Всем доброго дня. Помогите пожалуйста опознать элемент в корпусе sot23-3. В общем.. Имеется NAS фирмы Akitio, модель не известна. В один прекрасный момент из NASa вышел волшебный белый дым и единственный HDD, который стоял в NASe, перестал работать. Вскрытие показало что вылетел элемент по питанию жесткого диска. В этом NASe можно ставить 2 HDD, после установки харда во второй слот выяснилось что там все нормально, хард работает, при подключению к компу обмен данными идет. Перебросил такой же элемент со второго канала на первый, результат - все хорошо, HDD завелся. Осталось самое "простое", найти замену сгоревшему элементу... И тут меня постигла неудача... Я ничего не смог найти в инете по маркировке. С помощью LCR-T4 выяснил что это P-E-MOS. HELP! Помогите опознать элемент и подобрать аналог.
В желтых овалах 4 одинаковых элемента, сгорел там где красная стрелка, перекинут с места где голубая стрелка.
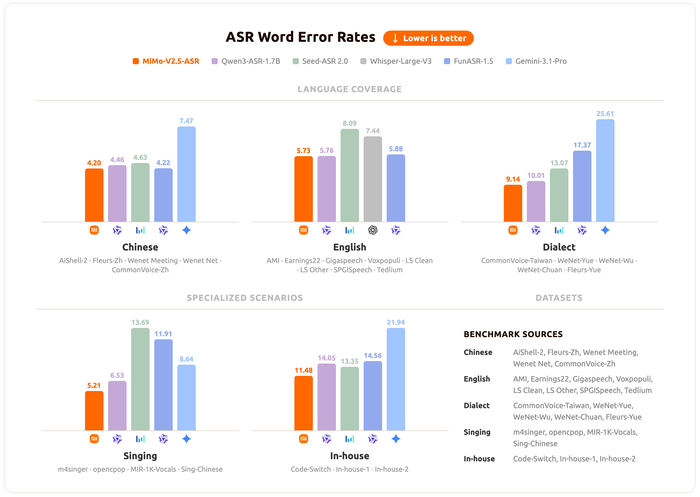
Она может распознавать китайский и английский, включая диалекты (у, кантонский, хоккиен, сычуаньский и др.), используя кодовое переключение без языковых тегов, распознавать пение даже с аккомпанементом, а также справляться с сильным шумом, далёким захватом и наложением голосов (многоговорящие сценарии). При этом она выдаёт точную транскрипцию сложного контента, включая классическую поэзию, термины, имена и техническую лексику со встроенной смысловой пунктуацией без постобработки.
Обучали её на крупномасштабном mid-training, качественном SFT и новых алгоритмах обучения с подкреплением (RL).
В результате модель хорошо себя показала на публичных и внутренних бенчмарках, превосходя Qwen3-ASR, Seed-ASR 2.0, Whisper Large V3, FunASR-1.5 и Gemini-3.1-Pro по среднему WER во всех категориях.
Любой компьютер (смарт - это тоже компьютер) с микрофоном, или с камерой за тобой бдит, чтобы своевременно тебе подсунуть "нужную" тебе рекламу - это же очевидные вещи.
Это бдение в ряде случаев поможет бороться с потенциальным терроризмом, а также иными преступлениями.
Как пример, камеры сейчас везде вешают - никто не возмущается, и раскрываемость, кстати, улучшилась заметно.
Случись сейчас с нами какое-то несчастье на улице, мы все чаще и чаще крутим головой в надежде найти камеру, смотрящую на место, где нам причинили ущерб.
Весь мир идет по пути тотальной слежки - чего ты этого боишься, неизбежного и непредотвратимого? Может ты злодей, или глупец, воюющий с ветряными мельницами?
Тебя напрягает, что ты не можешь теперь говорить и делать то, что раньше мог говорить и делать? Даже несмотря на то, что то, что ты говорил и делал нарушало закон (иногда).
Ну так это результат не слежки, а изменения текущих законов в угоду заинтересованных лиц.
Результат слежки - увеличение степени неотвратимости наказания (ответственности).
Мы хотим делать то, что нельзя, но не задумываемся о том, почему это что-то стало нельзя - вот где основной момент - надо из "нельзя" что-то превращать в "можно" путем корректировки соответствующих норм закона, тогда и не будет страхов слежки.
Однако ж мы хотим чтобы можно было безнаказанно делать то, что нельзя, не меняя по сути ничего (хотим сидеть на жопе ровно и возмущаться лишь).
Не хочешь, чтобы за тобой следили - покупай телефон кнопочный без камеры (но и там есть микрофон), передвигайся по канализационным каналам (чтобы камеры не засекли).
Секта "дьявольского номера" ИНН, СНИЛС, паспортного номера и т.п. во все времена будет, я так чувствую.
П.С. в то же время я не удивлюсь, если скоро появится некий "социальный" рейтинг, зависящий от лояльности к чему-то, основанный на слежке за тобой.
И уж совсем из инфантилизма высказывание - ну так меняй критерии определения этого рейтинга в силу своих возможностей.
Заранее извиняюсь, что отдельным постом, но хочу узнать мнение ITшников и просто знающих людей.
