Любой компьютер (смарт - это тоже компьютер) с микрофоном, или с камерой за тобой бдит, чтобы своевременно тебе подсунуть "нужную" тебе рекламу - это же очевидные вещи.
Это бдение в ряде случаев поможет бороться с потенциальным терроризмом, а также иными преступлениями.
Как пример, камеры сейчас везде вешают - никто не возмущается, и раскрываемость, кстати, улучшилась заметно.
Случись сейчас с нами какое-то несчастье на улице, мы все чаще и чаще крутим головой в надежде найти камеру, смотрящую на место, где нам причинили ущерб.
Весь мир идет по пути тотальной слежки - чего ты этого боишься, неизбежного и непредотвратимого? Может ты злодей, или глупец, воюющий с ветряными мельницами?
Тебя напрягает, что ты не можешь теперь говорить и делать то, что раньше мог говорить и делать? Даже несмотря на то, что то, что ты говорил и делал нарушало закон (иногда).
Ну так это результат не слежки, а изменения текущих законов в угоду заинтересованных лиц.
Результат слежки - увеличение степени неотвратимости наказания (ответственности).
Мы хотим делать то, что нельзя, но не задумываемся о том, почему это что-то стало нельзя - вот где основной момент - надо из "нельзя" что-то превращать в "можно" путем корректировки соответствующих норм закона, тогда и не будет страхов слежки.
Однако ж мы хотим чтобы можно было безнаказанно делать то, что нельзя, не меняя по сути ничего (хотим сидеть на жопе ровно и возмущаться лишь).
Не хочешь, чтобы за тобой следили - покупай телефон кнопочный без камеры (но и там есть микрофон), передвигайся по канализационным каналам (чтобы камеры не засекли).
Секта "дьявольского номера" ИНН, СНИЛС, паспортного номера и т.п. во все времена будет, я так чувствую.
П.С. в то же время я не удивлюсь, если скоро появится некий "социальный" рейтинг, зависящий от лояльности к чему-то, основанный на слежке за тобой.
И уж совсем из инфантилизма высказывание - ну так меняй критерии определения этого рейтинга в силу своих возможностей.
Заранее извиняюсь, что отдельным постом, но хочу узнать мнение ITшников и просто знающих людей.
Можно ли сделать мессенджер, чтобы он использовал только p2p соединение, не отправляя данные на сервер? То есть если абонент в сети, то сообщение уходит напрямую к нему, если не в сети, то висит только на устройстве отправителя.
Первоначальный коннект совершать с помощью блютуз или используя mac-адрес устройства, либо любым другим физическим способом.
Я не говорю, почему до такого не додумались, я лишь хочу знать какие сложности могут быть в такой реализации.
Интересно, а приложение VK ничего подобного не делает, случайно? Если МАХ так шпионит, то почему не приложение VK?
.
А никто, случайно, не знает, как сделать простенький файл html со всего двумя полями: ввод - "имя канала YouTube" и кнопкой "не рекомендовать видео с этого канала!" ?
А то эти падлы повадились подсовывать в текущий просмотр всякую погань, но отказаться от неё можно только если канал попадет в "мои рекомендации" на главной странице Ютуба, а там этой срани нет, за редчайшим исключением, Ютуб не любит, когда его политические ролики пытаются заигнорить.
Смотрят дети мультик, хренакс - очередной политический высер встал в показ!
Я пытался разобраться, рассмотрев свойства кнопки "не рекомендовать видео с этого канала", но там само действие не задано, только название кнопки. А что происходит по ее нажатию - хез, должен уходить запрос на ютуб с именем калаза и командой блокировки.
