
Выбор жесткого диска WD Purple или WD Blue
Друзья, подскажите какой лучше взять диск для хранения файлов ? Смотрел отзывы, что-то не очень. Purple гудит как самолет и много у кого сломался. Blue примерно так же.
Друзья, подскажите какой лучше взять диск для хранения файлов ? Смотрел отзывы, что-то не очень. Purple гудит как самолет и много у кого сломался. Blue примерно так же.
Собираюсь покупать б/у комплект (8400F с одной планкой на 16gb 6000mhz) на авито за 27.000, вместе с б/у rx9070 за 53.000. Хочу чередовать разрешение экрана, сойдет?

Количество ядер, их архитектура и частота — три ключевые характеристики центрального процессора. Но не менее важную роль играет еще одна: кэш. Это быстрая память небольшого объема, расположенная на кристалле рядом с вычислительными ядрами. Для чего нужен кэш? Как он работает, на что влияет и как устроен внутри?
Компьютеры, ноутбуки, планшеты, смартфоны и даже миниатюрные смарт-часы — все эти устройства представляют собой разновидности вычислительных систем. В основе работы любой из них два ключевых компонента: подсистема памяти, в которой находятся данные для расчетов, и процессор, который эти расчеты производит.
На заре появления вычислительные системы состояли из простых пар «процессор — память». Сначала код полностью загружался в память с помощью тумблеров, штекерной панели или перфокарт, и лишь затем процессор начинал считывать его оттуда и выполнять команды. Результаты вычислений выводились либо на панель с индикаторами, либо с помощью «дедушек» современных принтеров — телетайпов, перфораторов или алфавитно-цифровых печатающих устройств.
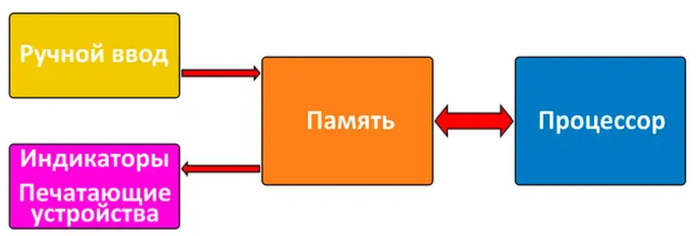
В конце 70-х годов прошлого века место ранее используемых ртутных, механических и магнитных видов памяти окончательно заняла полупроводниковая. Перфокарты и перфоленты уступили место кассетам с магнитной лентой, а еще через несколько лет — флоппи-дискам. Тогда вычислительные системы наконец обрели близкий к современным формат работы: устройство постоянной памяти (накопитель) — оперативная память (ОЗУ) — процессор.

Типы оперативной и постоянной памяти с тех пор не раз менялись, но общий принцип работы вычислений оставался прежним. Упрощенно его можно представить так:
Программа загружается из постоянной памяти в оперативную.
Процессор считывает данные из оперативной памяти и выполняет над ними вычисления.
Результаты вычислений возвращаются в оперативную память.
Программа использует результаты для передачи на устройство вывода (экран/динамики/принтер), либо для записи обратно в постоянную память.
Частоты ЦП в то время росли не по дням, а по часам. Уже к середине 80-х процессоры стали работать заметно быстрее, чем микросхемы оперативной памяти. Из-за этого все чаще возникали ситуации, которые сегодня называют боттлнеком: во многих задачах ЦП приходилось ждать загрузки из ОЗУ и пропускать рабочие такты, теряя заметную часть производительности.
Решением этой проблемы стало внедрение кэша: очень быстрой памяти малого объема, служащей буфером данных между процессором и оперативкой. В x86-процессорах кэш впервые появился в 1987 году у модели Intel 80386, с тех пор став стандартным элементом практически любой вычислительной системы.
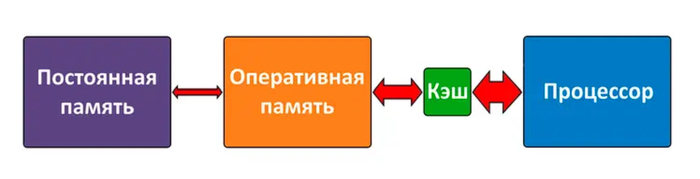
Про кэш часто говорят, что «это та же оперативная память, только в разы быстрее и намного меньше по объему». Отчасти это и правда так, ведь кэш выполняет работу, которая до его появления была исключительно делом ОЗУ — максимально быстро передавать процессору данные, необходимые для расчетов.
Однако на деле принципы работы кэша и оперативки заметно отличаются. ОЗУ заполняется только теми данными, которые запрашивают выполняемые программы. Контролирует этот процесс операционная система — то есть, в данном случае управление памятью полностью программное.
Если бы кэш-память можно было бы сделать размером с оперативную, то последняя оказалась не нужна бы вовсе. Но ОЗУ у современных систем исчисляется гигабайтами, а кэш — мегабайтами. Разница в объеме между ними составляет порядка тысячи раз, и подобное положение сохраняется уже четвертое десятилетие.
Но как же кэш при столь малом объеме помогает ЦП получать быстрый доступ к данным выполняемых программ? Дело в том, что такая память намного «умнее». Вместо того, чтобы загружать только используемую в данный момент информацию, кэш заполняется данными на основе:
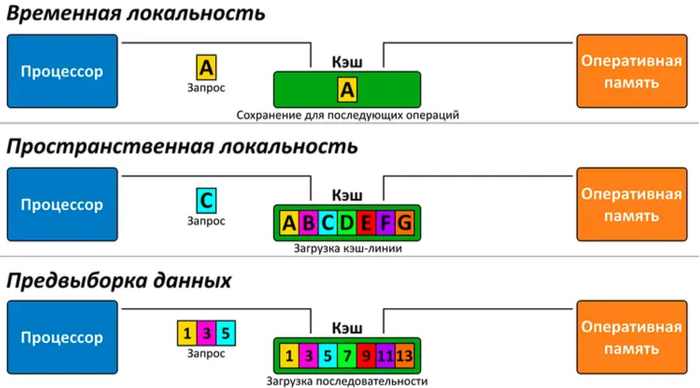
Принципа временной локальности. Когда процессор делает запрос к определенному адресу в ОЗУ, то он с большой вероятностью будет обращаться к нему снова. Для таких случаев кэш продолжает сохранять ранее запрошенные данные.
Принципа пространственной локальности. Если процессор делает запрос к определенному байту памяти, то он наверняка будет обращаться и к информации в соседних байтах. Поэтому в кэш загружается не один запрашиваемый байт, а целая кэш-линия, обычно 64 байта.
