

Нейросети для работы
1 пост
1 пост
3 поста

В странах СНГ Telegram давно стал центральным инструментом для развития бизнеса и работы с аудиторией. По свежей статистике 2026 года, ежедневная аудитория (DAU) сервиса в РФ перешагнула отметку в 70 млн пользователей, а число активных пабликов и ботов исчисляется сотнями тысяч. QR-код для Telegram — это удобная точка входа, позволяющая мгновенно направить человека в ваш канал, приватную группу или диалог с ботом без необходимости вбивать юзернейм вручную.
В этой статье разберем разновидности ссылок t.me, пошаговый алгоритм создания QR-кода, особенности работы со start-параметрами, нюансы упаковки приватных приглашений и эффективные локации для размещения.
Чтобы сгенерировать корректный QR, первым делом нужно правильно сформировать исходную ссылку. Мессенджер поддерживает несколько структур адресов — каждая заточена под конкретные задачи.
[https://t.me/username](https://t.me/username) — ведет на страницу пользователя, бота или публичный канал.
[https://t.me/joinchat/ABC123](https://t.me/joinchat/ABC123) — устаревший формат ссылок-приглашений в закрытые группы.
[https://t.me/+ABC123](https://t.me/+ABC123) — современная инвайт-ссылка (внедрена после 2022 года), подходящая для закрытых каналов и чатов.
[https://t.me/username/12345](https://t.me/username/12345) — прямой переход к конкретной публикации.
[https://t.me/username?start=xyz%5D%28https%3A%2F%2Ft.me%2Fus... — запуск бота с передачей стартового параметра.
[https://t.me/username?startgroup=xyz%5D%28https%3A%2F%2Ft.me... — добавление бота в пользовательскую группу.
[https://t.me/username?videochat%5D%28https%3A%2F%2Ft_me%2Fus... — присоединение к трансляции/видеочату.
tg://resolve?domain=username — сразу открывает аккаунт или бота внутри приложения.
tg://resolve?domain=username&start=xyz — запуск бота в приложении с параметром.
tg://join?invite=ABC123 — вступление в приватный чат.
tg://msg_url?url=...&text=... — отправка ссылки через интерфейс шеринга Telegram.
Главное различие: ссылки t.me корректно обрабатываются и веб-браузерами, и приложением, тогда как tg:// срабатывает исключительно при установленном клиенте. Для подавляющего большинства задач рекомендуется выбирать t.me — это универсальный стандарт, считываемый сканерами на Android и iOS. Схему tg:// обычно применяют во внутренних системах, где гарантированно установлен мессенджер.

Базовый сценарий: вы хотите перенести юзернейм (канала, бота или личного профиля) на полиграфию, будь то визитка, флаер или полиграфический стенд.
Перейдите в генератор QRkoder.
Выберите режим «Ссылка» и указать URL формата [https://t.me/your_username](https://t.me/your_username).
Настройте внешний вид: скруглите элементы, задайте фирменный голубой цвет #229ED9 (акцентный цвет Telegram) или оттенки вашего бренда.
Разместите иконку Telegram по центру (самолётик) и укажите уровень коррекции ошибок H.
Экспортируйте файл в SVG (для печатных макетов) или PNG (для использования в цифровой среде).
Совет: Для небольших визиток оптимален размер кода 2.5×2.5 см, для выставочных конструкции — от 15×15 см. Базовое правило расчета: размер QR-кода = расстояние до сканирующего / 10.
Прежде чем отдавать макет в печать, убедитесь в следующем:
юзернейм активен, а аккаунт/канал не заблокирован;
у ресурса отсутствуют гео-ограничения;
адрес вида t.me/username направляет в нужную локацию;
в URL отсутствуют случайные опечатки и пробелы (распространенная ошибка: «t.me/ username»).
Для открытых ресурсов применяется привычный адрес t.me/username. Разница заключается лишь в типе объекта: публичный имеет короткий юзернейм, а закрытый — специальный invite-хеш.
Перейдите в Telegram → Управление каналом → Ссылки.
Скопируйте публичную ссылку вида t.me/your_channel.
Вставьте её в QRkoder для генерации кода.
У закрытых ресурсов нет юзернейма, доступ осуществляется по ссылке-приглашению формата t.me/+Abc123XyZ. У таких ссылок есть важные нюансы:
Для них можно настроить лимит по времени действия (1 час, сутки, неделя, без ограничений) или числу участников.
Создатель может аннулировать ссылку в любой момент, сделав её недействительной.
Для закрытых ресурсов предпочтительнее задействовать динамический режим в QRkoder. В этом случае в сам код зашивается короткая ссылка сервиса, которая перенаправляет на актуальное приглашение Telegram. Если срок действия инвайта истечет, вы просто обновите редирект в панели управления без необходимости перепечатывать полиграфию.
Параметр start — эффективная механика для управления сценариями бота. Он превращает стандартную ссылку в инструмент сквозной аналитики или персонализированной коммуникации (реферальные метки, идентификаторы истока трафика, метки промо-акций).
Публичный запуск: [https://t.me/YourBot?start=PAYLOAD%5D%28https%3A%2F%2Ft.me%2...
Добавление в группу: [https://t.me/YourBot?startgroup=PAYLOAD%5D%28https%3A%2F%2Ft...
Когда человек открывает бота по такой ссылке и нажимает «Запустить», передаваемое значение PAYLOAD отправляется боту в поле start_param первого сообщения. Значение может содержать латинские символы, цифры, дефисы и нижние подчёркивания. Предельная длина — 64 знака.
Реферальная сеть: QR передает payload = ID пригласившего для автоматического начисления бонусов.
Офлайн-аналитика: Использование разных кодов с уникальными payload (один на столах, второй на буклетах, третий на вывеске) показывает реальную конверсию локаций.
Персонализация: Персональные визитки менеджеров с payload=manager_petrov помогают боту закрепить клиента за конкретным сотрудником.
Индивидуальный онбординг: На основе полученного payload бот запускает нужный сценарий приветствия (для покупателей, партнеров или персонала).
Скидочные купоны: Передача Payload=PROMO20 автоматически активирует дисконт при первом обращении.
На ивенте раздаются промо-буклеты: «Отсканируй код и получи подарок». QR указывает на [https://t.me/YourBot?start=event_moscow_2026%5D%28https%3A%2.... Бот считывает параметр, выдает виртуальный купон и присваивает контакту метку «Москва, апрель 2026».
Закулисные сообщества, закрытые клубы и платные подписки — трендовые форматы коммуникации. Код с приватным инвайтом позволяет комфортно выдавать доступ на живых мероприятиях, в закрытых рассылках или при личной встрече.
В настройках приватного канала/чата выберите: Пригласительные ссылки → «Создать новую».
Задайте лимит по времени, число активаций и понятное название (для внутреннего учета).
Скопируйте созданный URL t.me/+hash.
Сгенерируйте код в QRkoder (рекомендуется динамический формат).
Протестируйте переход с двух независимых устройств, чтобы подтвердить корректность работы.
Запускается печать большого тиража (от 1000 экземпляров).
Ссылка ограничена по времени или переходам, и её потребуется периодически обновлять.
Запланировано перенаправление разных сегментов аудитории.
Требуется детальная статистика: количество сканирований, геопозиция, время и типы устройств.
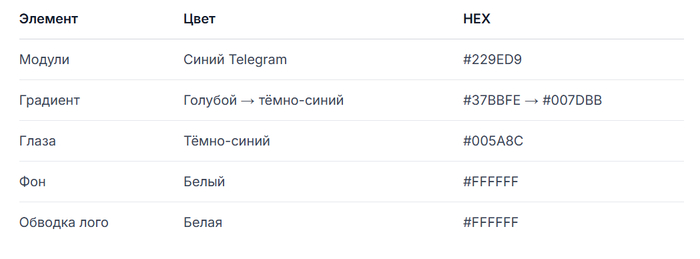
Классическое оформление Telegram строится вокруг синего цвета #229ED9 и градиента #37BBFE → #007DBB. При создании кодов наиболее востребована контрастная пара: тёмно-синий #229ED9 на чистом белом фоне.
Избыточность данных (коррекция ошибок): строго уровень H (30%).
Размер логотипа: не более 25% от всей площади матрицы.
Центральный элемент: фирменный самолётик Telegram в окружности с белой рамкой толщиной 2–3 пикселя.
Угловые метки («глаза»): скругленные квадраты или круги.
Модули: скругленные точки, классические блоки или каплевидные элементы.
Контрастность: соотношение тёмных и светлых участков не менее 4:1.
Тихая зона (Quiet zone): свободный отступ шириной в 4 модуля по всему периметру.
Вариантов интеграции кодов в бизнес-процессы множество. Ниже представлены рабочие механики с подтвержденной эффективностью.
Кассовый чек: QR-код на бота программы лояльности с start=ID_точки. Конверсия: 6–12% от чеков.
Дверные наклейки: «Подпишитесь на закрытые распродажи» + QR. CTR достигает 8% в пиковые часы.
Бьюти-сфера: Код на запись через бота — снижает нагрузку на администраторов на 40–60%.
Заведения общепита: QR «Чаевые официанту» со прямой ссылкой на платежный инструмент.
Бейджи участников: Ссылка на персональный канал или контакт — подписка в одно касание.
Выставочные стенды: Доступ в закрытый чат для VIP-гостей.
Печатные раздатки: Листовки с разделением по блокам: канал, бот, техподдержка.
Наружная реклама: Ситиформаты, билборды, реклама в транспорте с переходами на промо-бота (start=adv_metro_2026).
Товарная упаковка: QR-приглашение в закрытый клуб покупателей.
Подпись в Email: Небольшой код для быстрого перехода в мессенджер.
Наклейка на посылке: Быстрый переход в бот службы заботы — уменьшает количество негативных звонков.
Визитка сотрудника: Индивидуальный код с payload=manager_ID для отслеживания источника контактов.
Превышение длины start-параметра: Предельный объем — 64 символа, иначе бот получит усеченные данные.
Кириллица в payload: Разрешены только латинские буквы, цифры, дефисы и _. Иное приведет к искажению строки.
Использование tg:// вместо t.me для наружной рекламы: Срабатывает только при установленном клиенте, вызывая отвал 20–30% пользователей.
Печать лимитированной инвайт-ссылки огромным тиражом: Ссылка перестает работать после исчерпания лимита переходов, блокируя весь тираж.
Отсутствие белой обводки у логотипа: Модули сливаются с иконкой, вызывая ошибки считывания.
Слабый контраст: Использование бледных градиентов делает код нечитаемым для большинства камер.
Размещение на текстурных/рифленых поверхностях: Преломление света и тени искажают геометрию модулей.
Сам Telegram не предоставляет встроенных инструментов статистики по сканированию кодов. Однако проблему решают два рабочих подхода.
Код ведет через промежуточный домен (например, qrkoder.page/link/abc). Система фиксирует факт сканирования и редиректит пользователя на t.me/your_bot?start=SOURCE. В панели управления QRkoder вы получаете данные по сканам, географии и типам устройств, а бот фиксирует активации по payload.
Каждый носитель снабжается индивидуальным значением: start=visitka, start=flayer, start=insta. Бот сохраняет метку в базу данных. В итоге вы точно видите окупаемость (ROI) каждого рекламного канала и можете вовремя отключить неэффективные.
Соотношение сканирований и запусков бота (конверсия из скана в старт).
Распределение активности по времени суток.
Географический срез.
Соотношение платформ (iOS / Android).
Cohort Retention (возвращаемость пользователей спустя время).
На столах разместили тейбл-тенты с QR-кодом на бота лояльности с привязкой к конкретной точке (start=ID_точки). Результат за 2 месяца: 4200 активаций, 38% повторных посещений, рост среднего чека на 7% за счет персональных спецпредложений.
На бейджи нанесли QR-код со ссылкой на закрытый канал мероприятия. Результат: 83% гостей вступили в канал в первые сутки, проведено 4 тематических интерактива, вовлеченность (ER) составила 28% (в 3 раза выше средних показателей по нише).
В коробки с товаром вкладывали вкладыш с QR: «Оставь отзыв и получи 500 ₽». Код вел на бота для сбора обратной связи. Результат: конверсия в отзыв составила 18%, объем пользовательского контента (UGC) вырос в 5 раз.
QR-код в экосистеме Telegram — это мост между физическим и цифровым мирами. Он превращает любое офлайн-взаимодействие (визитку, упаковку, билборд или бейдж) в управляемый канал коммуникации с минимальным порогом входа для пользователя.
Как мы выяснили, успех внедрения зависит не только от генерации кода, но и от правильного выбора типа ссылки: будь то t.me для максимальной совместимости, динамический формат для защищенных приватных чатов или использование start= параметров для тонкой настройки сценариев бота и сквозной аналитики.
Универсальность — ссылки формата t.me являются золотым стандартом для печати и наружной рекламы, обеспечивая работу на любых устройствах.
Гибкость — применение стартовых параметров превращает статичный код в инструмент персонализации, позволяя отслеживать ROI каждой рекламной площадки и автоматизировать приветствие клиентов.
