У меня большой соблазн написать: "Вы описали устаревший подход. Я тоже так думал, и поэтому год назад завалил собеседование в 'Эпл' и 'Амазон', причем в первом незнакомтсво с общепринятым в современности подходом было одной из главных причин, почему мне отказали на самом последнем этапе (шестое интервью после пяти успешно пройденных). Сейчас коллаборативная фильтрация обычно реализуется совсем по-другому, ее обычно уже и не называют коллаборативной фильтрацией".
Но на самом деле это было бы несправедливой придиркой. Да, коллаборативная фильтрация в том виде, как вы ее изложили, это технологии 2010-х годов, от которых давно отходят. Но так как ваше изложение все равно очень короткое и поверхностное, в принципе, под него можно притянуть и современные подходы - и иногда так и делают. Если поискать сочетание терминов collaborative filtering и two tower, последнее часто описывают как частный случай первого. Но чаще нейросетевые подходы к рекомендательным системам рассматривают, не упоминая коллаборативную фильтрацию.
В общем, коллаборативная фильтрация активно используется и сейчас. Но вот это ваше описание:
Допустим, недавно Вася посмотрел до конца и поставил высокую оценку вот таким тайтлам: Мастер и Маргарита, Атака Титанов, Фишер, Игры
А Петя сделал то же самое вот с таким контентом: Киберслав, Атака Титанов, Фишер, Игры
Итак, у Васи и Пети все тайтлы одинаковые, кроме одного различия: Мастер и Маргарита против Киберслава (ставьте лайк, если хотели бы увидеть такой кроссовер). По логике КФ, если пользователи “обменяются” своими 4 тайтлами (Вася глянет Киберслава, а Петя М&М), то им должно понравиться. Собственно, отсюда и слово “коллаборативная” в названии - пользователи как бы сотрудничают, подкидывая наилучшие рекомендации друг другу.
- это очень упрощенный пересказ того, как работали рекомендательные системы 10 лет назад. Подробнее он изложен, например, в книге Лесковеча, Раджарамана и Ульмана. Только эта книга издавалась и переиздавалась с 2010 по 2019 годы. Сейчас рекомендательные системы работают по-другому.
Если вы собираетесь проходить собеседования на специалиста по машинному обучению, рекомендую хотя бы поверхностно ознакомиться с темой современной коллаборативной фильтрации. Тем более что схожие подходы используются и в других областях: так сейчас делают и поиск, и распознавание лиц...
Вы приходите домой и включаете любимый стриминг. Лента сразу же выдаёт вам несколько фильмов и сериалов, которые… действительно хочется смотреть. Сегодня разберём, как именно рождается эта магия вне Хогвартса, и что сидит под капотом рекомендательного движка онлайн-кинотеатра.
Это крайне сложный мем про онлайн-кинотеатры и всю индустрию стриминга в целом. Просьба отнестись с пониманием и проникнуться глубиной!
Так как лично я чаще других сервисов включаю Кинопоиск (да, я посчитал с точностью до минуты), то детализировать детали и анализировать нюансы я буду именно на его примере. И да, в этой статье не будет сложных технических терминов и греческих букв. Её цель - раскрыть основные принципы стримингов человечьим языком и наглядно.
Итак, погнали:
Этого стриминга в Химках видал, неточными рекомендациями торгует!
Давайте пойдём поэтапно. Что нужно сделать онлайн-кинотеатру, чтобы быть классным? Рискну предположить, что сначала ему нужно вот что:
Составить хорошую библиотеку. Добавить к себе сериалов и фильмов крутых и разных, да побольше!
Набрать пользовательскую базу. Чтобы я, вы, ваша мама, ваш коллега и вон тот парень оформили подписку. Но не только - важно, чтобы вы ещё регулярно смотрели (почему - объясню ниже, это важный момент).
Итак, у нас есть контент, и у нас есть пользователи. Говоря более научно, есть item, и есть user. И теперь кинотеатру нужно сделать третий шаг, ключевой:
Соединить user и item. Проще говоря, дать пользователю Васе именно тот фильм, сериал или аниме по манге (мало ли от чего прётся наш Василий), который ему а) нужен в целом и б) актуален прямо сейчас.
Но как это сделать?
Вариант первый - плясать от юзера Васи (user-based recommendations). Допустим, мы видим, что Вася с кайфом посмотрел последний российский детектив про жуткого маньяка. Ну окей, пульнём ему другие леденящие душу истории про серийных убийц. Но что если ему понравился именно тот детектив, а новые не зайдут?
Хорошо, тогда можно использовать обратный подход - плясать от контента (item-based recommendations). Пусть алгоритмы глянут, что там "сидит" внутри этого детектива - сюжетные повороты, темп повествования, атмосфера, антураж, локации, год выпуска, набор актёров, подмешивание других жанров и т.д. Находим максимально похожий тайтл и кидаем его Васе на первое место в ленте!