Работы Prefetchers. Это аппаратные блоки предвыборки данных, занимающиеся поиском зависимостей в коде (Instruction Prefetchers) и данных (Data Prefetchers). Когда они «видят», что программа запрашивает информацию в определенной последовательности, то начинают загружать эту последовательность в кэш заранее — еще до того, как эти данные понадобятся процессору.
После того, как кэш заполнился, в дело вступают алгоритмы вытеснения данных. Они решают, какую информацию еще нужно держать в кэше, а какую можно удалить, освободив место для новой. За их работу отвечают:
Контроллер кэша. Хранит и сверяет теги, указывающие на соответствие данных в кэше адресам из ОЗУ.
Блок замещения. Следит за «возрастом» данных в строках кэша, чтобы при поступлении новой информации заменить ей самую старую.
Буфер обратной записи. Вступает в дело после блока замещения: сохраняет старую информацию до тех пор, пока она не будет записана в кэш уровнем ниже или оперативную память.
Агент когерентности. Когда одно ядро ЦП изменяет определенную информацию в ОЗУ, то кэши других ядер продолжают хранить ее старые версии. Этот блок отслеживает изменения в кэшах, помечая старые данные недействительными и организуя загрузку их актуальных версий.
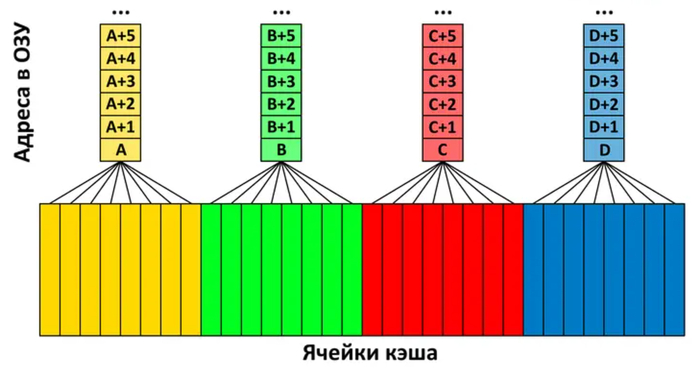
Чтобы отслеживать устаревание данных одновременно во всем массиве кэша и при этом обеспечивать запись новой информации в любую его точку, требуется очень сложная логика. Для решения этой проблемы с конца 80-х годов и по сегодняшний день в процессорах используется множественно-ассоциативный кэш (Set-Associative Cache).
При таком подходе набор адресов оперативной памяти привязывается к нескольким ячейкам кэша (в современных ЦП — от 8 до 20). Когда поступает команда на запись из привязанного адреса, алгоритмы вытесняют информацию из одной ячейки набора, не затрагивая остальные. Это позволяет эффективно избавляться от старых данных, сохраняя актуальную информацию в кэше без необходимости постоянно «гонять» ее из ОЗУ.
За счет слаженной работы вышеописанных алгоритмов и блоков кэш способен предварительно загрузить в себя до 99 % данных, необходимых для расчетов. Это избавляет вычислительный конвейер процессора от простоя, вызванного ожиданием информации из оперативной памяти.
Вдобавок к аппаратным методам управления содержимым кэша существуют также программные. Если разработчик ПО видит, что его код при «самодеятельности» процессора не очень эффективно использует кэш или забивает его ненужными данными, он может использовать:
Команды предвыборки. «Советуют» процессору подтянуть выбранные данные из ОЗУ в кэш заранее.
Команды потоковой записи. Заставляют ЦП записывать данные напрямую в оперативную память, минуя кэш.
Команды обслуживания. Позволяют сбрасывать содержимое кэша частично или полностью.
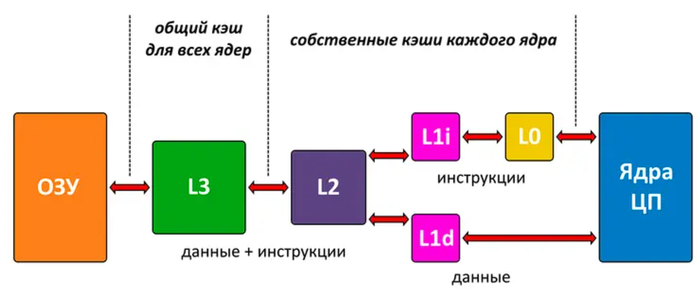
Единственный кэш пробыл у процессоров недолго. В 1989 году в Intel 80486 дебютировала система кэширования с двумя уровнями (L1 и L2). А четыре года спустя в Intel Pentium кэш первого уровня для более эффективной работы был поделен на две независимые части — для инструкций (L1 Instruction) и для данных (L1 Data).
С развитием многоядерности в 2007-2008 годах в ЦП появился кэш третьего уровня (L3). В отличие от прочих уровней, он стал общим хранилищем для всех процессорных ядер и помог им обмениваться данными друг с другом без помощи оперативной памяти. А последним появился кэш микроопераций (L0): им оснащены все Intel Сore (со второго поколения) и AMD Ryzen.
К сегодняшнему дню иерархия кэшей у современных процессоров приняла следующий вид:
Кэш L0. Хранит очередь микроопераций, декодированных ядром из инструкций.
Кэш L1I. Используется для инструкций, которым предстоит пройти декодирование.
Кэш L1D. Хранит данные: числа, указатели, логические значения.
Кэш L2. Общий уровень для данных и инструкций каждого ядра.
Кэш L3. Общий уровень для данных и инструкций всех ядер.
Чем выше уровень кэша, тем быстрее он работает. Но чем быстрее ячейки кэш-памяти, тем сложнее их разводка, выше энергопотребление и нагрев. Если сделать L1 размером с L3, то он будет потреблять огромное количество энергии и перегревать ядра даже в простых задачах. Поэтому система кэширования сочетает несколько уровней разного объема, задержка доступа к которым заметно различается. У современных ЦП это:
L0: без задержки или 1 такт, 4000-6000 микроопераций (на ядро),
L1 (I+D): 4-5 тактов, 64-112 кБ (на ядро),
L2: 8-16 тактов, 0.5-3 МБ (на ядро),
L3: 40-55 тактов, 12-192 МБ (общий для всех ядер).
