
Ответ на пост «Перекличка мамонтов»2172
А были даже такие диски

А были даже такие диски
Для лиги лени: ничего нового, просто запускаю DiskSPD
Про тестирование и дисков и систем хранении написаны сотни статей, и ничего нового вы тут не увидите, проходите мимо.
Тестирование локальных дисков и систем хранения данных: подводные камни. Часть 2 - виртуализация
Тестирование локальных дисков и систем хранения данных: подводные камни. Часть 3 – цифры и предварительные итоги
Тестирование локальных дисков и систем хранения данных: подводные камни. Часть 4. Ребилд и прочие ситуации «ой пропали диски».
Что упущено в части 1.
Время тестирования. Оно имеет значение – поскольку речь про Windows, а в нем сама операционная система постоянно что-то кеширует. Прогрев кеша, попадание в него, вот это все – это вроде надо учитывать, но не понятно как.
Размер блоков. С этим интересно – поскольку для механических дисков разметка 512 \ 512e \ 520 \ 528 \ 4096 еще имела какой-то смысл. Для Optane или TLC \ QLC SSD, этот вопрос мне не понятен – все равно все сначала данные попадают в оперативную память SSD модуля.
Нагрузка при расчете parity. Для Storage space контрольные суммы вычисляет процессор, а он вовсе не оптимизирован под такие задачи – так что, используя диски с четностью, учитывайте и нагрузки на CPU.
Тестовые нагрузки при параллельном исполнении – будут исполняться где угодно. Это или баг, или фича планировщика, но планировщик CPU иногда балансирует нагрузку по тестовым потокам крайне странно.
Подходим снизу еще раз
Начну опять снизу. Когда мы создаем дисковый пул, через New-StoragePool, то у нас есть параметры:
LogicalSectorSizeDefault - 512 и 4096
MediaTypeDefault - HDD, SSD, SCM
WriteCacheSizeDefault
AutoWriteCacheSize
Причем последний параметр работает как-то не очевидно.
Следующий не очевидный момент – это работа storage bus cache из статьи Tutorial: Enable storage bus cache with Storage Spaces on standalone servers. Во первых, для storage bus cache нужен ReFS, во вторых: This feature requires your server to have the Failover Clustering feature installed, but your server can't be a part of a Failover Cluster.
Следом мы создаем новый том New-Volume, и уже там определяем
ResiliencySettingName
FileSystem
WriteCacheSize
ReadCacheSize
NumberOfColumns – этот параметр самый интересный, показывает:
Specifies the number of columns to use when creating the volume on a Windows Storage subsystem. Columns represent the number of underlying physical disks across which one stripe of data for a volume is written.
Кажется, что параметров даже слишком много, особенно в части кеширования.
Но не расстраивайтесь, в GUI ничего этого нет.
В остатке после всей пирамиды:
Дисковый пул и сами диски (SAS SSD и SAS NVME), разметка дисков и оперативная память.
Создаваемый поверх пула диск и его кеширование и разметка.
Создаваемый поверх диска том, и его кеширование и разметка.
И это только то, с чем будет работать даже не ОС гипервизора.
Особенности Hyper-V.
Hyper-V – это гипервизор типа 1.5. То есть, существует сам гипервизор, который грузится до загрузки операционной системы, со всеми своими minroot, VMQ, Dynamic VMMQ (d.VMMQ).
И, только после загрузки гипервизора, в первый раздел, грузится Windows Server. Иногда это приводит к комичным ситуациям – управляющая операционная система мертва, а все остальные виртуальные машины работают до перезагрузки. Сам не видел, а коллеги в российском филиале на бета-тесте русской версии ловили. Какой-то статистики набрать не удалось, но помогало удаление всех антивирусов, и переустановка на английскую редакцию. После декабрьских патчей не встречалось.
Отдельные особенности при создании дисков для виртуальных машин.
Командлет New-VHD предлагает параметры:
LogicalSectorSizeBytes
PhysicalSectorSizeBytes
С вариантами 512 и 4096 байт для обоих параметров.
При создании из GUI – диск создается с параметрами по умолчанию, и это не всегда хорошо, потому что создается он с PhysicalSectorSizeBytes = 512 и LogicalSectorSizeBytes = 4096, то есть с разметкой 512е
К чему это приводит? К тому, что гостевая ОС видит этот диск как .. как-то.
И поверх этой разметки делает NTFS, ReFS, EXT3, zFS или ZFS, Btrfs и так далее, со своим размером кластера. Для NTFS - 4KB и далее, в зависимости от размера диска, для Ext3 – 1,2,4 (иногда 8), Ext34 по умолчанию - 4 KiB. И так далее.
Что происходит в цепочке: Блок прилетает на файловую систему гостевой ОС. Гостевая ОС его транслирует в блоки по 512 байт и передает по цепочке ниже. Ниже живут блоки по 4096 байт, и каждый блок надо считать целиком, поменять в нем 512 байт, и записать обратно. Read-Modify-Write в ее лучшем виде.
Но что, если ниже у вас решили создать тома не по 16 терабайт, максимальный размер для NTFS с кластером 4096, а создали сразу на все деньги, все 20 терабайт? Получите блоки по 8 Кб, и не болейте.
Поэтому что надо делать? Смотреть надо, что делаете.
Дальше ситуация будет еще интереснее, потому что Microsoft рекомендует для MS SQL размер кластера в 64к, и такими блоками и будет писать на тот том, где лежит база данных. 64 килобайта, побитые на блоки по 4, побитые на блоки по 512, побитые ..
А, да. Там еще свое кеширование имеется.
Подводя итог
Получаем цепочку:
Уровень приложения внутри VM и размер страниц, которыми оперирует приложение.
Файловая система внутри VM
Логическая разметка виртуального тома
Физическая разметка виртуального тома
Файловая система на гипервизоре
Логическая разметка тома на гипервизоре
Физическая разметка тома на гипервизоре
и, если у вас все это еще и по сети – размеры блоков FC, и файловая система на томах, отданных с системы хранения данных. Сдается мне, не от хорошей жизни и ИИ на одном вендоре систем хранения только недавно ушли от лозунга «640 16 Тб должно хватить всем», а на другом вендоре нужно при создании тома выбирать, под что сделана оптимизация тома – раздел Planning Storage Resources, параграф Application Type, с текстом:
Each preset application type has a default application request size, 32 KB for Oracle_OLAP and SQL_Server_OLAP, and 8 KB for the remaining types.
The application type of a LUN cannot be changed after being set.
Inconsistency between LUN application types and actual I/O models may decrease LUN performance.
В следующих сериях:
Наконец-то цифры. Но это не точно