Но Вася проходит мимо и садится смотреть турецкий сериал с Серканом Болатом, или как там его зовут. Почему? Да хрен его знает. Может после того сериала у него детективный передоз, и больше он не хочет смотреть на мрачные расследования? А может Вася планирует поездку в Турцию, и хочет полюбоваться видами Стамбула? Или ещё проще - у Васи появилась девушка, и пульт теперь у неё (ну или мы просто чего-то о нём не знаем). Люди - существа иррациональные, причин может быть очень много, а на поверхности - ни одной.
Раз уж вспомнили турецкие сериалы, то держите уютного стамбульского котика (запомните этот момент, это пасхалочка ко второй половине этой статьи).
Как видите, чистый user-based и item-based - это упражнение, конечно, интересное, но полезное лишь для общего развития. А для точных стриминговых рекомендаций нужно что-то позабористее. Но что?
Существует три вида лжи…
… ложь, наглая ложь и статистика. Так про статистику говорил то ли Бенджамин Дизраэли, то ли Марк Твен (но не Ленин, как многие думают, Ильич как раз статистику очень любил и уважал). Смысл цитаты в том, что статистическими выводами можно:
а) вертеть как угодно
и б) делать это на максимально серьёзных щщах
Ведь вывод будет подкреплён (ну, типа) анализом выборки, а не просто взят с потолка.
Не буду спорить, но в случае рекомендательных систем - это вовсе не минус, а очень даже плюс. Потому что нас интересует не единственно верная истина, а набор наиболее релевантных вариантов. Но давайте конкретнее:
В рекомендательных системах онлайн-кинотеатра выбор на основе большой статистики воплощён в виде коллаборативной фильтрации (КФ). КФ - это база-основа любого годного стриминга, от Ютуба до Яндекс Музыки. Онлайн-кинотеатры в целом, и Кинопоиск в частности - не исключение.
Давайте разберём, что это такое:
Коллаборативная фильтрация работает на предположении, что:
Пользователи, которые одинаково оценили какие-либо тайтлы (т.е. фильмы/ сериалы) в прошлом, склонны давать похожие оценки другим тайтлам в будущем.
То есть, если фильм "Ромашка" понравился многим пользователям с похожей историей просмотров, то он скорее всего понравится и другим пользователям с такой же (или почти такой же) историей просмотров.
Давайте на примере (очень упрощённо и схематично):
Допустим, недавно Вася посмотрел до конца и поставил высокую оценку вот таким тайтлам:
Мастер и Маргарита
Атака Титанов
Фишер
Игры
А Петя сделал то же самое вот с таким контентом:
Киберслав
Атака Титанов
Фишер
Игры
Итак, у Васи и Пети все тайтлы одинаковые, кроме одного различия: Мастер и Маргарита против Киберслава (ставьте лайк, если хотели бы увидеть такой кроссовер). По логике КФ, если пользователи “обменяются” своими 4 тайтлами (Вася глянет Киберслава, а Петя М&М), то им должно понравиться. Собственно, отсюда и слово “коллаборативная” в названии - пользователи как бы сотрудничают, подкидывая наилучшие рекомендации друг другу.
Понятное дело, что пример выше упрощён до неприличия. В реальности должны быть не Вася с Петей, а несколько сотен тысяч (а лучше миллионов) юзеров, и тайтлов в анализе должно быть слегка больше четырёх. И тогда рекомендательная система может на больших данных глянуть, что смотрят юзеры с похожими предпочтениями, и сделает статистически значимый вывод.
Чтобы было ещё понятнее, давайте проведём аналогию с чем-нибудь из жизни. Я вот с утра в зал сходил, давайте с ним и сравним:
Представьте какой-нибудь суперумный фитнес-зал (ИИшка видит его так), где камеры под потолком анализируют ВСЕ действия ВСЕХ посетителей.
Зал видит, что вы сделали жим сотку, гантели по тридцатке и пошли на кардио. А ещё он в своей базе данных видит, что были другие посетители, которые делали то же самое. Многие из них ещё делали румынскую тягу и французский жим. Логично будет порекомендовать эти упражнения и вам (вероятность попадания будет статистически высокая).
Однако, что будет, если вам нельзя делать румынскую тягу по медицинским показаниям, а во время французского жима вы год назад уронили гантелину на голову и теперь у вас психологический блок на это упражнение? Или ещё прикольнее - система подобрала целых 10/ 20/ 50/ да хоть тысячу статистически актуальных упражнений. Какое порекомендовать первым, а какое последним? И вообще, зачем всех под одну гребёнку пихать? Я же уникальная снежинка, предложи мне что-нибудь эдакое!