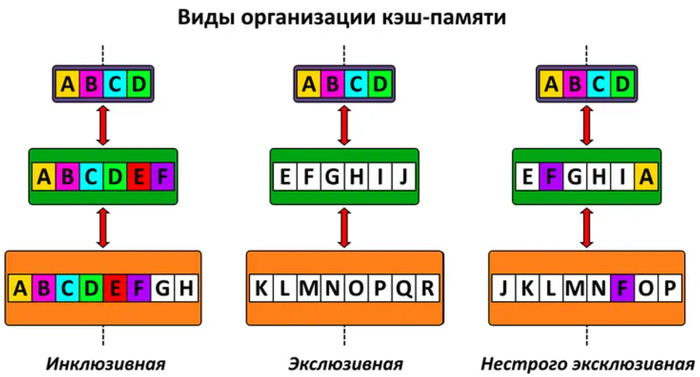
В зависимости от архитектуры процессора, разные уровни могут иметь отличающуюся организацию кэш-памяти:
Инклюзивную. Кэш хранит в себе полную копию информации, которая есть в верхних уровнях. При таком подходе тратится меньше времени на поиск данных между ядрами, но из-за дубликатов не весь объем кэша используется эффективно.
Эксклюзивную. Данные могут находиться только на одном уровне кэша, что позволяет максимально эффективно использовать его объем. Но если одному ядру нужны данные, лежащие в кэше другого, то приходится обновлять информацию на всех уровнях иерархии — это вызывает дополнительную задержку.
Нестрого инклюзивную. Сочетает преимущества двух вышеописанных организаций. Здесь данные могут дублироваться на нижних уровнях кэша, но только в том случае, если так «решили» его алгоритмы работы.
Принцип работы кэша схож при любой организации: когда запускаются вычисления, процессор начинает искать нужную информацию в L0/L1. При неудаче («промах») отправляется запрос в L2, а если ее и там не нашлось — то в L3. В случае, когда нужных данных нет ни на одном уровне кэша, процессору приходится запрашивать их из оперативной памяти. С современной DDR4 и DDR5 такой запрос обходится потерей от 250 до 450 тактов: это в 5-10 раз больше, чем доступ к самому «медленному» L3.
На заре появления микросхемы кэша располагались либо на материнской плате, либо в картридже процессора. Но к 2000 году и Intel, и AMD интегрировали оба уровня кэш-памяти внутрь кристаллов своих ЦП, наконец избавив кэш от роли внешнего элемента.
С тех пор объемы кэшей понемногу росли. Однако главным препятствием к их резкому увеличению все также оставалась сложность SRAM-памяти, требующей много транзисторного бюджета. Создавать процессор, где более половины кристалла занял бы кэш, в 2000-е годы было трудно. Но даже когда такая возможность появилась, проектировать нишевый чип никто не хотел, ведь вместо огромного кэша на той же площади можно было разместить больше вычислительных ядер.
Для решения данной задачи проще всего было вернуться к корням кэша: многочиповой компоновке. Впервые на это в 2013 году решилась компания Intel. Тогда она оснастила свои мобильные Core четвертого поколения дополнительным кристаллом eDRAM объемом 128 МБ. Он работал заметно медленнее L3 и поэтому играл роль общего кэша следующего, четвертого уровня (L4).
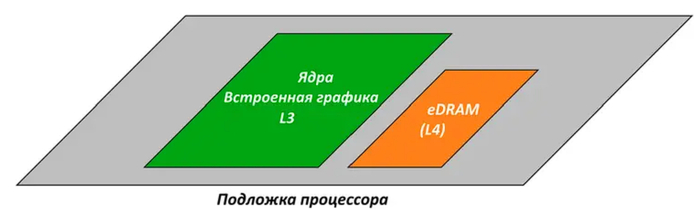
Благодаря огромному объему чип eDRAM позволял процессорам тех лет практически не обращаться в ОЗУ напрямую, за счет чего их конвейер не простаивал даже в самых сложных ситуациях. Но память eDRAM была дорога, поэтому так и не стала массовой: в топовых мобильных Intel она изредка встречалась вплоть до восьмого поколения Core, а в десктопе и вовсе появилась только в двух моделях пятого поколения.
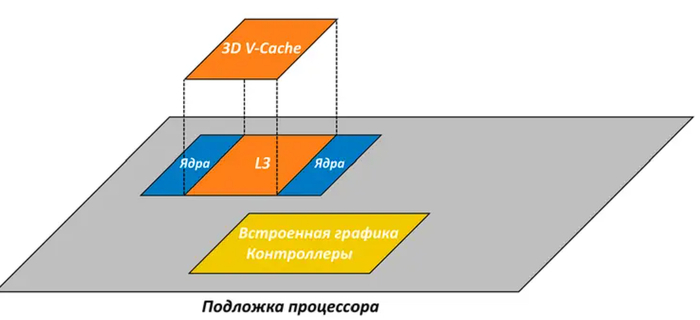
В 2022 году схожую идею впервые реализовала компания AMD. Но она выбрала другой путь: вместо добавления относительно медленного чипа L4 «приклеивать» поверх процессорного чиплета быстрый кристалл c дополнительным объемом L3. Эта технология получила название 3D V-Cache.
В отличие от ОЗУ, кэш является высоко интегрированной памятью. Скорость и ассоциативность кэша подбираются на этапе проектирования процессорной архитектуры так, чтобы при ограниченном транзисторном бюджете максимально выгодно устранить ее «узкие» места. Поэтому сравнивать эти параметры напрямую у ЦП разных поколений не имеет смысла.
Гораздо более универсальная характеристика, на которую стоит обращать внимание при выборе ЦП — это общий объем кэша. Хотя из-за отличающейся компоновки процессоров Intel и AMD используют разные подходы к формированию его уровней («синие» — упор на объем L2, «красные» — упор на объем L3), правило «больше — значит лучше» работает здесь почти всегда.
Почему? Все просто: чем объемнее кэши, тем больше в них «влезает» различных данных, которые могут понадобиться ЦП в следующий момент времени. Поэтому процент ситуаций, когда нужная информация оказалась в кэше («попадание») с ростом его объема становится более высоким. За счет этого процессор реже обращается за данными к медленной ОЗУ и, как следствие, меньше теряет свою скорость.
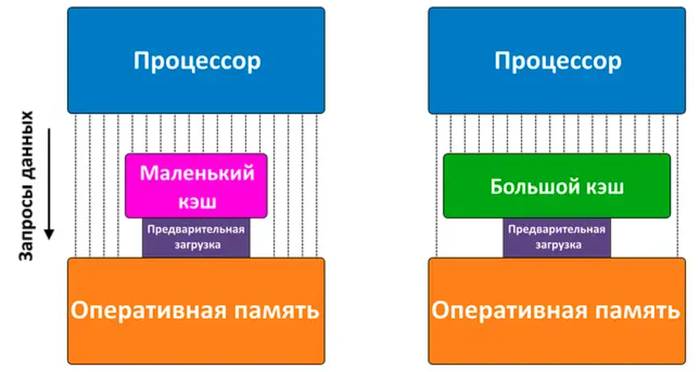
Впрочем, производительность ЦП зависит от объема кэша далеко не всегда. Прирост от его увеличения заметен лишь тогда, когда выполняемый код хаотичен — в играх, 3D-моделировании или инженерном ПО. И чем больше кэш, тем выше он будет. Например, трехкратное увеличение объема кэша у процессоров AMD Ryzen X3D способно дать им в подобных задачах от 10 до 50 % дополнительной скорости.
