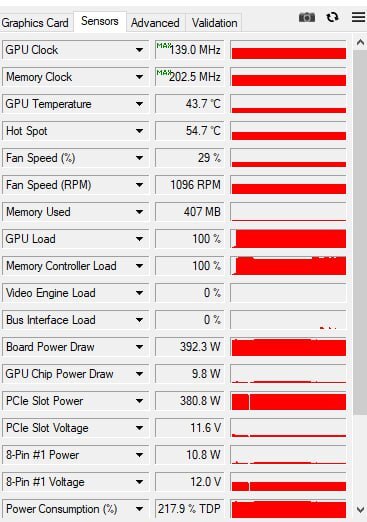
Вообщем дело обстоит так , карта запускается , драйвер встает , напруги все в норме . Но работает на низких частотах что память что гпу . Гпу на 139 Mz и выше не поднимает , с такой же частотой крутит все тесты . Энергопотребление PCex рисует аж 380 w что исходя из температур неправда , потребление по доп питанию низкое 7-20w . Контроллер тока INA3221 был заменен что не дало результатов . Шунты все прозваниваются .
Дело было в оборванной дорожке от резистора на токовую микруху , от чего она неправильно читала данные и выдавала чушь. Всем спасибо за ответы
Попала ко мне видеокартв rtx 3050 6gb с брендового ПК, судя по всему Lenovo. Карта low profile. А мне нужен брекет под фул размер, типа как на картинке 12см. Т.к карта оемная - родной этой планки, видимо, не существует в природе. Может кто то из сообщества Пикабу сможет подсказать где искать, может где то можно заказать изготовление, за вменяемые деньги? Заранее благодарю!
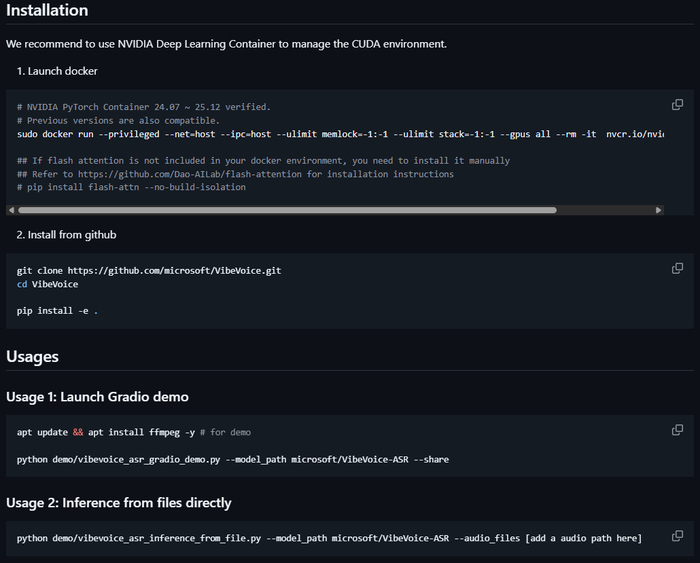
Всем привет! Команда Microsoft Research выложила в открытый доступ VibeVoice-ASR — нейросетевую модель для распознавания речи с диаризацией (разделением) спикеров. Сегодня хочу рассказать об этой технологии подробнее и поделиться портативной версией.
Меня зовут Илья, я основатель сервиса для генерации изображений ArtGeneration.me, блогер и просто фанат нейросетей. А ещё я собрал портативную версию VibeVoice ASR под Windows и успел её как следует протестировать.
Whisper которому уже года три
Я сам пользуюсь Whisper уже много лет — делаю транскрипции своих видео, чтобы потом собрать оглавление для YouTube и использовать материал в текстовых статьях. И скажу честно — никогда не был полностью доволен результатом. Да, Whisper быстрый. Но на этом его достоинства для меня заканчивались.
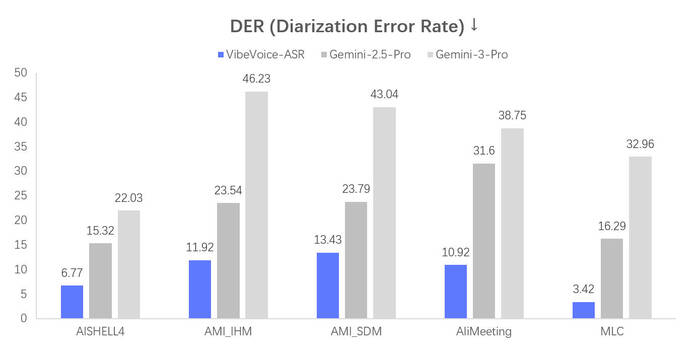
Поэтому к изучению VibeVoice ASR я подошёл со всей ответственностью — протестировал на разных записях, сравнил качество, покрутил настройки.
Главная особенность системы в том, что она обрабатывает до 60 минут аудио за один проход без нарезки на чанки. На выходе — структурированная транскрипция с указанием кто говорит, когда и что именно сказал. И всё это работает локально на вашем компьютере.