Вот и с контентом в онлайн-кинотеатре то же самое.
А что если Вася сильно отличается от других юзеров, которые смотрели похожие тайтлы?
А если актуальных рекомендаций много, то какую порекомендовать первой, второй, двадцать седьмой?
И вообще, настроение у Василия игривое, он хочет сюрпризов, удивите!
Или ещё сложнее - что если Вася только-только зарегался на Кинопоиске, и у него ещё нет никакой истории (a.k.a. “холодный юзер”)?
(Cat)бустим коллаборативную фильтрацию
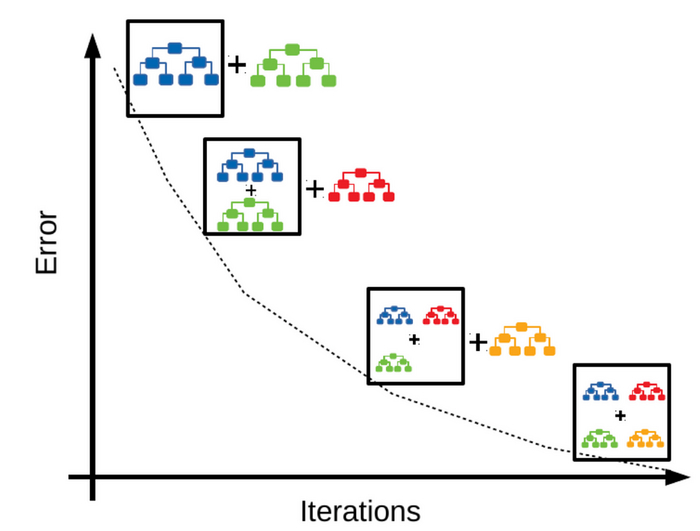
Для преодоления вышеописанных преград, коллаборативная фильтрация отлично дополняется градиентным бустингом. Для начала очень кратко распишу, что это вообще за зверь такой:
Итак, градиентный бустинг - это такой метод машинного обучения, когда несколько “небольших” моделей применяются последовательно, и каждая из них исправляет ошибки предыдущей. Шаг за шагом ошибка становится всё меньше и меньше, а результат всё точнее и точнее.
Логика примерно такая. Берём дерево решений и пускаем по нему алгоритм. Смотрим, насколько существенна ошибка функции. Добавляем ещё дерево и запускаем новую итерацию. Ошибка становится меньше. И так далее, пока ошибка не минимизируется.
Множество маленьких моделек градиентного бустинга ещё называют “ансамбль моделей”. По-французски emsemble значит "вместе", ну вы поняли.
Давайте разберём на примере пиццы. Ну а что, в зал мы уже сходили, так что имеем право.
Итак, допустим, вы понятия не имеете, как готовить пиццу (= не знаете юзера Васю), но слышали, что её делают из теста и сыра. Вы кидаете кусок теста и сыра в печку. Получилась дрянь. Вы думаете: “А что, если раскатать тесто и положить на него сыр?”. Уже лучше, но тесто сгорело. Вы повторяете попытку, уменьшая жар. Ещё лучше, но сыр подгорел. Вы насыпаете его более равномерно. Отлично, но не хватает томатной пасты. Вы добавляете пасту. Теперь это уже похоже на пиццу, но всё равно есть что улучшать. Вы можете дальше повторять итеграции, играясь с рецептом и технологией готовке, пока у вас не получится идеальная пицца как у дядюшки Джузеппе.
Градиентный бустинг в онлайн-кинотеатре работает точно так же, только шагов и ошибок в “дереве решений” может быть гораздо-гораздо больше, ну и тесто с сыром не нужно портить (это ж машинное обучение, в конце концов).
У Кинопоиска за градиентный бустинг отвечает штука под названием CatBoost.
Кэт буст. Вижу так.
CatBoost - это набор библиотек (= готовых шаблонов и решений) градиентного бустинга, который Яндекс использует во многих своих сервисах: в маркетплейсе, прогнозе погоды, рекламных системах, музыкальном стриминге и т.д. Ну и в онлайн-кинотеатре, само собой.
“Cat” здесь значит “категориальный”, то есть модель заточена на работу с категориями, а не только с числовыми данными. Она умеет мыслить не только понятиями "один-ноль" и “больше-меньше”, но и отличать кошечку от собачки, Турцию от Кореи (а Южную Корею от Северной), детектив от триллера (или от комедии, хоррора, пеплума, …), Юру Борисова от Ванпанчмена и т.д.
С последним могут возникнуть проблемы. Не, ну правда, тут придётся очень много моделек запускать.
Итак, вернёмся к нашему юзеру Васе.