Прототип модуля SSD SanDisk (ранее SunDisk) для IBM (1991)
Разработана энергонезависимая флэш-память для систем массового хранения данных
Устраняя движущиеся части, твердотельный накопитель (SSD) обеспечивает надежность, низкое энергопотребление и производительность полупроводниковой технологии с привычной архитектурой хранения HDD.

Интегрированный чип SSD SanDisk (2010)
Первые коммерческие SSD появились в 1970-х годах, когда высокая скорость или надежная работа были первостепенными. Используя энергозависимые чипы RAM, поддерживаемые батареями и жесткими дисками для сохранения данных при отключении питания, StorageTek, Луисвилл, штат Колорадо, представила корпоративный SSD STC 4305, который хранил 45 МБ за 400 000 долларов в 1978 году.

Эли Харари с генеральным директором и соучредителем SanDisk Санджаем Мехротрой
Названная так из-за быстрого стирания по сравнению с более ранними устройствами, Flash EEPROM стала доминирующей технологией SSD. Изобретенная Фудзио Мацуокой из Toshiba в 1980 году, когда ячейка была сконфигурирована как NOR-вентиль, Flash обеспечивает произвольный доступ к любой ячейке памяти и служит прямой заменой чипов EE и EPROM. Ячейка NAND Flash, также изобретенная Масуокой, менее гибкая, но с меньшим размером чипа и лучшей выносливостью она больше подходит для приложений массового хранения.