Надежность — использование высокого уровня коррекции ошибок (H), качественного контраста и динамических ссылок для инвайтов спасает от перепечатки тиражей и сохраняет бюджет.
Аналитика — без сбора данных (через уникальные payload или сервисы редиректа) QR-код остается лишь красивой картинкой; именно цифры конверсий превращают его в бизнес-актив.
Внедряя описанные механики, вы не просто упрощаете переход в мессенджер, а создаете полноценную воронку продаж и лояльности. Заменив статичный код на визитке динамическим с UTM-меткой или добавив бота с персональным приветствием на упаковку товара — появится возможность наблюдать, как растет вовлеченность аудитории.
Используйте QR-код как точку входа, а Telegram — как пространство для диалога. В эпоху перегруженности информацией именно простота и скорость доступа решают, выберет ли клиент вас или останется у конкурентов.

Послеремонтный клининг — это не про протереть пыль и вымыть полы. Его стоит рассматривать как полноценный технологический процесс, требующий профильной химии и специального оборудования. Строительная взвесь оседает неделями, затирочные смеси и грунтовка не смываются универсальными бытовыми средствами, а стандартный домашний пылесос от гипсовой пыли забивается за десять минут и выходит из строя. По этой причине и расценки здесь иные: клининг после строительства стоит в 1,5–2 раза дороже, чем обычная генеральная уборка на аналогичной площади.
Ориентиры по ценам на 2026 год следующие: частные мастера и самозанятые просят от 120 до 200 ₽ за квадратный метр, клининговые службы — от 160 до 300 ₽/м². Однокомнатная квартира обходится в среднем в 5 000–13 000 ₽, а трехкомнатная после капитальных работ — вплоть до 25 000 ₽. Ниже детально разберем, из чего формируются эти расценки, что по умолчанию должно включаться в услугу, а за что с вас попросят отдельную доплату.
(все указанные суммы — это ориентиры для Москвы и Московской области; в регионах прайс обычно ниже на 20–30%)
Главный оппонент здесь — строительная пыль. Мелкодисперсная взвесь из гипса и цемента висит в воздухе и оседает не за пару часов, а в течение нескольких дней: вымыли полы вечером — к утру серый налет снова покрывает все поверхности. По этой причине помещение после ремонта отмывают в несколько заходов и только с использованием строительного пылесоса: у него принципиально иная система фильтрации и мощность, в то время как бытовая техника от подобной нагрузки перегревается и сгорает.
Второе различие — характер загрязнений. Капли краски на кафеле, засохшие остатки затирки, следы грунтовки на ламинате, монтажная пена на подоконниках, клей от защитных пленок и малярного скотча на окнах — всё это требует узкоспециализированных составов: смывок цементных налётов, растворителей для краски и скребков для стеклокерамики. А также четкого понимания, где скребок применить можно, а где он оставит царапины, устранение которых обойдется дороже всей уборки.
Третье — объем работ. Обычная поддерживающая уборка затрагивает полы, сантехнику и открытые видимые поверхности. После ремонта отмывают буквально каждый сантиметр: потолки, стены, светильники, внутренние секции шкафов, дверные коробки, плинтусы, розетки, радиаторы и откосы. Если же вам требуется регулярный, а не послестроительный уход, ориентиры по стоимости мы собрали в отдельном материале — сколько стоит уборка квартиры.
Сбор остатков мусора — обрезки материалов, упаковка, защитная плёнка и картон с пола. Речь идёт о лёгком мусоре: мешки выносят к контейнеру, если это заранее прописано в задаче.
Обеспыливание абсолютно всех поверхностей — потолки, стены, карнизы, трубы, радиаторы отопления, светильники. Сначала применяется строительный пылесос, затем проводиться влажная обработка.
Мытье окон изнутри — стеклопакеты, рамы, откосы, подоконники, удаление малярного скотча, пленки и брызг раствора.
Удаление локальных загрязнений — следы краски, грунтовки, плиточной затирки, клея, побелки, силиконового герметика со стен, пола, плитки и сантехники.
Зона кухни и санузел — отмывание кафеля и швов, полировка смесителей и стекол, обработка сантехники от известкового и цементного налета.
Двери, плинтусы и фурнитура — коробки, наличники, ручки, выключатели и розетки (снаружи, без демонтажа).
Финишное мытье полов — в 2–3 прохода, с итоговой полировкой ламината, плитки или паркета.
Что практически всегда оплачивается отдельно: вывоз строительного мусора (мешки с боем плитки и гипсокартоном — это уже работа для грузчиков и грузовой машины), химчистка мягкой мебели, мытье окон снаружи выше первого этажа, а также уборка балконов и лоджий с остеклением. Перед заказом подробно перечислите клинеру все, что видите на объекте, — тогда ценник из отклика не вырастет прямо на месте.
На рынке используются два метода расчета: за квадратный метр или фиксированной ценой за объект. По метражу проще сравнивать предложения, а фиксированная сумма удобнее для планирования бюджета. Вот ориентиры для квартир со стандартной степенью загрязнения:
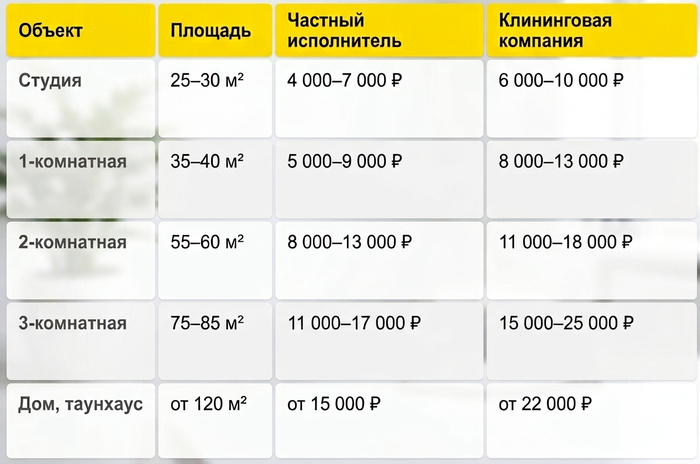
Очистку окон часто тарифицируют отдельно — 300–600 ₽ за створку с удалением скотча и остатков краски. Минимальный чек за выезд у большинства мастеров — 3 000–4 000 ₽, даже если нужно убрать одну небольшую комнату. Все суммы ориентировочные: на сервисе стоимость устанавливает заказчик, а узнать, как она соотносится с рынком по другим услугам, можно на странице с прайсом на работы.
За метр или за объект — как считать выгоднее
Расчет за квадратный метр справедливее для больших и относительно чистых квартир: 80 м² после косметического ремонта по 130 ₽/м² — это 10 400 ₽, а вот фиксированной стоимостью за «трёшку» с вас, скорее всего, попросят больше. Фиксированная ставка выгоднее для компактных, но сильно загрязненных помещений: санузел 4 м² после замены плитки по метражу стоил бы 800 ₽, хотя реальной работы там на 3–4 часа.
Практический прием: в заявке укажите и метраж, и масштаб ремонта, а цену поставьте за объект целиком — так отклики будет удобно сравнивать между собой, и никто не пересчитает стоимость на месте «по факту площади».
Масштаб ремонта. После косметических работ (обои, покраска) стоимость ближе к нижней границе вилки. После капитального ремонта со штроблением, стяжкой и переносом перегородок — к верхней: цементная пыль находится везде, включая внутренности розеток.
Площадь и высота потолков. С квартирами всё линейно, но потолки выше 3 метров прибавляют к чеку 15–20% — требуются стремянки и уходит больше времени на стены.
Количество окон. Каждое окно после ремонта — это 30–60 минут работы: скотч, плёнка, брызги грунтовки. Панорамное остекление удорожает заказ сильнее всего.
Сложные загрязнения. Засохшая монтажная пена на плитке, краска на паркете, цементные подтёки на ванне — за каждую такую сложную точку клинер справедливо накинет 500–1 500 ₽.
Срочность. Формат «сегодня вечером, завтра заезжаем» дороже планового на 20–30%. Если можете подождать 1–2 дня — сэкономите.
Вынос мусора без лифта. Спуск мешков с пятого этажа пешком — тяжелый физический труд, его честнее оплачивать отдельно или заказывать грузчиков.
Сухой сбор. Крупный мусор, пленка, картон и остатки материалов упаковываются в мешки. Помещение готовится к обеспыливанию.
Обеспыливание. Строительный пылесос проходит потолок, стены, углы, плинтусы и полы — в направлении сверху вниз, чтобы пыль не оседала на уже очищенные участки.
Влажная обработка. Стены, двери, подоконники, радиаторы и мебель протираются с нейтральной химией, часто в два захода.
Удаление локальных загрязнений. Точечная работа со следами краски, затирки, клея и пены — самый длительный и квалифицированный этап.
Финиш. Мытьё окон, полировка стёкол и смесителей, финальное мытьё полов по направлению от дальней комнаты к выходу.
По времени: студию и однушку пара исполнителей отмывает за 4–6 часов, двушку — за 6–8, на трёшку после капитального ремонта уходит полный день или бригада из трёх-четырёх человек.
Пример из практики: двушка 56 м² после замены стяжки и штукатурки — двое мастеров, 7 часов работы, 11 000 ₽ с мытьем четырёх окон. Заказчица дважды заказывала обычную уборку до этого — оба раза пыль возвращалась за ночь, потому что без строительного пылесоса её просто гоняли по квартире.
Компании берут дороже на 30–50%, но за эти деньги вы получаете бригаду с промышленным оборудованием, официальный договор и менеджера. Для крупных объектов — дом 200 м², офис после отделки — это оправдано: там необходимы роторные машины и слаженная команда.
Для типовой квартиры экономнее нанять частного исполнителя или пару самозанятых: у опытных специалистов есть и строительный пылесос, и профессиональная химия, а цена ниже, так как вы не оплачиваете офис и рекламу посредника. Самозанятый клинер после оплаты формирует чек через приложение «Мой налог» — для отчётности его полностью достаточно, это предусмотрено 422-ФЗ (по состоянию на 2026 год).
Выбирая человека по отклику, смотрите на три вещи: рейтинг и число выполненных сделок, отзывы именно по уборке после ремонта, а не по любой подработке, и вопросы, которые исполнитель задаёт в чате. Тот, кто спрашивает про метраж, число окон и масштаб ремонта, оценивает объём честно — с ним финальная сумма не «поплывет» на месте.
Квартира в новостройке после отделки от застройщика — самый предсказуемый вариант: пустые комнаты, ровные поверхности, типовые загрязнения. Клинеры любят такие заказы и часто дают цену по нижней границе — 100–150 ₽/м². Единственный нюанс: в свежесданных домах ремонты идут у всех соседей одновременно, и пыль летит из подъезда и вентиляции ещё месяцами. Требовать от разовой уборки стерильности на полгода вперед бессмысленно — реалистичная цель «чисто к заезду», дальше выручает регулярная поддерживающая уборка.
Вторичка после ремонта сложнее: мебель, которую двигали и укрывали пленкой, но пыль всё равно проникла внутрь шкафов; старые окна с рассохшимися рамами, которые нельзя тереть агрессивной химией; ковры и текстиль, впитавшие строительную взвесь. Реальный объем работы здесь на 20–30% больше, чем в пустой новостройке той же площади, — заложите это в бюджет и обязательно напишите в задаче, что квартира с мебелью.
Отдельная история — уборка после частичного ремонта в жилой квартире: пыльная зона одна, а обеспыливать приходится всё жильё, потому что взвесь разносится за дни работы строителей.
Ориентир для торга: пустая новостройка — нижняя граница вилки, вторичка с мебелью — плюс 20–30%, капитальный ремонт со штроблением — плюс ещё 20%. Если отклик сильно дешевле этой логики, исполнитель, скорее всего, недооценил объем — уточните, видел ли он фото.
Вынесите крупный мусор заранее. Мешки со строительным боем — не работа клинера. Вывезете их отдельно (или силами бригады, делавшей ремонт) — уборка подешевеет на 10–15%.
Снимите защитную пленку сами. Час вашего времени экономит исполнителю два, а вам — до 1 000 ₽.
Не заказывайте день в день. Срочность добавляет 20–30% к цене. Пыль всё равно оседает 2–3 дня после окончания работ — спешить некуда.
Закажите частичную уборку. Если ремонт был только в санузле и кухне, не платите за всю квартиру: опишите две зоны, чек будет 3 000–5 000 ₽ вместо 10 000 ₽.
Опишите объект честно и подробно. Парадоксально, но это главная экономия: точное описание = точная цена в отклике, без «на месте оказалось больше, доплатите».
Приемка занимает 10–15 минут и избавляет от взаимных претензий. Проходите по квартире при дневном свете, лучше — против солнца: так видны разводы и пропущенная пыль. Проверьте по списку:
Стекла и зеркала — без разводов и следов скотча по периметру рам, включая верхнюю кромку.
Подоконники и откосы — без точек грунтовки и монтажной пены, углы чистые.
Полы — проведите ладонью вдоль плинтуса и в углах: серого налета на руке быть не должно.