Сценарий первый. Коллаборативная фильтрация отобрала ему 50 самых-самых релевантных фильмов. И ещё 10 сериалов в качестве бонуса. Как всю эту очередь расставить в ленте?
Допустим, в списке есть Начало и Интерстеллар. Кого поставить выше? CatBoost видит, что Вася ставил всем фильмам Нолана оценку 8+ (любит он Нолана, в общем). Также он видит, что Вася плюс-минус одинаково хорошо смотрит и Ди Каприо, и Макконахи. Он идёт дальше, перебирает другие факторы. И видит, что по вечерам Васе чуть лучше заходит космическая тематика. А ещё он в Яндексе недавно чёрные дыры искал - совпадение? Сейчас как раз вечер, так что поставим Интерстеллара чуть выше Начала.
Понятно, что в реальности алгоритм будет ранжировать (да, забыл сказать, такая операция называется “ранжирование”) из множества единиц контента и одновременно учитывать сотни и тысячи единиц информации о пользователе. Но логика такая.
Сценарий второй. Вася из другой реальности (скажем, с Земли-616) только-только зарегался на Кинопоиске. Данных по нему нет, сравнить с другими пользователями не выйдет, коллаборативно фильтрануть не получится. Но! Во-первых, он наверняка зарегается не просто так из вакуума, а придёт за определённым тайтлом.
Ну например, увидит сериал “Игры” и такой: “О, это мне надо, хочу смотреть на младшего Верника в антураже брежневского Союза”. И оформит подписку.
И алгоритмы такие: “Ага, ему нравится младший Верник (ну или Серебряков, единственный в своём роде), антураж СССР, спортивная тематика, драмы с элементами детектива, современные российские сериалы, …”. Это всё гипотезы, каждую из них CatBoost может начать отрабатывать. Рекомендовать, смотреть на результат. Рекомендовать дальше, улучшать результат, отрабатывать ошибку. И так далее, далее, далее. Повышая знание о пользователе, учитывая всё новые факторы, делая “градиент” всё более плавненьким. В какой-то момент у Василия будет достаточно истории, и его получится нормально запихнуть в коллаборативную фильтрацию.
Если Вася всё же пришёл из ниоткуда (действительно холодный юзер), то ему сначала дадут глянуть что-нибудь из самого популярного. Посмотрят, как он реагирует на разные тайтлы из топ-10, а дальше см. выше.
Знания о пользователе крутятся, кэт бустится.
Здесь ещё можно было бы разобрать, какие факторы учитываются в градиентном бустинге, как именно алгоритм достаёт эти данные, с какой скоростью он учится… и многое другое.
Однако, статья и так получилась чуть больше, чем я планировал, поэтому на этой ноте откланяюсь. Напоследок держите набор простейших действий, способных здорово помочь КэтБусту и натренировать Кинопоиск. С другими онлайн-кинотеатрами тоже должно сработать - вплоть до Netflix или даже Youtube (последний - это тоже своего рода стриминг). Итак:
Ставим высокие оценки фильмам и сериалам, которые вам нравятся, и низкие - тем, которые не зашли. Для этого в конце просмотра есть специальная голосовалка, не пропускаем её.
Если листаем ленту и видим что-то прикольное, не стесняемся добавлять в “Буду смотреть”.
Если видим, что рекомендательная система прогадала и запихнула в ленту залётные неактуальные тайтлы, то прожимаем кнопку "Неинтересно".
Если вас зацепил какой-то фильм или сериал из ленты, но вы не хотите его смотреть прямо сейчас, то можно включить его хотя бы на пару минут (а лучше минут на 5-10). Это станет важным сигналом для рекомендательных систем.
Если не забывать про эти простые шаги, то алгоритмы скажут вам “спасибо”, коллаборативная фильтрация станет ещё более меткой, а вы сможете тратить ещё меньше времени на поиск персонализированной актуалочки.
Очень надеюсь, что вам стало понятнее, по какой логике алгоритмы этих наших стримингов вываливают на нас именно те фильмы, сериалы и прочее народное творчество, которое актуально, релевантно и желанно именно нам и именно в данный конкретный момент времени.
P.S. Понятно, что выше я описал основные подходы и базовую логику их применения. На самом деле сложность и продвинутость сего действия нужно умножить на дцать, и вообще, там всё переплетено так, что мама не горюй. Но принцип именно такой.
Если вам понравилось, то подписывайтесь на мой тг-канал Дизраптор, где я человечьим языком разбираю интересное из технологий, инноваций и бизнеса. А на втором канале Фичизм выходят самые кайфовые фичи и всё такое.
Доброго времени суток форумчане! Это мой первый пост и маленький крик души! (Не сочтите за рекламу).