Плата SSD Samsung 256 ГБ использует восемь чипов NAND емкостью 32 ГБ (2011 г.)
Эли Харари, который был пионером в области обработки тонкого оксида в Hughes Aircraft в 1970-х годах, стал соучредителем SunDisk (теперь SanDisk) в 1988 году для разработки технологии для цифровых камер. В 1991 году компания построила прототип модуля SSD для IBM, который соединил массив флэш-памяти с интеллектуальным контроллером для автоматического обнаружения и исправления дефектных ячеек и продемонстрировал практическое применение технологии для массового хранения. Многочисленные компании вышли на рынок флэш-чипов и специализированных систем хранения в портативных корпусах, таких как флэш- накопитель . Поскольку нетбуки и ультрабуки стали популярными, SSD-накопители стандартизировались вокруг форм-фактора 2,5-дюймовых ноутбуков. В 2006 году Samsung представила первый ноутбук Windows XP большого объема с использованием SSD-накопителей. Сегодня SSD-накопители составляют самый быстрорастущий сегмент рынка хранения данных.

Стив Джобс представляет рабочую станцию NeXT (октябрь 1988 г.)
В 1980-х годах емкость магнитооптических носителей информации превзошла емкость магнитных дисков.
Работа над магнитооптическими (МО) технологиями для хранения данных началась в 1950-х и 1960-х годах в Bell Telephone, Honeywell, IBM, 3M и других лабораториях в США, Европе и Японии. Запись и стирание информации на магнитооптических пленках использует термомагнитный процесс. При температуре окружающей среды материал имеет высокую коэрцитивную силу (меру легкости намагничивания) и не реагирует на приложенное магнитное поле.

Оптический диск NeXT в коробке
При нагревании до точки Кюри сфокусированным лазерным лучом пленка уменьшает коэрцитивную силу, позволяя электромагниту менять направление намагничивания. После охлаждения домен фиксируется и считывается с помощью эффекта Керра, который определяет направление намагничивания по вращению поляризованного луча отраженного света. Данные можно стирать и перезаписывать неограниченное количество раз.

П. Чаудхари, Дж. Дж. Куомо и Р. Дж. Гамбино — изобретатели MO-диска IBM
Ди Чен продемонстрировал хранение данных на тонких пленках MnBi в Honeywell, Миннеаполис, MN, в 1967 году. Полупроводниковые диоды излучения вывели на рынок коммерческие накопители с носителями на основе аморфных магнитных пленок, смонтированных в сменных картриджах, в 1980-х годах. Легендарная презентация Стива Джобса в 1988 году 256-мегабайтного 5,25-дюймового MO-накопителя в рабочей станции NeXT представила эту технологию мировой аудитории. Хотя он был чрезвычайно надежным и предлагал большую емкость, медленная запись сделала MO непригодным для приложений, отличных от защищенного и архивного хранения. Последние часто включались в роботизированные библиотеки.

