя только один идеальный контур.
3. Технология Slicing: Как съесть слона по частям
Это самая крутая фича. Представьте огромную фуру с досками в 4K разрешении. Если засунуть её в нейросеть целиком — мелкие детали потеряются.
Мы внедряем Slicing Aided Inference: приложение будет «резать» фото на блоки по 1024 пикселя, прогонять каждый через ИИ отдельно, а потом склеивать результат. Это гарантирует 100% точность даже на гигантских штабелях.
4. Зрение ночного хищника (Contrast Enhancement)
Лес часто грузят в сумерках или в глубокой тени. Мы добавили предварительную обработку фото: перед тем как ИИ начнет считать, программа программно «вытягивает» контраст и яркость в тенях. То, что для человеческого глаза — черное пятно, для нашей нейронки станет четким набором досок.
Зачем я это рассказываю?
Разработка ИИ — это не только «нажал кнопку и готово». Это тысячи итераций, подбор порогов уверенности (сейчас остановились на 0.35) и постоянная работа с кодом.
Скоро эта «ультра-модель» прилетит всем пользователям в обновлении. Проект остается бесплатным и открытым для ваших идей.
Проверить, как ИИ считает сейчас, можно тут (RuStore):
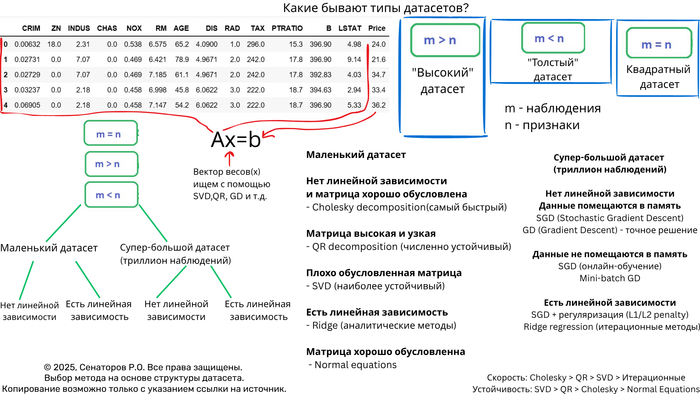
Полное руководство по выбору алгоритма для систем линейных уравнений
Выбор оптимального метода решения СЛАУ на основе анализа датасета
Меня зовут Руслан Сенаторов, я занимаюсь математическим обоснованием машинного обучения. В этой статье, я расскажу как выбрать метод для определённого типа датасета, чтобы ваш код работал быстро, точно и без ошибок? И вы получили премию от руководства!
Введение
Решение систем линейных уравнений (СЛАУ) вида Ax = b — фундаментальная задача вычислительной математики и машинного обучения. Однако универсального метода не существует — выбор алгоритма критически зависит от характеристик датасета. Неправильный выбор может привести к катастрофическому замедлению вычислений или полной потере точности.
Ключевые характеристики датасета
1. Размер и структура матрицы
n_samples × n_features — соотношение наблюдений и признаков
Плотность/разреженность — процент ненулевых элементов
Обусловленность — число обусловленности матрицы
2. Вычислительные ограничения
Объем оперативной памяти
Требования к точности
Время вычислений
Дерево решений для выбора метода
Маленькие датасеты (n < 1000)
Плотные хорошо обусловленные матрицы
# Холецкий — самый быстрый для POSDEF матриц
if np.all(np.linalg.eigvals(A) > 0):
L = np.linalg.cholesky(A)
x = solve_triangular(L.T, solve_triangular(L, b, lower=True))
Встречайте свежий релиз PyTorch 2.6! 🚀 Эта версия приносит множество улучшений, которые делают работу с фреймворком ещё удобнее и эффективнее. Давайте разберём основные нововведения!