Как это работает
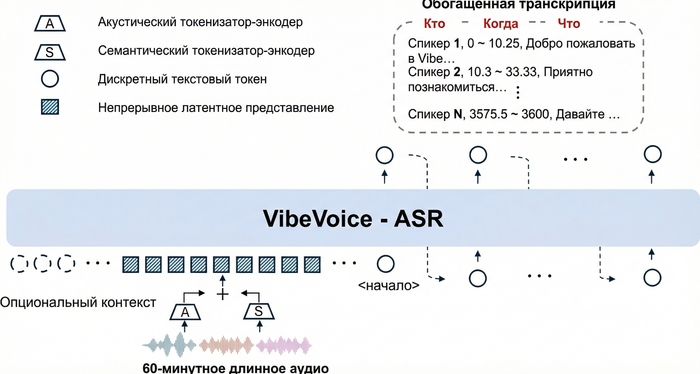
В основе VibeVoice-ASR лежит архитектура на базе Qwen 2.5 (~9 млрд параметров). Ключевая инновация — двойная система токенизации с ультранизким frame rate 7.5 Hz: акустический и семантический токенизаторы.
Такой подход позволяет модели работать с контекстным окном в 64K токенов — это и даёт возможность обрабатывать целый час аудио без потери контекста. Для сравнения: Whisper режет аудио на 30-секундные кусочки и теряет связность на границах сегментов.
На выходе модель генерирует Rich Transcription — структурированный поток с тремя компонентами:
{"Start":1.51,"End":7.49,"Speaker":0,"Content":"У неё преждевременное сохранять невозможно, родила, начала сразу родильная деятельность."},
{"Start":7.51,"End":9.41,"Speaker":1,"Content":"Марина, что с ней?"},
{"Start":10.28,"End":16.22,"Speaker":0,"Content":"У неё преждевременное сохранять невозможно, отошли годы, начала, начала сразу родовая деятельность."},
{"Start":16.22,"End":18.02,"Speaker":1,"Content":"Марина, что с ней?"},
{"Start":18.13,"End":27.94,"Speaker":0,"Content":"Она рожает, привезли в ближайшую больницу родовую. В каком состоянии ребёнок ещё хуже, срок маленький."},
Помимо спикеров, модель размечает неречевые события: [Music], [Silence], [Noise], [Human Sounds] (смех, кашель), [Environmental Sounds], [Unintelligible Speech]. Это сделано чтобы модель не галлюцинировала текст во время пауз или фоновой музыки.
Обработка длинных записей: до 60 минут аудио за один проход без потери контекста. Идеально для митингов, подкастов, лекций.
Диаризация спикеров: автоматическое определение кто говорит в каждый момент времени. Работает на записях с несколькими участниками.
Временные метки: точные таймкоды для каждого сегмента речи. Готовый материал для субтитров.
Customized Hotwords: вот что меня реально зацепило — возможность задать пользовательский контекст. Перед распознаванием указываешь список слов: фамилии, названия продуктов, термины, сокращения. Всё то, что обычно произносится нестандартно и превращается в кашу. Если в видео часто звучит "ArtGeneration" или "НЕЙРО-СОФТ" — просто добавляешь в контекст, и модель ВСЕГДА распознаёт корректно. Для технического контента — просто спасение.
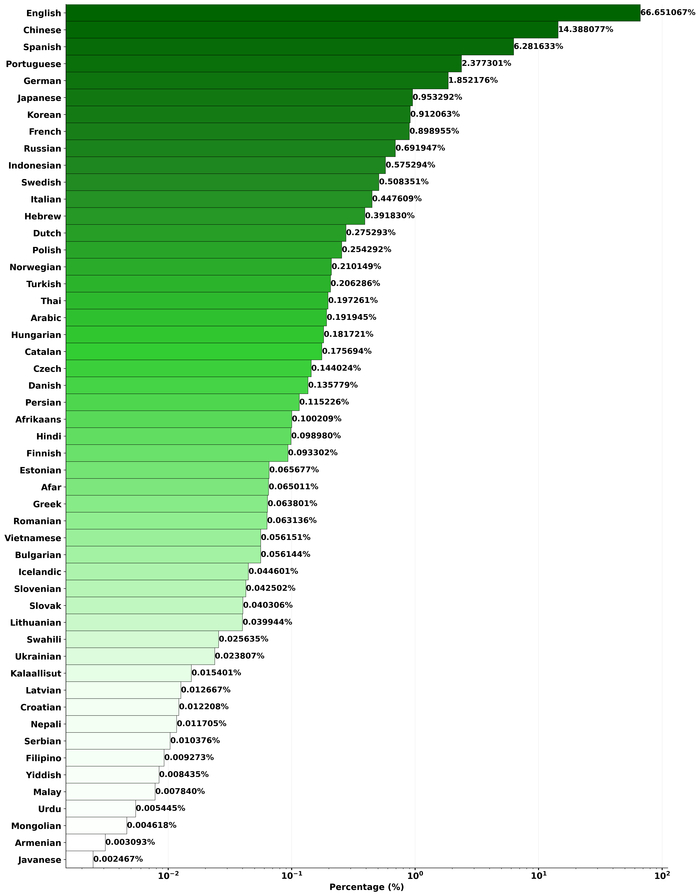
51 язык: включая русский, хотя основной фокус на английском и китайском.