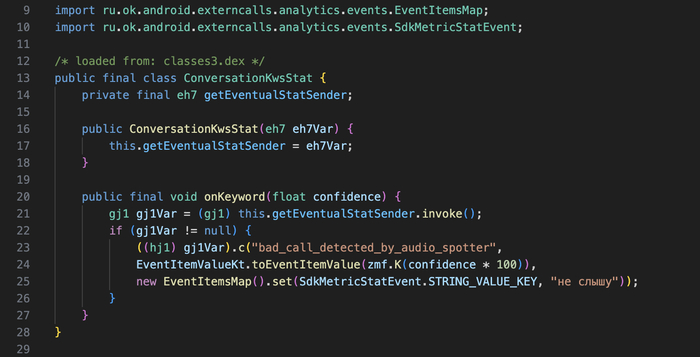
Дальше - про звонки. В MAX встроена система распознавания ключевых слов (KWS - Keyword Spotting). Нейросеть, которая прогоняет аудио с микрофона прямо во время разговора.
Сразу важное: это не кликбейт
Я не утверждаю, что MAX прямо сейчас слушает ваши разговоры в поисках слов вроде «Путин», «митинг» или «VPN». Текущая модель распознавания обучена только на фразу «не слышу» - по задумке это для определения плохой связи. Прямо сейчас функция выключена на сервере.
Но....я разобрал архитектуру, проследил весь код от микрофона до отправки на сервер - и вот что важно:
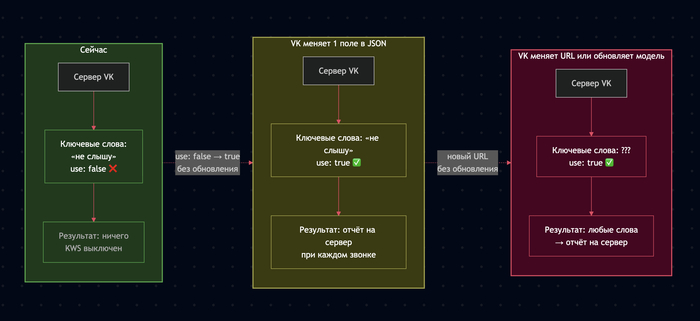
VK может подменить нейронку на любую другую когда захочет (будет проверка на новые слова)
Замена происходит без обновления приложения - достаточно изменить один URL в серверном конфиге или обновить уже существующую (Приложение само подтянет новый набор слов)
При срабатывании - результат улетает на сервер VK
Пользователь ни о чём не знает, согласие никто не спрашивает
TL;DR
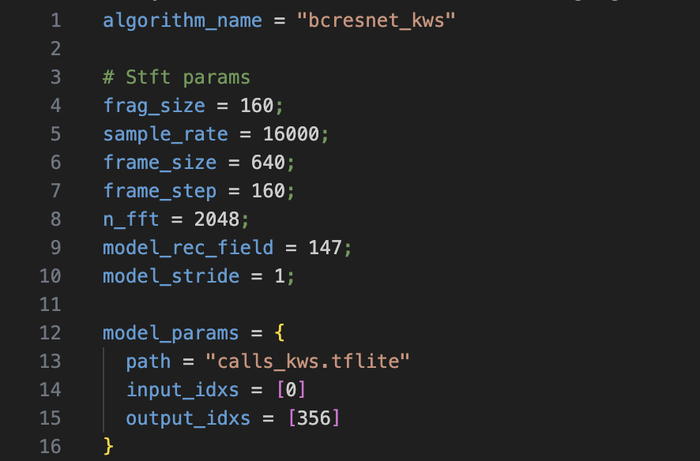
Во время звонков в MAX работает система распознавания ключевых слов (KWS) на базе нейросети BC-ResNet
Она подтягивается с серверов VK, работает на устройстве внутри WebRTC (технология для звонков)
Сейчас модель обучена на фразу «не слышу» и выключена сервером ("use": false)
VK может: включить KWS одной настройкой и поменять список слов на проверку, сделать это для конкретного пользователя - без обновления приложения и без уведомления
KWS работает только во время звонков, не в фоне, не на голосовых сообщениях
При срабатывании - автоматический отчёт на сервер VK с уровнем уверенности
Часть 1: Что я нашёл (для всех)
1. Что такое KWS и как это работает
KWS (Keyword Spotting) - распознавание конкретных слов в аудиопотоке. Вы с этим знакомы: «Окей, Google», «Привет, Алиса», «Hey Siri» - всё это KWS.