Но с относительно линейным и предсказуемым кодом современные ЦП не получают от большого кэша заметного буста. К таким ситуациям относится работа с 2D-графикой, рендеринг, монтаж и кодирование видео — в них прирост от увеличения кэша колеблется от 0 до 5 %. Поэтому для подобных сценариев на объем кэша можно не обращать внимания: в них куда важнее архитектура процессора, его тактовая частота и количество ядер.
P/S
Размышлизмы:
Сверхоперативная память процессора. Снижает потери времени на ожидание данных. Конвейер чаще работает и чем он быстрее, тем требовательнее к оперативной памяти. У актуального SRAM удельное быстродействие больше, чем у LPDDR5X, GDDR7 и даже HBM4. Обычный DRAM почти во всём значительно проигрывает.
Но его в сотни или тысячи раз больше. Пришлось пользоваться как посредником между кэшем и SSD или иной постоянной памятью. ПЗУ ещё медленнее, без системного ОЗУ простои будут слишком длительными и это ускорит их поломку. Больше ядер и частот - чаще обращается к кэшу. Больше кэша - меньше обращений к DDR.
Что до практики, много кэша позволяют частично забить на скорость обычной оперативной памяти и системных шин. Но SRAM дорогая, медленным CPU и GPU её добавляют по минимуму или нехватку компенсируют быстрым DRAM.
Обычно старшие APU самые требовательные до ОЗУ. С дискретной видеокартой проблема меньше выражена. И нельзя сравнивать разные архитектуры только по одному параметру. Смотрим комплексно, также долго тестируем большим набором задач.
Своими словами и подробнее, наглядно. Либо со смежными темами. Много кэша уместнее при непредсказуемом потоке вычислений. SRAM дорог и CPU с eDRAM, 3D V - cache или bLLC нужны немногим.
Не массовый продукт, для специфичных задач. Усреднённый оптимальный объём итак реализован в большинстве привычных моделей. Но если ажиотаж с DRAM продлится долго, то может появиться кэш L4. Особенно если DDR6 будет не так хороша, как ожидают.
L3 существовал в 2003 году. Pentium 4 EE сокета 478 на ядре Gallatin. Серверный кристалл Xeon с 2 мегабайтами кэша установили на настольный процессор. Но массовым кэш 3 уровня стал с 2007 года, начиная с линейки Phenom сокета АМ2+. Поначалу было мало и медленно, лучше сделали к 2010.
Упрощающее очеловечивание. SRAM это карлик - гигачад. DRAM это толпа депрессивных астеников. Суммарно последние перенесут намного больше вещей за раз. Но быстро устают, больше едят и каждое действие долгое. Первого уместнее поставить у станка, а не грузчиком назначить.
Acer
Agilent
AVC
AOC
Apem
Apple
Asus
Benq
Bon electronics
Broadcom
Cisco
Dell
Digis
Eizo
Epson
Everlight electronics
Extron
Harman
Harman/Kardon
Hewlett packard (HP)
Hitachi
Hpe
Iiyama
JBL
Javad
JVC
Kenwood
Leica
LG
Lumien
Marshall
MSI
Nakamichi
NEC
Onkron
Optoma
Panasonic
Pioneer
Promethean
Samsung
Screenmedia
Sony
Viewsonic
Vishay
Western digital (WD)
Winstar
Yamaha
Что будет вообще теперь? А что еще?
У неня есть еще один сервер Dell и комплект памяти Samsung. Можно ли поднимать цену еще в два раза?
Недавно я уже проверял комплект ADATA XPG Lancer Blade RGB на 32 ГБ, и к его работе вопросов не возникло. Но со временем стало интересно: что изменится, если добавить еще один близкий по параметрам комплект и перейти на 64 ГБ? Для этого я взял ADATA XPG Lancer Blade AX5U6000C3016G-DTLABBK без RGB-подсветки и проверил, сохранится ли частота 6000 МГц при четырех модулях, пройдет ли система стресс-тесты и есть ли практический смысл в таком апгрейде.

ADATA XPG Lancer Blade упакована в прозрачный пластиковый блистер с красной бумажной вставкой. Отдельной картонной коробки нет, поэтому планки видны еще до вскрытия: можно рассмотреть радиаторы, проверить заводские наклейки и сразу сверить основные параметры. На лицевой части упаковки указаны серия Lancer Blade, стандарт DDR5, пометка Low Profile Heatsink, состав комплекта 16 GB x 2 и скорость 6000 MT/s. Там же размещены логотипы профилей разгона для платформ AMD и Intel.


Комплект поставки минимальный: внутри находятся только два модуля памяти, зафиксированные в пластиковых ячейках. На обратной стороне упаковки есть наклейка с точной моделью AX5U6000C3016G-DTLABBK, таймингами CL 30-40-40 и напряжением 1.4 В. Эти же параметры продублированы на наклейках самих модулей.
Внешне ADATA XPG Lancer Blade выглядит проще версии Lancer Blade RGB, которую я рассматривал раньше. Здесь нет RGB-подсветки. Модули закрыты черными алюминиевыми радиаторами с диагональным рельефом, а ближе к правому краю нанесен логотип XPG DDR5. Оформление не перегружено декоративными элементами, поэтому память спокойно вписывается в темную сборку.




Главное конструктивное отличие от RGB-версии связано с высотой. У Lancer Blade без подсветки она составляет 33.8 мм, тогда как у Lancer Blade RGB заявлено 40 мм. При этом важно не путать высоту с общей толщиной модулей: RGB-версия тоже тонкая, просто RGB вставка сверху добавляет несколько миллиметров. В обычной версии верхняя часть ниже.


В моем случае этот набор покупался не для изменения внешнего вида сборки. Задача была проще и практичнее: увеличить общий объем ОЗУ. По рабочим характеристикам комплект близок к уже установленной ADATA XPG Lancer Blade RGB: две планки по 16 ГБ, режим DDR5-6000, схема таймингов CL30-40-40, а также поддержка готовых профилей разгона для платформ AMD и Intel. Разница между наборами в основном внешняя: у этой версии нет подсветки, радиатор ниже, а оформление сделано проще.
