
0 просмотренных постов скрыто



Иронично
Утилита управления версиями node.js для Windows. По иронии судьбы написан на Go.

Как сохранить список запрещенных в России в файл?1
ПРЕДЫСТОРИЯ
Однажды вечером, в конце рабочего дня, я получил в телеге от своего друга сообщения следующего содержания:
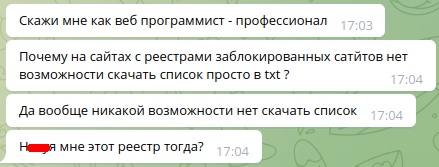
Что ответить на такой вопрос я не нашелся, но поинтересовался, а что, собственно случилось и зачем ем список этих сайтов вообще нужен?
Оказалось, что файл с этими данными нужен для того, чтобы по нему блочить сайты, на которые нельзя ходить студентам одного из наших учебных заведений, в котором мой друг имеет удовольствие трудиться. А тут выясняется, что он проверил 10 подобных сайтов и ни на одном не нашел возможности сохранить данные в файл.
Далее я опрометчиво предложил все нужные данные спарсить, а он возьми и согласись.
Мне была предоставленна следующая ссылка https://ruzapret.com. Тут оговорюсь, что другие сайты я не проверял и возможность скачать нужный файл лично не искал. Да и не в этом дело. Главное, что появился повод блеснуть выдающимися программерскими скилами.

Короче говоря, появилась задача - сделать простой инструмент для скачивания в файл всех запрещенных в России сайтов. Инструмент должен иметь минимум зависимостей и чтобы им мог воспользоваться человек, который работает с компьютерами, но не связан с программированием напрямую.
Поэтому я принял решение написать простенькую консольную утилиту на nodejs, чтобы можно было скопипастив одну строчку установить ее на компьютер, а скопипастив вторую - скачать себе весь реестр запрещенных сайтов.
Перейдя по полученной ссылке https://ruzapret.com я сразу же увидел кнопку API в верхнем меню и обрадовался - раз есть api, значит наверняка есть метод для получения списка сайтов! И это была ошибка. Изучая докумментацию апи я наткнулся на множество неработающих методов и страниц, которые никуда не ведут. Кроме того сама страница сайта рендерилась на сервере и ни к какому апи запросов не отправляла. Поэтому я решил побороть проблему лобовым методом. То есть написать классический парсер - качаем страницу, находим нужные места в html-коде, выдираем их и сохраняем в файл. И так 3573 раза - именно столько страниц на сайте.
Итого:
- В качестве ЯП был выбран JS, а точнее nodejs, потому что его леко установить и использовать даже не программирующему человеку. Кроме того, имеется обширная библиотека пакетов среди которых есть те, которые мне понадобятся.
- Сама программа должны быть консольной утилитой, которую можно просто скопипастить в консоль и скачать список файлов. В то же время, можно предусмотреть список параметров, если вдруг понадобиться как-то влиять на ход выполнения программы, ее вывод и т.д.
- В меру возможностей код попытаться сделать на спагетти, чтобы при необходимости иметь возможность дописать какие-нибудь нужные функции. Например сохранение в разные форматы файлов, парсинг только части реестра, парсинг только недостоющей в файле информации и т.д.
ПРОГРАММИРОВАНИЕ
После инициализации проекта и создания скелета получается такая вот файловая структура
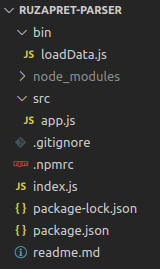
Утилита довольно простая и я решил разделить ее на три абстракции:
1) cкачивание страницы / работа с сетью
2) парсинг страницы / получение структуры данных пригодной для дальнейшей обработки
3) сохранение / работа с файловой системой
Так же будет нужна абстракция самого приложения, которая свяжет воедино все три перечисленных выше функции и точка входа.
Приступим. Начнем со скачивания страницы.
Даплее добавил файл src/loadData.js со следующим содержимым
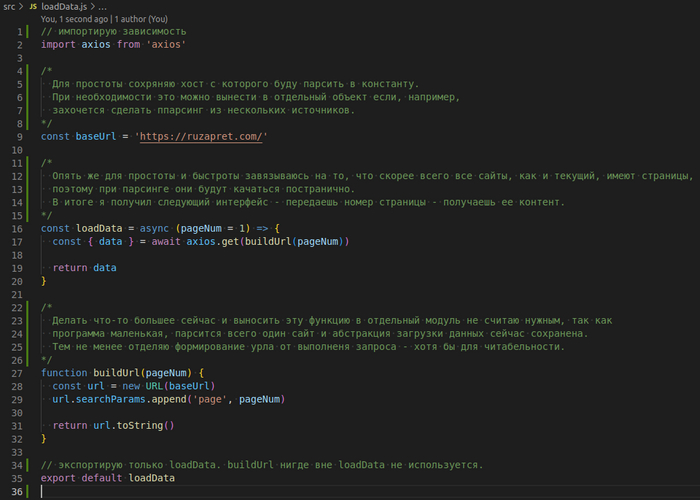
Когда страница скачана - самое время вынуть из нее нужные нам данные.
Но перед этим нужно решить в какой форме их возвращать. Для этих целей я решил добавить класс RecordNode, в который буду сохранять одну запись, хранящую в себе данные об одном сайте. Для парсинга одного источника это, конечно, немного лишнее, но если возникнет желание сохранять данные в разные форматы, то гораздо удобнее работать с унифицированным объектом. Вобщем класс RecordNode
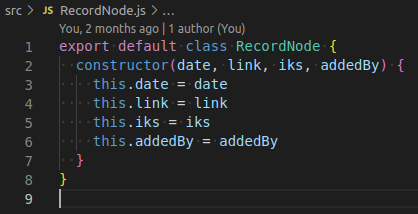
И еще один момент перед парсингом. Добавляю к проекту новую зависимосмть - cheerio. Эта библиотека позволяет работать на сервере с html-кодом в стиле старушки jquery. Получилось следующее