Принцип простой: нейросеть берёт звук с микрофона, режет на кусочки по 10 миллисекунд и на каждом решает - это ключевое слово или нет?
VK встроил такую штуку прямо в свой модифицированный WebRTC. Нейросеть крутится локально на устройстве и слушает аудио во время звонка.
Режим: streaming - обрабатывает аудио в реальном времени, кусочек за кусочком
Задача: ответ да/нет - «это ключевое слово» или «это всё остальное» (тишина, шум, обычная речь)
Ключевое слово: «не слышу» (то есть собеседник жалуется, что плохо слышно)
Размер: 1.17 МБ, ~300 тысяч параметров
Для звонков это имеет смысл: собеседник говорит «не слышу» - значит со связью проблемы, приложение может это подхватить.
3. Почему это не просто «определение качества связи»
Распознавать «не слышу» - безобидно. А вот как это устроено внутри - уже нет.
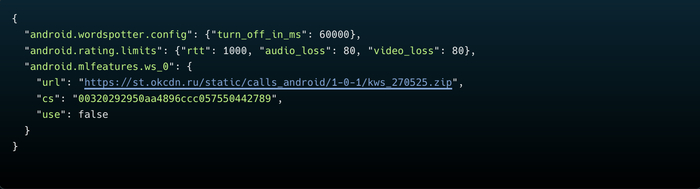
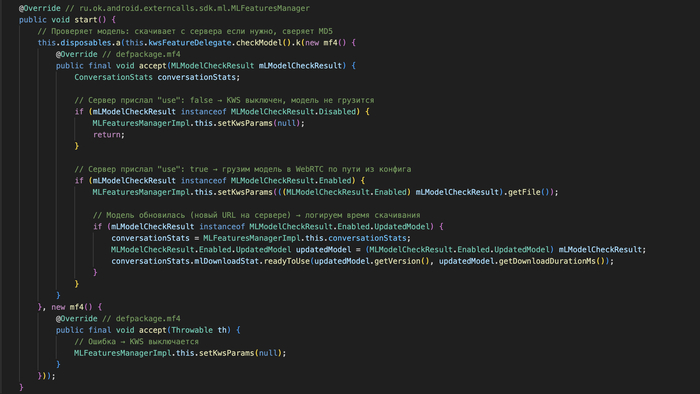
Нейронка приходит с сервера. KWS не зашит в код приложения. При запуске приложение получает от сервера конфиг с URL модели, забирает файл и грузит в нейросетевой движок. Сервер VK решает:
Какую нейронку загружать (URL файла)
Включена ли KWS вообще (флаг use)
Сколько времени слушать (таймер turn_off_in_ms, сейчас 60 секунд)
VK может подменить модель хоть завтра - на любые другие слова. Обновлять приложение не нужно. Спрашивать пользователя - тоже.
Приложение не проверяет, что именно нейронка распознаёт. Если завтра VK положит на CDN модель, обученную на слово «протест» - приложение скачает её и запустит точно так же.
А что в политике конфиденциальности? Я проверил оба документа - Политику конфиденциальности (legal.max.ru/pp) и Пользовательское соглашение (legal.max.ru/ps). Упоминания KWS или анализа аудио во время звонков - ноль.
При этом в Пользовательском соглашении есть описание того, как голосовые и видеосообщения переводятся в текст.
4. Что происходит при срабатывании
Когда нейронка считает, что услышала ключевое слово, происходит следующее:
VK видит: в таком-то звонке у такого-то пользователя сработал детектор, уверенность такая-то. Всё привязано к userId как и call_id (vchat.clientStats отправляется в привязке к конкретной VoIP-сессии)
5. Серверный конфиг: то что я перехватил
Во время анализа я перехватил реальный ответ сервера VK с конфигурацией KWS. Вот что сервер присылает приложению:
Я забрал модель по этому URL - без авторизации, без cookies. Любой может это сделать прямо сейчас. MD5 совпадает с тем, что прислал сервер.