Друзья, уже в течении 3-х лет существует пост данного предложения для приложения кинопоиска для тв. и у меня появилась идея.., у меня небольшая просьба, по большей части, к тем кто пользуется данным сервисом, но и к другим, кто не может стоять в стороне равнодушным, заранее большущие спасибо.
Давайте добьемся поиска треков в КиноПоиске! Друзья, я обратился в поддержку КиноПоиска, чтобы выяснить, почему в разделе "Музыка" приложения для телевизора до сих пор отсутствует функция поиска треков. Вот что они ответили:
"При реализации идей мы учитываем их актуальность, количество голосов и технические моменты. Сделать что-то новое не всегда получается быстро.".
Повторюсь, предложению уже 3 года, а подвижек к его реализации нет. Сложилось впечатление, что недостаток голосов является препятствием для внедрения этой функции. Если мы хотим изменить ситуацию, нам нужно больше единомышленников, готовых поддержать эту идею. Предлагаю всем неравнодушным объединиться, и проголосовать за продвижение идеи! надеюсь вместе мы сможем сделать КиноПоиск более удобным для всех пользователей.
👉 Проголосовать можно здесь (для голосования необходимо зарегистрироваться в сервисе предложений)
😊P.S. Надеюсь, что идея о поиске треков в разделе "Музыка" будет реализована в ближайшее время!
1) Текущая ситуация с оценками и соответственно с рейтингом фильмов:
Многие понимают что хорошим фильмам надо ставить высокие оценки и так сильно это понимают, что забывают, что одновременно с этим надо средним фильмам ставить средние оценки и плохим - низкие, худшим фильмам - минимальную оценку 1, лучшим - максимальную 10. На Кинопоиске оценок 7, 8, 9, 10 - 80%, средняя оценка - 8,1.Оценки 1 и 10 одинаково нужны, просто они противоположные, но оценок 1 - 3%, а оценок 10 - 40%, в 13 раз больше.
В основном используют только 3-4 оценки из 10, только высокие или только средние, то есть все фильмы по их оценкам получаются только хорошие или только средние. Первые, фильмам, которые они сами же считают худшими, ставят 7 или 8, не могут же ставить ниже, стесняются поставить 1 как надо, завышают до высоких, равняют их с хорошими фильмами и портят рейтинг.Неправильно оценивают - относительно 10 в одну сторону, уменьшения до 8 или 7. Вторые, кто ставит только средние оценки, хорошим фильмам занижают и также плохим завышают до средних.Нужно же делать наоборот - плохим занижать, а хорошим завышать! Такие оценки одного уровня никому не нужны, ими говорят что все фильмы одного уровня, не различают их.
Разные люди используют разные 3-4 оценки, это значит что одинаковые оценки разных людей имеют разные значения. Что означает оценка, например 8, от людей по разному оценивающих: От того кто ставит оценки только 8, 9, 10 - 8 его минимальная оценка, значит кино плохое, худшее. От того кто ставит оценки только 7, 8, 9 - 8 его средняя оценка, значит кино среднее. От того кто ставит оценки только 6, 7, 8 - 8 его максимальная оценка, значит кино хорошее, лучшее. Так как десятибалльная шкала используется разными людьми только частично и неправильно и по разному - оценки и рейтинг вообще ничего не значат.
2) Совет про оценки для выбора фильмов, до просмотра будете знать, понравятся вам они или нет:
Лучше тремя оценками использовать весь диапазон десятибалльной шкалы. 3 оценки соответствуют трём группам в которых 10 оценок: низкие (1, 2, 3), средние (4, 5, 6, 7) и высокие (8, 9, 10).Нет никакого смысла выбирать из оценок одного уровня, они же почти одинаковые, лучше их объединить. 1) Из группы высоких оценок лучше взять 10, для лучших фильмов, которые интересны, нравятся и рекомендуешь другим. 2) Средняя оценка из 10 - 5,5, округляем, завышаем за проявление интереса до 6 для средних, нормальных фильмов.Проще оценивать относительно центра 6 в обе стороны до предела - уменьшения до 1 и увеличения до 10. 3) Из группы низких лучше взять 1, для худших фильмов, которые не интересны, не нравятся и не рекомендуешь, чтобы другие зря не тратили на них время.
Не количество вариантов оценок важно, а равное количество минимальных, средних и максимальных оценок. У того кто использует 10 оценок в идеале должно быть по 10% просмотренных фильмов с каждой оценкой: 30% худших фильмов с оценками 1, 2, 3; 40% средних фильмов с оценками 4, 5, 6, 7; 30% лучших фильмов с оценками 8, 9, 10. У того кто использует 3 оценки в идеале должно быть по 33% просмотренных фильмов с каждой оценкой: 33% худших фильмов с оценкой 1; 33% средних фильмов с оценкой 6; 33% лучших фильмов с оценкой 10.