🌟 Основные улучшения:
Поддержка Python 3.13 для torch.compile
Теперь вы можете использовать torch.compile с Python 3.13, что открывает новые возможности для оптимизации вашего кода. Это особенно полезно для работы с большими моделями и сложными вычислениями.
Улучшения AOTInductor
AOTInductor (Ahead-of-Time компилятор) получил несколько значительных обновлений. Эти изменения позволяют ещё больше ускорить выполнение моделей на CPU и GPU 💻.
Поддержка FP16 на X86 CPU
В PyTorch 2.6 добавлена поддержка FP16 (полуточности) для процессоров с архитектурой X86. Это означает, что теперь можно добиться более высокой производительности даже на CPU! ⚡️
Расширение возможностей torch.fx
Библиотека torch.fx получила обновления, которые позволяют более гибко работать с графами вычислений. Если вы вносите изменения в граф, не забудьте вызвать метод recompile() для обновления кода 🔄
Новые возможности для работы с моделями
Обновлены инструменты для загрузки и сохранения моделей через torch.load(). Теперь работа с тензорами стала ещё удобнее благодаря улучшенной обработке хранилищ данных 📂
Разработчикам приложений Generative AI стоит обратить внимание на новую коллекцию моделей Qwen 2.5 и Qwen 2.5 Coder. С сентября 2024 года эти модели привлекают внимание разработчиков благодаря своей эффективности.
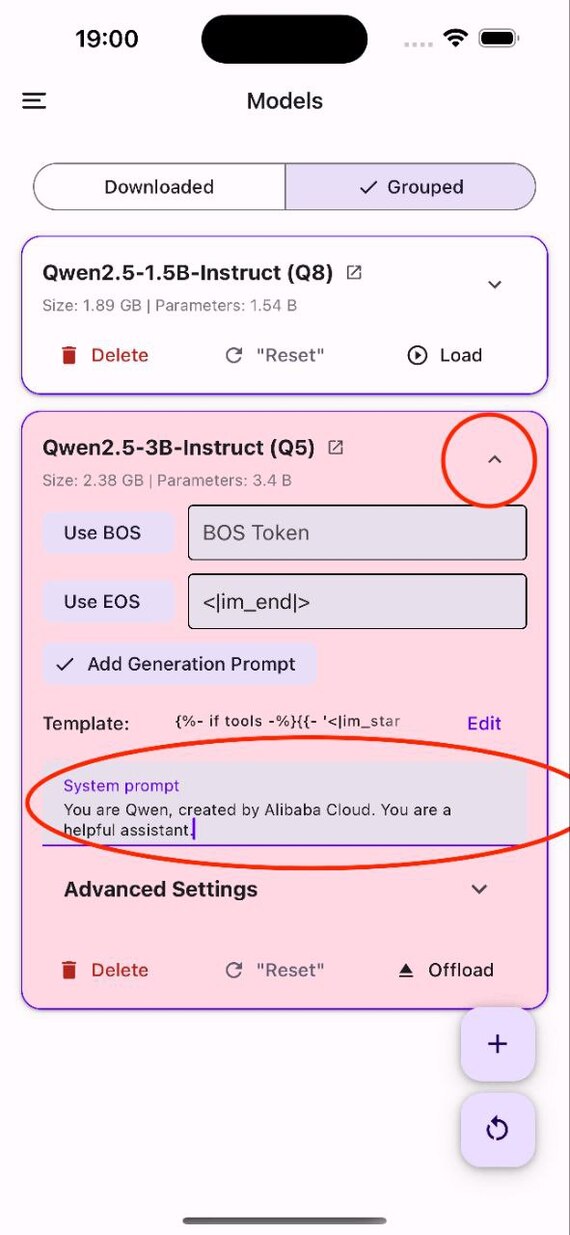
Во-первых, веса Qwen 2.5 доступны в версиях от 0.5B параметров — это очень легковесная модель — до 72B. Посередине есть 3, 7, 14 и 32B, каждую из которых вполне можно запускать локально, если у вас есть, например RTX 3080 с 16ГБ видеопамяти. В этом поможет квантизация (особенно в случае с 32B). Квантованные веса в форматах GGUF, GPTQ, AWQ есть в официальном репозитории.