Набор языков отличный
Модели
Помимо оригинальной модели от Microsoft, сообщество уже сделало квантованные версии для видеокарт с меньшим объёмом памяти.
Полная модель — microsoft/VibeVoice-ASR Размер 17.3 GB, требует ~8 ГБ VRAM. Лучшее качество распознавания.
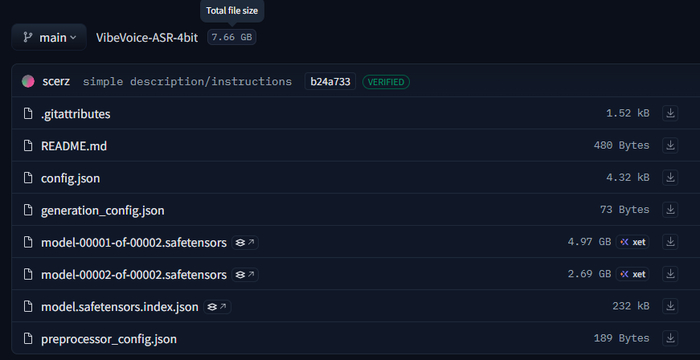
4-bit квантизация — scerz/VibeVoice-ASR-4bit Требует ~4 ГБ VRAM, немного медленнее. Подходит для видеокарт с меньшим объёмом памяти.
В моей портативке доступны обе версии — можно выбрать прямо в интерфейсе. Также есть эмуляция 4-bit квантизации для полной модели, если хотите попробовать оригинал, но памяти впритык.
Текущие ограничения
К сожалению, не все задачи система решает одинаково хорошо:
Перекрывающаяся речь: если два человека говорят одновременно, модель не разделит их корректно.
Короткие фрагменты: диаризация плохо работает на высказываниях менее 1 секунды.
Только batch processing: нет real-time режима, только обработка готовых файлов.
Ресурсоёмкость: требует достаточно мощную видеокарту для комфортной работы.
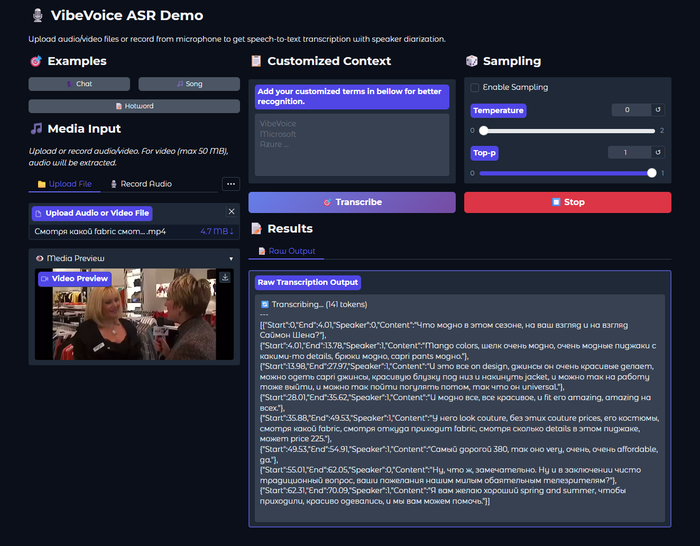
Я с каналом Нейро-Софт подготовил портативную сборку VibeVoice ASR Portable RU. В ней:
Русифицированный интерфейс
Установка в один клик (install.bat)
Поддержка полной и 4-bit моделей
Парсер результатов с фильтрацией — можно отдельно включать/выключать временные метки, спикеров, дескрипторы (музыка, шум, тишина). Удобно когда нужен только чистый текст без разметки
Фильтр по спикерам — можно вывести текст только конкретного участника разговора
Выбор видеокарты и установка нужной версии CUDA
Flash Attention 2 для RTX 30xx/40xx/50xx
Поддержка всех форматов аудио и видео через FFmpeg
Тёмная тема интерфейса
Всё необходимое уже включено в дистрибутив, просто распакуйте и запускайте, есть версия с готовым окружением под win 11 и RTX4090. Забирайте архив тут.
NVIDIA GPU с 8+ ГБ видеопамяти (или 4+ ГБ для 4-bit модели)
Windows 10/11 64-bit
16 ГБ оперативной памяти
10 ГБ свободного места на диске
Распакуйте в любую папку (путь без кириллицы), запустите install.bat, выберите видеокарту из списка. Модели скачаются при первом запуске.
Рассказывайте в комментариях как вы могли бы использовать такой инструмент и чего не хватает.
Я рассказываю больше о нейросетях у себя на YouTube, в Телеграм и на Бусти. Буду рад вашей подписке и поддержке. На канал Нейро-Софт тоже подпишитесь, чтобы не пропустить полезные репаки. Всех обнял. Удачных транскрипций!