Плитка и швы — затирка не размазана по поверхности, смесители и стекло душа отполированы.
Двери — верхние торцы полотен и коробок (самое частое пропущенное место), ручки, наличники.
Розетки и выключатели — чистые снаружи, без потеков от влажной протирки.
Верх шкафов, карнизы, светильники — проверьте пальцем или салфеткой, туда пыль оседает первым делом.
Нашли пропуски — спокойно покажите их исполнителю до подтверждения оплаты: доделать пару точек на месте занимает минуты, и это нормальная часть работы, а не конфликт. Подтверждайте оплату только после того, как результат вас устроил.
Заказывать уборку до конца «пыльных» работ. Если впереди ещё шлифовка стен или подрезка плитки — любая уборка бессмысленна, платить придется дважды.
Не проговаривать состав работ. «Уборка после ремонта» у всех разная: у одного она включает внутренности шкафов и балкон, у другого — нет. Список из этой таблицы выше решает проблему за минуту.
Принимать работу в сумерках. Разводы на стеклах и остатки пыли на стенах видны только при дневном свете. Приемка вечером под лампочкой — почти гарантированные претензии на следующий день.
Платить вперед. Предоплата переводом на карту до начала работы — красный флаг. Оплата на сервисе проходит после подтверждения результата, и это защищает обе стороны.
Забыть про мусор. Пять мешков цементного боя в коридоре не исчезнут после клининга — вывоз строительного мусора планируйте отдельной задачей заранее.
Качественная уборка после ремонта — это финишный и самый долгожданный этап, который превращает строительную площадку в уютное, чистое и готовое для жизни жилье. Пытаться справиться со въевшейся грунтовкой, следами затирки и тоннами мелкодисперсной пыли своими силами — это почти всегда потеря нескольких дней и риск испортить свежую отделку бытовыми средствами.
Разумеется, для того чтобы убраться в квартире, не нужна ученая степень и годы практики, но доверив эту задачу профессионалам со специальной химией и мощными строительными пылесосами, вы экономьте время, силы и нервы. Главное — четко сформулировать задачу, дождаться полного окончания строительных работ и принимать объект при дневном свете.
Оформить заказ, установить удобную стоимость и быстро подобрать проверенных клинеров с реальными отзывами вы можете на сервисе Свободные руки.

Многие собственники бизнеса сталкиваются с этой ситуацией: SEO-подрядчик присылает отчет, где всё выглядит блестяще. Сайт поднимается в выдаче, трафик идет в гору, часть запросов уже обосновалась в топ-10. Однако при открытии CRM или подсчете звонков за месяц картина не меняется. Заявок больше не становится, а вопрос «за что именно мы платим» так и повисает в воздухе.
Суть не в том, что подрядчик недобросовестен или бездействует. Суть в другом: место в поисковой выдаче — это индикатор процесса, а не бизнес-результата. Оно свидетельствует о том, что поисковик хорошо видит сайт. Но оно ничего не говорит о том, придет ли на этот сайт нужный клиент и совершит ли он заказ.
На связи команда Big Panda, мы уже 13 лет на рынке digital и в этой статье мы разберем, почему рост позиций и рост выручки — далеко не одно и то же, как самостоятельно выявить, продают ли вам красивую отчетность или реальный эффект, а также что нужно дорабатывать на сайте, чтобы трафик конвертировался в заявки, а не оставался просто цифрой в презентации.
Стандартный SEO-отчет строится вокруг конкретных метрик: позиции по ключевым словам, объем органического трафика, число проиндексированных страниц. Все эти параметры описывают техническую видимость ресурса для поисковых роботов. Но они не дают ответа на главный вопрос: купил ли кто-либо что-либо.
Топ-1 по информационному запросу с нулевым коммерческим потенциалом в отчете выглядит так же весомо, как и топ-1 по горячему коммерческому запросу с высокой готовностью к покупке. Для отчета это просто одинаковые строки. Для бизнеса же разница конкретная: во втором случае человек ищет, где приобрести прямо сейчас, в первом — просто проявляет интерес к теме.
● Не тот тип запроса. Когда продвижение строится вокруг общих или информационных ключевиков, а не вокруг тех фраз, с которыми люди приходят с намерением заказать услугу, рост позиций не перетекает в обращения. Разделение семантики на информационную и коммерческую — это база, без которой все остальные работы теряют смысл.
● Zero-click и AI-ответы. Пользователь получает ответ прямо в поисковой выдаче или в диалоге с нейросетью и просто не переходит на сайт. Это не гипотеза, а зафиксированный тренд последних двух лет.
● Разрыв на стороне сайта. Даже целевой посетитель, попавший на ресурс, может не оставить заявку — если форма не работает, страница долго грузится на мобильном, не видно цен или контактов. Позиции здесь ни при чем: проблема кроется на финальном шаге, который решается уже не ключевыми словами, а юзабилити.
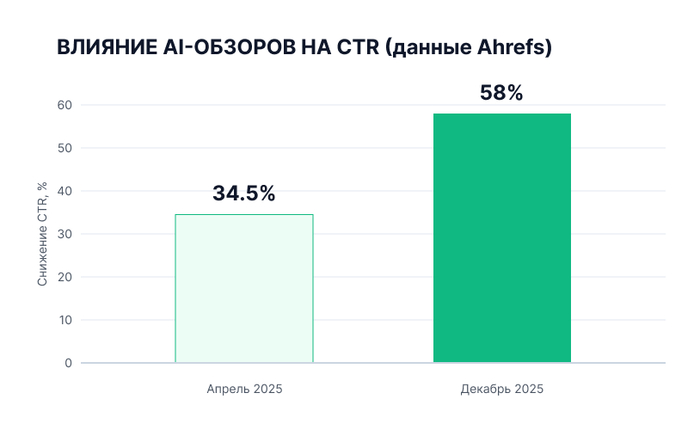
По данным исследования Ahrefs, построенного на анализе 300 000 запросов и данных Google Search Console, к декабрю 2025 года присутствие AI-обзора в выдаче снижало средний CTR для страницы на первой позиции на 58% по сравнению с аналогичными запросами без AI-обзора — рост с 34,5% в апреле того же года:
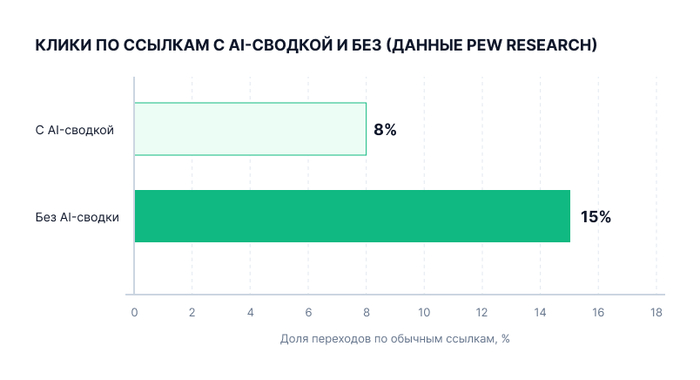
Исследование Pew Research Center, основанное на отслеживании почти 69 000 реальных поисковых запросов, показало похожую картину: при наличии AI-сводки пользователи переходят по обычным ссылкам в среднем в 8% случаев против 15% без неё. Важная деталь: AI-обзоры почти не появляются по явно транзакционным и коммерческим запросам вроде «заказать», «купить», «цена» — эффект сильнее всего бьет именно по информационному трафику.
Прежде чем разбираться, что именно чинить, стоит понять, отражает ли текущий отчет действительно нужные показатели. Вот вопросы, которые полезно задать себе или подрядчику:
Какая доля продвигаемых запросов относится к коммерческим, а не к информационным
Настроена ли сквозная аналитика по звонкам и заявкам, а не только фиксация визитов на страницу «Контакты»?
Присутствует ли в отчете показатель конверсии из органического трафика, а не только сам трафик и позиции?
Анализировалось ли поведение пользователей на сайте — записи сессий, карты кликов и скроллинга?
Есть ли в отчетах гипотезы и тесты, а не просто формулировка «работы выполнены по плану»?
Если на большинство пунктов ответ «нет» — скорее всего, вам демонстрируют метрики процесса, а не метрики денег. Разница между ними хорошо укладывается в простое сопоставление:
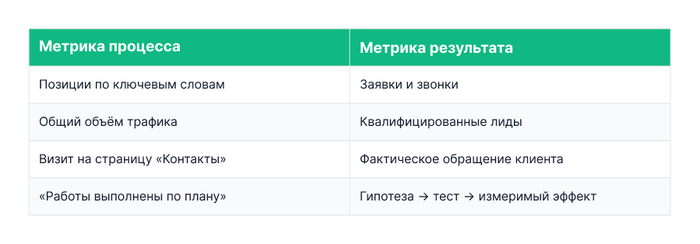
Коммерческие факторы — это элементы сайта, которые сигнализируют одновременно и поисковой системе, и живому пользователю: здесь можно доверять и здесь удобно оформить заказ. К ним относят полные контактные данные и разные способы связи, страницу «О компании» с реквизитами и историей, понятные условия оплаты и доставки, отзывы, сертификаты и лицензии, защищённое соединение.
Здесь важен один момент: коммерческие факторы — это не отдельная строка бюджета «для поисковика». Одни и те же доработки одновременно повышают доверие алгоритма и снижают количество людей, которые уходят с сайта, так и не оставив заявку. Это редкий случай, когда работа на позиции и работа на конверсию — буквально одно и то же действие.
Скорость загрузки, корректная работа сайта на мобильных устройствах, работоспособность формы заявки — не «приятные бонусы», а обязательные условия для того, чтобы трафик вообще имел шанс превратиться в обращение. Записи сессий и карты кликов дают конкретные гипотезы для доработки: например, где именно пользователи «спотыкаются» на форме или какой блок на странице игнорируют.
Погоня за максимальным количеством запросов в топе часто размывает фокус: часть усилий уходит на низкоконверсионные фразы просто потому, что по ним легче показать рост в отчёте. Более рабочий подход — сузить фокус на запросах, которые реально ведут к заявке, даже если их меньше и конкуренция выше.
Тренд на снижение переходов из-за AI-ответов делает ставку исключительно на трафик еще более рискованной стратегией. Если раньше можно было компенсировать слабую конверсию за счет большого объема посетителей, то на фоне падения CTR по информационным запросам этот путь работает всё хуже.
При этом у ситуации есть и обратная сторона: AI-обзоры почти не затрагивают явно коммерческие и транзакционные запросы — то есть именно тот сегмент, где сайт с проработанными коммерческими факторами и удобной формой заявки получает относительно больше шансов забрать клиента, а не просто показ. Иными словами, чем меньше остаётся «дешёвого» информационного трафика, тем дороже становится каждый пришедший посетитель — и тем важнее, чтобы сайт умел его конвертировать.
● Фиксировать KPI не только по позициям и трафику, но и по конверсиям, звонкам и заявкам. Позиции можно оставить как промежуточный ориентир, но не как единственную цель.
● Настраивать сквозную аналитику до начала работ, а не пытаться разобраться в источниках лидов постфактум, когда данных за прошлые месяцы уже нет.
● Менять вопрос к подрядчику. Вместо «сколько ключей в топе» — «сколько заявок пришло и во сколько обошлась каждая».
● Требовать в отчетах не только цифры, но и логику. Гипотеза, что именно исправлено, тест, измеримый эффект — это признак работы на результат, а не имитации бурной деятельности.
Позиция в поисковой выдаче — инструмент, а не цель бизнеса. Она полезна ровно настолько, насколько помогает нужному человеку дойти до сайта и совершить целевое действие. SEO продолжает работать и приносить деньги, но только если в фокусе оказываются правильные метрики: не только видимость в выдаче, но и коммерческие факторы, юзабилити и реальный путь клиента от клика до заявки.
Если ситуация знакома — трафик растет, а звонков и заявок больше не становится, — имеет смысл не менять подрядчика вслепую, а сначала разобраться, где именно теряется клиент: на этапе поиска, перехода или уже на самом сайте. Это тот случай, когда точный диагноз важнее быстрого решения.

Вы действуете строго по инструкции: яркий баннер, четкое УТП, скидка заметным шрифтом, призыв к действию на самом видном месте. А CTR всё равно неуклонно снижается, лиды дорожают, и маркетолог только разводит руками — мол, аудитория «выгорела». Знакомо для любой ниши с высокой конкуренцией.
Проблема в том, что «правильная» реклама ориентирована на сознание покупателя — но решение о покупке в 90% случаев принимается совсем не там. Оно возникает за доли секунды, на уровне автоматических реакций мозга, и только затем человек находит для него рациональное обоснование. Пока креатив взывает к логике («у нас цена ниже», «у нас качество лучше»), он уступает конкурентам, которые воздействуют на более древние и быстрые механизмы восприятия.
Мы — команда Big Panda, вот уже 13 лет работаем в сфере digital, и в этой статье хотели бы поделиться с вами прикладными когнитивными триггерами: как они функционируют на уровне мозга, где их уместно применять и как не перейти в манипуляцию, которая наносит урон репутации бренда.