Магнитооптический привод Sony RMO-S561 9,1 ГБ
Появилось много производителей приводов и носителей, включая гигантов HP, IBM, Kodak, Philips, Pioneer и 3M, а также стартапы Laser Byte, MaxOptix, MOST и Pinnacle Micro. 5,25-дюймовые диски предлагали емкость от 256 МБ до 9,2 ГБ, а форматы 3,5-дюймовых и Sony MiniDisc оказались популярными для Nintendo и других развлекательных систем. Более дешевые приводы CD/DVD и флэш-накопители в значительной степени заменили устройства MO.
Жертва - Win10.
Способ номер раз. На чистой установке с помощью diskpart создаем раздел в GPT и присваиваем ему букву A. Ставим винду. Результат - мы идем нахрен
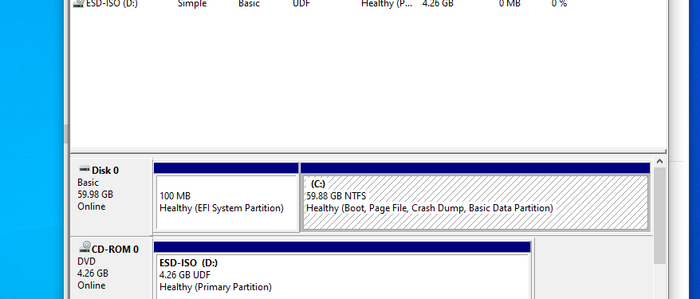
Способ номер два. Ну что же. Меняем букву диска и перезагружаемся. Ииииили нет, мы идем нахрен. Винда не даст это сделать.
К слову, здесь я использовал psexec -i -s чтобы повысить себя до уровня СИСТЕМА
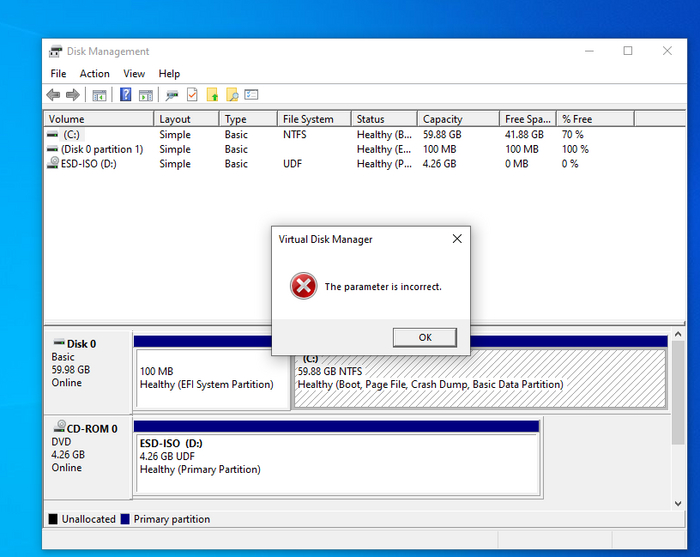
Способ номер три. Дискпарт после установки. Угадайте, что будет?

Правильно, мы опять идем нахер. Потому что дядя Гейтс (или же дядя Наделла) отобрали у нас дробовик и выдали водный пистолетик. Потому православно закурткобейнить систему мы не сможем даже если очень захочется.
Ну и не будем у них спрашивать, правда? У нас есть NIH. Много NIH.
Для начала закинемся акронисом.
И пока он идет путем эникея, мы заодно проверим что у нас в записи загрузки.
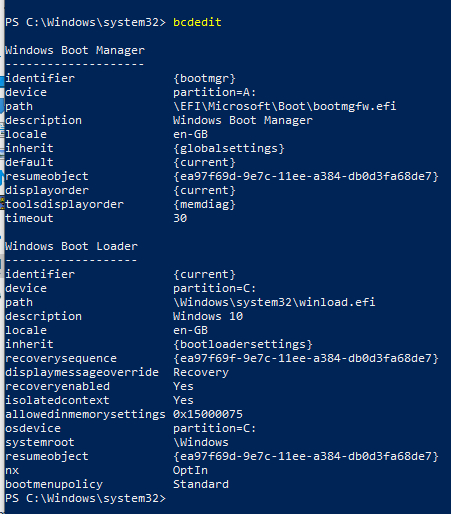
Вот так так. Оказывается, Майкрософт уже использует диск А: для загрузчика. То есть занять эту букву на этапе загрузки ядра мы не сможем. Ладно, давайте хотя бы попробуем изменить имя раздела на В:
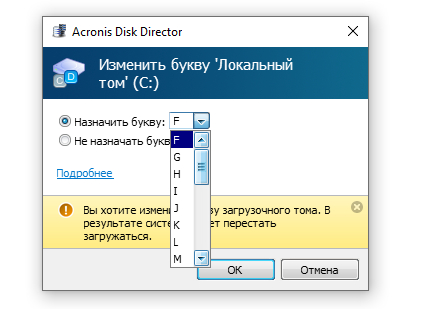
с точки зрения Акрониса мы тоже идем нахрен.
Напоследок применим темную магию.

Перезагружаемся. И идем нахрен.

Чисто технически это не все способы. Можно клонировать диск на другой партишен с помощью DD и подровнять загрузочную запись. Но стоит ли оно того?
Начать устанавливать раздел диска A в качестве системного, а в качестве дополнительного использовать раздел диска B и т.д.?