Можно ли сделать мессенджер, чтобы он использовал только p2p соединение, не отправляя данные на сервер? То есть если абонент в сети, то сообщение уходит напрямую к нему, если не в сети, то висит только на устройстве отправителя.
Первоначальный коннект совершать с помощью блютуз или используя mac-адрес устройства, либо любым другим физическим способом.
Я не говорю, почему до такого не додумались, я лишь хочу знать какие сложности могут быть в такой реализации.
Интересно, а приложение VK ничего подобного не делает, случайно? Если МАХ так шпионит, то почему не приложение VK?
.
А никто, случайно, не знает, как сделать простенький файл html со всего двумя полями: ввод - "имя канала YouTube" и кнопкой "не рекомендовать видео с этого канала!" ?
А то эти падлы повадились подсовывать в текущий просмотр всякую погань, но отказаться от неё можно только если канал попадет в "мои рекомендации" на главной странице Ютуба, а там этой срани нет, за редчайшим исключением, Ютуб не любит, когда его политические ролики пытаются заигнорить.
Смотрят дети мультик, хренакс - очередной политический высер встал в показ!
Я пытался разобраться, рассмотрев свойства кнопки "не рекомендовать видео с этого канала", но там само действие не задано, только название кнопки. А что происходит по ее нажатию - хез, должен уходить запрос на ютуб с именем калаза и командой блокировки.
Дальше - про звонки. В MAX встроена система распознавания ключевых слов (KWS - Keyword Spotting). Нейросеть, которая прогоняет аудио с микрофона прямо во время разговора.
Сразу важное: это не кликбейт
Я не утверждаю, что MAX прямо сейчас слушает ваши разговоры в поисках слов вроде «Путин», «митинг» или «VPN». Текущая модель распознавания обучена только на фразу «не слышу» - по задумке это для определения плохой связи. Прямо сейчас функция выключена на сервере.
Но....я разобрал архитектуру, проследил весь код от микрофона до отправки на сервер - и вот что важно:
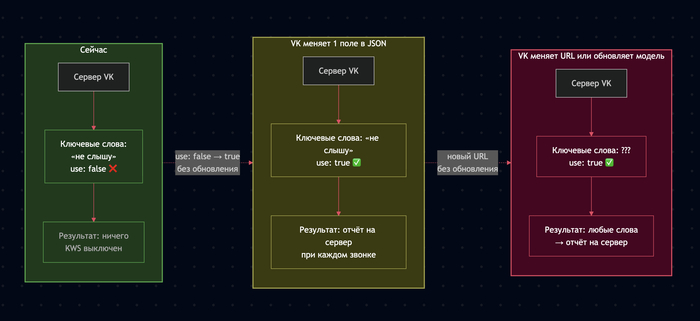
VK может подменить нейронку на любую другую когда захочет (будет проверка на новые слова)
Замена происходит без обновления приложения - достаточно изменить один URL в серверном конфиге или обновить уже существующую (Приложение само подтянет новый набор слов)
При срабатывании - результат улетает на сервер VK
Пользователь ни о чём не знает, согласие никто не спрашивает
TL;DR
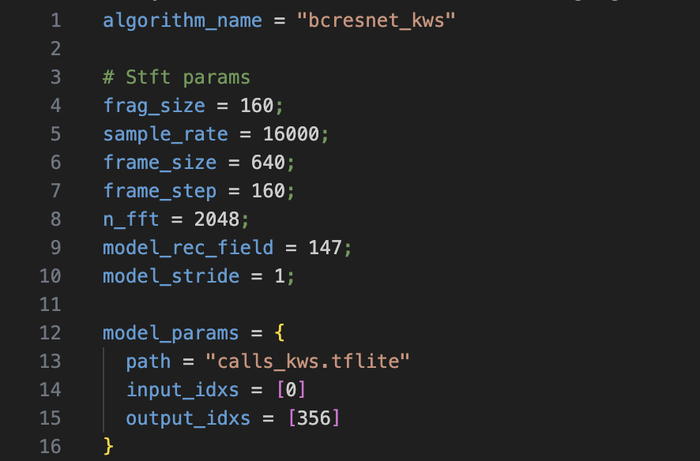
Во время звонков в MAX работает система распознавания ключевых слов (KWS) на базе нейросети BC-ResNet
Она подтягивается с серверов VK, работает на устройстве внутри WebRTC (технология для звонков)
Сейчас модель обучена на фразу «не слышу» и выключена сервером ("use": false)
VK может: включить KWS одной настройкой и поменять список слов на проверку, сделать это для конкретного пользователя - без обновления приложения и без уведомления
KWS работает только во время звонков, не в фоне, не на голосовых сообщениях
При срабатывании - автоматический отчёт на сервер VK с уровнем уверенности
Часть 1: Что я нашёл (для всех)
1. Что такое KWS и как это работает
KWS (Keyword Spotting) - распознавание конкретных слов в аудиопотоке. Вы с этим знакомы: «Окей, Google», «Привет, Алиса», «Hey Siri» - всё это KWS.