У баннерной слепоты есть простое объяснение: мозг — это орган, экономящий энергию. Он не способен осознанно перерабатывать весь визуальный поток, который на него обрушивается, и потому автоматически отсеивает всё, что определяет как привычный, повторяющийся паттерн.
Яркая кнопка с надписью «Скидка 10%», стоковое фото счастливого человека, стандартная композиция «текст слева — картинка справа» — всё это мозг помечает как «реклама» еще до того, как вы успели прочитать оффер, и просто пропускает мимо. Поэтому один и тот же креатив, который отлично работал в первый месяц кампании, ко второму приносит кликов вдвое меньше при тех же аудитории и настройках: дело не в алгоритмах площадки, а в том, что глаз пользователя уже запомнил этот визуальный паттерн и перестал на нём задерживаться.
Отсюда логичный вывод: побеждает не тот креатив, который «красивее» с точки зрения дизайна, а тот, который строится на понимании того, как именно мозг фильтрует и перерабатывает информацию. Это и есть суть нейромаркетинга — работа с конкретными механизмами восприятия и принятия решений.
В основе большинства современных моделей потребительского поведения лежит представление о двух режимах мышления. Первый — быстрый, автоматический, эмоциональный: он действует по шаблонам и эвристикам, принимает решения почти мгновенно и требует минимум энергии. Второй — медленный, аналитический, требующий сознательных усилий: сравнение цен, изучение характеристик, взвешивание аргументов.
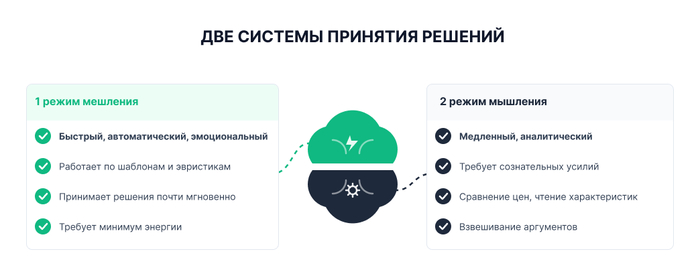
Проблема для маркетолога в том, что подавляющее большинство решений о покупке — особенно в сегменте недорогих и импульсных товаров — принимается именно первым, быстрым режимом. Человек видит оффер, испытывает эмоциональную реакцию (интерес, тревогу дефицита, доверие), принимает решение — и только затем находит рациональное обоснование: «у них хорошие отзывы», «выгодная цена», «нужная вещь».
Это значит, что креатив и лендинг должны быть в первую очередь заточены на быстрый, эмоциональный уровень восприятия — а рациональные аргументы (характеристики, сравнения, гарантии) включаются уже на втором этапе, закрепляя решение, которое человек фактически уже принял.
Далее — разбор конкретных триггеров, которые обращены именно к этому быстрому уровню.
Эффект якоря: как первая цифра управляет всем восприятием
Эффект якоря — одно из самых изученных когнитивных искажений. Суть в том, что мозг, оценивая любую величину (в том числе цену), сильно опирается на первую полученную информацию, даже если она логически не связана с последующим решением. Первая цифра, которую увидел человек, становится точкой отсчёта, относительно которой оцениваются все остальные варианты.
В маркетинге это работает через несколько простых механик:
Зачёркнутая старая цена рядом с новой. Мозг сравнивает не абсолютную цену товара, а разницу между «было» и «стало» — и именно эта разница воспринимается как выгода, даже если итоговая цена всё ещё выше рынка.
Порядок тарифов в прайсе. Если первым показать самый дорогой тариф, все последующие варианты будут восприниматься как более доступные — просто потому что якорь уже задан на высоком уровне.
Дробление суммы. «Всего 990 ₽ в месяц» воспринимается легче, чем «11 880 ₽ в год», хотя речь об одной и той же сумме — якорем становится меньшее число.

Важный нюанс: якорь работает только тогда, когда выглядит правдоподобно. Зачёркнутая цена, которая в три раза выше реальной рыночной, скорее вызовет недоверие и раздражение, чем ощущение выгоды — аудитория в высококонкурентных нишах, как правило, уже умеет считать и сверять цены у конкурентов в соседней вкладке.
Социальное доказательство: почему мы копируем чужой выбор
Ещё один мощный механизм — склонность ориентироваться на поведение других людей в ситуации неопределённости. Если человек не уверен, стоит ли доверять новому продукту или незнакомому бренду, мозг ищет подсказку в самом простом источнике: а что выбрали другие.
Практические форматы социального доказательства:
Количественные показатели — счётчики «купили 12 000 человек», «выбрали 4,8 из 5», отметки «бестселлер» или «хит продаж».
Отзывы и UGC-контент — особенно с фото и конкретными деталями, а не обобщённой похвалой.
Кейсы «до / после» — визуальное или текстовое доказательство результата, которое снижает субъективное ощущение риска.
Экспертное доказательство — упоминания в СМИ, сертификации, рекомендации специалистов или лидеров мнений.
Социальное доказательство работает тем сильнее, чем выше воспринимаемый риск покупки: для товара за 300 рублей оно почти не нужно, а для дорогой услуги или покупки в незнакомой нише может стать решающим фактором. Именно поэтому в высококонкурентных нишах, где рациональные преимущества у всех примерно одинаковые, доверие через чужой опыт зачастую работает сильнее, чем ещё один аргумент в пользу продукта.
Отдельный и часто недооцененный инструмент — управление вниманием через направление взгляда на изображении. Это работает на уровне древнего эволюционного механизма: мозг человека автоматически считывает, куда смотрит другой человек, и невольно следует за его взглядом — так работало распознавание опасности или интересного объекта задолго до появления рекламы.
Именно на этом принципе строится технология eye-tracking, которая позволяет измерять, куда именно смотрит пользователь и сколько времени задерживается на разных элементах страницы. И практика показывает системную ошибку: персонаж на баннере, смотрящий прямо в камеру или в сторону, уводит внимание зрителя от ключевого сообщения — заголовка, цены, кнопки. А вот если взгляд модели направлен на оффер или на призыв к действию, зритель неосознанно следует за этим взглядом и «дочитывает» именно то, что должно было зацепить его в первую очередь.

Практические выводы для дизайна креатива и лендинга:
Направляйте взгляд персонажа на баннере на ключевой элемент — цену, кнопку, заголовок, а не в объектив камеры.
Учитывайте естественные паттерны считывания страницы (F-паттерн для текстовых блоков, Z-паттерн для лендингов с одним акцентом) — ключевое сообщение должно попадать в те зоны, где взгляд задерживается дольше всего.
Проверяйте, не перетягивает ли декоративный элемент внимание с формы заявки или цены — красивая, но избыточная деталь способна полностью «съесть» конверсию, даже если сам оффер сильный.
Первый экран должен считываться за секунды: если для понимания сути предложения нужно всматриваться, мозг, скорее всего, просто пропустит баннер дальше.
Помимо якоря, социального доказательства и управления взглядом, есть ряд более узких, но не менее рабочих механизмов.
Эффект дефицита. Ограниченность по времени или количеству («осталось 3 места», «акция до пятницы») усиливает субъективную ценность предложения — но только если ограничение реальное. Фейковые обратные отсчёты, которые обнуляются при обновлении страницы, быстро считываются аудиторией и работают против доверия к бренду.
Эффект фрейминга. Одна и та же информация воспринимается по-разному в зависимости от подачи: «эффективность 85%» звучит убедительнее, чем «риск неудачи 15%», хотя это математически одно и то же. Формулировка через выгоду и позитивный исход почти всегда работает лучше, чем формулировка через угрозу или недостаток.
Избегание когнитивного диссонанса. После совершения покупки человек склонен искать подтверждение, что сделал правильный выбор, и избегать информации, которая заставит в этом усомниться. Письмо или сообщение после оплаты, которое подкрепляет решение позитивным сигналом («вы сделали отличный выбор», подборка советов по использованию), снижает вероятность возврата и повышает лояльность.
Принцип взаимного обмена. Бесплатная ценность до момента продажи — полезный гайд, диагностика, пробный период — формирует у человека ощущение небольшого «долга» и повышает готовность ответить встречным действием, то есть покупкой.
Когнитивная простота. Чем легче считывается сообщение — короче фразы, понятнее структура, меньше визуального шума, — тем выше уровень доверия к нему. Мозг склонен путать лёгкость восприятия с достоверностью: простое кажется более правдивым, чем сложное.
Возьмём условный оффер услуги — например, онлайн-курс в перегретой нише инфобизнеса. Стандартный подход: яркий баннер с «экспертом», списком из пяти УТП и кнопкой «Записаться». Такой креатив в 2026 году практически гарантированно тонет в баннерной слепоте — аудитория видела сотни визуально похожих предложений.
Что меняется при работе с когнитивными триггерами:
На баннере — реальный человек (не стоковое фото), взгляд которого направлен на цену и кнопку записи, а не в камеру.
Рядом с ценой — зачёркнутая «полная» стоимость и то, за что именно скидка (якорь, привязанный к правдоподобной причине, а не к произвольно завышенной цифре).
Прямо под ценой — конкретная цифра о количестве уже записавшихся или короткий отзыв с именем и результатом (социальное доказательство в зоне, куда как раз ведёт взгляд с баннера).
Заголовок сформулирован через выгоду, а не через страх упустить возможность (фрейминг).
Вместо пяти УТП списком — одно ключевое сообщение, считываемое за секунду, и ссылка «подробнее» для тех, кто готов перейти в аналитический режим чтения.
Разница не в бюджете и не в качестве картинки, а в том, что каждый элемент теперь работает на конкретный механизм восприятия, а не существует «потому что так принято».
Когнитивные триггеры — это не про «добавить все сразу и посмотреть, что получится». Правильный подход:
Одна гипотеза — один тест. Меняйте по одному элементу (только якорь, только направление взгляда, только формулировку заголовка), иначе невозможно понять, что именно повлияло на результат.
Смотрите не только на CTR. Время на странице, глубина скролла, карта кликов и внимания дают гораздо больше информации о том, где именно теряется интерес, чем один финальный показатель конверсии.
Используйте доступные инструменты аналитики. Вебвизор и тепловые карты в Яндекс Метрике, простые сервисы для проверки гипотез о внимании — не обязательно дорогое оборудование для нейромаркетинговых исследований, чтобы начать замечать закономерности.
Обновляйте креативы до момента выгорания, а не после. Если ориентироваться только на падение метрик, часть бюджета уже будет потрачена впустую — эффективнее закладывать ротацию креативов заранее, ориентируясь на среднюю частоту показов на аудиторию.
Важно провести чёткую границу. Когнитивный триггер усиливает восприятие реальной выгоды продукта. Манипуляция создаёт ложное представление о ней.
Зачёркнутая цена, которая никогда не была актуальной; счётчик «осталось 2 места», который не меняется неделями; фейковые отзывы — всё это тоже опирается на те же когнитивные механизмы, но работает на разрушение доверия в среднесрочной перспективе. Пользователь, обнаруживший обман, не просто не купит — он с высокой вероятностью расскажет об этом другим, а в перегретых нишах репутационные потери восстанавливаются намного дольше, чем падение CTR.
Работающий принцип простой: продавать подсознанию — не значит обманывать сознание. Все перечисленные выше триггеры дают устойчивый эффект именно тогда, когда за ними стоит реальный продукт, реальная цена и реальный социальный опыт.
В высококонкурентных нишах побеждает не самый громкий креатив, а тот, который точнее устроен в соответствии с тем, как мозг фильтрует информацию и принимает решения. Эффект якоря, социальное доказательство и управление взглядом — это не разовые «фишки», а рабочие инструменты, которые можно тестировать и встраивать в воронку системно, от баннера до формы оплаты.
Триггеры помогают привлечь внимание и подтолкнуть к первому решению — но удержать клиента после покупки помогают уже другие механизмы, включая персонализацию на основе данных о поведении.

Структура корпоративных коммуникаций в России за последние несколько лет кардинально преобразилась. Если раньше выбор площадки для общения с клиентами или внутреннего обмена данными в команде определялся личным удобством и привычкой, то в 2026 году это решение диктуется сухим прагматизмом и стремлением обезопасить компанию от возможной внезапной изоляции.
В агентстве Big Panda мы на ежедневной основе проводим анализ эффективности различных каналов трафика и коммуникаций и наблюдаем устойчивую тенденцию: некогда непоколебимые инструменты постепенно сдают позиции в плане стабильности. Вступление в силу и ужесточение норм законодательства (включая известный № 41-ФЗ) возложили серьезные обязательства на игроков из ритейла, финтеха, медицинской сферы и B2C-сегмента. Технические ограничения со стороны регуляторов, например, блокировка аудио- и видеозвонков на зарубежных платформах, превратили привычные чаты в зону повышенного риска. В любой момент компания может столкнуться с тем, что ее сотрудники не смогут оперативно связаться с заказчиком, а наработанная годами база клиентов окажется недоступной.
Мы не агитируем за мгновенный отказ от всех зарубежных приложений и принудительный перевод пользователей на новые площадки. Наша цель — провести объективный и холодный аудит текущего состояния рынка.