Для более быстрого инференса и файнтюнинга Qwen 2.5 можно арендовать облачный GPU и работать с этой моделью так же, как с привычной нам Llama. Я показывал примеры файнтюнинга последней в предыдущих статьях, используя облачные видеокарты и стек Huggingface Transformers (код Qwen 2.5 добавлен в одну из последних версий transformers).
Есть базовая модель и версия Instruct, вы можете пробовать файнтюнить обе и смотреть, какой результат вам лучше подходит. Но если вы хотите взять готовую модель для инференса, то лучше конечно Instruct. Благодаря разнообразию размеров и форматов, Qwen может быть полезен для разных типов приложений - клиент-серверных, или десктопных, и даже на мобильных - вот как это выглядит:
Но по-настоящему Qwen 2.5 привлек внимание разработчиков, когда вышла коллекция Qwen 2.5 Coder. Бенчмарки показали, что 32 B версия этой модели может конкурировать с GPT-4o по написанию кода, а это очень интересно, притом что 32 миллиарда параметров вполне можно запустить на средней мощности видеокарте, и получить хорошую скорость генерации токенов.
Вообще какие приложения можно создавать с помощью новых моделей Qwen? Это конечно различные чатботы, но не только.
Разработчики говорят, что Qwen хорош для систем агентов.
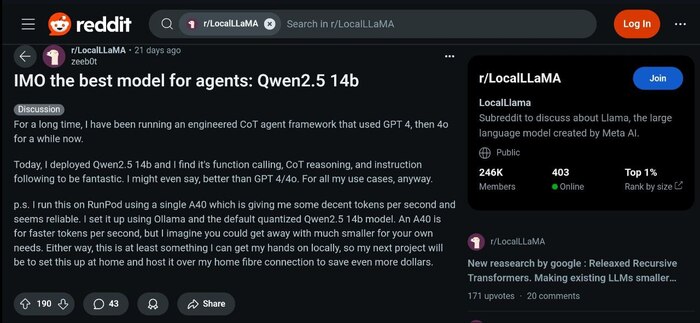
Вот что написал недавно в Reddit один из них:
Я длительное время использовал кастомный Chain-of-thoughts фреймворк с GPT-4, затем 4o.
Сегодня я развернул Qwen 2.5 14B и обнаружил, что его возможности вызова функций, Chain of Thoughts и следования инструкциям фантастические. Я бы даже сказал, лучше чем GPT 4/4o - для моих задач, во всяком случае
Кажется интересным не только то, что разработчик получил такую высокую производительность для сложных задач, требующих продвинутой логики, на открытой LLM. Интересно и то, что для этого ему потребовались сравнительно небольшие мощности — ведь речь идёт о квантованной 14B модели:
Я использую одну видеокарту A40 для надёжности системы и высокой скорости генерации. Я выполнил установку через Ollama, взяв дефолтный квантованный Qwen 2.5 14B. A40 нужна для более высокой скорости, но я могу представить, что вам подойдёт и намного меньшая видеокарта для ваших задач
Мне нравится идея разработки агентских систем с помощью открытой модели на 14B параметров, для работы которой достаточно экономичной видеокарты A40 или даже менее мощной модели.
Агенты, вспомним, это GenAI приложения которые могут оперировать компьютером пользователя, взаимодействовать с другими программными компонентами. Для этого очень важна способность интегрироваться с разными API, вызов функций и логическое мышление модели.
По поводу логического мышления, традиционный подход — это Chain of Thoughts, особая стратегия промптинга. Она побуждает LLM строить пошаговые рассуждения, более эффективные для решения задачи и самовалидации решения на каждом шаге. Некоторые модели специально обучены для работы с таким промптом, например, GPT-4o1. Непонятно, обучали ли Qwen строить цепочки мыслей, но, как видим, разработчики указывают на высокую производительность модели в этом отношении.