Принцип простой: нейросеть берёт звук с микрофона, режет на кусочки по 10 миллисекунд и на каждом решает - это ключевое слово или нет?
VK встроил такую штуку прямо в свой модифицированный WebRTC. Нейросеть крутится локально на устройстве и слушает аудио во время звонка.
Режим: streaming - обрабатывает аудио в реальном времени, кусочек за кусочком
Задача: ответ да/нет - «это ключевое слово» или «это всё остальное» (тишина, шум, обычная речь)
Ключевое слово: «не слышу» (то есть собеседник жалуется, что плохо слышно)
Размер: 1.17 МБ, ~300 тысяч параметров
Для звонков это имеет смысл: собеседник говорит «не слышу» - значит со связью проблемы, приложение может это подхватить.
3. Почему это не просто «определение качества связи»
Распознавать «не слышу» - безобидно. А вот как это устроено внутри - уже нет.
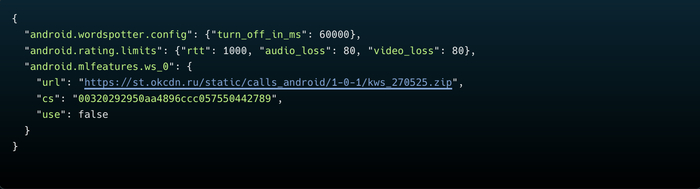
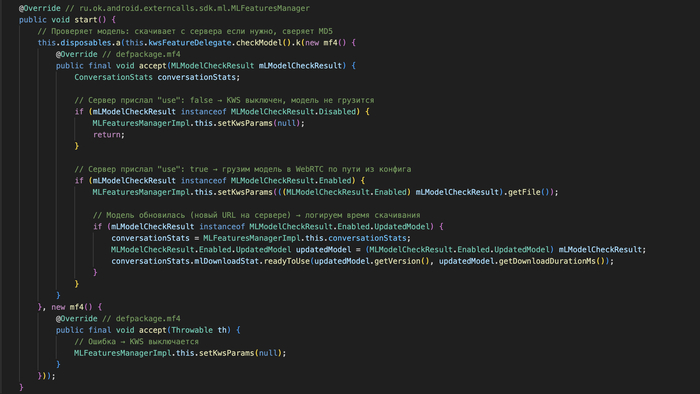
Нейронка приходит с сервера. KWS не зашит в код приложения. При запуске приложение получает от сервера конфиг с URL модели, забирает файл и грузит в нейросетевой движок. Сервер VK решает:
Какую нейронку загружать (URL файла)
Включена ли KWS вообще (флаг use)
Сколько времени слушать (таймер turn_off_in_ms, сейчас 60 секунд)
VK может подменить модель хоть завтра - на любые другие слова. Обновлять приложение не нужно. Спрашивать пользователя - тоже.
Приложение не проверяет, что именно нейронка распознаёт. Если завтра VK положит на CDN модель, обученную на слово «протест» - приложение скачает её и запустит точно так же.
А что в политике конфиденциальности? Я проверил оба документа - Политику конфиденциальности (legal.max.ru/pp) и Пользовательское соглашение (legal.max.ru/ps). Упоминания KWS или анализа аудио во время звонков - ноль.
При этом в Пользовательском соглашении есть описание того, как голосовые и видеосообщения переводятся в текст.
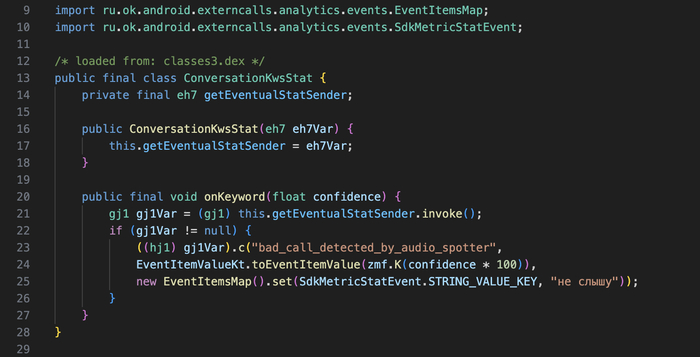
4. Что происходит при срабатывании
Когда нейронка считает, что услышала ключевое слово, происходит следующее:
VK видит: в таком-то звонке у такого-то пользователя сработал детектор, уверенность такая-то. Всё привязано к userId как и call_id (vchat.clientStats отправляется в привязке к конкретной VoIP-сессии)
5. Серверный конфиг: то что я перехватил
Во время анализа я перехватил реальный ответ сервера VK с конфигурацией KWS. Вот что сервер присылает приложению:
Я забрал модель по этому URL - без авторизации, без cookies. Любой может это сделать прямо сейчас. MD5 совпадает с тем, что прислал сервер.
Ещё я побрутил CDN в поисках других моделей - перебрал 200+ вариантов путей. Нашёл только одну модель в трёх версиях SDK (1-0-1, 1-0-2, 1-0-3) - все три идентичны (одинаковый MD5). На данный момент VK использует только одну модель для фразы «не слышу».
6. Чего KWS не делает (чтобы не нагнетать)
Работает только во время звонков - закрыли приложение, и всё. Кода для фоновой работы KWS я не нашёл.