В этой статье мы детально рассмотрим техническую составляющую отечественных платформ, проанализируем их реальные возможности для бизнеса на примере MAX и VK, а также покажем, как выстроена разработка под эти экосистемы и за счет чего они обеспечивают требования комплаенса, помогая выстраивать устойчивую бизнес-модель.
Представленная информация носит исключительно ознакомительный характер и не является официальной юридической консультацией. Законодательство в области цифровых коммуникаций и персональных данных регулярно обновляется. Перед принятием инфраструктурных решений настоятельно рекомендуем проконсультироваться с корпоративными юристами.
Права и обязанности бизнеса при использовании мессенджеров регулируются следующими первоисточниками:
Персональные данные: Федеральный закон № 152-ФЗ «О персональных данных» — определяет правила сбора, хранения и трансграничной передачи ПД.
Запрет иностранных платформ: Статья 10 Федерального закона № 149-ФЗ (в ред. закона № 41-ФЗ) — устанавливает ограничения на использование зарубежного ПО для банков, госкомпаний и КИИ.
Реклама и рассылки: Федеральный закон № 38-ФЗ «О рекламе» — регулирует правила отправки рекламных сообщений, пушей и получения согласия пользователей.
Ответственность и штрафы: Статья 13.11 КоАП РФ (нарушения в ИТ и ПД) и Статья 14.3 КоАП РФ (нарушения законодательства о рекламе).
Говоря о поиске альтернативных решений, важно учитывать не только юридическую безопасность, но и уровень развития ИТ-инфраструктуры. Бизнесу нужна площадка с удобными инструментами разработки. И здесь логичным промежуточным решением выглядит экосистема VK, которую технологически выстраивали на протяжении многих лет.
Интерфейс для создания встроенных приложений — VK Mini Apps — развивается с 2018–2019 годов. Для digital-рынка это весомое преимущество: под эту экосистему уже существует качественная документация, понятные API-интерфейсы и сформирован пул опытных разработчиков. Бизнесу не нужно изобретать велосипед, чтобы развернуть внутри мессенджера или соцсети полноценные коммерческие решения.
Что именно можно реализовать на базе этой платформы без потери качества пользовательского опыта?
Встроенные экосистемы (Mini Apps): Это веб-приложения, работающие непосредственно в интерфейсе VK без перехода во внешний браузер. Здесь можно организовать полноценный интернет-магазин с каталогом и корзиной, личный кабинет клиента, интерактивную карту или программу лояльности. Пользователю не нужно загружать отдельное приложение на смартфон — всё функционирует в один клик.
Автоматизация рутины: Мессенджер VK предоставляет широкие возможности для создания ботов под любые задачи. Они эффективно закрывают потребности B2B-сегмента (например, автоматическое выставление счетов, сбор закрывающих документов, опросы контрагентов) и B2C-маркетинга (проведение акций, автоматическое распределение лидов в CRM, первичный скрининг кандидатов).
Переход к ИИ-агентам: Сегодня простые кнопочные сценарии уступают место интеллектуальным системам. Благодаря открытому API, компании интегрируют в текстовые каналы VK современные языковые модели. Такой ИИ-ассистент не просто действует по шаблону, а понимает контекст живой речи, умеет работать с базами данных бренда и самостоятельно выполнять сложные команды (например, проверять остатки на складе или статус доставки).
Если перед вашей командой стоит задача быстро запустить автоматизацию в российском контуре, создание чат-бота в MAX или VK становится рядовой инженерной задачей. При этом разработка позволяет применять схожую логику архитектуры (Node.js, Python), что заметно сокращает издержки на перенос ИТ-инфраструктуры с зарубежных платформ.
Если VK — это давно известная рынку экосистема, то MAX, также созданный VK, стал главным предметом обсуждения в B2B-среде. Платформа проектировалась с оглядкой на опыт WeChat, объединяя в одном окне личные переписки, госсервисы и коммерческие инструменты.
Аудитория MAX формируется не за счет стихийного органического трафика, а благодаря системным государственным механизмам. Обязательная предустановка приложения на все ввозимые в РФ смартфоны, постепенный перевод ведомственных коммуникаций и корпоративных чатов госслужащих обеспечивают платформе стабильный приток активных пользователей. Для бизнеса это означает одно: игнорировать данный канал в рамках долгосрочной стратегии уже нельзя.
Рассмотрим, как устроен бизнес на этих платформах с технической и организационной точек зрения.
Прежде всего, руководителю стоит понимать: в мессенджере действует строгий бизнес-режим. В отличие от Telegram, где автоматизацию может настроить любой анонимный пользователь за пару минут, регистрация бизнеса в MAX требует официальной верификации. Для получения доступа к коммерческим возможностям необходимо предоставить документы юрлица (ИНН, ОГРН) и пройти модерацию.
После верификации компания получает полноценный бизнес-профиль, который открывает доступ к следующим инструментам:
Официальный канал для бизнеса: Компании могут вести публичные блоги, публиковать новости, аналитику и обновления продуктов. Запуск вещания начинается с создания канала через панель управления и подтверждения прав на бренд. Это защищает бизнес от фейковых аккаунтов и мошенничества от имени вашей организации.
Бизнес-аккаунты и тарифы на рассылки: Официальный аккаунт позволяет осуществлять легальные массовые рассылки по базе клиентов (например, сервисные уведомления или статусы заказов) с прозрачной тарификацией и гарантией доставки, что заменяет дорогие СМС-шлюзы.
Сквозной комплаенс и Госуслуги: Это ключевое УТП платформы. Мессенджер полностью автономен и находится в российской юрисдикции, что снимает риски по закону № 41-ФЗ. Благодаря интеграции с «Госуслугами», пользователи могут авторизоваться в вашем мини-приложении через «Цифровой ID» (подтверждая возраст, личность или льготы), а также подписывать договоры через встроенный сервис «Госключ».
Банкинг и Финтех без ограничений: Для банков, столкнувшихся с удалением приложений из App Store и Google Play, MAX стал технологическим спасением. Платформа позволяет создавать сложные финансовые Mini Apps. Поскольку они работают внутри мессенджера, санкции не влияют на их доступность для пользователей iOS и Android.
Таким образом, оценивая возможности MAX для бизнеса, мы видим изолированную, юридически чистую и технически оснащенную среду для безопасного развертывания корпоративных сервисов любого масштаба.
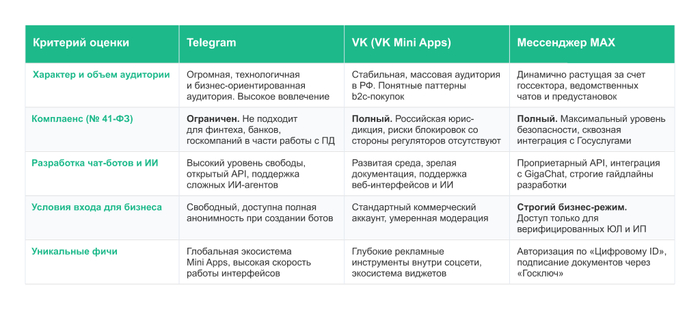
Чтобы помочь техническим специалистам и маркетологам принять взвешенное решение, мы в Big Panda свели ключевые параметры трех экосистем в единую матрицу. Это позволит оценить готовность каждой площадки под конкретные задачи вашего бизнеса в 2026 году.
Автоматизация текстовых каналов — это первый логичный шаг для компании, осваивающей новую площадку. Рассмотрим практическую сторону вопроса для реальных бизнес-задач без привлечения дорогостоящей ИТ-команды.
На рынке адаптировались стандартные конструкторы чат-ботов — no-code и low-code платформы позволяют собирать базовые сценарии (ответы на FAQ, сбор контактов, отправку ссылок) через визуальные блоки. Если нужен простой линейный ассистент, запустить его можно довольно быстро.
Однако если речь идет о полноценном бизнес-чате в MAX, интегрированном с внутренней ИТ-инфраструктурой, конструктора будет недостаточно. Для создания кастомных решений (проверка баланса в CRM, выставление счетов через эквайринг или бронирование в календаре) применяется разработка на Python или Node.js с использованием официального API.
Технической команде стоит обратить внимание на расширенные возможности платформы:
Чат-бот MAX и Госуслуги: Разработчики могут настроить сценарий так, чтобы при критически важных операциях бот запрашивал авторизацию через ЕСИА. Это полностью легализует транзакции и обмен данными.
Госключ MAX: Интеграция, позволяющая автоматизировать подписание B2B-договоров или B2C-оферт прямо в интерфейсе чата. Бот генерирует документ, отправляет запрос в «Госключ» и возвращает верифицированный статус в вашу учетную систему.
Перед тем как создать бизнес-чат в MAX или запустить автоматизацию, подготовьте серверную инфраструктуру внутри российского контура (например, у отечественных облачных провайдеров) — это базовое требование для прохождения модерации.
Если ваша компания приняла решение диверсифицировать риски и развернуть резервный канал, воспользуйтесь этим пошаговым регламентом.
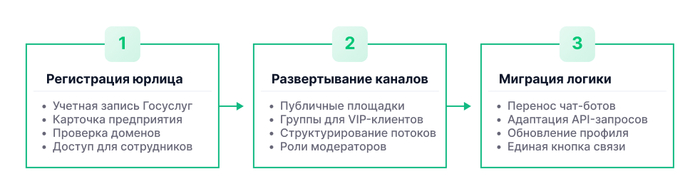
Шаг 1. Вход и регистрация юридического лица
Для входа в бизнес-панель потребуется учетная запись организации на Госуслугах. Физическое лицо или анонимный аккаунт не смогут активировать коммерческие опции. Подготовьте карточку предприятия (ИНН, ОГРН, уставные документы) и укажите официальные домены сайтов. После проверки модераторами вам станет доступна регистрация, и вы сможете управлять правами доступа сотрудников.
Шаг 2. Развертывание каналов и чатов для аудитории
Определитесь с форматом взаимодействия. Если цель — вещание и маркетинг, настройте публичную площадку. Для координации проектных команд или закрытого комьюнити для премиальных клиентов настройте бизнес-чат или группу. Это позволит структурировать информационные потоки и распределить роли модераторов.
Шаг 3. Миграция программной логики и настройка User Flow
Перенос существующих чат-ботов с зарубежных платформ не означает, что код придется писать с нуля. Архитектурная логика (дерево диалогов, интеграции с БД, обработка вебхуков) сохраняется. Вашей ИТ-команде потребуется лишь переписать слой обработки API-запросов под спецификации новой платформы. На финише обновите бизнес-профиль — добавьте графики работы, адреса, ссылки на сайт и настройте омниканальные виджеты на основном веб-ресурсе для бесшовного выбора канала связи.
Подводя итог технического аудита новых площадок, подчеркнем: перенос части корпоративных коммуникаций на российские ИТ-платформы в 2026 году — это не признак паники, а зрелый и прагматичный подход к риск-менеджменту.
Мы детально разобрали, как бизнесу перейти на отечественные платформы, настроить автоматизацию и использовать официальный чат-бот для защиты от блокировок и комплаенс-рисков. Интеграция с государственными цифровыми сервисами дает российским компаниям утилитарные инструменты (верификация по паспорту, подписание договоров в один клик), аналогов которым нет на зарубежных площадках.
Финальный выбор технологического стека и глубина миграции всегда остаются за вами — они должны опираться на специфику отрасли, объемы трафика и внутренние политики безопасности. Главное — помнить, что устойчивость бизнеса определяется его способностью бесперебойно взаимодействовать с клиентом при любых внешних условиях.

Данный материал подготовлен в информационных целях и не заменяет собой индивидуальную юридическую консультацию. Все законодательные нормы приведены по состоянию на конец июня 2026 года — ряд из них находится на финальном этапе внедрения.
За прошедшие месяцы законодательство пополнилось требованиями, которые напрямую влияют на повседневную рутину маркетологов: от привычных кнопок авторизации на лендингах до рекламных креативов, умных чат-ботов и CRM-систем с алгоритмами ИИ. Штрафные санкции заметно выросли, а процесс выявления нарушений стал автоматизированным — Роскомнадзор и ФАС активно применяют парсеры и нейросети для сканирования сайтов и медиапространства. Оправдание «мы не знали о новых правилах» в 2026 году регуляторами больше не принимается.
Мы, команда digital-агентства Big Panda, уже 13 лет помогаем бизнесу развиваться в цифровой среде. В этой статье мы без лишней юридической канцелярии разберем три критические зоны, где чаще всего спотыкается современный digital-бизнес, и дадим четкие чек-листы для самопроверки.
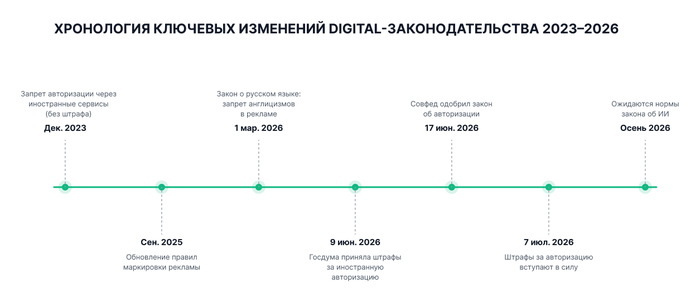
Если пользователи вашего ресурса или мобильного приложения все еще могут нажать кнопку «Войти через Google» либо «Войти через Apple ID» — этот раздел требует вашего незамедлительного внимания.