Соответствие и разница основных оценок 1, 6, 10 с десятью оценками, на которые они делятся: 10 и 8, 9, 10 - Лучшим оценка выше: +2, +1, 0. 6 и 4, 5, 6, 7 - Средним: +2, +1, 0, -1. 1 и 1, 2, 3 - Худшим оценка ниже: 0, -1, -2. Если наоборот, переходить с 3 оценок на 10, то нужно из худших фильмов с оценкой 1, выбрать 1/3 и поставить им 2 (+1), ещё 1/3 и поставить им 3 (+2).Также и с остальными.Зачем их делить?Пусть будет 1. Нет смысла делить 1, 6, 10 на 10 оценок и наоборот - увеличивать оценку тем что не нравятся и уменьшать тем что нравятся.2 оценки - это мало, а 4 - уже много, лучший вариант это 3 оценки, остальные 7 оценок вообще нисколько не нужны.
Тремя оценками проще чётко обозначить свои интересы.Хорошие фильмы максимально отделяются от плохих с разницей в 9 баллов.Так будет максимальное влияние своими интересами на общий рейтинг фильмов и рейтинг по оценкам 300 друзей по интересам на Кинопоиске, которые набираются по совпадению и близости оценок. Те, кто будет занижать хорошим и завышать плохим для вас фильмам (особенно если максимально на 9 баллов), пропадут из вашего списка друзей по интересам, их заменят максимально подходящие и ориентируясь на их оценки до просмотра кино будете знать, понравится вам оно или нет.
3) Влияние:
У людей разные интересы и с оценками 1, 6, 10 влияют на рейтинг по средней оценке в 4,5 раза больше, чем с любыми тремя оценками рядом идущих (8, 9, 10 например).Потому что разница между худшими и лучшими фильмами у первых - 9 баллов, а у вторых всего 2.
4 примера как оценки 1, 6, 10 влияют на рейтинг по оценкам 8, 9, 10: 1) Три человека с одинаковыми интересами поставили трём фильмам оценки 8, 9, 10, рейтинг этих фильмов - соответствующий - 8, 9, 10, но пришёл один с противоположными интересами (для них худший фильм - для него лучший), поставил 10, 6, 1 и развернул порядок фильмов по рейтингу наоборот, в свою сторону, который стал 8,5, 8,3, 7,8.
2) Четыре человека (8, 9, 10) против одного (10, 6, 1) - рейтинг 8,4, 8,4, 8,2. Он им сравнял худший и средний, а лучший для них стал худшим по рейтингу, в пользу поставившего 10, 6, 1.
3) Пять человек (8, 9, 10) против одного (10, 6, 1) - рейтинг 8,3, 8,5, 8,5. Он им сравнял средний и лучший, пять человек смогли отстоять только худший для них.
4) Шесть человек (8, 9, 10) против одного (10, 6, 1) - рейтинг 8,3, 8,6, 8,7. Только шесть человек смогли отстоять свои интересы, порядок фильмов по рейтингу полностью совпал с порядком по их оценкам.Только им такой рейтинг не нужен, потому что он почти одинаковый, разница между лучшим и худшим всего лишь 0,4.
Большинство людей используют десятибалльную шкалу только на 30-40% - всем фильмам подряд ставят только высокие оценки, не различают их, не могут ставить оценки ниже 7.Неправильно мыслят - относительно 10 в одну сторону, уменьшения до 7.Такие оценки никому не нужны, ими говорят что все фильмы одного уровня - хорошие.То есть фильмам, которые они сами же считают худшими, ставят 7 или 8, а не 1 как надо, завышают, равняют их с хорошими и портят рейтинг.Стесняются поставить 1 худшим фильмам, а оценка 1 нужна также как и 10 - чтобы другие зря не тратили на них время. Оценок 7, 8, 9, 10 на Кинопоиске - 80%, статистика - https://www.kinopoisk.ru/votes/
Что означает оценка, например 8, от людей по разному оценивающих: От того кто ставит оценки только 8, 9, 10 - 8 его минимальная оценка, значит кино плохое, худшее. От того кто ставит оценки только 7, 8, 9 - 8 его средняя оценка, значит кино среднее. От того кто ставит оценки только 6, 7, 8 - 8 его максимальная оценка, значит кино хорошее, лучшее.
3 оценки соответствуют трём группам в которых 10 оценок: низкие (1, 2, 3), средние (4, 5, 6, 7) и высокие (8, 9, 10).Нет никакого смысла выбирать из оценок одного уровня, они же почти одинаковые, лучше их объединить. Очевидно же, что худшим фильмам надо ставить минимальную оценку 1, лучшим - максимальную 10, средним - среднюю 6.Из группы низких лучше взять 1, а из группы высоких - 10.Так хорошим фильмам оценка выше, а плохим ниже и они максимально отделяются с разницей в 9 баллов. Лучше тремя оценками использовать весь диапазон десятибалльной шкалы и мыслить относительно центра 6 (средних, нормальных фильмов) в обе стороны до предела - уменьшения до 1 и увеличения до 10.