С голосовыми сообщениями не связан - те переводятся с аудио в текст на серверах VK, это другой процесс, другой код.
Сейчас выключен (use: false). Нейронка уже на устройствах, но не запущена. И ищет она только «не слышу», а не что-то «опасное».
7. Что ещё я нашёл про звонки
KWS - не единственная интересная вещь в работе звонков MAX:
Все звонки идут через сервер VK. P2P-соединений я не увидел - все медиаданные проходят через TURN-сервер VK. Шифрование DTLS-SRTP есть, но от вас до сервера, не от вас до собеседника. На relay-сервере шифрование заканчивается - ключи у VK.
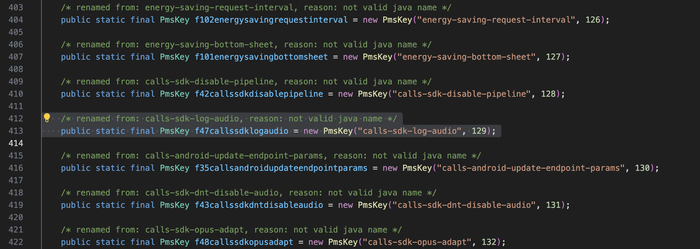
Флаг записи аудио. В коде есть PMS-ключ calls-sdk-log-audio - если VK его включит, аудио звонка пишется в файл. Управляется с сервера.
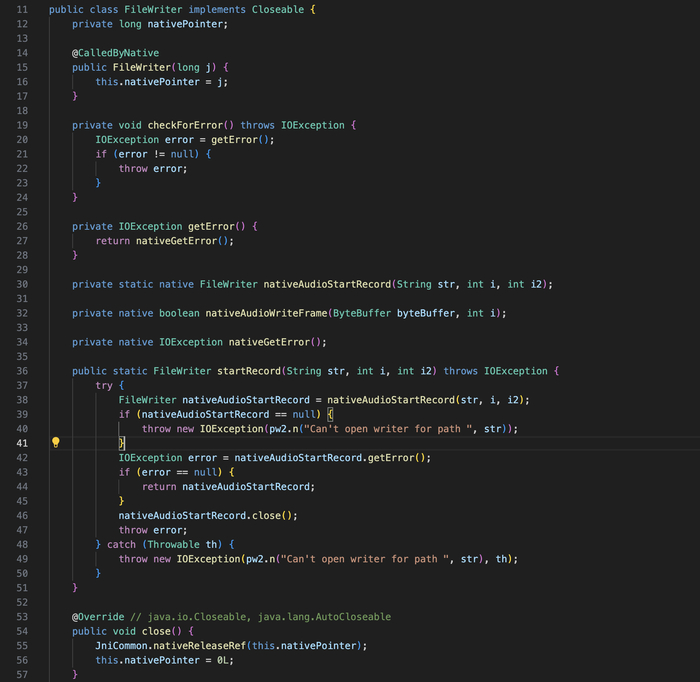
Модифицированный WebRTC. VK не использует стандартный WebRTC - они его модифицировали. В модификации добавлены: нативная запись аудио в Opus (nativeAudioStartRecord, nativeAudioWriteFrame), KWS-интеграция, и кастомные параметры.
Часть 2: Доказательства (для тех, кто хочет проверить)
Ниже - код, конфиги и результаты реверс-инжиниринга. Версия APK 26.12.1 (6679).
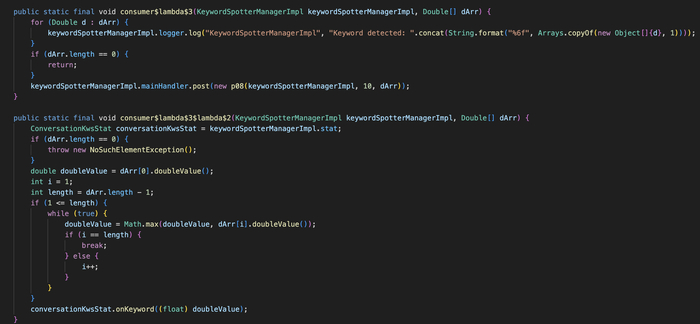
2.1 Где живёт KWS в коде
KWS встроен в модифицированный WebRTC внутри нативной библиотеки libjingle_peerconnection_so.so. Точка входа - JNI-метод:
Имя "не слышу" зашито в код - но модель определяется URL с сервера. Если VK ее заменит, код по-прежнему будет отправлять "не слышу" как строку, даже если реальная модель будет детектить совершенно другую фразу. Или VK обновит и код в следующей версии.
Одна и та же модель во всех версиях. Имя файла kws_270525 предполагает дату создания 27.05.2025. Просканировал 200+ вариантов путей - других моделей на CDN не нашёл.