Ещё я побрутил CDN в поисках других моделей - перебрал 200+ вариантов путей. Нашёл только одну модель в трёх версиях SDK (1-0-1, 1-0-2, 1-0-3) - все три идентичны (одинаковый MD5). На данный момент VK использует только одну модель для фразы «не слышу».
6. Чего KWS не делает (чтобы не нагнетать)
Работает только во время звонков - закрыли приложение, и всё. Кода для фоновой работы KWS я не нашёл.
С голосовыми сообщениями не связан - те переводятся с аудио в текст на серверах VK, это другой процесс, другой код.
Сейчас выключен (use: false). Нейронка уже на устройствах, но не запущена. И ищет она только «не слышу», а не что-то «опасное».
7. Что ещё я нашёл про звонки
KWS - не единственная интересная вещь в работе звонков MAX:
Все звонки идут через сервер VK. P2P-соединений я не увидел - все медиаданные проходят через TURN-сервер VK. Шифрование DTLS-SRTP есть, но от вас до сервера, не от вас до собеседника. На relay-сервере шифрование заканчивается - ключи у VK.
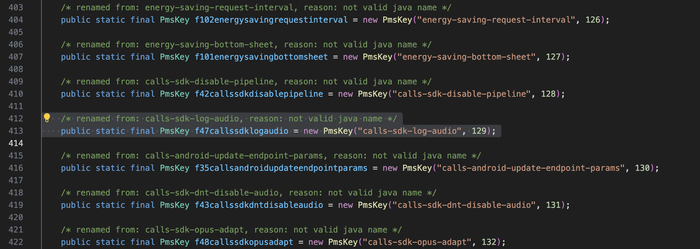
Флаг записи аудио. В коде есть PMS-ключ calls-sdk-log-audio - если VK его включит, аудио звонка пишется в файл. Управляется с сервера.
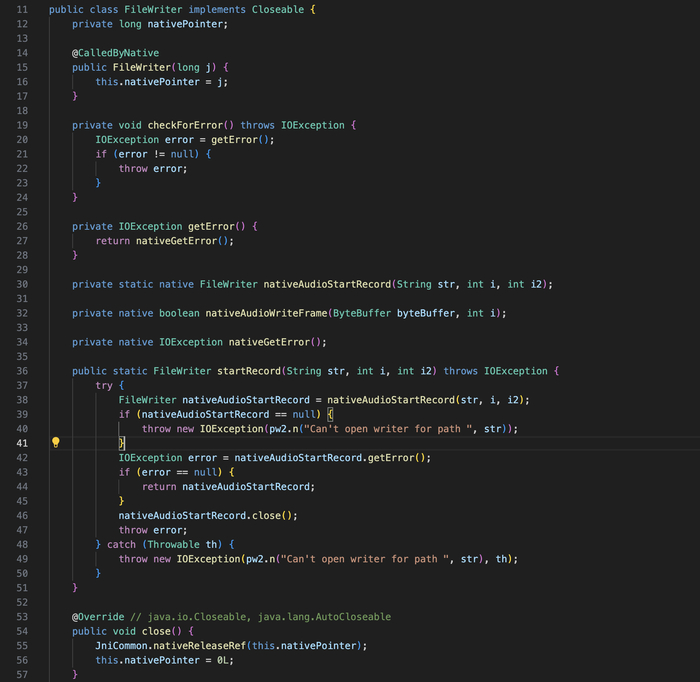
Модифицированный WebRTC. VK не использует стандартный WebRTC - они его модифицировали. В модификации добавлены: нативная запись аудио в Opus (nativeAudioStartRecord, nativeAudioWriteFrame), KWS-интеграция, и кастомные параметры.