Соответствие и разница оценок 1, 6, 10 с десятью оценками: 10 и 8, 9, 10 - Тем что нравятся оценка выше: +2, +1, 0. 6 и 4, 5, 6, 7 - Средним +2, +1, 0, -1. 1 и 1, 2, 3 - Тем что не нравятся оценка ниже: 0, -1, -2. Нет смысла делить 1, 6, 10 на 10 оценок и наоборот - уменьшать оценку тем что нравятся и увеличивать тем что не нравятся.
Так будет максимальное влияние своими интересами на общий рейтинг фильмов и рейтинг по оценкам 300 друзей по интересам на Кинопоиске, среди которых отсеиваются несовпадающие и набираются совпадающие по близости оценок. 1) Те, которые хорошему для вас фильму с оценкой 10, поставят свою минимальную оценку 8, то может показаться что интересы совпадают - оценки же одного уровня - высокие.Но это не так, для них это плохое кино, просто оценки ниже 8 они не ставят. 2) А если наоборот, плохому для вас фильму с оценкой 1 они поставят 10 (пускай даже 8), то тут уже разница максимальная, оценки противоположные, понятно что интересы не совпадают и такие люди пропадут из вашего списка друзей по интересам и до просмотра кино будете знать, понравится вам оно или нет.
Большинство людей не могут полностью использовать десятибалльную шкалу - не могут ставить оценки ниже 7.Мыслят - относительно 10 в одну сторону, уменьшения до 7.То есть фильмам, которые они сами же считают худшими, ставят 7 или 8, а не 1 как надо, завышают, равняют их с хорошими и портят рейтинг.Стесняются поставить 1 худшим фильмам, а оценка 1 нужна также как и 10 - чтобы другие зря не тратили на них время. Оценок 7, 8, 9, 10 на Кинопоиске - 80%, статистика - https://www.kinopoisk.ru/votes/
Лучше оценивать кино только с оценками 1, 6, 10, чем только с высокими 8, 9, 10, как большинство людей.Очевидно же, что худшим фильмам надо ставить минимальную оценку 1, лучшим - максимальную 10, средним - среднюю 6.Из группы низких (1, 2, 3) лучше взять 1, а из группы высоких (8, 9, 10) - 10.Так хорошим фильмам оценка выше, а плохим ниже и они максимально отделяются с разницей в 9 баллов.Лучше тремя оценками использовать весь диапазон десятибалльной шкалы и мыслить относительно центра 6 (средних, нормальных фильмов) в обе стороны до предела - уменьшения до 1 и увеличения до 10. Соответствие и разница оценок 1, 6, 10 с десятью оценками: 10 и 8, 9, 10 - Тем что нравятся оценка выше: +2, +1, 0. 6 и 4, 5, 6, 7 - Средним +2, +1, 0, -1. 1 и 1, 2, 3 - Тем что не нравятся оценка ниже: 0, -1, -2. Нет смысла делить 1, 6, 10 на 10 оценок и наоборот - уменьшать оценку тем что нравятся и увеличивать тем что не нравятся.
Так будет максимальное влияние своими интересами на общий рейтинг фильмов и рейтинг по оценкам 300 друзей по интересам на Кинопоиске, среди которых отсеиваются несовпадающие и набираются совпадающие по близости оценок. 1) Те, которые хорошему для вас фильму с оценкой 10, поставят свою минимальную оценку 8, то может показаться что интересы совпадают - оценки же одного уровня - высокие.Но это не так, для них это плохое кино, просто оценки ниже 8 они не ставят. 2) А если наоборот, плохому для вас фильму с оценкой 1 они поставят 10 (пускай даже 8), то тут уже разница максимальная, оценки противоположные, понятно что интересы не совпадают и такие люди пропадут из вашего списка друзей по интересам и до просмотра кино будете знать, понравится вам оно или нет.
3 оценки соответствуют трём группам в которых 10 оценок: низкие (1, 2, 3), средние (4, 5, 6, 7) и высокие (8, 9, 10).Нет никакого смысла выбирать из оценок одного уровня, они же почти одинаковые, лучше их объединить. А большинство людей выбирает оценки только из высоких 8, 9, 10, не понимая что есть ещё 7 оценок ниже и что они используют десятибалльную шкалу только на 30%.Такие оценки никому не нужны, ими говорят что все фильмы одного уровня - хорошие. Оценок 7, 8, 9, 10 на Кинопоиске - 80%, статистика - https://www.kinopoisk.ru/votes/ Мыслят относительно 10 в одну сторону - уменьшения до 7 или 8, когда лучше мыслить относительно центра 6 (средних, нормальных фильмов) в обе стороны - уменьшения до 1 и увеличения до 10.