Формально ограничение на привязку личных кабинетов на российских IT-ресурсах к зарубежным почтовым сервисам или аккаунтам действует еще с 2023 года. Однако долгое время за несоблюдение этого требования не было предусмотрено реального наказания.
Ситуация изменилась летом 2026 года: 9 июня Государственная Дума приняла законопроект, устраняющий этот пробел и вводящий административные штрафы за использование зарубежных систем авторизации на отечественных площадках. Уже 17 июня документ был одобрен Советом Федерации. Штрафные санкции официально вступают в силу с 6 июля 2026 года.
Речь идет не о введении нового ограничения, а о появлении реального финансового наказания за игнорирование уже существующего правила. Законодатели подчеркивают: санкции не затронут простых интернет-пользователей. Вся ответственность ложится на владельцев интернет-ресурсов, которые продолжают предлагать зарубежные инструменты для подтверждения профиля.
Правило распространяется на любые компании и проекты, использующие личные кабинеты, регистрацию или вход через внешние платформы (Social Login). В группе риска находятся:
интернет-магазины, маркетплейсы и сервисы с клиентскими профилями;
образовательные и EdTech-платформы;
информационные B2B-порталы;
мобильный софт, требующий создания учетной записи;
любые веб-ресурсы, где авторизация настроена через API Google, Apple или других зарубежных провайдеров.
Для пользователей, которые ранее уже зарегистрировались через иностранные профили, экстренная переавторизация не требуется — они могут продолжать пользоваться сервисом под своими учетными данными. Наказание грозит бизнесу не за сам факт наличия таких пользователей, а за сохранение возможности новой авторизации через зарубежные кнопки.
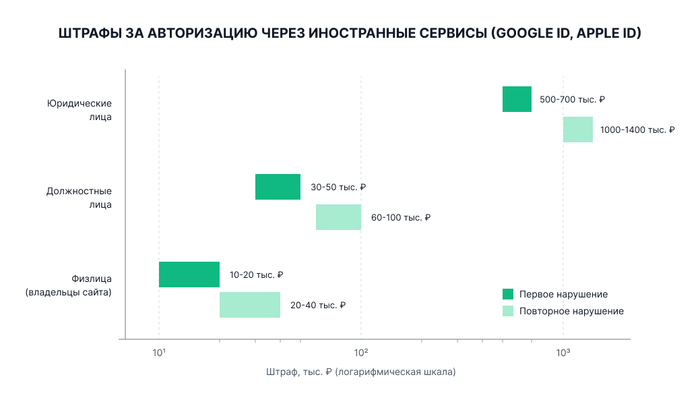
Обратите внимание: Если компания проигнорирует требование Роскомнадзора об отключении рекомендательных алгоритмов, предусмотрены еще более жесткие меры: при повторном нарушении штраф для юрлиц может составить до 2,8 млн рублей. Для операторов связи санкции могут исчисляться в процентах от годовой выручки.
Под «физлицами» в данном контексте понимаются частные администраторы веб-ресурсов или создатели небольших приложений, а не рядовые посетители сайтов.
Провести ревизию всех точек входа: изучить сайт, приложения, промо-страницы, устаревшие версии личных кабинетов и тестовые серверы.
Интегрировать отечественные альтернативы: настроить авторизацию через Госуслуги (ЕСИА), SMS по российскому номеру, стандартную связку почты и пароля, VK ID или Яндекс ID.
Изучить API и SDK: иногда Social Login автоматически подтягивается из зарубежных библиотек разработки, добавленных программистами без согласования с юристами.
Скорректировать интерфейсы: убедиться, что зарубежные методы авторизации полностью убраны из доступных вариантов для новых пользователей.
Сфера маркетинга быстрее остальных интегрировала искусственный интеллект: генерация визуального контента, кастомизация рассылок, виртуальные ассистенты, скоринг заявок и веб-аналитика. При этом компании часто упускают из виду, что как только в эти алгоритмы загружаются сведения о реальных людях, бизнес автоматически берет на себя обязательства оператора персональных данных в рамках закона 152-ФЗ «О персональных данных». И тот факт, что информацию обрабатывает нейросеть, а не человек, роли не играет.
Базовый закон гласит: любые персональные данные не могут обрабатываться без контроля и правовых оснований, даже в полностью автоматическом режиме. Искусственный интеллект с юридической точки зрения признается средством автоматизации. Соответственно, его взаимодействие с информацией клиентов должно подчиняться стандартным регламентам. Если ваш маркетинговый алгоритм собирает историю покупок или анализирует действия пользователей на сайте, вы обязаны соблюдать все требования 152-ФЗ.
Новые требования к согласиям: цели сбора информации должны быть четко детализированы, маркетинговая активность выносится в отдельный пункт, а передача данных за рубеж (включая API иностранных ИИ-сервисов) должна быть прописана явным образом.
Защита биометрии: для обработки биометрических и специальных данных теперь требуется отдельное письменное согласие и усиленный контур безопасности.
Усиление ответственности: зафиксированы новые составы нарушений, выросли штрафы, а за масштабные утечки в определенных случаях возможна уголовная ответственность.
Проверки по реестрам: Роскомнадзор сверяет данные из поданных бизнесом уведомлений с реальной работой веб-форм на сайтах.
Трансграничная передача данных. Подключение удобного зарубежного облачного ИИ-сервиса сотрудником может нарушить требование о локализации баз данных на территории РФ (ч. 5 ст. 18 закона 152-ФЗ).
Обучение моделей на клиентской базе. Использование реальных данных пользователей для кастомизации нейросети без предварительного обезличивания создает угрозу утечки данных. Такое использование должно быть прямо разрешено клиентом в согласии.
Принятие решений алгоритмами. Если ИИ используется для автоматического скоринга, генерации индивидуальных цен или отбора заявок, вы обязаны уведомить об этом пользователя и предоставить ему право оспорить решение с участием реального сотрудника.
Ключевое правило: В случае утечки данных через сторонний ИИ-сервис или при ошибке нейросети всю юридическую ответственность перед клиентами и регулятором несет сама компания-оператор, а не разработчик ИИ-инструмента.
К лету 2026 года законопроект о регулировании искусственного интеллекта был существенно скорректирован: под новые жесткие правила подпадают лишь крупнейшие базовые модели (с объемом обучения от миллиарда параметров). Это касается только нескольких отечественных IT-гигантов. Требования об обязательном использовании только российских данных и реестр «доверенного ИИ» из итогового проекта были исключены.
Рядовому бизнесу важно помнить: пока профильный закон об ИИ дорабатывается в Госдуме, стандартные требования 152-ФЗ о персональных данных уже полностью действуют и обязательны для всех без исключения.
Хотя правила маркировки интернет-рекламы действуют еще с 2022 года, именно период 2025–2026 гг. стал временем тотального контроля за счет автоматизации проверок регуляторами.
Любой рекламный материал в сети, имеющий объект продвижения и коммерческую цель, перед публикацией должен пройти регистрацию в Едином реестре (ЕРИР) через Оператора рекламных данных (ОРД) для получения токена (erid). Токен привязывается к финальной версии креатива. Любые правки в тексте или макете после получения токена недопустимы — система сочтет это подменой рекламы, что потребует повторной регистрации.
На креативе обязательно должна присутствовать отметка «Реклама» или «На правах рекламы» (с указанием названия рекламодателя или его ОГРН). Популярные плашки вроде #реклама или Sponsored могут быть лишь дополнением, но не заменой установленной законом текстовой формулировки.
Публикация без токена: текстовая пометка и реквизиты указаны, но сам код erid отсутствует — для проверяющих систем это явное нарушение.
Использование синонимов: замена обязательного слова «Реклама» на любые другие формулировки.
Ошибки в отчетности ОРД: передача некорректных данных или задержка сроков подачи ежемесячных отчетов.
Отсутствие маркировки нативных интеграций: продвижение по бартеру или за бонусы у блогеров требует маркировки на общих основаниях.
ИИ-креативы: распространение сгенерированных ИИ промо-материалов или массовых псевдо-отзывов бренда без надлежащей маркировки.
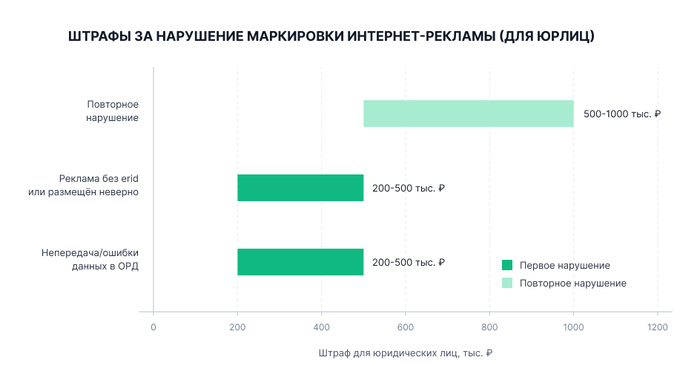
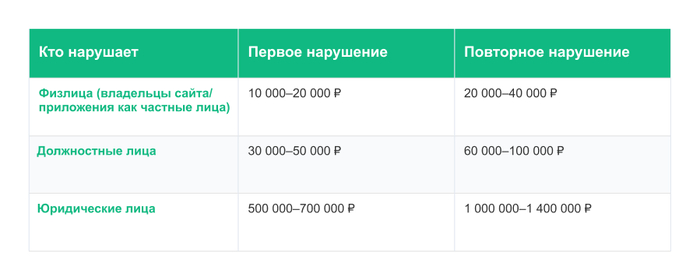
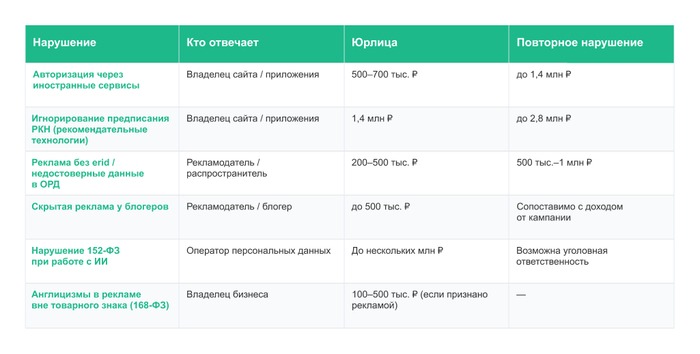
Вид нарушенияРазмер штрафаРаспространение рекламы без токена (erid)от 200 000 до 500 000 рублейНепредставление данных в ОРД / нарушение сроковот 200 000 до 700 000 рублейОтсутствие обязательной пометки «Реклама»от 100 000 до 500 000 рублей
Роскомнадзор и ФАС задействуют алгоритмы, которые круглосуточно мониторят социальные сети, сайты и мессенджеры на предмет наличия признаков рекламы (призывы купить, ссылки, промокоды, цены). Если бот фиксирует рекламный пост без токена, карточка нарушения создается автоматически. Дополнительно работает сквозная сверка цепочек в ЕРИР: несоответствие бюджетов агентства и зарегистрированных креативов блогера мгновенно подсвечивается системой.
Запрещенные платформы: ФАС подтверждает запрет на размещение рекламы на площадках, доступ к которым официально ограничен на территории РФ (включая YouTube и другие ресурсы). Ответственность несут и рекламодатель, и распространитель.
Закон о защите русского языка (168-ФЗ): с 1 марта 2026 года запрещено использовать в рекламе иностранные слова без их кириллического аналога или фиксации в словарях РАН (исключение составляют зарегистрированные товарные знаки).
Реклама энергетических напитков: с 1 марта 2026 года введен запрет на ее адресацию несовершеннолетним, упоминание витаминов в составе, а также установлена обязанность размещать предупреждение о вреде избыточного потребления.
Знание законов помогает точечно, но гораздо надежнее выстроить системный процесс комплаенса внутри вашей компании.
Регулярный аудит цифровых активов. Проводите плановую проверку сайтов, форм сбора данных, рекламных интеграций и настроек авторизации раз в квартал.
Назначение ответственного за комплаенс. Важно зафиксировать роль сотрудника (например, ведущего маркетолога или штатного юриста), который будет согласовывать запуски новых активностей.
Использование внутренних чек-листов. Создайте простой регламент для команды: кампания или новый инструмент не запускаются, пока не будут закрыты все юридические вопросы (маркировка, обработка ПДн, требования к авторизации).
Договорная дисциплина. Прописывайте разграничение ответственности за маркировку рекламы и обработку персональных данных во всех соглашениях с блогерами, агентствами и IT-подрядчиками.
Своевременное обращение к профильным юристам. Консультация специалиста необходима при внедрении сложных ИИ-решений, масштабных ререлизах систем авторизации или при получении официальных запросов от ФАС и Роскомнадзора.