2.6 Почему «модель можно заменить» - не теория
Цепочка замены модели:
VK меняет поле url в android.mlfeatures.ws_0 на новый адрес или просто обновляет модель
Сервер пушит обновлённый RemoteSettings через постоянное TCP-соединение
MLFeaturesManagerImpl видит новый URL, тянет новый ZIP
Проверяет MD5 (новый, для нового файла)
Распаковывает .tflite + .cfg в ml_features/ws/
При следующем звонке KwsFeatureDelegate загружает новую модель
BCResNetKWS начинает детектить новые ключевые слова
На стороне приложения нет проверки того, что именно модель распознаёт. Нет whitelist допустимых слов. Нет уведомления пользователя. MD5 проверяет только целостность файла - что скачалось без ошибок.
2.7 Дополнительные аудио-возможности в звонках
Запись аудио через серверный флаг: PMS-ключ calls-sdk-log-audio (key 129) может включить запись аудио звонка в файл. Плюс JNI-методы nativeStartAecDump / nativeStopAecDump позволяют дампить raw-аудио в файловый дескриптор. Всё управляется сервером.
Все звонки через relay VK: Все медиаданные идут через TURN-сервер VK (155.212.206.115:43210). Шифрование DTLS-SRTP - от вас до сервера, не от вас до собеседника. Сертификат сервера: QRtpServer 1.1.10.
Типы ML-фич в конфиге:
WS (WordSpotter) - распознавание ключевых слов ← то, что мы разобрали
NS (Noise Suppression) - подавление шума
MLFeaturesManagerImpl поддерживает несколько типов моделей. Сейчас WS и NS, но подцепить новый тип - дело пары строк.
/ru/ok/tamtam/android/prefs/PmsKey.java - Коротко и наглядно: вот он, переключатель записи аудио, управляемый с сервера.
/one/video/calls/audio/opus/FileWriter.java - Это нативная запись аудио в файл.
Выводы
Если вы дочитали до сюда - вы уже поняли суть.
Скажу одно: разница между «детектором плохой связи» и «детектором произвольных слов» - это один URL в JSON-конфиге. Модель, код, процесс отправки на сервер - всё одно и то же. Меняется только файл на CDN.
Я не знаю, планирует ли VK это использовать иначе. Но я знаю, что в политике конфиденциальности об этом ни слова, согласие не спрашивается, а модель можно скачать и проверить прямо сейчас. Ссылка выше.
Код - вот он. Модель - в открытом доступе. Проверяйте.
Друзья, всем привет! Я печатаю целыми днями - посты, статьи, ответы в чатах - и в какой-то момент запястья просто начинают болеть. Пробовал разные браузерные расширения для голосового ввода вроде Voice In, но это какое-то гиблое дело: то текст не вставляется куда надо, то расширение крашится, то работает только в браузере и всё, то лимит кончается. Короче, обплевался.
Начал искать альтернативу и нашел - Epicenter Whispering. Зажимаешь кнопку, говоришь в микрофон, отпускаешь - текст появляется там, где стоит курсор. В любой программе. Этот пост, кстати, тоже надиктован через неё. И самое главное - никому ни за что не нужно платить и может работать даже без интернета.
Что умеет Epicenter Whispering
Работает на уровне всей ОС. Не привязан к браузеру, вставляет текст в любое активное окно - хоть мессенджер, хоть редактор кода, хоть комментарии на Пикабу. Это прям главное отличие от всяких браузерных расширений.
Локальная работа без интернета. Встроенная поддержка моделей NVIDIA NeMo (Parakeet). Всё крутится на вашем компьютере, приватно и бесплатно. При желании можно подключить облачные API (Groq, OpenAI, ElevenLabs), но для большинства задач хватает локальной модели.
LLM-фильтр на лету. Уникальная киллер-фича! Можно прикрутить промпт, чтобы нейронка моментально переписывала сказанное. Наговариваете на эмоциях: «Е**чие пдорасы, вы меня за**али!»*, а она выдает: «Рад вас видеть сегодня, дорогие коллеги».
Режим активации голосом (VAD). Если не хочется постоянно держать кнопку - есть умная активация, которая сама определяет когда вы говорите.
Гибкий вывод. Текст можно отправлять сразу в активное поле (даже настроить автонажатие Enter после вставки) или просто тихо копировать в буфер обмена.
Как установить и запустить
Переходим на GitHub проекта и скачиваем установщик под свою систему из раздела Releases (есть под Windows, macOS и Linux)
Устанавливаем и идём в Settings → Transcription
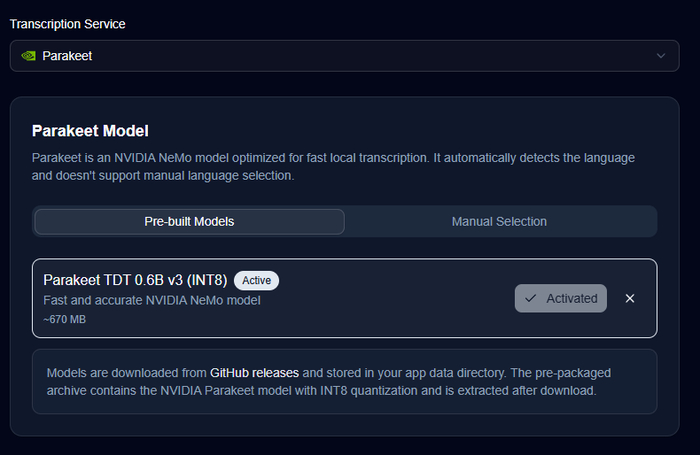
В разделе Transcription Service выбираем «Parakeet» (Local) для быстрой оффлайн-работы
В блоке Parakeet Model выбираем «Parakeet TDT 0.6B v3 (INT8)» - весит около 670 МБ, автоматически определяет язык. Жмём Activated для скачивания
Нажимаем горячую клавишу (по умолчанию Ctrl+Shift+;), говорим текст, отпускаем - готово
Если вы много печатаете и хотите иногда дать пальцам отдохнуть - попробуйте. Если вам надоели глючные браузерные расширения которые работают через раз - тем более. Ну и если хочется поиграться с LLM-фильтром для автоматической обработки надиктованного текста - это вообще отдельное удовольствие.