Отлично, теперь у меня есть структура данных, которая содержит в себе данные сайта, это значит, что можно приступить к сохранению в файл.
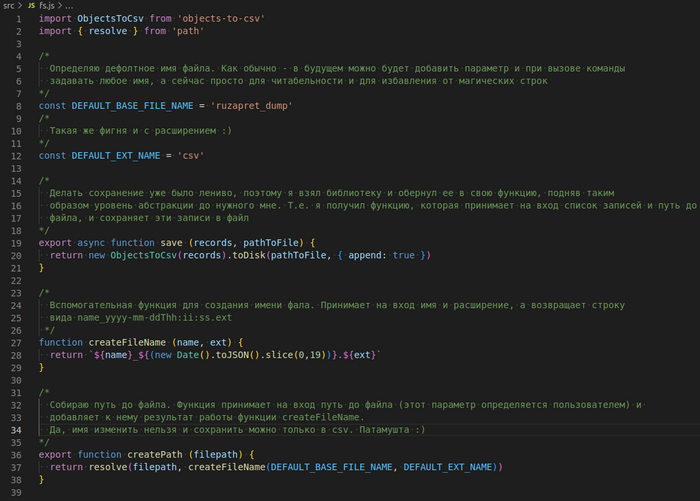
К этому моменту мне уже поднадоело заниматься утилитой, но бросать на пол пути не по-пацански :) Поэтому я быстренько нашел библиотеку для сохранения объекта в csv файл и добавил её в проеккт objects-to-csv.
Так же в этот модуль я добавил функцию для сборки пути до файла. В данном виде абстракция пока не протекает, все функции служат одной цели - сохранению в файл.
Получилось следующее
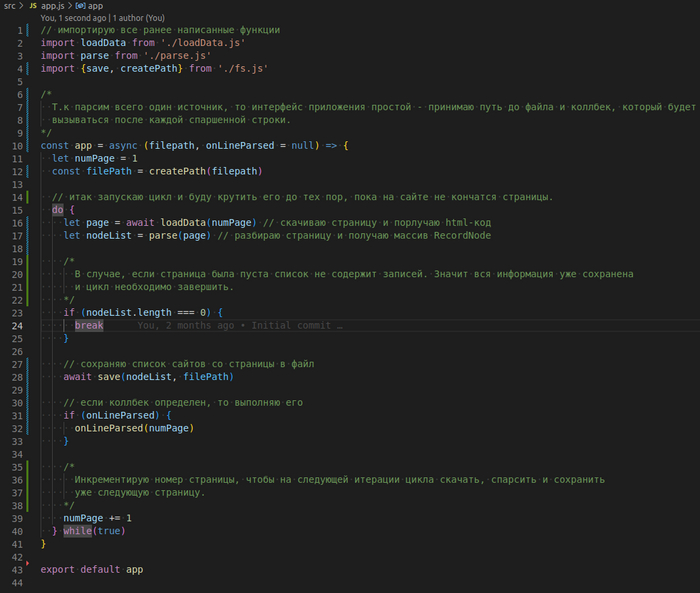
Уфф, практически все готово. Осталось объеденить три разрозненные функции в единое приложение. Добавляю фавйд src/app.js
Финишная прямая. Осталось описать запуск этого приложения.
Для начала добавляю в корень приложения index.js
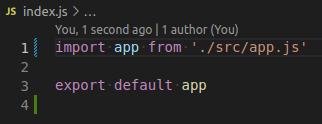
Теперь приложение инкапсулирует в себе все абстракции описанные выше и экспортирует наружу только главную функцию предоставляющую возможность спарсить данные.
Нужен только способор запустить приложение. Для этого я взял библиотеку commander,которая позволяет легко создавать cli утилиты.
Дело за малым. Я добавил файл bin/loadData.js который и станет точкой входа.
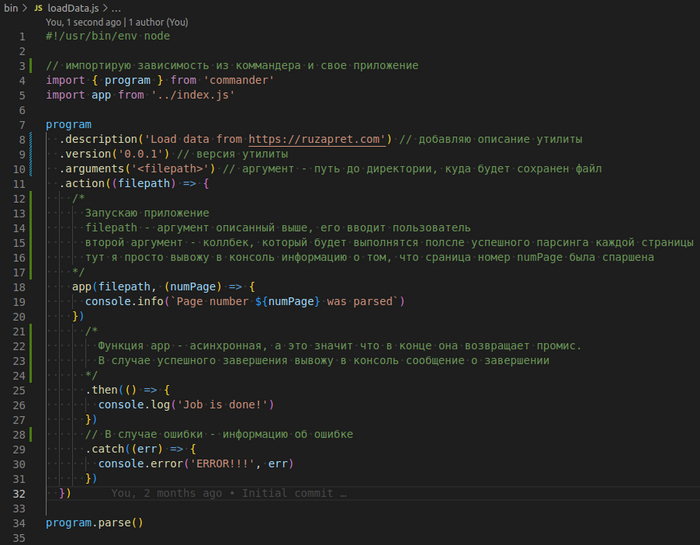
Так же в файле package.json необходимо описать запуск команды как исполняемый файл