Авторизация, защита персональных данных при работе с ИИ и правила маркировки рекламы объединены ключевым трендом 2026 года: контроль со стороны государства стал технологичным и автоматизированным. Рассчитывать на то, что мелкое нарушение останется незамеченным, больше не приходится.
Тем не менее все эти правила полностью выполнимы без ущерба для эффективности маркетинга. Своевременный аудит, корректные договоры и простые системные процессы позволят вам безопасно использовать современные инструменты — от удобного входа на сайт до передовых нейросетей — без риска получить внезапные штрафы в разгар бизнес-сезона.
Бюджет на рекламу выделен, кампании запущены, переходы на сайт есть — а заявок не прибавляется. Согласно исследованию E-Promo Group, в первом квартале 2026 года средняя цена клика в digital-рекламе подросла на 3% по сравнению с прошлым годом, а цена целевого действия — сразу на 26%. В e-commerce расхождение еще выраженнее: клик стал дороже на 19,1%, а конверсия — на 39,8%.

Рост стоимости клика и стоимости целевого действия год к году
Параллельно растет и доля мобильного трафика: по разным подсчетам, от 56 до 64% всех заходов в интернет совершается со смартфонов. В контекстной рекламе ситуация похожая — в 2025 году с мобильных устройств пришло 52% кликов, а 70% показов было сделано именно на смартфонах.
Получается двойное давление: трафик дорожает, а заходит в основном с телефона. И именно на этом стыке сайты чаще всего теряют деньги. За 13 лет работы в Big Panda мы много раз видели ситуацию, когда реклама была настроена грамотно, а конверсии всё равно не было. Проблема обычно крылась не в кампаниях, а в самом сайте — он просто не был готов принимать оплаченный трафик.
Ниже разберем пять самых частых точек, где утекает платный трафик, и что с этим делать.
Человек видит конкретное предложение в объявлении, переходит по нему — и попадает на страницу, где всё иначе. Цена не та, что в рекламе, продукт описан общими словами, а понятного оффера нет вовсе. Посетитель не находит того, ради чего пришёл, и закрывает вкладку в первые секунды. Деньги за клик уже потрачены, а заявки не будет.
В маркетинге такое несовпадение называют разрывом между обещанием в рекламе и тем, что пользователь видит на сайте. Чем сильнее разрыв, тем хуже конверсия — и тем дороже обходится каждый ушедший посетитель, если клик стоит дорого.
Пример: компания запускает контекстную рекламу по запросу «разработка сайтов недорого», обещая цену 52 500 рублей и срок 5 дней. А на сайте пользователь видит прайс от 300 000 рублей и портфолио из одних крупных долгих проектов. Или магазин техники рекламирует холодильник со скидкой 20%, но на странице товара скидки уже нет — вместо неё предлагают кредит. Итог один: посетитель не находит обещанного и уходит, а клик уже оплачен.
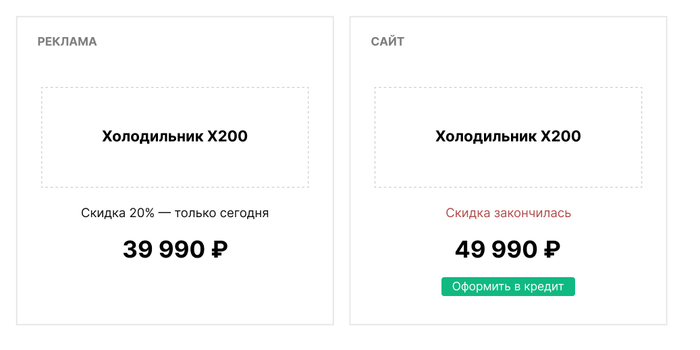
Разрыв между обещанием в рекламе и тем, что видит пользователь на сайте
Чаще всего причина в том, что рекламу ведёт один человек или подрядчик, а за сайт отвечает другой. Маркетолог придумывает объявление под новую гипотезу, а контент на сайте давно не обновлялся и с этой гипотезой не связан. Бывает и так, что отдельных страниц под рекламные кампании просто нет, и весь трафик идёт на главную — она по определению универсальна и не закрывает ни один конкретный запрос. Случается и проще: оффер на сайте не меняли с прошлой кампании, а новую запустили без проверки актуальности контента.
Первые секунды на сайте — решающие. Если посетитель сразу не понимает, чем компания может ему помочь, он уходит. Размытые формулировки типа «комплексный подход» или «инновационные решения» не работают на холодном трафике: человек не знаком с брендом и не готов тратить время на разгадывание смыслов. По нашим наблюдениям, именно на ошибках первого экрана теряется до 40% платного трафика.
Допустим, компания продает промышленное оборудование, и на первом экране сайта — фото завода с подписью «Надежный партнер с 2007 года» и кнопка «Узнать больше». Человек, который искал «купить компрессор», не видит ни компрессоров, ни цен — он не понимает, туда ли попал. Для владельца бизнеса факт работы с 2007 года звучит весомо, но для холодного посетителя это не аргумент. Имиджевые сообщения хорошо работают на уже знакомой аудитории, но не на платном трафике.
Первый экран для платного трафика должен закрывать три вопроса:
1. Что вы предлагаете
2. В чём выгода для пользователя
3. Что делать дальше
Интернет-магазину стоит показать категории товаров или хиты продаж. Сфере услуг — назвать проблему клиента и предложенное решение. B2B-сервису — указать, для кого он работает и какие задачи решает. А имиджевые формулировки лучше оставить для страницы «О компании» или для прогретой аудитории, которая уже знает бренд.
По рекламе приходят люди, которые ничего не знают о компании. Чтобы оставить контакты, им нужно убедиться, что вам можно доверять. Если на сайте нет кейсов, отзывов и портфолио — или они спрятаны в самом низу страницы — заявок не будет: посетитель просто не понимает, с кем имеет дело, и не готов делиться своими данными.
В b2b это особенно критично, потому что цена ошибки для клиента высока. Покупая аудит, внедрение ПО или промышленное оборудование, клиент хочет видеть, что вы уже решали похожие задачи для компаний его масштаба и отрасли. Доказательства, а не просто обещания — вот что заставляет оставить заявку.
Важно не ограничиваться списком логотипов клиентов, а показывать конкретные результаты: что было до работы, что получилось после, какие метрики изменились. «Сократили время простоя» — абстрактная фраза, а «сократили время простоя на 30% за два месяца» уже звучит убедительно. То же касается отзывов: общая фраза «отличная компания, рекомендую» не работает, а развёрнутый рассказ клиента с деталями, датами и цифрами — работает в разы лучше.
Несколько принципов работы с доказательствами для платного трафика:
• Кейсы и отзывы видны сразу, без прокрутки и переходов на другие страницы
• В тексте есть конкретные цифры и результаты, а не общие формулировки
• Показаны примеры работы с клиентами из похожей отрасли или с похожими задачами
• Кейсы регулярно обновляются — старые примеры из 2018 года заставляют сомневаться в текущей компетентности
• Если названия клиентов раскрывать нельзя, можно обезличить кейс, сохранив суть проблемы и результата
Посетитель готов оставить контакты — но видит форму на 15 полей, непонятную кнопку или лишние шаги перед отправкой. Каждое дополнительное поле отсеивает часть аудитории: чем проще путь к заявке, тем выше итоговая конверсия.
Перегруженные формы обычно возникают из желания собрать побольше информации о клиенте уже на первом касании — кажется, что так проще подготовить персональное предложение. На практике эффект обратный: заявок становится меньше, а заметного роста качества лидов не происходит, потому что большая часть посетителей просто не дочитывает форму до конца.
Вторая частая проблема — незаметная кнопка отправки: серая на сером фоне, слишком мелкая, с неясной надписью или в неожиданном месте интерфейса. Человек заполнил поля, но не понимает, как отправить форму, и закрывает страницу. Или формулировка кнопки сбивает с толку — вместо «Оставить заявку» написано «Отправить данные», и пользователь не рискует нажимать, не понимая, что произойдёт.
Путь к заявке должен быть максимально коротким: имя, телефон и, при необходимости, комментарий — этого достаточно в большинстве случаев. Одна заметная кнопка с понятной формулировкой. Никаких лишних шагов вроде подтверждения по СМС, если это не требование бизнеса. Дополнительную информацию о клиенте лучше собирать позже, на следующих этапах воронки, когда интерес уже подтверждён.
Полезная привычка — периодически смотреть на форму глазами пользователя и честно спрашивать себя: действительно ли каждое поле необходимо для приёма заявки? Если нет — убрать. Практика показывает: короткая форма почти всегда выигрывает с заметным отрывом.
Основная часть платного трафика сегодня приходит со смартфонов. По данным Statcounter за 2025 год, мобильные устройства генерируют 63% всего интернет-трафика, а визиты на ритейл-сайты со смартфонов составляют 77%. В поисковой рекламе, по данным Statista, доля мобильных кликов в 2025 году достигла 52%, а доля показов на смартфонах — 70%.
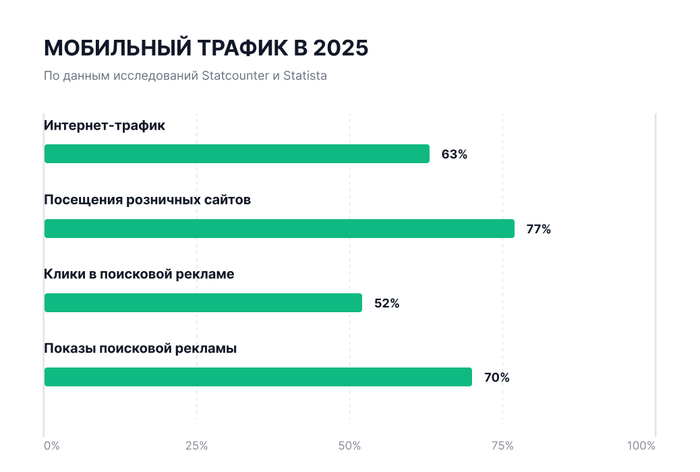
Доля мобильных устройств в платном и органическом трафике
Если мобильная версия медленная, кнопки не реагируют на нажатия, текст наезжает на блоки — посетитель уходит почти сразу. Никто не будет ждать загрузку или вручную увеличивать масштаб страницы: проще закрыть вкладку и перейти к конкуренту.
Скорость загрузки на мобильных устройствах — отдельная больная тема. Исследования Google и Akamai показывают: задержка загрузки на одну секунду снижает конверсию на 7%. Ещё двадцать лет назад Amazon провёл масштабное A/B-тестирование и выяснил, что дополнительная секунда загрузки стоит компании 10% продаж. При обороте 100 миллионов рублей в год это 10 миллионов потерь только из-за скорости.
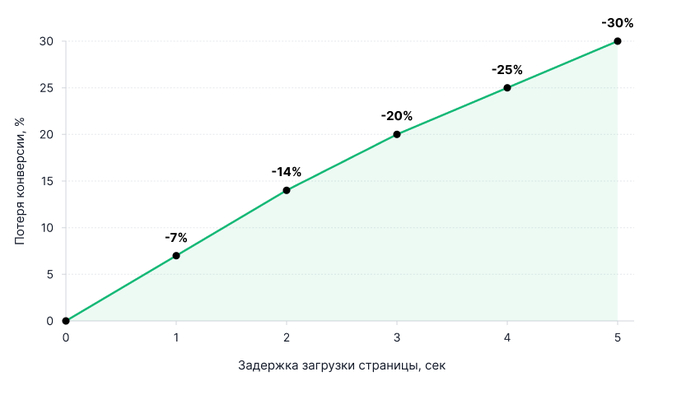
Зависимость потери конверсии от задержки загрузки страницы
Помимо скорости есть и проблема адаптивной вёрстки: сайт может выглядеть аккуратно на десктопе и превращаться в хаос на телефоне. Мелкий текст без возможности комфортно прочитать, кнопки, в которые трудно попасть пальцем, наезжающие друг на друга блоки, всплывающие окна без кнопки закрытия, клавиатура, перекрывающая поля формы.
Проверить состояние мобильной версии можно через Google PageSpeed Insights и Lighthouse — они показывают скорость, адаптивность, доступность и другие метрики Core Web Vitals. Особое внимание стоит обратить на Largest Contentful Paint (скорость загрузки основного контента) и Cumulative Layout Shift (насколько элементы «прыгают» при загрузке).
Мониторинг мобильной производительности стоит сделать регулярной привычкой, особенно при работе с платным трафиком: каждый новый скрипт, виджет, пиксель или баннер постепенно утяжеляет страницу. Проверять показатели разумно хотя бы раз в квартал — и обязательно перед запуском крупной рекламной кампании.
В итоге, если мобильная версия не готова, всё остальное теряет смысл — пользователи просто не доходят до контента, каким бы качественным он ни был. Нередко жалобы на низкую конверсию решаются банальной оптимизацией изображений и настройкой кеширования, без серьёзных изменений в дизайне. Это быстро, недорого и дает измеримый результат.