Это не моя сборка, но реально полезный инструмент который я сам использую каждый день. Такие штуки я регулярно нахожу и выкладываю у себя на канале НЕЙРО-СОФТ - там мы собираем портативные сборки нейросетей, репаки и полезные open-source инструменты, всё на русском и с простыми инструкциями по установке. Если вам заходит такой формат - заглядывайте.
Друзья, поддержите пост плюсиком, если было полезно! А если пользуетесь чем-то похожим для голосового ввода - делитесь в комментариях, интересно сравнить.
А я больше про нейросети рассказываю на YouTube, в телеграм, на Бусти. Буду рад вашей подписке и поддержке, всех обнял и удачных транскрпиций!
В потоке визуального контента, которым заполнены соцсети, маркетплейсы и рабочие чаты, ИИ с распознаванием фото стал тихим «фильтром», без которого система просто захлебнулась бы в хаосе. Он умеет видеть не только текст и объекты на картинке, но и контекст: тип товара, сцену, эмоции. Для бизнеса это означает меньше ручной работы, быстрее принятые решения и более точную аналитику по визуальным данным.
Я собрал 8 реально рабочих нейросетей для распознавания изображений: от облачных API до готовых инструментов для разработчиков и маркетологов.
ТОП-8 ИИ с распознаванием фото в 2026 году
MashaGPT — русскоязычный чат-бот на базе продвинутых моделей, который точно распознает текст, объекты и лица на фотографиях.
ChatGPT — ИИ от OpenAI, извлекающий текст, описывающий сцены и отвечающий на вопросы по загруженным изображениям.
Study AI — платформа с ИИ-ботами, где можно загружать скрины, фото заданий и документов, а нейросети распознают изображение, решают задачи и помогают с учебой и работой.
Gemini — мультимодальный ИИ от Google, который распознает изображения, ищет информацию по фото и отличает сгенерированные ИИ картинки от реальных.
SmartBuddy — сервис для OCR-распознавания текста с изображений, документов и сканов.
GoGPT — агрегатор нейросетей, которые поддерживают фотоанализ: извлекают текст, описывают содержимое и генерируют идеи на основе загруженных картинок.
ruGPT — инструмент для распознавания текста с русских изображений, мемов и документов с высокой точностью кириллицы.
GPTunneL — нейро-офис объединяет сотню+ моделей и позволяет в одном интерфейсе распознавать, анализировать и генерировать изображения для рабочих и креативных задач.
Российский онлайн‑сервис, который дает доступ к моделям GPT (включая GPT‑4o‑mini и более продвинутые варианты) без зарубежных карт. В разделе чата пользователи могут просто начать диалог с ИИ, задавать вопросы, решать задачи, а также загружать файлы и изображения для анализа. Сервис позиционируется как «единое окно» к ИИ‑ассистенту для текста, фото, документов и креатива.
Стоимость: от 990 ₽/мес
Бесплатный доступ: есть бесплатный доступ к облегченной модели GPT‑4o‑mini
Функции: распознавание объектов, OCR-текст, описание сцен, анализ эмоций, распознавание графиков, анализ документов, идентификация растений/животных, мультимодальный диалог с уточнениями по фото, решение задач по изображениям перечислить через запятую именно про распознавание изображений
Плюсы:
Поддержка русского языка «из коробки» и адаптация под российскую аудиторию.
Есть бесплатный порог входа для тестирования.
Умеет работать не только с текстом, но и с изображениями и файлами.
Универсальный ИИ для распознавания изображений и работы с текстом. Пользователь может загрузить фото, скриншот или документ, а модель проанализирует содержимое, опишет картинку, найдет ошибки, прочитает текст и ответит на вопросы по изображению. Текущие версии (GPT‑4o и GPT‑5.2 в веб‑интерфейсе) поддерживают мультимодальный режим: текст + картинка в одном диалоге.
Стоимость: от $20/мес
Бесплатный доступ: ограничен 10 сообщениями каждые 5 часов
Функции: распознавание текста (OCR), описание сцен и объектов, анализ эмоций/лиц, извлечение данных из графиков/документов, ответы на вопросы по фото, генерация идей/редактирование изображений, интеграция с Sora для видео из фото
Плюсы:
Сильная мультимодальная модель: хорошо понимает как объекты на фото, так и контекст (подписи, интерфейсы, диаграммы).