Теперь просто выполняю npm link и вуаля: утилитой можно пользоваться
Выглядит работа утилиты примерно так:
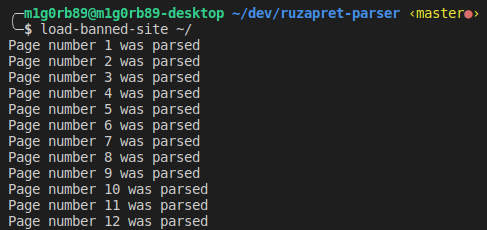
~/ - это тот самый параметр filepath, путь до места на диске, куда будет сохранен файл.
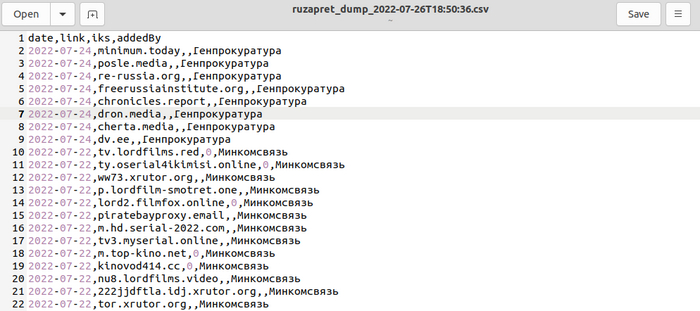
Результат работы выглядит так
ЭПИЛОГ
На написание утилиты потратил где-то часа 2, парсинг всех 3573 страниц занял минут 50, что весьма небыстро. И это неудивительно. Ведь операции выполняются последовательно, т.е. страница сначала качается, потом парсится, потом сохраняется и только потом начинается тот же процесс для следующей страницы. А это означает, что с каждой страницей процесс сохранения растягивается во времени, т.к. файл становится больше и больше.
Вобщем улучшать есть что. Распараллелить сохранение и скачивание, одновременно скачивать несколько страний, сохранять в файл пачками по несколько страниц, добавить больше параметров для влияния на утилиту, добавить возможность скачивать только определенные типы сайтов и тд, но это уже совсем другая история.