После добавления второго набора объем ОЗУ вырос до 64 ГБ. При этом это не единый кит из четырех планок, а пара самостоятельных комплектов по 32 ГБ: ранее установленная версия Lancer Blade RGB и новая Lancer Blade без подсветки. Для DDR5 такая схема требует отдельной проверки, потому что при заполнении всех DIMM-слотов нагрузка на контроллер памяти становится выше, чем при работе с двумя модулями. Поэтому тестирование не про один докупленный набор сам по себе. Важнее было проверить всю конфигурацию после апгрейда: сохранится ли рабочий режим памяти, как поведут себя четыре планки вместе и не придется ли снижать частоту после перехода с 32 на 64 ГБ.
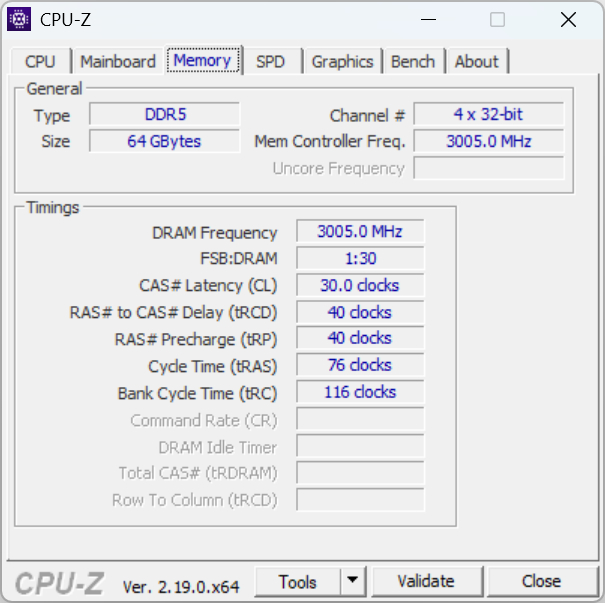
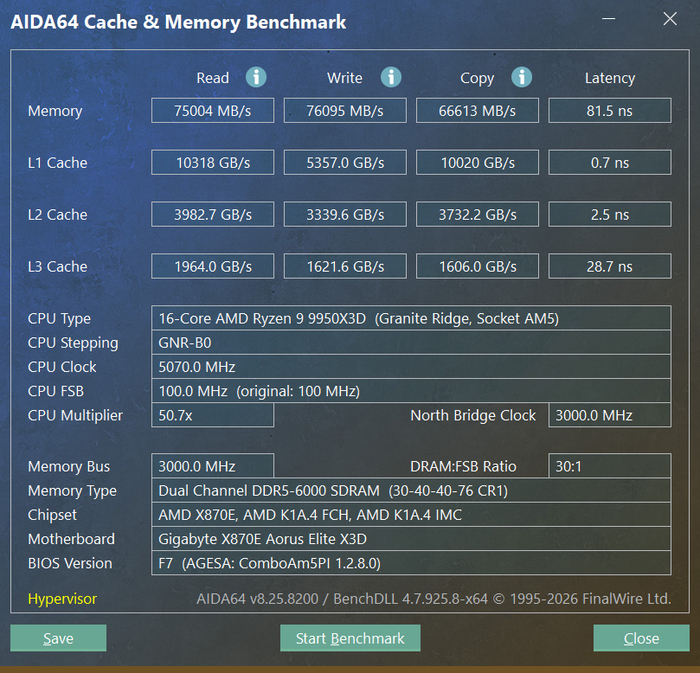
Тестовая платформа построена на 9950X3D (AMD Ryzen 9) и плате Gigabyte X870E Aorus Elite X3D. После установки всех четырех планок память осталась на эффективной частоте 6000 МТ/с в двухканальном режиме. Основные задержки были выставлены как CL30-40-40-76, Command Rate — 1T. Частота memory bus отображалась на уровне 3000 МГц, такой же показатель был у North Bridge Clock.
Сначала я проверил параметры в CPU-Z. Программа определила общий объем памяти как 64 ГБ DDR5. Вкладка Memory показала режим 4 x 32-bit, частоту DRAM Frequency 3005.0 МГц и соотношение FSB:DRAM 1:30. Тайминги соответствовали заявленному профилю: CL 30, tRCD 40, tRP 40, tRAS 76, tRC 116. Частота контроллера памяти в CPU-Z также отображалась как 3005.0 МГц.
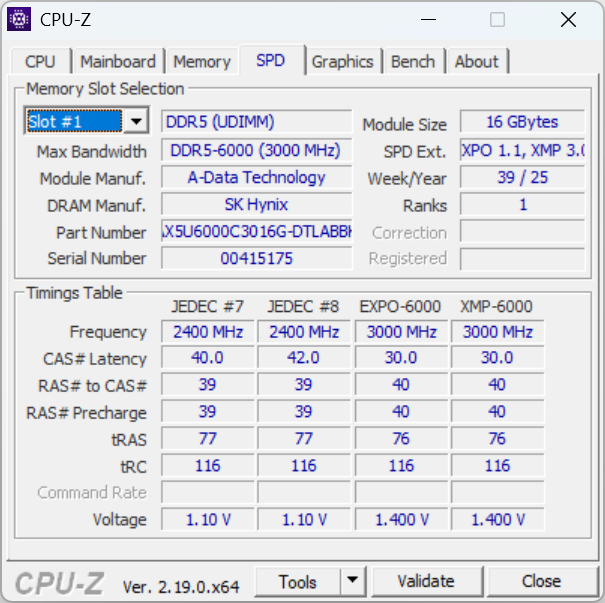
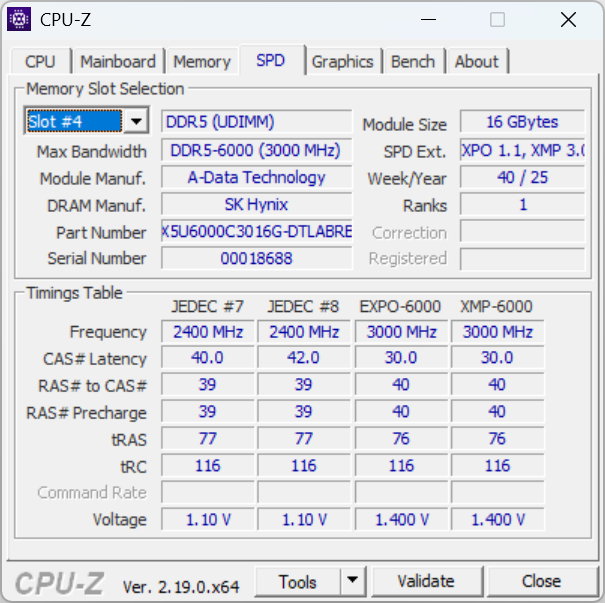
SPD я проверил по каждой установленной планке. По данным CPU-Z, все модули определяются как A-Data Technology, емкость каждого составляет 16 ГБ. Чипы памяти — SK Hynix, ранговость — single rank. В профилях записаны EXPO-6000 и XMP-6000 с частотой 3000 МГц, схемой задержек CL30-40-40-76, значением tRC 116 и питанием 1.40 В. По этим строкам видно, что новый комплект совпадает с уже установленными планками именно по рабочим параметрам: частоте, основным задержкам, профилям и напряжению. Разница остается в физическом исполнении самих модулей: у одного набора есть подсветка и более высокий радиатор, у второго оформление проще и без RGB.