Удобный и простой интерфейс: достаточно перетащить картинку в чат и задать вопрос.
Работает в браузере и мобильных приложениях, без сложной настройки.
Минусы:
Строгие лимиты на тарифах Free/Go, очереди в пике на Plus.
Платформа с набором ИИ‑ботов, которая закрывает задачи от учебы до контента. Сервис распознает задания по снимкам (рукописный и печатный текст), помогает решать задачи по картинке и работает с документами и тестами по скриншотам. Отдельные боты отвечают за генерацию и обработку изображений: от улучшения качества до оживления фото в короткие видео. Все нейросети собраны в одном интерфейсе, а умный поиск подбирает нужный бот под конкретную задачу.
Стоимость: от 199 ₽/нед
Бесплатный доступ: 50 приветственных токенов после регистрации для 1–3 запросов
Функции: распознавание текста и формул с фото, решение задач по изображениям, анализ скриншотов/рукописных заметок, извлечение данных из графиков/диаграмм, описание учебных материалов
Плюсы:
Один аккаунт дает доступ сразу к множеству ботов: и для учебы, и для работы с изображениями.
Умеет распознавать сложные задания по фото (включая рукописный текст), что удобно для школьных и вузовских задач.
Интерфейс и поддержка заточены под русскоязычную аудиторию.
Минусы:
Лимиты токенов быстро исчерпываются на пробном доступе.
Мультимодальная нейросеть Google, которая в 2026 году лидирует в анализе изображений благодаря моделям Gemini 2.5 Flash и 3 Pro с функцией Agentic Vision. Нейросеть с функцией распознавания фото позволяет загружать изображение для детального распознавания объектов, текста и сцен, а также проверки на AI-генерацию через SynthID. Сервис интегрируется с поиском Google, пдходит для поиска информации по фото и творческих задач.
Стоимость: $20/мес
Бесплатный доступ: неограниченный анализ изображений на Gemini 2.0 Flash
Функции: распознавание объектов и сцен, OCR-текст, анализ эмоций/лиц, проверка AI-генерации (SynthID), выделение элементов по запросу, Agentic Vision для детального зума/поворота фото, извлечение данных из графиков/документов
Плюсы:
Бесплатный мощный Vision без лимитов.
Интеграция с Google Search и высокой точностью SynthID.
Быстрый анализ сложных изображений.
Минусы:
Полноценный доступ к самым мощным моделям и расширенным лимитам требует платной подписки Google One AI / Gemini Advanced.
Российская платформа с 100+ нейросетями, включая Claude, Gemini и GPT для анализа изображений. Она фокусируется на OCR-распознавании текста с фото, сканов и документов, поддерживая русский язык. Сервис подходит для бизнеса, учебы и креатива: извлекает данные из таблиц, схем и графиков. Дополнительно генерирует диаграммы, переводит и анализирует файлы в одном интерфейсе.
Стоимость: привязана к количеству запросов и используемым моделям
Бесплатный доступ: 3 бесплатных запроса без регистрации
Функции: OCR-текст с фото/сканов, распознавание объектов/эмоций, анализ диаграмм/графиков, подсчет предметов, поиск дефектов/различий, извлечение данных из таблиц/документов
Плюсы:
Очень простой вход: можно протестировать сервис без регистрации и с бонусом после создания аккаунта.
Поддерживается работа с множеством форматов файлов (PDF, изображения, офисные документы), что удобно для документооборота.
Нейросеть для OCR встроена в более широкую экосистему: распознанный текст сразу можно перевести, проанализировать или переписать.
Агрегатор нейросетей, предоставляющий доступ к ChatGPT, Claude, Gemini и другим моделям, которые делают анализ изображений: вы загружаете фото, а ИИ делает поиск по фото, распознает текст или дает описание за секунды. Она подходит для повседневных задач, от генерации контента до анализа файлов и ссылок, с удобным чатом и готовыми промптами.
Стоимость: от 699 ₽/мес
Бесплатный доступ: 10–20 запросов в день на базовых моделях
Функции: распознавание объектов и текста на фото, описание сцен, анализ изображений для идей/редактирования, извлечение данных из графиков, поддержка FaceSwap и стилизации
Плюсы:
Доступ к нескольким сильным vision‑моделям и генераторам картинок в одном сервисе.
Гибкая система GoCoin: видно примерную стоимость каждого запроса, неиспользованный баланс переносится при продлении тарифа.
Можно в одном окне и распознавать изображения, и сразу генерировать/дорабатывать новые.
Минусы:
Лимиты на бесплатном быстро исчерпываются при частом использовании.
Платформа на русском языке, через которую каждый месяц проходит свыше 200 000 изображений. Сервис использует передовые алгоритмы ИИ для точного распознавания содержимого фотографий: сервис извлекает текст со сканов и снимков, анализирует визуальный контент и мгновенно преобразует информацию с картинок в цифровой формат — от рукописных заметок до сложных документов и инфографик. Простой и понятный интерфейс разработан с учётом потребностей аудитории из России и стран СНГ.