Некоторое время назад я увлёкся нейросетями. Начиналось всё с попыток запуска готовых моделей на локальном железе и эксплуатированием для своих простых проектов а-ля телеграм бот или голосовой помощник со встроенной нейросетью. Спустя время я с этим наигрался и захотел попробовать создавать, а не созерцать. Тогда я пошёл изучать теорию для работы. Изучив теорию решил выбрать для себя инструмент и цель. Как инструмент мне больше подошёл pytorch. А как цель поставил себе сделать нейросеть-переводчик. И вот на моменте реализации у меня возникли проблемы: как вводить изображения(будь то фото для классификации или цветной шум для генерации фото) в интернете написано, а вот как вводить текст или хотя бы последовательность битов я найти не смог(да-да не смог, можно уже начинать кидать в меня помидорами и ссылками, за ссылки буду благодарить, а из помидоров сделаю томатную пасту); как выводить картинку или пару нейронов классификатора в интернете описали, в некоторых местах даже описали нейросети продолжающие текст на основе какого-либо книжного произведения, но как выводить сразу текст, а не вытягивать посимвольную информацию я не нашёл(да, опять); ну и под конец я не нашёл как разбивать свой датасет для нейросетей генерирующих что-либо не из рандомных чисел.
Если у кто-то знает как реализовать что-либо из вышеперечисленного, поделитесь пожалуйста знаниями, ссылками на гайды и помидорами в комментариях. Заранее спасибо!
1 Google Data Analytics Professional Certificate - курс, после прохождения которого вы получите глубокое понимание практик и процессов, используемых младшим или помощником аналитика данных в своей повседневной работе.
2 Machine Learning Specialization - вы изучите фундаментальные концепции ИИ и приобретите практические навыки машинного обучения в удобной для начинающих программе из 3 курсов.
3 Introduction to Artificial Intelligence (AI) - вы узнаете, что такое (ИИ, изучите примеры использования и применения ИИ, разберетесь в концепциях и терминах ИИ, таких как машинное обучение, глубокое обучение и нейронные сети.
6 Generative AI for Leaders - курс предлагает полное погружение в понимание способов использования и освоения генеративного ИИ в качестве надежного инструмента для усиления лидерских способностей.
7 Generative AI for Everyone - курс "Генеративный ИИ для всех", разработанный пионером в области ИИ Эндрю Нг, предлагает его уникальную точку зрения на расширение ваших возможностей и вашей работы с помощью генеративного ИИ. Эндрю расскажет вам о том, как работает генеративный ИИ и что он может (и не может) делать.
8 Innovation Management - вы разовьете инновационное мышление и получите знания о том, как компании успешно создают новые идеи для продвижения новых продуктов на рынок. В программу также включены занятия по инновационной стратегии, управлению идеями и социальным сетям.
И даже если не любили раньше, возможно полюбите после поста про синтвйев киберпанк котиков и песиков.
WARNING много тяжёлых и красивых картинок под катом.
Я использовал дообученную на синтвейве модель и Stable Diffusion в сборке automatic 1111.
Просто скачиваете модель и устанавливаете как обычно, затем выбираете модель в интерфейсе и используете в конце промпта snthwve style.
Промпт тут в целом используется один и дает очень хорошие результаты: super realistic painting of a cyborg cat with braids combined with flowers, colorful, highly detailed, 4k, trending on artstatiotion.
Как вы уже догадались cat отлично заменяется на любое другое животное или персону. CFG scale 7-10 показывает приятный глазу результат. Семплер DPM++ 2M Karras, 50 шагов. Разрешение рендеринга 512х512. Все картинки увеличены в 4 раза апскейлером Lanczos. Апскейлер для детализации тот же.