Затем я запустил AIDA64 тест памяти. В конфигурации на 64 ГБ чтение составило около 75000 МБ/с, запись — 76100 МБ/с, копирование — 66600 МБ/с. Задержка вышла 81.5 нс. Для меня здесь был важен не рекорд в бенчмарке, а сам факт сохранения режима 6000 МТ/с после заполнения всех четырех слотов. Пропускная способность осталась на нормальном уровне для такой конфигурации, но латентность уже выше, чем обычно ждешь от пары DDR5-планок с теми же частотой и таймингами. Это как раз тот случай, когда контроллеру памяти приходится работать с более тяжелой схемой подключения.
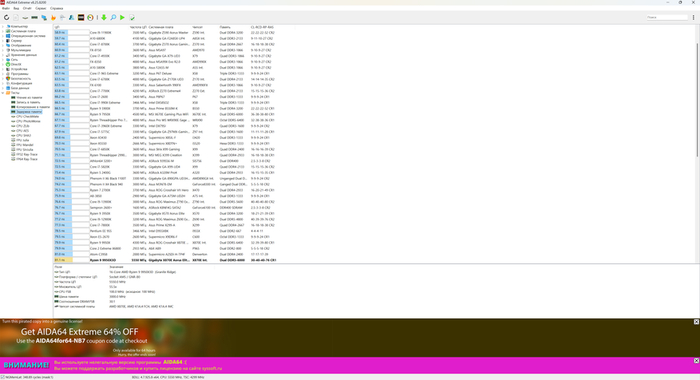
Дальше я перешел к проверке стабильности. В TestMem5 использовалась конфигурация Absolut @ anta777. Тест запускался на 32 потока, под проверку было выделено 50176 МБ памяти из доступных 62958 МБ. Проход занял чуть более часа. Ошибок за время проверки не появилось. Для апгрейда через установку второго комплекта это один из главных пунктов: система не просто загрузилась с четырьмя модулями, а прошла отдельную проверку памяти под нагрузкой.
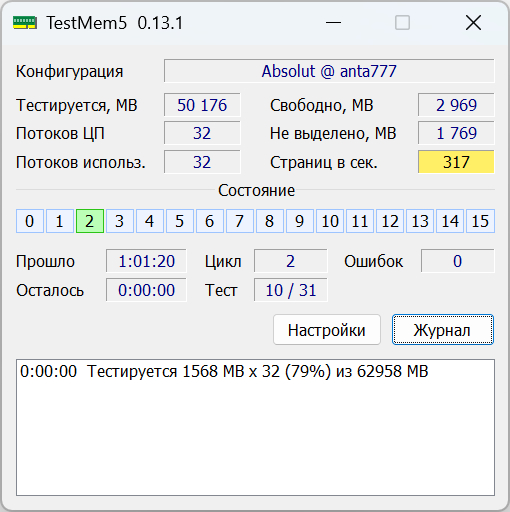
Дополнительно запускался y-cruncher, тест VT3. На момент фиксации результата было пройдено 23 итерации, все со статусом Passed. Общее время составило 2798.980 секунды, то есть 46.650 минуты. Скорость теста держалась около 1.2 x 1010 bits/sec. Этот тест хорошо нагружает не только процессор, но и подсистему памяти, поэтому я использовал его как дополнительную проверку после TestMem5.
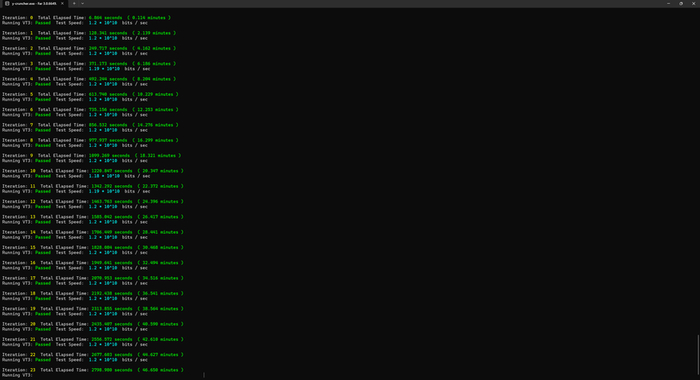
Для оценки общей производительности системы после установки четырех модулей был запущен Cinebench 2026. Процессор AMD Ryzen 9 9950X3D набрал 939 pts в многопоточном тесте и 762 pts в однопоточном. Сам по себе Cinebench не показывает скорость оперативной памяти напрямую, но он полезен как контрольная нагрузка на систему после изменения конфигурации ОЗУ. Сбоев или нестабильного поведения во время теста не было.
В WinRAR 7.20 встроенный тест быстродействия запускался в многопоточном режиме на 32 потока. Общая скорость составила 54964 КБ/с, текущая — 51424 КБ/с. За время проверки было обработано 5272 МБ данных, ошибок не зафиксировано. Нагрузка здесь смешанная: часть результата зависит от процессора, часть от памяти, поэтому такой тест хорошо дополняет синтетику AIDA64.
В 7-Zip 26.00 тест производительности также запускался на 32 потока. Размер словаря был установлен на 32 МБ, программа использовала 7120 МБ из 62958 МБ доступной памяти. После 10 проходов общий рейтинг составил 3022%, итоговая оценка — 8.04 GIPS и 243.394 GIPS. В упаковке итоговая скорость составила 187053 КБ/с, в распаковке — 307078 КБ/с. Здесь уже заметнее, что 64 ГБ дают запас по объему, хотя сам тест в первую очередь упирается в процессор и работу многопоточной нагрузки.
Для игровой части я выбрал Cyberpunk 2077 и сделал прогон в двух сценариях. Первый запуск проходил в 1920х1080 с минимальным пресетом графики. В этом варианте средняя частота кадров дошла до 186 FPS, показатель 1% Low Average составил 122.1 FPS, а 0.1% Low Average — 110.8 FPS. CapFrameX не отметил stuttering, вся тестовая запись прошла как Smooth. По мониторингу игра использовала примерно 3.37 ГБ оперативной памяти.