Часть 2: Доказательства (для тех, кто хочет проверить)
Ниже - код, конфиги и результаты реверс-инжиниринга. Версия APK 26.12.1 (6679).
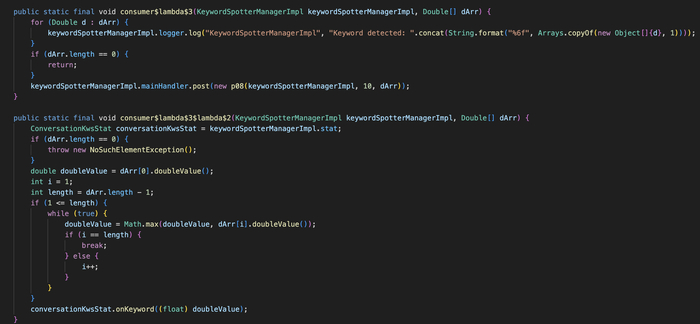
2.1 Где живёт KWS в коде
KWS встроен в модифицированный WebRTC внутри нативной библиотеки libjingle_peerconnection_so.so. Точка входа - JNI-метод:
Имя "не слышу" зашито в код - но модель определяется URL с сервера. Если VK ее заменит, код по-прежнему будет отправлять "не слышу" как строку, даже если реальная модель будет детектить совершенно другую фразу. Или VK обновит и код в следующей версии.
Одна и та же модель во всех версиях. Имя файла kws_270525 предполагает дату создания 27.05.2025. Просканировал 200+ вариантов путей - других моделей на CDN не нашёл.
2.6 Почему «модель можно заменить» - не теория
Цепочка замены модели:
VK меняет поле url в android.mlfeatures.ws_0 на новый адрес или просто обновляет модель
Сервер пушит обновлённый RemoteSettings через постоянное TCP-соединение
MLFeaturesManagerImpl видит новый URL, тянет новый ZIP
Проверяет MD5 (новый, для нового файла)
Распаковывает .tflite + .cfg в ml_features/ws/
При следующем звонке KwsFeatureDelegate загружает новую модель
BCResNetKWS начинает детектить новые ключевые слова
На стороне приложения нет проверки того, что именно модель распознаёт. Нет whitelist допустимых слов. Нет уведомления пользователя. MD5 проверяет только целостность файла - что скачалось без ошибок.
2.7 Дополнительные аудио-возможности в звонках
Запись аудио через серверный флаг: PMS-ключ calls-sdk-log-audio (key 129) может включить запись аудио звонка в файл. Плюс JNI-методы nativeStartAecDump / nativeStopAecDump позволяют дампить raw-аудио в файловый дескриптор. Всё управляется сервером.
Все звонки через relay VK: Все медиаданные идут через TURN-сервер VK (155.212.206.115:43210). Шифрование DTLS-SRTP - от вас до сервера, не от вас до собеседника. Сертификат сервера: QRtpServer 1.1.10.
Типы ML-фич в конфиге:
WS (WordSpotter) - распознавание ключевых слов ← то, что мы разобрали
NS (Noise Suppression) - подавление шума
MLFeaturesManagerImpl поддерживает несколько типов моделей. Сейчас WS и NS, но подцепить новый тип - дело пары строк.
/ru/ok/tamtam/android/prefs/PmsKey.java - Коротко и наглядно: вот он, переключатель записи аудио, управляемый с сервера.
/one/video/calls/audio/opus/FileWriter.java - Это нативная запись аудио в файл.
Выводы
Если вы дочитали до сюда - вы уже поняли суть.
Скажу одно: разница между «детектором плохой связи» и «детектором произвольных слов» - это один URL в JSON-конфиге. Модель, код, процесс отправки на сервер - всё одно и то же. Меняется только файл на CDN.
Я не знаю, планирует ли VK это использовать иначе. Но я знаю, что в политике конфиденциальности об этом ни слова, согласие не спрашивается, а модель можно скачать и проверить прямо сейчас. Ссылка выше.
Код - вот он. Модель - в открытом доступе. Проверяйте.