Если объединить все пять ошибок в одну схему, получится воронка: на каждом шаге сайт теряет часть платного трафика еще до того, как пользователь успевает заполнить форму.
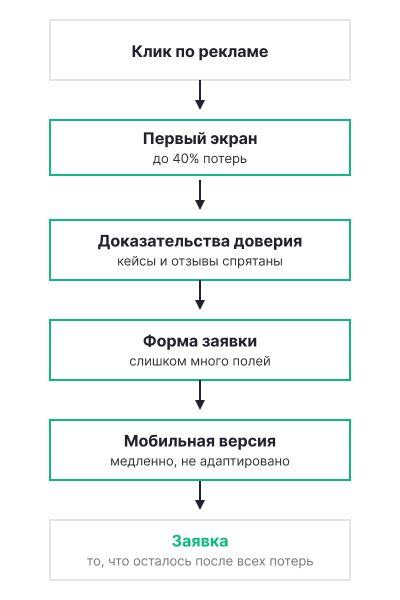
Путь от клика по рекламе до заявки и точки потерь на каждом этапе
Если в рекламу вкладывается бюджет, имеет смысл периодически проверять сайт на готовность принимать трафик. Вот короткий список на 15–20 минут.
Рекламное сообщение и контент на сайте совпадают
На первом экране есть понятный оффер и заметная кнопка действия
На сайте есть доказательства экспертности — кейсы, отзывы с цифрами
Путь к заявке короткий — два-три поля, без лишних шагов
Мобильная версия работает без нареканий, страницы грузятся быстро
Если по двум и более пунктам есть сомнения, платный трафик скорее всего работает не в полную силу. Дело не в рекламе, а в сайте — и это обычно исправляется быстрее и дешевле, чем кажется на первый взгляд.
Реклама делает свою работу — приводит людей на сайт. А дальше всё зависит от того, готов ли сайт их принять. Самые частые точки потерь лежат на поверхности: разрыв между обещанием и реальностью, слабый первый экран, отсутствие доказательств доверия, перегруженная форма, неработающая мобильная версия. Каждая ошибка по отдельности съедает часть бюджета, а вместе они способны обнулить результат даже самой продуманной рекламной кампании.
В Big Panda мы регулярно находим такие точки потерь у клиентов, устраняем их и возвращаем бюджет, который раньше уходил впустую. Знаем, какие барьеры мешают пользователю оставить заявку, и умеем убирать их так, чтобы сайт работал на платный трафик, а не против него.

Несколько лет мы занимались поставкой расходных материалов и ремонтом печатной техники. Основной деятельностью были тонеры, заправка картриджей и обслуживание принтеров различных марок.
В процессе нашей работы накопился практический опыт в устройстве печатных машин, их слабых местах и реальных возможностях. Стало понятно, что значительная часть проблем клиентов связана не с поломками оборудования, а с неправильным выбором типа печати, неверной подготовкой макетов или неоправданно высокими требованиями к тиражам.
Одновременно с этим мы наблюдали ситуацию, когда хорошее оборудование простаивало, а клиенты переплачивали посредникам. Многие заказчики жаловались, что типографии выставляют минимальные тиражи от 1000 экземпляров, даже если нужно всего 50 визиток или 100 наклеек. Сроки исполнения заказов зачастую растягивались на неделю и более, а цена не всегда соответствовала качеству.
В какой-то момент представилась возможность приобрести набор оборудования: принтер Konica Minolta, плоттер, резак и биговщик. Всё в рабочем состоянии и подходящее для запуска полноценной цифровой типографии. Было принято решение попробовать собственное производство, опираясь на накопленный инженерный опыт.
Так появилась Печатня. Основная идея заключалась в том, чтобы печатать малые тиражи быстро, с прозрачной ценой и без принуждения клиента заказывать лишние экземпляры.
Основной профиль команды — техническое обслуживание и ремонт печатного оборудования. Многолетняя работа с принтерами Konica Minolta и других производителей сформировала глубокое понимание того, как устроена цифровая печать, от чего зависит стабильность качества и на каких этапах чаще всего возникают ошибки.
Этот инженерный опыт напрямую влияет на качество услуг.
Стабильность параметров печати. Понимание слабых мест конкретных моделей принтеров позволяет заранее исключать режимы и материалы, на которых техника работает нестабильно. Клиент получает предсказуемый результат без сюрпризов.
Работа с малыми тиражами без экономической нецелесообразности. Цифровая печать не требует изготовления печатных форм и длительной приладки, поэтому запуск тиража от 24 визиток или 35 наклеек экономически оправдан. Это прямое следствие особенностей оборудования, а не маркетинговый ход.
Контроль макетов до печати. Любая ошибка в макете (неправильная цветовая модель, отсутствие вылетов под резку, низкое разрешение) приводит к браку. Инженерный подход подразумевает проверку каждого файла до запуска. Если обнаруживается проблема, менеджер связывается с клиентом и предлагает исправления, а не печатает заведомо бракованный тираж.
Ответственность за результат. Поскольку Печатня не является посредником или агрегатором, вся ответственность за качество лежит на собственных сотрудниках. Это мотивирует тщательно контролировать каждый этап — от приёмки макета до упаковки готового заказа.
Таким образом, инженерное прошлое компании стало не случайным обстоятельством, а основой для построения производственных процессов. Типография работает так, как работала бы ремонтная мастерская: с вниманием к деталям, без лишних обещаний и с четкими критериями качества.
При запуске рассматривались разные технологические подходы. Офсетная печать традиционно ассоциируется с высоким качеством и низкой ценой за единицу продукции, но только при больших тиражах. Широкоформатная печать решает другие задачи — в первую очередь наружную и интерьерную рекламу. Цифровая печать оказалась наиболее подходящей для тех задач, с которыми чаще всего сталкивались клиенты за время ремонтной деятельности.
Экономика офсета. В офсетной печати основные затраты приходятся на допечатную подготовку: изготовление печатных форм, приладку машины, вывод красок в баланс. Эти расходы практически не зависят от тиража. При заказе 1000 экземпляров стоимость подготовки распределяется на каждый лист и становится незаметной. При заказе 50 экземпляров эти же затраты делают цену за единицу запредельно высокой. Поэтому офсетные типографии устанавливают минимальные тиражи — им просто невыгодно брать малые заказы.
Экономика цифры. В цифровой печати нет печатных форм и приладки в классическом понимании. Изображение переносится на бумагу напрямую с барабана или ленты. Затраты на подготовку минимальны и состоят в основном из проверки макета и калибровки оборудования. Это делает экономически оправданными тиражи от одного экземпляра. Себестоимость единицы продукции при увеличении тиража снижается, но не так драматично, как в офсете, потому что стартовые затраты и так невелики.
Практический вывод. Для тиражей до 500-1000 экземпляров цифровая печать оказывается выгоднее или сопоставимой по цене, но при этом даёт выигрыш в скорости. Для тиражей свыше 1000 экземпляров имеет смысл сравнивать оба варианта. Мы специализируемся на первом сегменте — там, где цифра дает оптимальное сочетание цены, качества и срока.
Важность для клиента. Предпринимателю, которому нужно 50 наклеек для пробной партии товара или 200 визиток для мероприятия, не имеет смысла переплачивать за офсетный тираж. Также нет смысла ждать неделю, если напечатать можно за один день. Понимание этой экономики заложено в модель работы с самого начала.
Один из наиболее частых вопросов от клиентов касается того, из чего складывается цена заказа. Многие полагают, что основную долю составляют бумага и краска. В цифровой печати это не так.
В зависимости от сложности заказа, от 30 до 50 процентов себестоимости приходится на постпечатную обработку и сопутствующие операции. Это не скрытая наценка, а объективные трудозатраты, которые требуются для получения готового продукта.
Приёмка и проверка макета. Каждый файл перед запуском проверяется по нескольким параметрам: цветовая модель (CMYK, не RGB), наличие вылетов под резку (обычно по 2-3 мм с каждой стороны), разрешение (не менее 300 dpi для качественной печати), соответствие шрифтов и корректность обрезных форматов. На эту операцию уходит время квалифицированного специалиста.
Цветокоррекция и растрирование. Даже при идеальном файле требуется адаптация под конкретную печатную машину и конкретную бумагу. Разные материалы по-разному впитывают тонер, что влияет на цветопередачу. Растрирование — преобразование изображения в точки, которые физически может напечатать принтер, — также требует настройки.
Резка. Для визиток, флаеров и открыток используется гильотинный резак. Точность должна составлять доли миллиметра, иначе край получается неровным или смещается изображение. Для наклеек применяется контурная резка (kiss-cut), которая прорезает только верхний слой материала, оставляя подложку целой. Это отдельная операция с настройкой плоттера.
Биговка. При печати на плотных картонах (от 250 г/м²) прямой сгиб приводит к трещинам на линии сгиба и осыпанию тонера. Биговка — продавливание канавки, по которой картон сгибается без повреждения. Требуется для открыток, приглашений, меню и флаеров на плотной бумаге.
Упаковка и контроль качества. Каждый заказ проверяется визуально перед упаковкой: нет ли смазывания, совпадает ли резка, не повреждены ли края. Упаковка должна исключить повреждения при транспортировке.
Почему нельзя исключить эти этапы. Попытка сэкономить на обработке приводит к одному результату — браку. Отсутствие проверки макета дает тираж с ошибками. Экономия на биговке даёт треснувшие сгибы. Упрощение резки дает неровные края. Поэтому мы не исключаем эти этапы, а включает их в себестоимость прозрачно.
Что может сделать клиент для снижения стоимости. Подготовка макета по техническим требованиям (CMYK, вылеты, 300 dpi) сокращает время на проверку и корректировку. Отказ от сложной постпечатной обработки (например, выбор бумаги без биговки) также снижает стоимость. Однако в большинстве случаев именно обработка обеспечивает тот уровень качества, ради которого клиент обращается к нам.
Производственная база Печатни состоит из нескольких единиц оборудования, каждая из которых отвечает за свой этап печатного процесса. Выбор техники определялся необходимостью покрыть основные потребности клиентов в малых тиражах — визитки, наклейки, этикетки, флаеры и открытки — при сохранении контроля над качеством на всех этапах.
Цифровая печатная машина Konica Minolta
Это центральный элемент производственной линии. Машина обеспечивает печать на бумаге плотностью от 130 до 300 г/м², что покрывает большинство задач: от стандартных визиток до плотных открыток и карточек меню. Точность цветопередачи достигается за счет калибровки под конкретный тип материала. Оборудование позволяет печатать переменные данные, что актуально для заказов с персонализацией (например, приглашения с разными именами или штрихкоды для маркетплейсов с уникальными номерами).
Плоттер для контурной резки
Используется для изготовления наклеек и стикеров в формате kiss-cut. Плоттер прорезает верхний слой материала (бумагу или самоклеящуюся пленку) по заданному контуру, не повреждая подложку. Это позволяет извлекать наклейку, оставляя защитный слой нетронутым до момента использования. Точность резки имеет критическое значение для наклеек сложной формы (сложные геометрические фигуры, фигурные края, логотипы неправильной формы).
Гильотинный резак
Предназначен для резки стоп бумаги на заданные форматы. Используется на этапе пост-печатной обработки визиток, флаеров и открыток. Точность резака составляет доли миллиметра, что необходимо для получения ровных краев и соблюдения заявленных размеров. Без этого этапа невозможно получить аккуратную продукцию даже при идеальной печати.
Биговщик
Применяется для продавливания линий сгиба на плотных картонах. Биговка предотвращает растрескивание тонера и бумаги в месте сгиба, что особенно важно для открыток, приглашений, обложек и флаеров на плотной бумаге. Процесс заключается в формировании канавки с тупой стороны сгиба, по которой материал складывается без повреждения печатного слоя.
УФ-лакировальное оборудование
Используется для финишной обработки отдельных видов продукции. УФ-лакировка может быть глянцевой или матовой, наносится выборочно или на всю поверхность. Задача лакировки — защита изображения от механических повреждений и придание дополнительной тактильной привлекательности.
Каждая единица оборудования обслуживается специалистами, знакомыми с её конструкцией и типичными неисправностями. Это прямое следствие инженерного прошлого компании: поломка не приводит к длительному простою, поскольку ремонт может быть выполнен собственными силами без ожидания сторонних сервисов.
Подводя итог, можно сказать так: мы не строили бизнес с нуля на пустом месте, а просто применили свой инженерный опыт в смежной области. Вместо того чтобы чинить чужие принтеры, мы решили печатать сами — и оказалось, что знания о том, как работает техника и на чем экономят посредники, здорово помогают на практике.
Нам искренне интересно делать качественные визитки, наклейки и открытки в тех объемах, которые реально нужны заказчику. Без лишних требований по минимальному тиражу, без недельного ожидания и без скрытых доплат за «сложность». Цена складывается из объективных трудозатрат, а не из маркетинговых надбавок.
Мы хорошо представляем, что можем гарантировать, а в чем лучше честно предупредить сразу. И это, пожалуй, главное. Если вам нужен понятный сервис, а не магия, и вы цените, когда заказ делают с толком, а не на потоке — будем рады помочь.