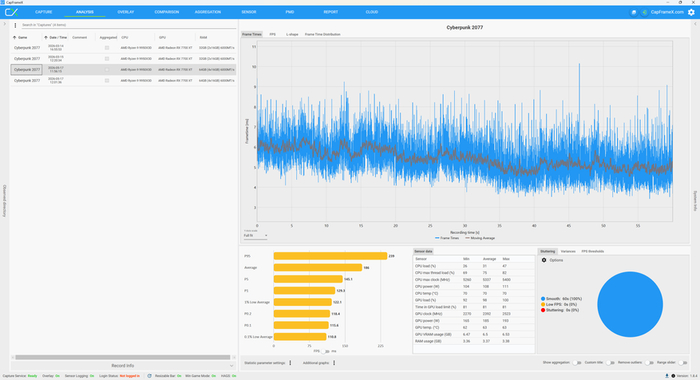
Второй запуск выполнялся уже в 3840х2160 с максимальным пресетом графики. В таком режиме средняя частота составила 45.4 кадра/с, показатель 1% Low Average опустился до 32.1 FPS, а 0.1% Low Average — до 30.9 FPS. CapFrameX снова не зафиксировал stuttering. По данным мониторинга, игра использовала примерно 3.47 ГБ оперативной памяти и около 8.03 ГБ видеопамяти.
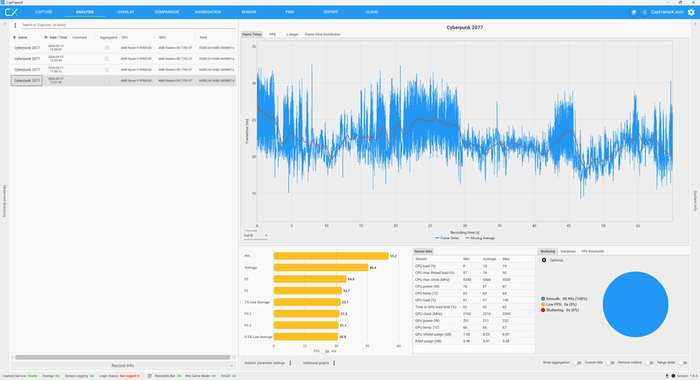
В легком режиме Cyberpunk 2077 держал высокий FPS, а при 3840x2160 с максимальным пресетом упор уже уходил в видеокарту. Для проверки памяти здесь важен не сам средний FPS, а поведение системы под игровой нагрузкой. Четыре планки DDR5 в режиме 6000 МТ/с отработали без заметных рывков, ошибок и признаков нестабильной работы после синтетических тестов.
В обзоре ADATA XPG Lancer Blade RGB я проверял систему с 32 ГБ оперативной памяти. Связка вполне понятная, но хотелось проверить другой вопрос. Что меняется, когда объем увеличивается вдвое, но при этом память остается близкой по частоте, таймингам и профилям?
После установки второго комплекта система увидела 64 ГБ и сохранила режим DDR5-6000 с теми же основными таймингами. Это важнее, чем может показаться на первый взгляд. С DDR5 четыре модуля не всегда ведут себя так же просто, как две планки. Нагрузка на контроллер памяти выше, и иногда приходится снижать частоту или вручную подбирать параметры. У меня система загрузилась в рабочем режиме, CPU-Z и AIDA64 подтвердили частоту и тайминги, а стресс-тесты не показали ошибок.
По синтетическим тестам картина получилась без особого скачка производительности. И это нормально. Само увеличение объема ОЗУ не обязано ускорять чтение, запись или копирование данных, если частота и тайминги остаются близкими. И здесь крайне важно, что это не единый заводской комплект 4x16 ГБ, а два отдельных набора по 32 ГБ, при этом после апгрейда система не потеряла рабочий режим DDR5-6000 и осталась стабильной под нагрузкой.
В архиваторах и процессорных тестах тоже нет свидетельств, что переход на 64 ГБ радикально меняет поведение системы. Такие задачи чаще завязаны на процессор, кэш, частоту памяти и особенности конкретного теста. Если проект или файл не упирается в доступный объем, дополнительные гигабайты просто остаются запасом. Но этот запас начинает иметь смысл, когда параллельно открыты браузер с большим числом вкладок, монтажная программа, исходники, архиватор, мониторинг, запись экрана и еще несколько рабочих утилит. В такой ситуации 32 ГБ может оказаться маловато.
Cyberpunk 2077 хорошо показал эту разницу в подходе. В игровой нагрузке переход на 64 ГБ не надо воспринимать как способ получить больше кадров. В минимальных настройках и HD-разрешении результат больше зависит от процессорной части и общего поведения системы, а в 4K на максимальных настройках основная нагрузка уходит в видеокарту. При этом игра не показала признаков того, что ей обязательно нужны 64 ГБ. Использование оперативной памяти оставалось далеко от предела даже в тяжелом графическом режиме.
Но игровая проверка все равно была полезной. Она показала, что четыре модуля DDR5-6000 не создают проблем в реальной нагрузке. Не только в TestMem5 или y-cruncher, где память проверяется специально, а именно в обычном сценарии, где одновременно работают игра, драйвер, мониторинг и запись данных через CapFrameX. Это ближе к тому, как система используется на практике, а не только в тестовом окне.
И здесь вполне логичный вопрос: для чего вообще переходить на 64 ГБ? Не для того, чтобы каждая игра сразу стала быстрее. Такой апгрейд имеет смысл, если компьютер используется не только как игровая машина. Например, для монтажа видео, работы с большими фотоархивами, виртуальных машин, тяжелых браузерных сессий, 3D-проектов, локальных нейросетевых инструментов, параллельного запуска нескольких рабочих программ. В таких задачах важен не пиковый FPS, а запас по памяти, при котором система меньше обращается к файлу подкачки и спокойнее переносит многозадачность.
ADATA XPG Lancer Blade AX5U6000C3016G-DTLABBK я рассматривал как второй комплект для уже собранного ПК. До этого в системе стояла ADATA XPG Lancer Blade RGB на 32 ГБ, которая работала в режиме DDR5-6000 с таймингами 30-40-40. Новый комплект был нужен для увеличения объема до 64 ГБ, но без смены частоты, таймингов и профилей памяти.
Это не два одинаковых комплекта из одной коробки. У RGB-версии есть подсветка и более высокий радиатор, у обычной Lancer Blade подсветки нет, а высота меньше. При этом по SPD совпали частота DDR5-6000, тайминги 30-40-40, профили EXPO/XMP и напряжение 1.40 В. CPU-Z также показал микросхемы SK Hynix.