Стоимость: от 165 ₽/мес
Бесплатный доступ: бесплатный тариф с 10 стартовыми запросами
Функции: OCR-текст с фото/сканов, распознавание объектов/сцен, анализ задач/формул, извлечение данных из документов/графиков, ответы на вопросы по изображениям
Агрегатор более 100 нейросетей (ChatGPT, Claude, Midjourney, Gemini), предоставляющий туннельный доступ для создания контента. Платформа поддерживает Vision-функции для поиска по фото с помощью ИИ: от OCR и описания сцен до генерации/редактирования фото и видео. Подходит для бизнеса и креатива с удобным интерфейсом, загрузкой файлов (PDF, изображения) и корпоративными аккаунтами.
Стоимость: оплата по факту за количество генераций
Бесплатный доступ: есть бесплатный доступ к ChatGPT
Функции: OCR-текст/объекты с фото, описание сцен/эмоций, анализ документов/графиков, редактирование изображений, FaceSwap, стилизация/генерация из фото
Плюсы:
100+ ИИ‑моделей в одном месте: можно комбинировать распознавание, генерацию и видео без переключения сервисов.
Бонусы/промокоды, низкие цены для РФ.
Поддерживает локальные способы оплаты: СБП, карты, SberPay.
1. Чем ИИ с распознаванием фото отличается от обычного «поиска по картинке» в браузере?
«Поиск по картинке» обычно ищет похожие изображения в интернете и страницы, где они встречаются. ИИ с распознаванием фото сначала «понимает» само изображение: что на нем находится, какой текст, какой контекст сцены, а уже потом может по запросу описать картинку, выделить нужные элементы, решить задачу, переписать текст, найти ошибки в верстке и т.д. Проще говоря, браузер ищет картинку в сети, а нейросеть анализирует ее содержимое и работает с ним как с данными.
2. Можно ли загружать в такие сервисы фотографии людей и документы с личными данными — что с безопасностью и приватностью?
Технически — да, большинство сервисов это позволяют, но с точки зрения безопасности это всегда риск. Часть платформ хранит загруженные данные для дообучения моделей или внутренней аналитики, пусть и в обезличенном виде; другие (обычно платные бизнес‑тарифы) обещают не использовать ваши данные для обучения. В идеале в публичные ИИ‑сервисы не стоит загружать паспорта, банковские карты, меддокументы и чужие лица без согласия — для таких задач лучше использовать локальные решения или корпоративные продукты с формальными договорами и DPA.
3. Насколько точно ИИ распознает текст на фото (сканы, рукописные конспекты, скриншоты тестов)?
С печатным текстом на качественных сканах и скриншотах современные OCR‑модели дают точность, близкую к «человеческой» — отдельные ошибки чаще всего в мелочах (символы, знаки, редкие шрифты). Со сканами плохого качества, перекошенными фотографиями страниц и особенно с рукописными конспектами точность резко падает: часть текста может искажаться или пропадать. Скриншоты тестов и интерфейсов в целом распознаются хорошо, но разметку (варианты ответов, таблицы, сложную верстку) иногда приходится вручную поправлять.
4. Можно ли с помощью этих нейросетей решать задачи по фото (математика, тесты, техдокументация) и не будет ли это считаться «списыванием»?
Да, многие модели уверенно распознают условие по фото и выдают готовое решение или даже пошаговое объяснение. Вопрос «списывания» — это уже не про технологии, а про правила конкретной школы, вуза или экзамена: где‑то ИИ прямо запрещен, где‑то допускается как «калькулятор на стероидах», а для домашних заданий учителя все чаще сами рекомендуют использовать ИИ как помощника. Безопасный подход — использовать нейросеть как объяснитель и проверяющий: попросить разобрать решение, подсказать ход мысли, а не просто выдавать ответ и сдавать его как свой.
5. Как ИИ справляется с «сложными» картинками — плохо освещенными фото, маленьким шрифтом, рукописным текстом, коллажами?
Плохое освещение, шум, размытие. Модели могут «дотянуть» до читабельного уровня, но ошибки резко растут: буквы путаются, мелкий текст теряется, куски пропадают.
Маленький шрифт. Если его сложно прочитать глазами, нейросеть почти наверняка тоже будет ошибаться; помогает переснять ближе или увеличить картинку.
Рукописный текст. Здесь все сильно зависит от почерка: аккуратная «школьная» печатная рукопись распознается терпимо, быстрые записи с кривым почерком — плохо.
Коллажи и «захламленные» изображения. ИИ может понимать общую сцену, но при большом количестве мелких элементов, наложенного текста и графики растет шанс перепутать структуру (что к чему относится, где подпись, где часть картинки). В таких случаях лучше либо упростить изображение, либо загружать его частями.
Мы живем в момент, когда «понимание картинок» больше не привилегия человека — его уверенно перенимают нейросети. Обозрев восемь разных ИИ с распознаванием фото, можно увидеть общую тенденцию: распознавание изображений становится не отдельным продуктом, а встроенной функцией во все — от учебных помощников до комплексных ИИ‑платформ. Это открывает простор для автоматизации: задания по фото, сканы документов, каталоги товаров, визуальная аналитика — все это можно обрабатывать быстрее и точнее.