Лучше тремя оценками использовать весь диапазон десятибалльной шкалы: 1) Очевидно же, что худшим фильмам надо ставить минимальную оценку 1 (а не 7 или 8 и равнять их с хорошими и портить рейтинг), лучшим - максимальную, средним - среднюю.Из группы низких лучше взять 1, а из группы высоких - 10, так хорошим фильмам оценка выше, а плохим ниже. Нужно чётко обозначить оценками какое кино хорошее, какое плохое и максимально отделить их с разницей в 9 баллов.А не фантазировать себе критерии оценки и всем фильмам подряд ставить только 7 или 8, и говорить ими что все фильмы одинаковые, не различая их, с разницей всего в 1 балл. 2) Десятую оценку нечестно будет добавлять в группу низких или высоких, они противоположно равнозначны, в них поровну по 3 оценки, поэтому в группе средних 4 оценки. 3) Средняя оценка из 10 - 5,5.По правилам математики округлять надо в большую сторону и за проявления интереса к фильму (захотел его посмотреть) лучше завысить оценку на 0,5 и поставить 6, чем занизить на те же 0,5 и поставить 5.
Разница между 1, 6, 10 и десятью оценками: 10 и 8, 9, 10 - Тем что нравятся оценка выше: +2, +1, 0. 6 и 4, 5, 6, 7 - Средним +2, +1, 0, -1. 1 и 1, 2, 3 - Тем что не нравятся оценка ниже: 0, -1, -2. Нет смысла делить 1, 6, 10 на 10 оценок и наоборот - уменьшать оценку тем что нравятся и увеличивать тем что не нравятся. У вас отсеются несовпадающие друзья по интересам на Кинопоиске, наберутся совпадающие и до просмотра кино будете знать, понравится вам оно или нет.
Топ 5 недооцененых фильмов в жанре мистика/хоррор с малым рейтингом, но от этого не являющихся плохими, а наоборот очень даже любопытными!
5: Два, Три, Демон Приди! - [ 2022 ] ( Фильм весьма атмосферный, от блоггеров Ютуба из Австралии, фильм с интересными взглядами на потусторонний мир )
4: Слендермен. - [ 2018 ] ( Фильм о подростках - девочках, которые лучше бы в куклы играли, а не ходили в одиночку по лесу, ну а если серьезно то очень жутковато монстра показали, атмосферу тоже нагнетают отлично в фильме )
3: Незваные. - [ 2009 ] ( Фильм про сестер, которые решили, что мачеха не достойна ихнего отца и началось... Но не всё так просто - смотреть до конца )
2: Тьма. - [ 2002 ] ( Фильм для тех кто действительно боится темноты, жуткие монстры, саспенс, религиозный бред, страх проникающий в тебя из темноты [ смотреть надо только ночью этот фильм ] - всё это присутствует в фильме и не худший сюжет ) P.S.: Не путать с сериалом Тьма от Нетфликс!
1: Сайлент Хилл Часть Вторая. - [ 2012 ] ( Фильм не только для поклонников игры, рейтинг 5 из 10 на КиноПоиске, что я считаю максимально не уместной оценкой, ребят ну Вы чего там на КиноПоиске? - фильм же реально прикольный! ... Какие монстры классные, а музыка, а атмосфера - я вообще молчу - вердикт: что - то тут не так - мистика какая - то { рейтинг должен быть выше } , смотрел этот фильм по Кабельному ТВ - до мурашек на спине как страшно было )
БОНУС ( сериал в жанре альманах ужасов ): Кабинет редкостей Гельермо Дель Торо. - [ 2002 ] ( Сериал реально вынес мне мозг местами, Удивительно, но факт: Критики разгромили этот сериал в пух и прах, назвав режиссёров ( там 8 отдельных историй, под руководством ) детьми неопытными и не интересными Гельермо Дель Торо...
НО детьми они ему не являются - а сериал очень мощный: каждая серия очень продуманная и поучительная в конце, смотрятся на одном дыхании и страшно и интересно...
Есть пару историй по Вселенной Говарда Ф. Лавкрафта и они удались как по мне... ( интересно - но Лавкрафта я начал читать лишь недавно ( лет 5 назад ) и остался в полном восторге от произведений Великого Автора! )
P.S.: Пишу этот текст в 3 часа 9 минут ночи ( напился кофе и заснуть не могу - это жесть какая-то), но публиковать буду завтра утром... Народ не пейте кофе позже 16 00 - а то можно не уснуть - это лютый Стресс для Организма!