В любом случае утилита выполнила свое предназначение, т.к. мой друг, с которого эта история и началась, получил свой файл и инструмент, чтобы файл актуализировать.
P.S.
Если вдруг кому-то захочется ознакомится с кодом, то сделать это можно тут
Показать полностью
13

Срочно нужны Java-экзорцисты
#comment_240406835
@ngorco ты в телевизоре :)



Как я nodejs ставил в aaPanel
Наверняка есть люди, которые пытались установить сей полезный инструмент себе на VPS или домашний компьютер, приобщиться к миру прекрасного. Многие используют aaPanel для какого-никакого управления сервером, и вот я столкнулся с проблемой, что после установки node.js через менеджер пакетов в aaPanel, не работает команда npm для установки собственно приложения:
[root@vh14803 blabla]# node -v
v16.15.0
[root@vh14803 blabla]# npm install blabla/usr/bin/env: node: No such file or directory
Облазил интернет и stackoverfolw, и там рецепт :
[root@vh14803 blabla]# which npm
alias npm='/www/server/nodejs/v16.15.0/bin/npm'
/www/server/nodejs/v16.15.0/bin/npm
[root@vh14803 blabla]# hash -r
[root@vh14803 blabla]# npm -v
/usr/bin/env: node: No such file or directory
как бы не помог. Расстроился. Ясно, что где-то ссылка не прописана или не та. Поковырялся и подумал, а что если:
[root@vh14803 bin]# /www/server/nodejs/v16.15.0/lib/node_modules/npm/bin/npm-cli.js -v
npm WARN config init.module Use `--init-module` instead.
8.11.0
Уже хорошо, версию выдает. Тогда так:[root@vh14803 bin]# /www/server/nodejs/v16.15.0/lib/node_modules/npm/bin/npm-cli.js ---
init-module
npm WARN invalid config init-module=true set in command line options
npm WARN invalid config Must be valid filesystem path
npm WARN config init.module Use `--init-module` instead.
npm <command>
-----блаблаблаИ для проверки:
[root@vh14803 mesh]# npm
npm WARN config init.module Use `--init-module` instead.
npm <command>
Ну вот и всё! Оболочка знает об npm теперь!
[root@vh14803 blabla]# npm install blablabla
npm WARN config init.module Use `--init-module` instead.
added 145 packages, and audited 146 packages in 41s
А дальше указываем в aaPanel куда мы там все развернули
Кому-то может поможет.
Показать полностью

Спасибо пикабушнику @Kalter1
Без рейтинга.
Выражаю искреннюю благодарность пикабушнику @Kalter1 за помощь в реализации очень нужного сервиса.
В общих словах надо было помочь нашим менеджерам получать актуальные цены на нашу же продукцию. Ранее это было "на коленке" сделано в Excel, но оно и работало медленно, и доступно было было только из офиса, а чтобы обновить данные в этом файле надо было выполнить довольно нудный танец с бубном.
Очень хотелось сделать web сервис который бы заменил этот Excel документ.
Техзадание на эту работу было подготовлено еще в августе 2021 и с тех пор ждало своего героя.
Я периодически работаю с 4мя программистами, но ни один из них не спешил браться за эту задачу, предпочитая более привычные.
@Kalter1 же взялся и сделал даже быстрее оговоренного срока. Спасибо.
PS: Работа была не за отзыв если что. Отзыв это просто от избытка чувств)
Показать полностью

Прокси-серве для Яндекс.Музыки
Прошлой весной начал разбираться с OpenAPI и решил написать схему для Яндекс.Музыки. Проблема была лишь в том, что из-за CORS нормально пользоваться сгенерированной документацией невозможно. Чтобы отключить CORS в хроме приходилось запускать его с флагом -disable-web-security.
Решение скажем честно - не очень 👎. Правильным решением будет написание прокси-сервера, на котором были бы разрешены кросдоменные запросы. Другими словами, вместо того, чтобы напрямую обращаться к серверу Я.Музыки, на котором запрещены крос-доменные запросы, мы обращаемся к прокси-серверу, который перенапрявляет все наши вопросы к Я.Музыке и возвращает нам ответ. Так как CORS, есть только в браузере, то мы свободно отправляем запросы с нашего прокси сервера на сервер Я.Музыки.
Собственно, вчера я и написал такой прокси-сервер на основе библиотеки cors-anywhere и захостить его на хероку (https://yandex-music-cors-proxy.herokuapp.com/).
Теперь все запросы можно проксировать следующим образом:
https://yandex-music-cors-proxy.herokyapp.com/<any-url>
Например:
https://yandex-music-cors-proxy.herokuapp.com/https://api.mu...
Ресурсы:
- Исходники OpenAPI-схемы Я.Музыки
- OpenAPI документация Я.Музыки
Ещё по теме:
Показать полностью