Главное, что совпадение характеристик осталось не только в описании. После установки четырех планок система продолжила работать в режиме DDR5-6000. Частоту снижать не пришлось: конфигурация из двух комплектов по 32 ГБ прошла TestMem5, y-cruncher, AIDA64, WinRAR, 7-Zip и проверку в Cyberpunk 2077.
Резкого роста производительности от перехода с 32 на 64 ГБ не появилось. При той же частоте и близких таймингах сам объем не обязан ускорять систему. В Cyberpunk 2077 это было видно по загрузке ОЗУ: даже в 4K на максимальных настройках игра не приближалась к пределу 32 ГБ, а итоговый FPS сильнее зависел от видеокарты и выбранного режима графики.
Для моей сборки это апгрейд по объему, а не попытка выжать скорость из той же платформы. 64 ГБ имеют смысл для монтажа, обработки больших файлов, виртуальных машин, записи экрана, тяжелых браузерных сессий и параллельного запуска нескольких программ.
Всем доброго здравия, хочу спросить о цене б/у пк знакомый предложил приобрести у него пк за 300 к деревянных рублей хотелось бы узнать у знающих людей стоит ли он этих денег на данный момент в эксплуатации он чуть более года вот такие характеристики цены за комплектующие указаны примерно :
Материнская плата ASUS ROG STRIX B650E-F GAMING WIFI - 20к
1000 ГБ M.2 NVMe накопитель Samsung 990 PRO [MZ-V9P1T0BW х2 - 42к
Блок питания DEEPCOOL PX1300P [R-PXD00P-FC0B-EU] черный - 34к
512 ГБ M.2 NVMe накопитель ADATA XPG GAMMIX S70 BLADE [AGAMMIXS70B-512G-CS] - 12к
Видеокарта MSI GeForce RTX 4080 SUPER GAMING X SLIM [912-V511-231] - 140к
Оперативная память ADATA XPG Lancer Blade [AX5U6400C3216G-DTLABBK] 32 ГБ - 46к
Система охлаждения DEEPCOOL LT520 WH белая - 8к
Процессор AMD Ryzen 7 9800X3D OEM - 40к
Новость:
Китайская память начинает выходить на глобальные рынки: модули DDR5 от Corsair замечены с DRAM от CXMT

В модулях Corsair Vengeance DDR5 обнаружены микросхемы CXMT (ChangXin Memory Technologies) с маркировкой CXMT-DDR5-16Gb. Планка объёмом 16 ГБ работает на частоте 6000 МТ/с с таймингами 36-36-36-76 при напряжении 1,35 В и поддерживает профиль XMP 3.0. Чипы выполнены по техпроцессу 17 нм класса G3 - характеристики полностью соответствуют аналогам от Samsung или SK Hynix.
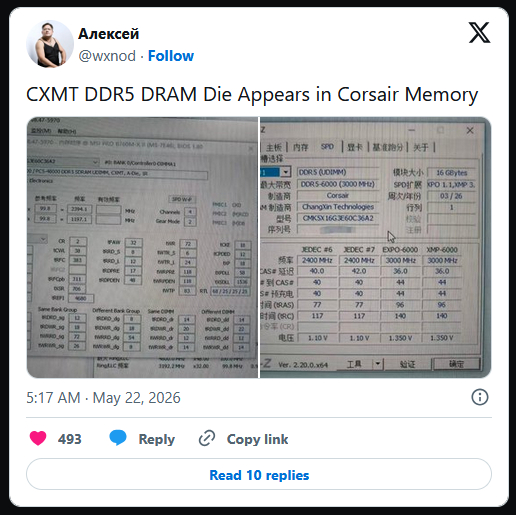
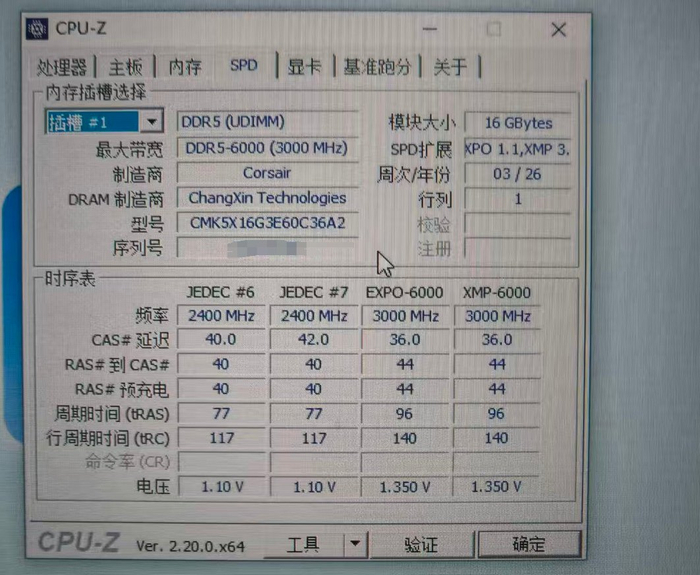

CXMT - ведущий китайский производитель DRAM-памяти, форсированно наращивающий компетенции в сегменте DDR5 на фоне глобального дефицита микросхем общего назначения. По итогам 2025 года компания заняла около 5-10% мирового рынка DRAM, увеличив выпуск с 20 тыс. пластин в месяц в 2020 году до 270-300 тыс. к концу 2025-го. В ноябре 2025 года CXMT официально представила полный спектр модулей DDR5 со скоростями до 8000 МТ/с и плотностью чипов 16 и 24 Гбит в семи форм-факторах, а также память LPDDR5X с пропускной способностью до 10667 МТ/с.

Параллельно с CXMT на рынок DDR5 выходят и другие китайские игроки. Так, компания Jiahe Jinwei (бренд POWEV/SINKER) запустила массовое производство модулей DDR5 RDIMM ёмкостью до 64 ГБ на скорости 5600 МТ/с, ориентированных как на внутренний рынок КНР, так и на экспорт. Ожидается, что китайские производители в совокупности способны занять до 15% мирового рынка DRAM-памяти в ближайшей перспективе, оказывая давление на цены и заставляя традиционных лидеров отрасли корректировать производственные стратегии.
Вдогонку:
Новость:
Бывший глава подразделения чипов Samsung заявляет, что крупные инвестиции Китая в рынок памяти могут обрушить 414%-ный скачок цен на DDR5 в течение года.
https://wccftech.com/ex-samsung-chip-boss-says-chinas-dram-b...








